
史上最全!押题率90%的 Android 中高级工程师面试复习大纲及真题答案整理(下篇)
缘起
转眼间2020就接近尾声了,年后有跳槽想法的小伙伴们心里应该也有自己的决定了。金三银四青铜五,总不能到跳槽的黄金期再开始复习吧。没办法,都是兄弟,宠着!2020年度Android中高级面试复习大全奉上。
篇幅过长,预计分三篇文章讲解,好兄弟们记得点个关注或者点赞Mark插个眼,后续不容错过哦
上一篇Java基础,计算机网络相关面试题点这里:
史上最全!押题率90%的 Android 中高级工程师面试复习大纲及真题答案整理(上篇)
上一篇Android基础夯实99题,点这里
史上最全!押题率90%的 Android 中高级工程师面试复习大纲及真题答案整理(中篇)
3、Android优秀三方库源码
1、你项目中用到哪些开源库?说说其实现原理?
一、网络底层框架:OkHttp实现原理
这个库是做什么用的?
网络底层库,它是基于http协议封装的一套请求客户端,虽然它也可以开线程,但根本上它更偏向真正的请求,跟HttpClient, HttpUrlConnection的职责是一样的。其中封装了网络请求get、post等底层操作的实现。
为什么要在项目中使用这个库?
- OkHttp 提供了对最新的 HTTP 协议版本 HTTP/2 和 SPDY 的支持,这使得对同一个主机发出的所有请求都可以共享相同的套接字连接。
- 如果 HTTP/2 和 SPDY 不可用,OkHttp 会使用连接池来复用连接以提高效率。
- OkHttp 提供了对 GZIP 的默认支持来降低传输内容的大小。
- OkHttp 也提供了对 HTTP 响应的缓存机制,可以避免不必要的网络请求。
- 当网络出现问题时,OkHttp 会自动重试一个主机的多个 IP 地址。
这个库都有哪些用法?对应什么样的使用场景?
get、post请求、上传文件、上传表单等等。
这个库的优缺点是什么,跟同类型库的比较?
- 优点:在上面
- 缺点:使用的时候仍然需要自己再做一层封装。
这个库的核心实现原理是什么?如果让你实现这个库的某些核心功能,你会考虑怎么去实现?
OkHttp内部的请求流程:使用OkHttp会在请求的时候初始化一个Call的实例,然后执行它的execute()方法或enqueue()方法,内部最后都会执行到getResponseWithInterceptorChain()方法,这个方法里面通过拦截器组成的责任链,依次经过用户自定义普通拦截器、重试拦截器、桥接拦截器、缓存拦截器、连接拦截器和用户自定义网络拦截器以及访问服务器拦截器等拦截处理过程,来获取到一个响应并交给用户。其中,除了OKHttp的内部请求流程这点之外,缓存和连接这两部分内容也是两个很重要的点,掌握了这3点就说明你理解了OkHttp。
各个拦截器的作用:
- interceptors:用户自定义拦截器
- retryAndFollowUpInterceptor:负责失败重试以及重定向
- BridgeInterceptor:请求时,对必要的Header进行一些添加,接收响应时,移除必要的Header
- CacheInterceptor:负责读取缓存直接返回(根据请求的信息和缓存的响应的信息来判断是否存在缓存可用)、更新缓存
- ConnectInterceptor:负责和服务器建立连接
ConnectionPool:
1、判断连接是否可用,不可用则从ConnectionPool获取连接,ConnectionPool无连接,创建新连接,握手,放入ConnectionPool。
2、它是一个Deque,add添加Connection,使用线程池负责定时清理缓存。
3、使用连接复用省去了进行 TCP 和 TLS 握手的一个过程。
- networkInterceptors:用户定义网络拦截器
- CallServerInterceptor:负责向服务器发送请求数据、从服务器读取响应数据
你从这个库中学到什么有价值的或者说可借鉴的设计思想?
使用责任链模式实现拦截器的分层设计,每一个拦截器对应一个功能,充分实现了功能解耦,易维护。
手写拦截器?
OKhttp针对网络层有哪些优化?
网络请求缓存处理,okhttp如何处理网络缓存的?
HttpUrlConnection 和 okhttp关系?
自己去设计网络请求框架,怎么做?
从网络加载一个10M的图片,说下注意事项?
http怎么知道文件过大是否传输完毕的响应?
谈谈你对WebSocket的理解?
WebSocket与socket的区别?
二、网络封装框架:Retrofit实现原理
这个库是做什么用的?
Retrofit 是一个 RESTful 的 HTTP 网络请求框架的封装。Retrofit 2.0 开始内置 OkHttp,前者专注于接口的封装,后者专注于网络请求的高效。
为什么要在项目中使用这个库?
1、功能强大:
- 支持同步、异步
- 支持多种数据的解析 & 序列化格式
- 支持RxJava
2、简洁易用:
- 通过注解配置网络请求参数
- 采用大量设计模式简化使用
3、可扩展性好:
- 功能模块高度封装
- 解耦彻底,如自定义Converters
这个库都有哪些用法?对应什么样的使用场景?
任何网络场景都应该优先选择,特别是后台API遵循Restful API设计风格 & 项目中使用到RxJava。
这个库的优缺点是什么,跟同类型库的比较?
- 优点:在上面
- 缺点:扩展性差,高度封装所带来的必然后果,如果服务器不能给出统一的API形式,会很难处理。
这个库的核心实现原理是什么?如果让你实现这个库的某些核心功能,你会考虑怎么去实现?
