


从头学Java17-Stream API(一)
Stream API
Stream API 是按照map/filter/reduce方法处理内存中数据的最佳工具。
本系列中的教程包含从基本概念一直到collector设计和并行流。
![]()
在流上添加中继操作
将一个流map为另一个流
mapping流就是使用函数转换其元素。此转换可能会更改该流处理的元素的类型。
您可以使用 map() 方法将一个流map为另一个流,该方法用Function作为参数。mapping一个流意味着该流的所有元素都将使用该函数进行转换。
代码模式如下:
List<String> strings = List.of("one", "two", "three", "four");
Function<String, Integer> toLength = String::length;
Stream<Integer> ints = strings.stream()
.map(toLength);
此代码粘贴到 IDE 运行时,你不会看到任何东西,你可能想知道为什么。
答案其实很简单:该流上没有定义末端操作。这段代码没有做任何事情。它不处理任何数据。
让我们添加一个非常有用的末端操作collect(Collectors.toList()),它将处理后的元素放在一个列表中。如果您不确定此代码的真正作用,请不要担心;我们将在本教程的后面部分介绍这一点。代码将变为以下内容。
List<String> strings = List.of("one", "two", "three", "four");
List<Integer> lengths = strings.stream()
.map(String::length)
.collect(Collectors.toList());
System.out.println("lengths = " + lengths);
运行此代码将打印以下内容:
lengths = [3, 3, 5, 4]
您可以看到此模式创建了一个 Stream<Integer>,由 map(String::length) 返回。你也可以通过调用mapToInt()来使其成为一个专门的IntStream。这个mapToInt()方法以ToIntFuction作参数。在上一示例中.map(String::length)更改为.mapToInt(String::length) 不会创建编译器错误。String::length方法引用可以是两种类型:Function<String、Integer> 和 ToIntFunction<String>。
专用流没有 collect() 方法将Collector作参数。因此,如果用 mapToInt(),则无法再在列表中收集结果。让我们获取有关该流的一些统计信息。这个 summaryStatistics() 方法非常方便,并且仅在专门的原始类型流上可用。
List<String> strings = List.of("one", "two", "three", "four");
IntSummaryStatistics stats = strings.stream()
.mapToInt(String::length)
.summaryStatistics();
System.out.println("stats = " + stats);
结果如下:
stats = IntSummaryStatistics{count=4, sum=15, min=3, average=3,750000, max=5}
从 Stream 转为原始类型流有三种方法:mapToInt()、mapToLong() 和 mapToDouble()。
filter流
filtering就是在流处理中使用Predicate丢弃某些元素。此方法可用于对象流和原始类型流。
假设您需要计算长度为 3 的字符串。您可以编写以下代码来执行此操作:
List<String> strings = List.of("one", "two", "three", "four");
long count = strings.stream()
.map(String::length)
.filter(length -> length == 3)
.count();
System.out.println("count = " + count);
运行此代码将生成以下内容:
count = 2
请注意,您刚刚使用了 Stream API 的另一个末端操作 count(),它只计算已处理元素的数量。此方法返回long ,您可以使用它计算很多元素。比 ArrayList 里面的更多。
flatmap流以处理 1:p 关系
让我们在一个示例中查看 flatMap 操作。假设您有两个实体:State和 City。一个state实例包含多个city实例,存储在一个列表中。
这是City类的代码。
public class City {
private String name;
private int population;
// constructors, getters
// toString, equals and hashCode
}
这是State类的代码,以及与City类的关系。
public class State {
private String name;
private List<City> cities;
// constructors, getters
// toString, equals and hashCode
}
假设您的代码正在处理状态列表,并且在某些时候您需要计算所有城市的人口。
您可以编写以下代码:
List<State> states = ...;
int totalPopulation = 0;
for (State state: states) {
for (City city: state.getCities()) {
totalPopulation += city.getPopulation();
}
}
System.out.println("Total population = " + totalPopulation);
此代码的内部循环是 map-reduce 的一种形式,也可以使用流编写:
totalPopulation += state.getCities().stream().mapToInt(City::getPopulation).sum();
外层和内层有点不匹配,将流放入循环中不是一个很好的代码模式。
这正是flatmap的作用。此运算符在对象之间打开一对多关系,并基于这些关系创建流。flatMap() 方法将一个特殊函数作为参数,这个函数返回 Stream 对象。类与类之间的关系由此函数定义。
在我们的示例中,此函数很简单,因为State类中有一个List<City>。所以你可以按以下方式编写它。
//根据state和city的关系,生成city流
Function<State, Stream<City>> stateToCity = state -> state.getCities().stream();
此List类型不是强制的。假设您有一个包含 Map <String,Country>的Continent类,其中键是国家/地区的代码(CAN 表示加拿大,MEX 表示墨西哥,FRA 表示法国等)。假设该类有一个返回此map的方法getCountries()。
这种情况下,可以通过这种方式编写此函数。
Function<Continent, Stream<Country>> continentToCountry =
continent -> continent.getCountries().values().stream();
flatMap() 方法的处理分两个步骤。
- 第一步,使用此函数mapping流的所有元素。从
Stream<State>创建一个Stream<Stream<City>>,每个州都map为城市流。 - 第二步,展平产生的流。您最终会得到一个单一的流,其中包含所有州的所有城市。
因此,使用flatmap,之前的嵌套 for 编写的代码可以改写为:
List<State> states = ...;
int totalPopulation =
states.stream()
.flatMap(state -> state.getCities().stream())//对每个state,都转换为city流,最后合并
.mapToInt(City::getPopulation)
.sum();
System.out.println("Total population = " + totalPopulation);
使用flatmap和 MapMulti 验证元素转换
flatMap 可用于流元素的转换中的验证。
