
数据采集与融合技术实践--作业四
数据采集与融合技术作业四
📌1.相关信息及链接
| 名称 | 信息及链接 |
|---|---|
| 学号姓名 | 102202108 王露洁 |
| 本次作业要求链接 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13288 |
| 作业①所在码云链接 | https://gitee.com/wanglujieeee/crawl_project/tree/master/作业4.1 |
| 作业②所在码云链接 | https://gitee.com/wanglujieeee/crawl_project/tree/master/作业4.2 |
| 作业③所在码云链接 | 无 |
📝2.作业内容
作业①:
✒️要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。 候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
🗃️MySQL数据库存储和输出格式如下: 表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计

🚀解决思路及代码实现
第一步,打开终端,连接数据库,切换到stock_data数据库,创建stock_2表,这里忘记插入序号列,后面又补上了。
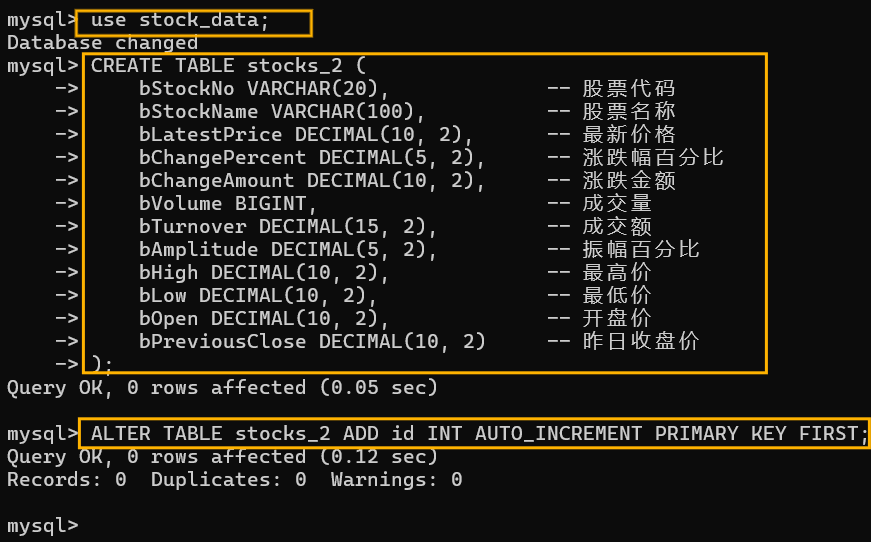
这里首先进行一些必要的库的导入和数据库的连接:
# 导入所需的库
from selenium import webdriver # 用于网页自动化控制的库
from selenium.webdriver.common.by import By # 用于定位页面元素的类
from selenium.webdriver.support.ui import WebDriverWait # 用于等待页面元素加载的类
from selenium.webdriver.support import expected_conditions as EC # 用于等待页面元素加载的条件
import mysql.connector # 用于连接MySQL数据库的库
import time # 用于时间处理的库
# 数据库连接设置
db_config = {
'user': 'root',
'password': '*********',#密码保密
'host': 'localhost',
'database': 'stock_data'
}
下面是一个init_db()函数用于初始化数据库连接,和一个insert_data()函数用于向数据库插入数据:
# 初始化数据库连接
def init_db():
conn = mysql.connector.connect(**db_config) # 创建数据库连接
cursor = conn.cursor() # 创建游标对象
return conn, cursor # 返回连接对象和游标对象
# 插入数据到数据库
def insert_data(cursor, conn, data):
sql = """
INSERT INTO stocks_2 (
bStockNo, bStockName, bLatestPrice, bChangePercent, bChangeAmount,
bVolume, bTurnover, bAmplitude, bHigh, bLow, bOpen, bPreviousClose
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
cursor.execute(sql, data) # 执行SQL插入语句
conn.commit() # 提交事务
接着是进行selelnium的配置:
# 配置 Selenium
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 设置无头模式,不打开浏览器界面
driver = webdriver.Chrome(options=options) # 创建Chrome浏览器实例
wait = WebDriverWait(driver, 10) # 设置等待时间为10秒
这个clean_decimal()函数跟上次一样,主要就是进行数据清洗,便于后续插入:
# 处理浮点数转换的函数
def clean_decimal(value):
if not value:
return None
value = value.strip().replace(',', '') # 去除空格和逗号
try:
if '%' in value:
return float(value.replace('%', '')) / 100 # 处理百分比
elif '亿' in value:
return float(value.replace('亿', '')) * 1e8 # 处理亿
elif '万' in value:
return float(value.replace('万', '')) * 1e4 # 处理万
return float(value) # 直接转换为浮点数
except ValueError:
return None # 转换失败返回None
下面是包含整个爬取数据的逻辑的函数scrape_data():
先创建了一个列表用于存储数据;
使用显示等待机制等待表格出现后使用xpath的方法定位到表格的所有行;
遍历每一行,获取每一行的每一个单元格并在清洗后赋值给相应的变量;
所有变量打包成一个元组,然后打印出来(可选),再插入到一开始创建的列表中;
最终返回一个数据列表,列表中包含该页面整个表格的我们所选择的数据。
# 爬取数据的函数
def scrape_data():
stock_data = [] # 初始化存储数据的列表
# 等待表格加载并找到所有行
wait.until(EC.presence_of_element_located((By.XPATH, '//table//tr'))) # 等待表格出现
rows = driver.find_elements(By.XPATH, '//table//tr') # 获取表格的所有行
for row in rows:
cols = row.find_elements(By.TAG_NAME, 'td') # 获取每行的所有单元格
if len(cols) >= 14: # 如果单元格数量足够
# 提取并清洗每个单元格的数据
bStockNo = cols[1].text.strip()
bStockName = cols[2].text.strip()
bLatestPrice = clean_decimal(cols[4].text.strip())
bChangePercent = clean_decimal(cols[5].text.strip())
bChangeAmount = clean_decimal(cols[6].text.strip())
bVolume = clean_decimal(cols[7].text.strip())
bTurnover = clean_decimal(cols[8].text.strip())
bAmplitude = clean_decimal(cols[9].text.strip())
bHigh = clean_decimal(cols[10].text.strip())
bLow = clean_decimal(cols[11].text.strip())
bOpen = clean_decimal(cols[12].text.strip())
bPreviousClose = clean_decimal(cols[13].text.strip())
# 将清洗后的数据打包成一个元组
stock_info = (
bStockNo, bStockName, bLatestPrice, bChangePercent, bChangeAmount,
bVolume, bTurnover, bAmplitude, bHigh, bLow, bOpen, bPreviousClose
)
# 打印每条数据
print(stock_info)
# 添加数据到列表中
stock_data.append(stock_info)
return stock_data # 返回数据列表
刚才的爬虫函数一次只能爬取一个页面的数据(即一个版块的数据),而题目要求我们爬取三个板块,这里就要用到下面的函数switch_section();
这个函数可以模拟点击切换版块;
首先用id来找到板块的按钮,再用click()方法进行模拟点击;
最后强制等待页面加载。
# 模拟点击切换板块
def switch_section(section_id):
section_tab = driver.find_element(By.ID, section_id) # 根据ID找到板块切换按钮
section_tab.click() # 点击按钮
time.sleep(3) # 等待页面加载
下面的主函数main()展示了整个爬取和存储过程:
用一个变量存储所要爬取页面的url;
用init_db()函数初始化数据库并获得数据库连接和游标对象;
前面创建的Chrome浏览器实例driver使用get()方法访问目标url;
首先爬取沪深A股板块数据,调用scrape_data()函数即可返回一个包含所有行的数据的列表;
将数据一行一行插入到数据库;
之后切换到上证A股板块,使用的是switch_section()函数,切换成功后就可以按之前的方式爬取和存储数据了,爬取深证A股板块也是类似;
最后关闭游标,数据库和浏览器实例。
# 主函数
def main():
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board" # 目标网页URL
# 连接数据库
conn, cursor = init_db() # 获取数据库连接和游标
try:
# 打开网页
driver.get(url) # 访问目标网页
# 爬取沪深A股板块数据
print("开始爬取沪深A股板块数据...")
hs_data = scrape_data() # 爬取数据
for stock in hs_data:
insert_data(cursor, conn, stock) # 将数据插入数据库
print("沪深A股数据爬取并存储成功!")
