47. 全排列 II(C++)
题目
给定一个可包含重复数字的序列,返回所有不重复的全排列。
示例:
输入: [1,1,2]
输出:
[
[1,1,2],
[1,2,1],
[2,1,1]
]
分析与题解
这道题目和46.全排列的区别在于给定一个可包含重复数字的序列,要返回所有不重复的全排列。
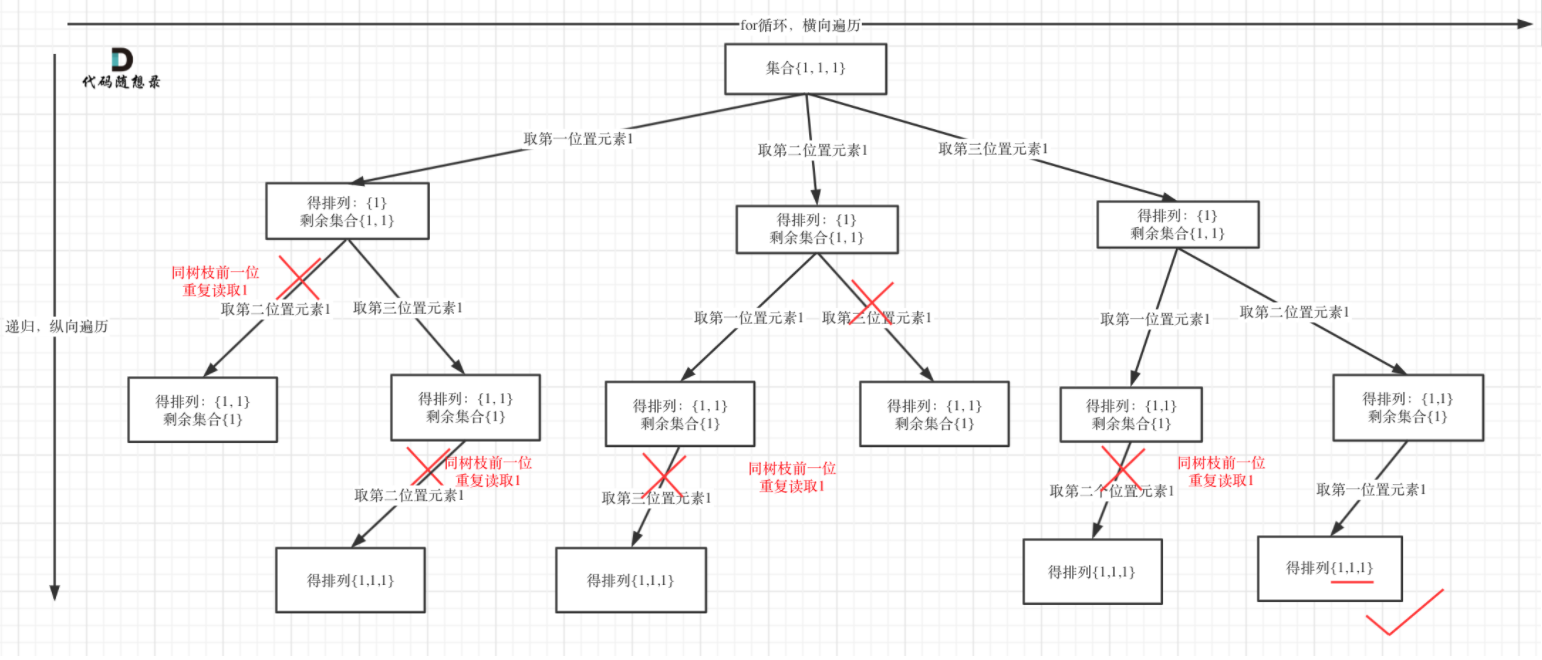
这里就涉及到去重问题,所谓去重,其实就是使用过的元素不能重复选取。我们通过简单示例来理解去重的步骤。
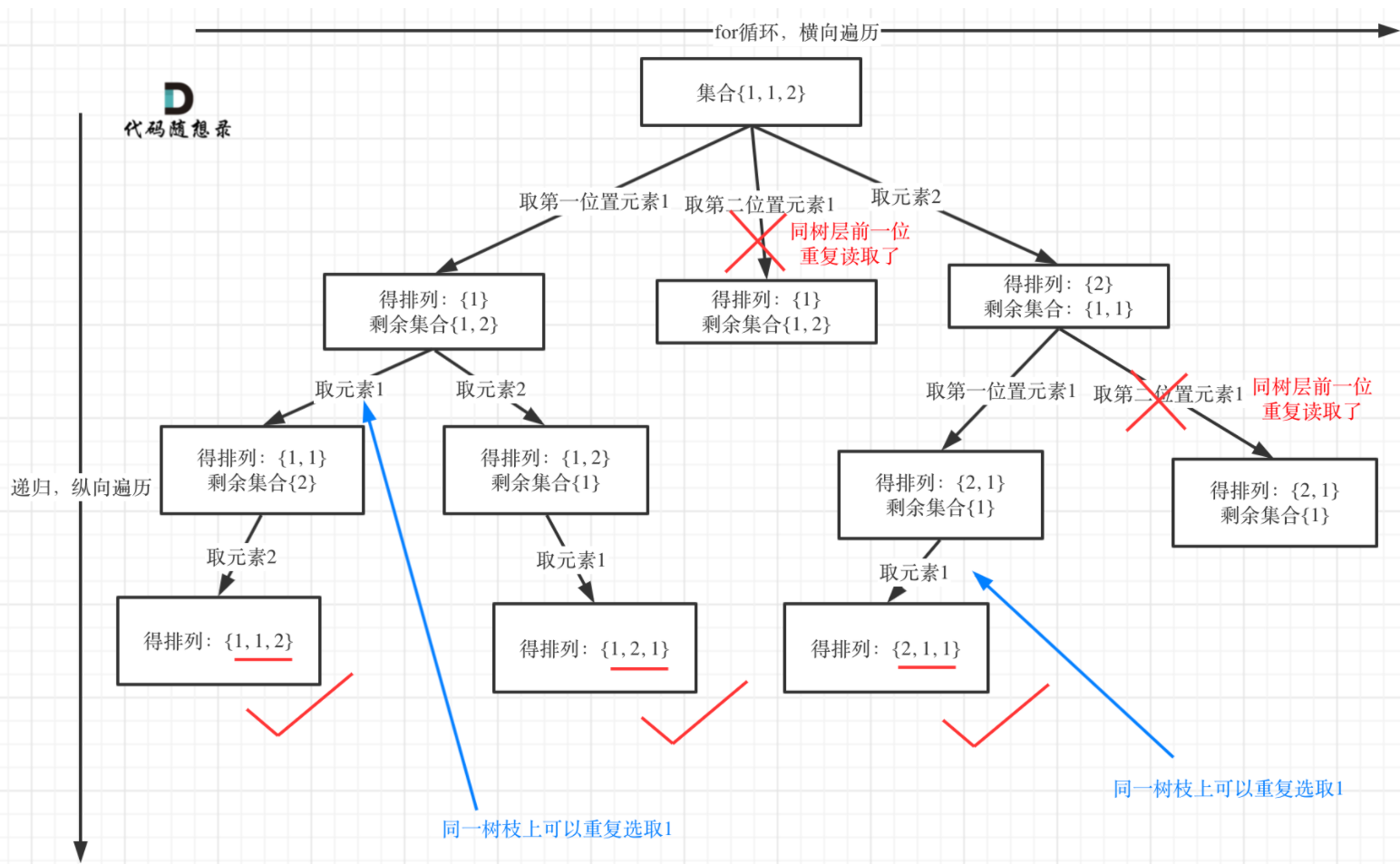
关键在于如何定义“使用过”,我们把排列问题抽象为树形结构之后,“使用过”在这个树形结构上是有两个维度的:
- 一个维度是同一树枝上使用过
- 一个维度是同一树层上使用过。
按照一般规律,按照数层进行去重会更加彻底和高效,首先我们需要对nums数组进行排序,因为数组中存在重复元素,而我们会对相邻元素进行比较。排序才能确保比较相邻元素就能够对所有重复元素进行遍历和讨论。
sort(nums.begin(), nums.end());
我们使用vector<bool> used来判断是否去重,核心代码如下:
if(i>0 && nums[i]==nums[i-1] && used[i-1]==false) continue;
以上仨条件需要同时进行满足:
-
首先
i>0排除第一个元素(因为首位元素没有前一位进行比较)通常第一位元素对应的路径可以进行选择
-
其次
nums[i]==nums[i-1]表示相邻元素需要相等,由于提前对数组进行排序,所以相等的元素必然相邻。 -
最后
used[i-1]是核心和难点,因为在回溯问题中,我们做出决定进行递归完成后,会撤销决定。因此在同一树层遍历所有路径时,无论相邻的前一路径nums[i-1]是否能走通,遍历到当前路径nums[i]时,used[i-1]都会为false,即已经撤销之前路径的决定。而当nums[i-1]设置为true后,它只有在树状图的下一树层才会维持true的状态,当在子树层遍历到同一个nums[i]元素时,哪怕nums[i]==nums[i-1],此时却可以仍然选择该路径。因为该方法只进行树层去重,而对于树枝去重不进行干涉。
