
JPA03 -- Spring Data JPA02
关于jpa总共写了三篇内容,下面附上链接:
JPA01:https://www.cnblogs.com/buwei/p/9979794.html
JPA02:https://www.cnblogs.com/buwei/p/9985287.html
JPA03:https://www.cnblogs.com/buwei/p/9985941.html
一、Specification动态查询
有时候我们在执行查询操作的时候,给定的条件时不固定的,这时候就需要动态的构建相应的查询语句。在Spring Data JPA中可以通过JpaSpecificationExecutor接口查询。相比于JPQL的优势是类型更加安全。
对于JpaSpecificationExecutor这个接口基本是围绕着Specification接口来定义的,我们可以简单的理解为,Specification接口构造的就是查询条件。
在Specification接口中之定义了一个方法:
1 public interface Specification<T> { 2 /** 3 * root:Root接口,代表查询的根对象,可以通过root获取实体中的属性 4 * query:代表一个顶层查询对象,用来自定义查询 5 * cb:用来构建查询,此对象里有很多条件方法 6 **/ 7 Predicate toPredicate(Root<T> var1, CriteriaQuery<?> var2, CriteriaBuilder var3); 8 }
1.1 使用Specifications完成条件查询与分页查询 -- 接JPA02的前提下扩展
1 public class SpecificationTest { 2 @Autowired 3 private CustomerDao customerDao; 4 5 /** 6 * 使用Specification的条件查询 7 */ 8 public void testSpecifications(){ 9 // 使用匿名内部类的方式,创建一个Specification的实现类,并实现toPredicate方法 10 Specification<Customer> spec = new Specification<Customer>(){ 11 @Override 12 public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) { 13 // criteriaBuilder:构建查询,添加查询方式,like:模糊匹配 14 // root:从实体Customer对象中按照CustName属性进行查询 15 return criteriaBuilder.like(root.get("custName").as(String.class),"不为"); 16 } 17 }; 18 Customer customer = customerDao.findOne(spec); 19 System.out.println(customer); 20 } 21 22 /** 23 * 基于Specification的分页查询 24 */ 25 public void testPage(){ 26 // 构造查询条件 27 Specification<Customer> spec = new Specification<Customer>() { 28 @Override 29 public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) { 30 return criteriaBuilder.like(root.get("custName").as(String.class),"不为%"); 31 } 32 }; 33 34 /** 35 * 构造分页参数 36 * Pageable:接口 37 * PageRequest实现了Pageable接口,调用构造方法的形式构造 38 * 参数1:页码(从0开始) 39 * 参数2:每页查询条数 40 */ 41 Pageable pageable = new PageRequest(0, 10); 42 43 /** 44 * 执行分页查询,其内部自动实现封装 45 */ 46 Page<Customer> page = customerDao.findAll(spec, pageable); 47 //获取总页数 48 int totalPages = page.getTotalPages(); 49 //获取总记录数 50 long totalElements = page.getTotalElements(); 51 //获取列表数据 52 List<Customer> content = page.getContent(); 53 } 54 }
二、多表设计
2.1 表与表之间关系的划分
数据库中多表之间的三种关系:
- 一对一(几乎不用)
- 一对多(分为一对多和多对一)
- 多对多
2.2 在JPA框架中关于多表关系分析步骤
1.首先确定两张之间的关系
2.在数据库中实现两张表的关系
3.在实体类中描述两个实体的关系
4.配置实体类和数据库表的关系映射
三、JPA中的一对多
3.1 案例:公司与公司员工两张表之间关系 -- 一对多
3.2 表关系建立
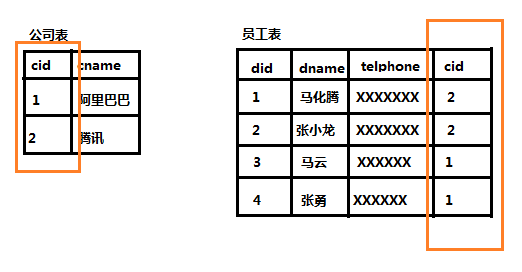
在一对多关系中,我们习惯把一的一方称为主表,把多的一方称之为从表,在数据库中建立一对多的关系,需要使用数据库的外键约束。
