技术架构(4)-分布式ID
为什么需要分布式ID
不管是存储数据,还是做表关联,关系型数据库必须有主键。
现在建系统,动不动就是分布式、微服务,如果新系统还玩单机,那都不好意思说。
同一个服务部署多个实例,每个实例要生成不一样的ID,还必须要快。如果指望数据库单节点来生成ID,那性能太差,还有单点故障。
需要有一种机制来生成集群内的唯一ID,还要性能好、没有单点故障。
-
全局唯一:必须保证ID是全局性唯一的,这是最基本的要求
-
高性能:高可用低延时,ID生成响应要块,否则反倒会成为业务瓶颈
-
高可用:100%的可用性是骗人的,但是也要无限接近于100%的可用性
-
好接入:要秉着拿来即用的设计原则,在系统设计和实现上要尽可能的简单
-
趋势递增:最好趋势递增,这个要求就得看具体业务场景了,一般不严格要求
下面来探讨几种常见的分布式ID生成方式,并分析优缺点。
数据库SEQUENCE
create sequence seq_id --序列名称seq_id
start with 1 --起始值为1
increment by 1 --递增1
minvalue 1 --最小值1
maxvalue 999999 --最大值999999
cycle --到最大值之后,又从最小值开始,循环使用编号
cache 20 --一次缓存20个序号,不用每次计算
使用数据库sequence时,序号放在最后,前面一般需要拼接一段有业务含义的字符串,比如:系统组件缩写+业务类型+数据库日期(年月日)+序号,一秒钟允许发生的业务量取决于sequence最大值。
sequence是部分数据库才有的,这种方法与数据库自增ID是类似的,自增ID每次插入一条记录并返回。
优点
- 容易理解,自主调整程度高
- 有序递增
- 有业务含义,可以快速查问题
缺点
- 数据库存在单点风险,无法扛住高并发场景
- 根据ID能推测出业务量
UUID
UUID是首先会被想到的唯一ID。UUID 的全称是 Universally Unique Identifier,中文为通用唯一识别码,由一组32位数的16进制数字所构成。以连字号分为五段,表现形式为8-4-4-4-12的32个字符。
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
如:30385d15-0a88-42eb-bc43-2c000e9f778c
其中 M 与 N 都有特殊含义:M 表示 UUID版本,目前只有五个版本,即只会出现1,2,3,4,5;N 的最高有效位表示 UUID 变体,目前只会出现 8,9,a,b 四种情况。
- v1 (timestamp):timestamp + MAC 地址。机器的MAC地址出厂后不能保证完全唯一,且之后 MAC 地址也可手动修改,MAC 地址的暴露会造成了隐私与安全问题,若一台机子上的两个进程同时跑,有可能出现重复问题。
- v2 (timestamp):基于 v1 的基础上优化了下,更安全。
- v3 (namespace):基于 namespace + 输入内容 进行 MD5。
- v4 (random):这个版本的UUID是使用最多的,基于随机数生成。
- v5 (namespace):跟 V3 差不多,只是把散列算法的 MD5 变成 SHA1。
它的用法也非常简单。
String uuid = UUID.randomUUID().toString()
优点
-
生成足够简单,本地生成无网络消耗,具有唯一性
缺点
- 无序的字符串,不具备趋势自增特性,导致数据位置频繁变动,严重影响性能
- 没有具体的业务含义,不可读
- 长度过长,36位长度的字符串,存储以及查询的性能消耗较大
- 从生成和存储效率来看,UUID将逐步被NanoID取代,后者更快且更短
雪花算法
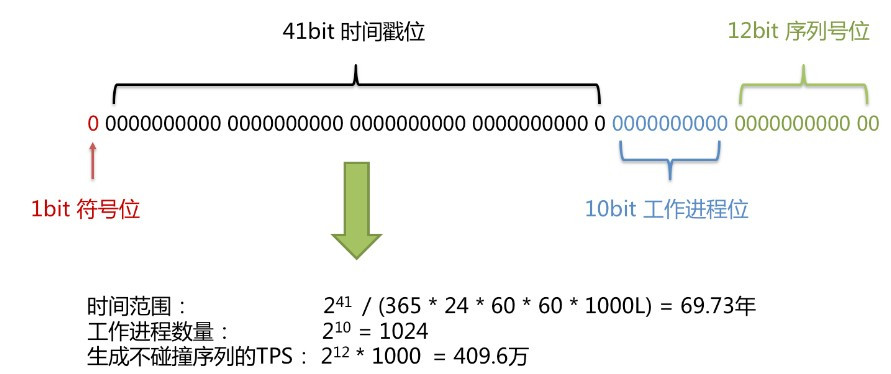
- 首位无效符:第一个 bit 作为符号位,因为生成的都是正数,所以第一个 bit 统一都是 0。
- 时间戳:占用 41 bit ,精确到毫秒。41位可以表示2^41-1毫秒,转化成单位年为 69 年。Java时间戳从1970年开始,69年也用不了多久了,所以可以吧部署的时刻作为起始点。
- 工作进程:占用10bit,其中高位 5 bit 是数据中心 ID,低位 5 bit 是工作节点 ID,最多可以容纳 1024 个节点。
- 序列号:占用12bit,每个节点每毫秒从0开始不断累加,最多可以累加到4095,一毫秒可以产生 4096 个ID,一秒钟就是409.6万个。
优点
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖第三方,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
其他
还有其他Redis、号段、步长、Leaf等等生成分布式ID的方式,不再赘述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号