大数据学习(04)——MapReduce原理
前两篇文章介绍了HDFS的原理和高可用,下面再来介绍Hadoop的另外一个模块MapReduce。它的思想是很多技术的鼻祖,值得一学。
MapReduce是什么
MapReduce是一个分布式计算系统,它可以类比为SQL里的select ...group by...
它被分为两个阶段。第一个阶段叫Map,它每次处理一条原始数据的映射、转换,并将中间结果合并、排序,生成Reduce阶段的输入数据。第二个阶段叫Reduce,它拉取Map处理好的数据做排序,一次处理一组数据,生成最终结果。
从上面的定义可以看出,MapReduce是用来做集合的分组汇总操作,它只关心想要的少部分字段,对于原始记录的大多数字段都会忽略掉。
迭代器模式
为啥要在这里提迭代器模式?这是一位老师总结出来的心得。他认为MapReduce的处理过程跟迭代器模式非常像。
我们来看看迭代器模式的定义。学过设计模式的都知道,设计模式包含定义、参与者、场景等等。这里我们来看看定义和场景。
定义:迭代器模式(Iterator),提供一种方法顺序访问一个聚合对象中的各种元素,而又不暴露该对象的内部表示。
场景:
-
访问一个聚合对象的内容而无需暴露它的内部表示
-
支持对聚合对象的多种遍历
-
为遍历不同的聚合结构提供一个统一的接口
目前还看不出来迭代器与MapReduce的相似之处,先写这里以后来看。
Map原理
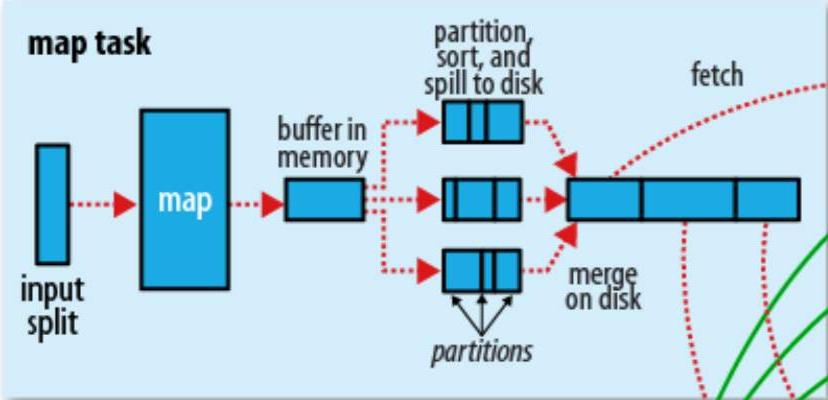
在HDFS中,文件是以Block为单位来存放的。但是在Map任务中,输入的单位是split,它跟Block可以是1:1、1:N、N:1的关系。也就是说
- 一个Block块可以被一个Map任务处理
- 一个Block块可以被多个Map任务处理,每个Map只处理其中一部分
- 多个Block块可以合并被一个Map任务处理
Map的处理是在内存里的,而一个Block块的大小可以是128M,也可以是1G,这取决于你在配置文件中的定义。在默认1:1的情况下,如果Block块太大,超出了Map进程所占用的内存,那就没办法一次放到内存中。另外,Map是针对每一条记录来做映射、转换的,它一次只需要读取一条记录,不关心后面还有多少记录。这就可以借鉴迭代器的处理方式,每次从文件读一条记录,处理完之后再判断后面还有没有记录,有的话继续处理,没有就结束。
每条记录经过Map处理的结果是一个K,V,P的三元组,K,V是键和值这好理解,K值相同的记录是一组。P是K的散列值(对Reduce任务数量做散列),决定了它会被哪一个Reduce任务拉取。
当Map任务处理了一部分数据之后,它需要把内存里的处理结果落盘,以便释放空间来处理后续的文件。在落盘之前,它会做这么一件事,就是在内存中,对处理结果排序。首先根据P来排序,不同P值的数据会被不同的Reduce拉取。同一个P值的数据再根据K来排序。排完序的数据就可以落盘了。经过多次这样的操作,它会生成很多个小文件,这些小文件之间内部有序外部无序。在原始文件处理完毕,小文件全部生成之后,使用归并算法将小文件合并成一个中间结果文件,这个文件总体来讲先以P排序,相同P值再以K排序。至此,Map阶段的任务就完成了。
Reduce原理
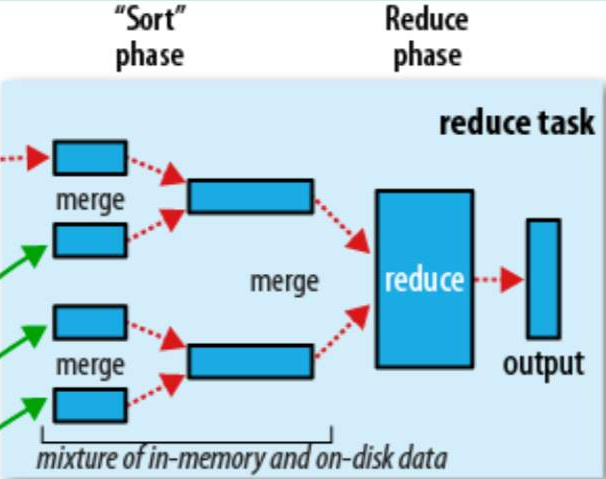
Reduce阶段它的大处理单元是分区,即Map阶段处理后的P值。它的小处理单元是组,即K值相同的一组数据。
首先,它从所有的Map任务节点拉取自己分区的数据,然后将这些文件归并排序生成Reduce任务的输入数据。经过Reduce计算后,生成最终结果数据。
Map和Reduce的关系
Map与Reduce两个阶段的任务是线性阻塞的。
Map的结果集中,Key值相同的数据属于同一个分组,一个组是不能被分割到不同的Reduce任务去处理的。
Map任务的个数取决于HDFS文件的Block数(Block:Split=1:1情况下),Reduce任务个数可以人工确定。
Map任务与Reduce任务的比例可以是N:1、N:N、1:1、1:N等多种情况。当任务数为1时,会牺牲系统的并发度。当任务数为N时,会增加整个系统的资源开销。
一个实际的任务很难由一次MapReduce过程完成,它会将多个MapReduce任务组成一个pipeline,上一次Reduce的输出成为下一次Map任务的输入,经过多次处理才能获取最终结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号