外键:指的是从表中有一列,取值参照主表的主键,这一列就是外键。
一对多数据库关系的建立,如下图所示:
3.3 一对多案例
1.创建maven工程
pom.xml中坐标以及Spring Data Jpa配置文件同JPA02,这里不再重复。
2.实体类关系建立以及映射配置
Company类:
1 @Entity 2 @Table(name = "tb_company") 3 public class Company implements Serializable { 4 5 @Id // 表名当前私有属性是主键 6 @GeneratedValue(strategy = GenerationType.IDENTITY) // 指定主键的生成策略 7 @Column(name = "tb_cid") // 指定和数据库表中的tb_cid对应 8 private Long cid; 9 10 @Column(name = "tb_cname") // 指定和数据库表中的tb_cid对应 11 private String cname; 12 13 // 配置公司和员工的一对多关系 14 @OneToMany(targetEntity = Employee.class) 15 @JoinColumn(name = "ep_tb_cid", referencedColumnName = "tb_cid") 16 // @OneToMany(mappedBy = "company") 17 private Set<Employee> employees = new HashSet<Employee>(); 18 19 public Long getCid() { 20 return cid; 21 } 22 23 public void setCid(Long cid) { 24 this.cid = cid; 25 } 26 27 public String getCname() { 28 return cname; 29 } 30 31 public void setCname(String cname) { 32 this.cname = cname; 33 } 34 35 public Set<Employee> getEmployees() { 36 return employees; 37 } 38 39 public void setEmployees(Set<Employee> employees) { 40 this.employees = employees; 41 } 42 43 @Override 44 public String toString() { 45 return "Company{" + 46 "cid=" + cid + 47 ", cname='" + cname + '\'' + 48 ", employees=" + employees + 49 '}'; 50 } 51 }
Employee类:
1 @Entity 2 @Table(name = "tb_employee") 3 public class Employee implements Serializable { 4 5 @Id 6 @GeneratedValue(strategy = GenerationType.IDENTITY) // 指定主键的生成策略 7 @Column(name = "tb_eid") 8 private Long eid; 9 10 @Column(name = "tb_ename") 11 private String ename; 12 13 @Column(name = "tb_ephone") 14 private String ephone; 15 16 // 多对一关系映射,多个员工对应一个公司 17 @ManyToOne(targetEntity = Company.class) 18 @JoinColumn(name = "ep_tb_cid",referencedColumnName = "tb_cid") 19 private Company company;// 用它的主键,对应员工表中的外键 20 21 public Long getEid() { 22 return eid; 23 } 24 25 public void setEid(Long eid) { 26 this.eid = eid; 27 } 28 29 public String getEname() { 30 return ename; 31 } 32 33 public void setEname(String ename) { 34 this.ename = ename; 35 } 36 37 public String getEphone() { 38 return ephone; 39 } 40 41 public void setEphone(String ephone) { 42 this.ephone = ephone; 43 } 44 45 public Company getCompany() { 46 return company; 47 } 48 49 public void setCompany(Company company) { 50 this.company = company; 51 } 52 53 @Override 54 public String toString() { 55 return "Employee{" + 56 "eid=" + eid + 57 ", ename='" + ename + '\'' + 58 ", ephone='" + ephone + '\'' + 59 ", company=" + company + 60 '}'; 61 } 62 }
