
图解Knative核心组件Serving基础设计
最近闲下来,打算把Knative的核心组件Serving给学习下,会继续采用k8s源码学习的方式,管中窥豹以小击大,学习serving的主要目标: 可观测性基础设施、自动伸缩、流量管理等核心组件的设计与实现,今天先简单臆测下,感兴趣的同学, 一起来学习吧
1. 基于云原生的单体应用构建
大多数公司的服务可能都已经经过单体、SOA演进到了当下流行的微服务架构,微服务给我们带来了独立演进、扩容、协作、数据自治等便利的背景下,也带来了诸如稳定性保障、维护、服务治理等实际的问题,我们今天来一起来回归单体,比如我们要新开一个业务,新上一个小的模块这个场景,在云原生的场景下,是如何玩的
1.1 云原生下的单体应用
云原生有很多大佬有很多的解释,我就简单理解成是基于云构建而来,可以使用云上所有已知的现有的服务,同时享受云所带来的弹性、按需付费、高可用等方面的原生能力
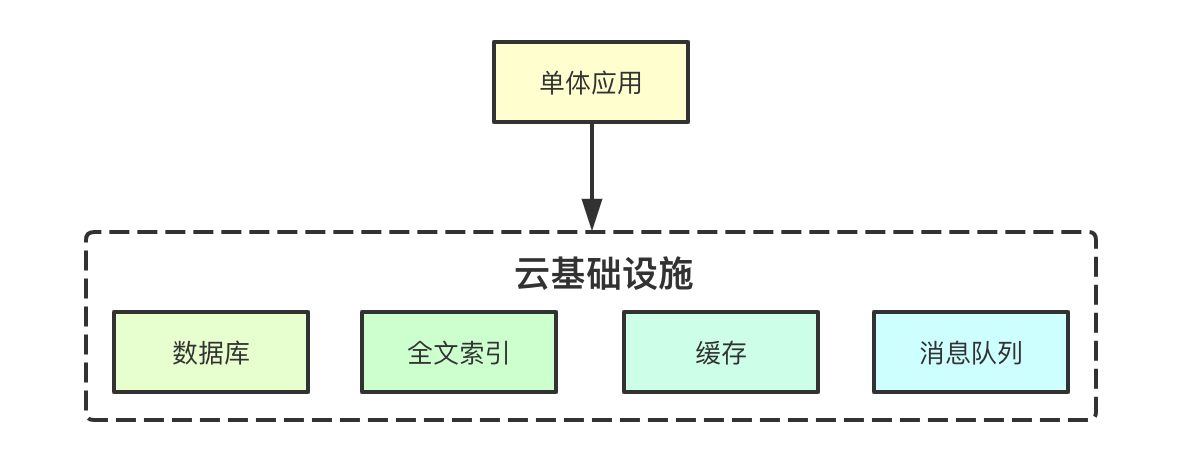
一个基础的单体应用通常会依赖如下几部分:持久化数据存储、高性能缓存、全文索引、消息队列等常见组件, 各家云厂商大多数会包含这些基础的服务,我们只需要引入对应的类库完成我们的应用逻辑即可, 然后程序就完成代码的coding后,下一步就是交付了
