大数据学习(20)—— Zookeeper介绍
ZooKeeper是什么
就像相声大师冯巩每次出场都说:“亲爱的观众朋友们,我想死你们啦”一样,我再强调一次,学习大数据官网很重要。Zookeeper官网看这里ZooKeeper
ZooKeeper 是一个开源的分布式协调服务,它本身也是分布式设计。它提供了一组简单的原语,基于这些指令,分布式应用能够实现同步、配置更新和分组等高级服务。它的设计宗旨是简单易用,它使用了树形结构的文件目录作为数据模型。
协调服务要做到准确无误是很难的,它容易引发条件竞争和死锁。ZooKeeper的目的,就是让分布式应用不在协调服务上耗费精力,只需要关注业务逻辑实现。通俗地讲,ZooKeeper就是一场交响乐的总指挥,你钢琴师、鼓乐手不用考虑乐队其他成员在干嘛,只看总指挥的指示就好了。
为啥叫ZooKeeper
ZooKeeper顾名思义,动物园管理员,它长这样

这个小伙子管了哪些东西呢?看下面




有啥发现没?是不是全是动物?
ZooKeeper架构

这是一个主从复制集群,每个Server里的数据一样,多个ZooKeeper实例之间通过选举确定一个leader,写操作都是leader来执行(follower节点把写请求转发给leader),读操作可以是客户端连接的follower节点处理。
Client通过TCP连到一个ZooKeeper上,向ZooKeeper集群进行发送请求、接收响应、监听事件、发送心跳等操作。如果Client连接的ZooKeeper宕机,它会自动连接到其他节点。
数据模型
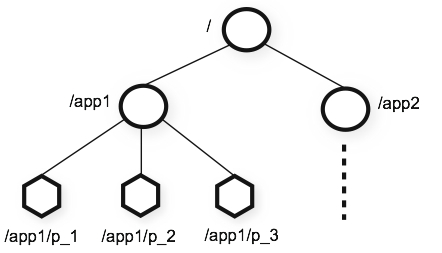
ZooKeeper的命名空间就像一个标准的文件系统,每个节点都是一个路径,叫Znode,可以存放数据。每个节点是一个键值对,它只能存放KB级的数据,比如状态信息、配置、位置信息等等。Znode会记录一些状态信息,比如数据版本号、访问控制列表变更、时间戳等等,用来做协调控制。每当数据更新的时候,版本号会+1。
还有一类节点叫临时节点,当创建这些节点的客户端还活着的时候它就一直存在,但连接断开之后就消失了。
监听
这个概念类似于Java中的actionListener。客户端可以在节点上设置监听,当节点数据发生变化的时候,客户端会收到通知。zk3.6版本之后,监听是永久的。在这个版本之前,监听被触发之后就自动失效。
特性
ZooKeeper基于内存处理数据,速度非常快,而且它提供了一系列机制来保证提供可靠的服务。
- 顺序执行:按照客户端发送指令的先后顺序来执行操作
- 原子性:更新操作不存在中间状态,只有成功或失败两种选择
- 统一视图:集群里的所有服务器都提供统一的视图。写请求通过一致性协议,保证所有Server一致。
- 可靠
- 快速
性能
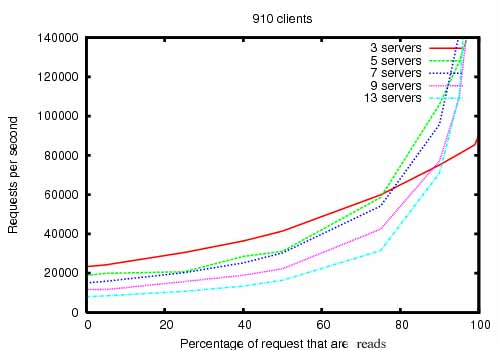
如上图所示,使用910个客户端来发起读写请求,当读请求的比例越来越高时,每秒能够处理的请求呈抛物线上升。因为写请求要保证所有节点数据一致,会消耗性能。
当读写比例大于10:1的时候,3个server每秒能支撑8万多的读请求,5个以上的server每秒能支撑14万以上的读请求。
上图还能看到一个很有意思的现象,当读请求比例是0的时候,server数越少,并发越高。server太多了,写的时候保存一致会花费更长的时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号