假设您有一个表示整数的字符串流。您需要用 Integer.parseInt() 将它们转为整数。不幸的是,其中一些字符串有问题:也许有些字符串为空,null,或者末尾有额外的空白字符。这些都会使解析失败,并出现 NumberFormatException。当然,您可以尝试filter此流,用Predicate删除错误的字符串,但最安全的方法是使用 try-catch 模式。
如下所示。
Predicate<String> isANumber = s -> {
try {
int i = Integer.parseInt(s);
return true;
} catch (NumberFormatException e) {
return false;
}
};
第一个缺陷是您需要实际进行转换以查看它是否有效。然后,您不得不在mapping函数中再次执行此操作:不要这样做!第二个缺陷是,从catch块return,绝不是一个好主意。
您真正需要做的是,当此字符串中有一个正确的整数时返回一个整数,如果有问题,则什么都不返回。这是flatmap的工作。如果可以解析整数,则可以返回包含结果的流。另一种情况下,您可以返回空流。
然后,可以编写以下函数。
Function<String, Stream<Integer>> flatParser = s -> {//根据String与Integer的关系,生成Integer流
try {
return Stream.of(Integer.parseInt(s));
} catch (NumberFormatException e) {
}
return Stream.empty();
};
List<String> strings = List.of("1", " ", "2", "3 ", "", "3");
List<Integer> ints =
strings.stream()
.flatMap(flatParser)//对每个String,都转为Integer流,最后合并 flatmap会跳过空流
.collect(Collectors.toList());
System.out.println("ints = " + ints);
运行此代码将生成以下结果。所有有问题的字符串都已静默删除。
ints = [1, 2, 3]
这种flatmap代码的使用效果很好,但它有一个开销:为流的每个元素都会创建一个流。从 Java SE 16 开始,Stream API 中添加了一个方法:当您创建零个或一个对象的多个流时。此方法称为mapMulti(),并将BiConsumer作为参数。
此 BiConsumer 使用两个参数:
- 需要mapping的流元素
- 对mapping结果调用的
Consumer
调用Consumer会将该元素添加到生成的流中。如果mapping无法完成,则biconsumer不会调用此消费者,并且不会添加任何元素。
让我们用这个 mapMulti() 方法重写你的模式。
List<Integer> ints =
strings.stream()
.<Integer>mapMulti((string, consumer) -> {//方法前面声明Integer
try {
consumer.accept(Integer.parseInt(string));//直接说明跟Integer的关系,生成最终Integer流
} catch (NumberFormatException ignored) {
}
})
.collect(Collectors.toList());
System.out.println("ints = " + ints);
运行此代码会产生与以前相同的结果。所有有问题的字符串都已被静默删除,但这一次,没有创建其他流。
ints = [1, 2, 3]
使用此方法,需要告诉编译器 Consumer 的类型。通过这种特殊语法,在 mapMulti() 前声明此类型。它不是您在 Java 代码中经常看到的语法。您可以在静态和非静态上下文中使用它。
删除重复项并对流进行排序
Stream API 有两个方法,distinct() 和 sorted(),去重和排序。distinct() 方法使用 hashCode() 和 equals() 方法来发现重复项。sorted() 方法有一个重载,需要一个comparator,用于比较和排序。如果未提供,则假定流元素具有可比性。否则,则会引发 ClassCastException。
您可能还记得本教程的前一部分,流应该是不存储任何数据的空对象。此规则也有例外,这两个方法就是。
事实上,为了发现重复项,distinct() 方法需要存储流元素。当处理一个元素时,首先检查该元素是否见到过。
sorted() 也是如此。此方法需要存储所有元素,然后在内部缓冲区中对它们进行排序,再发送到管道的下一步。
distinct() 可以用于非绑定(无限)流,而 sorted() 不能。
限制和跳过流的元素
Stream API 提供了两种选择流元素的方法:基于索引或使用Predicate。
第一种方法,使用 skip() 和 limit() 方法,两者都将 long 作为参数。使用这些方法时,需要避免一个小陷阱。您需要记住,每次在流中调用中继方法时,都会创建一个新流。因此,如果您在 skip() 之后调用 limit(),请不要忘记从该新流开始计算。
假设您有一个包含所有整数的流,从 1 开始。您需要选择 3 到 8 之间的整数。正确的代码如下。
List<Integer> ints = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9);
List<Integer> result =
ints.stream()
.skip(2)//产生了新流
.limit(5)//不是limit(8)
.collect(Collectors.toList());
System.out.println("result = " + result);
此代码打印以下内容。
result = [3, 4, 5, 6, 7]
Java SE 9 又引入了两种方法。它不是根据元素在流中的索引跳过和限制元素,而是根据Predicate。
dropWhile(Predicate)如果Predicate为true,一直跳过元素,直到Predicate为false。此时,该流后面所有元素都将传输到下一个流。takeWhile(Predicate)做相反的事情:如果Predicate为true,它一直将元素传输到下一个流,直到Predicate为false,后面都跳过。这个是短路的
请注意,这些方法的工作方式类似于门。一旦 dropWhile() 打开了门让处理后的元素流动,它就不会关闭它。一旦 takeWhile() 关闭了门,它就不能重新打开它,没有更多的元素将被发送到下一个操作。
串联流
Stream API 提供了多种模式,可将多个流连接成一个。最明显的方法是使用 Stream 接口中定义的工厂方法:concat()。
此方法接收两个流并生成一个流,其中包含第一个流的元素,然后是第二个流的元素。
您可能想知道为什么此方法不用 vararg 来连接任意数量的流。如果你有两个以上,JavaDoc API文档建议你使用另一种模式,基于flatmap。
让我们在一个例子上看看这是如何工作的。
List<Integer> list0 = List.of(1, 2, 3);
List<Integer> list1 = List.of(4, 5, 6);
List<Integer> list2 = List.of(7, 8, 9);
// 1st pattern: concat
List<Integer> concat =
Stream.concat(list0.stream(), list1.stream())
.collect(Collectors.toList());
// 2nd pattern: flatMap
List<Integer> flatMap =
Stream.of(list0.stream(), list1.stream(), list2.stream())//类似city的外层组成的流
.flatMap(Function.identity())//变成了city流,每个Stream<Integer>要变成Stream<Integer>,原样返回即可
.collect(Collectors.toList());
System.out.println("concat = " + concat);
System.out.println("flatMap = " + flatMap);
运行此代码将产生以下结果:
concat = [1, 2, 3, 4, 5, 6]
flatMap = [1, 2, 3, 4, 5, 6, 7, 8, 9]