Retrofit主要是在create方法中采用动态代理模式(通过访问代理对象的方式来间接访问目标对象)实现接口方法,这个过程构建了一个ServiceMethod对象,根据方法注解获取请求方式,参数类型和参数注解拼接请求的链接,当一切都准备好之后会把数据添加到Retrofit的RequestBuilder中。然后当我们主动发起网络请求的时候会调用okhttp发起网络请求,okhttp的配置包括请求方式,URL等在Retrofit的RequestBuilder的build()方法中实现,并发起真正的网络请求。
你从这个库中学到什么有价值的或者说可借鉴的设计思想?
内部使用了优秀的架构设计和大量的设计模式,在我分析过Retrofit最新版的源码和大量优秀的Retrofit源码分析文章后,我发现,要想真正理解Retrofit内部的核心源码流程和设计思想,首先,需要对它使用到的九大设计模式有一定的了解,下面我简单说一说:
1、创建Retrofit实例:
- 使用建造者模式通过内部Builder类建立了一个Retroift实例。
- 网络请求工厂使用了工厂方法模式。
2、创建网络请求接口的实例:
- 首先,使用外观模式统一调用创建网络请求接口实例和网络请求参数配置的方法。
- 然后,使用动态代理动态地去创建网络请求接口实例。
- 接着,使用了建造者模式 & 单例模式创建了serviceMethod对象。
- 再者,使用了策略模式对serviceMethod对象进行网络请求参数配置,即通过解析网络请求接口方法的参数、返回值和注解类型,从Retrofit对象中获取对应的网络的url地址、网络请求执行器、网络请求适配器和数据转换器。
- 最后,使用了装饰者模式ExecuteCallBack为serviceMethod对象加入线程切换的操作,便于接受数据后通过Handler从子线程切换到主线程从而对返回数据结果进行处理。
3、发送网络请求:
- 在异步请求时,通过静态delegate代理对网络请求接口的方法中的每个参数使用对应的ParameterHanlder进行解析。
4、解析数据
5、切换线程:
- 使用了适配器模式通过检测不同的Platform使用不同的回调执行器,然后使用回调执行器切换线程,这里同样是使用了装饰模式。
6、处理结果
Android:主流网络请求开源库的对比(Android-Async-Http、Volley、OkHttp、Retrofit)
三、响应式编程框架:RxJava实现原理
RxJava 变换操作符 map flatMap concatMap buffer?
- map:【数据类型转换】将被观察者发送的事件转换为另一种类型的事件。
- flatMap:【化解循环嵌套和接口嵌套】将被观察者发送的事件序列进行拆分 & 转换 后合并成一个新的事件序列,最后再进行发送。
- concatMap:【有序】与 flatMap 的 区别在于,拆分 & 重新合并生成的事件序列 的顺序与被观察者旧序列生产的顺序一致。
- buffer:定期从被观察者发送的事件中获取一定数量的事件并放到缓存区中,然后把这些数据集合打包发射。
手写rxjava遍历数组。
你认为Rxjava的线程池与你们自己实现任务管理框架有什么区别?
四、图片加载框架:Glide实现原理
这个库是做什么用的?
Glide是Android中的一个图片加载库,用于实现图片加载。
为什么要在项目中使用这个库?
1、多样化媒体加载:不仅可以进行图片缓存,还支持Gif、WebP、缩略图,甚至是Video。
2、通过设置绑定生命周期:可以使加载图片的生命周期动态管理起来。
3、高效的缓存策略:支持内存、Disk缓存,并且Picasso只会缓存原始尺寸的图片,内Glide缓存的是多种规格,也就是Glide会根据你ImageView的大小来缓存相应大小的图片尺寸。
4、内存开销小:默认的Bitmap格式是RGB_565格式,而Picasso默认的是ARGB_8888格式,内存开销小一半。
这个库都有哪些用法?对应什么样的使用场景?
1、图片加载:Glide.with(this).load(imageUrl).override(800, 800).placeholder().error().animate().into()。
2、多样式媒体加载:asBitamp、asGif。
3、生命周期集成。
4、可以配置磁盘缓存策略ALL、NONE、SOURCE、RESULT。
这个库的优缺点是什么,跟同类型库的比较?
库比较大,源码实现复杂。
这个库的核心实现原理是什么?如果让你实现这个库的某些核心功能,你会考虑怎么去实现?
- Glide&with:
1、初始化各式各样的配置信息(包括缓存,请求线程池,大小,图片格式等等)以及glide对象。
2、将glide请求和application/SupportFragment/Fragment的生命周期绑定在一块。
- Glide&load:
设置请求url,并记录url已设置的状态。
3、Glide&into:
1、首先根据转码类transcodeClass类型返回不同的ImageViewTarget:BitmapImageViewTarget、DrawableImageViewTarget。
2、递归建立缩略图请求,没有缩略图请求,则直接进行正常请求。
3、如果没指定宽高,会根据ImageView的宽高计算出图片宽高,最终执行到onSizeReay()方法中的engine.load()方法。
4、engine是一个负责加载和管理缓存资源的类
Glide源码机制的核心思想:
使用一个弱引用map activeResources来盛放项目中正在使用的资源。Lrucache中不含有正在使用的资源。资源内部有个计数器来显示自己是不是还有被引用的情况,把正在使用的资源和没有被使用的资源分开有什么好处呢??因为当Lrucache需要移除一个缓存时,会调用resource.recycle()方法。注意到该方法上面注释写着只有没有任何consumer引用该资源的时候才可以调用这个方法。那么为什么调用resource.recycle()方法需要保证该资源没有任何consumer引用呢?glide中resource定义的recycle()要做的事情是把这个不用的资源(假设是bitmap或drawable)放到bitmapPool中。bitmapPool是一个bitmap回收再利用的库,在做transform的时候会从这个bitmapPool中拿一个bitmap进行再利用。这样就避免了重新创建bitmap,减少了内存的开支。而既然bitmapPool中的bitmap会被重复利用,那么肯定要保证回收该资源的时候(即调用资源的recycle()时),要保证该资源真的没有外界引用了。这也是为什么glide花费那么多逻辑来保证Lrucache中的资源没有外界引用的原因。
Glide如何确定图片加载完毕?