# 切换到上证A股板块并爬取数据
print("切换到上证A股板块...")
switch_section("nav_sh_a_board") # 切换到上证A股
sz_data = scrape_data() # 爬取数据
for stock in sz_data:
insert_data(cursor, conn, stock) # 将数据插入数据库
print("上证A股数据爬取并存储成功!")
# 切换到深证A股板块并爬取数据
print("切换到深证A股板块...")
switch_section("nav_sz_a_board") # 切换到深证A股
zx_data = scrape_data() # 爬取数据
for stock in zx_data:
insert_data(cursor, conn, stock) # 将数据插入数据库
print("深证A股数据爬取并存储成功!")
except Exception as e:
print("爬取失败:", e) # 捕获异常并打印
finally:
cursor.close() # 关闭游标
conn.close() # 关闭数据库连接
driver.quit() # 关闭浏览器实例
if __name__ == "__main__":
main() # 运行主函数
🌞运行结果截图
这是控制台的输出(只截了一张):

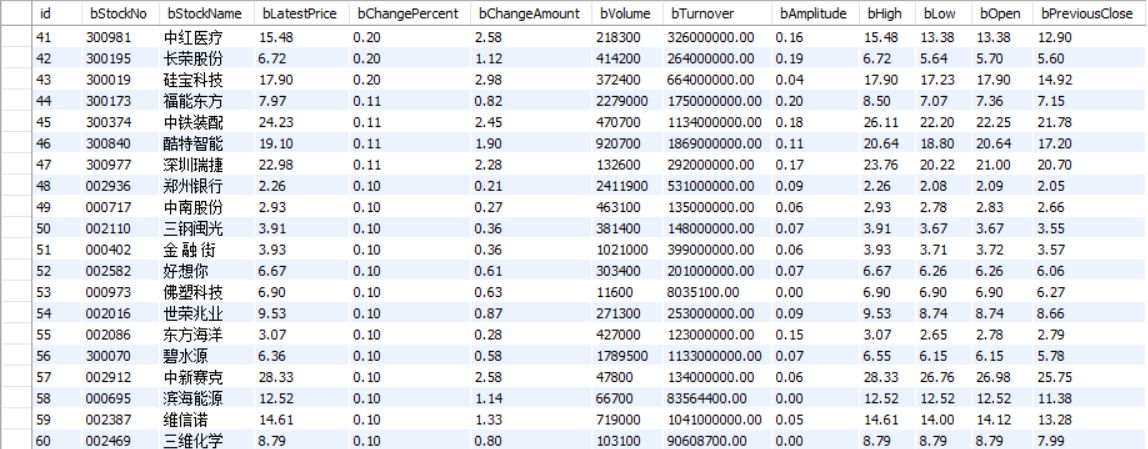
这是插入到数据库的数据:
沪深A股:
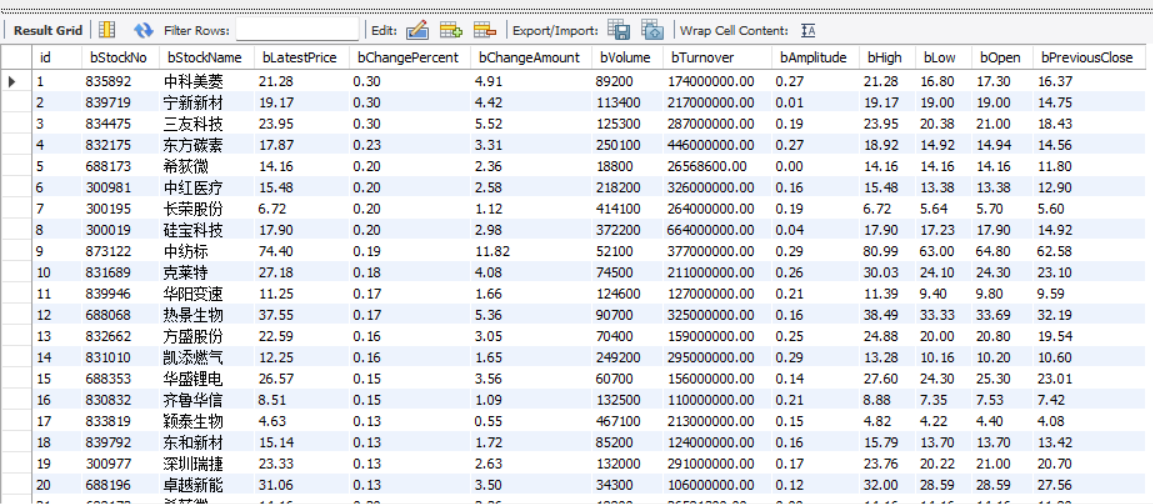
上证A股:

深证A股:
🌈心得体会
-->这个题目上次也有做,只不过上次是使用了selenium+scrapy框架的方式,我觉得这次会比上次稍微简单一些。不同的地方是这里需要进行切换版块然后爬取不同板块的数据,解决方法就是找到页面中版块的位置进行模拟点击的操作来进行板块的切换,重点是点击之后要添加等待机制,不然就会在页面加载不全的时候就开始爬取数据,这样当然会爬取失败。我就是因为网络太慢,一直超时,一直爬取不成功,然后就不停增加等待的时间,最后才爬取成功。而且我发现相同的代码每次运行结果可能会成功也可能会失败,只能说影响爬虫结果的因素太多了。
作业②:
✒️要求:熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)。 候选网站:中国mooc网:https://www.icourse163.org
🗃️MySQL数据库存储和输出格式如下: MYSQL数据库存储和输出格式 Gitee文件夹链接

🚀解决思路及代码实现
下面仅展示一些重要的函数代码:
首先是进行数据库连接和创建表格,这也是比较常规的一个操作了;
# MySQL 配置
db_config = {
'user': 'root',
'password': 'Wlj98192188?',
'host': 'localhost',
'database': 'mooc_data'
}
# 初始化数据库连接
def init_db():
conn = mysql.connector.connect(**db_config)
cursor = conn.cursor()
# 创建表格
cursor.execute("""
CREATE TABLE IF NOT EXISTS courses (
id INT AUTO_INCREMENT PRIMARY KEY,
course_name VARCHAR(255),
school_name VARCHAR(255),
teacher VARCHAR(255),
team_members TEXT,
participants INT,
progress VARCHAR(50),
description TEXT
)
""")
conn.commit()
return conn, cursor
下面是一个具有插入数据功能的函数insert_data():
只有一个要注意的点就是团队成员是一个列表,不能直接插入到sql表格中,所以这里需要多加一个把列表转换成字符串的步骤;
# 插入数据到数据库
def insert_data(cursor, conn, data):
sql = """
INSERT INTO courses (
course_name, school_name, teacher, team_members,
participants, progress, description
) VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
try:
# 将团队成员列表转换为字符串
data = list(data)
if isinstance(data[3], list): # 检查 team_members 是否为列表
data[3] = ', '.join(data[3]) # 使用逗号将成员名拼接成字符串
# 插入数据
cursor.execute(sql, tuple(data))
conn.commit()
print("成功插入一条数据")
except Exception as e:
conn.rollback()
print(f"插入数据失败: {e}")
配置selenium(可能加了很多有的没的):
# 配置 Selenium
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无头模式
driver = webdriver.Chrome(options=options)
wait = WebDriverWait(driver, 40)
driver.set_page_load_timeout(120) # 设置页面加载超时时间
options.add_argument('--disable-gpu') # 禁用 GPU 加速
options.add_argument('--no-sandbox') # 禁用沙盒模式
options.add_argument('--disable-dev-shm-usage') # 禁用共享内存
options.add_argument('--disable-extensions') # 禁用扩展
下面这是一个模拟用户登录的函数login():
首先driver对象访问界面的url,使用浏览器开发者工具找到登录按钮所在的标签位置,然后进行点击操作;
点击登录之后,会跳出一个登录框,我们要在这个登录框上定位到手机号和密码的输入框,然后使用send_keys()方法模拟输入;
结果你会发现不管怎样都定位不到输入框,那是因为登录框在该网页的内嵌框架(iframe)里,我们需要切换到这个iframe内部才能与其中的元素进行交互,这里使用switch_to.frame()的方式;
输入信息之后点击登录按钮,我们将 WebDriver 的焦点从当前活动的 iframe 切换回最外层的文档,以重新获得对主文档的访问权限,这里使用switch_to.default_content();
最后注意这里每进行一步,都要模拟等待,因为页面跳转,加载等等都需要时间,搞不好就会出错。
我这里还使用 driver.maximize_window() 方法将浏览器窗口最大化,以便能够完整地看到页面上的所有元素。
# 模拟登录
def login():
url="https://www.icourse163.org"
driver.get(url)
login = driver.find_element(By.CLASS_NAME, "_3uWA6") # 查找登录按钮
login.click() # 点击登录按钮
log=driver.find_element(By.TAG_NAME,"iframe")
driver.switch_to.frame(log) # 切换到登录框
WebDriverWait(driver, 15, 0.5).until(
EC.presence_of_element_located((By.XPATH, "//*[@id='login-form']/div"))) # 等待登录框加载
username = driver.find_element(By.XPATH, "//input[@id='phoneipt']")
username.send_keys("18120958838") # 输入用户名
time.sleep(2)
password = driver.find_element(By.XPATH, "//input[@type='password' and @name='email' and contains(@class, 'j-inputtext')]")
password.send_keys("wlj98192188") # 输入密码
time.sleep(2)
button = driver.find_element(By.XPATH, "//*[@id='submitBtn']")
button.click() # 点击登录按钮
time.sleep(2)
driver.switch_to.default_content()
time.sleep(5)
driver.maximize_window()
time.sleep(3)
print("登录成功,准备爬取课程信息...")
