
搜索解决方案 -- ElasticSearch入门
一、基本简介——来自百度百科
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
ElasticSearch是一个基于Lucene的高扩展的分布式搜索服务器,支持开箱即用。
ElasticSearch隐藏了Lucene的复杂性,对外提供Restful接口来操作索引、搜索。
优点:
1、扩展性好,可部署上百台服务器集群,可以处理PB级数据;
2、近实时的去索引数、搜索数据。
es和solr的选择问题?
如果是一个新的全文检索项目的开发,建议优先考虑ElasticSearch。
二、原理与应用
2.1 索引结构
下图是ElasticSearch的索引结构,上面部分是逻辑结构,下边部分是物理结构,逻辑结构是为了更好的去描述ElasticSearch的工作原理及去使用物理结构中的索引文件。

逻辑结构部分是一个倒排索引表
- 将要搜索的文档内容分词,所有不重复的词组成分词列表;
- 分词的结果会根据分词器使用的不同而有所不同——常用中文分词器:IK分词器
- 将搜索的文档最终以Document方式存储起来;
- 每个词和document都有关联。
- 如下:

- 现在如果我们想搜索quick brown,我们只需要查找包含每个词条的文档:

- 两个文档都匹配,但是第一个文档比第二个匹配度更高,如果我们使用仅计算匹配词条数量的简单性算法,那么对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
- 关于倒排索引
- 我们传统的搜索是通过文档去里面找词,称为正排索引
- 现在的搜索是通过词来搜索对应的文章
- 我们传统的搜索是通过文档去里面找词,称为正排索引
2.2 Restful引用方法
Elasticsearch提供 RESTful Api接口进行索引、搜索,并且支持多种客户端。
在项目中我们一般的应用方式:
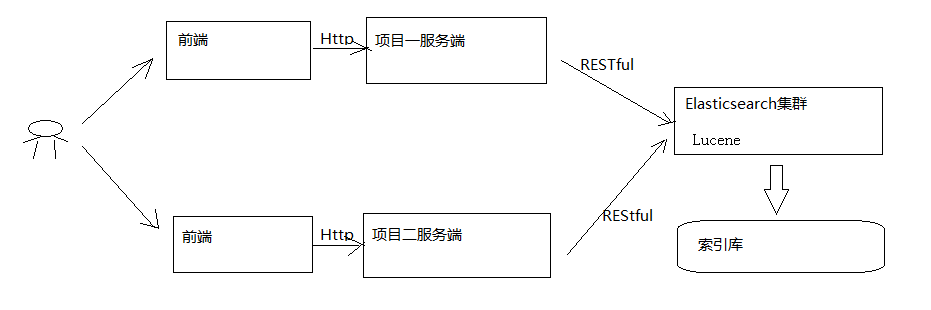
前端是可以直接通过访问ElasticSearch进行访问的,创建服务工程主要是为了对搜索进行一些个性化设置以及一些安全设置。
- 用户在前端搜索关键字
- 项目前端通过http方式请求项目服务端
- 项目服务端通过Http Restful方式请求ES集群进行搜索
- ES集群从索引库检索数据
三、ElasticSearch安装
ElasticSearch支持多种安装方式,在Windows下建议使用ZIP方式安装,需注意与JDK的版本对应。
本次案例使用ElasticSearch-6.2.1.zip,需要jdk1.8及以上,解压即可使用,目录结构如下:

3.1 配置文件
ES中主要的有三个配置文件,配置文件的位置在config目录下:

elasticsearch.yml:要注意语法:(空格)name:(空格)value,编码使用UTF-8
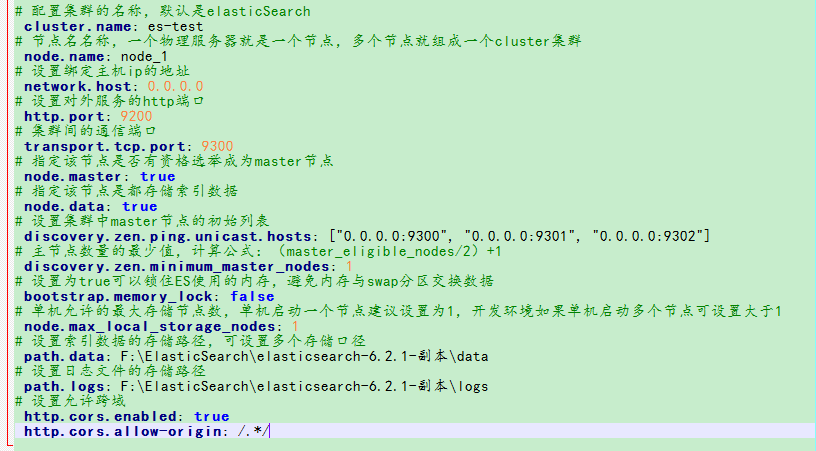
jvm.options:设置最小及最大的JVM堆内存大小,主要设置两个参数-Xms和Xmx,注意如下:
- 两个值设置为相等
- 将X梦想设置为不超过物理内存的一半
log4j2.properties:日志文件设置,ES使用log4j,注意日志级别的配置
3.2 启动ES
进入bin目录,在cmd下运行:elasticsearch.bat,shift+鼠标右键——》在此处打开命令窗口
注:如果启动失败,注意检查elasticsearch.yml中的语法问题
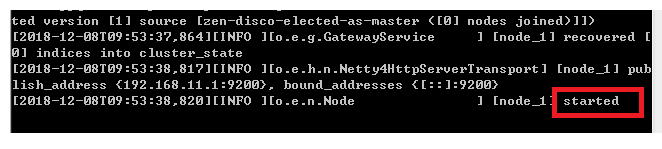
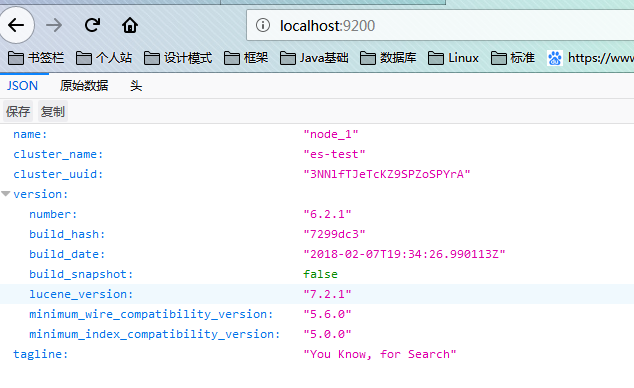
浏览器输入:http://localhost:9200,显示结果如下说明ES启动成功,Firefox对json数据显示友好
3.3 head插件安装
head插件是ES的一个可视化管理插件,用来监视ES的状态,并通过head客户端与ES服务进行交互,比如创建映射,创建索引等,head的项目地址在https://github.com/mobz/elasticsearch-head
从ES6.0开始,head插件支持使得node.js运行,所以安装head插件先安装node.js
- 安装node.js
- 安装head插件
- git clone git://github.com/mobz/elasticsearch-head.git
- cd elasticsearch-head
- npm install
- npm run start
命令需要在heade插件的目录运行,看到如下则表示运行成功
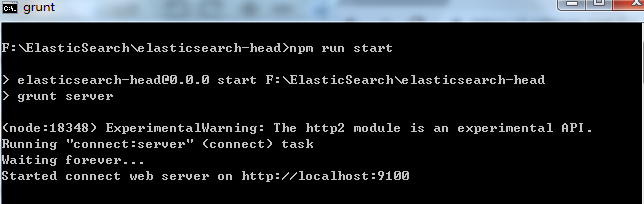
浏览器访问:http://localhost:9100,如下图表示成功连上es