Glide使用什么缓存?
Glide内存缓存如何控制大小?
计算一张图片的大小
图片占用内存的计算公式:图片高度 * 图片宽度 * 一个像素占用的内存大小。所以,计算图片占用内存大小的时候,要考虑图片所在的目录跟设备密度,这两个因素其实影响的是图片的宽高,android会对图片进行拉升跟压缩。
加载bitmap过程(怎样保证不产生内存溢出)
由于Android对图片使用内存有限制,若是加载几兆的大图片便内存溢出。Bitmap会将图片的所有像素(即长x宽)加载到内存中,如果图片分辨率过大,会直接导致内存OOM,只有在BitmapFactory加载图片时使用BitmapFactory.Options对相关参数进行配置来减少加载的像素。
BitmapFactory.Options相关参数详解:
(1).Options.inPreferredConfig值来降低内存消耗。
比如:默认值ARGB_8888改为RGB_565,节约一半内存。
(2).设置Options.inSampleSize 缩放比例,对大图片进行压缩 。
(3).设置Options.inPurgeable和inInputShareable:让系统能及时回收内存。
A:inPurgeable:设置为True时,表示系统内存不足时可以被回收,设置为False时,表示不能被回收。
B:inInputShareable:设置是否深拷贝,与inPurgeable结合使用,inPurgeable为false时,该参数无意义。
(4).使用decodeStream代替decodeResource等其他方法。
Android中软引用与弱引用的应用场景。
Java 引用类型分类:
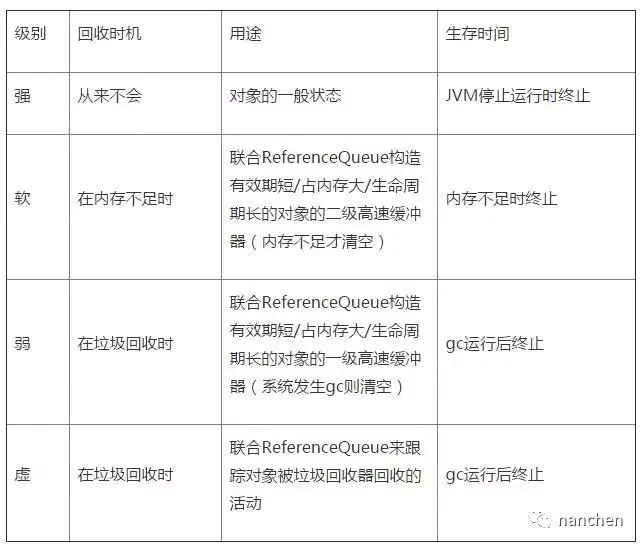
在 Android 应用的开发中,为了防止内存溢出,在处理一些占用内存大而且生命周期较长的对象时候,可以尽量应用软引用和弱引用技术。
- 1、软/弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java 虚拟机就会把这个软引用加入到与之关联的引用队列中。利用这个队列可以得知被回收的软/弱引用的对象列表,从而为缓冲器清除已失效的软 / 弱引用。
- 2、如果只是想避免 OOM 异常的发生,则可以使用软引用。如果对于应用的性能更在意,想尽快回收一些占用内存比较大的对象,则可以使用弱引用。
- 3、可以根据对象是否经常使用来判断选择软引用还是弱引用。如果该对象可能会经常使用的,就尽量用软引用。如果该对象不被使用的可能性更大些,就可以用弱引用。
Android里的内存缓存和磁盘缓存是怎么实现的。
内存缓存基于LruCache实现,磁盘缓存基于DiskLruCache实现。这两个类都基于Lru算法和LinkedHashMap来实现。
LRU算法可以用一句话来描述,如下所示:
LRU是Least Recently Used的缩写,最近最少使用算法,从它的名字就可以看出,它的核心原则是如果一个数据在最近一段时间没有使用到,那么它在将来被访问到的可能性也很小,则这类数据项会被优先淘汰掉。
LruCache原理
之前,我们会使用内存缓存技术实现,也就是软引用或弱引用,在Android 2.3(APILevel 9)开始,垃圾回收器会更倾向于回收持有软引用或弱引用的对象,这让软引用和弱引用变得不再可靠。
其实LRU缓存的实现类似于一个特殊的栈,把访问过的元素放置到栈顶(若栈中存在,则更新至栈顶;若栈中不存在则直接入栈),然后如果栈中元素数量超过限定值,则删除栈底元素(即最近最少使用的元素)。
它的内部存在一个 LinkedHashMap 和 maxSize,把最近使用的对象用强引用存储在 LinkedHashMap 中,给出来 put 和 get 方法,每次 put 图片时计算缓存中所有图片的总大小,跟 maxSize 进行比较,大于 maxSize,就将最久添加的图片移除,反之小于 maxSize 就添加进来。
LruCache的原理就是利用LinkedHashMap持有对象的强引用,按照Lru算法进行对象淘汰。具体说来假设我们从表尾访问数据,在表头删除数据,当访问的数据项在链表中存在时,则将该数据项移动到表尾,否则在表尾新建一个数据项。当链表容量超过一定阈值,则移除表头的数据。
详细来说就是LruCache中维护了一个集合LinkedHashMap,该LinkedHashMap是以访问顺序排序的。当调用put()方法时,就会在结合中添加元素,并调用trimToSize()判断缓存是否已满,如果满了就用LinkedHashMap的迭代器删除队头元素,即近期最少访问的元素。当调用get()方法访问缓存对象时,就会调用LinkedHashMap的get()方法获得对应集合元素,同时会更新该元素到队尾。
LruCache put方法核心逻辑
在添加过缓存对象后,调用trimToSize()方法,来判断缓存是否已满,如果满了就要删除近期最少使用的对象。trimToSize()方法不断地删除LinkedHashMap中队头的元素,即近期最少访问的,直到缓存大小小于最大值(maxSize)。
LruCache get方法核心逻辑
当调用LruCache的get()方法获取集合中的缓存对象时,就代表访问了一次该元素,将会更新队列,保持整个队列是按照访问顺序排序的。
为什么会选择LinkedHashMap呢?
