
How to Avoid Producing Legacy Code at the Speed of Typing
英语不好翻译很烂。英语好的去看原文。
About the Author

I am a software architect/developer/programmer.
I have a rather pragmatic approach towards programming, but I have realized that it takes a lot of discipline to be agile. I try to practice good craftsmanship and making it work.
lars.michael.dk, 2 Mar 2015 CPOL
原文地址:http://www.codeproject.com/Articles/882165/How-to-Avoid-Producing-Legacy-Code-at-the-Speed-of
This article provides a recipe on how to avoid producing legacy code at the speed of typing by using a proper architecture and unit testing.
Introduction
作为一个企业软件开发者,你经常和产出遗留代码(legacy code)做斗争-那种不值得维护或支持的代码。你在不断努力避免重写重复的东西抱着微弱的希望以期下次你能刚好做的正确。【原文:You are constantly struggling to avoid re-writing stuff repeatedly in a faint hope that next time you will get it just right.】
遗留代码(legacy code)的特征是,其中,不好的设计和建造模式或者依赖于过时的框架或第三方组件。一下是你可能认识的几个典型例子:
你或者你的团队产出了一个漂亮的,功能丰富的Windows应用。之后,你意识到真正的需求是一个浏览器(web应用)或者移动应用。你意识到为你的应用替换UI将需要付出更加大量的努力,因为你嵌入了太多领域功能(domain functionality)在它的UI里面。
另一个情景可能是你编写了一个后端,它是深度渗透在某一个特定的ORM-例如Nhibernate或者Entity Framework-或者高度依赖与某一个RDBMS。在这一个点上,你想要改变策略来让后端避免使用ORM和使用文件存储的持久化数据库,但是很快你就意识到这几乎是不可能完成的,因为你domain functionality 和data layer 是紧紧耦合。
在上述两种情况下,你以打字的速度来生产遗留代码(legacy code)。
然而,那还是有希望的。通过采用一些简单技巧和原则,你可以永远改变这一已经注定的局面。
The Architectural Evolution
下面,我将描述三个阶段标准商业软件开发的三个典型模式。几乎所有开发者都处于第二阶段,但关键是要进入第三阶段,你将最终成为一个建筑模式的忍者。

Phase 1 - Doing it Wrong
大多数开发者听过分层设计模式,所以很多第一次尝试设计模式就像下面一样-把前后端进行功能责任分离的两层结构:
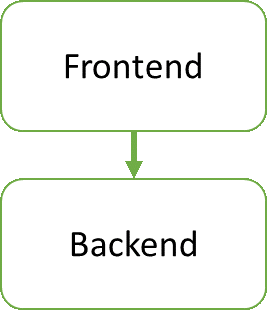
到目前为止还好,但是很快你就意识到那有一个极大的问题,也就是引用程序的业务逻辑和前端以及后端纠缠在一起,并且依赖于它们。
Phase 2 – A Step Forward
因此,下一个尝试是引入一个中间层-一个domain layer-由你应用程序的真正的业务逻辑组成:
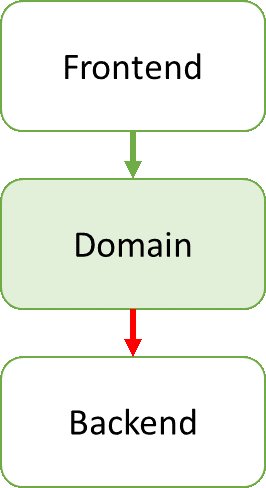
这种模式看起来具有迷惑性的良好结构和解耦性。然而,事实并非如此。问题是红色的依赖箭头表明domain layer对后端具有天生的依赖-典型的,因为你在domain layer使用new(c#或者java)来创建后端类(backend classes)的实例。domain layer 和后端是紧紧耦合的。这有许多缺点:
- domain layer 功能不能再其他的上下文环境中单独重用。你需要把他的依赖项(the backend)一并引入。
- domain layer 无法单独的进行单元测试。你需要关联它的依赖项,后端代码
-
一个后端的实现(例如一个使用RDMBS数据库)无法简单的被另一个后端(使用文件数据库)实现替换
All of these disadvantages dramatically reduces the potential lifetime of the domain layer. That is why you are producing legacy code at the speed of typing.