1.2 基于k8s的云原生交付
基于k8s的云原生已经成为一个事实上的标准,将代码和应用的数据打包成docker镜像,基于Pod的交付模式,让我们并不需要关注我们是使用IDC里面的实体机,还是公有云的云服务,我们只需要打包成docker镜像,然后设置好档期环境的配置数据,我们的单体应用就可以运行了, 但是通常我们会有一些非业务需求, 比如监控、日志等, 下一节我们来解决这些问题
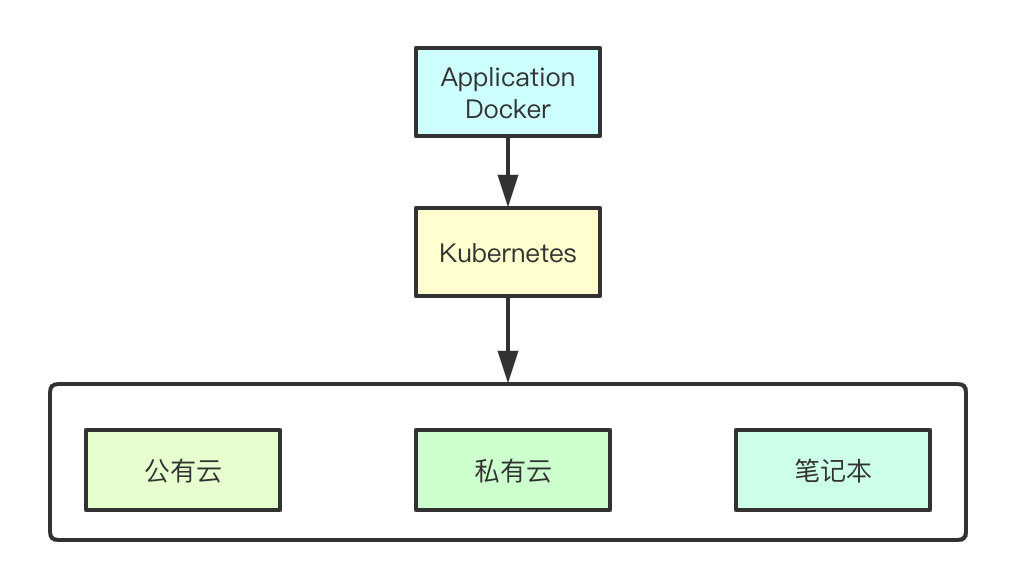
1.3 slidecar模式
在应用开发的初期,我们可能并没有考虑监控、日志这种可观测性的需求,通常是在上线的时候才会考虑这些,而基于k8s的云原生的环境下,通常会使用一个slidecar来实现这种基础功能的增强,通过嵌入一个slidecar容器完成这种基础组件的复用,可以基于slidecar模式实现日志、监控、分布式跟踪、Https支持等基础功能,而让上层应用只关注业务逻辑的实现
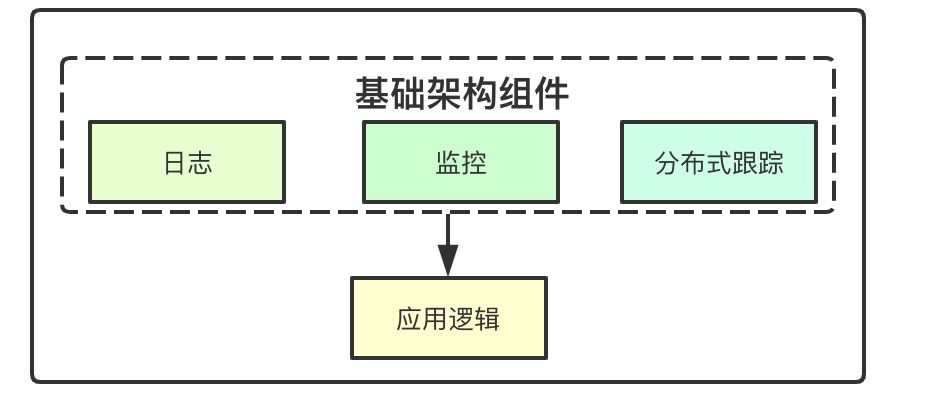
1.4 服务即基础设施
在公司中通常一个业务往往都会进行一些公司内部系统的接入,比如用户、支付、运营等服务,如果公司的服务也可以与基础设施同等对待,并且这些服务也可以通过k8s的形式进行交付,则我们就可以只关注单体应用自身的扩展(小前台)