3.CompanyMapper与EmployMapper接口
CompanyMapper:
1 public interface CompanyMapper extends 2 JpaRepository<Company, Long>,JpaSpecificationExecutor<Company> { 3 }
EmployeeMapper:
1 public interface EmployeeMapper extends 2 JpaRepository<Employee, Long>,JpaSpecificationExecutor<Employee> { 3 }
4.测试类
1 @RunWith(SpringJUnit4ClassRunner.class) 2 @ContextConfiguration(locations = "classpath:applicationContext.xml") 3 public class OneToManyTest { 4 5 @Autowired 6 private CompanyMapper companyMapper; 7 8 @Autowired 9 private EmployeeMapper employeeMapper; 10 11 @Test 12 @Transactional // 开启事务 13 @Rollback(false)// 设置为不回滚 14 public void testAdd() { 15 Company Alibaba = new Company(); 16 Alibaba.setCname("阿里巴巴"); 17 18 Employee employee1 = new Employee(); 19 employee1.setEname("马云"); 20 employee1.setEphone("18888888888"); 21 22 Employee employee2 = new Employee(); 23 employee2.setEname("张勇"); 24 employee2.setEphone("16666666666"); 25 26 Alibaba.getEmployees().add(employee1); 27 Alibaba.getEmployees().add(employee2); 28 employee1.setCompany(Alibaba); 29 employee2.setCompany(Alibaba); 30 31 companyMapper.save(Alibaba); 32 employeeMapper.save(employee1); 33 employeeMapper.save(employee2); 34 } 35 }
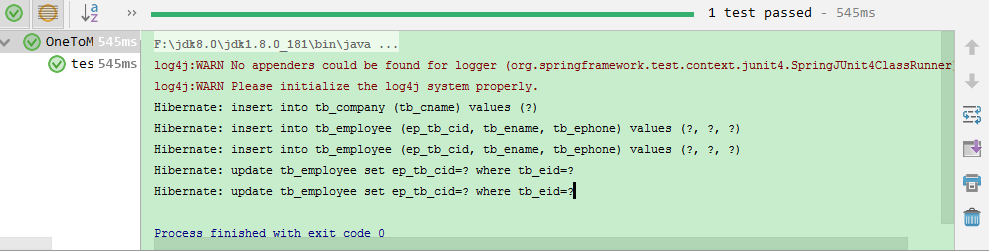
执行测试方法发现控制台打印sql语句如下:
数据库中生成表信息如下:
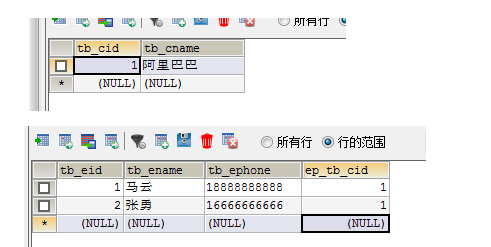
我们发现,在设置了双向关系之后,会发送三条insert语句,两条多余的update语句,解决思路就是在一的一方放弃一的维护权。
1 // 配置公司和员工的一对多关系 2 @OneToMany(mappedBy = "company") // mapperdBy后面的是从表中引用的主表的类的属性名 3 private Set<Employee> employees = new HashSet<Employee>();
5.删除
1 @Autowired 2 private CompanyMappercompanyMapper; 3 4 @Test 5 @Transactional 6 @Rollback(false)//设置为不回滚 7 public void testDelete() { 8 companyMapper.delete(1L); 9 }
上面的测试方法中写的是添加方法,这里讲删除方法。
删除操作的说明如下:
-
- 删除从表数据:可以随时任意删除
- 删除主表数据:
- 有从表数据
- 默认情况下,他会将外键字段设置为null,然后删除主表数据。如果在数据库的表结构上,外键字段有非空约束,默认情况就会报错。
- 如果配置了放弃维护关联关系的权利,则不能删除(与外键字段是否允许为null没有关系),因为删除时,他跟不用去更新从表的外键字段了。
- 如果还想删除,使用级联删除引用
- 没有从表数据引用:随便删
- 有从表数据
在实际开发过程中,级联删除慎用!(在一对多的情况下)
6.级联删除
级联删除:指操作一个对象同时操作它的关联对象
使用方法:只需要在操作主体的注解上配置cascade
1 /** 2 * cascade:配置级联操作 3 * CascadeType.MERGE 级联更新 4 * CascadeType.PERSIST 级联保存: 5 * CascadeType.REFRESH 级联刷新: 6 * CascadeType.REMOVE 级联删除: 7 * CascadeType.ALL 包含所有 8 */ 9 @OneToMany(mappedBy = "company", cascade = CascadeType.ALL)
四、JPA中的多对多
4.1 示例分析
我们采用的实例为用户和角色。
用户:假设为某个班上的学生,老师
角色:假设为学生对应的身份信息和老师对应的身份信息
