[LeetCode]HashTable主题系列{第3,36,49,94,136,138,187,202,204,205,290,347,389,409,438,451,463,500,508,560,594,599题}
1. 内容介绍
开一篇文章记录在leetcode中HashTable主题下面的题目和自己的思考以及优化过程,具体内容层次按照{题目,分析,初解,初解结果,优化解,优化解结果,反思}的格式来记录,供日后复习和反思[注:有些题目的解法比较单一,就没有优化过程]。题目的顺序按照leetcode给出的题目顺序,有些题目在并不是按照题目本身序号顺序排列的,也不是严格按照难易程度来排列的。
因此,这篇文章并不具有很强的归类总结性,归类总结性知识将会在其他文章记录,本篇重点在记录解题过程中的思路,希望能对自己有所启发。
2. 题目和解题过程
2.1 Longest Substring Without Repeating Characters
- 题目:Given a string, find the length of the longest substring without repeating characters.Examples:Given
"abcabcbb", the answer is"abc", which the length is 3.Given"bbbbb", the answer is"b", with the length of 1.Given"pwwkew", the answer is"wke", with the length of 3. Note that the answer must be a substring,"pwke"is a subsequence and not a substring. - 分析:题目点明了三个要素:子串,无重复字符,最长。其中子串意味着选取的字符串在源字符串中是连续存在的,无重复和最长是自明的。题目的难点之一是对于一个字符,如何在现有子串中快速判重,显然,遍历搜索时间复杂度是O(n),红黑树set查询的时间复杂度是O(logn),而哈希表unordered_set拥有最快速的速度,其时间复杂度是O(1)。以下先给出一个暴力解法,便于理清基本思路和观察可以优化的地方,同时也方便拿时间和优化解法的时间进行对比,凸显算法设计的重要性。
- 初解:先从源字符串S头部第一个字符开始,向后连续生成子串,对于每一个后续的字符进行判重,如果重复则记录下当前子串长度和内容,然后移动到第二个字符重复之前的过程,依次类推,直到源字符串的最后一个字符。其中如果遇到比当前最长无重复子串长度更长的子串,则更新此记录。该解法的时间复杂度约为O(n2)。
class Solution { public: int lengthOfLongestSubstring(string s) { string longest_substr=""; for(int index=0; index < s.size(); ++index) { set<char> char_set; string tmp_substr = ""; find_longest_substr(s, index, char_set, tmp_substr); if(tmp_substr.size() > longest_substr.size()) longest_substr = tmp_substr; } return longest_substr.size(); } void find_longest_substr(string& s, int index, set<char>& char_set, string& tmp_substr) { for(int start = index; start < s.size(); ++start) { if(char_set.find(s[start])==char_set.end()) { char_set.insert(s[start]); tmp_substr+=s[start]; } else break; } } };
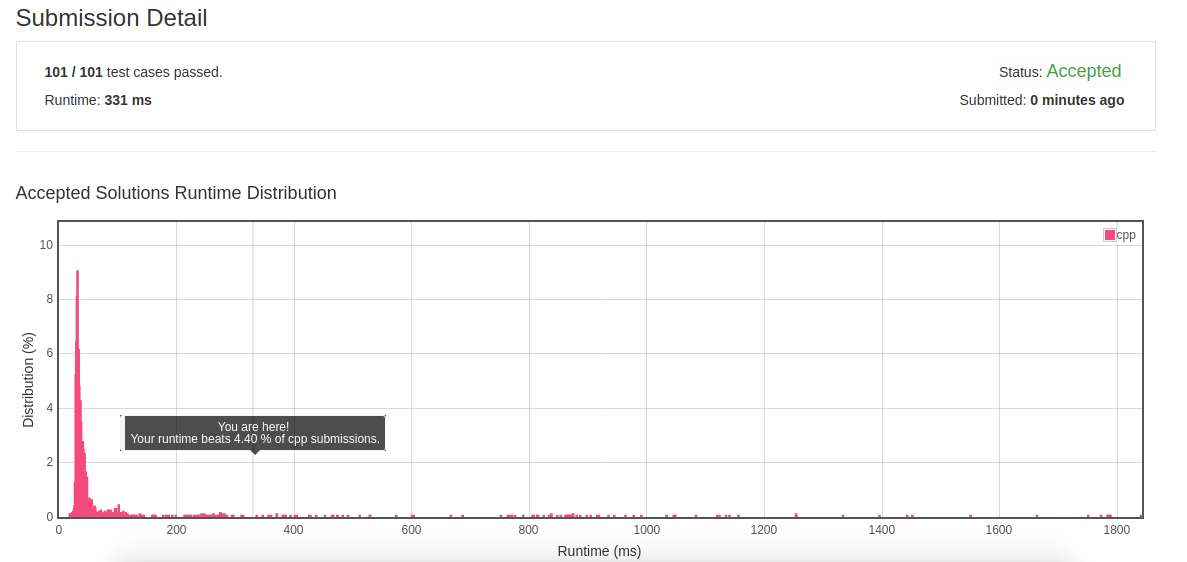
- 初解结果:
![]()
- 优化解法1:初解中每次遇到重复字符时,重新从当前起始字符的下一个字符开始搜索,这样会做额外的无用功,因为例如字符串abcdad,从a开始搜索时a字符重复但是中间字符串bcd并未重复,因此可以不必重新从b开始搜索,而是将首部的a去掉直接从bcda后的d开始继续搜索。根据上面的例子可以总结出一个规律:当出现重复字符时,只需要将该字符在子串中重复的位置以前的字符去除掉,然后判断当前剩余的字符长度加上现有子串长度之和小于当前计算出来的最长子串长度时,可以终止搜索了,否则继续沿着当前搜索的位置向后搜索,直到源字符串结尾。此处的优化思想是从现有结果中提取无需重复计算的结果,节省计算时间,减少总体重复计算的总量。至于查重方法,暂时使用红黑树实现的set。
class Solution { public: int lengthOfLongestSubstring(string s) { if(s.size() <= 1) return s.size(); int length = 0, last_pos = 0; set<char> substring; for(int i = 0; i < s.size(); ++i) find_longest_substr(s, i, substring, last_pos, length); if(length < substring.size()) length = substring.size(); return length; } void find_longest_substr(string& s, int& index, set<char>& substring, int& last_pos, int& length) { if(substring.find(s[index]) == substring.end()) substring.insert(s[index]); else erase_duplicate_subsubstring(s, index, substring, last_pos, length); } void erase_duplicate_subsubstring(string& s, int& index, set<char>& substring, int& last_pos, int& length) { if(length < substring.size()) length = substring.size(); for(int j = last_pos; j < index; ++j) { substring.erase(s[j]); if(s[j]==s[index]) { last_pos = j+1; break; } } substring.insert(s[index]); } };
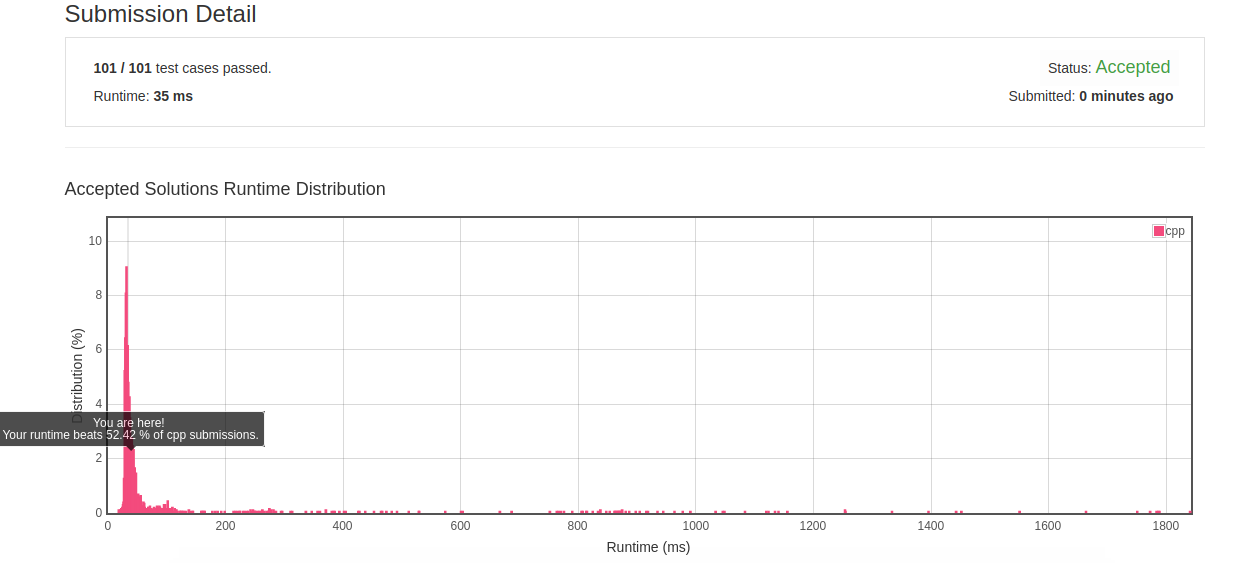
- 优化结果1:
![]()
- 优化解法2:将查重方式改为哈希表unordered_set。
- 优化结果2:结果差别不大,不予展示。
2.2 Valid Sudoku
- 题目:Determine if a Sudoku is valid, according to: Sudoku Puzzles - The Rules.The Sudoku board could be partially filled, where empty cells are filled with the character
'.'.Note:A valid Sudoku board (partially filled) is not necessarily solvable. Only the filled cells need to be validated.![]()
- 分析:题目要求判断数独是否是有效的,也就是要判断是否满足三个条件:行无重复数字,列无重复数字,九宫格无重复数字。
- 初解:按照三个条件来检查,先检查行,后检查列,最后检查九宫格,查重的方式是使用哈希表来判断是否已经存在该数字。
class Solution { public: bool isValidSudoku(vector<vector<char>>& board) { if(row_check(board) == false) return false; if(col_check(board) == false) return false; if(matrix_check(board)==false) return false; return true; } bool row_check(vector<vector<char>>& board) { for(auto row:board) { vector<bool> check_vec(10, false); for(auto c:row) { if(c != '.') { int num = (int)c - 48; if(check_vec[num]==true) return false; check_vec[num]=true; } } } return true; } bool col_check(vector<vector<char>>& board) { for(int col=0; col < 9; ++col) { vector<bool> check_vec(10, false); for(int row=0; row < 9; ++row) { if(board[row][col]!='.') { int num = (int)board[row][col] - 48; if(check_vec[num]==true) return false; check_vec[num]=true; } } } return true; } bool matrix_check(vector<vector<char>>& board) { for(int row=0; row < 9; row+=3) for(int col=0; col < 9; col+=3) if(sub_matrix_check(board, row, col)==false) return false; return true; } bool sub_matrix_check(vector<vector<char>>& board, int start_row, int start_col) { vector<bool> check_vec(10, false); for(int row = start_row; row < start_row+3; ++row) for(int col = start_col; col < start_col+3; ++col) { if(board[row][col]!='.') { int num = (int)board[row][col] - 48; if(check_vec[num]==true) return false; check_vec[num]=true; } } return true; } };
- 初解结果:
![]()
- 优化解法:
- 优化结果:
- 反思:

2.3 Group Anagrams
- 题目:Given an array of strings, group anagrams together.For example, given:
["eat", "tea", "tan", "ate", "nat", "bat"],
Return:[ ["ate", "eat","tea"], ["nat","tan"], ["bat"] ]
Note: All inputs will be in lower-case. - 分析:题目要求对含有相同字符但顺序可以不同的字符串进行归类,无序这个特点使得我们无法使用按顺序对两个字符串进行字符比较的操作,但是换个角度考虑,判断一个字符串中的所有字符是否都在另一个字符串中出现,也能完成比较操作,但是这要求互相验证,因为有可能一个是另一个的子集。除此之外,还可以看到,等价字符串的字母代表的整数值之和也是一样的,但是反之不成立。考虑到两者的结合,这样可以快速过滤一定不可能等价的字符串,对于有可能等价的字符串进行互相验证,验证方法可以使用哈希表,其时间复杂度是O(1)。
- 初解:直接从头开始遍历字符串数组,对于每一个字符串,都向后与尚未分类的字符串进行哈希互相验证,成功的归为一类,否则跳过。时间复杂度为O(n2 * k), k取最长的字符串长度。