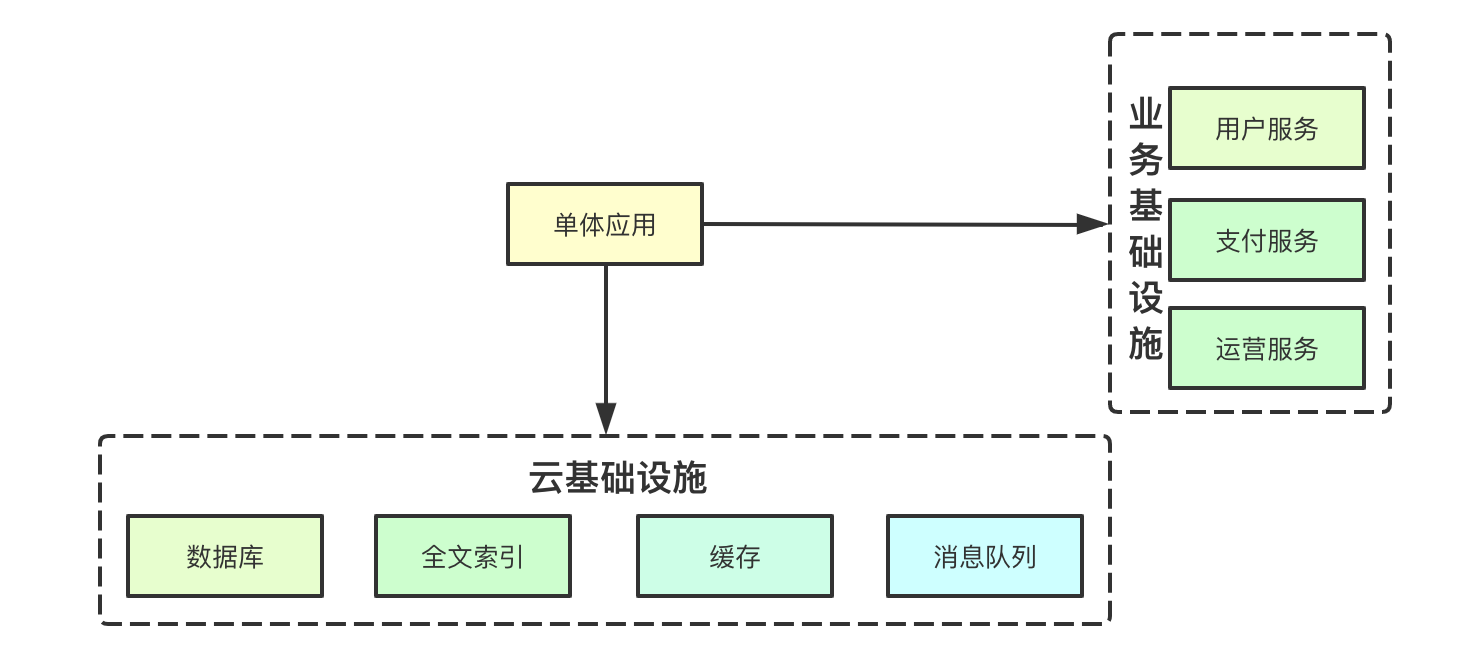
通过上面的设想我们构建出了一个基础的单体应用,应用程序只需要关注应用逻辑的编写,全部的业务逻辑都耦合在一个应用内,其余的基础设施、非业务需求全都由其他组件实现,接下来就该部署了,通常我们就需要分配个XHXG配置的Pod,然后为了高可用可能还需要N个replicaset,然后再来个HPA体验下自动伸缩,跑了一段时间可能会发现,可能一天就两个巴掌的访问量,可是依旧占用着N*XHXG的资源,以这个角度我们来进入我们今天的主题Knative
2.Knative
Knative还在不断变化中,一些设计文档也并没有对外开放,读起来就相对k8s难一些,但整体代码量相比较也少了一些,在后续的文章里面我们还是先管中窥豹,逐个组件进行代码阅读,但因为没有相关的Proposal, 主要是参考冬岛大神的相关文章来进行代码的阅读,只是个人理解,如有不对,欢迎指教,接下来我们看看knative是如何完成上面提到的功能与实现按需分配关键组件, 我们从流量入口开始依次介绍各个组件
2.1 基于Istio实现南北向流量的管控
在k8s中南北向流量通常由Ingress来进行管控,而在kantive流量管控的实现,主要是依赖于istio, Istio是一个ServiceMesh框架,Knative中与其集成主要是使用了istio的南北向流量管控的功能,其实就是利用istio对应的ingress的功能, 主要功能分为下面两个部分