建议使用 flatMap() 方式的原因是 concat() 在连接期间会创建中继流,来连接两个流。如果需要连接多个,则最终每次串联都需要一个很快就会被丢弃的流。
使用flatmap模式,您只需创建一个流来保存所有流并执行flatmap。开销要低得多。
您可能想知道为什么添加了这两种模式。看起来 concat() 并不是很有用。事实上,如果连接的两个流的源的大小已知,则生成的流的大小也是已知的,只是两个串联流的总和。
如果连接的两个流的源的大小已知,则生成的流的大小也是已知的。实际上,它只是两个串联流的总和。
在流上使用flatmap可能会创建未知数量的元素,以便在生成的流中进行处理。Stream API 会丢失对元素数量的跟踪。
换句话说:concat 产生一个 SIZED 流,而flatmap不会。此 SIZED 属性是流可能具有的一种属性,本教程稍后将介绍。
调试流
有时,在运行时能检查流处理的元素可能很方便。Stream API 有一个方法:peek() 方法。此方法用于调试数据处理管道。不应在生产代码中使用此方法。
绝对不要使用此方法在应用程序中执行一些副作用。
此方法将Consumer作为参数,将每个元素上调用。让我们实际效果。
List<String> strings = List.of("one", "two", "three", "four");
List<String> result =
strings.stream()
.peek(s -> System.out.println("Starting with = " + s))
.filter(s -> s.startsWith("t"))
.peek(s -> System.out.println("Filtered = " + s))
.map(String::toUpperCase)
.peek(s -> System.out.println("Mapped = " + s))
.collect(Collectors.toList());
System.out.println("result = " + result);
如果运行此代码,您将在控制台上看到以下内容。
Starting with = one
Starting with = two
Filtered = two
Mapped = TWO
Starting with = three
Filtered = three
Mapped = THREE
Starting with = four
result = [TWO, THREE]
让我们分析一下这个输出。
- 要处理的第一个元素是
one。你可以看到它被filter掉了。 - 第二个是
two。此元素通过filter,然后map为大写。然后将其添加到结果列表中。 - 第三个是
three,它也通过filter。 - 最后一个是
four,被filtering步骤拒绝。
有一点你在本教程前面看到,现在很明显:流确实一一处理了它必须处理的所有元素,从流的开始到结束。这在之前已经提到过,现在你可以看到它的实际效果。
您可以看到,此peek(System.out::println)模式对于逐个跟踪流处理的元素非常有用,无需调试代码。调试流很困难,需要小心放置断点的位置。大多数情况下,在流处理上放置断点会跳转到Stream接口的实现。这不是你需要的。您需要将这些断点放在 lambda 表达式的代码中。
创建流
创建流
在本教程中,您已经创建了许多流,所有这些都是通过调用 Collection 接口的 stream() 方法创建的。此方法非常方便:只需要两行简单的代码,您可以使用此流来试验Stream API 的几乎任何功能。
如您所见,还有许多其他方法。了解这些方法后,您可以在应用程序中的许多位置利用 Stream API,并编写更具可读性和可维护性的代码。
让我们快速浏览您将在本教程中看到的内容,然后再深入研究它们中的每一个。
第一组模式使用 Stream 接口中的工厂方法。使用它们,您可以从以下元素创建流:
- vararg 参数;
- supplier;
- unary operator,从前一个元素生成下一个元素;
- builder。
您甚至可以创建空流,这在某些情况下可能很方便。
您已经看到可以在集合上创建流。如果您拥有的只是一个iterator,而不是一个成熟的集合,那么您可以在iterator上创建流。如果你有一个数组,那么还有一个模式可以在数组的元素上创建一个流。
它并不止于此。JDK 中的许多模式也已添加到众所周知的对象中。然后,您可以从以下元素创建流:
- 字符串的字符;
- 文本文件的行;
- 通过使用正则表达式拆分字符串来创建的元素;
- 一个随机变量,可以创建随机数流。
您还可以使用builder模式创建流。
从集合或iterator创建流
您已经知道Collection接口中有一个可用的 stream() 。这可能是创建流的最经典方法。
在某些情况下,您可能需要基于map的内容创建流。Map 接口中没有stream()方法,因此无法直接创建。但是,您可以通过三个集合访问map的内容:
- 键的集合,
keySet() - 键值对的集合,
entrySet() - 值的集合,
values ()。
Stream API 提供了一种从简单iterator创建流的模式,它可能是在非标准数据源上创建流的非常方便的方法。模式如下。
Iterator<String> iterator = ...;
long estimateSize = 10L;
int characteristics = 0;
Spliterator<String> spliterator = Spliterators.spliterator(iterator, estimateSize, characteristics);
boolean parallel = false;
Stream<String> stream = StreamSupport.stream(spliterator, parallel);
此模式包含几个神奇元素,本教程稍后将介绍。让我们快速浏览它们。
estimateSize是您认为此流将消费的元素数。在某些情况下,此信息很容易获得:例如,如果要在数组或集合上创建流。但某些情况下是未知的。
本教程稍后将介绍characteristics参数。它用于优化数据的处理。
parallel参数告知 API 要创建的流是否为并行流。本教程稍后将介绍。
创建空流
让我们从最简单的开始:创建一个空流。Stream接口中有一个工厂方法。您可以通过以下方式使用它。
Stream<String> empty = Stream.empty();
List<String> strings = empty.collect(Collectors.toList());
System.out.println("strings = " + strings);
运行此代码会在主机上显示以下内容。
strings = []
在某些情况下,创建空流可能非常方便。事实上,您在本教程的前一部分看到了一个,使用空流和flatmap从流中删除无效元素。从 Java SE 16 开始,此模式已被 mapMulti() 模式所取代。
从 vararg 或数组创建流
两种模式非常相似。第一个在 Stream 接口中使用 of() 工厂方法。第二个使用 Arrays 工厂类的 stream() 工厂方法。事实上,如果你检查 Stream.of() 方法的源代码,你会看到它调用了 Arrays.stream()。
这是第一个实际模式。
Stream<Integer> intStream = Stream.of(1, 2, 3);
List<Integer> ints = intStream.collect(Collectors.toList());
System.out.println("ints = " + ints);
运行第一个示例将提供以下内容:
ints = [1, 2, 3]
这是第二个。
String[] stringArray = {"one", "two", "three"};
Stream<String> stringStream = Arrays.stream(stringArray);
List<String> strings = stringStream.collect(Collectors.toList());
System.out.println("strings = " + strings);
运行第二个示例将提供以下内容:
strings = [one, two, three]
从supplier创建流
Stream 接口上有两种工厂方法。
第一个是 generate(),以supplier为参数。每次需要新元素时,都会调用该supplier。
您可以使用以下代码创建这样的流,但不要这样做!