class Solution { public: vector<vector<string>> groupAnagrams(vector<string>& strs) { vector<bool> flag(strs.size(), false); vector<vector<string>> res; for(int i=0; i < strs.size(); ++i) { if(flag[i]==true) continue; flag[i]=true; vector<string> group{strs[i]}; vector<bool> char_table(27, false); int hash_val = 0; for(auto c:strs[i]) { char_table[c-96]=true; hash_val += (c-96); } for(int j=i+1; j < strs.size(); ++j) { if(flag[j]==true) continue; if(hash_compare(strs[j], char_table, hash_val)==true) { group.push_back(strs[j]); flag[j]=true; } } res.push_back(group); } return res; } bool hash_compare(string& target, vector<bool>& char_table, int& hash_val) { vector<bool> target_char_table(27, false); int target_hash_val = 0; for(auto c:target) { target_char_table[c-96]=true; target_hash_val += (c-96); } if(target_hash_val != hash_val) return false; auto iter_a = char_table.begin(), iter_b = target_char_table.begin(); for(; iter_a != char_table.end(); ++iter_a, ++iter_b) { if(*iter_a != *iter_b) return false; } return true; } };
- 初解结果:
![]()
- 优化解法1:显然时间复杂度太高,需要在遍历的过程中加速搜索那些有可能等价的字符串,因此,先对所有的字符串进行哈希求值,然后在遍历的过程中据此筛选掉不可能等价的字符串。
class Solution { public: vector<vector<string>> groupAnagrams(vector<string>& strs) { vector<bool> flag(strs.size(), false); vector<vector<string>> res; vector<int> hash_val_vec(strs.size(), 0); for(int i=0; i < strs.size(); ++i) for(auto c:strs[i]) hash_val_vec[i]+=(c-96); for(int i=0; i < strs.size(); ++i) { if(flag[i]==true) continue; flag[i]=true; vector<string> group{strs[i]}; vector<int> char_table(27, 0); for(auto c:strs[i]) char_table[c-96]+=1; for(int j=i+1; j < strs.size(); ++j) { if(flag[j]==true || hash_val_vec[i]!=hash_val_vec[j]) continue; if(hash_compare(strs[j], char_table)==true) { group.push_back(strs[j]); flag[j]=true; } } res.push_back(group); } return res; } bool hash_compare(string& target, vector<int> char_table) { for(auto c:target) char_table[c-96]-=1; for(auto num:char_table) if(num!=0) return false; return true; } };
- 优化结果1:
![]()
- 优化解法2:优化解法1中利用了字符串的哈希值粗略的将字符串数组进行了归类,在对每个类别中的字符串进行双向验证,效率依然太低。考虑到等价的字符串仅仅是顺序不同,字符集合是相同的,因此尝试使用字符集合本身来做分类,对于每个字符串,都将字符串中的字符进行排序,得到一个有序字符串,然后以此作为索引,将无序但等价的字符串存放到同一个集合中,此集合使用哈希表来访问。总的时间复杂度是O(n * k2 * logk), k取最长的字符串长度。
class Solution { public: vector<vector<string>> groupAnagrams(vector<string>& strs) { unordered_map<string, multiset<string>> mp; for (string s : strs) { string t = s; sort(t.begin(), t.end()); mp[t].insert(s); } vector<vector<string>> anagrams; for (auto m : mp) { vector<string> anagram(m.second.begin(), m.second.end()); anagrams.push_back(anagram); } return anagrams; } };
- 优化结果2:
![]()
- 反思:对于无序对象的比较,先排序在比较,或者使用哈希双向验证,但是对于归类访问时,使用哈希表。本题目中对于无序对象的比较还具有一个索引作用,因此最好排序会后在比较,而如果使用哈希双向验证,则索引过程需要自定义,且需要比较整个字母哈希表而不是仅字符串长度。
2.4 Binary Tree Inorder
- 题目:Given a binary tree, return the inorder traversal of its nodes' values.For example:
Given binary tree[1,null,2,3],1 \ 2 / 3return[1,3,2]. - 分析:中序遍历二叉树是对于给定结点,先遍历左子树,再遍历给定结点,最后遍历友子树。整个过程是递归向下的。
- 解法1:使用系统栈实现递归解法,时间复杂度O(n),空间复杂度O(n)。
- 解法2:使用手工栈实现迭代解法,时间复杂度O(n),空间复杂度O(n)。
- 解法3:使用哈希表加上手工栈实现迭代解法,时间复杂度O(n),空间复杂度O(n)。
- 解法4:使用线索二叉树,时间复杂度O(n),空间复杂度O(1)。
2.5 Single Number
- 题目:Given an array of integers, every element appears twice except for one. Find that single one.Note:
Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory? - 分析:简单思路可以考虑使用哈希表来统计每个整数的出现次数,但是要求使用线性时间且不需要额外内存空间则需要对简单思路的实现进行压缩化处理,即将所有的数都存到一个变量里面,然后还能进行对这些数进行区分,这需要用到异或(XOR)运算,异或本质的思想是将两个数按位标示中不同的位保存下来,而相同的位去除掉,这就起到了一个将不同的数存到同一个地方且能将这两个数区分开来,而每个独特的整数按位表示的时候彼此之间一定有一位的值不同,那么累加起来也能够对这些值进行区分。
- 初解:从头开始对数组进行遍历并执行异或操作,最后的结果就是只出现一次的数。
class Solution { public: int singleNumber(vector<int>& nums) { int res = 0; for(auto iter:nums) res^=iter; return res; } };
- 初解结果:
![]()
- 反思:对于仅仅区分不同的数且最终只保留一个数的值时,异或操作可以起到非常高效的作用。
2.6 Copy List with Random Pointer
- 题目:A linked list is given such that each node contains an additional random pointer which could point to any node in the list or null.Return a deep copy of the list.
- 分析:这道题要求对链表进行复制,但是难点在于每个副本结点上的随机指针在第一次复制的时候无法获取在原始链表中实际对应的位置,因为整个链表尚未构造完毕。当构造完之后,为了能获取原始链表中随机指针指向的位置到副本链表中随机指针指向的位置的映射关系,我们需要对这种映射关系进行一个存储和访问。
- 初解:使用哈希表来存储原始链表结点到副本链表结点的映射关系,然后在对副本链表中的随机指针进行设置时参考原始链表中随机指针指向的原始链表结点的位置,再映射到对应的副本链表结点即可。
/** * Definition for singly-linked list with a random pointer. * struct RandomListNode { * int label; * RandomListNode *next, *random; * RandomListNode(int x) : label(x), next(NULL), random(NULL) {} * }; */ class Solution { public: RandomListNode *copyRandomList(RandomListNode *head) { RandomListNode* copy_head = nullptr; RandomListNode** copy_cur = ©_head; RandomListNode** cur = &head; unordered_map<RandomListNode*, RandomListNode*> copy_map;; while(*cur!=nullptr) { *copy_cur = new RandomListNode((*cur)->label); copy_map.insert(std::make_pair(*cur,*copy_cur)); copy_cur = &((*copy_cur)->next); cur = &((*cur)->next); } cur = &head; copy_cur = ©_head; while(*cur!=nullptr) { auto random_pointer = (*cur)->random; if(random_pointer!=nullptr) { auto pair_iter = copy_map.find(random_pointer); (*copy_cur)->random = pair_iter->second; } copy_cur = &((*copy_cur)->next); cur = &((*cur)->next); } return copy_head; } };
- 初解结果:
![]()
- 反思:对于构建带有随机索引的数据结构副本需要使用映射关系来辅助建立。
2.7 Repeated DNA Sequence
- 题目:All DNA is composed of a series of nucleotides abbreviated as A, C, G, and T, for example: "ACGAATTCCG". When studying DNA, it is sometimes useful to identify repeated sequences within the DNA.Write a function to find all the 10-letter-long sequences (substrings) that occur more than once in a DNA molecule.For example,
Given s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT", Return: ["AAAAACCCCC", "CCCCCAAAAA"].
