论文分享:目标检测-YOLO
You Only Look Once: Unified, Real-Time Object Detection 论文地址
算法思路
仿照人类视觉系统,只看一次图片就可以知道目标的类别以及位置。在实际测试时将图片人分成S*S的方格,对每个方格回归出两个边框以及相应的置信度,和20类类别。
motivation
目前的算法都是先提取候选区域在进行类别的判别和边框优化,不仅降低了整个算法运行时间们还容易导致后续边框优化时缺乏上下文信息而不够精确。
本文提出一种将二者合二为一的YOLO算法,通过卷积层提取特征,然后使用全连接层直接预测目标的位置以及类别信息。
做法
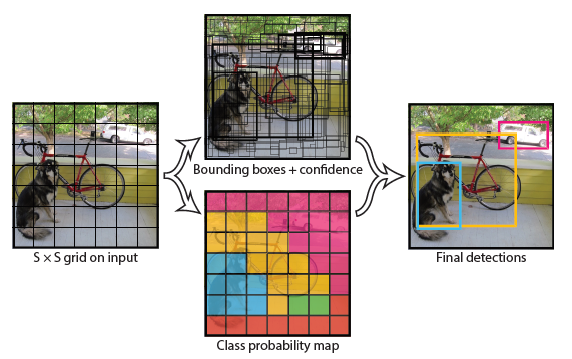
本文算法分为三个步骤: 首先将图片分成S*S个网络,如上图左边所示; 接着对每个网格回归出两个边框,以及他们的类别和置信度; 最后使用Soft-NMS除去重合的边框,得到最终的结果。
整个网络架构如下所示:

性能
由于没有特征再提取操作,所以整个算法的效率提升了不少,精度没有多少的损失。
下图是当时与最好算法性能的比较:
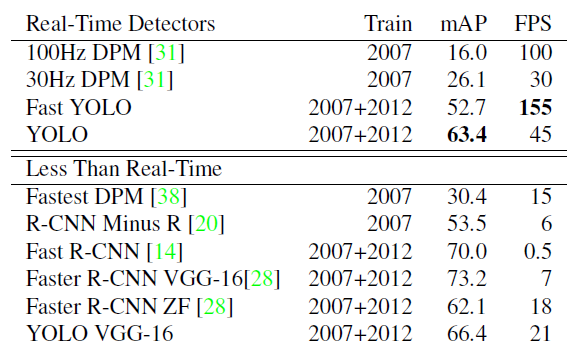
在实时性的目标检测算法中,本文提出的YOLO算法不仅在速度上有巨大的优势,而且精度上也比以往的提升了两倍。 与非实时性算法相比,本文提出的算法在损失较小的性能指标下,获得6X倍速度的提升。
Thoughts
- 本文算法首次将single network引入到目标检测中,极大的提升了算法的速度。利用预设的锚点可以保证网络有足够的边框回归出目标的位置以及大小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号