2.1.1 版本部署管理
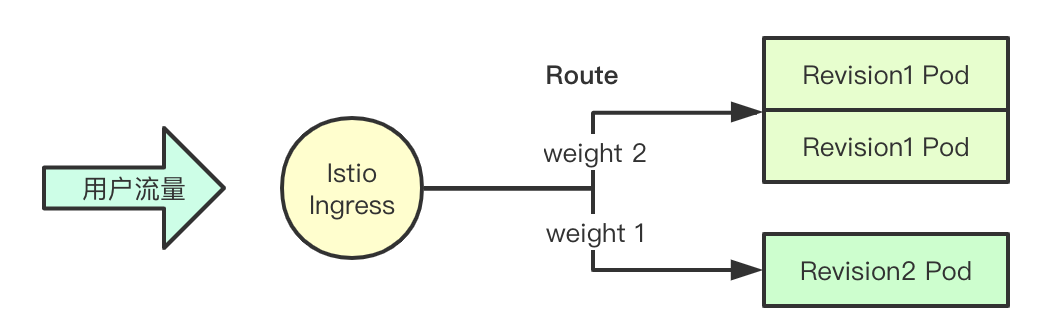
Knative里面支持蓝绿、金丝雀等发布策略,其核心就是通过自己的revision版本管理和istio中的ingress的路由配置功能,即我们可以根据自己的需要设定对应的流量策略,从而进行版本的发布配置管理
2.1.2 自动伸缩(至零)
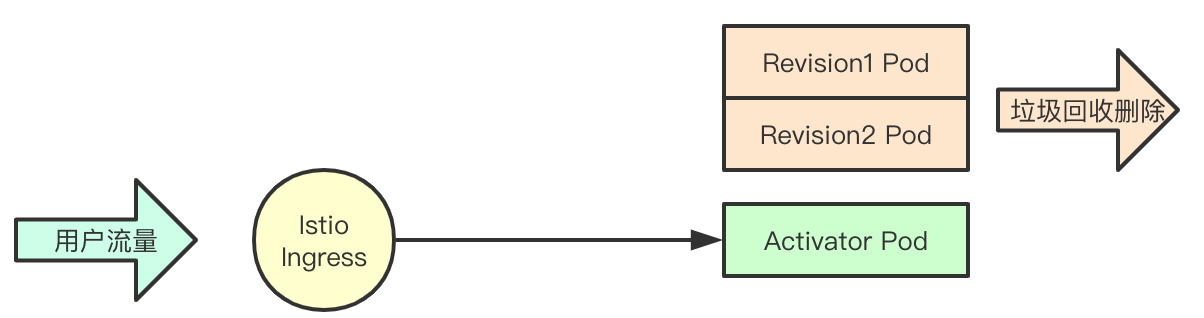
Knative自动伸缩有两个特点:按需自动分配、缩容至零,按需分配时指的knative可以根据应用的并发能力,来自动计算实现自动扩容,而且整个基本上是秒级,不同于HPA, 其次是就是缩容至零,即可以将对应的业务容器Pod,全部干掉,但是新进入请求之后会立即进行分配,并不影响正常访问(可能初期延迟会相对高一些)
2.2 Queue slidecar
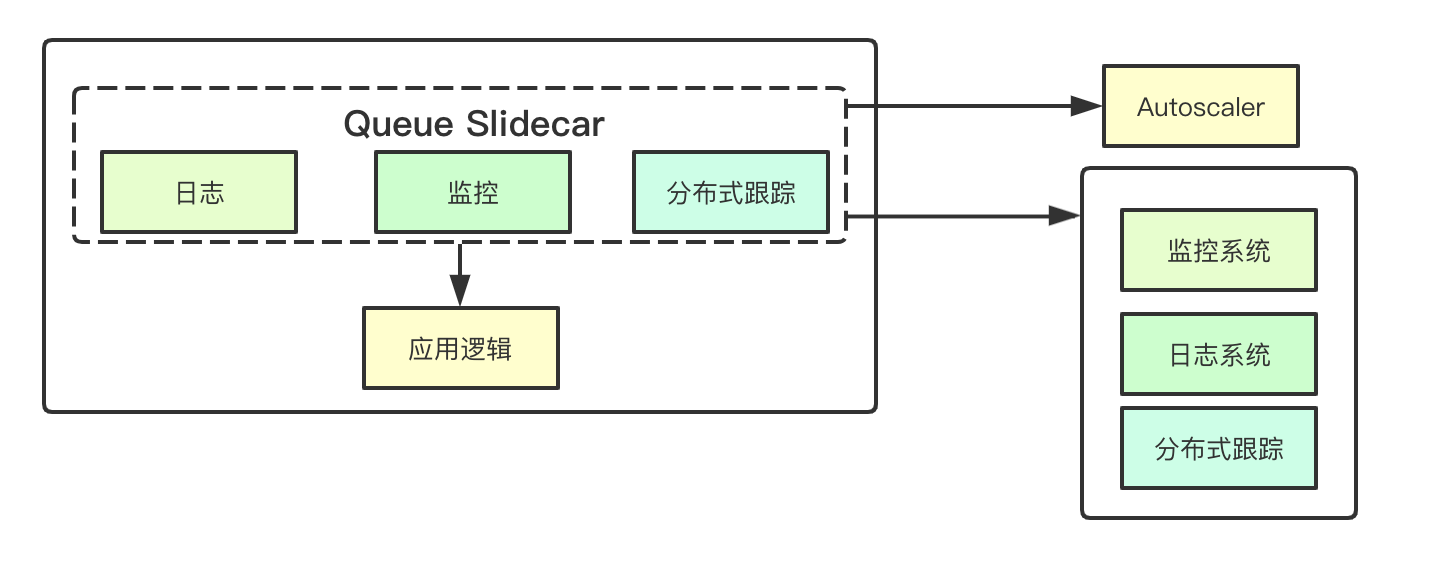