- 分析:题目的两个要求:1.找出所有10字节长度的子串 2.筛选出重复的子串。涉及到查重操作。
- 初解:简单暴力,直接对所有10字节连续子串进行枚举,并存储到哈希表中进行统计重复次数,最后只输出那些重复次数大于等于2的子串。如果不考虑字符串比较的时间,那么该算法的时间复杂度是O(n)。
class Solution { public: vector<string> findRepeatedDnaSequences(string s) { vector<string> res; if(s.size()<10) return res; unordered_map<string, int> DNA_map; for(int i=0; i < s.size() - 9; ++i) { string substr = s.substr(i, 10); if(DNA_map.find(substr)==DNA_map.end()) DNA_map.insert(std::make_pair(substr,1)); else DNA_map[substr]+=1; } for(auto iter=DNA_map.begin(); iter!=DNA_map.end(); ++iter) { if(iter->second != 1) res.push_back(iter->first); } return res; } };
- 初解结果:
![]()
- 优化解法:根据初解中的结果,算法大体框架没有问题,时间复杂度已经是很低的,问题应该出在每次取子串和拿子串去哈希表中查询所耗费的时间,因此我们需要换一种方法来把子串压缩并唯一的存储到哈希表中。观察A,C,G,T四个字母所对应的Ascii码:0x41,0x43,0x47,0x54可以看出,他们的最后一位数值不相同,也就是在二进制的低三位是具有区分这四个字母的能力。如果按照顺序将10个字母的低三位存储到int中,恰好可以占30位,这样就能在bit级别对不同的子串进行区分。
class Solution { public: vector<string> findRepeatedDnaSequences(string s) { vector<string> res; if(s.size()<10) return res; unordered_map<int, int> DNA_map; for(int i=0; i < s.size() - 9; ++i) { string substr = s.substr(i, 10); int val = str2int(substr); DNA_map[val]+=1; if(DNA_map[val]==2) res.push_back(substr); } return res; } int str2int(string& s) { int str=0; for (int i = 0; i < s.size(); ++i) str = (str<<3) +(s[i]&7); return str; } };
- 优化结果:
![]()
- 反思:优化数据存储的访问速度的方式时,如果要存储的数据在相同bit区间上有且非常明显的区别,那么我们可以根据此差异来计算这个数据的压缩值,然后使用此压缩值来唯一的代替该数据。

2.8 Happy Number
- 题目:Write an algorithm to determine if a number is "happy".A happy number is a number defined by the following process: Starting with any positive integer, replace the number by the sum of the squares of its digits, and repeat the process until the number equals 1 (where it will stay), or it loops endlessly in a cycle which does not include 1. Those numbers for which this process ends in 1 are happy numbers.Example: 19 is a happy number
- 12 + 92 = 82
- 82 + 22 = 68
- 62 + 82 = 100
- 12 + 02 + 02 = 1
- 分析:题目很清楚的告诉我们判断条件:1.最终会到1 2.会进入一个没有1的循环
- 初解:按照计算方式进行计算,对于每一次的结算结果,先判断是不是1,如果不是再判断哈希表中是否存在该值,如果不存在就插入表中。
class Solution { public: bool isHappy(int n) { if(n<=0) return false; unordered_set<int> mid_val; while(1) { int val = compute(n); if(val == 1) break; else if(mid_val.find(val)!=mid_val.end()) return false; else { mid_val.insert(val); n = val; } } return true; } int compute(int n) { int val = 0; while(n!=0) { int mod = n % 10; val+=mod*mod; n = n / 10; } return val; } };
- 初解结果:
![]()
- 反思:快速查重使用哈希表。
2.9 Count Primes
- 题目:Description:Count the number of prime numbers less than a non-negative number, n.
- 分析:寻找小于n的所有素数,需要知道素数的判定性质和筛选方法。素数是大于1且只能被1和它本身整除的数。筛选方法是:如果一个数是素数,那么它的倍数就绝对不是素数。
- 初解:
class Solution { public: int countPrimes(int n) { int counter = 0; vector<bool> prime(n, true); prime[0]=prime[1]==false; for(int val = 2; val*val < n; ++val) { if(prime[val]==true) { for(int seq = val+val; seq < n; seq+=val) prime[seq]=false; } } for(int val = 2; val < n; ++val) if(prime[val]==true) ++counter; return counter; } };
- 初解结果:
![]()
- 反思:此题需要对素数的筛选方法熟练掌握。
2.10 Isomorphic Strings
- 题目:Given two strings s and t, determine if they are isomorphic.Two strings are isomorphic if the characters in s can be replaced to get t.All occurrences of a character must be replaced with another character while preserving the order of characters. No two characters may map to the same character but a character may map to itself.For example,
Given"egg","add", return true.Given"foo","bar", return false.Given"paper","title", return true.Note:
You may assume both s and t have the same length. - 分析:题目所说的同构字符串本质上的意思是说两个字符串的模式相同。对两个字符串进行同构映射,难点在于这种映射必须是一对一的,不能使多对一,也不能是一对多,因此是一个一一映射函数,而我们需要做的就是对给定两个字符串对应的映射进行检查是否满足一一映射条件。
- 初解:检查一一映射条件需要双向检查,同时对两个字符串进行遍历,对每个字符串进行建立到另一个字符串的映射表,在每次遍历一个字符时,检查该字符与另一个字符串中的字符给定的映射关系是否与其他已经存在的映射关系冲突。如果冲突,则立马返回false。否则继续遍历到字符串结束。
class Solution { public: bool isIsomorphic(string s, string t) { unordered_map<char,char> isomorphic_table; unordered_map<char,char> reverse_map; auto s_iter = s.begin(), t_iter = t.begin(); while(s_iter!=s.end()) { auto p_pair = isomorphic_table.find(*s_iter); if(p_pair != isomorphic_table.end()) { if(p_pair->second != *t_iter) return false; } else { auto n_pair = reverse_map.find(*t_iter); if(n_pair!=reverse_map.end()) { if(n_pair->second != *s_iter) return false; } isomorphic_table.insert(std::make_pair(*s_iter, *t_iter)); reverse_map.insert(std::make_pair(*t_iter, *s_iter)); } ++s_iter;++t_iter; } return true; } };
- 初解结果:
![]()
- 反思:快速双向验证需要哈希表的支持。
2.11 Word Pattern
- 题目:Given a
patternand a stringstr, find ifstrfollows the same pattern.Here follow means a full match, such that there is a bijection between a letter inpatternand a non-empty word instr.Examples:- pattern =
"abba", str ="dog cat cat dog"should return true. - pattern =
"abba", str ="dog cat cat fish"should return false. - pattern =
"aaaa", str ="dog cat cat dog"should return false. - pattern =
"abba", str ="dog dog dog dog"should return false.
You may assumepatterncontains only lowercase letters, andstrcontains lowercase letters separated by a single space. - pattern =
- 分析:仍旧是一一映射的检查
- 初解:
class Solution { public: bool wordPattern(string pattern, string str) { unordered_map<char,string> pattern_map; unordered_map<string, char> reverse_map; list<string> str_list; string tmp_str; str+=' '; for(int i=0; i<str.size(); ++i) { if(str[i]!=' ') tmp_str+=str[i]; else { str_list.push_back(tmp_str); tmp_str.clear(); } } if(pattern.size()!=str_list.size()) return false; for(auto c:pattern) { string tmp = str_list.front(); str_list.pop_front(); auto iter = pattern_map.find(c); if(iter!=pattern_map.end()) { if(iter->second != tmp) return false; } else { auto reverse_iter = reverse_map.find(tmp); if(reverse_iter!=reverse_map.end()) { if(reverse_iter->second != c) return false; } pattern_map.insert(std::make_pair(c,tmp)); reverse_map.insert(std::make_pair(tmp,c)); } } return true; } };
- 初解结果:
![]()
- 反思: 同上。
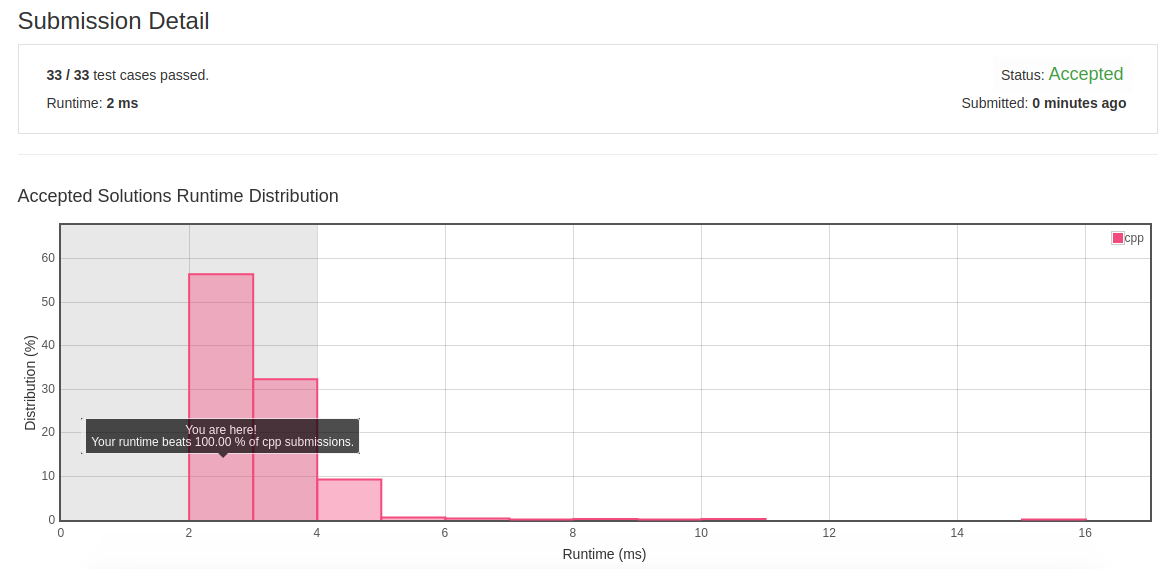
2.12 Top K Frequent Elements
- 题目:Given a non-empty array of integers, return the k most frequent elements.For example,
Given[1,1,1,2,2,3]and k = 2, return[1,2].Note:- You may assume k is always valid, 1 ≤ k ≤ number of unique elements.
- Your algorithm's time complexity must be better than O(n log n), where n is the array's size.
