KafkaMirrorMaker 的不足以及一些改进
背景
某系统使用 Kafka 存储实时的行情数据,为了保证数据的实时性,需要在多地机房维护多个 Kafka 集群,并将行情数据同步到这些集群上。
一个常用的方案就是官方提供的 KafkaMirrorMaker 方案:
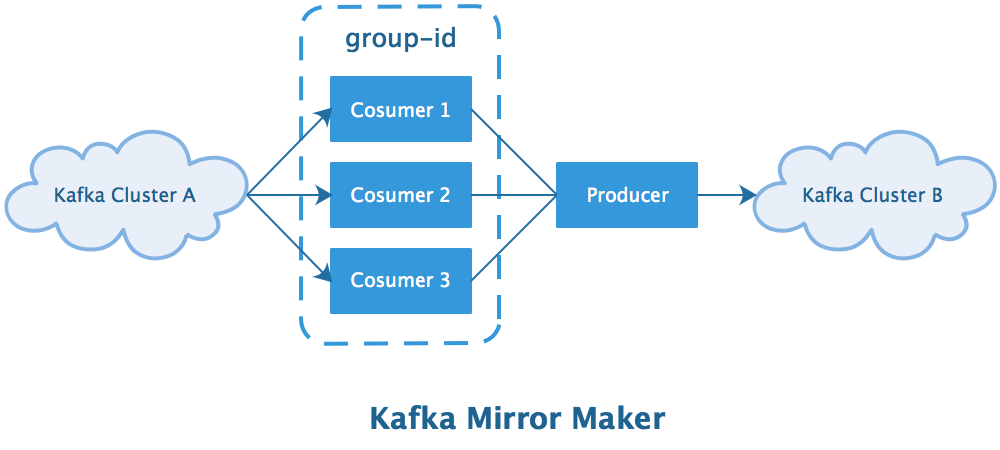
该方案的优点是能尽可能保证两个 Kafka 集群的数据一致(为了避免网络故障导致丢数据,要将其与 Kafka Cluster B 部署在同个机房),并且使用者无需进行开发工作,只需要进行响应的配置即可。
存在的问题
行情数据具有数据量大且时效性强的特点:
- 跨机房同步行情数据会消耗较多的专线带宽
- 网络故障恢复后继续同步旧数据意义不大并且可能引起副作用(行情数据延迟较大意味着已经失效)
因此 KafkaMirrorMaker 的同步方式存在以下两个不合理的地方:
- 无法实现多机房广播,会造成专线带宽浪费(多个机房同时拉取同一份数据)
- 单个 Producer 可能成为系统吞吐量的瓶颈(降低一致性以提高性能)
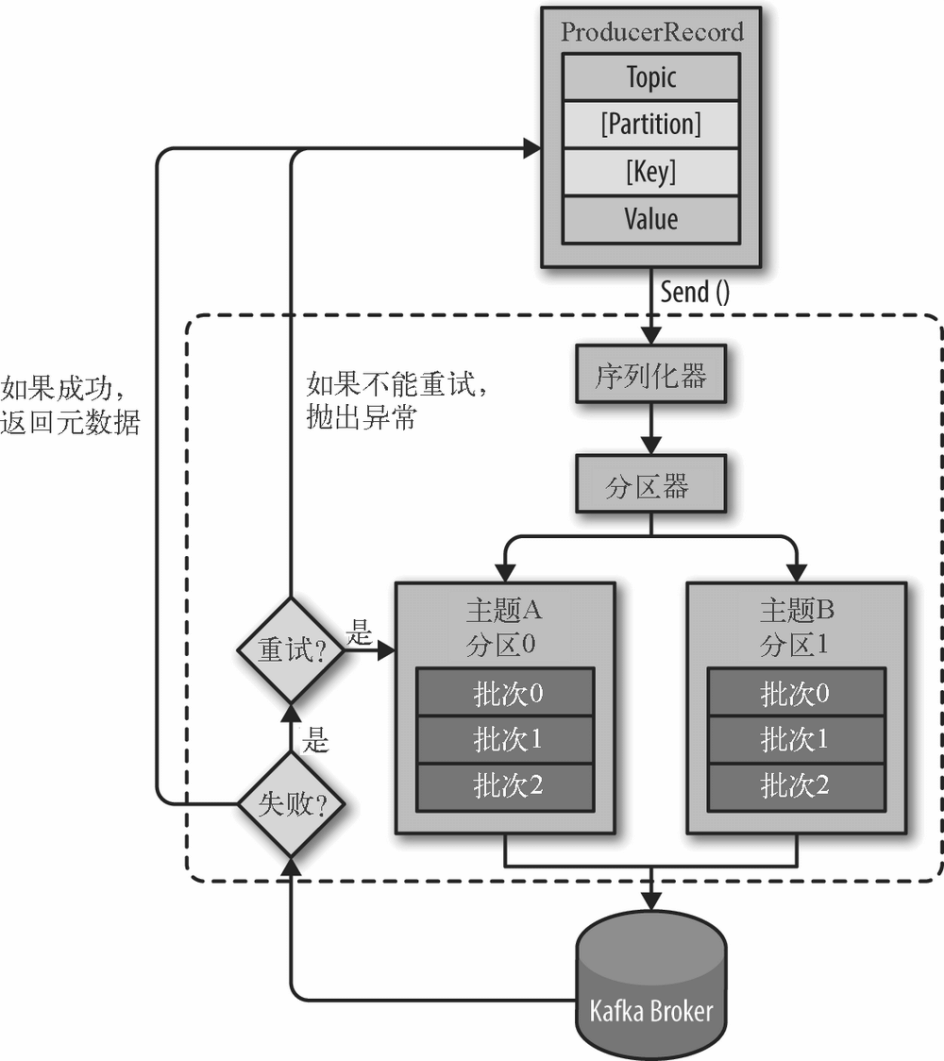
Producer 发送链路
主要的发送流程发送流程如下:
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
// 1. 阻塞获取集群信息,超时后抛出异常
ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
Cluster cluster = clusterAndWaitTime.cluster;
// 2. 序列化要发送的数据
byte[] serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
byte[] serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
// 3. 决定数据所属的分区
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
// 4. 将数据追加到发送缓冲,等待发送线程异步发送
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
// 5. 唤醒异步发送线程,将缓冲中的消息发送给 brokers
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
return result.future;
} catch (Exception e) {
// ...
