大数据学习(05)——MapReduce/Yarn架构
Hadoop1.x中的MapReduce
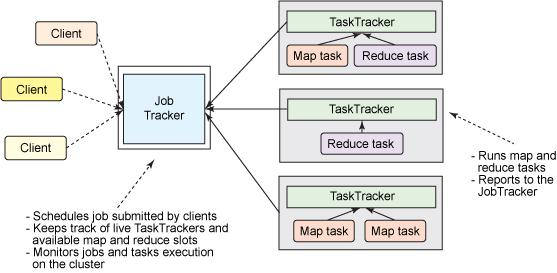
MapReduce作为Hadoop最核心的两个组件之一,在1.0版本中就已经存在了。它包含这么几个角色:
- Client
- 多数情况下Client的作用就是向服务端发送请求并返回结果。但是在MapReduce里,Client的作用可不小。
- Client根据传入的数据参数,向HDFS的NameNode获取元数据信息,计算出Map任务的split切片信息。split跟Block有映射关系,Client可以计算出split在文件中的偏移量,再根据计算向数据移动的原则,建议JobTracker将计算程序移动到哪些主机节点。
- Client生成计算程序的配置文件。
- Client将程序jar包、split清单、xml配置文件上传到HDFS的目录中(10副本,避免多个Map任务读取程序文件造成瓶颈)。
- Client调用JobTracker启动计算程序,告知计算需要的文件放在哪里。
- JobTracker
- 主从架构中的主节点,像HDFS中的NameNode。它有两个作用:资源管理和任务调度。
- 从HDFS获取split清单。
- JobTracker收到TaskTracker心跳时,记录下TaskTracker当前的资源情况,为任务调度做准备。
- 按照计算向数据移动的原则,根据资源使用情况为任务分配离数据最近的TaskTracker。
- TaskTracker
- 主从架构中的从节点,像HDFS中的DataNode,相同的架构会出现在大数据技术的多个地方。
- 为尽量实现本地计算而不需要网络传输,通常TaskTracker和HDFS的DataNode在相同主机上。
- 与JobTracker的每次心跳时,汇报自身的资源状况。
- 心跳时从JobTracker获取MapReduce任务。
- 从HDFS下载计算程序相关的文件,启动MapTask/ReduceTask。
在上面的架构中,JobTracker要为所有的计算任务做调度,而且全局只有一个进程不利于水平扩展。这个架构最大的缺点是单点故障风险,另外资源和调度耦合太高,资源管理难以扩展到其他计算框架。为了解决上述问题,在Hadoop2.x中,MapReduce的资源管理被切割出来,成为一个独立的资源管理模块Yarn。
MapReduce on Yarn
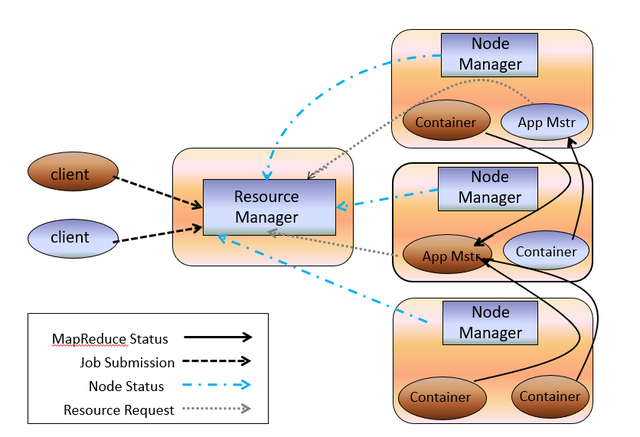
为了解决MapReduce1.x中存在的问题,Hadoop2.x中增加了Yarn模块,专门用来做资源管理。
Yarn包含角色:
- Resource Manager
- 负责整体资源的管理
- 在客户端发起计算任务时,选择空闲资源多的节点,通知Node Manager启动Container
- Node Manager
- 与Resource Manager心跳时,报告自身主机节点的资源情况
- 接收Resource Manager的指令,启动Container
- ApplicationMaster
- 相当于JobTracker不带资源管理功能,只负责任务调度
- Container
- 可用资源的集合,执行具体的计算任务
- 反射生成计算任务的实例
MapReduce包含角色:
- MRClient
- 将split切片清单、xml配置、程序jar上传到HDFS
- 向Resource Manager发请求,申请创建AppMaster
- MRAppMaster
- 在Container中反射生成MRAppMaster
- 从HDFS下载split切片清单
- 向Resource Manager申请执行计算任务的资源
- 向Name Manager分配的Container中调度计算任务并监控其运行状态
- Task
- Container反射生成计算任务的实例,执行Map/Reduce计算任务
新架构解决了MapReduce1.x中的痛点。它的任务调度进程MRAppMaster是每个客户端作业对应一个,单点故障不再是全局性的,并且MRAppMaster和Container都有失败重试的功能,分别由ResourceManager和MRAppMaster来完成重试的动作。任务调度压力也分散到不同的进程里。不同的计算框架可以共用Yarn的资源管理功能。
Yarn本身也是高可用架构,通过Zookeeper选主,架构如下图
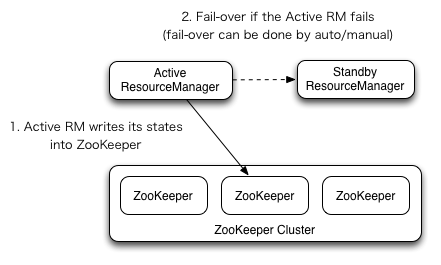
这个架构图是不是跟HDFS里的NameNode高可用非常像?可以看到主备高可用的方案都是相似的,可以说是形成了一种设计模式。
这个图比NameNode少了ZKFS这个角色,不是说它不需要了,而是它更方便地集成到ResourceManager中去了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号