- 分析:题目首先要求对元素频率进行统计,其次要求输出频率最高的前k个值。统计涉及到哈希表,而输出最高的前k的值要求对数据进行排序或者建堆。
- 初解:直接统计,然后排序。时间复杂度为O(nlogn)。
class Solution { public: vector<int> topKFrequent(vector<int>& nums, int k) { unordered_map<int, int> val_freq; for(auto val:nums) { if(val_freq.find(val)!=val_freq.end()) val_freq[val]+=1; else val_freq[val]=1; } vector<vector<int>> val_freq_vec; for(auto iter=val_freq.begin(); iter!=val_freq.end(); ++iter) val_freq_vec.push_back(vector<int>{iter->first, iter->second}); sort(val_freq_vec.begin(), val_freq_vec.end(), compare); vector<int> res; for(int i=0; i<k; ++i) res.push_back(val_freq_vec[i][0]); return res; } static bool compare(const vector<int>& a, const vector<int>& b) { return a[1]>b[1]; } };
- 初解结果:
![]()
- 优化解法:考虑到题目要求时间复杂度要低于O(nlogn),因此对于筛选方法来说不能使用排序。考虑到在大量数据中筛选出少量数据这个特性,我们可以使用堆来完成快速提取操作,因为堆的每次操作时间复杂度是O(nlogn),n是堆数据总数,如果我们将n减少为k,那么就可以提高算法效率。怎么减少堆的数据总数呢,通过建立小頂堆并且限制堆的数量即可,也就是说每次向堆中添加元素时,如果当前堆的size超过了k,那么就将当前最小的元素踢出,这样做是因为该元素一定不是前k个元素,因此最终算法的时间复杂度是O(nlogk)。
class Solution { public: vector<int> topKFrequent(vector<int>& nums, int k) { unordered_map<int, int> counts; priority_queue<int, vector<int>, greater<int>> max_k; for(auto i : nums) ++counts[i]; for(auto & i : counts) { max_k.push(i.second); // Size of the min heap is maintained at equal to or below k while(max_k.size() > k) max_k.pop(); } vector<int> res; for(auto & i : counts) { if(i.second >= max_k.top()) res.push_back(i.first); } return res; } };
- 优化结果:
![]()
- 反思:对于从大量数据中提取少量数据,又想使得每次提取的操作代价尽量小,可以考虑使用小頂堆或者大顶堆来完成。
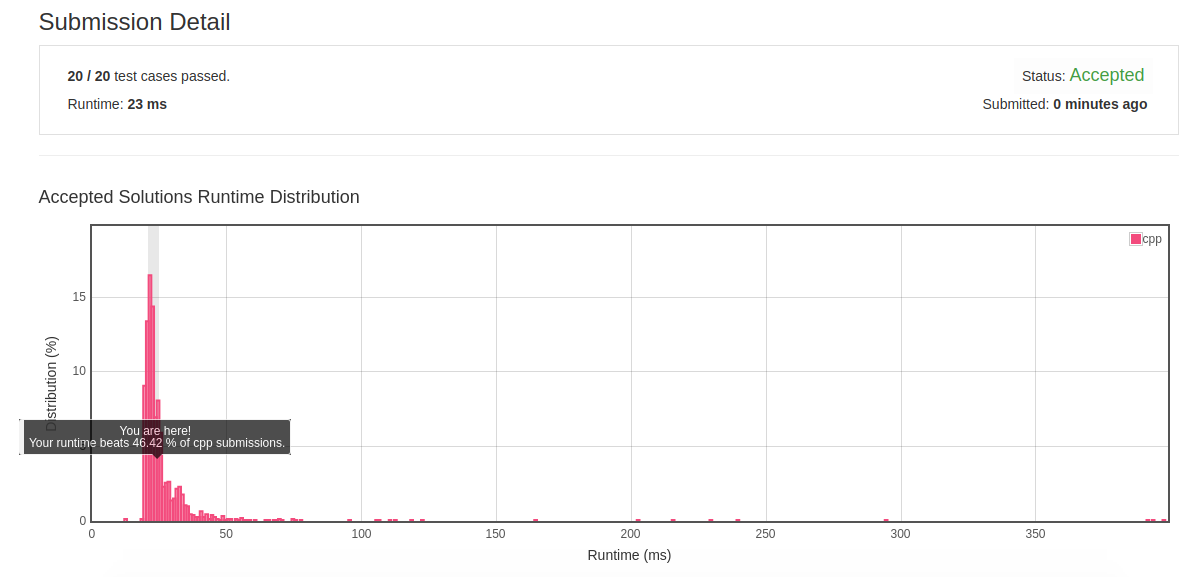
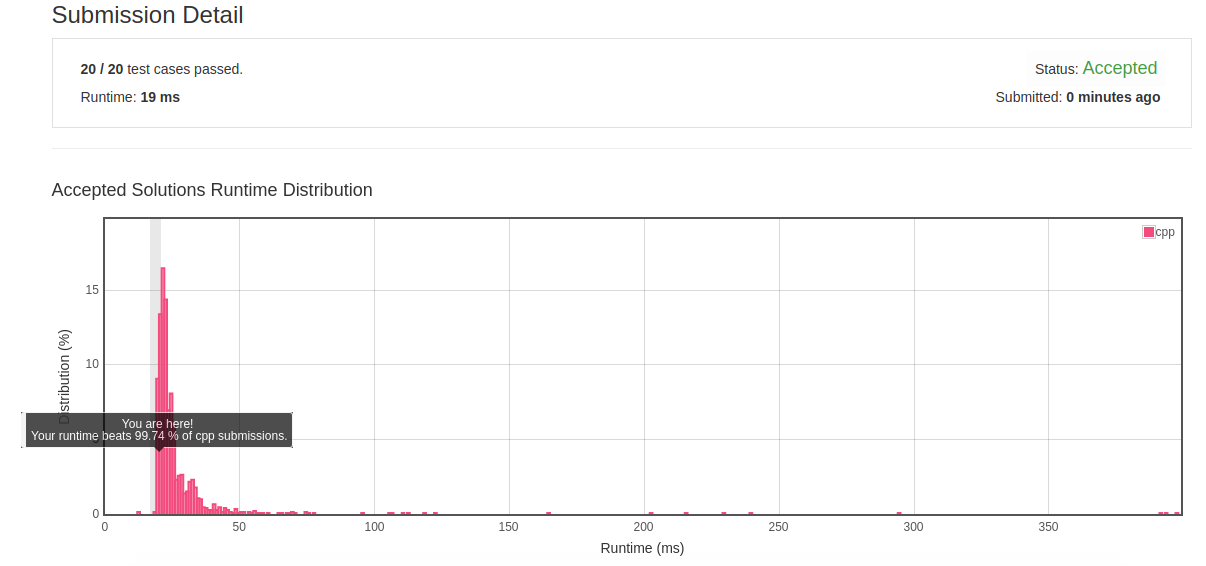
2.13 Find the Difference
- 题目:Given two strings s andt which consist of only lowercase letters.String t is generated by random shuffling string s and then add one more letter at a random position.Find the letter that was added in t.Example:Input: s = "abcd" t = "abcde" Output: e Explanation: 'e' is the letter that was added.
- 分析:检查两个字符串的差别实际上是对两个字符串集合进行检查,因此只需要对字符串生成字符串集合并对字符串集合进行对比即可。
- 初解:
class Solution { public: char findTheDifference(string s, string t) { unordered_map<char, int> char_map; for(auto c:s) { if(char_map.find(c)==char_map.end()) char_map[c]=1; else char_map[c]+=1; } char res = ' '; for(auto c:t) { if(char_map.find(c)==char_map.end()) return c; else char_map[c]-=1; } for(auto iter=char_map.begin(); iter!=char_map.end(); ++iter) { if(iter->second!=0) { res = iter->first; break; } } return res; } };
- 初解结果:
![]()
- 优化解法:换一种角度,如果将两个字符串看做是同一个集合中的元素,那么可以得到仅有一个字符出现了奇数次,其他均出现偶数次,可以使用异或运算来计算结果。
class Solution { public: char findTheDifference(string s, string t) { char r=0; for(char c:s) r ^=c; for(char c:t) r ^=c; return r; } };
- 优化结果:
![]()
- 反思:对于两个集合进行求一个差别元素的类型,可以利用异或运算来加速。

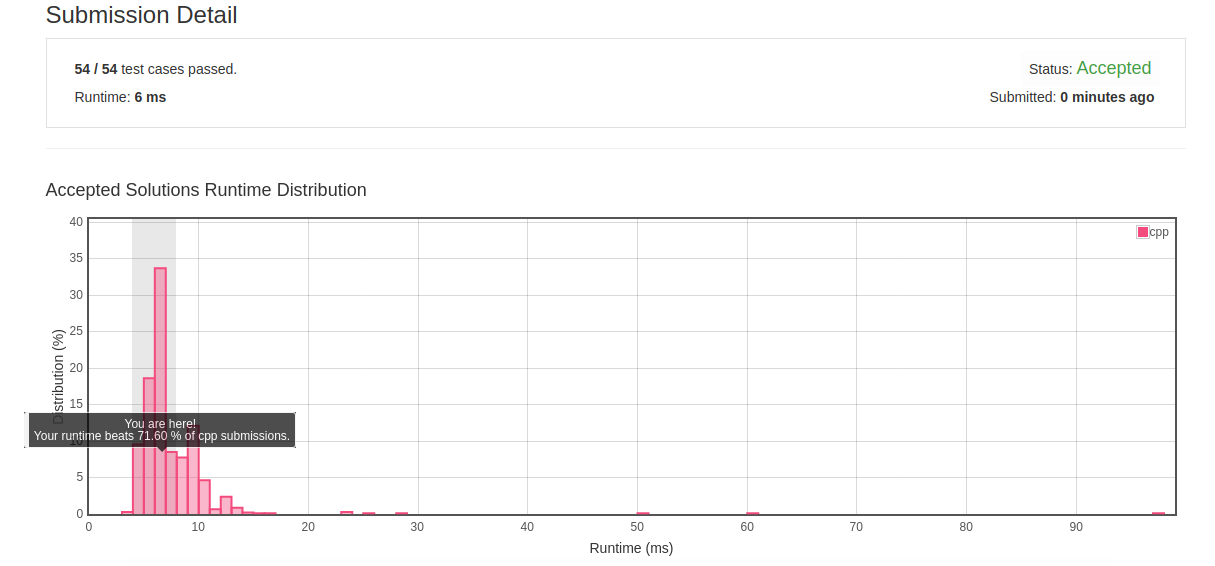
2.14 Longest Palindrome
- 题目:Given a string which consists of lowercase or uppercase letters, find the length of the longest palindromes that can be built with those letters.This is case sensitive, for example
"Aa"is not considered a palindrome here.Note:
Assume the length of given string will not exceed 1,010.Example:Input: "abccccdd" Output: 7 Explanation: One longest palindrome that can be built is "dccaccd", whose length is 7.