}
}
决定分区
Producer 的功能是向某个 topic 的某个分区消息,所以它首先需要确认到底要向 topic 的哪个分区写入消息:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
// 如果 key 为空,使用 round-robin 策略确认目标分区(保证数据均匀)
int nextValue = nextValue(topic);
return Utils.toPositive(nextValue) % numPartitions;
} else {
// 如果 key 不为空,使用 key 的 hash 值确认目标分区(保证数据有序)
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
追加缓冲
为了保证防止过量消息积压在内存中,每个 Producer 会设置一个内存缓冲,其大小由buffer.memory选项控制。
如果缓冲区的数据超过该值,会导致Producer.send方法阻塞,等待内存释放(记录被发送出去或超时后被清理):
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
// 如果缓冲中存在未满的 ProducerBatch,则会尝试将记录追加到其中
// ...
// 估计记录所需要的空间
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
// 分配内存空间给当前记录
// 如果内存空间不足则会阻塞等待内存空间释放,如果超过等待时间会抛出异常
buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// 再次尝试向现存的 ProducerBatch 中追加数据,如果成功则直接返回
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
return appendResult;
}
// 新建 ProducerBatch 并将当前记录追加到其中
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()))
;
dq.addLast(batch);
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
} finally {
if (buffer != null)
free.deallocate(buffer);
}
}
异步发送
每个 Producer 都有一个发送线程KafkaProducer.ioThread,该线程会不停地调用Sender.sendProducerData方法将缓冲中的 RecordBatch 发送出去:
private long sendProducerData(long now) {
Cluster cluster = metadata.fetch();
// 获取就绪的 broker 节点信息,准备发送
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
if (!result.unknownLeaderTopics.isEmpty()) {
// 如果部分 topic 没有 leader 节点,则触发强制刷新
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
this.metadata.requestUpdate();
}
// 根据就绪 broker 节点信息,获取缓冲中对应的 ProducerBatch,准备发送
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes,
this.maxRequestSize, now);
if (guaranteeMessageOrder) {
// 排除已经检查过的分区,避免重复检查
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
// 清理已经过期的 ProducerBatch 数据,释放被占用的缓冲内存
List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(this.requestTimeout, now);
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", expiredBatches.size());
for (ProducerBatch expiredBatch : expiredBatches) {
failBatch(expiredBatch, -1, NO_TIMESTAMP, expiredBatch.timeoutException(), false);
}
// 如果任意 broker 节点已经就绪,则将 pollTimeout 设置为 0
// 这是为了避免不必要的等待,让内存中的数据能够尽快被发送出去
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
if (!result.readyNodes.isEmpty()) {
pollTimeout = 0;
}
// 通过 NetworkClient -> NetworkChannel -> TransportLayer
// 最终将将消息写入 NIO 的 Channel
sendProduceRequests(batches, now);
return pollTimeout;
}
优化方案
从前面的分析我们可以得知以下两点信息:
- 每个 Producer 有一个内存缓冲区,当空间耗尽后会阻塞等待内存释放
- 每个 Producer 有一个异步发送线程,且只维护一个 socket 连接(每个 broker 节点)
为了提高转发效率、节省带宽,使用 Java 复刻了一版 KafkaMirrorMaker 并进行了一些优化:
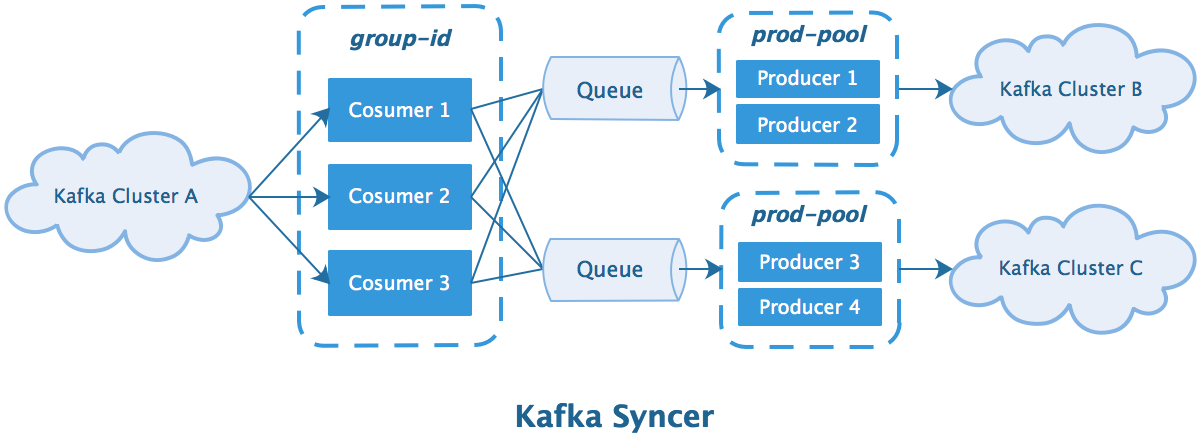
- 支持将一个集群的数据广播到多个集群
- 使用多个 Producer 同时进行转发提高效率
数据保序
如果同时使用多个 Producer,可能在转发过程中发生数据乱序,折中的策略是根据 key 的 hash 值来选择 Producer,保证 key 相同的数据会使用同个 Producer 进行发送:
void send(ConsumerRecord<byte[], byte[]> message) {
ProducerRecord record = new ProducerRecord<>(message.topic(), message.key(), message.value());
int hash = Math.abs(Arrays.hashCode(message.key()));
producers[hash % producers.length].send(record, onSend);
}
水位控制
多集群广播虽然能够一定程度上节省流量与机器资源,但是需要处理多个集群间发送速度不一致的问题。
极端情况下,如果其中某个机房的专线发生故障,Producer 会阻塞等待消息超时。当过量消息积压在 Queue 中,会导致 JMV 频繁的 FullGC,最终影响到对另一个机房的转发。
为了处理这一情况,需要在发送队列上加上水位线watermark限制:
interface Watermark {
default long high() { return Long.MAX_VALUE; }
default long low() { return 0; }
}
final BlockingQueue<byte[]> messageQueue = new LinkedBlockingQueue<>();
final AtomicLong messageBytes = new AtomicLong();
private void checkWatermark(Watermark bytesWatermark) {
long bytesInQueue = messageBytes.get();
if (bytesInQueue > bytesWatermark.high()) {
long discardBytes = bytesInQueue - bytesWatermark.low();
WatermarkKeeper keeper = new WatermarkKeeper(Integer.MAX_VALUE, discardBytes);
keeper.discardMessage(messageQueue);
long remainBytes = messageBytes.addAndGet(-discard.bytes());
}
}
为了实现高效的数据丢弃,使用BlockingQueue.drainTo减少锁开销:
public class WatermarkKeeper extends AbstractCollection<byte[]> {
private final int maxDiscardCount; // 丢弃消息数量上限
private final long maxDiscardBytes; // 丢弃消息字节上限
private int count; // 实际丢弃的消息数
private long bytes; // 实际丢弃消息字节数
public MessageBlackHole(int maxDiscardCount, long maxDiscardBytes) {
this.maxDiscardCount = maxDiscardCount;
this.maxDiscardBytes = maxDiscardBytes;
}
public void discardMessage(BlockingQueue<byte[]> queue) {
try {
queue.drainTo(this);
} catch (StopDiscardException ignore) {}
}
@Override
public boolean add(byte[] record) {
if (count >= maxDiscardCount || bytes >= maxDiscardBytes) {
throw new StopDiscardException();
}
count++;
bytes += record.length;
return true;
}
@Override
public int size() {
return count;
}
public long bytes() {
return bytes;
}
@Override
public Iterator<byte[]> iterator() {
throw new UnsupportedOperationException("iterator");
}
// 停止丢弃
private static class StopDiscardException extends RuntimeException {
@Override
public synchronized Throwable fillInStackTrace() {
return this;
}
}
}
监控优化
不使用 KafkairrorMaker 的另一个重要原因是其 JMX 监控不友好:
- RMI 机制本身存在安全隐患
- JMX 监控定制化比较繁琐(使用 jolokia 也无法解决这一问题)
一个比较好的方式是使用 SpringBoot2 的 micrometer 框架实现监控:
// 监控注册表(底层可以接入不同的监控平台)
@Autowired
private MeterRegistry meterRegistry;
// 接入 Kafka 的监控信息
new KafkaClientMetrics(consumer).bindTo(meterRegistry);
new KafkaClientMetrics(producer).bindTo(meterRegistry);
// 接入自定义监控信息
Gauge.builder("bytesInQueue", messageBytes, AtomicLong::get)
.description("Estimated message bytes backlog in BlockingQueue")
.register(meterRegistry);
通过这一方式能够最大程度地利用现有可视化监控工具,减少不必要地开发工作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号