在上面到过可观测性需求,在应用服务中通常可以分为三个部分:日志、监控、分布式跟踪,为了实现这些功能Knative实现了Queue组件,其职责目前理解主要是分为两个部分:完成观测性数据收集、代理业务容器的访问, Queue组件通过代理的方式实现上面提到指标的统计, 并将对应的数据汇报给后端的日志/监控/分布式跟踪服务, 同时还需要向autoscaler同步当前的并发监控, 以便实现自动伸缩功能, Queue主要是代理应用容器, 而Kantive支持缩容至零的特性, 在缩容至零的时候, Knative就会使用一个Activator Pod来替代Queue和应用容器,从而实现缩容至零
2.3 Activator
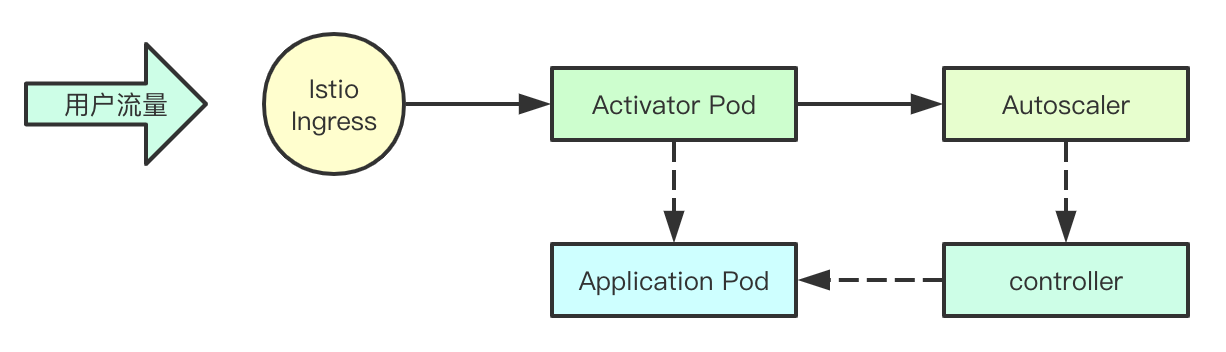
Activator容器是缩容至零的关键,当业务容器没有访问的时候,Knative就会将对应的ingress流量指向Activator组件,当缩容至零的时候,如果此时又业务请求,Activator会立即通知autoscaler立刻拉起业务容器,并将流量转发真正的业务容器,这样既可以完成流量的无损转发,又可以实现按需付费,再也不用为没有访问量的业务,一直启动着Pod了, Activator并不负责实际的伸缩决策,伸缩组件主要是通过Autoscaler来实现
2.4 Autoscaler
Autoscaler是Knative中实现自动扩容的关键,其通过Activator和Queue两个组件传递过来的监控数据并根据配置来计算,实时动态的调整业务容器的副本数量,从而实现自动伸缩