- 分析:构成回文数的情况有两种:1.偶数个对称字符 2.偶数个对称字符和一个对称中心字符
- 初解:先对字符串的字符频率进行统计,然后将出现偶数次的字符出现的次数加起来,对于奇数次的字符对其出现频率减去1转换成偶数,最后在加上一次即可。
class Solution { public: int longestPalindrome(string s) { unordered_map<char, int> char_map; for(auto c:s) { if(char_map.find(c)==char_map.end()) char_map[c]=1; else char_map[c]+=1; } int p = 0, len = 0; for(auto iter=char_map.begin(); iter!=char_map.end(); ++iter) { if(iter->second % 2==0) len+=iter->second; else { len+=iter->second -1; p = 1; } } return len+p; } };
- 初解结果:
![]()
- 反思:无。
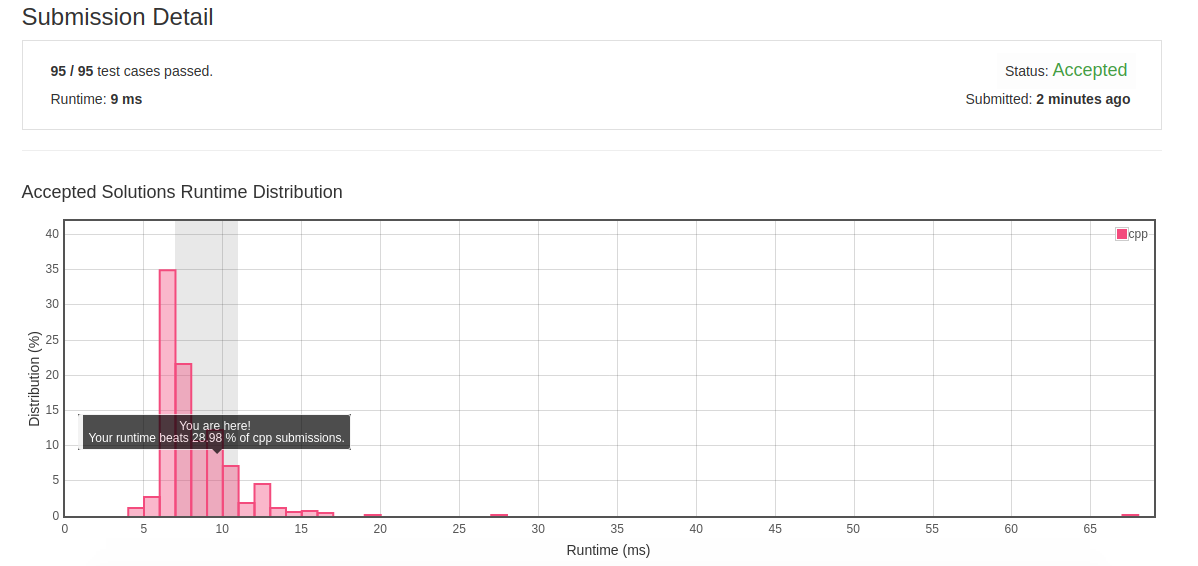
2.15 Find All Anagrams in a String
- 题目:Given a string s and a non-empty string p, find all the start indices of p's anagrams in s.Strings consists of lowercase English letters only and the length of both strings s and p will not be larger than 20,100.The order of output does not matter.Example 1:Input: s: "cbaebabacd" p: "abc" Output: [0, 6] Explanation: The substring with start index = 0 is "cba", which is an anagram of "abc". The substring with start index = 6 is "bac", which is an anagram of "abc". Example 2:Input: s: "abab" p: "ab" Output: [0, 1, 2] Explanation: The substring with start index = 0 is "ab", which is an anagram of "ab". The substring with start index = 1 is "ba", which is an anagram of "ab". The substring with start index = 2 is "ab", which is an anagram of "ab".
- 分析:要找出与给定字符串同字符集的所有子串需要:1.找出长度与给定字符串相同的子串 2.判定是否是相同的字符集
- 初解:使用哈希表先统计给定字符串的字符集,然后目标字符串进行取子串操作并统计相应的字符集,然后对比即可,为了在每次统计字符集的时候高效利用之前计算的结果,仅在第一次对子串进行完全统计,而后面的每一次计算都是去掉首部字符,加上尾部字符。
class Solution { public: vector<int> findAnagrams(string s, string p) { vector<int> res; unordered_map<char, int> p_map; for(auto c:p) p_map[c]+=1; unordered_map<char,int> s_map; for(int i=0; i<p.size(); ++i) s_map[s[i]]+=1; if(equal(p_map,s_map)==true) res.push_back(0); for(int i=1; i<s.size();++i) { s_map[s[i-1]]-=1; s_map[s[i+p.size()-1]]+=1; if(equal(p_map,s_map)) res.push_back(i); } return res; } bool equal(unordered_map<char,int>& a, unordered_map<char,int>& b) { for(auto iter=a.begin(); iter!=a.end(); ++iter) { if(iter->second != b[iter->first]) return false; } return true; } };
- 初解结果:
![]()
- 优化解法:初解中算法的框架没有问题,但是时间较长,问题可能出现在equal函数中,因为每次需要对两个哈希表进行访问,多了两次哈希计算的过程。考虑到由于字符串的字符范围确定,可以使用vector来实现固定顺序的手工哈希表,然后按序比较即可。
class Solution { public: vector<int> findAnagrams(string s, string p) { vector<int> pv(26,0), sv(26,0), res; if(s.size() < p.size()) return res; for(int i = 0; i < p.size(); ++i) { ++pv[p[i]-'a']; ++sv[s[i]-'a']; } if(pv == sv) res.push_back(0); for(int i = p.size(); i < s.size(); ++i) { ++sv[s[i]-'a']; --sv[s[i-p.size()]-'a']; if(pv == sv) res.push_back(i-p.size()+1); } return res; } };
- 优化结果:
![]()
- 反思:对于范围确定且仅仅起到统计作用的哈希表,实际上可以使用vector来代替。
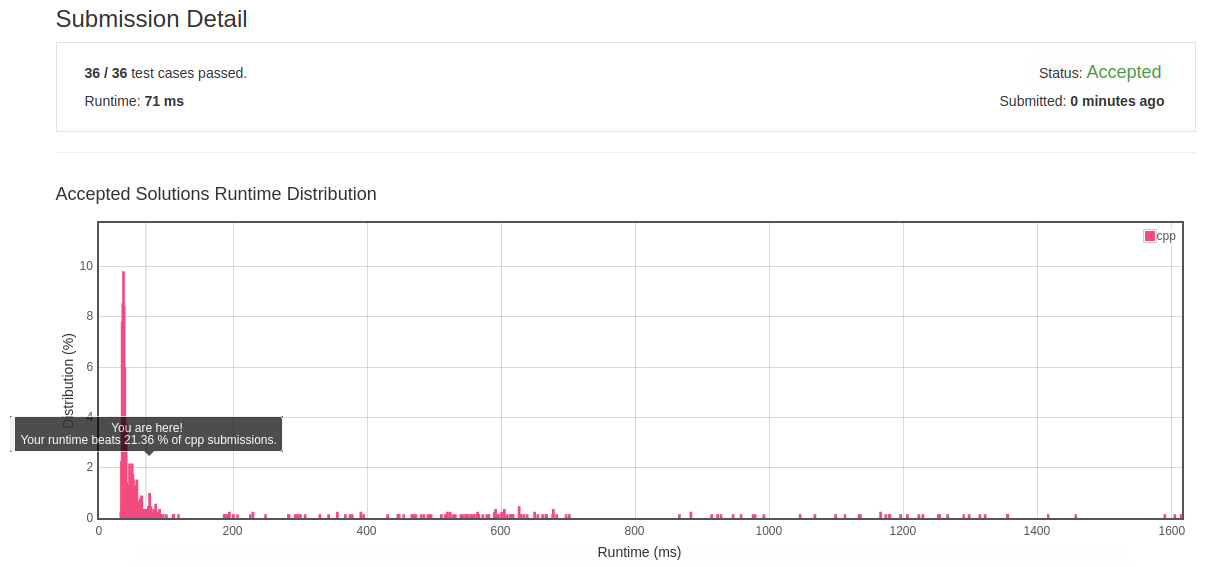
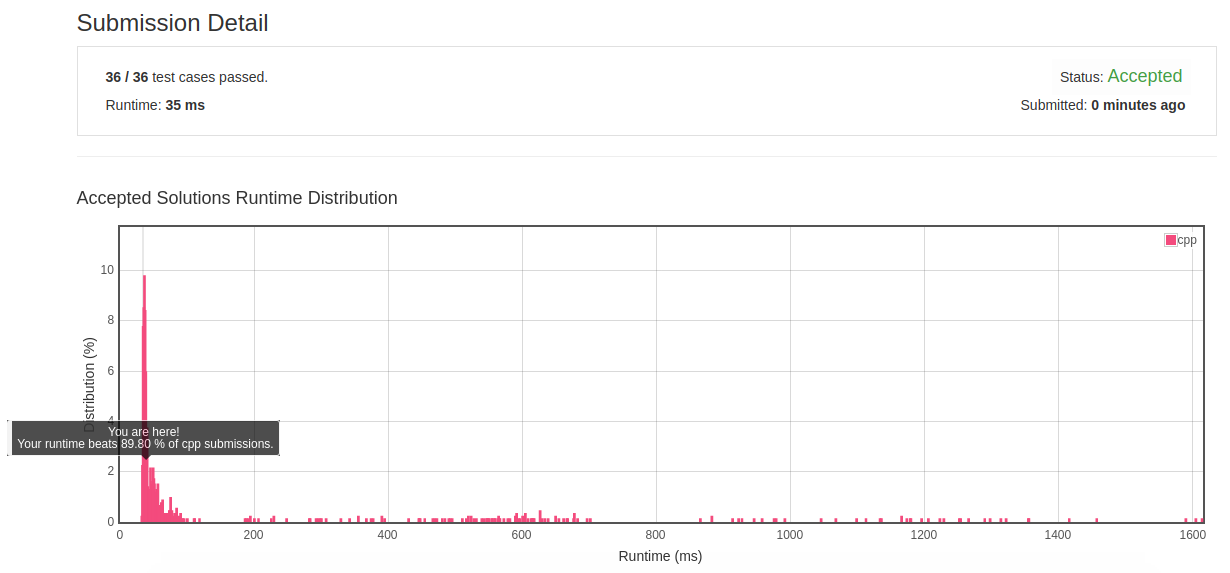
2.16 Sort Characters By Frequency
-
题目:Given a string, sort it in decreasing order based on the frequency of characters.Example 1:
Input: "tree" Output: "eert" Explanation: 'e' appears twice while 'r' and 't' both appear once. So 'e' must appear before both 'r' and 't'. Therefore "eetr" is also a valid answer.
Example 2:
Input: "cccaaa" Output: "cccaaa" Explanation: Both 'c' and 'a' appear three times, so "aaaccc" is also a valid answer. Note that "cacaca" is incorrect, as the same characters must be together.
