大数据学习(08)—— Hive简介
前面的Hadoop学习是非常体系化的,有主线有细节。到了Hive这里,知识点非常零散,感觉没有什么主线能把它串起来。从官方网站上就能看出这点差异。
什么是Hive
Hive是一个基于Hadoop的企业级数据仓库,它的图标是大象头和蜜蜂身体。大象头表示它跟Hadoop有非常紧密的联系。
Hive通过类似SQL的方式做数据分析,它的数据存储在HDFS,而Hive SQL会转化为MapReduce任务。
由Hive SQL语句到具体的任务执行还需要经过解释器,编译器,优化器,执行器四部分才能完成。
(1)解释器:调用语法解释器和语义分析器将SQL语句转换成对应的可执行的java代码或者业务代码
(2)编译器:将对应的java代码转换成字节码文件或者jar包
(3)优化器:从Hive SQL语句到java代码的解析转化过程中需要调用优化器,进行相关策略的优化,实现最优的查询性能
(4)执行器:当业务代码转换完成之后,需要上传到MapReduce的集群中执行
为什么会出现Hive
当我们使用Hadoop来做数据分析的时候,编写MapReduce程序是非常麻烦的。一个MapReduce包含Map任务、自定义分区方法、排序比较器、分组比较器、Reduce任务。对像我这样十年的Java码农来说,编写一个完整的MapReduce程序尚且不是那么容易,可想而知对于那些没有Java基础的人来说,这种方式学习成本非常高。况且有相当一部分做数据分析工作的人是非计算机专业的,让他们写MapReduce代码几乎是不可能的。
这种情况下,Hive就出现了,它能够极大地降低数据分析门槛,只需要学习一些简单的类似SQL的语法就能快速上手数据分析工作。
Hive架构

Client
CLI(Command Line Interface):用户可以使用Hive自带的命令行接口执行Hive QL、设置参数等功能
JDBC/ODBC:用户可以使用JDBC或者ODBC的方式在代码中操作Hive
Web GUI:浏览器接口,用户可以在浏览器中对Hive进行操作(2.2之后淘汰)
Thrift Server
Thrift服务运行客户端使用Java、C++、Ruby等多种语言,通过编程的方式远程访问Hive。它介于Client和Driver之间。
Driver
Driver是Hive的核心,其中包含解释器、编译器、优化器等各个组件,完成Hive SQL查询从词法分析、语法分析、编译、优化以及查询计划的生成,生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行。
Metastore
Hive的元数据存储服务,一般将数据存储在关系型数据库中,为了实现Hive元数据的持久化操作,Hive的安装包中自带了Derby内存数据库,但是在实际的生产环境中一般使用mysql来存储元数据。
Hive执行流程
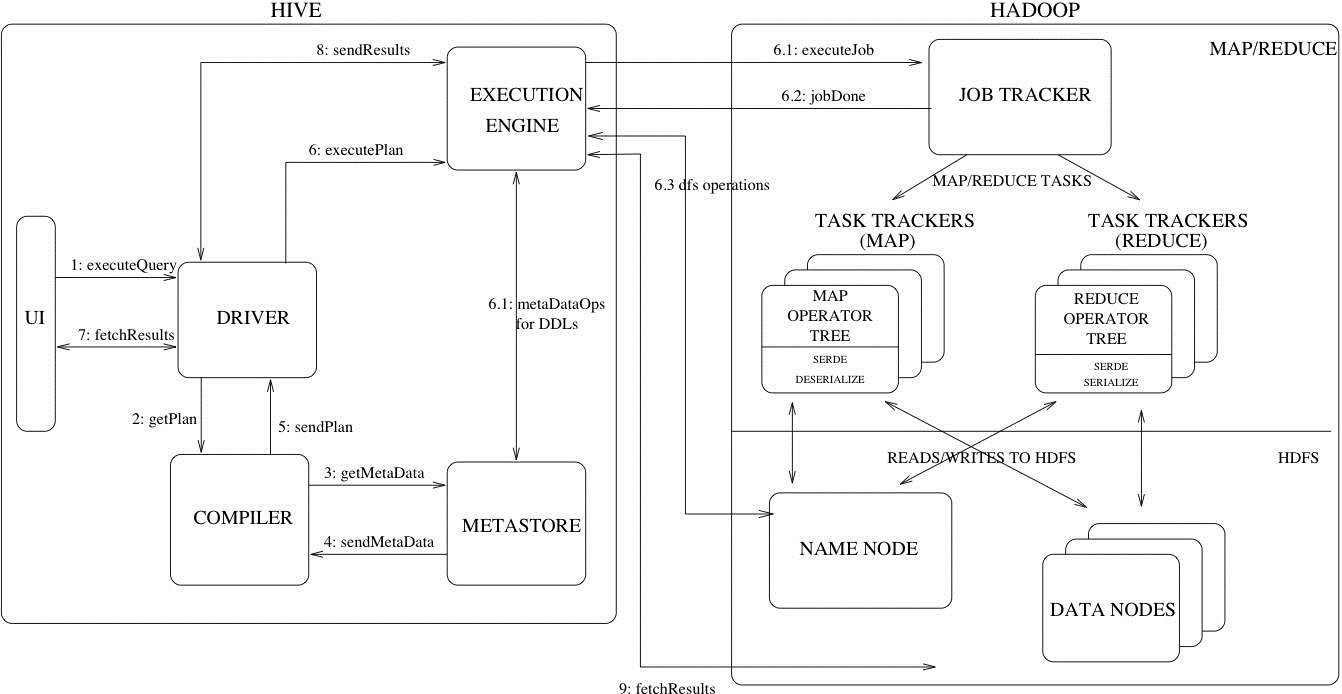
这张图详细描述了一个HiveSQL请求是怎么转换成MapReduce任务的。右边Hadoop的部分不是很准确,从Hadoop2.x开始,就由Yarn接管资源调度了,JobTracker还是Hadoop1.x特有的东西。
对于绝大多数使用Hive的人来说,不需要关注执行流程,优化器有100多个优化方法来帮助我们把HiveSQL转换成高效的MapRedcue任务,让使用者更加专注于业务逻辑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号