2.5 Controller
Controller是Knative对应资源的控制器,其本身的功能跟k8s中其他的组件的实现类似,根据资源的当前状态和期望状态来进行一致性调整,从而实现最终一致性
2.6 webhook
Knative是基于k8s的CRD实现的,其webhook主要包含对应资源数据的验证和修改等admission相关
3. 总结
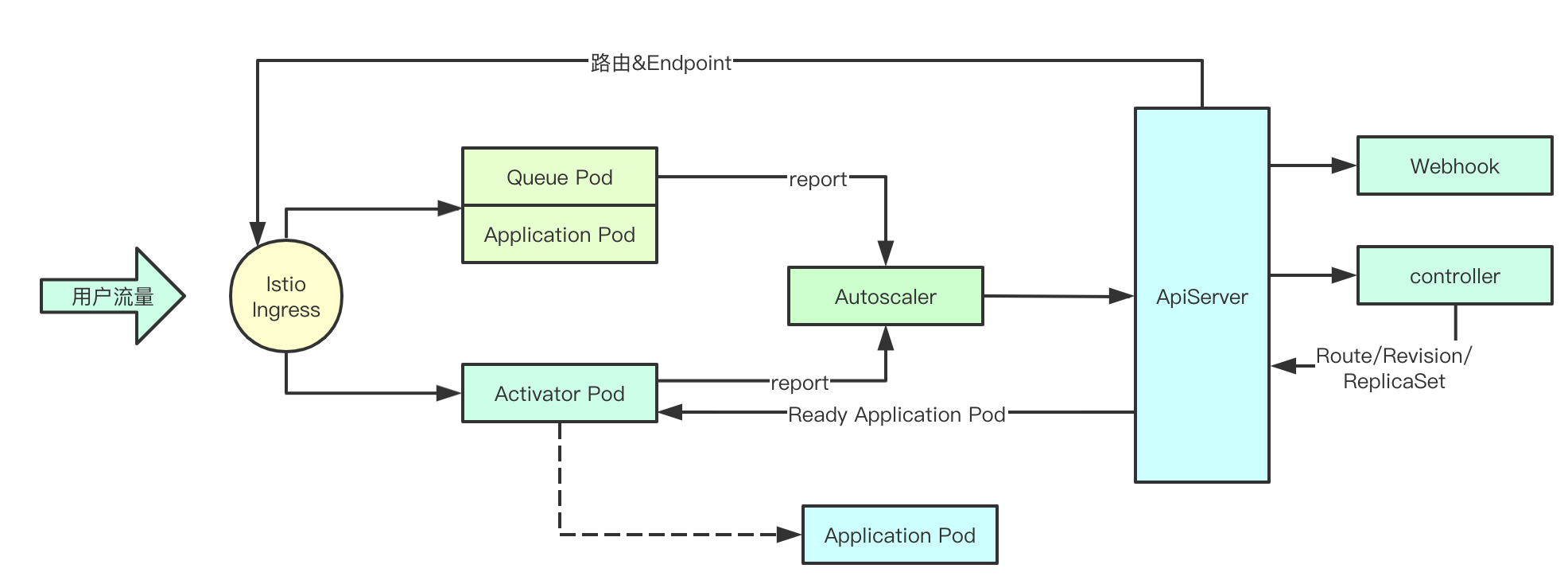
结合上面的组件功能猜想,大概猜想了核心的数据流的实现,如图所示,我们可以分为五层来考虑:观测层(Queue和Activator)、决策层(Autoscaler)、控制层(Controller)、准入层(Webhook)、路由层(Istio INgress), 通过观测层实时获取用户请求数据,发给决策层进行决策,并将决策结果写入到Apiserver, 控制层感知,负责进行对应资源的更新,最终由路由层感知,进行流量分配,这样就实现了整体流量的感知、决策、路由等核心功能,暂时就理解这些,后续希望随着代码的深入,有更深的体会,祝我好运,good luck!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号