这跟LinkedHashMap的特性有关,LinkedHashMap的构造函数里有个布尔参数accessOrder,当它为true时,LinkedHashMap会以访问顺序为序排列元素,否则以插入顺序为序排序元素。
LinkedHashMap原理
LinkedHashMap 几乎和 HashMap 一样:从技术上来说,不同的是它定义了一个 Entry<K,V> header,这个 header 不是放在 Table 里,它是额外独立出来的。LinkedHashMap 通过继承 hashMap 中的 Entry<K,V>,并添加两个属性 Entry<K,V> before,after,和 header 结合起来组成一个双向链表,来实现按插入顺序或访问顺序排序。
DisLruCache原理
DiskLruCache与LruCache原理相似,只是多了一个journal文件来做磁盘文件的管理,如下所示:
libcore.io.DiskLruCache
1
1
1
DIRTY 1517126350519
CLEAN 1517126350519 5325928
REMOVE 1517126350519
注:这里的缓存目录是应用的缓存目录/data/data/pckagename/cache,未root的手机可以通过以下命令进入到该目录中或者将该目录整体拷贝出来:
//进入/data/data/pckagename/cache目录
adb shell
run-as com.your.packagename
cp /data/data/com.your.packagename/
//将/data/data/pckagename目录拷贝出来
adb backup -noapk com.your.packagename
我们来分析下这个文件的内容:
第一行:libcore.io.DiskLruCache,固定字符串。 第二行:1,DiskLruCache源码版本号。 第三行:1,App的版本号,通过open()方法传入进去的。 第四行:1,每个key对应几个文件,一般为1. 第五行:空行 第六行及后续行:缓存操作记录。 第六行及后续行表示缓存操作记录,关于操作记录,我们需要了解以下三点:
DIRTY 表示一个entry正在被写入。写入分两种情况,如果成功会紧接着写入一行CLEAN的记录;如果失败,会增加一行REMOVE记录。注意单独只有DIRTY状态的记录是非法的。 当手动调用remove(key)方法的时候也会写入一条REMOVE记录。 READ就是说明有一次读取的记录。 CLEAN的后面还记录了文件的长度,注意可能会一个key对应多个文件,那么就会有多个数字。
Bitmap 压缩策略
加载 Bitmap 的方式:
BitmapFactory 四类方法:
- decodeFile( 文件系统 )
- decodeResourece( 资源 )
- decodeStream( 输入流 )
- decodeByteArray( 字节数 )
BitmapFactory.options 参数:
- inSampleSize 采样率,对图片高和宽进行缩放,以最小比进行缩放(一般取值为 2 的指数)。通常是根据图片宽高实际的大小/需要的宽高大小,分别计算出宽和高的缩放比。但应该取其中最小的缩放比,避免缩放图片太小,到达指定控件中不能铺满,需要拉伸从而导致模糊。
- inJustDecodeBounds 获取图片的宽高信息,交给 inSampleSize 参数选择缩放比。通过 inJustDecodeBounds = true,然后加载图片就可以实现只解析图片的宽高信息,并不会真正的加载图片,所以这个操作是轻量级的。当获取了宽高信息,计算出缩放比后,然后在将 inJustDecodeBounds = false,再重新加载图片,就可以加载缩放后的图片。
高效加载 Bitmap 的流程:
- 1、将 BitmapFactory.Options 的 inJustDecodeBounds 参数设为 true 并加载图片
- 2、从 BitmapFactory.Options 中取出图片原始的宽高信息,对应于 outWidth 和 outHeight 参数
- 3、根据采样率规则并结合目标 view 的大小计算出采样率 inSampleSize
- 4、将 BitmapFactory.Options 的 inJustDecodeBounds 设置为 false 重新加载图片
Bitmap的处理:
当使用ImageView的时候,可能图片的像素大于ImageView,此时就可以通过BitmapFactory.Option来对图片进行压缩,inSampleSize表示缩小2^(inSampleSize-1)倍。
BitMap的缓存:
1.使用LruCache进行内存缓存。
2.使用DiskLruCache进行硬盘缓存。
实现一个ImageLoader的流程
同步异步加载、图片压缩、内存硬盘缓存、网络拉取
- 1.同步加载只创建一个线程然后按照顺序进行图片加载
- 2.异步加载使用线程池,让存在的加载任务都处于不同线程
- 3.为了不开启过多的异步任务,只在列表静止的时候开启图片加载
Bitmap在decode的时候申请的内存如何复用,释放时机
图片库对比
stackoverflow.com/questions/2…
Bitmap如何处理大图,如一张30M的大图,如何预防OOM?