Example 3:
Input: "Aabb" Output: "bbAa" Explanation: "bbaA" is also a valid answer, but "Aabb" is incorrect. Note that 'A' and 'a' are treated as two different characters.
- 分析:题目实际上想考察的是对sort函数的自定义排序方法。
- 初解:先对字符进行频率统计,然后使用自定义函数或者lambda表达式来对结果进行排序。
class Solution { public: string frequencySort(string s) { unordered_map<char, int> char_freq; for(auto c:s) char_freq[c]+=1; vector<pair<char,int>> freq_vec; for(auto iter=char_freq.begin(); iter!=char_freq.end(); ++iter) freq_vec.push_back(std::make_pair(iter->first, iter->second)); sort(freq_vec.begin(), freq_vec.end(), [](pair<char,int>& a, pair<char,int>& b)->bool{return a.second > b.second;}); string res=""; for(int i=0; i<freq_vec.size(); ++i) res+=string(freq_vec[i].second,freq_vec[i].first); return res; } };
- 初解结果:
class Solution { public: string frequencySort(string s) { unordered_map<char, int> char_freq; for_each(s.begin(),s.end(),[&](char& c){char_freq[c]+=1;}); vector<pair<char,int>> freq_vec; for_each(char_freq.begin(),char_freq.end(),[&](unordered_map<char,int>::reference i) { freq_vec.push_back(make_pair(i.first,i.second)); }); sort(freq_vec.begin(), freq_vec.end(), [](pair<char,int>& a, pair<char,int>& b)->bool{return a.second > b.second;}); string res=""; for_each(freq_vec.begin(),freq_vec.end(),[&](pair<char,int>& i){res+=string(i.second,i.first);}); return res; } };
- 反思:自定义升序排序时,需要对小于情况返回true,降序排序需要对大于情况返回true。
2.17 Island Perimeter
- 题目:You are given a map in form of a two-dimensional integer grid where 1 represents land and 0 represents water. Grid cells are connected horizontally/vertically (not diagonally). The grid is completely surrounded by water, and there is exactly one island (i.e., one or more connected land cells). The island doesn't have "lakes" (water inside that isn't connected to the water around the island). One cell is a square with side length 1. The grid is rectangular, width and height don't exceed 100. Determine the perimeter of the island.Example:[[0,1,0,0], [1,1,1,0], [0,1,0,0], [1,1,0,0]] Answer: 16 Explanation: The perimeter is the 16 yellow stripes in the image below:
![]()
- 分析:要计算岛屿的周长,需要对每一个土地方格考虑上下左右四种情况,边界加1,非边界如果隔壁为水地,也加1。
- 初解:
class Solution { public: int islandPerimeter(vector<vector<int>>& grid) { int perimeter = 0; if(grid.size() == 0) return perimeter; int row = grid.size(), col = grid[0].size(); for(int i=0; i< row; ++i) for(int j=0; j < col; ++j) if(grid[i][j]==1) perimeter += check(grid, i, j, row, col); return perimeter; } int check(vector<vector<int>>& grid, int row, int col, int& row_lim, int& col_lim) { int len = 0; if((row-1>=0 && grid[row-1][col]==0) || row-1<0) ++len; if((row+1<row_lim && grid[row+1][col]==0) || row+1>=row_lim) ++len; if((col-1>=0 && grid[row][col-1]==0) || col-1<0) ++len; if((col+1<col_lim && grid[row][col+1]==0) || col+1>=col_lim) ++len; return len; } };
- 初解结果:
![]()
- 反思:


2.18 Keyboard Row
- 题目:
Given a List of words, return the words that can be typed using letters of alphabet on only one row's of American keyboard like the image below.
![American keyboard]()
Example 1:
Input: ["Hello", "Alaska", "Dad", "Peace"] Output: ["Alaska", "Dad"]
Note:
- You may use one character in the keyboard more than once.
- You may assume the input string will only contain letters of alphabet.
- 分析:判断字符串是否落在同一键盘行上本质上是在判断该字符串的字符集是否是某一行字符集的子集。
- 初解:对键盘行的字符串进行建立集合,对于每一个字符串,先判断第一个字符落在哪个键盘行集合中,然后在该集合中对该字符串后续字符进行存在判断。
class Solution { public: vector<string> findWords(vector<string>& words) { vector<unordered_set<char>> keyboard {unordered_set<char>{'q','w','e','r','t','y','u','i','o','p'}, unordered_set<char>{'a','s','d','f','g','h','j','k','l'}, unordered_set<char>{'z','x','c','v','b','n','m'}}; vector<string> res; for(auto word:words) { int row = check_row(tolower(word.front()), keyboard); auto& hash_row = keyboard[row]; if(is_same_row(word, hash_row)==true) res.push_back(word); } return res; } int check_row(char c, vector<unordered_set<char>>& keyboard) { int row=0; for(int i=0; i<keyboard.size(); ++i) if(keyboard[i].find(c)!=keyboard[i].end()) { row = i; break; } return row; } bool is_same_row(string& word, unordered_set<char>& hash_row) { for(auto c:word) { if(hash_row.find(tolower(c))==hash_row.end()) return false; } return true; } char tolower(char c) { if ((c >= 'A') && (c <= 'Z')) return c + ('a' - 'A'); return c; } };
- 初解结果:
![]()
- 反思:题目长了需要把题目的本质弄清楚。

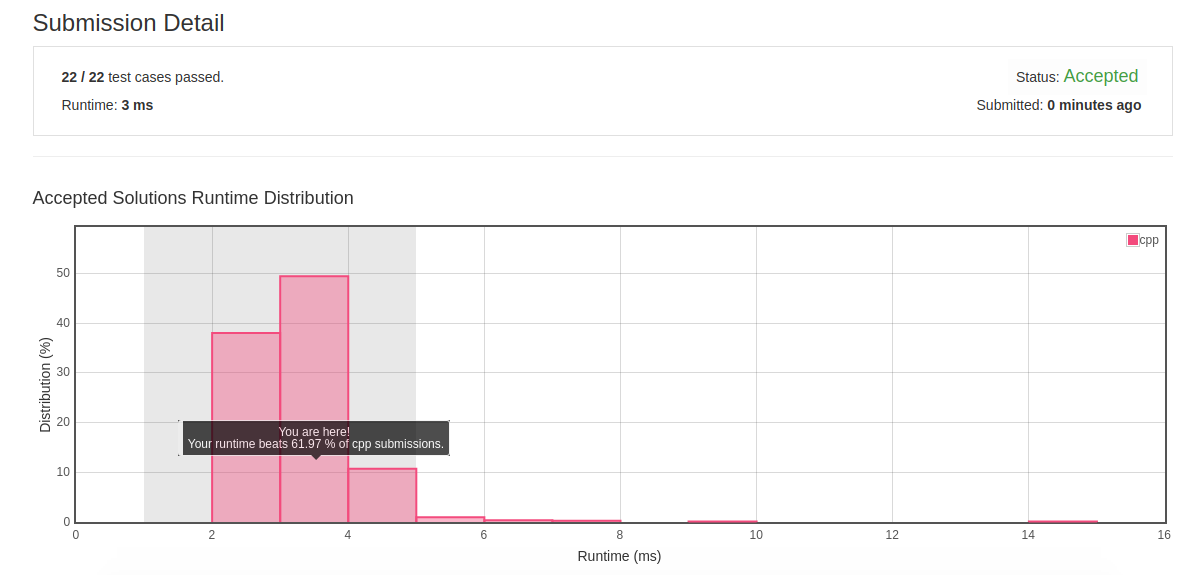
2.19 Most Frequent Subtree Sum
- 题目:
Given the root of a tree, you are asked to find the most frequent subtree sum. The subtree sum of a node is defined as the sum of all the node values formed by the subtree rooted at that node (including the node itself). So what is the most frequent subtree sum value? If there is a tie, return all the values with the highest frequency in any order.
Examples 1
Input:5 / \ 2 -3
return [2, -3, 4], since all the values happen only once, return all of them in any order.Examples 2
Input:5 / \ 2 -5
return [2], since 2 happens twice, however -5 only occur once.Note: You may assume the sum of values in any subtree is in the range of 32-bit signed integer.
- 分析:题目本质是考察对二叉树的递归遍历或者迭代遍历,实现方式有很多种:前序,中序,后序,层次。
- 初解:使用前序递归遍历树结点,并计算子树求和的值,统计值的频率。
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode(int x) : val(x), left(NULL), right(NULL) {} * }; */ class Solution { public: vector<int> findFrequentTreeSum(TreeNode* root) { unordered_map<int, int> subtreesum_freq; vector<int> res; deep_search(root, subtreesum_freq); int max_freq=0; for(auto iter=subtreesum_freq.begin(); iter!=subtreesum_freq.end(); ++iter) if(iter->second > max_freq) max_freq = iter->second; for(auto iter=subtreesum_freq.begin(); iter!=subtreesum_freq.end(); ++iter) if(iter->second == max_freq) res.push_back(iter->first); return res; } int deep_search(TreeNode* root, unordered_map<int,int>& sum_freq) { int sum = 0; if(root==nullptr) return sum; else sum+=root->val; sum+=deep_search(root->left, sum_freq); sum+=deep_search(root->right,sum_freq); sum_freq[sum]+=1; return sum; } };
- 初解结果:
![]()
- 反思: 熟记树的各种递归遍历方式。
2.20 Subarray Sum Equals K
- 题目:Given an array of integers and an integer k, you need to find the total number of continuous subarrays whose sum equals to k.Example 1:
Input:nums = [1,1,1], k = 2 Output: 2
Note:- The length of the array is in range [1, 20,000].
- The range of numbers in the array is [-1000, 1000] and the range of the integer k is [-1e7, 1e7].
