
5月6日
三、预测结果的解码
1、获得预测框与得分
在对预测结果进行解码之前,我们再来看看预测结果代表了什么,预测结果可以分为3个部分:
通过上一步,我们获得了每个特征层的三个预测结果。
本文以(20,20,1024)对应的三个预测结果为例:
1、Reg预测结果,此时卷积的通道数为4,最终结果为(20,20,4)。其中的4可以分为两个2,第一个2是预测框的中心点相较于该特征点的偏移情况,第二个2是预测框的宽高相较于对数指数的参数
2、Obj预测结果,此时卷积的通道数为1,最终结果为(20,20,1),代表每一个特征点预测框内部包含物体的概率。
3、Cls预测结果,此时卷积的通道数为num_classes,最终结果为(20,20,num_classes),代表每一个特征点对应某类物体的概率,最后一维度num_classes中的预测值代表属于每一个类的概率;
该特征层相当于将图像划分成20x20个特征点,如果某个特征点落在物体的对应框内,就用于预测该物体。
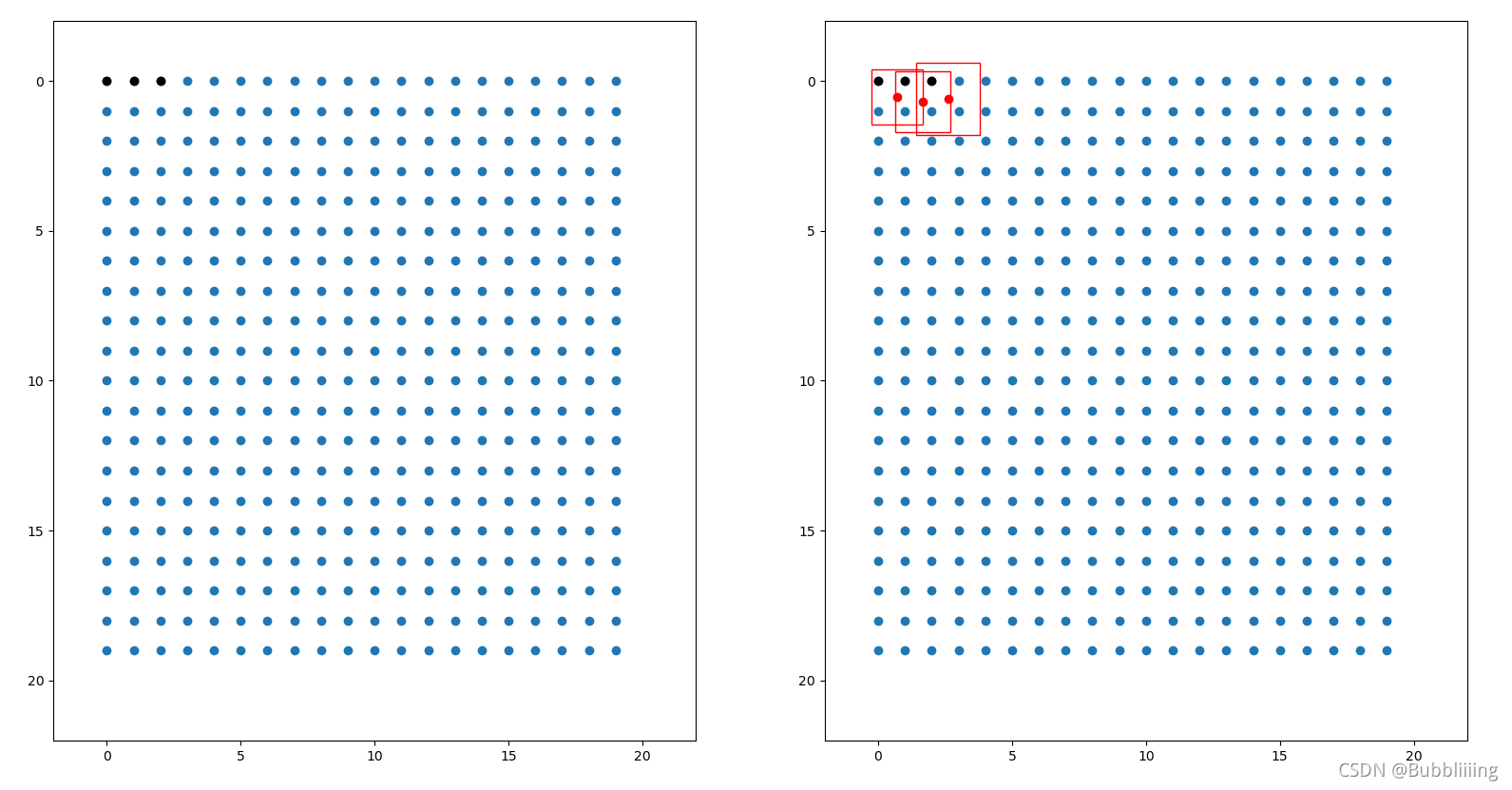
如图所示,蓝色的点为20x20的特征点,此时我们对左图红色的三个点进行解码操作演示:
1、进行中心预测点的计算,利用Regression预测结果前两个序号的内容对特征点坐标进行偏移,左图红色的三个特征点偏移后是右图绿色的三个点;
2、进行预测框宽高的计算,利用Regression预测结果后两个序号的内容求指数后获得预测框的宽高;
3、此时获得的预测框就可以绘制在图片上了。
除去这样的解码操作,还有非极大抑制的操作需要进行,防止同一种类的框的堆积。
2、得分筛选与非极大抑制
得到最终的预测结果后还要进行得分排序与非极大抑制筛选。
得分筛选就是筛选出得分满足confidence置信度的预测框。
非极大抑制就是筛选出一定区域内属于同一种类得分最大的框。
得分筛选与非极大抑制的过程可以概括如下:
1、找出该图片中得分大于门限函数的框。在进行重合框筛选前就进行得分的筛选可以大幅度减少框的数量。
2、对种类进行循环,非极大抑制的作用是筛选出一定区域内属于同一种类得分最大的框,对种类进行循环可以帮助我们对每一个类分别进行非极大抑制。
3、根据得分对该种类进行从大到小排序。
4、每次取出得分最大的框,计算其与其它所有预测框的重合程度,重合程度过大的则剔除。
得分筛选与非极大抑制后的结果就可以用于绘制预测框了。
四、训练部分
1、计算loss所需内容
计算loss实际上是网络的预测结果和网络的真实结果的对比。
和网络的预测结果一样,网络的损失也由三个部分组成,分别是Reg部分、Obj部分、Cls部分。Reg部分是特征点的回归参数判断、Obj部分是特征点是否包含物体判断、Cls部分是特征点包含的物体的种类。
