跨境 TCP 传输优化实录 — 使用 BBR 解决 LFN 问题
背景
公司近期开通了一条访问美国机房的 1G 专线,并基于 TCP 建立了一套数据传输服务。上线后发现一个严重的问题:应用程序发送队列中的数据大量积压,最终导致程序 OOM Kill,但观察监控发现专线带宽利用率只有 50% - 60%。
经过沟通,发现运维同事当时使用 iperf3 测试专线带宽使用的是 UDP 协议,于是在运维同事协助下使用 TCP 进行二次测试,发现了比较严重的问题:
- 在国内机房使用 iperf3 测试单个 socket 流量,在同机房内部(1G交换机)可以达到的最大带宽约为 110Mb(对照组)
- 在跨境专线使用 iperf3 测试单个 socket 流量,发现极不稳定
Connecting to host US_NY_VM_01, port 5001
[ 4] local HK_QW_VM_01 port 58341 connected to US_NY_VM_01 port 5001
[ ID] Interval Transfer Bandwidth Retr Cwnd
[ 4] 0.00-1.00 sec 109 KBytes 892 Kbits/sec 0 42.4 KBytes
[ 4] 1.00-2.00 sec 1.04 MBytes 8.75 Mbits/sec 0 324 KBytes
[ 4] 2.00-3.00 sec 5.45 MBytes 45.7 Mbits/sec 0 1.52 MBytes
[ 4] 3.00-4.00 sec 7.50 MBytes 62.9 Mbits/sec 6 1.88 MBytes
[ 4] 4.00-5.00 sec 10.0 MBytes 83.9 Mbits/sec 0 2.10 MBytes
[ 4] 5.00-6.00 sec 11.2 MBytes 94.4 Mbits/sec 0 2.27 MBytes
[ 4] 6.00-7.00 sec 8.75 MBytes 73.4 Mbits/sec 0 2.38 MBytes
[ 4] 7.00-8.00 sec 12.5 MBytes 105 Mbits/sec 0 2.48 MBytes
[ 4] 8.00-9.00 sec 12.5 MBytes 105 Mbits/sec 0 2.56 MBytes
[ 4] 9.00-10.00 sec 11.2 MBytes 94.4 Mbits/sec 0 2.62 MBytes
[ 4] 10.00-11.00 sec 11.2 MBytes 94.4 Mbits/sec 0 2.65 MBytes
[ 4] 11.00-12.00 sec 12.5 MBytes 105 Mbits/sec 3 1.93 MBytes
[ 4] 12.00-13.00 sec 7.50 MBytes 62.9 Mbits/sec 92 1.42 MBytes
[ 4] 13.00-14.00 sec 6.23 MBytes 52.3 Mbits/sec 0 1.51 MBytes
[ 4] 14.00-15.00 sec 7.50 MBytes 62.9 Mbits/sec 0 1.58 MBytes
[ 4] 15.00-16.00 sec 8.75 MBytes 73.4 Mbits/sec 0 1.63 MBytes
[ 4] 16.00-17.00 sec 6.25 MBytes 52.4 Mbits/sec 0 1.66 MBytes
[ 4] 17.00-18.00 sec 8.75 MBytes 73.4 Mbits/sec 0 1.68 MBytes
[ 4] 18.00-19.00 sec 7.50 MBytes 62.9 Mbits/sec 0 1.69 MBytes
[ 4] 19.00-20.00 sec 8.75 MBytes 73.4 Mbits/sec 0 1.69 MBytes
[ 4] 20.00-21.00 sec 6.25 MBytes 52.4 Mbits/sec 0 1.69 MBytes
[ 4] 21.00-22.00 sec 8.75 MBytes 73.4 Mbits/sec 0 1.69 MBytes
[ 4] 22.00-23.00 sec 8.75 MBytes 73.4 Mbits/sec 0 1.70 MBytes
[ 4] 23.00-24.00 sec 6.25 MBytes 52.4 Mbits/sec 0 1.71 MBytes
[ 4] 24.00-25.00 sec 8.75 MBytes 73.4 Mbits/sec 0 1.73 MBytes
[ 4] 25.00-26.00 sec 8.75 MBytes 73.4 Mbits/sec 0 1.77 MBytes
[ 4] 26.00-27.00 sec 8.75 MBytes 73.4 Mbits/sec 0 1.82 MBytes
[ 4] 27.00-28.00 sec 7.50 MBytes 62.9 Mbits/sec 0 1.88 MBytes
[ 4] 28.00-29.00 sec 10.0 MBytes 83.9 Mbits/sec 0 1.99 MBytes
[ 4] 29.00-30.00 sec 10.0 MBytes 83.9 Mbits/sec 0 2.12 MBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-30.00 sec 249 MBytes 69.6 Mbits/sec 101 sender
[ 4] 0.00-30.00 sec 248 MBytes 69.3 Mbits/sec receiver
iperf Done.