所有这些缺点都在减少domain layer的声明周期。这是为什么你在以打字的速度产生遗留代码的原因
Phase 3 – Doing it Right
你要做的其实很简单。你只需调转代表依赖关系的红色箭头。这是一个微小的调整,但是结果大不同:
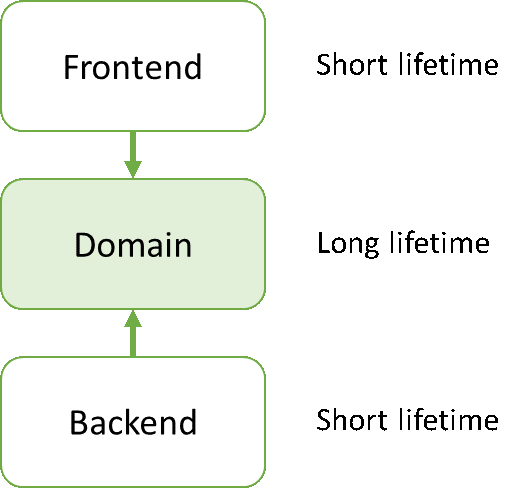
这一设计模式坚持依赖倒置原则【Dependency Inversion Principle 】(DIP)-面向对象设计最重要的原则之一。重点是,一旦这一模式被确立-依赖关系立刻调转-领域层的潜在生命周期得到大幅度增加。UI需求或者转变从Windows窗口到浏览器或者移动设备,或者你的持久化存储可能从关系型数据库(RDBMS)转换到文件型存储,但是现在所有改变都可以很容易在不修改领域层的情况下实现。因为这样的实现前端和后端很好的与领域层解耦。因此,领域层编程一个代码库理论上你几乎永远不用去替代-至少持续到你的业务改变或者整体框架发生改变的时候。现在,你可以有效地和你的遗留代码战斗了
另一方面来说,让我给你一个简单的示例来演示如何在实践中提升DIP:
也许你有一个product service在领域层,它可以对定义在后端的products repository执行CRUD操作。这样经常导致像下图一样的错误指向的依赖关系:
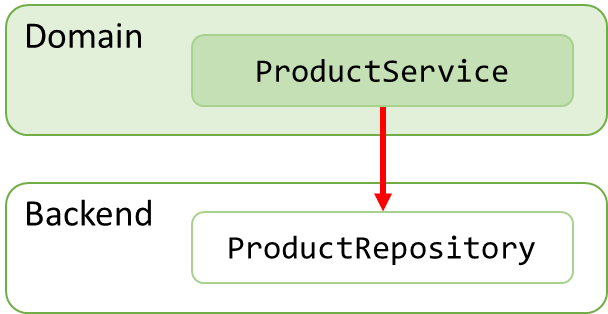
这样是因为你不得不在product service的某处使用”new“,这就产生了对product repository的依赖:
var repository = new ProductRepository();应用DIP原则来倒转这样依赖关系,你必须在领域层以IProductRepository接口的方式引入一个product repository的抽象并且让product repository 实现这个接口(implementation of this interface):
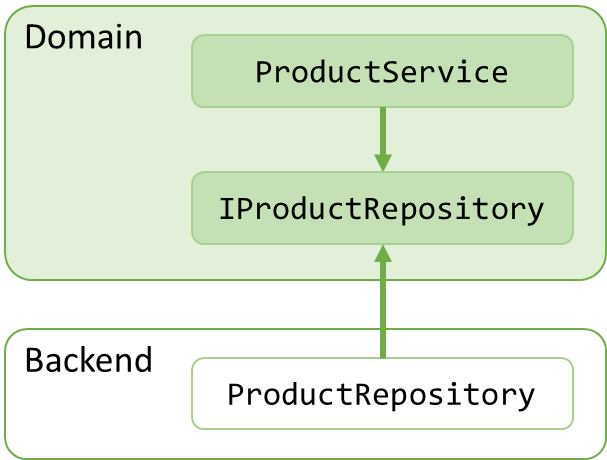
现在,作为使用New产生product repository 实例的替代方案,你可以注入repository 到service 通过一个构造参数(constructor argument):
private readonly IProductRepository _repository;
public ProductService(IProductRepository repository){_repository = repository;
}
这是依赖注入的知识(Dependency injection DI)。我以前已经在一篇博客中做过详细介绍见:Think Business First.
