大数据学习(27)—— DataSet和DataFrame
DataFrame是spark1.3之后引入的分布式集合,DataSet是spark1.6之后引入的分布式集合。在spark2.0之后,DataFrame和DataSet的API统一了,DataFrame是DataSet的子集(
type DataFrame = org.apache.spark.sql.Dataset[org.apache.spark.sql.Row]
),DataSet是DataFrame的扩展。
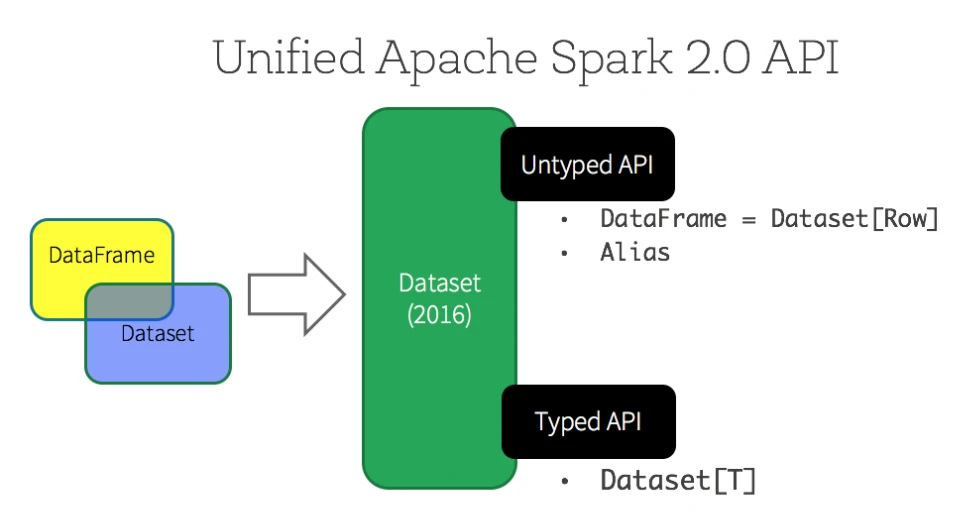
DataFrame
DataFrame的数据都被组织到有名字的列中,就像关系型数据库中的表一样。它既包含数据结构信息schema,又包含数据。它除了提供与RDD类似的API之外,还提供了spark sql支持,方便了数据处理操作。
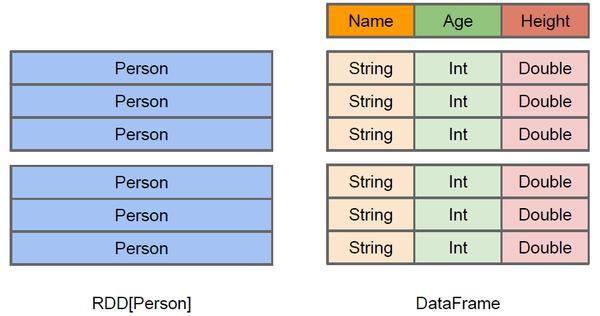
DataFrame是DataSet[Row]的别名,它存放的是一行记录,如果给它指定了schema,它才知道这一行里包含哪些列,而且要自己解析字符串,才能知道每一列的值。它不是强类型检查的,可能会出现运行时错误。
DataSet
DataSet结构跟DataFrame一样,但它是强类型的,它包含的每一个元素已由case class定义,每一个属性的类型都是确定的,在编译阶段检查。它也支持spark sql。
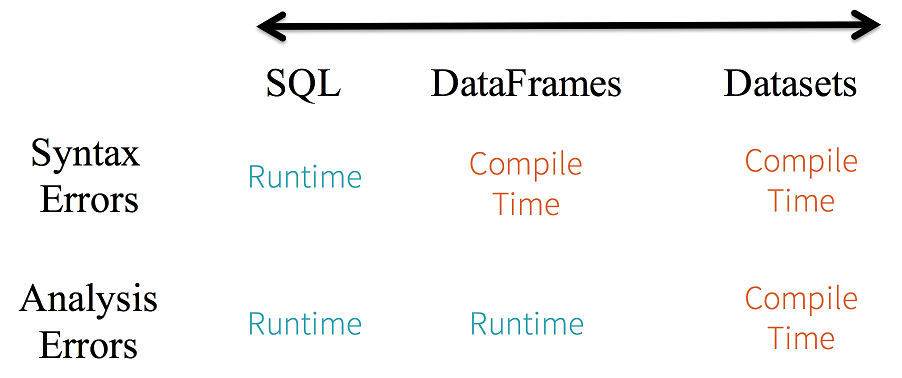
DataSet和DataFrame使用场景
DataFrame 和 Dataset API 都是基于 Spark SQL 引擎构建的,它使用 Catalyst 来生成优化后的逻辑和物理查询计划,因而会获得空间和速度上的效率。逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程,把大结果集先过滤处理成小结果集,然后再做join之类的操作。
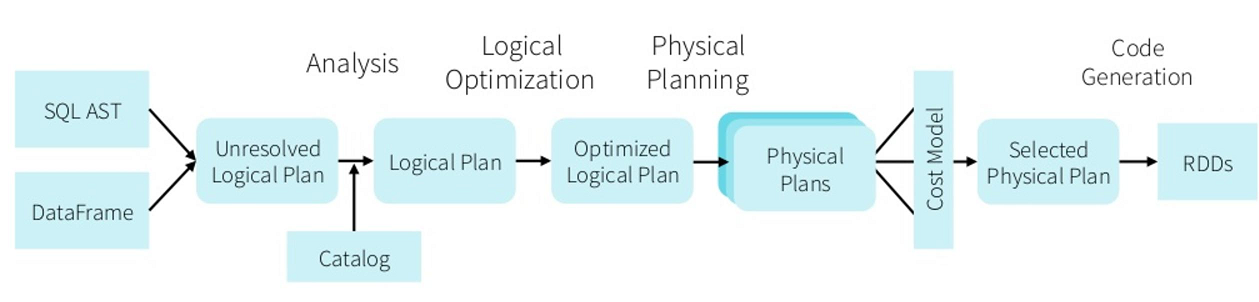
那么什么时候需要使用DataSet或者DataFrame,而不是RDD呢?
- 如果你需要丰富的语义、高级抽象和特定领域专用的 API,那就使用 DataFrame 或 Dataset;
- 如果你的处理需要对半结构化数据进行高级处理,如 filter、map、aggregation、average、sum、SQL 查询、列式访问或使用 lambda 函数,那就使用 DataFrame 或 Dataset;
- 如果你想在编译时就有高度的类型安全,想要有类型的 JVM 对象,用上 Catalyst 优化,那就使用 Dataset;
- 如果你想在不同的 Spark 库之间使用一致和简化的 API,那就使用 DataFrame 或 Dataset;
在使用DataSet或者DataFrame的时候,需要导入包import spark.implicits._,这个导入代码要写在方法体里,并且是下面这个变量之后。
val spark= SparkSession.builder() .appName("Test") .config(conf) .getOrCreate()
RDD vs DataFrame vs DataSet

RDD、DataFrame、DataSet相互转换
先定义一个rdd,再互相转换一波
val input = List("zhangshan 18","lisi 22","wangwu 19","zhaoliu 21")
val rdd = sc.parallelize(input)
rdd.foreach(println)
输出结果
zhangshan 18 lisi 22 wangwu 19 zhaoliu 21
RDD转DataFrame
val df = rdd.map(line => { val strings = line.split(" ") (strings(0), strings(1).toInt) }).toDF("name", "age") df.show()
输出结果
+---------+---+ | name|age| +---------+---+ |zhangshan| 18| | lisi| 22| | wangwu| 19| | zhaoliu| 21| +---------+---+
RDD转DataSet
DataSet是强类型的,先定义个类,再转换。
case class Person(name:String, age:Int)
转换代码如下
val ds = rdd.map(line => { val strings = line.split(" ") Person(strings(0), strings(1).toInt) } ).toDS() ds.show()
输出结果
+---------+---+ | name|age| +---------+---+ |zhangshan| 18| | lisi| 22| | wangwu| 19| | zhaoliu| 21| +---------+---+
DataFrame转DataSet
这个很简单。 val toDS = df.as[Person]
DataSet转DataFrame
也很简单。 val toDF = ds.toDF()
DataFrame和DataSet转RDD
val dftordd = df.rdd val dstordd = ds.rdd dftordd.foreach(println) dstordd.foreach(println)
输出结果
[zhangshan,18] [lisi,22] [wangwu,19] [zhaoliu,21] Person(zhangshan,18) Person(lisi,22) Person(wangwu,19) Person(zhaoliu,21)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号