从上图可以观察到存在以下问题:
- 网络状况不稳定,低速率时也会偶尔会出现 TCP 重传
- 传输速率波动较大,无法长时间维持在最佳的 105M 带宽,导致带宽利用率低
长肥管道 (LFN)
跨境专线具有较长的往返时间RTT与较高带宽 Bandwidth,这类具有大管道容量 BDP = RTT * Bandwidth 的网络我们称之为长肥管道LFN (Long Fat Networks)。

LFN 的 RTT 较长,因此一个包从发送到接收到 ACK 需要经历的时间比普通的网络更长。由于 TCP 滑动窗口的特性,网络会存在较长的空闲时间,导致网络的利用率不高。这篇文章中的动画很好的展示了这一点,推荐观看。因此一个简单的方案就是:增大在途未确认数据量amount inflight,使其填满整个管道。
决定在途数据量的因素有以下几个方面:
- 发送端:拥塞窗口大小
cwnd以及 发送缓冲大小 - 接收端:接收窗口大小
rwnd以及 接收缓冲大小
由于 cwnd 和 rwnd 大小是系统根据网络状况进行自适应调整的,无法无法直接干预。因此决定先尝试调整 TCP 缓冲配置,观察传输效果是否有提升。
TCP 缓冲调参
首先计算管道容量:已知专线带宽为 1Gb,通过 ping 查看专线 RTT 约为 210ms,据此 计算专线 BDP 约为 25MB。
做过 TCP 开发的同学应该都熟悉 SO_RECVBUF 和 SO_SENDBUF 这两个 socekt 选项,我们可以通过这两个参数来设置接收与发送缓冲区的大小。如果我们在建立连接 TCP 时指定了这两个参数,那么操作系统就会使用一个固定的缓冲区大小,而不再会根据网络进行动态调整,因此这两个选项要慎用。
然而当指定参数过后,会发现实际的 TCP 缓冲区大小与参数有所出入。这是什么原因造成的呢?首先来看几个重要的内核参数:
[lhop@localhost ~]$ sysctl -a 2>&1 | egrep 'core.wmem_max|core.rmem_max|ipv4.tcp_wmem|ipv4.tcp_rmem|tcp_adv_win_scale|tcp_moderate_rcvbuf'
net.core.wmem_max = 124928
net.core.rmem_max = 124928
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.tcp_rmem = 4096 87380 4194304
net.ipv4.tcp_adv_win_scale = 2
net.ipv4.tcp_moderate_rcvbuf = 1
-
net.ipv4.tcp_wmem与net.ipv4.tcp_rmem是单个 tcp socket 缓冲区的最小值min、默认值default、最大值max,单位为字节。 -
net.core.wmem_max与net.core.rmem_max是单个 socket 所能使用的缓冲区大小上限,单位为字节。该参数的优先级高于tcp_wmem与tcp_rmem的最大值,调整参数时需要注意两者的对应关系。 -
net.ipv4.tcp_moderate_rcvbuf是否允许操作系统动态调整 tcp 缓冲。开启后,系统会根据当前可用资源对接收缓冲进行动态调整,此时接收缓冲的大小会在tcp_rmem最大与最小值之间浮动。当 tcp socket 连接较多时,可以系统会酌情减少每个连接的缓存内存,避免资源耗尽。 -
net.ipv4.tcp_adv_win_scale是单个 tcp socket 接收缓冲预留给应用的比例。tcp 的接收缓冲可以分为两部分,一部分是用作接收窗口保存未确认报文,另一部分则是缓存未被应用程序读取的已确认报文,因此需要预留 1/2tcp_adv_win_scale 内存空间给未读报文。这也是tcp_rmem的初始默认值比tcp_wmem大的原因。