接着是爬取课程列表的一个主要的函数scrape_courses(),因为一开始出了很多错误,所有我加了很多打印语句用来调试,由于比较长,我把它分成了两个部分来分析:
这个部分的大致功能就是模拟滑动条的滚动,来找到课程列表所在的位置(因为该页面内容很多,只有向下滑动之后才能看到课程列表,也是只有列表可见之后才方便我们进行操作);
前面先是初始化数据库,因为后面我是采用边爬取数据边存储的方式进行的;
然后创建一个存储课程数据的列表;
紧接着定义一些常量:每次滚动后的等待时间,最大滚动次数和滚动尝试次数,方便后面直接使用;
用一个循环来完成一次次的滑动,只要滚动次数不超过最大次数,就会一直执行;
检查目标元素(这是课程列表)是否加载到页面,如果已经定位到,就执行:driver.execute_script("arguments[0].scrollIntoView(true);", target_element)滚动到目标元素;
这里execute_script 是 WebDriver 提供的一个方法,用于在当前页面上执行任意的 JavaScript 代码;
arguments[0].scrollIntoView(true) 是要执行的 JavaScript 代码字符串。这里,arguments[0] 是传递给 execute_script 方法的第一个参数(在这个例子中是 target_element),它代表页面上的一个元素。scrollIntoView 是该元素的一个方法,用于将该元素滚动到浏览器的可视区域内。true 参数表示在滚动时,如果元素不在视图中,则尽可能平滑地滚动,并尝试将元素的顶部与其最近的滚动祖先的可视区域的顶部对齐。
如果目标元素尚未加载,则继续滚动,使用execute_script("window.scrollBy(0, 800);"),每次向下滚动 800 像素;
最后滚动次数达到上限就会退出这个循环。
# 爬取课程列表并进入每个课程的详情页
def scrape_courses():
# 初始化数据库
conn, cursor = init_db()
print("开始!")
course_data_list = []
scroll_pause_time = 1 # 每次滚动后的等待时间
max_scroll_attempts = 50 # 最大滚动次数,防止无限循环
scroll_attempts = 0
while scroll_attempts < max_scroll_attempts:
try:
# 检查目标元素是否加载到页面
target_element = driver.find_element(By.XPATH, "//div[@class='_15K5J']")
print("已经定位到目标元素")
# 滚动到目标元素
driver.execute_script("arguments[0].scrollIntoView(true);", target_element)
print("已经滚动到目标元素")
time.sleep(2) # 等待加载
break
except Exception:
# 如果目标元素尚未加载,则继续滚动
driver.execute_script("window.scrollBy(0, 800);") # 每次向下滚动 800 像素
time.sleep(scroll_pause_time)
# 增加滚动尝试次数
scroll_attempts += 1
print(f"滚动尝试次数:{scroll_attempts}")
# 如果滚动尝试达到最大次数,退出并报告
if scroll_attempts >= max_scroll_attempts:
print("已滚动多次仍未找到目标元素,退出")
这是函数的后半部分,主要作用就是进行每个课程详情数据的爬取,其中调用了后面写的一个函数scrape_course_details(driver)来进行具体数据的爬取;
首先就是定位到该页面所有的课程并存储成一个列表,然后对列表的每一个元素进行遍历:同样这里先滚动滑动条到可视区,再进行点击;
由于点击之后会打开一个新的窗口或标签页,所以我们需要确保这个新窗口或标签页确实已经打开,然后再进行下一步操作,这里用EC.number_of_windows_to_be(2)是等待打开的窗口数量达到2个;
这时我们使用driver.switch_to.window() 方法切换浏览器窗口,类似于登录那边用到的switch_to.frame()方法切换网页的内外层框架,这里是切换标签页;
其参数driver.window_handles 是一个属性,它返回当前会话中所有打开的窗口(或标签页)的句柄列表,因为Python中的列表索引是从0开始的,而 -1 表示列表中的最后一个元素。因此,driver.window_handles[-1] 将返回最近打开的窗口的句柄。
切换到课程详情页,调用scrape_course_details()函数,该函数会返回所爬取的课程数据,如果非空,就使用insert_data()函数将其插入到数据库表格中;
每爬取完一门课程,就要关闭该课程详情页,再退回到课程列表。driver.close() 方法用于关闭当前活动的浏览器窗口(或标签页),这不会关闭整个浏览器应用程序,只是关闭当前正在与之交互的窗口。而需要注意区分driver.quit() 方法用于关闭所有与当前WebDriver会话相关联的窗口,并结束WebDriver进程。
返回课程主页就用switch_to.window(driver.window_handles[0]),索引为0表示第一个标签页;
页面切换仍然要进行等待,为了以防万一再重新获取课程列表,就这样遍历完所有课程卡片。
# 找到课程卡片
course_cards = wait.until(EC.presence_of_all_elements_located((By.XPATH, "//div[@class='_2mbYw commonCourseCardItem']")))
print("已经找到多张课程卡片")
for i, card in enumerate(course_cards):
try:
# 将课程滚动到可视区域并点击
driver.execute_script("arguments[0].scrollIntoView();", card)
time.sleep(2)
card.click()
# 等待新窗口/标签页打开
WebDriverWait(driver, 10).until(EC.number_of_windows_to_be(2))
driver.switch_to.window(driver.window_handles[-1])
print("已切换到课程详情页。")
# 点击课程卡片进入详情
time.sleep(10) # 等待页面加载
# 解析课程详情数据
course_data = scrape_course_details(driver)
if course_data:
# 插入数据到数据库
insert_data(cursor, conn, (
course_data['course_name'],
course_data['school_name'],
course_data['teacher'],
course_data['team_members'],
course_data['participants'],
course_data['progress'],
course_data['description']
))
print("已成功存储一条数据!")
# 关闭详情页并返回主页面
driver.close()
driver.switch_to.window(driver.window_handles[0])
print("已返回主课程页面。")
time.sleep(5) # 等待页面加载
# 重新获取课程列表
course_cards = wait.until(EC.presence_of_all_elements_located((By.XPATH, "//div[@class='_2mbYw commonCourseCardItem']")))
except StaleElementReferenceException:
print("捕获到 StaleElementReferenceException,重新加载课程列表")
if len(driver.window_handles) > 1:
driver.close()
driver.switch_to.window(driver.window_handles[0])
return course_data_list
下面就是具体的爬取课程数据的细节函数scrape_course_details(driver),也是比较长,其中也包括了页面滚动操作(因为教师和团队信息在页面下方,只有滚动之后才能可视和爬取);
我设了多重等待机制,因为有时候页面加载完成但是课程详情可能还没能完全加载,也容易让我们爬取失败;
后面是使用XPATH的方法来获取课程名,学校名,参与人数,课程进度,课程简介;进行页面滚动后再来获取教师名,团队成员;
所有的标签都是要打开浏览器开发者工具进行查看和分析的,最后返回课程数据;
这里主要就是要注意团队成员的元素是多个值,需要提取每个团队成员的名字形成一个列表,再返回;
def scrape_course_details(driver):
try:
# 确保页面完全加载
WebDriverWait(driver, 30).until(
lambda d: d.execute_script('return document.readyState') == 'complete'
)
print("页面完全加载完成")
# 等待课程详情部分加载
WebDriverWait(driver, 30).until(
EC.visibility_of_element_located((By.XPATH, "//div[@id='g-body']"))
)
print("课程详情加载完成")
# 1. 获取课程名
try:
course_name_element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located(
(By.XPATH, "//span[@class='course-title f-ib f-vam']")
))
course_name = course_name_element.text
except TimeoutException:
course_name = "未知课程"
print(f"课程名: {course_name}")
# 2. 获取学校名
try:
school_name = driver.find_element(By.XPATH,"//div[@class='m-teachers']//a[@class='ga-click m-teachers_school-img f-ib']/img").get_attribute("alt")
except Exception:
school_name = "未知学校"
print(f"学校名: {school_name}")
# 3. 获取参与人数
try:
participants_element = driver.find_element(By.XPATH, "//span[@class='count']")
participants_text = participants_element.text if participants_element else "0"
participants = int("".join(filter(str.isdigit, participants_text)))
except Exception:
participants = 0
print(f"参与人数: {participants}")
# 4. 获取课程进度
try:
progress_element = driver.find_element(By.XPATH, "//span[@class='text']")
progress = progress_element.text if progress_element else "未知进度"
except Exception:
progress = "未知进度"
print(f"课程进度: {progress}")
# 5. 获取课程简介
try:
description_element = driver.find_element(By.XPATH, "//div[@class='course-heading-intro_intro']")
description = description_element.text if description_element else "暂无简介"
except Exception:
description = "暂无简介"
print(f"课程简介: {description}")
# 滚动查找目标元素
scroll_attempts = 0
max_scroll_attempts = 10 # 最大滚动次数
scroll_pause_time = 2 # 每次滚动后的等待时间
while scroll_attempts < max_scroll_attempts:
try:
# 尝试查找目标元素
target_element = driver.find_element(By.XPATH, "//div[@class='m-teachers_teacher-list']")
print("找到教师信息元素!")
# 滚动到目标元素
driver.execute_script("arguments[0].scrollIntoView(true);", target_element)
print("已经滚动到教师信息位置")
time.sleep(scroll_pause_time) # 等待页面加载
break # 找到目标元素后退出循环
except Exception:
# 如果未找到目标元素,则向下滚动页面
driver.execute_script("window.scrollBy(0, 800);") # 每次向下滚动 800 像素
print(f"未找到目标元素,尝试向下滚动... 第 {scroll_attempts + 1} 次")
time.sleep(scroll_pause_time) # 等待页面内容加载
scroll_attempts += 1 # 增加滚动次数
# 如果达到最大滚动次数
if scroll_attempts >= max_scroll_attempts:
print("滚动达到最大次数,未找到目标元素")
# 6. 获取教师名
try:
teacher = driver.find_element(By.XPATH, "//div[@class='m-teachers_teacher-list']//h3[@class='f-fc3']").text
except Exception:
teacher = "未知教师"
print(f"教师名: {teacher}")
# 7. 获取团队成员
try:
# 获取团队成员的元素列表
team_member_elements = driver.find_elements(By.XPATH,"//div[@class='m-teachers_teacher-list']//h3[@class='f-fc3']")
# 提取每个团队成员的名字
team_members = [member.text for member in team_member_elements]
# 如果列表为空,则没有找到团队成员
if not team_members:
team_members = "暂无团队成员"
except Exception:
team_members = "暂无团队成员"
print(f"团队成员: {team_members}")
# 返回课程数据
course_data = {
"course_name": course_name,
"school_name": school_name,
"teacher": teacher,
"team_members": team_members,
"participants": participants,
"progress": progress,
"description": description,
}
print("课程数据:", course_data)
return course_data
except TimeoutException as e:
print(f"加载课程详情失败: 页面加载超时,异常信息: {str(e)}")
return None
except Exception as e:
print(f"加载课程详情时发生未知错误: {str(e)}")
return None
最后是主函数,由于前面的函数很复杂,所以这个主函数结构就比较简单了;
初始化数据库,登录,爬取课程信息,最后关闭游标对象,数据库连接和浏览器驱动。
def main():
# 初始化数据库
conn, cursor = init_db()
login() # 登录
try:
# 抓取课程信息并插入数据库
print("开始爬取课程信息...")
scrape_courses()
print("数据存储成功!")