- 分析:
- 初解:
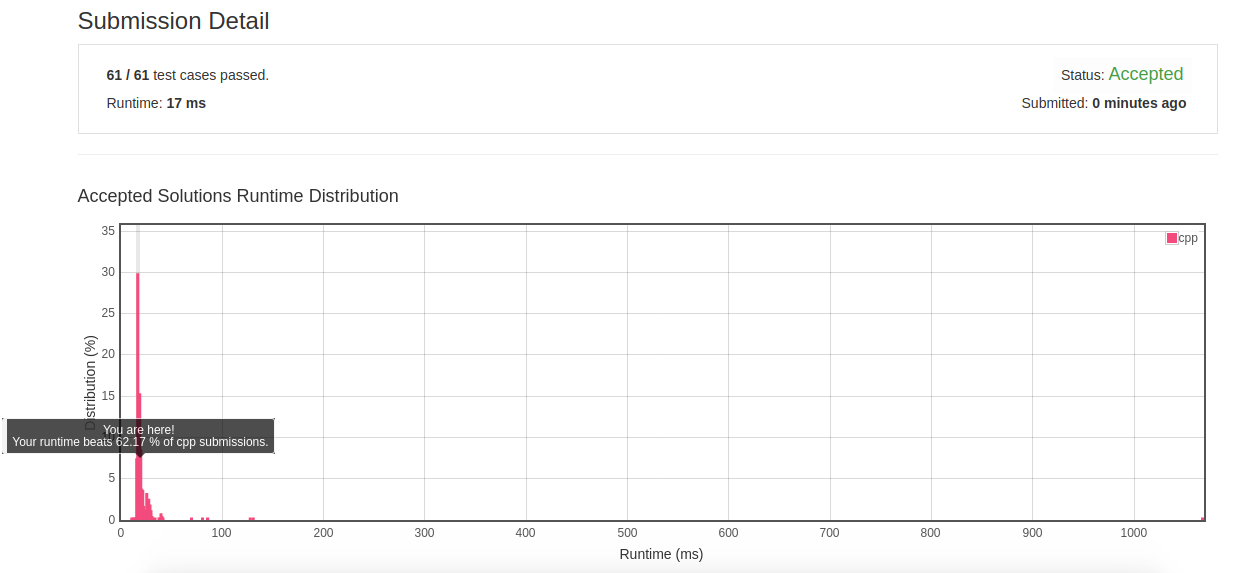
class Solution { public: int subarraySum(vector<int>& nums, int k) { int sum = 0, counter = 0; unordered_map<int, int> accu_val; accu_val[k]=1; for(auto val:nums) { sum+=val; if(accu_val.count(sum)==1) counter+=accu_val[sum]; ++accu_val[sum+k]; } return counter; } };
- 初解结果:
![]()
- 反思:
2.21 Longest Harmonious Subsequence
- 题目:We define a harmonious array is an array where the difference between its maximum value and its minimum value is exactly 1.Now, given an integer array, you need to find the length of its longest harmonious subsequence among all its possible subsequences.Example 1:
Input: [1,3,2,2,5,2,3,7] Output: 5 Explanation: The longest harmonious subsequence is [3,2,2,2,3].
Note: The length of the input array will not exceed 20,000. - 分析:题目要求对子序列的上下限之差恰好为1,即不能全相等也不能差超过1。题目所说的子序列并不要求序列在源数字串中是连续的,因此可以将数字统计起来再做判断。
- 初解:对于给定的一个数a,仅仅需要判断a和a-1构成的序列长度和a与a+1构成序列长度,哪个更大。
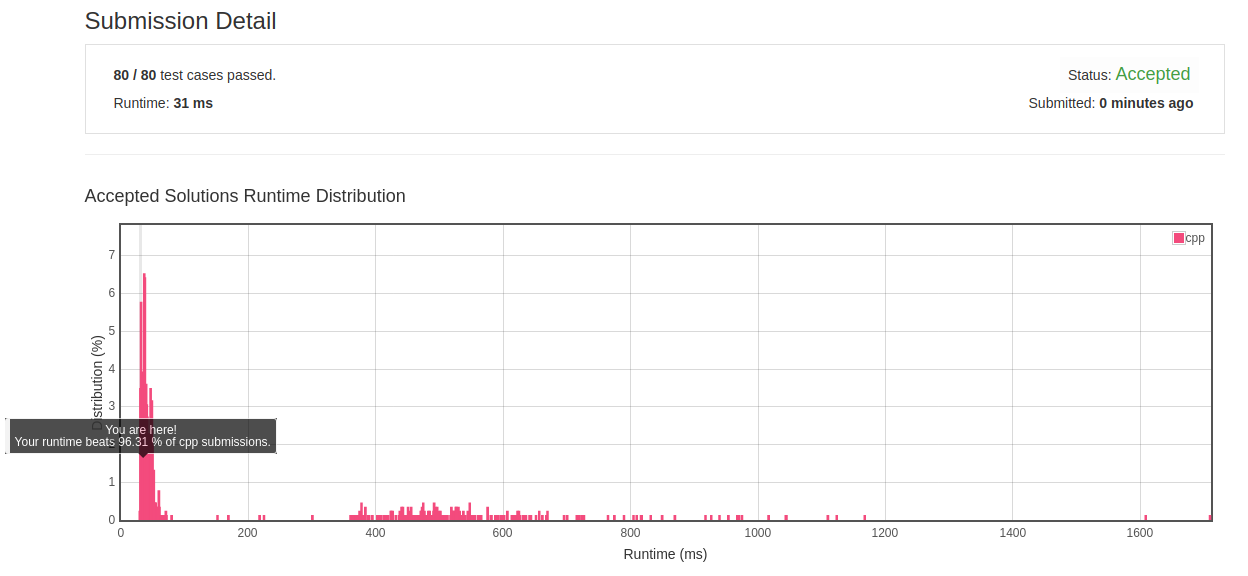
class Solution { public: int findLHS(vector<int>& nums) { unordered_map<int, int> stat; for_each(nums.begin(),nums.end(),[&](int& a){stat[a]+=1;}); int len = 0; for(auto iter=stat.begin(); iter!=stat.end(); ++iter) { int tmp_len_pre = iter->second, tmp_len_next = iter->second; if(stat.count(iter->first-1)==0 && stat.count(iter->first+1)==0) continue; if(stat.count(iter->first-1)!=0) tmp_len_pre += stat[iter->first-1]; if(stat.count(iter->first+1)!=0) tmp_len_next+= stat[iter->first+1]; if(tmp_len_pre > len) len = tmp_len_pre; if(tmp_len_next > len) len = tmp_len_next; } return len; } };
- 初解结果:
![]()
- 反思: 对于无序但值相邻的判断要求,可以使用哈希表来统计和快速查询。
2.22 Minimum Index Sum of Two Lists
- 题目:Suppose Andy and Doris want to choose a restaurant for dinner, and they both have a list of favorite restaurants represented by strings.You need to help them find out their common interest with the least list index sum. If there is a choice tie between answers, output all of them with no order requirement. You could assume there always exists an answer.Example 1:Input: ["Shogun", "Tapioca Express", "Burger King", "KFC"] ["Piatti", "The Grill at Torrey Pines", "Hungry Hunter Steakhouse", "Shogun"] Output: ["Shogun"] Explanation: The only restaurant they both like is "Shogun". Example 2:Input: ["Shogun", "Tapioca Express", "Burger King", "KFC"] ["KFC", "Shogun", "Burger King"] Output: ["Shogun"] Explanation: The restaurant they both like and have the least index sum is "Shogun" with index sum 1 (0+1). Note:
- The length of both lists will be in the range of [1, 1000].
- The length of strings in both lists will be in the range of [1, 30].
- The index is starting from 0 to the list length minus 1.
- No duplicates in both lists.
- 分析:最小索引和需要对两个链表共同的项之和进行依次比较求出最小的和,然后对对应的项输出。
- 初解:为了快速找出共同项的索引,需要对两个链表建立哈希表。
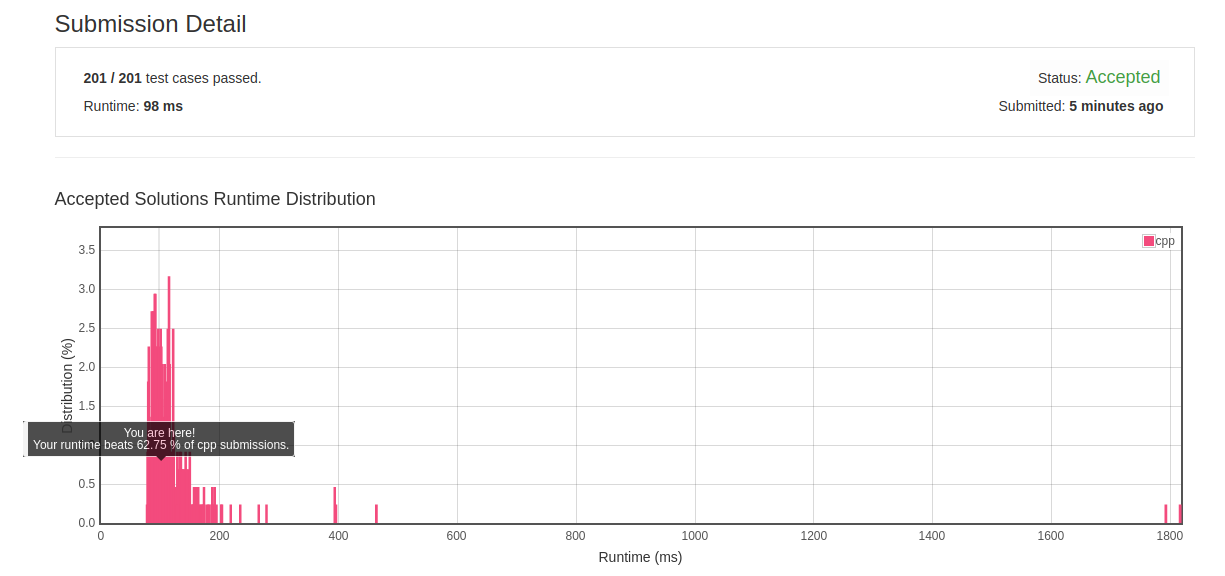
class Solution { public: vector<string> findRestaurant(vector<string>& list1, vector<string>& list2) { unordered_map<string, int> list1_map; for(int i=0; i<list1.size(); ++i) list1_map[list1[i]]=i; int min_sum=2000; vector<string> res; for(int i=0; i<list2.size(); ++i) { int tmp_sum = i; if(list1_map.count(list2[i])!=0) tmp_sum+=list1_map[list2[i]]; else continue; if(tmp_sum < min_sum) min_sum = tmp_sum; } for(int i=0; i<list2.size(); ++i) { int tmp_sum = i; if(list1_map.count(list2[i])!=0) tmp_sum+=list1_map[list2[i]]; else continue; if(tmp_sum == min_sum) res.push_back(list2[i]); } return res; } };
- 初解结果:
![]()
2.23 Replace Words
- 题目:In English, we have a concept called
root, which can be followed by some other words to form another longer word - let's call this wordsuccessor. For example, the rootan, followed byother, which can form another wordanother.Now, given a dictionary consisting of many roots and a sentence. You need to replace all thesuccessorin the sentence with therootforming it. If asuccessorhas manyrootscan form it, replace it with the root with the shortest length.You need to output the sentence after the replacement.Example 1:Input: dict = ["cat", "bat", "rat"] sentence = "the cattle was rattled by the battery" Output: "the cat was rat by the bat" Note:- The input will only have lower-case letters.