根据 sysctl 给出的结果,我们需要调整有:
- net.core.wmem_max = BDP = 26214400
- net.core.rmem_max = BDP/(1-1/2tcp_adv_win_scale) = 34952000
[lhop@localhost ~]$ cat <<EOF>> /etc/sysctl.conf
net.core.wmem_max = 26214400
net.core.rmem_max = 34952000
net.ipv4.tcp_wmem = 4096 87380 26214400
net.ipv4.tcp_rmem = 4096 87380 34952000
EOF
sysctl -p
调整后重新使用 ipref3 进行测试,发现测试结果基本上没有变化。基本可以断定:缓存不足不是造成 TCP 流量瓶颈的主因。
从前面的 iperf3 结果中可以看出,当出现重新传时,拥塞窗口急剧缩小,最终导致了传输速度的下降。决定拥塞窗口大小的就是拥塞控制算法,因此我们将目光转移到拥塞算法上。
拥塞控制
TCP拥塞控制算法的目的可以简单概括为:公平 与 效率。
- 当网络拥塞时,TCP 连接降低传输速率,减少由于竞争导致的网络资源浪费。
- 当网络空闲时,TCP 连接提升传输速率,提高通信效率。
根据实现方式不同,拥塞算法可以分为两类:基于丢包反馈 与 基于传输延时。
其最终目的是找到一个适合当前网络状况的最佳拥塞窗口 Wbest。
基于丢包反馈
基于丢包反馈的拥塞算法是目前应用最广泛且较为成熟的算法。
Linux 系统中默认的拥塞算法 reno 与 cubic 都属于这类:
[lhop@localhost ~]$ sysctl -a 2>&1 | egrep 'tcp_available_congestion_control|tcp_congestion_control'
net.ipv4.tcp_congestion_control = cubic
net.ipv4.tcp_available_congestion_control = cubic reno
Reno 算法
reno 是最经典的拥塞算法,其核心是基于 加性增窗/乘性减窗 AIMD 的反馈控制:当检测到信道拥塞时,拥塞窗口会呈指数级快速减小(减少网络丢包),然后窗口缓慢地线性增长(避免再次拥塞)。算法流程如下图所示:
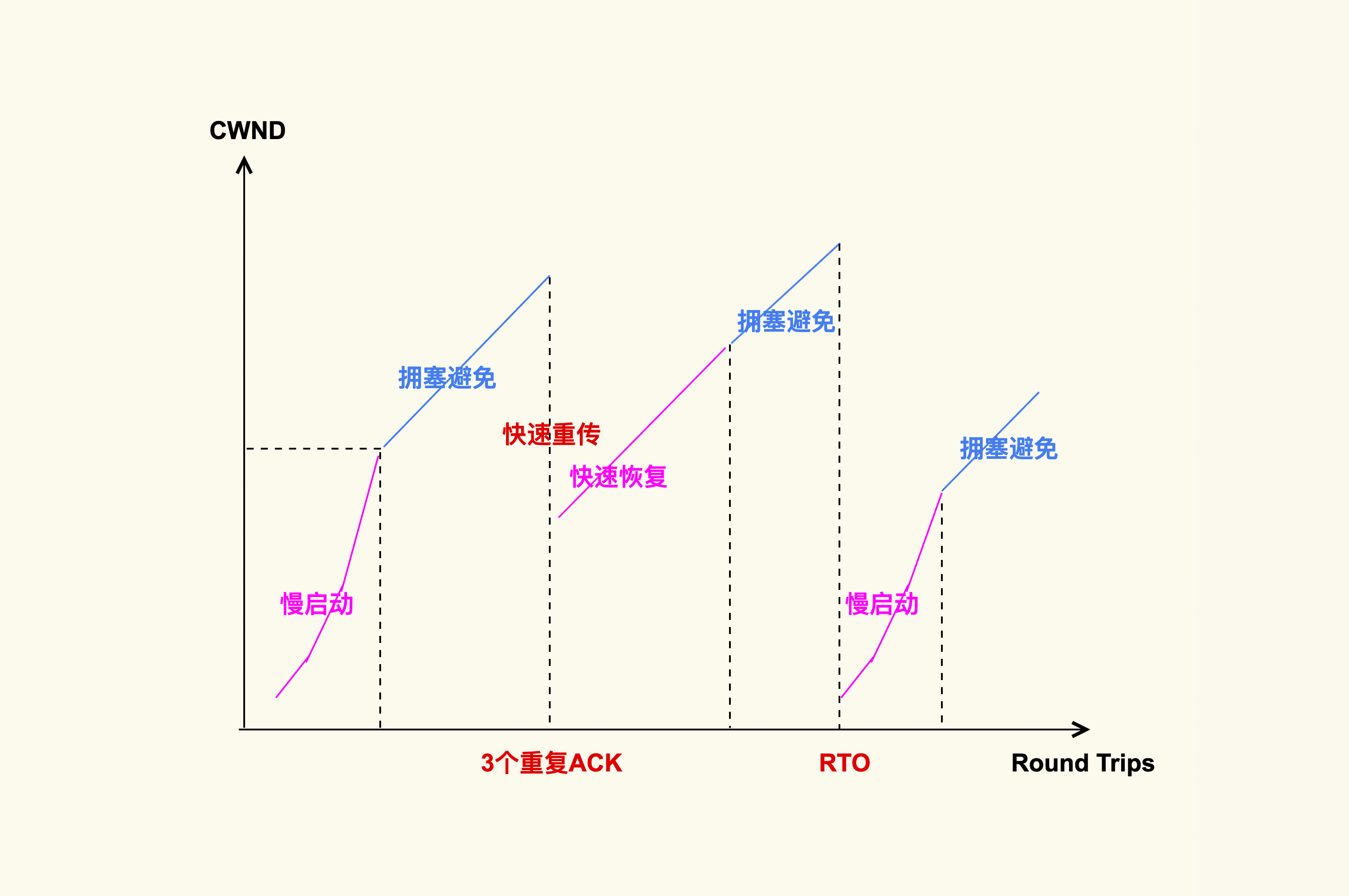
然而加性增窗的特性决定了 reno 存在一个明显缺点:如果算法进入拥塞避免与快速恢复状这两个阶段时,每经过一个 RTT 才会将窗口大小加1,假设我们链路状况好,但如果RTT很长的话,reno 需要很长时间才能达到 Wbest。实际上受限于丢包率,reno 的另一个典型问题就是还没等 cwnd 增长到 Wbest,就已经发生丢包并削减cwnd了。
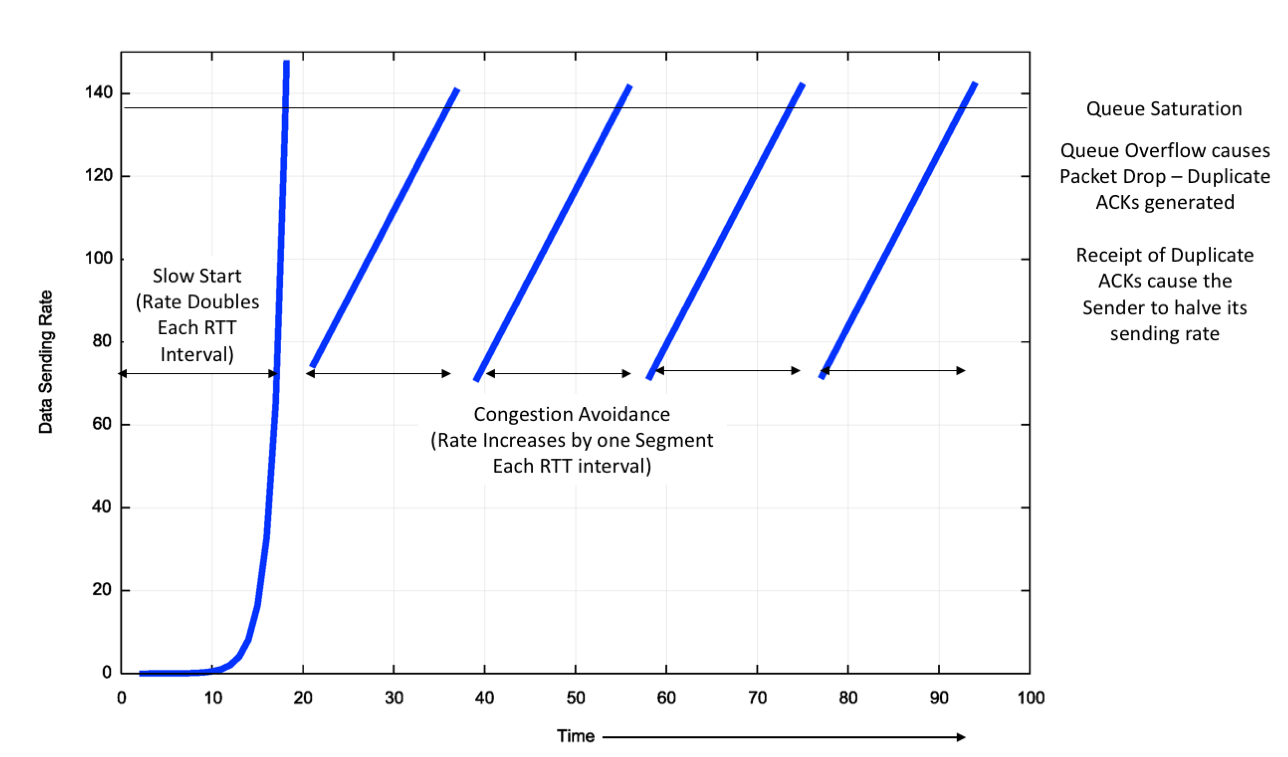
BIC 算法
为了提高 TCP 在 LFN 上的传输效率,后续提出了 bic 拥塞算法:

bic 也采用乘法减小的方式减小窗口,并引入一个参数 β 作为减窗因子。若发生丢包时的 cwnd 大小为 Wmax,则减小后的窗口大小为 W = β * Wmax。
bic 假定 W < Wbest < Wmax,因此在恢复阶段 bic 是一个变速过程:
- 在远离 Wmax 时,快速增大窗口,使 cwnd 尽快恢复至 Wbest(对应图中的
Addtitive Increase过程) - 在靠近 Wmax 时,缓慢增大窗口,使 cwnd 尽可能长期保持在 Wbest 附近(对应图中的