Stream<String> generated = Stream.generate(() -> "+");
List<String> strings = generated.collect(Collectors.toList());
如果你运行这段代码,你会发现它永远不会停止。如果您这样做并且有足够的耐心,您可能会看到 OutOfMemoryError。如果没有,最好通过 IDE 终止应用程序。它真的产生了无限的流。
我们还没有介绍这一点,但拥有这样的流是完全合法的!您可能想知道它们有什么用?事实上有很多。要使用它们,您需要在某个时候截断此流,而Stream API 为您提供了几种方法来执行此操作。
你已经看到了一个,是调用该流上的 limit()。让我们重写前面的示例,并修复它。
Stream<String> generated = Stream.generate(() -> "+");
List<String> strings =
generated
.limit(10L)
.collect(Collectors.toList());
System.out.println("strings = " + strings);
运行此代码将打印以下内容。
strings = [+, +, +, +, +, +, +, +, +, +]
limit() 方法称为短路方法:它可以停止流元素的消费。
从unary operator和种子创建流
如果您需要生成常量的流,使用supplier非常有用。如果你需要一个具有不同值的无限流,那么你可以使用 iterate() 模式。
此模式适用于种子,种子是第一个生成的元素。然后,它使用 UnaryOperator 转换前一个元素来生成流的下一个元素。
Stream<String> iterated = Stream.iterate("+", s -> s + "+");//根据前后关系函数,挨个生成无限流
iterated.limit(5L).forEach(System.out::println);
您应该看到以下结果。
+
++
+++
++++
+++++
使用此模式时,不要忘记限制元素数。
从 Java SE 9 开始,此模式具有重载,它将Predicate作为参数。当此Predicate变为 false 时,iterate() 方法将停止生成元素。前面的代码可以通过以下方式使用此模式。
Stream<String> iterated = Stream.iterate("+", s -> s.length() <= 5, s -> s + "+");
iterated.forEach(System.out::println);
运行此代码会得到与上一个代码相同的结果。
从一系列数字创建流
使用以前的模式可以创建一系列数字。但是,使用专门的数字流及其 range() 工厂方法会更容易。
range() 接收初始值和范围的上限(不包含)为参数。也可以在 rangeClosed() 方法中包含上限。调用 LongStream.range(0L, 10L) 将简单地生成一个流,其中所有long都在 0 到 9 之间。
这个 range() 方法也可以用来遍历数组的元素。这是您可以做到这一点的方法。
String[] letters = {"A", "B", "C", "D"};
List<String> listLetters =
IntStream.range(0, 10)
.mapToObj(index -> letters[index % letters.length])//实现了数组的遍历
.collect(Collectors.toList());
System.out.println("listLetters = " + listLeters);
结果如下。
listLetters = [A, B, C, D, A, B, C, D, A, B]
基于此模式,您可以做很多事情。请注意,由于 IntStream.range() 创建了一个 IntStream(原始类型流),因此您需要使用 mapToObj() 方法将其转换为对象流。
创建随机数流
Random类用于创建随机数字序列。从 Java SE 8 开始,已向此类添加了几个方法来创建不同类型的随机数流int,long,double
您可以创建提供种子参数的Random实例。此种子是一个long。随机数取决于该种子。对于给定的种子,您将始终获得相同的数字序列。这在许多情况下可能很方便,包括编写测试。这种情况下,数字序列可以预先知道。
有三种方法可以生成这样的流,它们都在 Random 类中定义:ints()、longs() 和doubles()。
所有这些方法都有几个重载可用,它们接受以下参数:
- 此流将生成的元素数;
- 生成的随机数的上限和下限。
下面是生成 10 个介于 1 和 5 之间的随机整数的第一种代码模式。
Random random = new Random(314L);
List<Integer> randomInts =
random.ints(10, 1, 5)
.boxed()//装箱
.collect(Collectors.toList());
System.out.println("randomInts = " + randomInts);
如果您使用的种子与此示例中使用的种子相同,则控制台中将具有以下内容。
randomInts = [4, 4, 3, 1, 1, 1, 2, 2, 4, 2]
请注意,我们在专用数字流中使用了 boxed() 方法,它只是将此流map为等效的包装器类型流。因此,通过此方法将 IntStream 转换为 Stream<Integer>。
这是第二种模式。该流的任何元素都是true,概率为 80%。
Random random = new Random(314L);
List<Boolean> booleans =
random.doubles(1_000, 0d, 1d)
.mapToObj(rand -> rand <= 0.8) // you can tune the probability here
.collect(Collectors.toList());
// Let us count the number of true in this list
long numberOfTrue =
booleans.stream()
.filter(b -> b)//b本身就是boolean
.count();
System.out.println("numberOfTrue = " + numberOfTrue);
如果您使用的种子与我们在本示例中使用的种子相同,您将看到以下结果。
numberOfTrue = 773
您可以调整此模式以生成具有所需概率的任何类型的对象。下面是另一个示例,它生成带有字母 A、B、C 和 D 的流。每个字母的概率如下:
- A的50%;
- B的30%;
- C的10%;
- D的10%。
Random random = new Random(314L);
List<String> letters =
random.doubles(1_000, 0d, 1d)
.mapToObj(rand ->
rand < 0.5 ? "A" : // 50% of A
rand < 0.8 ? "B" : // 30% of B
rand < 0.9 ? "C" : // 10% of C
"D") // 10% of D
.collect(Collectors.toList());
Map<String, Long> map =
letters.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));//每个出现的次数
map.forEach((letter, number) -> System.out.println(letter + " :: " + number));
使用相同的种子,您将获得以下结果。
A :: 470
B :: 303
C :: 117
D :: 110
此时,使用此 groupingBy() 构建map可能看起来不明白。不用担心,本教程稍后将介绍。
从字符串的字符创建流
String 类在 Java SE 8 中添加了一个 chars() 方法。此方法返回一个 IntStream,该 IntStream 为您提供字符。