2、正样本特征点的必要条件
在YoloX中,物体的真实框落在哪些特征点内就由该特征点来预测。
对于每一个真实框,我们会求取所有特征点与它的空间位置情况。作为正样本的特征点需要满足以下几个特点:
1、特征点落在物体的真实框内。
2、特征点距离物体中心尽量要在一定半径内。
特点1、2保证了属于正样本的特征点会落在物体真实框内部,特征点中心与物体真实框中心要相近。
上面两个条件仅用作正样本的而初步筛选,在YoloX中,我们使用了SimOTA方法进行动态的正样本数量分配。
3、SimOTA动态匹配正样本
在YoloX中,我们会计算一个Cost代价矩阵,代表每个真实框和每个特征点之间的代价关系,Cost代价矩阵由三个部分组成:
1、每个真实框和当前特征点预测框的重合程度;
2、每个真实框和当前特征点预测框的种类预测准确度;
3、每个真实框的中心是否落在了特征点的一定半径内。
每个真实框和当前特征点预测框的重合程度越高,代表这个特征点已经尝试去拟合该真实框了,因此它的Cost代价就会越小。
每个真实框和当前特征点预测框的种类预测准确度越高,也代表这个特征点已经尝试去拟合该真实框了,因此它的Cost代价就会越小。
每个真实框的中心如果落在了特征点的一定半径内,代表这个特征点应该去拟合该真实框,因此它的Cost代价就会越小。
Cost代价矩阵的目的是自适应的找到当前特征点应该去拟合的真实框,重合度越高越需要拟合,分类越准越需要拟合,在一定半径内越需要拟合。
在SimOTA中,不同目标设定不同的正样本数量(dynamick),以旷视科技官方回答中的蚂蚁和西瓜为例子,传统的正样本分配方案常常为同一场景下的西瓜和蚂蚁分配同样的正样本数,那要么蚂蚁有很多低质量的正样本,要么西瓜仅仅只有一两个正样本。对于哪个分配方式都是不合适的。
动态的正样本设置的关键在于如何确定k,SimOTA具体的做法是首先计算每个目标Cost最低的10特征点,然后把这十个特征点对应的预测框与真实框的IOU加起来求得最终的k。
因此,SimOTA的过程总结如下:
1、计算每个真实框和当前特征点预测框的重合程度。
2、计算将重合度最高的十个预测框与真实框的IOU加起来求得每个真实框的k,也就代表每个真实框有k个特征点与之对应。
3、计算每个真实框和当前特征点预测框的种类预测准确度。
4、判断真实框的中心是否落在了特征点的一定半径内。
5、计算Cost代价矩阵。
6、将Cost最低的k个点作为该真实框的正样本。
原文链接:https://blog.csdn.net/weixin_44791964/article/details/120476949