四、ES快速入门
ES作为一个索引及搜搜服务,对外提供丰富的REST接口,下面的快速入门使用head插件来测试,进行一个简单的了解。
4.1 创建索引库
ES的索引库是一个逻辑概念,它包括了分词列表以及文档列表,同一个额索引库中存储了相同类型的文档,他就相当于MySQL中的表或者Mongodb中的集合。
索引:
索引(名词):ES是一个基于Lucene构建的一个搜索服务,他要从索引库搜索服务条件索引数据。
索引(动词):索引库港建起来的时候是空的,需要将数据添加到索引库的过程称为索引。
下面介绍两种创建索引库的方法,它们的公子哥原来都是一样的,通过客户端向ES服务发哦送命令。
- 使用postman或者curl这样的工具创建,put:http://localhost:9200/索引库名称:
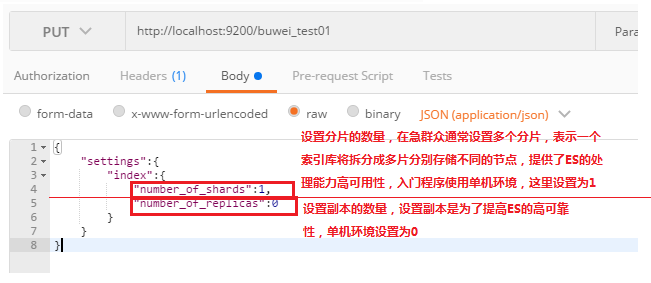

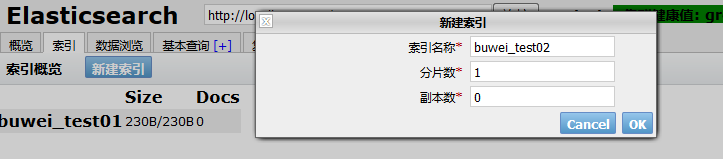
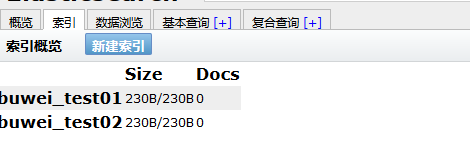
如上创建一个buwei-test01索引库,一个分片,0个副本刷新head的界面:
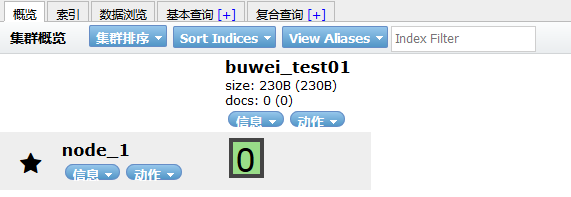
- 使用head插件创建,在索引菜单下,新建索引,填写基本信息,确认:
4.2 创建映射
1.概念
在索引库中每个文档都包含一个或多个field,创建映射就是想索引库中创建Field的过程,下面是document和Field与关系数据库的类比:
文档(document)---------------------------row记录
字段(Field)----------------------------------columns列
关于索引库的域关系型数据库的类比
- 如果类比于数据库的话就表示一个索引库可以创建很多不同类型个的文档,在ES中允许这样
- 如果类比于表就表示一个索引库只能存储相同类型的文档,ES官方建议在一个索引库中之存储相同类型的文档。
2.创建映射
我们要把被检索的信息存储到ES中,需要创建信息的映射,先做一个简单的映射,如下:
发送:post:http:localhost:9200/索引库名称/类型名称/_mapping
创建索引库buwei_test01的映射,包括三个字段:name、description、studymondel
由于ES6.0版本还没有将type彻底删除,这里将type设置为一个没有意义的名字
post请求:http://localhost:9200/buwei_test01/doc/_mapping
1 { 2 "properties":{ 3 "name":{ 4 "type":"text" 5 }, 6 "description":{ 7 "type":"text" 8 }, 9 "studymodel":{ 10 "type":"keyword" 11 } 12 } 13 }
映射创建成功,查看head界面:
3.创建文档
ES中的文档相当于MySQL数据库表中的记录
发送:put或post:http://localhost:9200/buwei_test01/doc/id值(如果不指定idES会自动生成id)
http://localhost:9200/buwei_test01/doc/001
1 { 2 "name":"测试文档", 3 "description":"这是一个测试的文档", 4 "studymodel":"201801" 5 }
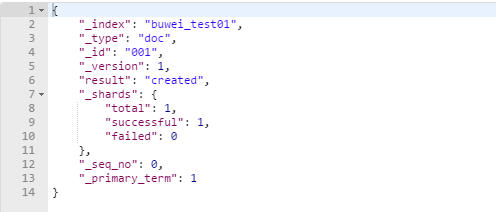
通过head查询数据