Binary Search过程) - 当到达 Wmax 时,如果仍未发生丢包,那么网络是空闲的,应该积极地去抢占网络资源。此时 TCP 连接会尝试增加拥塞窗口大小,并且增加速度越来越快,直到发现新的 Wmax 为止(对应图中的
Max Probing过程)
CUBIC 算法
然而在 RTT 较小的非 LFN 环境中,bic 的增长策略显得过于激进,会抢占其他其他拥塞算法的 TCP 连接资源。后来,该算法的作者提出了普适性更好的 cubic 算法。
为了减少 RTT(受物理设备影响)对算法的影响,cubic 会记录最近一次发生网络拥塞的时间 treduce,距离最近一次拥塞发生的时间可以表示为 t = tnow - treduce。
cubic 的减窗与增窗过程可以简化为一个的与时间 t 为自变量的窗口增长函数 W(t):

cubic 的窗口增长函数仅仅取决于与拥塞事件的时间间隔,从而将窗口增长独立于网络的时延RTT,因而能够在多条共享瓶颈链路的 TCP 连接之间保持良好的RTT公平性。
cubic 与 reno 的拥塞窗口行为比较:
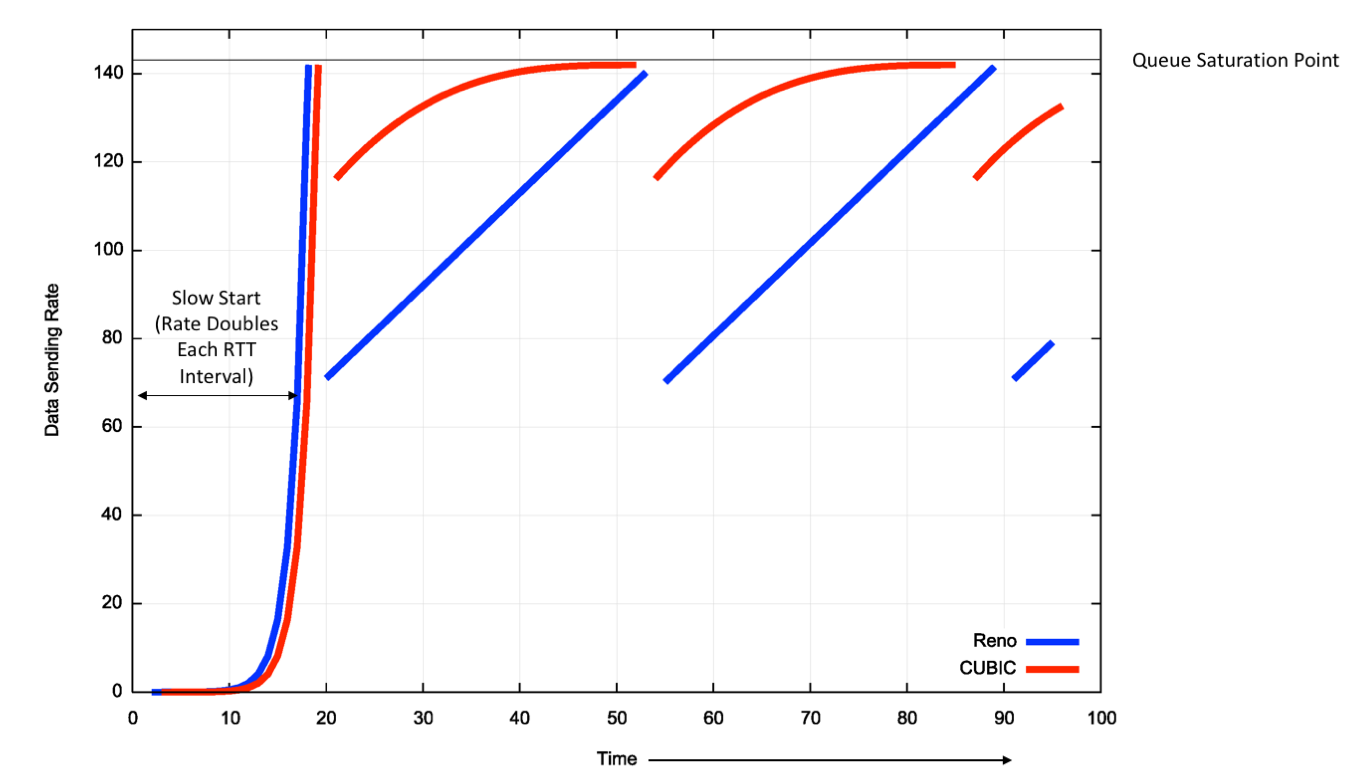
cubic 保证了 TCP 尽可能的长时间保持在 Wbest,从而避免了 reno 算法漫长增窗过程导致传输效率低下的问题。
Bufferbloat 现象
随着内存越来越便宜,TCP 链路上的网络设备的 Buffer 倾向于配置的特别大。但这一做法对于基于丢包反馈的 TCP 拥塞算法相当不友好:

- 发送方无法及时感知到拥塞:当数据开始在队列排队时,链路已经出现拥塞,但因为 Buffer 很大,数据包不会被丢弃,发送端根本无法感知到拥塞的发生。
- 无效的数据包占用网络资源:等真的出现丢包时候,重传的包放在链路上还得等之前积压在 Buffer 的数据包都送达接收端后才能被处理,对网络网络资源造成了浪费。
- 接收方队头阻塞并丢弃数据:接收端在等待重传的过程中,如果 Buffer 不足够大,大量数据送达接收端后都会被丢弃,无形中增加了重传率,极大增加传输延迟。
Bufferbloat 造成的高重传率,无形中增加了网络传输的延迟,并且还会导致网络传输不稳定,有时候延迟很小,有的时候延迟又很大。这一表现正好符合我们之前的 iperf3 的测试结果:
- 较长的 RTT 导致网络非拥塞时频繁丢包,基于丢包反馈的拥塞算法的窗口会比较小,对带宽的利用率很低,吞吐量下降很明显,但是实际上网络负载并不高。
- 在网络拥塞但无丢包情况下算法一直加窗,丢包事件很快就发生了,乘性减窗使发送速率迅速降低,造成整个网络的瞬时抖动性,总体呈现较大的锯齿状波动。
基于传输时延
下图是 TCP 传输链路上某个缓存队列,根据网络状况变化,队列可能处于以下 3 种状态之一:
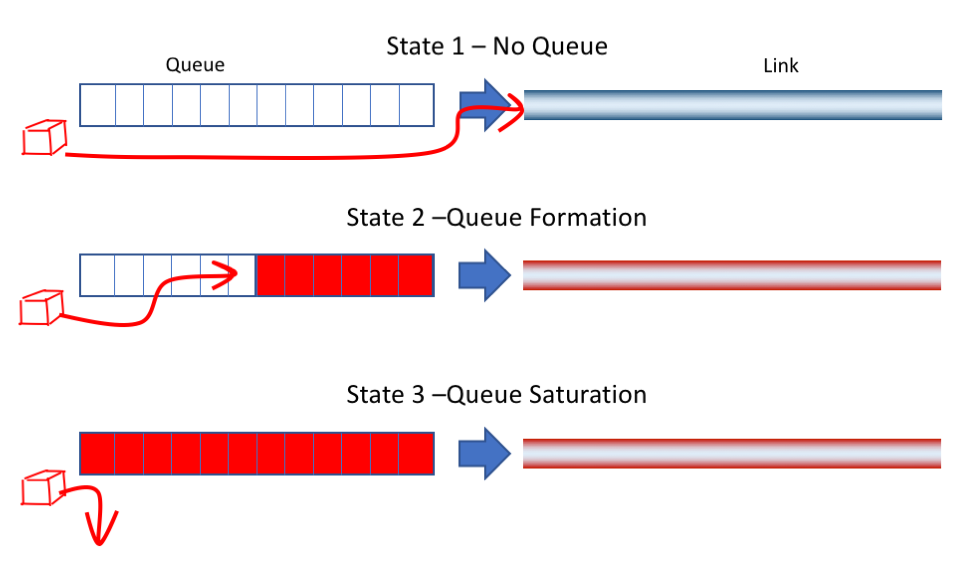
- State 1: 网络空闲,没有排队的数据。网络延迟最低
- State 2: 网络占满,数据开始排队,网络延迟开始增大
- State 3: 队列溢出,网络出现丢包
cubic 的拥塞避免策略是让拥塞窗口尽可能保持在上一个 Wmax 附近,即 State 2 与 State 3 之间的状态。相当于尽可能把链路资源(线路带宽+中继Buffer)占满,也因此造成了较高的网络延迟。
而理想状态是维持在 State 1 和 State 2 之间,即没有出现排队导致延迟升高,又能完全占满链路带宽发送数据,高效且低延迟。为了实现这一点,需要使用 基于传输时延 的拥塞避免算法:
- 速率提高后 RTT 不变(无需排队),则此时链路处于 State 1,可以继续提高发送速率
- 速率提高后 RTT 升高(开始排队),说明此时链路从 State 1 切换到了 State 2,需要降低发送效率,使其恢复到 State 1
最优控制点
下面通过一张图直观地感受一下网络拥塞的变化过程:

- RTprop
round-trip propagation time:链路固有的传播时延 - BtlBw
bottleneck bandwidth:链路的带宽上限 - Amount Inflight:在途数据量
- Delivery Rate:数据送达速率
横向将网络状态分为 3 个阶段:
- app limited:性能瓶颈是应用本身(网络空闲)
- bandwidth limited:性能瓶颈是网络带宽(网络拥塞)
- buffer limit:性能瓶颈是中继 buffer 容量(网络耗尽)
纵向两幅图分别描绘了网络延迟与吞吐量的变化:
-
上图展示了 RTT 与 在途数据量 的之间的关系:
- app limited:网络空闲时,RTT 大小仅取决于 线路 RTprop
- bandwidth limited:网络拥塞时,RTT 大小取决于 网络带宽 BtlBw 与 buffer 数据量(BtlBw限制了队列的消费速率)
- buffer limit:网络资源耗尽,开始丢包
-
下图展示了 送达率 与 在途数据量 的之间的关系:
- app limited:网络空闲时,送达速率取决于 应用发送速率 与 线路 RTprop(RTprop限制了ACK响应速率)
- bandwidth limited:网络拥塞时,送达速率仅取决于 网络带宽 BtlBw
- buffer limit:网络资源耗尽,开始丢包
注意图中的两个点:
- 最优点
optimum operating point is here:理想的拥塞算法应该将在途数据量控制在 BDP 附近。 - 丢包点
loss-based congestion control opreates here:基于丢包的拥塞算法将在途数据量控制在 BDP + BtlneckBufSize 附近。
在最优点附近,发送速率达到 BltBw,从而占满链路带宽,最高效的利用带宽;在途数据量不超过链路的 BDP = BtlBw * RTprop,从而有最优的延迟。
当链路上 Buffer 较小时,最优点与丢包点十分接近,此时基于丢包的算法延迟就不会很高。当链路上 Buffer 很大时,基于丢包的拥塞算法就容易导致将 Buffer 占满,就容易出现 BufferBloat。
反过来说,如果链路的 BtlBw 与 RTprop 已知,那么拥塞控制算法就可以根据这两个值,计算得出最优的发送速率 BDP。这也为拥塞算法的开发提供了新的思路。
BBR 算法
bbr 是 Google 开源的拥塞算法,其目的就是为了解决基于丢包的拥塞控制算法存在的弊端:
- 在 Buffer 较大的链路中,容易造成 BufferBloat,增加了传输延迟
- 在 Buffer 较小的长距离链路中,会对突发流量造成的丢包反应过度,导致吞吐量极低
其核心理念就是建立一套探测模型,动态评估链路上 BtlBw 与 RTprop 的变化情况:
- 将最近一个时间窗口 WR(一般是在几十秒到几分钟之间)内监控到的 RTT 最小值作为近似的 RTprop
- 将最近一个时间窗口 WB(一般是 10 个 RRT)内监控到的 送达率 最大值作为近似的 BtlBw
bbr 算法可以分为 4 个阶段:

StartUp
bbr以指数形式增大发送速率,每经过一个 RTT 发送速率会增大 $2/ln(2)$ 倍,从而保证能够在 O(log(BDP)) 个 RRT 内找到 BtlBw。
当bbr发现增大速率后,送达率没有明显上升时,会认为链路上的 Buffer 已经开始积压,于是认为已经探测到 BtlBw。
Drain
bbr会监控在途数据量 Inflight,当 Inflight 与估计的 BDP 接近时,会进入稳定状态。
ProbeBW
bbr的主要阶段。
ProbeBW 状态分为两个周期:
- 增周期:提高发送率到稳定期的 1.25 倍,直到出现丢包或 Inflight 达到 1.25 倍 BDP 为止。如果观察到延迟升高且送达率不变,说明链路上带宽没有变化且产生了队列堆积。
- 减周期:降低发送率到稳定期的 0.75 倍,等待一个 RTprop 或 Inflight低于 BDP 为止。让链路上在增周期出现堆积的队列清空。
ProbeRTT
bbr运行了很长时间一直没有更新 RTprop 时,会进入 ProbeRTT 状态并试图探测到更小 RTprop。探测完成之后再根据最新数据来确定进入 StartUp 还是 ProbeBW 阶段。
cubic、reno 与 bbr 的拥塞窗口行为比较:
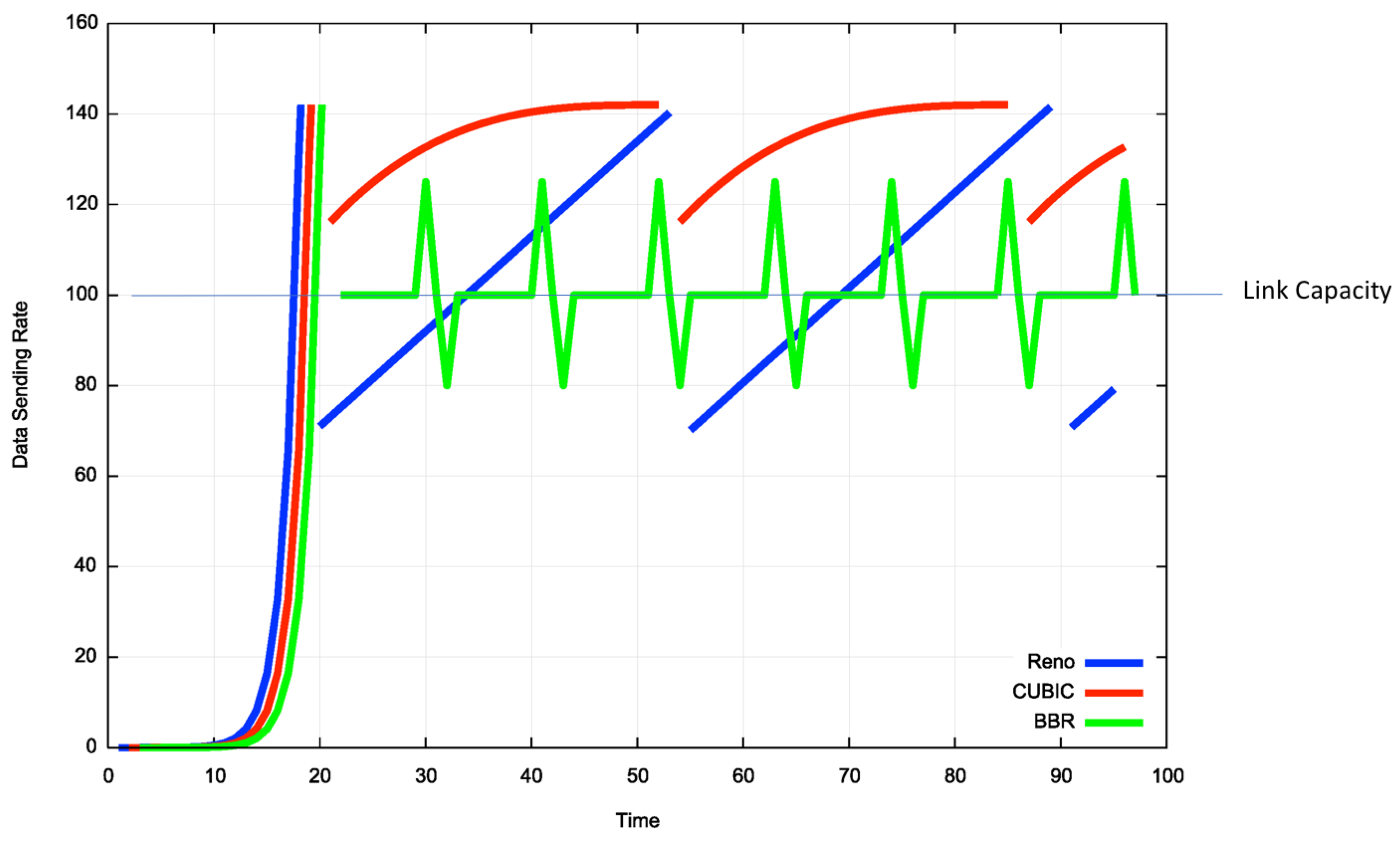
bbr 保证了 TCP 尽可能的长时间保持对网络的 100% 的利用率,规避了 cubic 过分占用网络资源引起 Bufferbloat 现象。
此外,由于 bbr 算法本身不依赖于丢包反馈,因此在高丢包率的网络下的表现明显优于 cubic。

优化效果
经过前面的分析,发现 bbr 算法对于正好能够解决之前 ipref3 测试中发现的问题。于是跟运维同时协商将 CentOS6 升级为高内核版本的 CentOS7,并开启 bbr 算法:
[lhop@localhost ~]$ sysctl -a 2>&1 | egrep 'tcp_available_congestion_control|tcp_congestion_control|default_qdisc'
net.core.default_qdisc = fq
net.ipv4.tcp_available_congestion_control = reno cubic bbr
net.ipv4.tcp_congestion_control = bbr
再次使用 iperf3 进行测试,结果如下:
Connecting to host US_NY_VM_01, port 5001
[ 4] local HK_QW_VM_01 port 58341 connected to US_NY_VM_01 port 5001
[ ID] Interval Transfer Bandwidth Retr Cwnd
[ 4] 0.00-1.00 sec 740 KBytes 6.06 Mbits/sec 0 97.6 KBytes
[ 4] 1.00-2.00 sec 4.17 MBytes 35.0 Mbits/sec 0 1.89 MBytes
[ 4] 2.00-3.00 sec 12.5 MBytes 105 Mbits/sec 0 8.76 MBytes
[ 4] 3.00-4.00 sec 13.8 MBytes 115 Mbits/sec 0 8.79 MBytes
[ 4] 4.00-5.00 sec 11.2 MBytes 94.4 Mbits/sec 3 8.79 MBytes
[ 4] 5.00-6.00 sec 13.8 MBytes 115 Mbits/sec 0 8.79 MBytes
[ 4] 6.00-7.00 sec 15.0 MBytes 126 Mbits/sec 0 8.79 MBytes
[ 4] 7.00-8.00 sec 12.5 MBytes 105 Mbits/sec 0 8.79 MBytes
[ 4] 8.00-9.00 sec 13.8 MBytes 115 Mbits/sec 0 8.79 MBytes
[ 4] 9.00-10.00 sec 13.8 MBytes 115 Mbits/sec 0 8.79 MBytes
[ 4] 10.00-11.00 sec 13.8 MBytes 115 Mbits/sec 0 8.79 MBytes