一旦你正确的应用了全部设计模式,对抗遗留代码的目标显而易见:把尽量多个功能引入domain layer(领域层),让前端和后端不断收缩同时让domain layer(领域层)不断丰满:
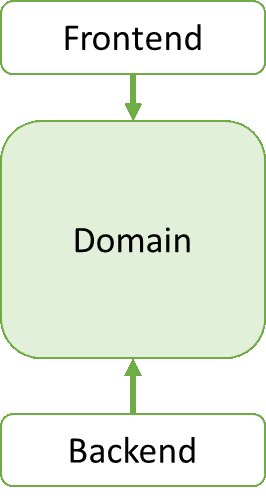
这一设计模式产出的一个实用的副产品,它使它自己很容易对domain functionality(领域功能)进行单元测试。因为domain layer 的耦合特性以及面对所有的依赖都是表现为抽象的(如一个接口或者一个抽象基类)。这样很容易为他们的抽象伪造出一个对象来实现单元测试。所以它是”在公园散步“来守卫整个domain layer和单元测试(unit tests)【注:原文 So it is “a walk in the park” to guard the entire domain layer with unit tests. 】.你要做的无外乎就是努力提供超过100%覆盖率的单元测试来保证你的domain layer足够健壮并且坚如磐石。这有增加了你domain layer的生命周期。
你可能已经了解到这不仅仅是传统的前端和后端,但是所有其他的组件-包括单元测试或者一个http-based 的Web API-会担当一个domain layer的消费者角色。因为,这样的设计模式描述起来像一个onion layers:
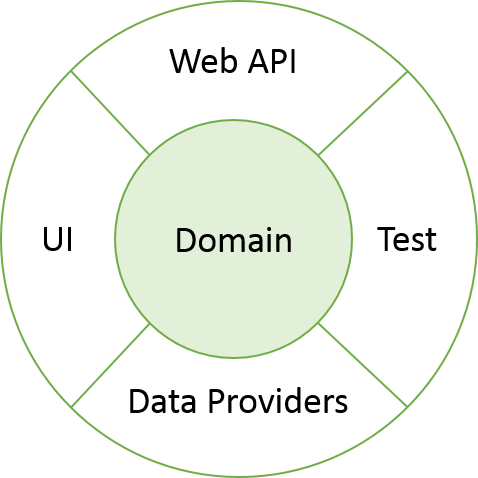
最外层的组件消费领域库代码(domain library code)-通过提供领域抽象(接口或者基类)具体实现或者作为领域方法(domain functionality)的直接用户(domain model 和services)。
无论如何,要记住:耦合的方向总是指向中心的-指向domain layer。
在这一点上,它看起来好像太理论化,and,well…,有点抽象。不过,它原则上不需要做很多。在另一篇文章中(CodeProject article of mine ),我描述和提供了一些遵从所有原则的简单的代码。那个示例的代码非常简单,但是非常接近于正式的产品代码。
Summary
作为一个商业软件开发者避免产生遗留代码(legacy code)是一场持久的战斗。想获胜的话,执行下列操作:
- 确保所有的依赖箭头通过应用依赖倒置原则(DIP)和依赖注入(DI)而指向中央和独立的domain layer
- 不断地健壮domain layer,通过尽可能多的把functionality移动到domain layer,使domain layer 变得丰满而是外层(onion layer 中的outer layer)逐渐萎缩。
-
使用单元测试(unit tests)覆盖领域层(domain layer)的每个的单个功能。
遵循这些简单原则也许最终将汇合到一起。你的code也许将比以前拥有一个超乎想象的长生命周期,因为:
- 领域层的功能(domain layer functionality)可以在许多不同的上下文环境中复用。
-
100%覆盖率的单元测试(unit test)可以使domain layer 非常健壮和坚如磐石。
-
领域层的抽象(例如持久化机制)实现可以轻松的替换成其他的实现方式
-
领域层是容易维护的。
License
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL)
