
【Lucene】Lucene 学习之索引文件结构
Lucene 索引文件结构
基本概念
- 索引(index)
- Lucene的索引由许多个文件组成,这些文件放在同一个目录下
- 段(segment)
- 一个Lucene的索引由多个段组成,段与段之间是独立的。添加新的文档时可以生成新的段,达到阈值(段的个数,段中包含的文件数等)时,不同的段可以合并。
- 在文件夹下,具有相同前缀的文件属于同一个段
- segments.gen 和 segments_N(N表示一个具体数字,eg:segments_5)是段的元数据文件,他们保存了段的属性信息。
- 文档(document)
- 文档时建索引的基本单位,一个段中可以包含多篇文档
- 新添加的文档时单独保存在一个新生成的段中,随着段的合并,不同的文档会合并到至相同的段中。
- 域(Field)
- 一个文档有可由多个域(Field)组成,比如一篇新闻,有 标题,作者,正文等多个属性,这些属性可以看作是文档的域。
- 不同的域可以指定不同的索引方式,比如指定不同的分词方式,是否构建索引,是否存储等
- 词(Term)
- 词 是索引的最小单位,是经过词法分词和语言处理后的字符串
正向信息: 索引(index)—— 文档(document)—— 域(field)—— 词(term)
总体结构(图片来自网络)

Lucene的一个index文件存放在同一个文件夹下,由多个文件组成。
segments.gen : 用于帮助定位到最新的segments_N。
segments.gen文件格式: ,读取gen文件,然后判定Version是否正确,接着读取gen0和gen1,如果两个值相当,那么genB=gen0;
,读取gen文件,然后判定Version是否正确,接着读取gen0和gen1,如果两个值相当,那么genB=gen0;
此外,会选择index所在文件夹下的segments_N文件,选择最大的一个作为genA,然后比较genA和genB,找到最大的一个,最后才打开segments_N。
IndexInput genInput = directory.openInput(IndexFileNames.SEGMENTS_GEN);//"segments.gen" int version = genInput.readInt();//读出版本号 if (version == FORMAT_LOCKLESS) {//如果版本号正确 long gen0 = genInput.readLong();//读出第一个N long gen1 = genInput.readLong();//读出第二个N if (gen0 == gen1) {//如果两者相等则为genB genB = gen0; } } if (genA > genB) gen = genA; else gen = genB;
segments_N:段的元数据信息文件。保存了此索引包含多少个段,每个段包含多少篇文档等信息。
- Format:
- 索引文件格式的版本号。由于Lucene是在不断开发过程中的,不同版本的Lucene可能有不同索引文件格式,所以规定了文件格式的版本号。