每个字符都作为一个整数给出, ASCII 码。在某些情况下,您可能需要转换为字符串。
您有两种模式可以执行此操作,具体取决于您使用的 JDK 版本。
在 Java SE 10 之前,您可以使用以下代码。
String sentence = "Hello Duke";
List<String> letters =
sentence.chars()
.mapToObj(codePoint -> (char)codePoint)//int => char
.map(Object::toString)// char =>String
.collect(Collectors.toList());
System.out.println("letters = " + letters);
在 Java SE 11 的 Character 类中添加了一个 toString() 工厂方法,您可以使用它来简化此代码。
String sentence = "Hello Duke";
List<String> letters =
sentence.chars()
.mapToObj(Character::toString)//int =>String
.collect(Collectors.toList());
System.out.println("letters = " + letters);
两个代码都打印出以下内容。
letters = [H, e, l, l, o, , D, u, k, e]
从文本文件的行创建流
能够在文本文件上打开流是一种非常强大的模式。
Java I/O API 有一个模式,能从文本文件中读取一行:BufferedReader.readLine()。您可以循环调用此方法,逐行读取整个文本。
使用 Stream API 能为你提供更具可读性和更易于维护的代码。
有几种模式可以创建这样的流。
如果需要基于buffered reader重构现有代码,则可以使用在此对象上定义的lines()方法。如果要编写新代码,可以使用工厂方法 Files.lines()。最后一种方法将 Path 作为参数,并具有一个重载方法,添加 CharSet为参数,以防文件不是以 UTF-8 编码。
您可能知道,文件资源与任何 I/O 资源一样,当不再需要时,应将其关闭。
好消息是Stream接口实现了AutoCloseable。流本身就是一个资源,您可以在需要时关闭它。上面您看到的所有示例都运行在内存中,并不需要,但下面情况下肯定是必需的。
下面是计算日志文件中警告数量的示例。
Path log = Path.of("/tmp/debug.log"); // adjust to fit your installation
try (Stream<String> lines = Files.lines(log)) {
long warnings =
lines.filter(line -> line.contains("WARNING"))
.count();
System.out.println("Number of warnings = " + warnings);
} catch (IOException e) {
// do something with the exception
}
try-with-resources模式将调用流的 close() 方法,该方法将正确关闭已解析的文本文件。
从正则表达式创建流
这一系列模式的最后一个示例是添加到 Pattern 类的方法,用于在将正则表达式应用于字符串生成的元素上创建流。
假设您需要用给定的分隔符拆分字符串。您有两种模式来执行此操作。
- 你可以调用
String.split()方法; - 或者,您可以使用
Pattern.compile().split()模式。
这两种模式都为您提供了一个字符串数组,其中包含拆分后的结果元素。
上面您看到了从此数组创建流的模式。让我们编写此代码。
String sentence = "For there is good news yet to hear and fine things to be seen";
String[] elements = sentence.split(" ");
Stream<String> stream = Arrays.stream(elements);
Pattern类也有一个适合你的方法。你可以调用 Pattern.compile().splitAsStream()。下面是可以使用此方法编写的代码。
String sentence = "For there is good news yet to hear and fine things to be seen";
Pattern pattern = Pattern.compile(" ");
Stream<String> stream = pattern.splitAsStream(sentence);//
List<String> words = stream.collect(Collectors.toList());
System.out.println("words = " + words);
运行此代码将生成以下结果。
words = [For, there, is, good, news, yet, to, hear, and, fine, things, to, be, seen]
您可能想知道这两种模式中哪一种最好。要回答这个问题,您需要仔细查看下。第一种模式首先,创建一个数组来存储拆分的结果,然后在此数组上创建一个流。
在第二种模式中没有创建数组,因此开销更少。
您已经看到某些流可能使用短路操作(本教程稍后将详细介绍这一点)。如果您有这样的流,拆分整个字符串并创建生成的数组可能是一个重要但无用的开销。流管道不一定非要使用其所有元素才能生成结果。
即使您的流需要使用所有元素,将所有这些元素存储在数组中仍然是不必要的。
因此,使用 splitAsStream() 模式更好。在内存和 CPU 方面更好。
使用builder模式创建流
使用此模式创建流的过程分为两个步骤。首先,在builder中添加流将使用的元素。然后,从此builder创建流。使用builder创建流后,您将无法向其添加更多元素,也无法再次使用它来构建另一个流。如果你这样做,你会得到一个IllegalStateException。
模式如下。
Stream.Builder<String> builder = Stream.<String>builder();
builder.add("one")
.add("two")
.add("three")
.add("four");
Stream<String> stream = builder.build();//无法再次更改
List<String> list = stream.collect(Collectors.toList());
System.out.println("list = " + list);
运行此代码将打印以下内容。
list = [one, two, three, four]
在 HTTP 源上创建流
我们在本教程中介绍的最后一个模式是关于分析 HTTP 响应的主体。您看到您可以在文本文件的行上创建流,也可以在 HTTP 响应的正文上执行相同的操作。此模式由添加到 JDK 11 的 HTTP Client API 提供。
这是它的工作原理。我们将在在线提供的文本中使用它:查尔斯狄更斯的《双城记》,由古腾堡项目在线提供:https://www.gutenberg.org/files/98/98-0.txt
文本文件的开头提供有关文本本身的信息。这本书的开头是“A TALE OF TWO CITIES”。文件的末尾是分发此文件的许可证。
我们只需要本书的文本,并希望删除此分布式文件的页眉和页脚。
// The URI of the file
URI uri = URI.create("https://www.gutenberg.org/files/98/98-0.txt");
// The code to open create an HTTP request
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder(uri).build();
// The sending of the request