except Exception as e:
print("爬取失败:", e)
finally:
cursor.close()
conn.close()
driver.quit()
if __name__ == "__main__":
main()
🌞运行结果截图
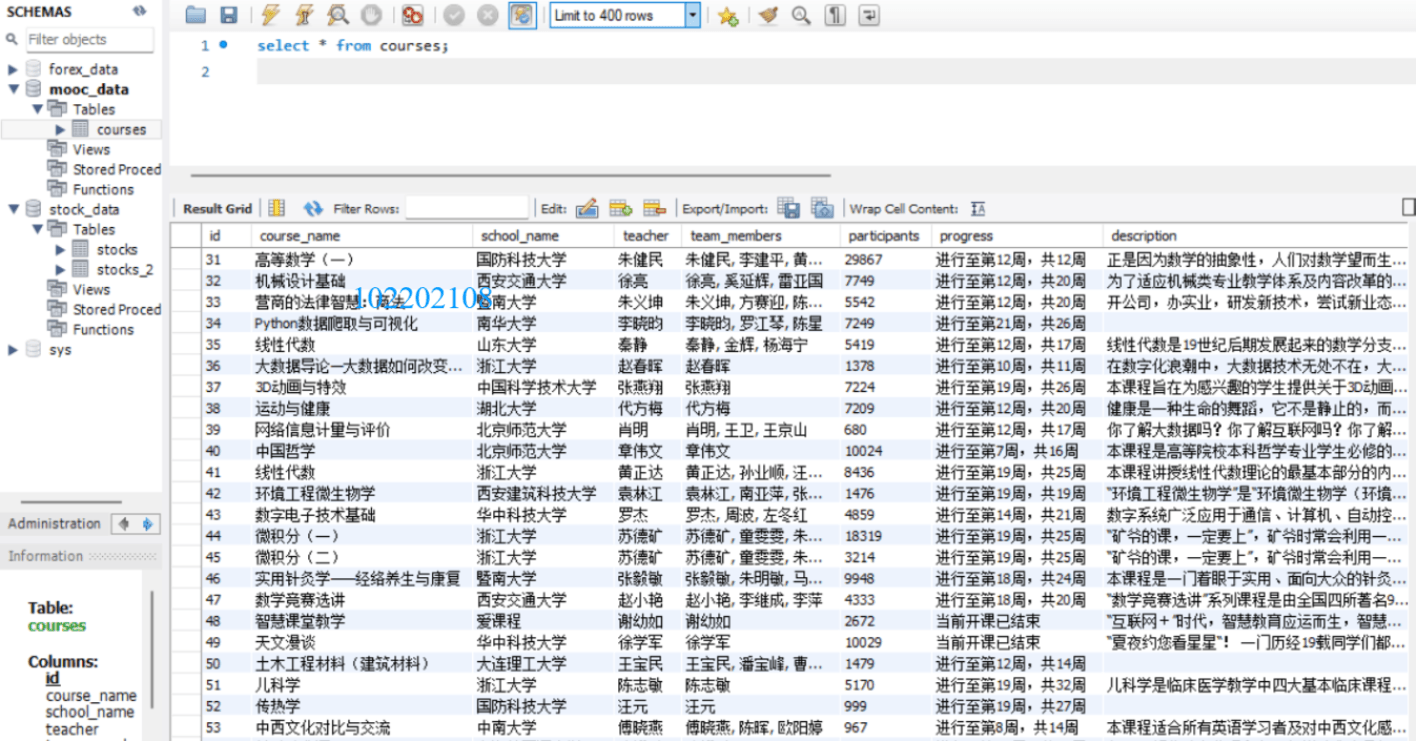
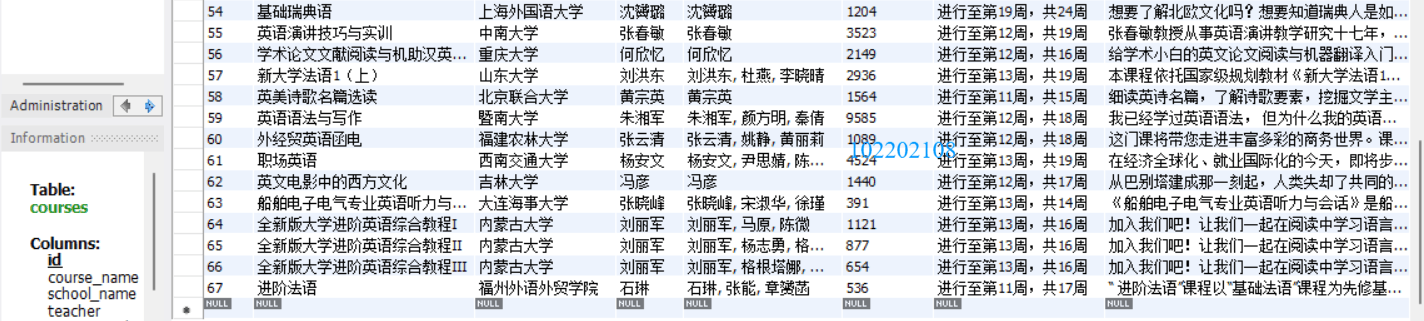
先是在控制台的输出信息(只截取一张),包含很多用于调试的语句,不用管它们:

再是在mysql数据库中的数据:
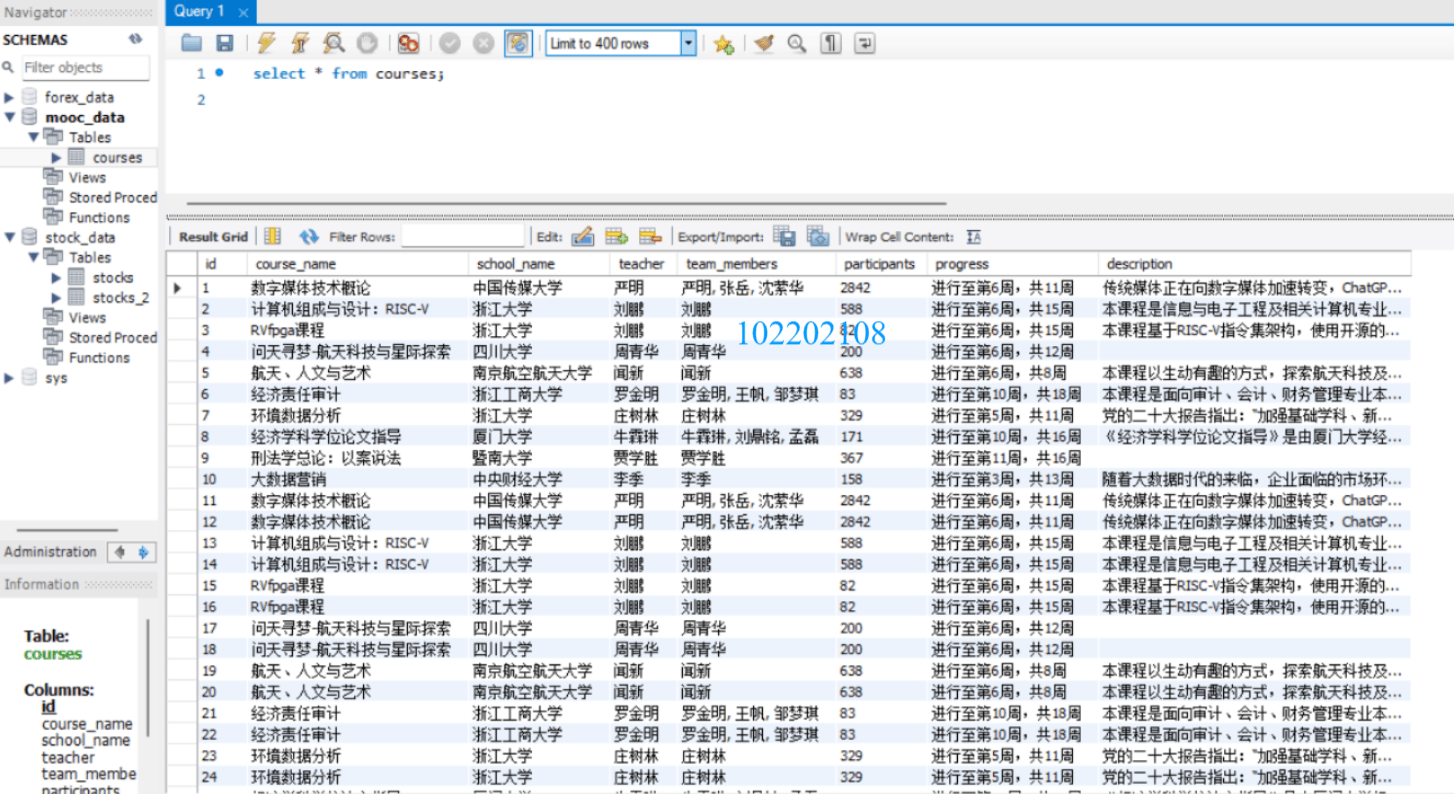
🌈心得体会
-->别的不说,我在这道题上的感受颇多,因为真的花了很多时间,并且学到了很多东西。都快不知道该从哪里说起了,我大概花了三天(不加实践课那天)。
-->第一天我盯着那看似“完美”的代码(实则漏洞百出),一遍遍问gpt然后反复修改,结果啥也不是。我就取消了“无头模式”,想看看到底怎么个事,只见它先是跳出谷歌浏览器的界面,缓慢地加载着慕课网站的信息,突然弹出一个登录框,看来它已经成功找到了登录按钮并进行了点击,正当我期待它继续往下进行(找到手机号和密码的输入框并填入相关信息)的时候----它,不动了。我以为是网络的问题,想着多等一会儿吧,此时我还抱着一丝期待,可最终等到的却是页面无情的闪退,只留下在原地愣住的我一个人。万万没想到,我的代码连登录的关都没过,那就不用谈什么课程信息的爬取了,前面我还一直在观察原html代码,为的是更精准地定位到各个数据,现在看来有点多次一举,毕竟连课程的封面都没有见到。(……此处省略一万字,毕竟找到真理的过程是很漫长的)那我最终是怎么发现问题出在哪里,又是怎么解决的呢?这也是我在此次作业中学到的第一个东西----网页中的内嵌框架。
-->这是我第一次知道网页中是包含iframe(内嵌框架)的,所以上面就是一直把浏览器的焦点定位在最外层的文档,导致找不到手机号和密码的输入框。只有切换到这个iframe内部才能与其中的元素进行交互。好了现在发现问题了,那怎么解决呢?只需要现成的driver.switch_to.frame(frame_reference)这个方法,它可以直接切换浏览器焦点到某个iframe,那到底是哪个咧,只需将参数传给它,frame_reference是iframe的引用,可以是通过各种定位策略得到的元素对象,也可以是iframe的索引。进行完这一步,就能成功找到输入框和点击“立即登录”的按钮了。不过还有,立即登录后,登录框会消失,一开始的主界面就会又出现在我们的面前,那就意味着我们现在必须让浏览器的焦点回到这个主文档上,以重新获取访问权限。driver.switch_to.default_content() 方法正是用于这个目的,直接使用即可,非常方便。总之一句话:“如果尝试在没有先切换到 iframe 的情况下与 iframe 内部的元素交互,或者在没有切换回主文档的情况下尝试与主文档中的元素交互,Selenium 将无法找到这些元素,并可能抛出 NoSuchElementException 异常。”
-->就这样一天只解决了登录的问题,登录成功之后,我也并没有爬取到想要的数据,这才有了下文。
