
混沌工程:通过试错的方法来提升稳定性
1. 什么是混沌工程?
起源:Netflix 和 Chaos Monkey
2008 年 Netflix 在整体微服务化和数据中心迁移至 AWS 云的背景下,开始了在生产环境进行系统弹性的测试。最早为大家熟知的是 Chaos Monkey,一个在生产环境中随机选择并关闭服务节点的工具。它的名字来源于其工作的方式:如同一只野生、武装的猴子,释放到在数据中心,来造成严重的破坏。
Chaos Monkey 的原则是:避免失败的最好办法就是经常失败。通过主动破坏自身环境,来发现系统的弱点。频繁的故障演练使开发团队能从问题中学习经验,从而对服务集群的稳定性有更高的重视。

发展:Simian Army
Chaos Monkey 之后,更多猴子陆续加入,统称为 Simian Army。它由一系列捣乱工具构成,其中的成员可用于随机关闭实例、服务调用中引入长时间延迟、模拟整个区域的断电场景等。并且通过与持续发布平台集成,自动进行线上演练。

混沌工程:Chaos Engineering
Netflix 在多年稳定性的实践历程中,总结了「混沌工程」的理念。
在复杂的分布式服务体系中,包含大量的交互、依赖点,故障发生的随机性和不可预测性都大大的增加了。混沌工程提倡通过不断重复失败过程,帮助我们发现系统中潜在的、可能导致灾难的脆弱环节,推动我们主动找出解决方案,从而不断打造更具弹性(系统应对故障、从故障中恢复的能力)的系统,建立对系统抵御生产环境中失控条件的能力以及信心。就像打疫苗可以预防疾病一样,通过混沌工程来提升系统的免疫力。
2. 混沌工程的实践原则
可以把混沌工程看作是为了揭示系统的弱点而进行的实验,实验中分为「控制组」和「实验组」:
- 实验组:引入一些“故障变量”,如服务器崩溃、硬盘故障、网络连接断开等
- 控制组:保持“稳定状态”,对照变化的实验组
通过这两组之间的稳定状态的差异来验证系统对故障的容错能力。注入故障后破坏稳定状态的难度越大,我们对系统的信心就越强。
举个例子,如下图:

1、设定系统故障容错的假设:API 服务调用 Gallery 服务,当 Gallery 不可用时,API 对 Gallery 的故障可优雅降级,不会导致系统不可用
2、设定实验范围:生产环境中,通过切小部分流量的方式,创建实验组、控制组环境
3、故障注入:API 调用 Gallery 的 rpc 请求注入中断故障
4、稳态验证:通过 GetGallery 监控指标进行容错假设的验证,预期故障注入后:
- 控制组:大量 countSuccess(请求成功数)
- 实验组:大量 countFallbackSuccess(成功降级数),极少数 countFallbackFailure(降级失败数),表示 API 对 Gallery 的故障降级 fallback 生效
- 在实验组注入故障后,监控指标能快速恢复至预期,可以认为系统是具备故障容错恢复能力的,否则就存在弱点