HttpResponse<Stream<String>> response = client.send(request, HttpResponse.BodyHandlers.ofLines());
List<String> lines;
try (Stream<String> stream = response.body()) {
lines = stream
.dropWhile(line -> !line.equals("A TALE OF TWO CITIES"))
.takeWhile(line -> !line.equals("*** END OF THE PROJECT GUTENBERG EBOOK A TALE OF TWO CITIES ***"))
.collect(Collectors.toList());
}
System.out.println("# lines = " + lines.size());
运行此代码将打印出以下内容。
# lines = 15904
流由您提供的body handler创建,作为 send() 方法的参数。HTTP Client API 为您提供了多个body handler。上面是由工厂方法 HttpResponse.BodyHandlers.ofLines() 创建的。这种消费响应主体的方式非常节省内存。如果仔细编写流,响应的正文将永远不会存储在内存中。
我们这里将所有文本行放在一个列表中,但是,您不一定需要这样做。实际上,大多数情况下,将此数据存储在内存中可能是一个坏主意。
reduce流
reduce流
到目前为止,您在本教程中了解到,reduce流包括以类似于 SQL 语言中的方式聚合该流的元素。在您运行的示例中,您还使用collect(Collectors.toList())模式在列表中收集了您构建的流的元素。所有这些操作在Stream API 中称为末端操作,包括reduce流。
在流上调用末端操作时,需要记住两件事。
- 没有末端操作的流不会处理任何数据。如果您在应用程序中发现这样的流,则很可能是一个错误。
- 一个流同时只能有一个中继或末端操作调用。您不能重复使用流;如果你尝试这样做,你会得到一个
IllegalStateException。
使用binary operator来reduce流
在 Stream 接口中定义的 reduce() 方法有三个重载。它们都接收 BinaryOperator 对象作为参数。让我们看看如何使用这个binary operator。
让我们举个例子。假设您有一个整数列表,您需要计算这些整数的总和。您可以使用经典的 for 循环模式编写以下代码来计算此总和。
List<Integer> ints = List.of(3, 6, 2, 1);
int sum = ints.get(0);
for (int index = 1; index < ints.size(); index++) {
sum += ints.get(index);
}
System.out.println("sum = " + sum);
运行它会打印出以下结果。
sum = 12
此代码的作用如下。
- 将列表中的前两个元素相加。
- 然后取下一个元素并将其求和到您计算的部分总和。
- 重复该过程,直到到达列表末尾。
如果仔细检查此代码,可以使用binary operator对 SUM 运算符进行建模,以获得相同的结果。然后,代码将变为以下内容。
List<Integer> ints = List.of(3, 6, 2, 1);
BinaryOperator<Integer> sum = (a, b) -> a + b;//把操作逻辑提取为lambda
int result = ints.get(0);
for (int index = 1; index < ints.size(); index++) {
result = sum.apply(result, ints.get(index));
}
System.out.println("sum = " + result);
现在您可以看到此代码仅依赖于binary operator本身。假设您需要计算一个 MAX。您需要做的就是为此提供正确的binary operator。
List<Integer> ints = List.of(3, 6, 2, 1);
BinaryOperator<Integer> max = (a, b) -> a > b ? a: b;//提供具体函数即可
int result = ints.get(0);
for (int index = 1; index < ints.size(); index++) {
result = max.apply(result, ints.get(index));
}
System.out.println("max = " + result);
结论是,您确实可以仅提供binary operator来计算reduce。这就是 reduce() 方法在 Stream API 中的工作方式。
选择可以并行使用的binary operator
不过,您需要了解两个注意事项。让我们在这里介绍第一个。
第一个是可以并行计算的流。本教程稍后将更详细地介绍这一点,但现在需要讨论它,因为它对这个binary operator有影响。数据源分为两部分,每部分单独处理。每个进程都与您刚刚看到的进程相同,它使用binary operator。然后,在处理每个部分时,两个部分结果将使用相同的binary operator合并。

并行处理这个数据流非常简单:只需在给定流上调用 parallel() 即可。
让我们来看看事情是如何工作的,为此,您可以编写以下代码。您只是在模拟如何并行执行计算。当然,这是并行流的过度简化版本,只是为了解释事情是如何工作的。
让我们创建一个 reduce() 方法,该方法接收binary operator并使用它来reduce整数列表。代码如下。
int reduce(List<Integer> ints, BinaryOperator<Integer> sum) {
int result = ints.get(0);
for (int index = 1; index < ints.size(); index++) {
result = sum.apply(result, ints.get(index));
}
return result;
}
下面是使用此方法的主要代码。
List<Integer> ints = List.of(3, 6, 2, 1);
BinaryOperator<Integer> sum = (a, b) -> a + b;//两个Integer的具体操作
int result1 = reduce(ints.subList(0, 2), sum);
int result2 = reduce(ints.subList(2, 4), sum);
int result = sum.apply(result1, result2);
System.out.println("sum = " + result);
为了让过程更明显,我们将您的数据源分为两部分,并将它们分别reduce为两个整数:reduce1和reduce2 。然后,我们使用相同的binary operator合并了这些结果。这基本上就是并行流的工作方式。
这段代码非常简化,它只是为了显示你的binary operator应该具有的一个非常特殊的属性。拆分流的方式不应影响计算结果。以下所有拆分都应提供相同的结果:
3 + (6 + 2 + 1)(3 + 6) + (2 + 1)(3 + 6 + 2) + 1
这表明您的binary operator应该具有一个称为结合性 associativity的已知属性。传递给 reduce() 方法的binary operator应该是可结合的。
Stream API 的 reduce() 重载版本, JavaDoc API 文档指出,您作为参数提供的binary operator必须是可结合的。
如果不是这样,会发生什么?嗯,这正是问题所在:编译器和 Java 运行时都不会检测到它。因此,您的数据将被处理,没有明显的错误。你可能有正确的结果,也可能没有;这取决于内部处理数据的方式。事实上,如果你多次运行代码,你最终可能会得到不同的结果。这是您需要注意的非常重要的一点。