-->好了,已经到第二天了,此时我突破了登录大关,开始瞄准课程列表。我反复比对我的XPATH路径和网页实际的html文档,但是似乎怎么都定位不到它,于是我又换了很多别的方法By.ID, By.CLASS_NAME等等,似乎都没起作用。我又反复问gpt,它给我出了很多主意和修改方式,每次都信誓旦旦地跟我说 “这样就能解决了。” “这次肯定能爬取到想要的数据了。”但是都没有解决,我几乎都快跟AI吵起来了,没办法,AI的确懂很多东西,但它不懂我的心,而我越是急越是没法描述清楚,越是描述不清楚越是急。最终,我选择放弃与它沟通,默默地点开了其他同学的博客(这通常都是没有办法的办法),想看看到底问题出在哪里,翻阅数篇博客之后,我找到了问题所在,这是我这次作业学到的第二个东西----Selenium模拟页面滚动。
-->在自动化测试或爬虫任务中,模拟滚动页面是一个常见的需求,没办法呀,我就是没见过呀,不过现在我知道了,如果想要爬取的数据在视图中不可见,那它即使存在于该界面之中,也是无法定位到的。那如何执行页面的滚动,就是用类似于driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")的语句,execute_script()是允许driver执行JavaScript语句的方法,括号内放想要执行的JavaScript语句,这里就是"window.scrollTo(0, document.body.scrollHeight);",作用是将页面滚动到底部,当然我不是需要滑动到底部,而是滑动到特定元素的位置。所以我就用了一个循环,每次先检查要找的元素有没有出现,如果没有,就向下滑动固定的长度,再次检查元素是否出现,直到找到元素或是滑动次数达到最大(这是我自己设置的,防止陷入死循环)。还有一个这次没有用到但是也值得注意的点:如果页面包含滚动条(比如在某个
-->hahaha!又是新的一天,直接进入正题:我明明点击了课程封面,怎么结果感觉像是没进去一样呢,因为一条信息都没爬到,我就在进行点击操作的代码下方加了一条测试语句来打印出进行点击操作之后的html的内容,看看是不是我对元素的定位出现了问题。打印出的html代码很长,我就慢慢在那里翻,越看越不对劲……最终恍然大悟:不对!这不是主页的html文档吗?这里哪来的课程详情的信息?难怪啥也爬不到!原来真的是没进去呀!看来之前的怀疑是对的。我就很疑惑,以为是点击没有生效,又去问了gpt(我们和好了),来来回回折腾的很多次发现,点击的确是没错的,错的是其他的地方。这里点击课程封面之后,它不是在原有的页面上刷新内容,而是重新开了一个窗口,这我虽然是知道的,但我不知道的,也是本次作业学到的第三样东西----driver在不同的浏览器窗口或标签页之间切换。
-->有了上面driver.switch_to.frame()做铺垫,这个切换标签页也就不难理解了。其方式就用driver.switch_to.window() 方法,括号内是要传入想要切换的窗口,通常用索引表示,driver.window_handles 会返回当前会话中所有打开的窗口(或标签页),索引从0开始,如果想切换到最近打开的窗口,就令索引等于-1即可。有打开就有关闭,driver.close() 方法用于关闭当前活动的浏览器窗口(或标签页),它不会关闭整个浏览器应用程序,只是关闭当前正在与之交互的窗口,这一点跟driver.quit()是不一样的,需要特别注意。别忘了关闭标签页后,还要将driver切换到第一个主界面的窗口,然后进行下一个课程的点击。
-->其实做到上面这一步时还没有结束,后面错误多着呢,只是大的问题大概就这三个,这样看还真的是一场充满刺激的冒险呢!我现在已经是筋疲力竭了,确实被这道题的弯弯绕绕给整的头晕目眩了,不过呢,它也让我学到了很多新东西。最后的最后,我只想说:我对Selenium一!无!所!知!