4.搜索文档
- 根据课程id查询文档
- 发送get:http://localhost:9200/buwei_test01/001
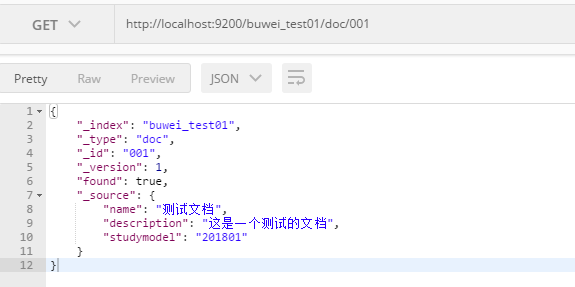
- 查询所有记录:发送get:http://localhost:9200/buwei_test01/_search
- 查询名称中包括文的关键字:发送get:http://localhost:9200/buwei_test01/_search?q:name:测试文档
5.搜索结果分析

五、IK分词器
5.1 测试分词器
在添加文档时会进行分词,索引中存放的就是一个一个的词(term),当你去搜索时就是拿关键字去匹配词,最终找到词关联的文档。
测试当前索引库使用的分词器:post:http://localhost:9200/_analyze
1 { 2 "text":"测试文档" 3 }
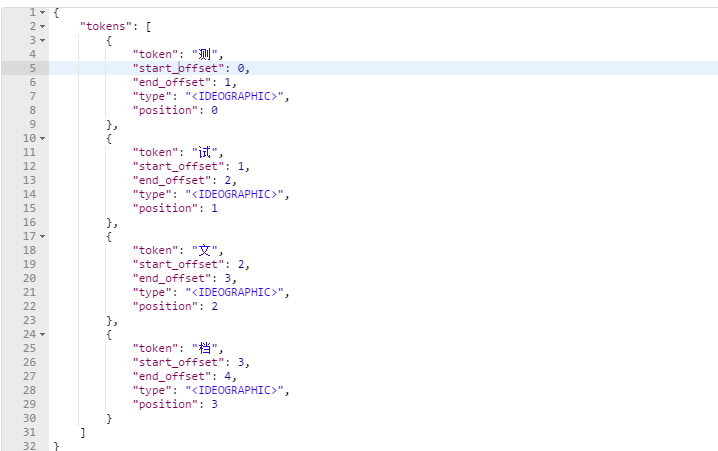
发现分词的效果是将"测试文档"这个词拆分成四个字,这是因为当前索引库使用的分词器是对中文单字分词。
5.2 安装IK分词器
使用IK分词器可以实现岁中文分词的效果
下载IK分词器:https://github.com/medcl/elasticsearch-analysis-ik,要找到对应版本
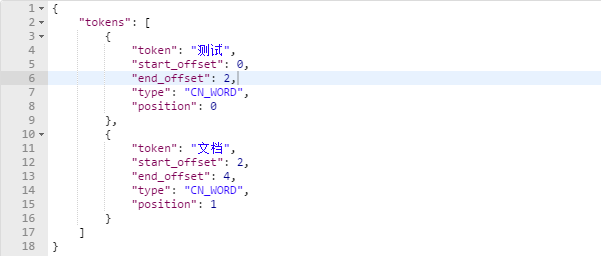
将下载后的文件解压后拷贝到ES安装目录的plugins下,,修改目录名为ik,重启elasticsearch。bat,再次请求数据
1 { 2 "text":"测试文档", 3 "analyzer":"ik_max_word" 4 }
5.3 两种分词模式
ik分词器由两种分词模式:ik_max_word和ik_samrt模式
- ik_max_word:会将文本做最细力度的拆分,比如会将"中华人民共和国"拆分如下:

- ik_smart:会做最粗粒度的拆分,同样是"中华人名共和国",拆分情况如下:

5.4 自定义词库
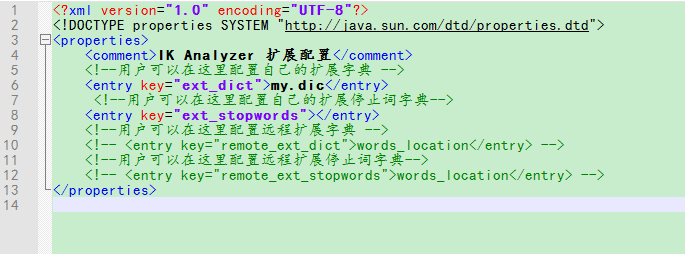
如果要让分词器支持一些专有词语,可以自定义词库。
在ik分词器的config目录下自带一个main.dic的文件,就是词库文件,可以在同级目录中创建一个my.dic文件(需为UTF-8格式)。在ik分词器的配置文件IKAnalyzer.cfg.xml中配置my.dic。
六、映射
在上面,我们安装了ik分词器,这时候我们就需要设置在索引和搜索时使用ik分词器,同时制定其他类型的Field,比如日期类型,数值类型等。
6.1 映射的维护方法
- 查询所有索引的映射:get:http://localhost:9200/_mapping
- 创建映射:post:http:localhost:9200/buwei_test01/doc/_mapping——前面的案例中有讲解
- 更新映射:映射创建成功可以添加新字段,不允许更新已有字段
- 删除映射:通过删除索引来删除映射
6.2 常见映射类型
- text文本字段
- type:定义属性
- analyzer:定义分词模式(ik_max_word/ik_smart)
- search_analyzer:定义搜索是的分词模式(ik_max_word/ik_smart)
- index:定义是否索引(true/false),只有进行索引的词才可以从索引库中搜索到,但是有些内容不需要被索引,比如图片地址等
- store:是否在source之外存储,每个文档索引后会在ES中保存一份原始文档,存放在"_source"中,一般情况下设置为true,因为在"_source"中已经有一份原始文档了
- keyword关键字字段
- 上边介绍的text文本字段在映射时需要设置分词器,keyword字段为关键字字段,通常搜索keyword字段是按照整体搜索的,索引创建keyword字段的索引是不需要进行分词的,比如手机号码、邮政编码等,keyword字段通常用于过滤、排序、聚合等。
- date日期类型
- 日期类型不用设置分词器,通常日期类型的字段用于排序
- format:设置日期的格式
- "format": "yyyy‐MM‐dd HH:mm:ss||yyyy‐MM‐dd"
- 数值类型:long、integer、short、byte、double、float、half_float、scaled_float
- 需尽量选择范围小的类型,提高搜索效率
七、索引管理
7.1 ES客户端
ES提供多种不同的客户端:
1、TransportClient
ES提供的传统客户端,官方计划8.0版本删除此客户端
2、RestClient
RestClient是官方推荐使用的,它包括两种:Java Low Level Rest Client和Java High Level Rest Client,不过当前前它还处于完善中,有些功能还没有。
使用的时候引入相关的依赖即可。
1 <dependency> 2 <groupId>org.elasticsearch.client</groupId> 3 <artifactId>elasticsearch-rest-high-level-client</artifactId> 4 <version>6.2.1</version> 5 </dependency> 6 <dependency> 7 <groupId>org.elasticsearch</groupId> 8 <artifactId>elasticsearch</artifactId> 9 <version>6.2.1</version> 10 </dependency>
在Java中就是通过执行RestClient的相关api执行对elasticsearch的操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号