以下从 5 个角度描述了应用混沌工程的理想方式(源自 Netflix 的经验总结:http://principlesofchaos.org):
1、建立稳定状态的假设
我们将系统正常运行时的状态定义为系统的“稳定状态”,可以使用稳定状态来建立混沌实验的假设,一般是这样的形式:我们向系统中注入不同类型的故障事件后,不会导致系统稳定状态发生明显的变化
可以借助监控体系中的可度量指标来定义、观测系统的稳定状态,比如:
- 系统级别的指标:CPU负载、内存使用率、网络IO、吞吐率、错误率、99%的延迟、数据库的查询耗时,等各类时序信息
- 业务级别的指标:客服的呼叫量、播放按钮的点击率等
2、用多样化的现实世界事件做验证
引入现实中破坏稳态的故障事件,例如:服务器宕机、网络延迟、错误响应等。
3、在生产环境中进行实验
从功能性的故障测试角度(比如:验证预案的有效性、服务间的强弱依赖)来看,线下的测试环境也可满足预期。随着故障演练的成熟和系统对故障容错能力信心的提升,可逐步推广采用生产环境流量进行实验,保证系统执行方式的真实性。
4、自动化实验以持续运行
混沌实验的初始阶段可以手动执行,快速落地并获得收益,但这是劳动密集型、不可持续的。
后期可逐渐演进混沌工程的工具和平台,将实验的编排执行与结果分析自动化运行,以此来提升效率、扩大规模。
5、最小化爆炸半径
在生产环境中进行混沌实验,让系统的薄弱环节曝光,有导致生产环境崩溃的风险,并造成不必要的客户投诉,所以需要最小化爆炸半径,保证这些后续影响最小化,精细化控制故障的影响范围。
3. 混沌工程的好处
以下是混沌工程的应用场景,以及所能带来的收益:
|
应用场景 |
收益 |
|
强弱依赖治理 |
自动化周期性的获取应用间的强弱依赖关系,验证和预期是否一致,并对不符合预期的强依赖推动其弱依赖化,配置限流、降级策略; 系统链路的容量评估:当某个弱依赖挂掉时,整体的容量是否有影响? |
|
降级预案演练 |
在真实故障场景中,验证降级预案的容错能力,是否能将系统的 SLA 维持在相对较高的水平。避免非故障场景下预案功能正常,故障场景下却失效了 |
|
数据中心断网演练 |
验证数据中心的多活容灾,在无需人工干预的情况下,服务能自动在不同集群间进行可用区的平滑迁移 |
|
架构容灾评测 |
批量回放通用的故障场景,验证极端情况下个体组件的故障不会影响整个系统,监控报警、降级、主备切换、故障迁移等容灾手段的健壮性。提前发现并修复风险 |
|
红蓝演练 Game Day |
通过蓝军、红军的方式以战养战,反复验证故障的【发现 → 诊断 → 解决】流程准确度和应急效率,提升团队的经验值和信心,避免在各种报警中自乱手脚
|
|
故障复盘 |
通过对线上故障的重现,验证故障复盘的后续 todo 项落地效果如何,完成流程闭环。发生过的故障也可时常演练,看是否有劣化趋势 |
|
监控报警 |
校验报警是否符合预期:监控报警覆盖度、监控维度是否正确、告警阈值是否合理、告警是否快速、告警接收人是否正确,优化无效告警 |
4. 基于上述原则如何落地?
混沌工程是一种偏方法论的理念,本身不绑定任何平台或框架。那么基于这种理念,如何指导在应用上的落地呢?以下是我的一些想法
4.1 故障注入能力
首先我们需要引入真实场景下可能出现的故障,然后才可进行混沌实验。
按 SaaS 类、PaaS 类、IaaS 类的故障全景图:

可以通过故障事件发生的频率和影响范围来排定引入的优先级。从开发成本、运维效率、规模化推广的角度考虑,建议复用一些成熟的开源组件或商业工具,参考 CNCF 混沌工程的开源项目(CNCF 云原生全景图 https://landscape.cncf.io/)

以下是两个 star 较多、开源社区较为活跃的混沌工程项目。故障注入都做到了开箱即用、业务无感知,不需要业务配合写一些混沌工程相关的代码,也不需要更改系统的部署逻辑。
ChaosBlade(https://github.com/chaosblade-io):阿里开源
提供了丰富的故障场景,包括:
- Java 应用:Dubbo、JVM、HttpClient、Servlet、MySQL、MQ 等,可指定任意类+方法注入复杂的实验逻辑
- C++ 应用:指定任意方法或某行代码注入延迟、修改返回值
- Linux 基础资源:CPU、内存、网络、磁盘、进程
- 云原生平台:K8S 平台 Node/Pod/Container 上的 CPU、内存、网络、磁盘,kill pod/container 等

Chaos Mesh(github.com/chaos-mesh/chaos-mesh):PingCAP开源
面向 Kubernetes 的云原生混沌工程平台,覆盖网络、磁盘、文件系统、操作系统等故障场景,并提供了交互友好的 Dashboard 让用户轻松进行故障注入和稳态指标观测