- Version
- 索引的版本号
- NameCount
- 下一个新段的段名
- SegCount
- 段的个数
SegCount个段的元数据信息:
- segment:
- segName
- 段名
- SegSize
- 此段包含的文档数
- 包含已经删除,尚未optimize的文档。因为在optimize之前,Lucene的段中包含了所有被索引过的文档,而被删除的文档时保存在.del文件中的,在搜索过程中,是从段中读到了被删除的文档,然后再用.del的标志,将这篇文档过滤掉。
- optimize时,会触发段的合并,此时不会将已删除的文档合并至新段中。
- DelGen
- .del文件的版本号
- 在optimize之前,删除的文档是保存在.del文件中的。 文档删除的几种方式(可以通过IndexReader或者IndexWriter进行删除)
- IndexReader.deleteDocument(int docID) 根据文档号删除
- IndexReader.deleteDocuemnts(Term term) 删除包含此term的文档
- IndexWriter.deleteDocuemnts(Term term) 删除 包含此term的文档(使用的是InderWriter)
- IndexWriter.deleteDocuments(Term[] terms) 删除包含这些terms的文档
- IndexWriter.deleteDocuemnts(Query query) 删除满足次查询的文档
- IndexWriter.deleteDocuemnts(Query[] queries)删除满足这些查询的文档
- 原来的版本中Lucene的删除一直是由InderReader来完成的,虽然后来可以同IndexWriter来删除,其实真正还是由IndexReader来完成的。IndexWriter将IndexReader保存在readerpool中,删除的时候从中取出完成少出操作。
- DelGen 是每当IndexWriter向索引文件中提交删除操作的时候,加1,并生成新的.del文件
- segName
segment_N 与 segment 文件格式:
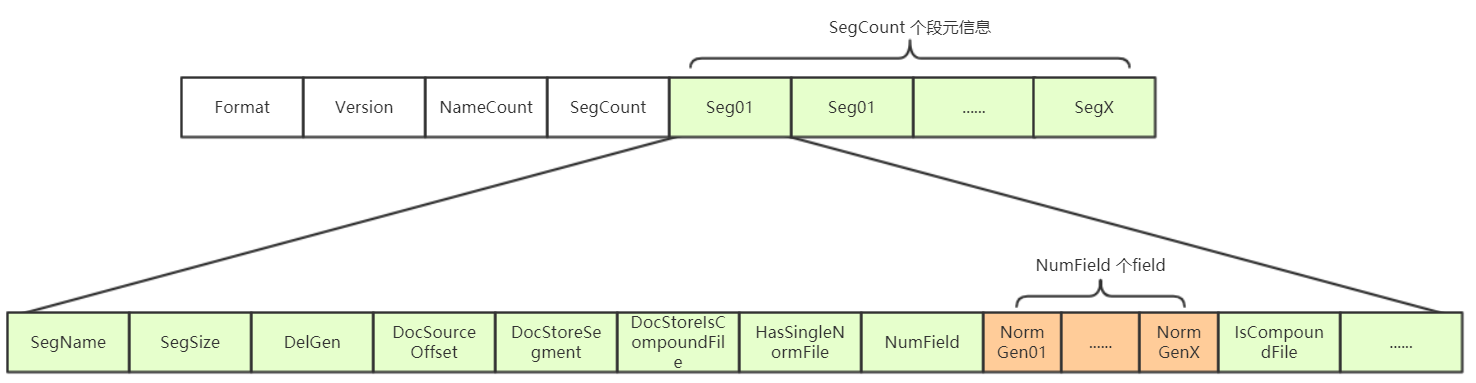
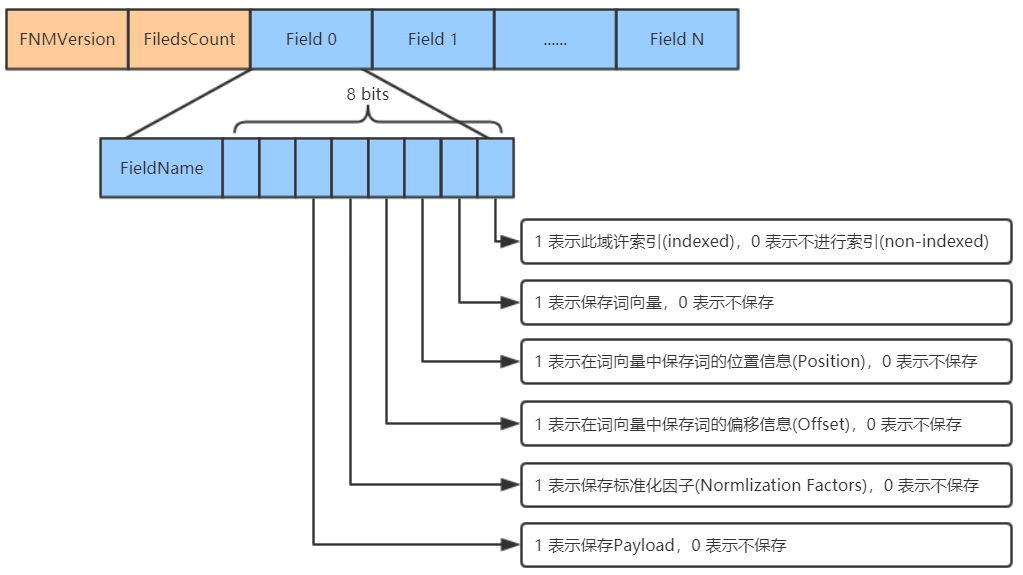
一个段(Segment)包含多个域,每个域都有一些元数据信息,保存在.fnm文件中,.fnm文件的格式如下:
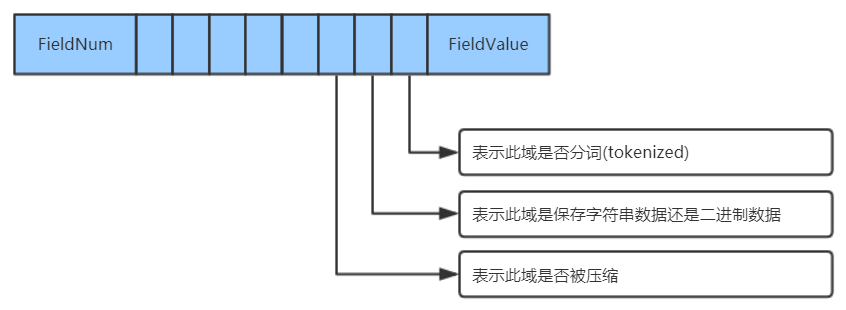
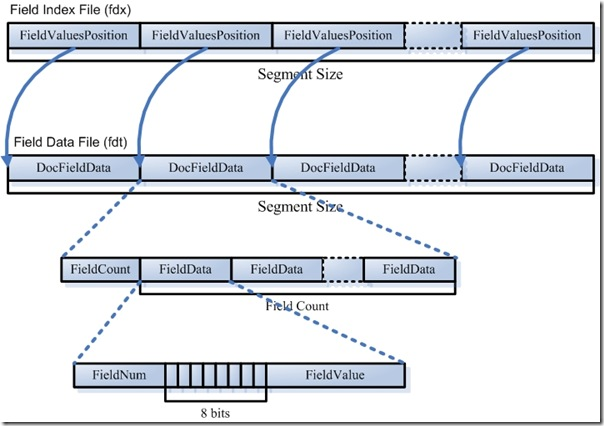
域 的数据信息存储在 .fdt 和 .fdx 文件中:
其中,.fdx 文件中存放FieldValuesPositon,指向.fdt文件,也就是说 域 的具体数据是存放在fdt文件中的。
- 域数据文件(fdt):
- 真正保存存储域(stored field)信息的是fdt文件