如何加载100M的图片却不撑爆内存?Bitmap处理一张 30M 的大图如何预防 OOM?
使用BitmapRegionDecoder动态加载图片的显示区域。
Bitmap对象的理解。
对inBitmap的理解。
自己去实现图片库,怎么做?(对扩展开发,对修改封闭,同时又保持独立性,参考Android源码设计模式解析实战的图片加载库案例即可)
写个图片浏览器,说出你的思路?
五、事件总线框架:EventBus实现原理
六、内存泄漏检测框架:LeakCanary实现原理
这个库是做什么用?
内存泄露检测框架。
为什么要在项目中使用这个库?
- 针对Android Activity组件完全自动化的内存泄漏检查,在最新的版本中,还加入了android.app.fragment的组件自动化的内存泄漏检测。
- 易用集成,使用成本低。
- 友好的界面展示和通知。
这个库都有哪些用法?对应什么样的使用场景?
直接从application中拿到全局的 refWatcher 对象,在Fragment或其他组件的销毁回调中使用refWatcher.watch(this)检测是否发生内存泄漏。
这个库的优缺点是什么,跟同类型库的比较?
检测结果并不是特别的准确,因为内存的释放和对象的生命周期有关也和GC的调度有关。
这个库的核心实现原理是什么?如果让你实现这个库的某些核心功能,你会考虑怎么去实现?
主要分为如下7个步骤:
- 1、RefWatcher.watch()创建了一个KeyedWeakReference用于去观察对象。
- 2、然后,在后台线程中,它会检测引用是否被清除了,并且是否没有触发GC。
- 3、如果引用仍然没有被清除,那么它将会把堆栈信息保存在文件系统中的.hprof文件里。
- 4、HeapAnalyzerService被开启在一个独立的进程中,并且HeapAnalyzer使用了HAHA开源库解析了指定时刻的堆栈快照文件heap dump。
- 5、从heap dump中,HeapAnalyzer根据一个独特的引用key找到了KeyedWeakReference,并且定位了泄露的引用。
- 6、HeapAnalyzer为了确定是否有泄露,计算了到GC Roots的最短强引用路径,然后建立了导致泄露的链式引用。
- 7、这个结果被传回到app进程中的DisplayLeakService,然后一个泄露通知便展现出来了。
你从这个库中学到什么有价值的或者说可借鉴的设计思想?
leakCannary中如何判断一个对象是否被回收?如何触发手动gc?c层实现?
BlockCanary原理:
该组件利用了主线程的消息队列处理机制,应用发生卡顿,一定是在dispatchMessage中执行了耗时操作。我们通过给主线程的Looper设置一个Printer,打点统计dispatchMessage方法执行的时间,如果超出阀值,表示发生卡顿,则dump出各种信息,提供开发者分析性能瓶颈。
七、依赖注入框架:ButterKnife实现原理
ButterKnife对性能的影响很小,因为没有使用使用反射,而是使用的Annotation Processing Tool(APT),注解处理器,javac中用于编译时扫描和解析Java注解的工具。在编译阶段执行的,它的原理就是读入Java源代码,解析注解,然后生成新的Java代码。新生成的Java代码最后被编译成Java字节码,注解解析器不能改变读入的Java类,比如不能加入或删除Java方法。
AOP IOC 的好处以及在 Android 开发中的应用
八、依赖全局管理框架:Dagger2实现原理
九、数据库框架:GreenDao实现原理
数据库框架对比?