4.2 平台化建设
基于故障注入的能力,将混沌实验的流程平台化,让用户更方便的使用。如下图:
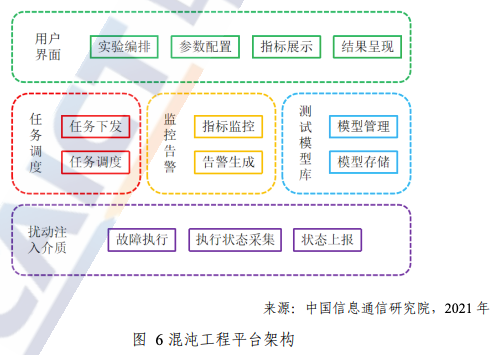
参考:信通院混沌工程实践指南(http://www.caict.ac.cn/kxyj/qwfb/ztbg/202112/P020211223588643401747.pdf)
(1)平台产品层
基于上文「3. 应用场景和收益」一节所描述的场景,总结实践经验和演练规范,抽象为开箱即用、简洁易懂的产品
(2)服务层
- 故障卡:对不同场景故障的一种抽象,以静态的形式表现在故障经验库 UI 界面中。可以与项目动态绑定,进而转化为 1 次故障演练。通过抽象模型,方便扩展新的故障场景,故障卡可定义如下:
- scope:故障范围。故障生效的机器/集群
- target:故障生效的组件。比如 dubbo 框架、MySQL、CPU 等
- action:故障模拟的场景。比如 dubbo 组件的延迟、抛异常;CPU 的满载
- matcher:故障生效的匹配条件。比如 dubbo 延迟,可以匹配 consumer 调用的 service 接口才生效,此外还可以匹配流量标识、请求用户、百分比比例、调用节点 IP 等条件
- 故障坐标:对故障卡进行优先级排序,展示在故障坐标系上。X 轴表示故障发生的可能性,Y 轴表示故障的影响范围
- 演练计划:选择故障坐标中的 n 个故障卡,将它们编排为 1 个 Game Day 的混沌工程实验
- 流程编排:根据编排好的 workflow,按指定的时间、串行/并行、手动/自动的执行「故障注入、稳态验证、故障清除」等动作
- 观测大盘:混沌实验期间,实时清晰的观测「稳态指标、故障指标、止损指标」。可集成监控平台:Sky Walking、Promethues 等
- 风险分析报告:混沌实验是否对系统造成影响的结论
- 服务树和架构拓扑图:方便混沌实验的分组,和全局的 Dashboard 可视化展示
- Agent 部署:方便故障注入 Agent 在服务机器上的安装、卸载和状态监控
- 变更规范:在生产环境注入故障,类似发布上线一样会对生产环境产生变更操作,所以需要有保护措施:权限校验、高峰期封线、审批/Double Check、消息通知、分级灰度发布、历史操作可审计等
- 周边系统对接:
- 对接预案平台,一站式验证降级预案的效果;
- 对接 CI 持续集成平台,周期性或服务发版时自动触发混沌实验的运行;
- 对接压测平台、QA 自动化测试平台、切流平台,复用流量构造方式,作为实验组的流量;
(3)底层基础能力
- 故障能力库:提供故障注入、清除的能力。技术选型和故障覆盖场景可参考上文「4.1 故障注入能力」
- 稳态指标:衡量系统稳定状态的监控指标,按定义的稳态假设,自动化分析故障对系统稳定性的影响是否符合预期
- 故障风险控制:
- 爆炸半径:通过上述故障模型的 scope + matcher 来控制故障的影响粒度,包括:服务、集群/机器、生效时间段、百分比流量、压测流量、城市、用户 ......
- 故障指标:指标确认故障注入是否成功,帮助用户直观看到故障功能的产生和结束。例如:对接口 /api/test 注入延迟 100ms 的故障,故障指标可以是 /api/test 的 top 99% 耗时监控
- 止损指标:指标表示此次演练能承受的最大限度,来自兜底的服务或业务指标。例如:对接口 /api/test 注入延迟 100ms 的故障,止损指标可以是接口失败率,当失败率 > 5% 时,需要立即终止实验