例如:学生A在学校身份是学生,在家就是子女。老师B在学校的身份是老师,在家也是子女
所以我们说,用户和角色之间的关系是多对多
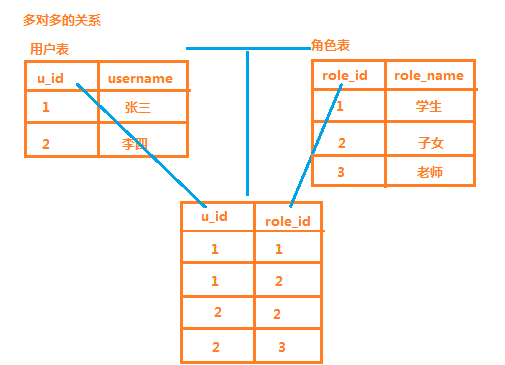
4.2 表关系建立
多对多的表关系依靠的值中间表,其中用户表和中间表是一对多,角色表和中间表的关系也是一对多,如下图所示:
4.3 一对多案例
1.创建maven工程
pom.xml中坐标以及Spring Data Jpa配置文件同JPA02,这里不再重复。
2.实体类关系建立以及映射配置
User类:
1 @Entity 2 @Table(name = "tb_user") 3 public class User implements Serializable { 4 5 @Id 6 @GeneratedValue(strategy= GenerationType.IDENTITY) 7 @Column(name="user_id") 8 private Long userId; 9 10 @Column(name="user_name") 11 private String userName; 12 13 // 多对多关系映射 -- mappedBy后面对应的是在对应的类中对应的属性名 14 @ManyToMany(mappedBy="users") 15 private Set<Role> roles = new HashSet<Role>(0); 16 17 // 省略getter和setter方法 18 }
Role类:
1 public class Role implements Serializable { 2 @Id 3 @GeneratedValue(strategy= GenerationType.IDENTITY) 4 @Column(name="role_id") 5 private Long roleId; 6 7 @Column(name="role_name") 8 private String roleName; 9 10 //多对多关系映射 11 @ManyToMany 12 @JoinTable(name="user_role",// 中间表的名称 13 // 中间表user_role字段关联tb_role表的主键字段role_id 14 joinColumns={@JoinColumn(name="role_id",referencedColumnName="role_id")}, 15 // 中间表user_role的字段关联tb_user表的主键user_id 16 inverseJoinColumns={@JoinColumn(name="user_id",referencedColumnName="user_id")} 17 ) 18 private Set<User> users = new HashSet<User>(0); 19 20 // 省略getter和setter方法 21 }
省略两个接口UserMapper和RoleMapper
3.映射注解的说明
@ManyToMany
作用:用于映射多对多的关系
属性:
cascade:配置级联操作
fetch:配置是否采用延迟操作
targetEntity:配置目标的实体类,映射对多对的时候不用写
@JoinTable
作用:针对中间表的配置
属性:
name:配置中间表的名称
joinClomns:中间表的外键字段关联当前实体类多对应表的主键字段
inverseJoinColumn:中间表的外键字段关联对方表的主键字段
@JoinColumn
作用:用于定义主键字段和外键字段的对应关系
属性:
name:指定外键字段的名称
referenceColumnName:指定应用主表的主键字段名称
unique:是否唯一、默认不唯一
nullable:是否允许为空。默认值允许。
insertable:是否允许插入。默认值允许。
updatable:是否允许更新。默认值允许。
columnDefinition:列的定义信息。
4.多对多的操作
1 @RunWith(SpringJUnit4ClassRunner.class) 2 @ContextConfiguration(locations = "classpath:applicationContext.xml") 3 public class ManyToManyTest { 4 5 @Autowired 6 private UserMapper userMapper; 7 8 @Autowired 9 private RoleMapper roleMapper; 10 11 /** 12 * 需求: 13 * 保存用户和角色 14 * 要求:创建2个用户和三个角色 15 * 让1号用户具有1号和2号角色 16 * 让2号用户具有1号、2号和三号角色 17 * 保存用户和角色 18 * 问题: 19 * 在保存时,会出现主键重复的错误,因为都是要往中间表中存放数据造成的 20 * 解决方案: 21 * 让任意一方放弃维护关联关系的权利 22 */ 23 24 @Test 25 @Transactional // 开启事务 26 @Rollback(false) // 设置不自动回滚 27 public void testAdd(){ 28 // 创建对象 29 User u1 = new User(); 30 u1.setUserName("小明"); 31 User u2 = new User(); 32 u2.setUserName("小红"); 33 34 // 创建角色 35 Role