数据库的优化
数据库数据迁移问题
数据库索引的数据结构
平衡二叉树
- 1、非叶子节点只能允许最多两个子节点存在。
- 2、每一个非叶子节点数据分布规则为左边的子节点小当前节点的值,右边的子节点大于当前节点的值(这里值是基于自己的算法规则而定的,比如hash值)。
- 3、树的左右两边的层级数相差不会大于1。
使用平衡二叉树能保证数据的左右两边的节点层级相差不会大于1.,通过这样避免树形结构由于删除增加变成线性链表影响查询效率,保证数据平衡的情况下查找数据的速度近于二分法查找。
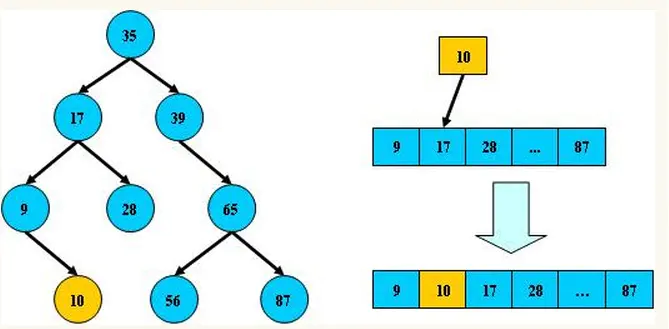
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构。
B-Tree
B树和平衡二叉树稍有不同的是B树属于多叉树又名平衡多路查找树(查找路径不只两个)。
- 1、排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则。
- 2、子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉)。
- 3、关键字数:枝节点的关键字数量大于等于ceil(m/2)-1个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2)。
- 4、所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指针地址都为null对应下图最后一层节点的空格子。
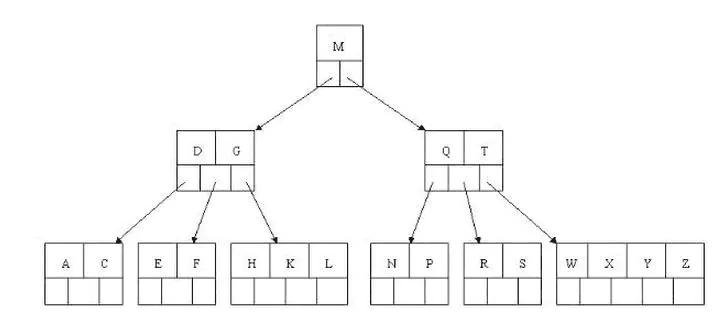
B树相对于平衡二叉树的不同是,每个节点包含的关键字增多了,把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度。
B+Tree
规则:
- 1、B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引。
- 2、B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样。
- 3、B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
- 4、非叶子节点的子节点数=关键字数(来源百度百科)(根据各种资料 这里有两种算法的实现方式,另一种为非叶节点的关键字数=子节点数-1(来源维基百科),虽然他们数据排列结构不一样,但其原理还是一样的Mysql 的B+树是用第一种方式实现)。
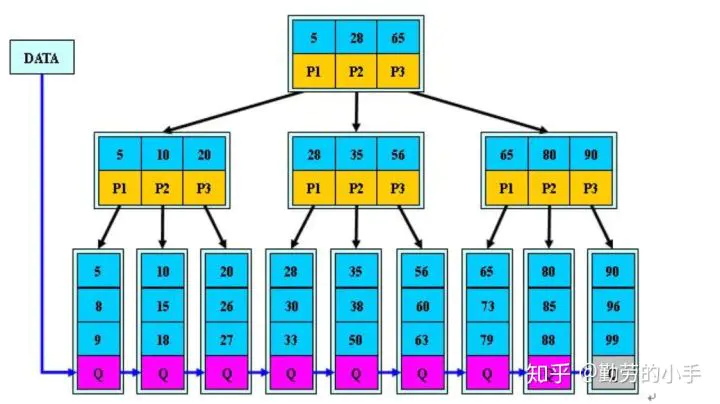
特点:
1、B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快。
2、B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定。
3、B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
4、B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
B*Tree
B*树是B+树的变种,相对于B+树他们的不同之处如下:
-
1、首先是关键字个数限制问题,B+树初始化的关键字初始化个数是cei(m/2),b树的初始化个数为(cei(2/3m))。
-
2、B+树节点满时就会分裂,而B*树节点满时会检查兄弟节点是否满(因为每个节点都有指向兄弟的指针),如果兄弟节点未满则向兄弟节点转移关键字,如果兄弟节点已满,则从当前节点和兄弟节点各拿出1/3的数据创建一个新的节点出来。
在B+树的基础上因其初始化的容量变大,使得节点空间使用率更高,而又存有兄弟节点的指针,可以向兄弟节点转移关键字的特性使得B*树分解次数变得更少。
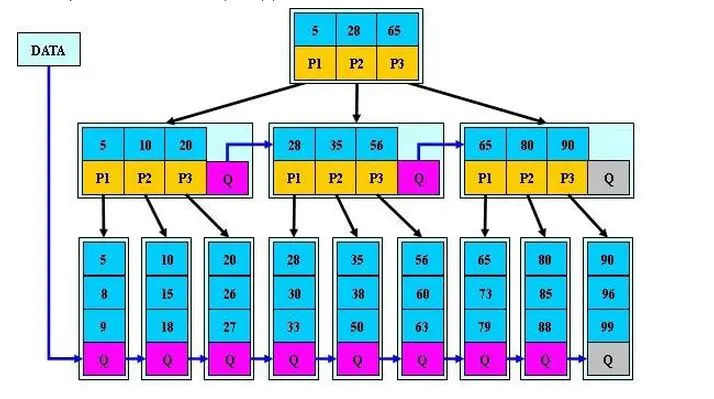
结论:
- 1、相同思想和策略:从平衡二叉树、B树、B+树、B*树总体来看它们贯彻的思想是相同的,都是采用二分法和数据平衡策略来提升查找数据的速度。
- 2、不同的方式的磁盘空间利用:不同点是他们一个一个在演变的过程中通过IO从磁盘读取数据的原理进行一步步的演变,每一次演变都是为了让节点的空间更合理的运用起来,从而使树的层级减少达到快速查找数据的目的;
还不理解请查看:平衡二叉树、B树、B+树、B*树 理解其中一种你就都明白了。
《设计思想解读开源框架》
随着互联网企业的不断发展,产品项目中的模块越来越多,用户体验要求也越来越高,想实现小步快跑、快速迭代的目的越来越难,还有65535,应用之间的互相调用等等问题,插件化技术应用而生。如果没有插件化技术,美团、淘宝这些集成了大量“app”的应用,可能会有几个g那么大。
所以,当今的Android移动开发,不会热修复、插件化、组件化,80%以上的面试都过不了。
Android热修复框架、插件化框架、组件化框架、图片加载框架、网络访问框架、RxJava响应式编程框架、IOC依赖注入框架、最近架构组件Jetpack等等Android第三方开源框架。系统教程知识笔记已整理成PDF电子书上传在【GitHub】
1042页完整版PDF点击我就可以白嫖啦,记得给文章点个赞哦。

五、架构设计
MVC MVP MVVM原理和区别?