- 一键停止:可随机终止混沌实验的能力异常关键,避免对系统造成过度伤害。当监测到止损指标的波动到达了底线阈值,表明故障对系统有潜在危险,必须立即一键清除所有故障
4.3 应用推广
1、引入混沌工程,需要建立面向失败和拥抱失败的技术文化(可以使系统暴露出已有问题的设计)
组织内沟通到位,达成一致,从思想上认同混沌工程的价值。混沌工程的核心是通过引入一些风险变量去暴露已有问题,而不是创造问题和事故。在恰当的时间和可控的爆炸半径下进行实验,有助于问题的发现和处理,降低潜在故障带来的影响。
如果不愿意实施混沌实验的原因是:对系统在注入事件后的反应缺乏信心,害怕实验会给客户带来影响。然而该发生的故障还是会发生,即使实验暴露风险点的同时也会导致一些小的负面影响,但是提前了解和控制影响范围,也比最终措手不及的应对大规模事故要好的多。
2、实施混沌工程,需要定义一个清晰可衡量的目标
混沌工程的业务价值并不适合用过程指标来衡量,比如:模拟了多少种实验场景、发起多少次实验等等。
需要配合其他稳定性手段一起来衡量,比如:
- 前期:复现历史故障,确保故障改进的有效性
- 中期:选择监控发现率,验证故障发现能力和监控的完备程度
- 后期:随着实施混沌工程经验越来越丰富,可以考虑引入一些复杂的 MTTR(Mean Time To Restoration)度量指标,比如故障的 “发现-定位-恢复” 时长这种综合性指标
3、推广混沌工程,要在控制风险的前提下不断提升效率
越贴近生产环境的实验,结果越真实,同时风险也越大。可以先从测试环境、简单的故障场景开始尝试,明确系统稳定状态、止损停止条件、服务自身可恢复的兜底预案后,再逐渐过渡生产环境全链路的复杂场景。
先人工手动跑通完整流程,然后总结各场景混沌实验的规范,最后将流程规范平台化,可以定期的自动化运行,从而提升了效率,持续获得混沌实验的价值。
5. 混沌工程的迭代方向
混动工程实验可以简单如在测试环境中某个实例运行 kill -9 来模拟一个服务节点的突然宕机,也可以复杂到在线上挑选一小部分流量,按一定规律或频率自动运行一系列实验。
Netflix 总结了混沌工程的成熟度模型,包含「熟练度」和「应用度」两个维度,给出了明确的方向建议。概括如下:
熟练度:反映混沌工程项目的有效性和安全性
|
故障注入场景 |
演练环境 |
稳态结果分析 |
演练流程 |
|
|
入门 |
kill节点 |
线下:dev/test环境 |
系统指标(如cpu.idle) |
全人工 |
|
简单 |
网络延迟 CPU、IO高 |
线下仿真:复制生产流量 |
服务应用指标(如 接口错误率) |
自动:故障注入 |
|
高级 |
服务延迟、异常 |
线上生产环境 |
业务指标(如订单量) |
自动:CI 持续集成,持续验证
|
|
熟练 |
服务返回结果修改 动态调整爆炸半径 |
线上生产环境 |
实验组、交互组的稳态指标交互式对比 |
全自动:
|
应用度:反映混沌工程覆盖的广度和深度,即业务的实践推广
|
|
业务覆盖 |
组织演练 |
|
暗中进行 |
少数非关键服务 |
无组织,偶尔尝试 |
|
适当投入 |
少数关键服务 |
多个团队有兴趣,参与不定期演练 |
|
正式采用 |
大多数关键服务 |
混沌工程团队,定期演练 故障复盘,回归验证 |
|
成为文化 |
所有关键服务、系统组件 多数非关键服务 |
Game day 红蓝演练 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· 展开说说关于C#中ORM框架的用法!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?