字符编码、文件处理
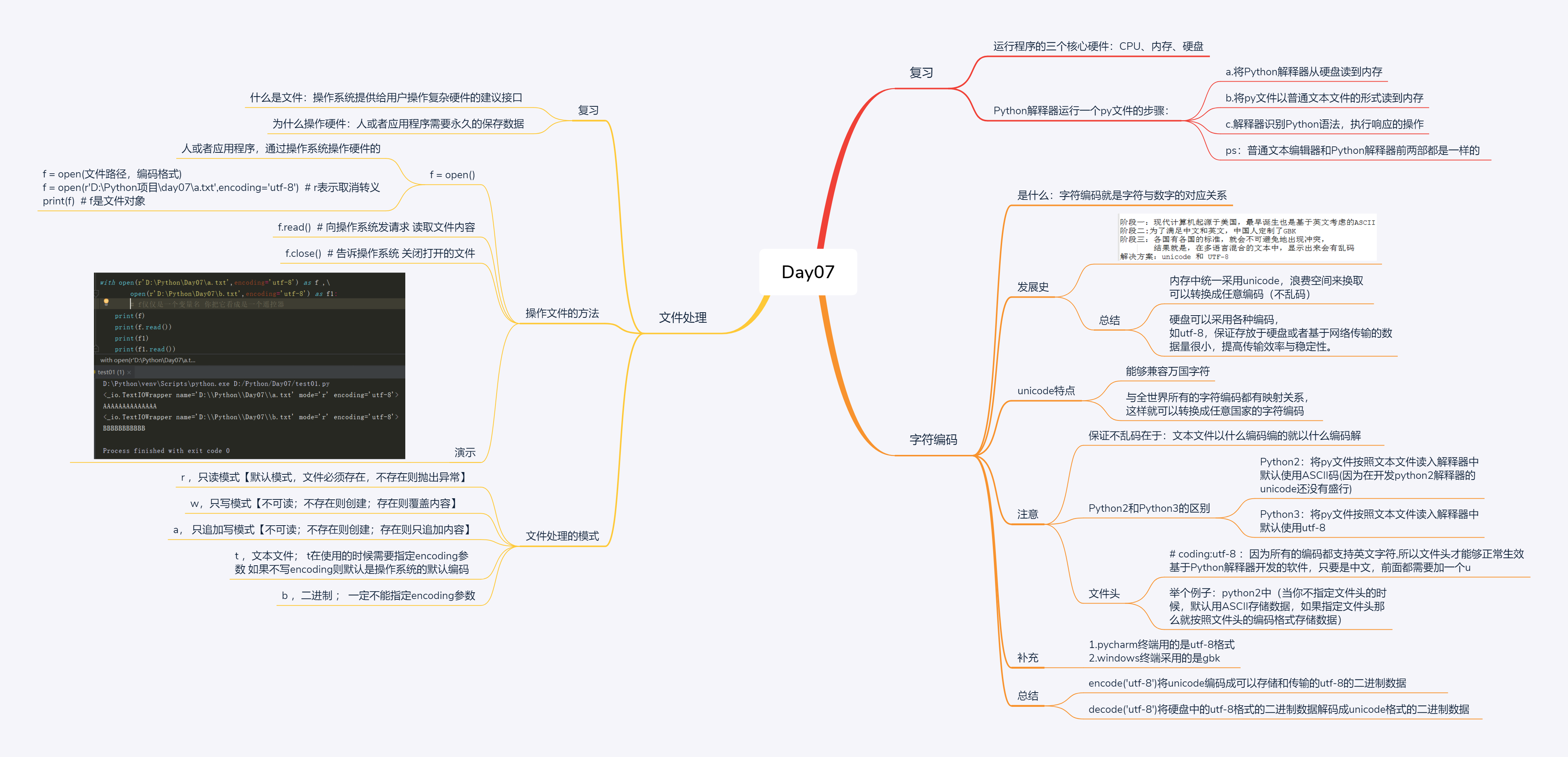
复习
运行程序的三个核心硬件:CPU、内存、硬盘
Python解释器运行一个py文件的步骤:
-
a.将Python解释器从硬盘读到内存
-
b.将py文件以普通文本文件的形式读到内存
-
c.解释器识别Python语法,执行响应的操作
-
ps:普通文本编辑器和Python解释器前两部都是一样的
字符编码
是什么:字符编码就是字符与数字的对应关系
发展史
阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII 阶段二:为了满足中文和英文,中国人定制了GBK 阶段三:各国有各国的标准,就会不可避免地出现冲突, 结果就是,在多语言混合的文本中,显示出来会有乱码 解决方案:unicode 和 UTF-8
-
总结
-
内存中统一采用unicode,浪费空间来换取可以转换成任意编码(不乱码)
-
硬盘可以采用各种编码, 如utf-8,保证存放于硬盘或者基于网络传输的数据量很小,提高传输效率与稳定性。
-
unicode特点
-
能够兼容万国字符
-
与全世界所有的字符编码都有映射关系,这样就可以转换成任意国家的字符编码
注意
-
保证不乱码在于:文本文件以什么编码编的就以什么编码解
-
Python2和Python3的区别
-
Python2:将py文件按照文本文件读入解释器中默认使用ASCII码(因为在开发python2解释器的unicode还没有盛行)
-
Python3:将py文件按照文本文件读入解释器中默认使用utf-8
-
-
文件头
-
coding:utf-8 :因为所有的编码都支持英文字符,所以文件头才能够正常生效
基于Python解释器开发的软件,只要是中文,前面都需要加一个u
-
举个例子:python2中(当你不指定文件头的时候,默认用ASCII存储数据,如果指定文件头那么就按照文件头的编码格式存储数据)
-
补充
-
1.pycharm终端用的是utf-8格式 2.windows终端采用的是gbk
总结
-
encode('utf-8')将unicode编码成可以存储和传输的utf-8的二进制数据
-
decode('utf-8')将硬盘中的utf-8格式的二进制数据解码成unicode格式的二进制数据
文件处理
复习
-
什么是文件:操作系统提供给用户操作复杂硬件的建议接口
-
为什么操作硬件:人或者应用程序需要永久的保存数据
操作文件的方法
-
f = open()
-
人或者应用程序,通过操作系统操作硬件的
-
f = open(文件路径,编码格式) f = open(r'D:\Python项目\day07\a.txt',encoding='utf-8') # r表示取消转义 print(f) # f是文件对象
-
-
f.read() # 向操作系统发请求 读取文件内容
-
f.close() # 告诉操作系统 关闭打开的文件
-
演示
with open(r'D:\Python\Day07\a.txt',encoding='utf-8') as f ,\ open(r'D:\Python\Day07\b.txt',encoding='utf-8') as f1: ''' f仅仅是一个变量名 你把它看成是一个遥控器 ''' print(f) print(f.read()) print(f1) print(f1.read())
文件处理的模式
-
r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
-
w,只写模式【不可读;不存在则创建;存在则覆盖内容】
-
a, 只追加写模式【不可读;不存在则创建;存在则只追加内容】
-
t ,文本文件; t在使用的时候需要指定encoding参数 如果不写encoding则默认是操作系统的默认编码
-
b ,二进制 ; 一定不能指定encoding参数
演示1:
# mode参数 可以不写,不写的话默认是rt(只读文本文件)这个t如果不写默认就是t
with open(r'D:\Python\Day07\a.txt',mode='r',encoding='utf-8') as f:
print(f.readable()) # 是否可读
print(f.writable()) # 是否可写
print(f.read()) # 一次性将文件全部读出来
#输出结果 True False AAAAAAAAAAAAAA Process finished with exit code 0
演示2:
with open(r'a.txt','r',encoding='utf-8') as f:
print(f.readable()) # 是否可读
print(f.writable()) # 是否可写
print('>>>1:')
print(f.read()) # 一次性将文件内容全部读出
print('>>>2:')
print(f.read())
print('>>>:结束')# 读完一次之后,文件的光标已经在文件末尾了,再读就没有内容可读了
#输出结果 True False >>>1: AAAAAAAAAAAAAA BBBBBBBB >>>2: >>>:结束
演示3:
with open(r'a.txt','r',encoding='utf-8') as f:
print(f.readlines()) # 返回的是一个列表,列表中的一个个元素对应的就是文件的一行行内容
print(f.read())
print('>>>:结束')
#输出结果 ['AAAAAAAAAAAAAA\n', 'BBBBBBBB'] >>>:结束
演示4:
with open(r'a.txt',mode='r',encoding='utf-8') as f:
print(f.readline()) # 只读取一行内容,读完本行后,光标跳到了下一行
print(f.readline())
print(f.readline())
print(f.readline())
print('>>>:结束')
#输出结果 AAAAAAAAAAAAAA BBBBBBBB >>>:结束
演示5:
with open(r'a.txt',mode='r',encoding='utf-8') as f:
for i in f: # f可以被for循环,没for循环一次,读一行内容
print(i) # 这个方法就可以解决大文件一次性读取占用内存过高的问题
print('结束')
#输出结果 AAAAAAAAAAAAAA BBBBBBBB 结束