架构设计的目的
通过设计是模块程序化,从而做到高内聚低耦合,让开发者能更专注于功能实现本身,提供程序开发效率、更容易进行测试、维护和定位问题等等。而且,不同的规模的项目应该选用不同的架构设计。
MVC
MVC是模型(model)-视图(view)-控制器(controller)的缩写,其中M层处理数据,业务逻辑等;V层处理界面的显示结果;C层起到桥梁的作用,来控制V层和M层通信以此来达到分离视图显示和业务逻辑层。在Android中的MVC划分是这样的:
- 视图层(View):一般采用XML文件进行界面的描述,也可以在界面中使用动态布局的方式。
- 控制层(Controller):由Activity承担。
- 模型层(Model):数据库的操作、对网络等的操作,复杂业务计算等等。
MVC缺点
在Android开发中,Activity并不是一个标准的MVC模式中的Controller,它的首要职责是加载应用的布局和初始化用户界面,并接受和处理来自用户的操作请求,进而作出响应。随着界面及其逻辑的复杂度不断提升,Activity类的职责不断增加,以致变得庞大臃肿。
MVP
MVP框架由3部分组成:View负责显示,Presenter负责逻辑处理,Model提供数据。
- View:负责绘制UI元素、与用户进行交互(在Android中体现为Activity)。
- Model:负责存储、检索、操纵数据(有时也实现一个Model interface用来降低耦合)。
- Presenter:作为View与Model交互的中间纽带,处理与用户交互的逻辑。
- View interface:需要View实现的接口,View通过View interface与Presenter进行交互,降低耦合,方便使用MOCK对Presenter进行单元测试。
MVP的Presenter是框架的控制者,承担了大量的逻辑操作,而MVC的Controller更多时候承担一种转发的作用。因此在App中引入MVP的原因,是为了将此前在Activty中包含的大量逻辑操作放到控制层中,避免Activity的臃肿。
MVP与MVC的主要区别:
- 1、(最主要区别)View与Model并不直接交互,而是通过与Presenter交互来与Model间接交互。而在MVC中View可以与Model直接交互。
- 2、Presenter与View的交互是通过接口来进行的,更有利于添加单元测试。
MVP的优点
- 1、模型与视图完全分离,我们可以修改视图而不影响模型。
- 2、可以更高效地使用模型,因为所有的交互都发生在一个地方——Presenter内部。
- 3、我们可以将一个Presenter用于多个视图,而不需要改变Presenter的逻辑。这个特性非常的有用,因为视图的变化总是比模型的变化频繁。
- 4、如果我们把逻辑放在Presenter中,那么我们就可以脱离用户接口来测试这些逻辑(单元测试)。
UI层一般包括Activity,Fragment,Adapter等直接和UI相关的类,UI层的Activity在启动之后实例化相应的Presenter,App的控制权后移,由UI转移到Presenter,两者之间的通信通过BroadCast、Handler、事件总线机制或者接口完成,只传递事件和结果。
MVP的执行流程:首先V层通知P层用户发起了一个网络请求,P层会决定使用负责网络相关的M层去发起请求网络,最后,P层将完成的结果更新到V层。
MVP的变种:Passive View
View直接依赖Presenter,但是Presenter间接依赖View,它直接依赖的是View实现的接口。相对于View的被动,那Presenter就是主动的一方。对于Presenter的主动,有如下的理解:
- Presenter是整个MVP体系的控制中心,而不是单纯的处理View请求的人。
- View仅仅是用户交互请求的汇报者,对于响应用户交互相关的逻辑和流程,View不参与决策,真正的决策者是Presenter。
- View向Presenter发送用户交互请求应该采用这样的口吻:“我现在将用户交互请求发送给你,你看着办,需要我的时候我会协助你”。
- 对于绑定到View上的数据,不应该是View从Presenter上“拉”回来的,应该是Presenter主动“推”给View的。(这里借鉴了IOC做法)
- View尽可能不维护数据状态,因为其本身仅仅实现单纯的、独立的UI操作;Presenter才是整个体系的协调者,它根据处理用于交互的逻辑给View和Model安排工作。
MVP架构存在的问题与解决办法
- 1、加入模板方法
将逻辑操作从V层转移到P层后,可能有一些Activity还是比较膨胀,此时,可以通过继承BaseActivity的方式加入模板方法。注意,最好不要超过3层继承。
- 2、Model内部分层
模型层(Model)中的整体代码量是最大的,此时可以进行模块的划分和接口隔离。
- 3、使用中介者和代理
在UI层和Presenter之间设置中介者Mediator,将例如数据校验、组装在内的轻量级逻辑操作放在Mediator中;在Presenter和Model之间使用代理Proxy;通过上述两者分担一部分Presenter的逻辑操作,但整体框架的控制权还是在Presenter手中。
MVVM
MVVM可以算是MVP的升级版,其中的VM是ViewModel的缩写,ViewModel可以理解成是View的数据模型和Presenter的合体,ViewModel和View之间的交互通过Data Binding完成,而Data Binding可以实现双向的交互,这就使得视图和控制层之间的耦合程度进一步降低,关注点分离更为彻底,同时减轻了Activity的压力。
MVC->MVP->MVVM演进过程