作业③:
✒️要求:掌握大数据相关服务,熟悉Xshell的使用 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。 环境搭建: 任务一:开通MapReduce服务 实时分析开发实战: 任务一:Python脚本生成测试数据 任务二:配置Kafka 任务三: 安装Flume客户端 任务四:配置Flume采集数据
🗃️输出:实验关键步骤或结果截图。
🚀关键步骤及结果截图
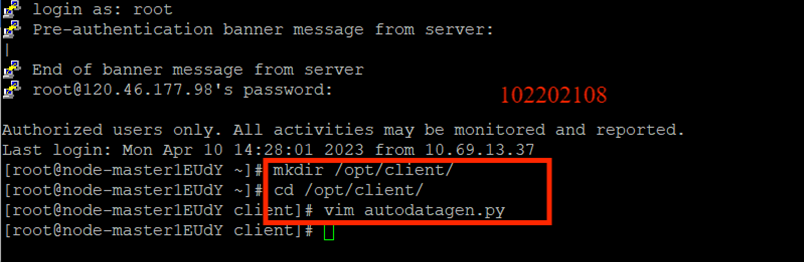
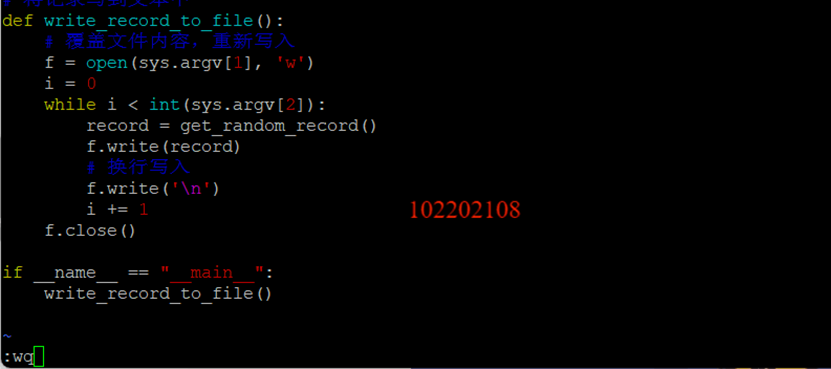
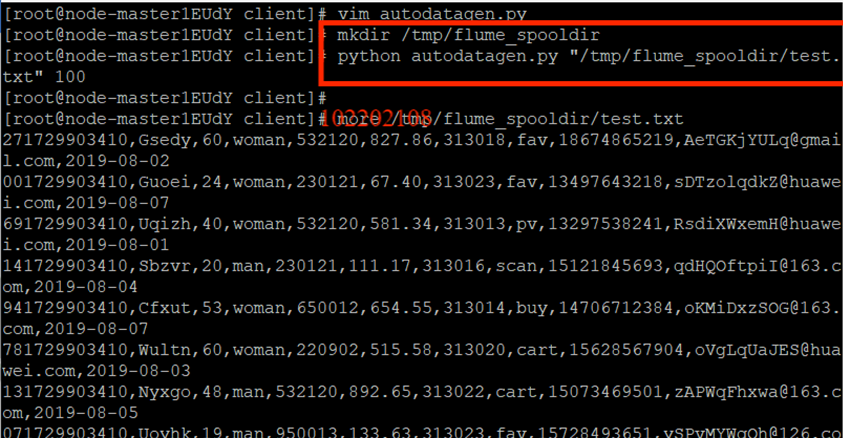
任务一:Python脚本生成测试数据
创建python脚本:
执行python脚本:
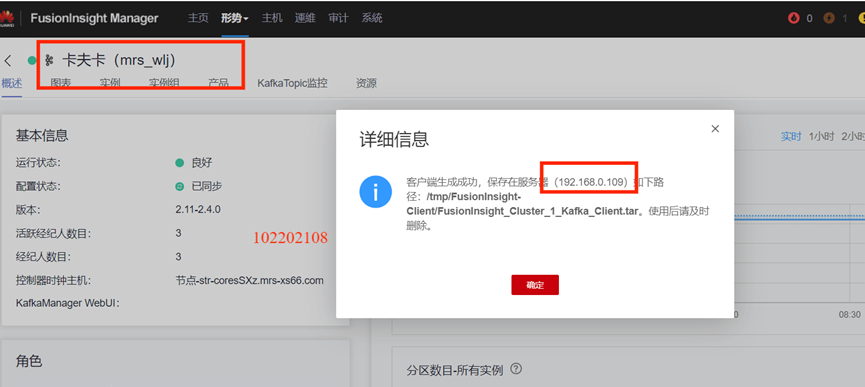
任务二:配置Kafka
下载安装配置Kafka:
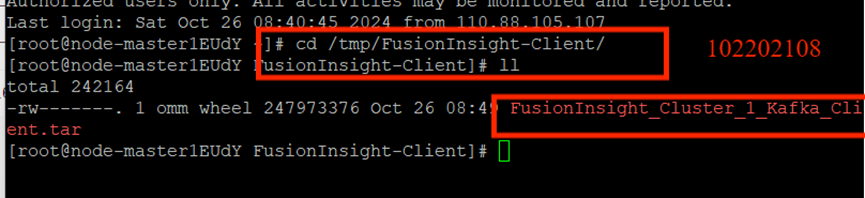
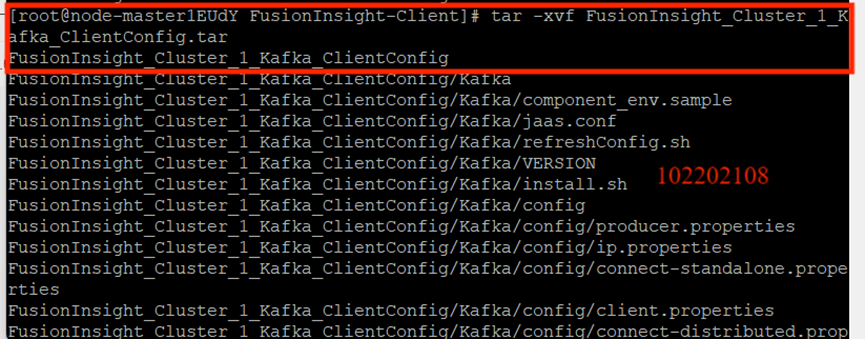
下载客户端:
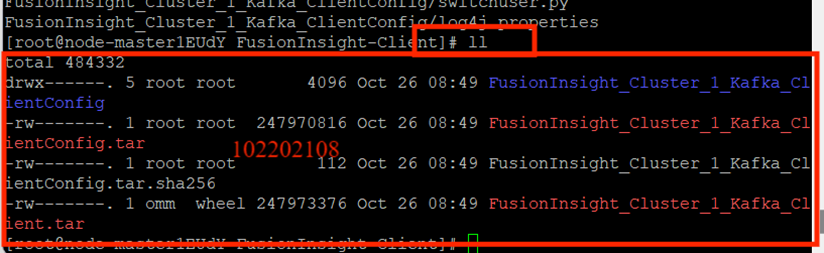
校验下载的客户端文件包:
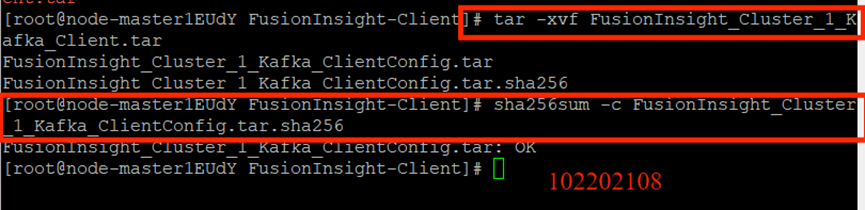
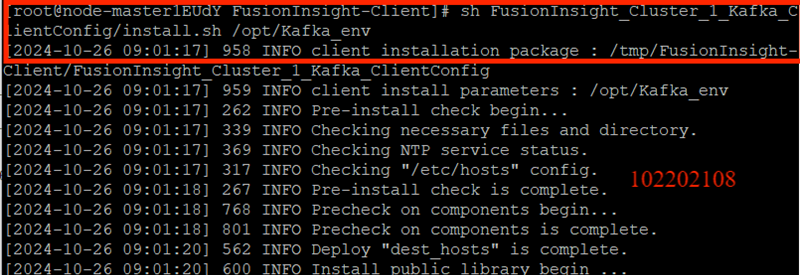
安装Kafka运行环境:
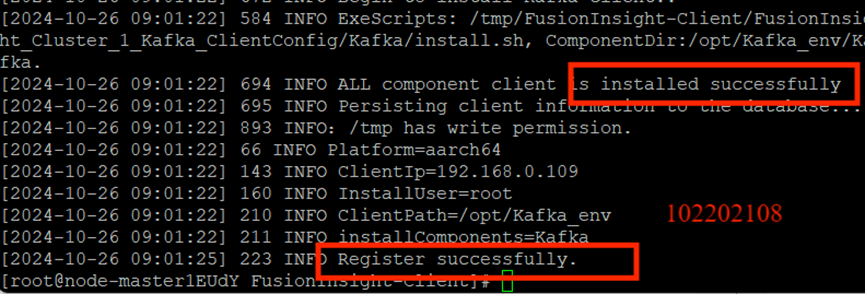