如何测试binary operator是否可结合?在某些情况下,这可能非常简单:SUM,MIN,MAX是众所周知的可结合运算符。在其他一些情况下,这可能要困难得多。检查的一种方法,可以是在随机数据上运行binary operator,并验证是否始终获得相同的结果。
管理具有幺元的binary operator
第二个是binary operator这种结合性产生的结果。
此结合性属性是由以下事实保证的:数据的拆分方式不应影响计算结果。如果将集合 A 拆分为两个子集 B 和 C,则reduce A 应该得到与reduce (B 的reduce和 C 的reduce)相同的结果。
可以将前面的属性写入更通用的表达式:
A = B ⋃ C ⇒ Red(A) = Red(Red(B), Red(C))
事实证明,这导致了另一个问题。假设事情出了意外,B实际上是空的。这种情况下,C = A。前面的表达式变为以下内容:
Red(A) = Red(Red(∅), Red(A)) //必须成立才行
当且仅当空集 (∅) 的reduce是reduce操作的幺元identity element时,才是正确的。
这是数据处理中的一种属性:空集的reduce是reduce操作的幺元。
在数据处理中这确实是一个问题,尤其是在并行处理中,一些非常经典的binary operator并没有幺元,比如 MIN 和 MAX。空集的最小元素没有定义,因为 MIN 操作没有幺元。
此问题必须在Stream API 中解决,因为您可能必须处理空流。您看到了创建空流的模式,很容易看出 filter() 可以filter掉所有数据,从而返回空流。
Stream API 是这样处理的。幺元未知(不存在或未提供)的reduce将返回 Optional 类的实例。我们将在本教程后面更详细地介绍此类。此时您需要知道的是,此 Optional 类是一个可以为空的包装类。每次对没有已知幺元的流调用末端操作时,Stream API 都会将结果包装在该对象中。如果处理的流为空,则此Optional对象也将为空,下一步如何处理将由您和您的应用程序决定。
探索Stream API 的reduce方法
正如我们前面提到的,Stream API 有三个重载的 reduce() 方法,我们现在可以详细介绍这些重载。
使用幺元进行reduce
第一个接收幺元和 BinaryOperator 的实例。由于您提供的第一个参数是binary operator的已知幺元,因此具体实现可能会使用它来简化计算。从这个幺元开始,启动进程,而不是选两个元素。使用的算法具有以下形式。
List<Integer> ints = List.of(3, 6, 2, 1);
BinaryOperator<Integer> sum = (a, b) -> a + b;
int identity = 0;
int result = identity;//人为设定幺元,初始值
for (int i: ints) {
result = sum.apply(result, i);
}
System.out.println("sum = " + result);
你可以注意到,即使你需要处理的列表是空的,这种编写方式也能很好地工作。这种情况下,它将返回幺元,这是您需要的。
API 不会检查您提供的元素确实是binary operator的幺元这一事实。提供不对的元素将返回错误的结果。
您可以在以下示例中看到这一点。
Stream<Integer> ints = Stream.of(0, 0, 0, 0);
int sum = ints.reduce(10, (a, b) -> a + b);//初始值为10
System.out.println("sum = " + sum);
您希望此代码在控制台上打印值 0。因为 reduce() 方法调用的第一个参数不是binary operator的幺元,所以结果实际上是错误的。运行此代码将在主机上打印以下内容。
sum = 10
这是您应该使用的正确代码。
Stream<Integer> ints = Stream.of(0, 0, 0, 0);
int sum = ints.reduce(0, (a, b) -> a + b);//初始值为0
System.out.println("sum = " + sum);
此示例说明在编译或运行代码时传递错误的幺元不会触发任何错误或异常。具体取决于您。
此属性的测试方式可以跟测试结合性相同。将候选幺元与尽可能多的值组合在一起。如果您找到一个因组合而改变的值,那么您的幺元就不是合适的候选。反之并不成立,如果您找不到任何错误的组合,并不一定意味着您的候选就是正确的。
不使用幺元进行reduce
reduce() 方法的第二个重载接收没有幺元的 BinaryOperator 实例作为参数。正如预期的那样,它返回一个 Optional 对象,包装reduce的结果。使用Optional做的最简单的事情,就是打开并查看其中是否有任何东西。
让我们举一个没有幺元的reduce示例。
Stream<Integer> ints = Stream.of(2, 8, 1, 5, 3);
Optional<Integer> optional = ints.reduce((i1, i2) -> i1 > i2 ? i1: i2);//大于空集没有意义,可能为null
if (optional.isPresent()) {
System.out.println("result = " + optional.orElseThrow());
} else {
System.out.println("No result could be computed");
}
运行此代码将产生以下结果。
result = 8
请注意,此代码使用 orElseThrow() 方法打开可选代码,该方法现在是执行此操作的首选方法。此模式已在 Java SE 10 中添加,以取代最初在 Java SE 8 中引入的更传统的 get() 方法。
get()方法的问题在于,如果Optional为空,可能会抛出一个NoSuchElementException。此方法的命名 orElseThrow() 比 get() 更直观,它提醒您,打开空的Optional您将收到异常。
使用Optional可以完成更多操作,您将在本教程后面了解。
在一种方法中组合map和reduce
第三个稍微复杂一些。它使用多个参数组合combine了内部mapping和reduce。
让我们检查一下此方法的签名。
<U> U reduce(U identity,//幺元
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);//两个U类型的具体操作
类型U在本地定义并由binary operator使用。binary operator的工作方式与 reduce() 刚才那个重载相同,只是它不应用于流的元素,而仅应用于它们mapping后的版本。
这种mapping和reduce本身实际上组合为一个操作:累加器accumulator。请记住,在本部分的开头,您看到reduce是逐步进行的,并且一次消费一个元素。在每一步,reduce操作的第一个参数是到目前为止消费的所有元素的reduce部分。
幺元是combiner的幺元。的确是这样。
假设您有一个 String 实例流,您需要对所有字符串的长度求和。
combiner组合了两个部分:到目前处理的字符串长度的部分总和,两个整数。
accumulator从流中获取一个元素,将其map为一个整数(该字符串的长度),并将其添加到到目前为止计算的总和中。
以下是该算法的工作原理。
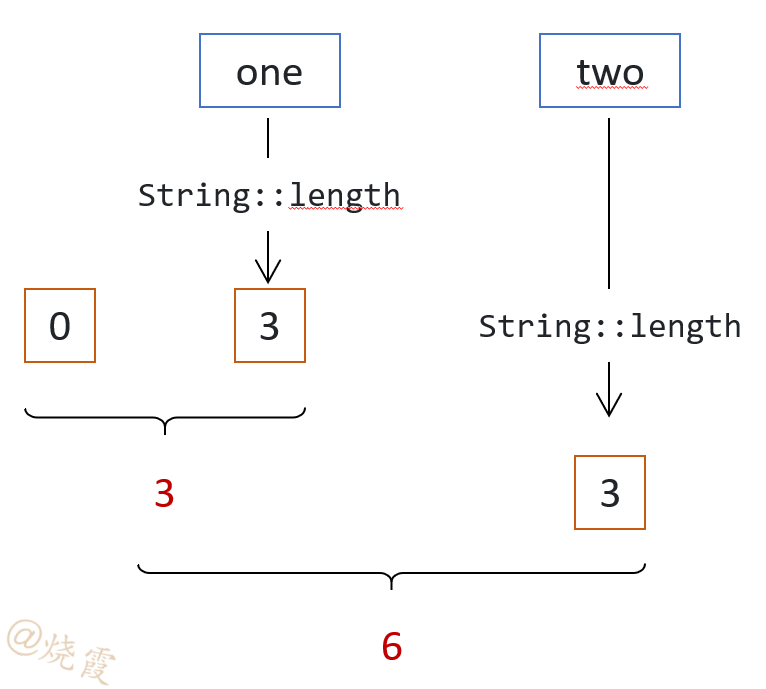
相应的代码如下。
Stream<String> strings = Stream.of("one", "two", "three", "four");
BinaryOperator<Integer> combiner = (length1, length2) -> length1 + length2;//两个Integer部分总和,具体操作
//累加mapping操作:部分总和Integer,跟新元素String作运算,返回新的部分总和Integer