MVC -> MVP -> MVVM 这几个软件设计模式是一步步演化发展的,MVVM 是从 MVP 的进一步发展与规范,MVP 隔离了MVC中的 M 与 V 的直接联系后,靠 Presenter 来中转,所以使用 MVP 时 P 是直接调用 View 的接口来实现对视图的操作的,这个 View 接口的东西一般来说是 showData、showLoading等等。M 与 V已经隔离了,方便测试了,但代码还不够优雅简洁,所以 MVVM 就弥补了这些缺陷。在 MVVM 中就出现的 Data Binding 这个概念,意思就是 View 接口的 showData 这些实现方法可以不写了,通过 Binding 来实现。
三种模式的相同点
M层和V层的实现是一样的。
三种模式的不同点
三者的差异在于如何粘合View和Model,实现用户的交互操作以及变更通知。
- Controller:接收View的命令,对Model进行操作,一个Controller可以对应多个View。
- Presenter:Presenter与Controller一样,接收View的命令,对Model进行操作;与Controller不同的是Presenter会反作用于View,Model的变更通知首先被Presenter获得,然后Presenter再去更新View。通常一个Presenter只对应于一个View。据Presenter和View对逻辑代码分担的程度不同,这种模式又有两种情况:普通的MVP模式和Passive View模式。
- ViewModel:注意这里的“Model”指的是View的Model,跟MVVM中的一个Model不是一回事。所谓View的Model就是包含View的一些数据属性和操作的这么一个东东,这种模式的关键技术就是数据绑定(data binding),View的变化会直接影响ViewModel,ViewModel的变化或者内容也会直接体现在View上。这种模式实际上是框架替应用开发者做了一些工作,开发者只需要较少的代码就能实现比较复杂的交互。
补充:基于AOP的架构设计
AOP(Aspect-Oriented Programming, 面向切面编程),诞生于上个世纪90年代,是对OOP(Object-Oriented Programming, 面向对象编程)的补充和完善。OOP引入封装、继承和多态性等概念来建立一种从上道下的对象层次结构,用以模拟公共行为的一个集合。当我们需要为分散的对象引入公共行为的时候,即定义从左到右的关系时,OOP则显得无能为力。例如日志功能。日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。对于其他类型的代码,如安全性、异常处理和透明的持续性也是如此。这种散布在各处的无关的代码被称为横切(Cross-Cutting)代码,在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。而AOP技术则恰恰相反,它利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其名为“Aspect”,即方面。所谓“方面”,简单地说,就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。
在Android App中的横切关注点有Http, SharedPreferences, Log, Json, Xml, File, Device, System, 格式转换等。Android App的需求差别很大,不同的需求横切关注点必然是不一样的。一般的App工程中应该有一个Util Package来存放相关的切面操作,在项目多了之后可以将其中使用较多的Util封装为一个Jar包/aar文件/远程依赖的方式供工程调用。
在使用MVP和AOP对App进行纵向和横向的切割之后,能够使得App整体的结构更清晰合理,避免局部的代码臃肿,方便开发、测试以及后续的维护。这样纵,横两次对于App代码的分割已经能使得程序不会过多堆积在一个Java文件里,但靠一次开发过程就写出高质量的代码是很困难的,趁着项目的间歇期,对代码进行重构很有必要。
最后的建议
如果“从零开始”,用什么设计架构的问题属于想得太多做得太少的问题。 从零开始意味着一个项目的主要技术难点是基本功能实现。当每一个功能都需要考虑如何做到的时候,我觉得一般人都没办法考虑如何做好。 因为,所有的优化都是站在最上层进行统筹规划。在这之前,你必须对下层的每一个模块都非常熟悉,进而提炼可复用的代码、规划逻辑流程。
MVC的情况下怎么把Activity的C和V抽离?
MVP 架构中 Presenter 定义为接口有什么好处;
MVP如何管理Presenter的生命周期,何时取消网络请求?
aop思想
Fragment如果在Adapter中使用应该如何解耦?
项目框架里有没有Base类,BaseActivity和BaseFragment这种封装导致的问题,以及解决方法?
设计一个音乐播放界面,你会如何实现,用到那些类,如何设计,如何定义接口,如何与后台交互,如何缓存与下载,如何优化(15分钟时间)
从0设计一款App整体架构,如何去做?
说一款你认为当前比较火的应用并设计(比如:直播APP,P2P金融,小视频等)
实现一个库,完成日志的实时上报和延迟上报两种功能,该从哪些方面考虑?
你最优秀的工程设计项目,是怎么设计和实现的;扩展,如何做成一个平台级产品?
面试资料PDF电子书
资料已经上传在我的GitHub无偿分享下载!
Android中高级面试题集解析电子书(1294页)
资料已经上传在我的GitHub免费下载!诚意满满!!!
听说一键三连的粉丝都面试成功了?如果本篇博客对你有帮助,请支持下小编哦

Android高级面试精选题、架构师进阶实战文档传送门:我的GitHub
整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断!!!
参考
https://juejin.cn/post/6844904079169159175
https://juejin.cn/post/6905226221357891592
https://juejin.cn/post/6888222422760488974

 浙公网安备 33010602011771号
浙公网安备 33010602011771号