- 在一个段中总共有segment size 篇文档,所有fdt文档中共有segment size 个项,每一个项保存一篇文档的域信息。
- 每一篇文档对应一个FieldCount,表示此文档包含的域的数目,接着是fieldcount个项,每个项保存一个域的信息
- 对于每一个域,fieldnum是域号,接着是一个byte,8bit,根据填充的0/1,代表不同的意义,最低一位表示此域是否分词,倒数第二位表示此域保存的是字符串数据还是二进制数据,倒数第三位表示此域是否被压缩。最后存储的是这个存储域的值。
- 域索引文件(fdx):
- 由域数据文件格式可知,每篇文档包含的域的个数、每个存储域的值都是不一样的,因为域数据文件中的segment size篇文档,每篇文档占用的大小也是一样的,那么如何快速在fdt文件中辨别每一篇文档的起始地址和终止地址?如何能够更快的找到第n篇文档的存储域的信息呢?这就需要借组域索引文件
- 域索引文件也总共有segment size 个项,每篇文档都有一个项,每一项都是一个long,大小固定,每一项都是对应的文档在fdt中的起始地址偏移量。
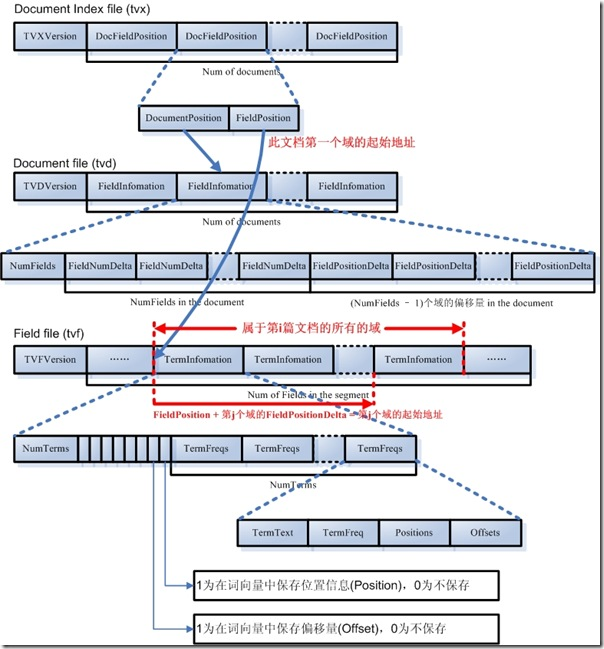
词向量(Term Vector)的数据信息(.tvx, .tvd, .tvf)
词向量 信息是从索引(index)到文档(document)到域(field)到词(term)的正向信息,有了词向量信息,就可以得到一篇文档包含哪些词的信息。
- 词向量索引文件(tvx):
- 一个段(segment)包含N篇文档,此文件就有N项,每一项代表一篇文档
- 每一项包含两部分信息:第一部分是词向量文档文件(tvd)中此文档的偏移量;第二部分是词向量文件(tvf)中此文档的第一个域的偏移量。
- 词向量文档文件(tvd):
- 每一项首先是此文档包含的域的个数NumFields,然后是一个NumFields大小的数组,数组每一项都是域号,然后是(NumField - 1)大小的数组,每一篇文档的第一个域在tvf文件中的偏移量信息存储在 tvx 文件中,而其他(NumFields - 1)个域在 tvf 中的偏移量就是第一个域的偏移量加上这(NumField - 1)个数组的每一项的值。
- 词向量域文件(tvf):
- 此文件包含了此段中的所有域,并不对文档做区分,到底第几个域到第几个域是属于那篇文件,是由tvx文件中的第一个域的偏移量以及tvd文件中的(NumField - 1)个域的偏移量来决定哪些域数据那个文档的。
- 对于每一个域,首先是此域包含的词的个数NumTerms,然后是8bit的byte,最后一位指定是否保存位置信息,倒数第二位表示是否保存偏移量信息。然后是NumTerms个项的数组,每一项代表一个词(Term),对于每一个词,由词的文本TermText,词频TermFreq(词在该文档中出现的次数),词的位置信息,词的偏移量信息。
参考:http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623599.html