r1 = new Role(); 36 r1.setRoleName("学生"); 37 Role r2 = new Role(); 38 r2.setRoleName("子女"); 39 Role r3 = new Role(); 40 r3.setRoleName("老师"); 41 42 // 建立联系 43 u1.getRoles().add(r1); 44 u1.getRoles().add(r2); 45 u2.getRoles().add(r2); 46 u2.getRoles().add(r3); 47 48 r1.getUsers().add(u1); 49 r2.getUsers().add(u1); 50 r2.getUsers().add(u2); 51 r3.getUsers().add(u2); 52 53 // 保存 54 userMapper.save(u1); 55 userMapper.save(u2); 56 roleMapper.save(r1); 57 roleMapper.save(r2); 58 roleMapper.save(r3); 59 } 60 }
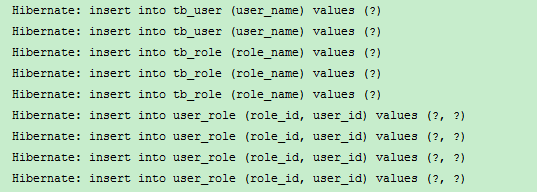
运行testAdd方法,控制台打印如下:
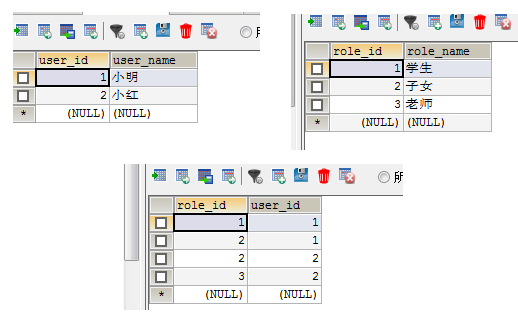
数据库中生成表信息如下:
5.删除
1 @Test 2 @Transactional 3 @Rollback(false) 4 public void testDelete(){ 5 roleMapper.delete(1L); 6 }
这是需要注意的是删除操作只能在拥有维护权的一方才能执行删除成功,所以我们在设计对应关系的时候需要考虑好。
控制台打印如下:
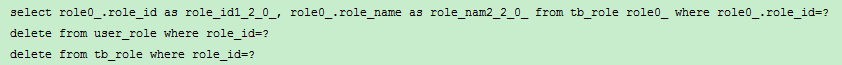
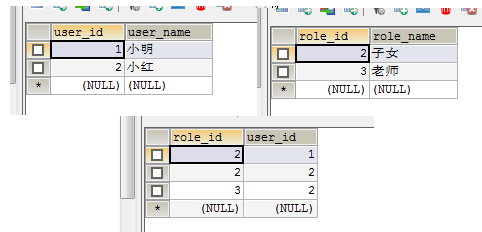
表中对应数据也已经删除:
五、Spring Data JPA中的多表查询
5.1 对象导航查询
对象导航检索方式是根据已经加载的对象,导航到他的关联对象。利用类与类之间的管理来检索对象。例如我们通过id查询出一个公司,可以调用Company类中的getEmployees()方法,来获取该公司的所有员工。对象导航查询的使用要求是,两个对象之间必须存在关联关系。
1 @Test 2 @Transactional // 由于是测试方法,为了解决no session问题,将操作配置到同一个事务中 3 public void testFind(){ 4 Company company = companyMapper.findOne(1L); 5 Set<Employee> employees = company.getEmployees(); 6 for (Employee employee : employees) { 7 System.out.println(employee); 8 } 9 } 10 11 @Test 12 @Transactional // 由于是测试方法,为了解决no session问题,将操作配置到同一个事务中 13 public void testFind1(){ 14 Employee employee = employeeMapper.findOne(1L); 15 Company company1 = employee.getCompany(); 16 System.out.println(company1); 17 }
省事情我就两个测试方法一起写了,第一次运行报错java.lang.StackOverflowError
参照https://blog.csdn.net/m0_37893932/article/details/70036587上的解决方法,发现原因是自己写了两个类的toString()方法
稍作修改,对Company中的toString()方法稍作修改,删除掉队Employees的打印,而Employee中的company的打印删不删都可以!!!


对象导航查询的问题分析:
1.在我们查询公司时,对于员工的查询?
采用延迟加载的思想,通过配置的方式来设定当我们在需要使用时,发起真正的查询
配置方式:
1 /** 2 * 在公司对象的@OneToMany注解中添加fetch属性 3 * FetchType.EAGER:立即加载 4 * FetchType.LAZY:延迟加载 5 */ 6 @OneToMany(mappedBy = "company",fetch=FetchType.LAZY) 7 private Set<Employee> employees = new HashSet<Employee>();
2.当我们查询员工时,对于公司的查询?
采用立即加载的思想,通过配置的方式来设定,只要查询从表实体,就把主表实体对象同时查出来。
1 // 多对一关系映射,多个员工对应一个公司 2 @ManyToOne(targetEntity = Company.class,fetch=FetchType.EAGER) 3 @JoinColumn(name = "tb_cid",referencedColumnName = "tb_cid") 4 private Company company;// 用它的主键,对应员工表中的外键
5.2 使用Specification查询
下次补充。。。。。。。。。。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号