- 1 <= dict words number <= 1000
- 1 <= sentence words number <= 1000
- 1 <= root length <= 100
- 1 <= sentence words length <= 1000
- 分析:题目本质要求为:1.识别字符串句子中的每个单词 2.对每个单词进行词根匹配 3.替换成词根
- 初解:将句子切分成单词,然后对每个单词进行词根匹配,最后替换成词根。
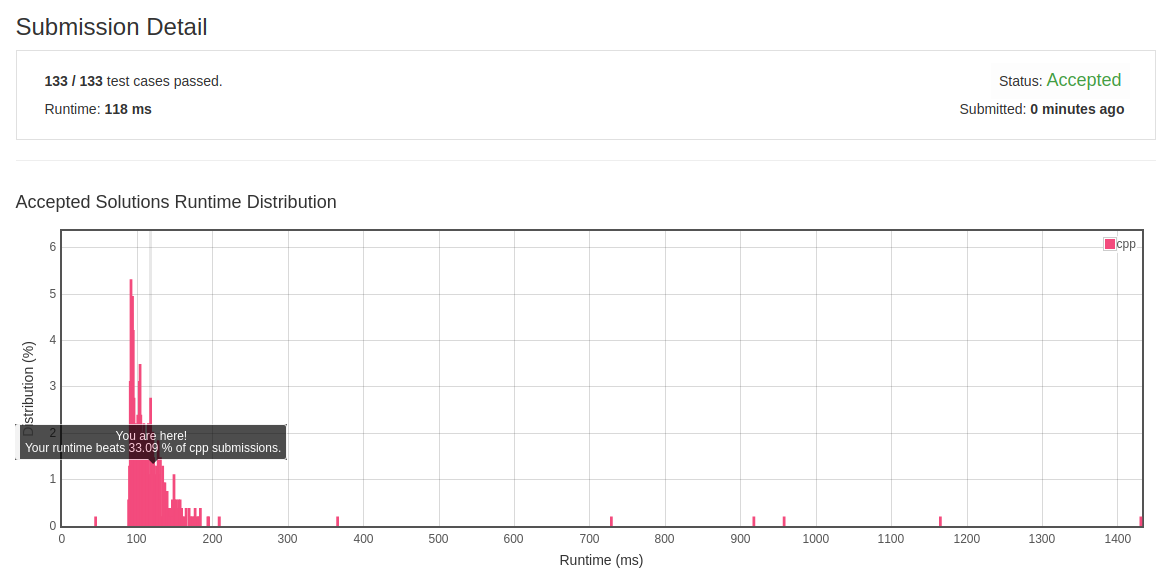
class Solution { public: string replaceWords(vector<string>& dict, string sentence) { sentence+=" "; unordered_set<string> dict_set(dict.begin(), dict.end()); string res=""; for(int i=0; i<sentence.size(); ) { int j=i+1; while(sentence[j]!=' ') ++j; res+=substitute(dict_set, sentence, i, j-i)+" "; i=j+1; } return res.substr(0,res.size()-1); } string substitute(unordered_set<string>& dict_set, string& sentence, int start, int len) { for(int tmp_len=1; tmp_len < len; ++tmp_len) { string subs = sentence.substr(start, tmp_len); if(dict_set.count(subs)!=0) return subs; } return sentence.substr(start, len); } };
- 初解结果:
![]()
- 反思:
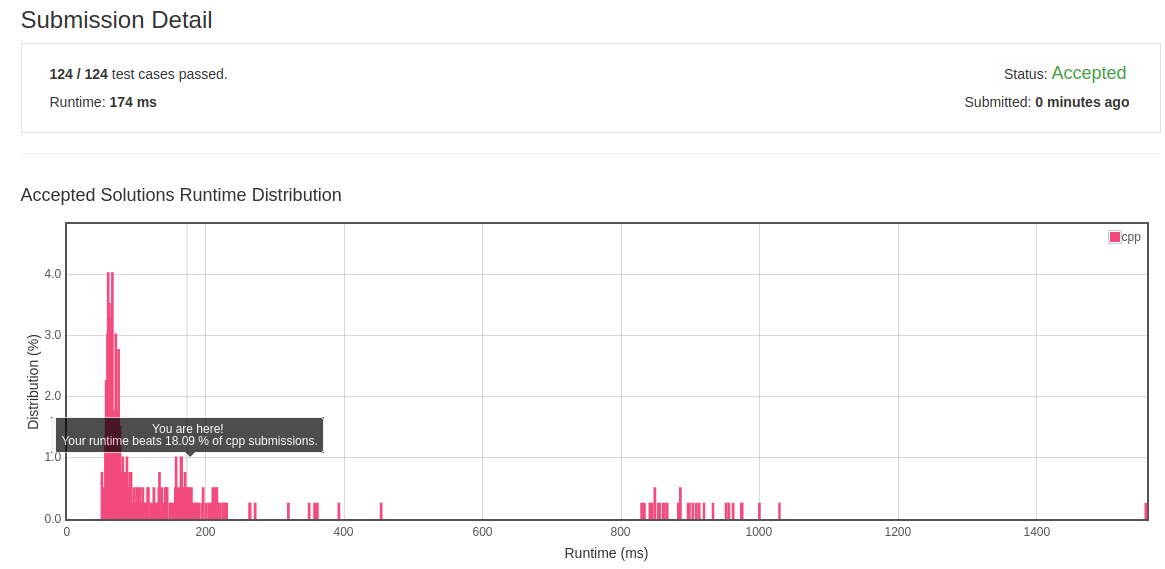
2.24 Top K Frequent Words
- 题目:Given a non-empty list of words, return the k most frequent elements.Your answer should be sorted by frequency from highest to lowest. If two words have the same frequency, then the word with the lower alphabetical order comes first.Example 1:Input: ["i", "love", "leetcode", "i", "love", "coding"], k = 2 Output: ["i", "love"] Explanation: "i" and "love" are the two most frequent words. Note that "i" comes before "love" due to a lower alphabetical order. Example 2:Input: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4 Output: ["the", "is", "sunny", "day"] Explanation: "the", "is", "sunny" and "day" are the four most frequent words, with the number of occurrence being 4, 3, 2 and 1 respectively. Note:
- You may assume k is always valid, 1 ≤ k ≤ number of unique elements.
- Input words contain only lowercase letters.
- Try to solve it in O(n log k) time and O(n) extra space.
- 分析:题目要考察的重点显然是哈希统计和构建堆以及堆提取的时间复杂度。
- 初解:直接对单词进行统计,然后先使用普通快速排序。
class Solution { public: vector<string> topKFrequent(vector<string>& words, int k) { unordered_map<string,int> stat; for_each(words.begin(),words.end(),[&](string& w){stat[w]+=1;}); vector<pair<int, string>> seq; for_each(stat.begin(), stat.end(), [&](unordered_map<string,int>::reference i){seq.push_back(make_pair(i.second,i.first));}); sort(seq.begin(),seq.end(),compare); vector<string> res; for_each(seq.begin(),seq.begin()+k,[&](pair<int, string>& i){res.push_back(i.second);}); return res; } static bool compare(pair<int,string>& a, pair<int,string>& b) { if(a.first>b.first) return true; else if(a.first==b.first) { if(a.second.compare(b.second)<0) return true; else return false; } else return false; } };
- 初解结果:
![]()
- 优化解法:
- 优化结果:
- 反思:
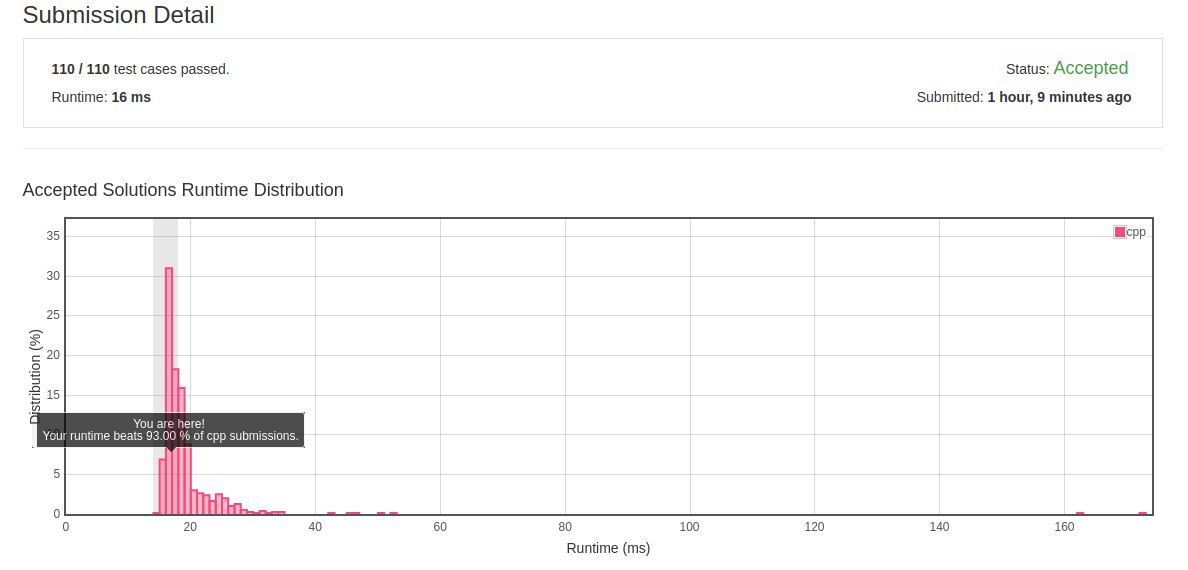
2.25 Daily Temperatures
- 题目:Given a list of daily
temperatures, produce a list that, for each day in the input, tells you how many days you would have to wait until a warmer temperature. If there is no future day for which this is possible, put0instead.For example, given the listtemperatures = [73, 74, 75, 71, 69, 72, 76, 73], your output should be[1, 1, 4, 2, 1, 1, 0, 0].Note: The length oftemperatureswill be in the range[1, 30000]. Each temperature will be an integer in the range[30, 100]. - 分析:
- 初解:
- 初解结果:
- 优化解法:
- 优化结果:
- 反思:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号