完整代码如下:
class Solution {
public:
//使用全局变量进行结果的存储,减少迭代函数的形参个数
vector<vector<int>> res;
void backtrack(vector<int>& nums, vector<int>& track, vector<bool> used){
//先设定迭代的中止条件
if(track.size() == nums.size()){
res.push_back(track);
return;
}
for(int i=0;i<nums.size();i++){
if(i>0 && nums[i]==nums[i-1] && used[i-1]==false) continue;
if(used[i]==false){
//做出决定
used[i]=true;
track.push_back(nums[i]);
backtrack(nums, track, used);
//撤销决定
used[i]=false;
track.pop_back();
}
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
//在进行去重时先进行排序
//因为我们对相邻元素进行比对
//这样重复元素会比较集中
sort(nums.begin(), nums.end());
vector<bool> used(nums.size(), false);
vector<int> track;
backtrack(nums, track, used);
return res;
}
};
另解拓展
我们提到上述方法为在同一树层进行去重,而其实我们只需要将核心代码used[i-1]==true,那么代码逻辑就会变更为树枝去重,只不过这种方法没有树层去重执行效率高。核心代码变更为:
if(i>0 && nums[i]==nums[i-1] && used[i-1]==true) continue;
同样使用一个[1, 1, 1]的简单例子进行理解: