大数据学习(26)—— Spark之RDD
做大数据一定要有一个概念,需要处理的数据量非常大,少则几十T,多则上百P,全部放内存是不可能的,会OOM,必须要用迭代器一条一条处理。
RDD叫做弹性分布式数据集,是早期Spark最核心的概念,是一种数据集合,它的核心就是迭代器。
创建方式
有两种创建RDD的方式:
- 在驱动程序中并行化现有集合
- 引用外部存储系统中的数据集
示例1:并行化集合
val rdd = sc.parallelize(Array(1,2,3,2,3,2,5))
示例2:引用外部文件
val file = sc.textFile("hdfs://mycluster/data.txt")
val rdd = file.flatMap(s => s.split(" "))
RDD操作
RDD 支持两种类型的操作:
- transformations,转换操作,从现有的数据集创建一个新的数据集。
- actions,执行操作,对数据集运行计算后返回一个值给驱动程序。
Spark 中的所有转换都是惰性的,因为它们不会立即计算结果。相反,他们只记住应用于某些基本数据集(例如文件)的转换。仅当操作需要将结果返回到驱动程序时才计算转换。这种设计使 Spark 能够更高效地运行。
转换操作
常用的转换操作如下表。很多转换操作传入的都是一个函数,这是Scala的语法,可以理解为Java的Lambda表达式。用多了就习惯了。
| Transformation | Meaning |
|---|---|
| map(func) | Return a new distributed dataset formed by passing each element of the source through a function func. |
| filter(func) | Return a new dataset formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator<T> => Iterator<U> when running on an RDD of type T. |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator<T>) => Iterator<U> when running on an RDD of type T. |
| sample(withReplacement, fraction, seed) | Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed. |
| union(otherDataset) | Return a new dataset that contains the union of the elements in the source dataset and the argument. |
| intersection(otherDataset) | Return a new RDD that contains the intersection of elements in the source dataset and the argument. |
| distinct([numPartitions])) | Return a new dataset that contains the distinct elements of the source dataset. |
| groupByKey([numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs. Note: If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will yield much better performance.Note: By default, the level of parallelism in the output depends on the number of partitions of the parent RDD. You can pass an optional numPartitions argument to set a different number of tasks. |
| reduceByKey(func, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral "zero" value. Allows an aggregated value type that is different than the input value type, while avoiding unnecessary allocations. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| sortByKey([ascending], [numPartitions]) | When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the boolean ascending argument. |
| join(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin. |
| cogroup(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (Iterable<V>, Iterable<W>)) tuples. This operation is also called groupWith. |
| cartesian(otherDataset) | When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). |
| pipe(command, [envVars]) | Pipe each partition of the RDD through a shell command, e.g. a Perl or bash script. RDD elements are written to the process's stdin and lines output to its stdout are returned as an RDD of strings. |
| coalesce(numPartitions) | Decrease the number of partitions in the RDD to numPartitions. Useful for running operations more efficiently after filtering down a large dataset. |
| repartition(numPartitions) | Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network. |
| repartitionAndSortWithinPartitions(partitioner) | Repartition the RDD according to the given partitioner and, within each resulting partition, sort records by their keys. This is more efficient than calling repartition and then sorting within each partition because it can push the sorting down into the shuffle machinery. |
执行操作
执行操作触发计算,返回结果。没有执行操作的RDD不会生成Job,没有实际意义。
| Action | Meaning |
|---|---|
| reduce(func) | Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
| collect() | Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
| count() | Return the number of elements in the dataset. |
| first() | Return the first element of the dataset (similar to take(1)). |
| take(n) | Return an array with the first n elements of the dataset. |
| takeSample(withReplacement, num, [seed]) | Return an array with a random sample of num elements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed. |
| takeOrdered(n, [ordering]) | Return the first n elements of the RDD using either their natural order or a custom comparator. |
| saveAsTextFile(path) | Write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark will call toString on each element to convert it to a line of text in the file. |
| saveAsSequenceFile(path) (Java and Scala) |
Write the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system. This is available on RDDs of key-value pairs that implement Hadoop's Writable interface. In Scala, it is also available on types that are implicitly convertible to Writable (Spark includes conversions for basic types like Int, Double, String, etc). |
| saveAsObjectFile(path) (Java and Scala) |
Write the elements of the dataset in a simple format using Java serialization, which can then be loaded using SparkContext.objectFile(). |
| countByKey() | Only available on RDDs of type (K, V). Returns a hashmap of (K, Int) pairs with the count of each key. |
| foreach(func) | Run a function func on each element of the dataset. This is usually done for side effects such as updating an Accumulator or interacting with external storage systems. Note: modifying variables other than Accumulators outside of the foreach() may result in undefined behavior. |
洗牌
shuffle (洗牌)是 Spark 重新分配数据的机制。我们在学习MapReduce的时候,在reduce阶段,数据就是根据key值通过shuffle操作到达不同的分区。这个操作涉及到数据复制,代价很高。应通过合理的API调用或者调优,尽量避免发生shuffle。
在程序本地执行时,4040端口可以查看DAG,从图中能看出是否有shuffle发生。
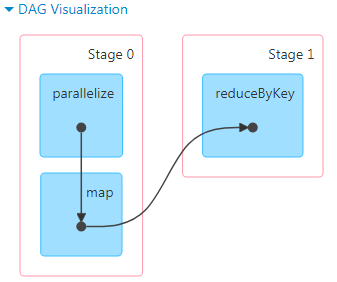
上图对应的代码如下
val conf = new SparkConf().setAppName("Test").setMaster("local") val sc = new SparkContext(conf) sc.setLogLevel("ERROR") val rdd = sc.parallelize(Array(1,2,3,2,1,4,5,2)) val kv = rdd.map(x=>(x,1)).reduceByKey(_+_) kv.foreach(println)
在调用reduceByKey时,作业产生了新的Stage1,这个过程就发生了shuffle,把相同key值的数据重新分区,计算出结果。
性能影响
发生shuffle时,它涉及到磁盘I/O,数据序列化和网络I/O,因此代价非常高。部分shuffle操作会用到相当多的堆内存,因为它在传输数据的过程中,会用到内存数据结构来组织数据。其中,reduceByKey和aggregateByKey这两个算子是在数据映射端创建内存数据结构,其他的byKey操作是在归约端创建。如果数据不适合放在内存里,Spark会将其溢写到磁盘上,从而导致额外的磁盘I/O开销和垃圾回收。
Shuffle还会在磁盘上生成大量中间文件。从 Spark 1.3 开始,这些临时文件会一直保留,直到相应的 RDD 不再使用并被垃圾回收。这样做是为了在重新计算血统时不需要重新创建 shuffle 文件。如果应用程序保留对这些 RDD 的引用或者 GC 不频繁启动,那长时间运行的 Spark 作业可能会消耗大量磁盘空间。
其他
Spark支持把数据持久化在内存中或者磁盘上,在性能调优的时候根据不同场景做出选择,这里不再赘述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号