安装Kafka客户端:
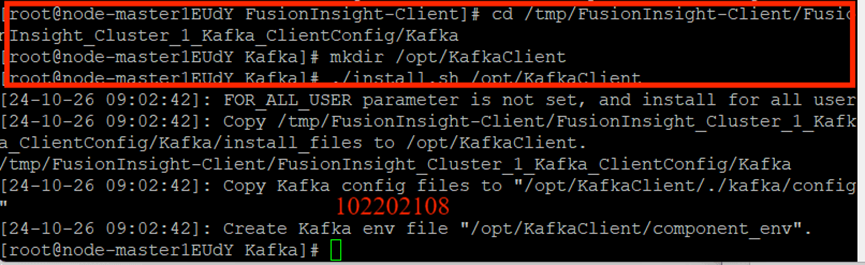
创建并查看topic:
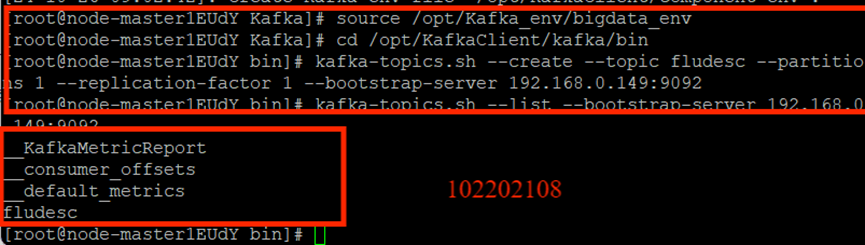
任务三: 安装Flume客户端
下载客户端文件包:

效验文件包:


安装Flume运行环境:
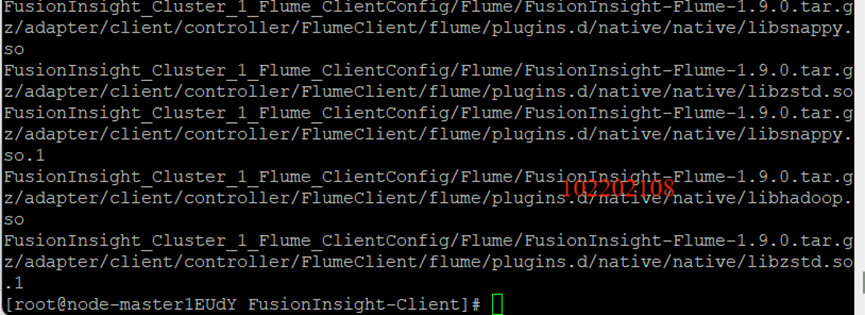
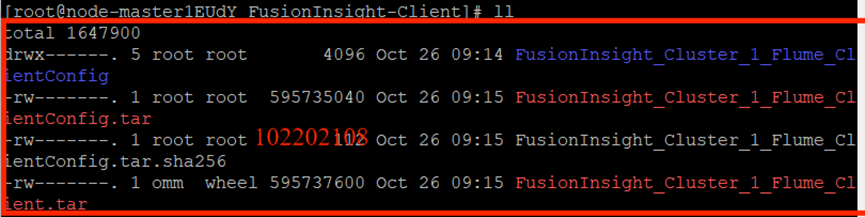
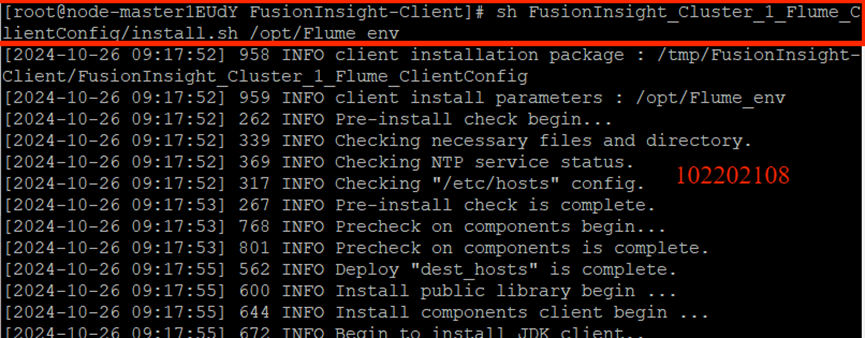


安装Flume客户端:
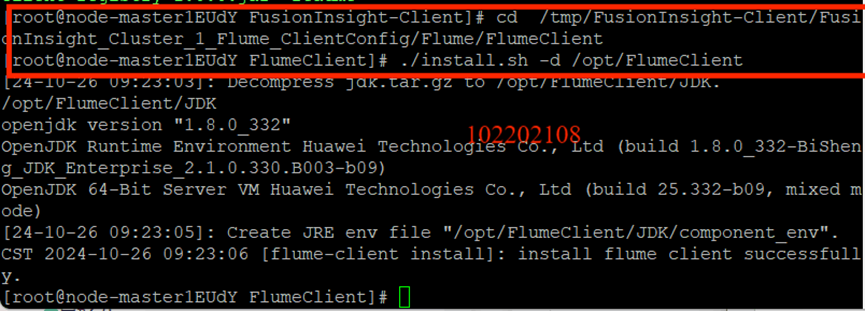
重启Flume服务:
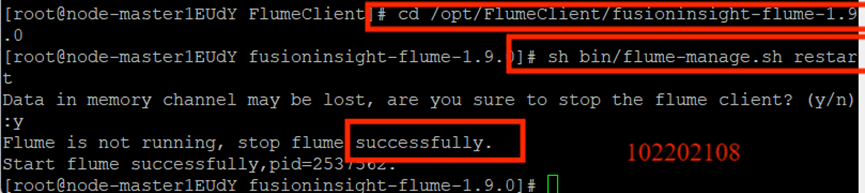
任务四:配置Flume采集数据
修改配置文件:
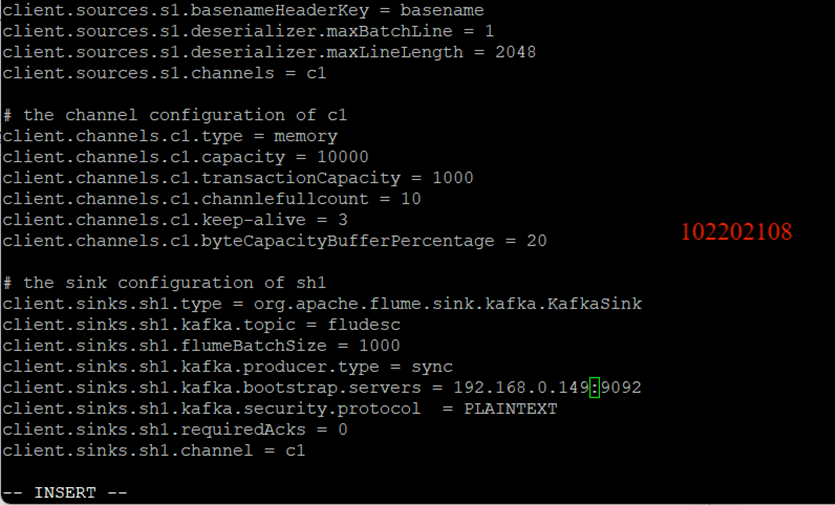
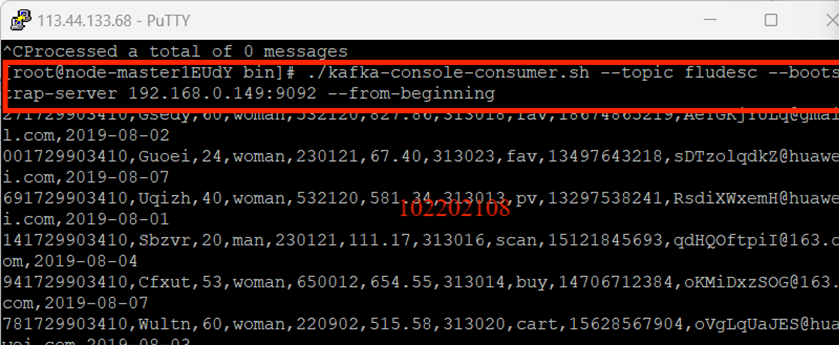
创建消费者消费数据:

🌈心得体会
这次实验是我华为云平台实验做的最快的一次(只用了三个多小时),只不过后面删除资源花了很长的时间(因为有些资源怎么都删除不掉,只能联系工程师)。这个实时数据分析实验真的有点神奇,尤其是后面的大屏幕可视化的部分看起来很高级的样子,我之前也有在学校的智慧食堂里看到类似实时数据分析的大屏幕,所以感觉这次的实验的应用非常广泛。只是我对很多地方的理解都不是很深,只是按照步骤一步一步做,最终得到了可视化的结果,但即使是这样,也是bangbang的!

