
5月10日
facenet预测部分
2、根据初步特征获得长度为128的特征向量
利用主干特征提取网络我们可以获得一个特征层,它的shape为(batch_size, h, w, channels),我们可以将其取全局平均池化,方便后续的处理(batch_size, channels)。
我们可以将平铺后的特征层进行一个神经元个数为128的全连接。此时我们相当于利用了一个长度为128的特征向量代替输入进来的图片。这个长度为128的特征向量就是输入图片的特征浓缩。
3、l2标准化
在获得一个长度为128的特征向量后,我们还需要进行l2标准化的处理。
这个L2标准化是为了使得不同人脸的特征向量可以属于同一数量级,方便比较。
在进行l2标准化前需要首先计算2-范数: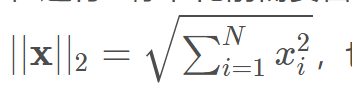
,也就是欧几里得范数,即向量元素绝对值的平方和再开方。
L2标准化就是每个元素/L2范数;
在pytorch代码中,只需要一行就可以实现l2标准化的层。
4、构建分类器(用于辅助Triplet Loss的收敛)
当我们完成第三步后,我们已经可以利用这个预测结果进行训练和预测了。
但是由于仅仅只是用Triplet Loss会使得整个网络难以收敛,本文结合Cross-Entropy Loss和Triplet Loss作为总体loss。
Triplet Loss用于进行不同人的人脸特征向量欧几里得距离的扩张,同一个人的不同状态的人脸特征向量欧几里得距离的缩小。
Cross-Entropy Loss用于人脸分类,具体作用是辅助Triplet Loss收敛。
想要利用Cross-Entropy Loss进行训练需要构建分类器,因此对第三步获得的结果再次进行一个全连接用于分类。