[ 4] 11.00-12.00 sec 12.5 MBytes 105 Mbits/sec 0 8.79 MBytes
[ 4] 12.00-13.00 sec 15.0 MBytes 126 Mbits/sec 0 8.79 MBytes
[ 4] 13.00-14.00 sec 8.75 MBytes 73.4 Mbits/sec 0 8.79 MBytes
[ 4] 14.00-15.00 sec 15.0 MBytes 126 Mbits/sec 0 8.79 MBytes
[ 4] 15.00-16.00 sec 12.5 MBytes 105 Mbits/sec 0 8.79 MBytes
[ 4] 16.00-17.00 sec 13.8 MBytes 115 Mbits/sec 0 8.79 MBytes
[ 4] 17.00-18.00 sec 13.8 MBytes 115 Mbits/sec 0 8.79 MBytes
[ 4] 18.00-19.00 sec 13.8 MBytes 115 Mbits/sec 0 8.79 MBytes
[ 4] 19.00-20.00 sec 12.5 MBytes 105 Mbits/sec 0 8.79 MBytes
[ 4] 20.00-21.00 sec 15.0 MBytes 126 Mbits/sec 0 8.79 MBytes
[ 4] 21.00-22.00 sec 13.8 MBytes 115 Mbits/sec 0 8.79 MBytes
[ 4] 22.00-23.00 sec 12.5 MBytes 105 Mbits/sec 0 8.79 MBytes
[ 4] 23.00-24.00 sec 11.2 MBytes 94.4 Mbits/sec 3 8.79 MBytes
[ 4] 24.00-25.00 sec 11.2 MBytes 94.4 Mbits/sec 0 7.44 MBytes
[ 4] 25.00-26.00 sec 11.2 MBytes 94.4 Mbits/sec 0 6.30 MBytes
[ 4] 26.00-27.00 sec 12.5 MBytes 105 Mbits/sec 0 6.30 MBytes
[ 4] 27.00-28.00 sec 11.2 MBytes 94.4 Mbits/sec 0 6.30 MBytes
[ 4] 28.00-29.00 sec 12.5 MBytes 105 Mbits/sec 0 6.30 MBytes
[ 4] 29.00-30.00 sec 11.2 MBytes 94.4 Mbits/sec 0 6.30 MBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-30.00 sec 365 MBytes 102 Mbits/sec 6 sender
[ 4] 0.00-30.00 sec 364 MBytes 102 Mbits/sec receiver
iperf Done.
观察测试结果发现网络的吞吐量明显上升,并且重传率保持在一个较低的水平。
并且拥塞窗口变化也更稳定,不再出现之前剧烈波动的情况。
使用 10 个 socket 基本上可以跑满整个专线,优化目标达成。
附录
在丢包率较高的网络中,调整 TCP 参数并不能起到很好的效果。但着这并不意味着 TCP 调参没有意义。
某个服务在同机房内,单个 TCP 连接流量能达到 80M,但在 RTT 1.5ms 且无丢包的跨机房网络环境上,突发流量峰值最多只能达到 60M 且不稳定。我们尝试通过调参,将 TCP 传输峰值较好地稳定在 70M 左右:
调整前:
[lhop@localhost ~]$ sysctl -a 2>&1 | egrep 'net.core.[r|w]mem_|net.ipv4.tcp_[r|w]*mem|tcp_adv_win_scale'
net.core.rmem_default = 212992
net.core.wmem_default = 212992
net.core.rmem_max = 212992
net.core.wmem_max = 212992
net.ipv4.tcp_mem = 765918 1021224 1531836
net.ipv4.tcp_rmem = 4096 87380 6291456
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.tcp_adv_win_scale = 1
调整后:
[lhop@localhost ~]$ sysctl -a 2>&1 | egrep 'net.core.[r|w]mem_|net.ipv4.tcp_[r|w]*mem|tcp_adv_win_scale'
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 65536
net.core.wmem_default = 65536
net.ipv4.tcp_mem = 4096 87380 4194304
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.ipv4.tcp_adv_win_scale = 2
可以看到,对于大流量的 TCP 传输通道,调整参数仍然能显著提升跨机房传输质量。
但想要获得一组适合的参数,需要依赖大量的测试才能获得。很多时候还是得靠业务设计来规避这类问题。
参考资料与图片来源
- https://blog.csdn.net/zhangskd/article/details/6715751
- https://blog.csdn.net/zk3326312/article/details/91375314
- https://blog.csdn.net/dog250/article/details/81393009
- https://blog.csdn.net/m0_37055174/article/details/102548937
- https://blog.csdn.net/c359719435/article/details/8815499
- https://zhuanlan.zhihu.com/p/64797781
- https://www.cnblogs.com/lshs/p/6038663.html
- https://www.sohu.com/a/388805449_100081454
- https://nextfe.com/tcp-congestion-control
- https://blog.apnic.net/2017/05/09/bbr-new-kid-tcp-block/
- https://www.cs.princeton.edu/courses/archive/fall16/cos561/papers/Cubic08.pdf
- https://wiki.untangle.com/index.php/Bufferbloat
- https://web.cs.wpi.edu/~claypool/papers/bbr-prime/claypool-final.pdf
- https://aws.amazon.com/cn/blogs/china/talking-about-network-optimization-from-the-flow-control-algorithm/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号