大数据学习(34)—— ElasticSearch原理
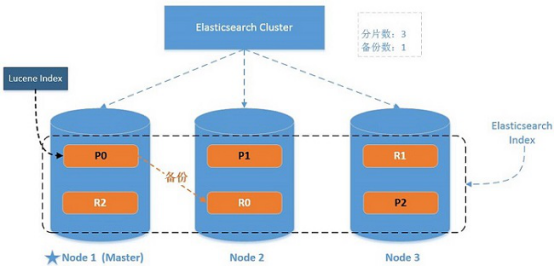
倒排索引
作为全文搜索引擎,它不像RDBMS那样用like '%'去全表查找包含特定关键字的记录,而是使用倒排索引直接定位到哪些记录是符合要求的。
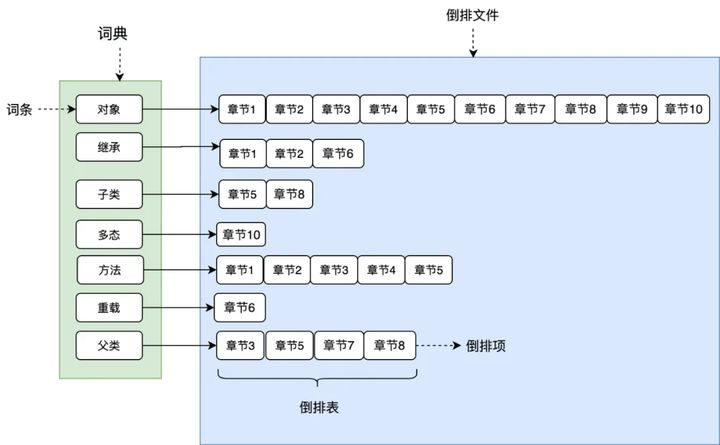
上图是一张倒排索引的图。正常情况下,我们去寻找一个词汇在书中出现的位置,必须把整本书所有章节阅读一遍才能知道哪些章节包含要找的词汇。倒排索引,是指在保存文档内容的时候,就按分词对每一个词条建立起它所在文档的索引,再去寻找词条出现的位置时,直接就能找到那些包含它的章节,这比把整本书读一遍要快多了,但是保存文档建立索引的过程做的事情会很多。
分片机制
文档写在索引的哪个分片上,是由公式来决定的。
shard = hash(routing) % number_of_primary_shards以上公式的值是在0到number_of_primary_shards-1之间的余数,也就是数据档所在分片的位置。routing通过Hash函数生成一个数字,然后这个数字再除以number_of_primary_shards(主分片的数量)后得到余数。routing是一个可变值,默认是文档的_id ,也可以设置成一个自定义的值。
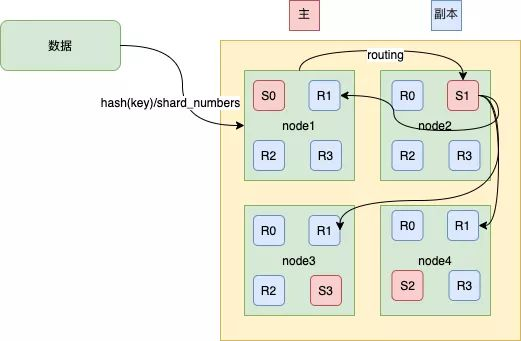
在一个写请求被发送到某个节点后,会充当协调节点,根据路由公式计算出写哪个分片,当前节点有其他节点的分片信息,如果发现对应的分片是在其他节点上,再将请求转发到该分片的主分片节点上。
为什么在创建索引的时候就要确定好主分片的数量,并且不可修改?因为如果数量变化了,那么所有之前路由计算的值都会无效,数据也就再也找不到了。虽然ES提供了相应的api来缩减和扩增分片,但是代价是很高的,需要重建整个索引,所有数据都要移动。
写操作是必须在主分片上完成,然后才能被复制到对应的副本上。ES为了提高写入的能力这个过程是并发写的,同时为了解决并发写的过程中数据冲突的问题,ES通过乐观锁的方式控制,每个文档都有一个 _version号,当文档被修改时版本号递增。当所有的副本分片都报告写成功才会向协调节点报告成功,协调节点向客户端报告成功。
存储原理
数据在写入到分片和副本上后,目前数据在内存中,要确保数据在断电后不丢失,还需要持久化到磁盘上。大数据的技术很多都是先写内存,稍后再落盘。
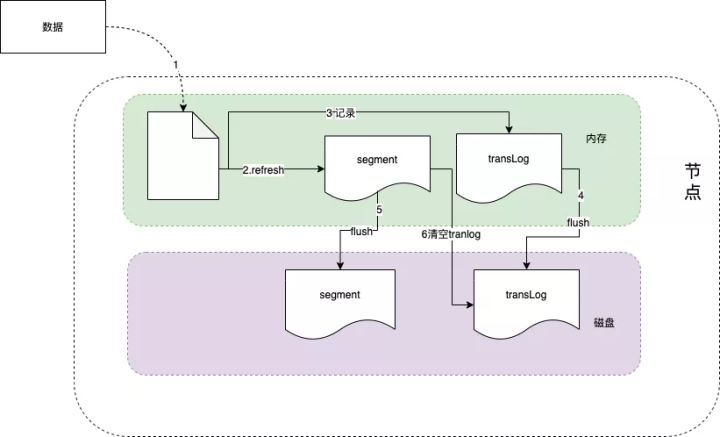
ES是基于Lucene实现的,内部是通过Lucene完成的索引的创建写入和搜索查询。当新增文档时,Lucene进行分词等预处理,然后将文档索引写入内存中,并将本次操作写入事务日志(transLog),transLog类似于mysql的binlog,用于宕机后内存数据的恢复,保存未持久化数据的操作日志。
默认情况下,Lucene每隔1s将内存中的数据刷新到文件系统缓存中,称为一个segment(段)。一旦刷入文件系统缓存,segment才可以被用于检索,在这之前是无法被检索的,因此说ES是一个准实时的系统。
segment 在磁盘中是不可修改的,因此避免了磁盘的随机写,所有的随机写都在内存中进行。随着时间的推移,segment越来越多,默认情况下,Lucene每隔30min或segment 空间大于512M,将缓存中的segment持久化落盘,称为一个commit point,此时删掉对应的transLog。
负载均衡
考虑到并发响应以及后续扩展节点的能力,分片的数量不能太少,假如只有一个分片,随着索引数据量的增大,后续进行了节点的扩充,但是由于一个分片只能分布在一台机器上,所以集群扩容对于该索引来说没有意义了。
但是分片数量也不能太多,每个分片都相当于一个独立的lucene引擎,太多的分片意味着集群中需要管理的元数据信息增多,master节点有可能成为瓶颈;同时集群中的小文件会增多,内存以及文件句柄的占用量会增大,查询速度也会变慢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号