

tensorflow 单机多GPU训练时间比单卡更慢/没有很大时间上提升
使用tensorflow model库里的cifar10 多gpu训练时,最后测试发现时间并没有减少,反而更慢
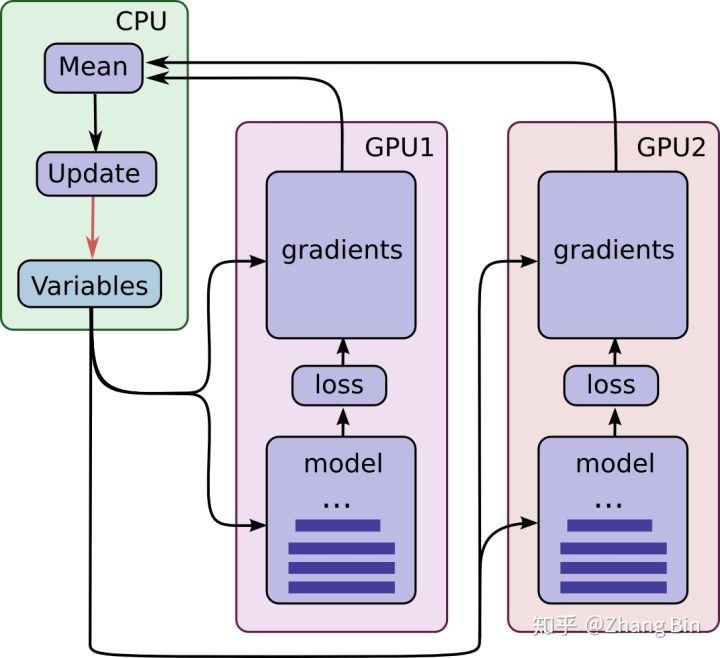
参考以下两个链接
https://github.com/keras-team/keras/issues/9204
https://medium.com/@c_61011/why-multi-gpu-training-is-not-faster-f439fe6dd6ec
原因可能是在cpu上进行参数梯度同步占每一步的很大比例
‘’‘
It seems that CPU-side data-preprocessing can be one of the reason that greatly slow down the multi-GPU training, do you try disabling some pre-processing options such as data-augmentation and then see any boost?
Besides, the current version of multi_gpu_model seems to benefit large NN-models only, such as Xception, since weights synchronization is not the bottleneck. When it is wrapped to simple model such as mnist_cnn and cifar_cnn, weights synchronization is pretty frequent and makes the whole time much slower.
’‘’
然后看到建议上提高模型复杂度(尤其是卷积层数)或者提高输入数据的大小,就可以看到多gpu训练的优势效果了