BiFunction<Integer, String, Integer> accumulator =
(partialReduction, element) -> partialReduction + element.length();
int result = strings.reduce(0, accumulator, combiner);//combiner的初始值为0
System.out.println("sum = " + result);
运行此代码将生成以下结果。
sum = 15
在上面的示例中,mapping过程实际为以下函数。
Function<String, Integer> mapper = String::length;
因此,您可以将accumulator重写为以下模式。这种写法清楚地显示了mapping的组合过程。
Function<String, Integer> mapper = String::length;//mapping
BinaryOperator<Integer> combiner = (length1, length2) -> length1 + length2;
BiFunction<Integer, String, Integer> accumulator =
(partialReduction, element) -> partialReduction + mapper.apply(element);
在流上添加末端操作
避免使用reduce方法
如果流不以末端操作结束,则不会处理任何数据。我们已经介绍了末端操作 reduce(),您在其他示例中看到了几个末端操作。现在让我们介绍其他几个。
使用 reduce() 方法并不是reduce流的最简单方法。您需要确保您提供的binary operator是可结合的,然后您需要知道它是否具有幺元。您需要检查许多点,以确保您的代码正确并产生您期望的结果。如果你可以避免使用 reduce() 方法,那么你绝对应该这样做,因为它很容易出错。
幸运的是,Stream API 为您提供了许多其他reduce流的方法:我们在介绍专门的数字流时介绍的 sum()、min() 和 max() 是您可以使用的便捷方法。事实上,你只能吧 reduce() 方法作为最后的手段,只有当你没有其他解决方案时。
计算元素数量
count() 方法存在于所有流接口中,包括专用流和对象流。它用long返回该流处理的元素数。这个数字可能很大,实际上大于 Integer.MAX_VALUE。
您可能想知道为什么需要如此多的数字。实际上,您可以从许多源创建流,包括可以生成大量元素的源,大于 Integer.MAX_VALUE。即使不是这种情况,也很容易创建一个中继操作,将流处理的元素数量成倍增加。我们在本教程前面介绍的 flatMap() 方法可以做到这一点。有很多方法可以让你最终超过 Integer.MAX_VALUE 。这就是 Stream API 支持它的原因。
下面是 count() 方法的一个示例。
Collection<String> strings =
List.of("one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten");
long count =
strings.stream()
.filter(s -> s.length() == 3)
.count();
System.out.println("count = " + count);
运行此代码将生成以下结果。
count = 4
逐个消费元素
Stream API 的 forEach() 方法允许您将流的每个元素传递给Consumer接口的实例。此方法对于打印流处理的元素非常方便。这就是以下代码的作用。
Stream<String> strings = Stream.of("one", "two", "three", "four");
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.forEach(System.out::println);
运行此代码将打印以下内容。
ONE
TWO
这种方法非常简单,但您可能会用错。
请记住,您编写的 lambda 表达式应避免改变其外部作用域。有时,在状态外发生突变称为传导副作用。刚才的Consumer很特殊,因为没有什么特别的副作用。实际上也有,调用 System.out.println() 会对应用程序的控制台产生副作用。
让我们考虑以下示例。
Stream<String> strings = Stream.of("one", "two", "three", "four");
List<String> result = new ArrayList<>();
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.forEach(result::add);
System.out.println("result = " + result);
运行前面的代码会打印出以下内容。
result = [ONE, TWO]
因此,您可能会想使用此代码,因为它很简单,而且能“正常工作”。好吧,这段代码正在做一些错误的事情。让我们来看看它们。
从流中调用result::add,将该流处理的所有元素添加到外部result列表中。此Consumer正在对流本身范围之外的变量产生副作用。
访问此类变量会使您的 lambda 表达式成为捕获式 lambda 表达式。创建这样的 lambda 表达式虽然完全合法,但会降低性能。如果性能是应用程序中的重要问题,则应避免编写捕获式 lambda。
此外,这种方式也会阻止此流的并行。实际上,如果您尝试使此流并行,您将有多个线程并行访问您的result列表。而 ArrayList 并不是并发安全的类。
有两种变通模式收集到列表。下面的示例演示使用集合对象。
Stream<String> strings = Stream.of("one", "two", "three", "four");
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toList());
这段代码同样创建 ArrayList 的实例,并将流处理的元素添加到其中。不会产生任何副作用,因此不会对性能造成影响。
并行性和并发性由Collector API 本身处理,因此您可以安全地使此流并行。
从Java SE 16开始,您有第二种更简单的模式,使用collector对象。
Stream<String> strings = Stream.of("one", "two", "three", "four");
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.toList();
此模式生成 List 的特殊不可变实例。如果你需要一个可变列表,你应该使用上一种。另外,它还比在 ArrayList 中收集流的性能更好。这一点将在下一段介绍。
收集到集合或数组中
Stream API 提供了多种将流元素收集到集合中的方法。在上一节中,您初步了解了其中两种。让我们看看其他的。
在选择所需的模式之前,您需要问自己几个问题。
- 是否需要构建不可变列表?
- 你对
ArrayList的实例感到满意吗?或者你更喜欢LinkedList? - 您是否确切地知道您的流将处理多少个元素?
- 您是否需要在精确的、可能是第三方或自制的
List中收集您的元素?
Stream API 可以处理所有这些情况。
在ArrayList中收集
您已经在前面的示例中使用了此模式。它是您可以使用的最简单的方法,并返回 ArrayList 实例中的元素。
下面是这种模式的实际示例。
Stream<String> strings = Stream.of("one", "two", "three", "four");
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toList());
此模式创建 ArrayList 的简单实例,并在其中累积流的元素。如果有太多元素, ArrayList 的内部数组无法存储它们,则当前数组将被复制到一个更大的数组中,并由GC回收。
如果你想避免这种情况,并且知道你的流将产生的元素数量,那么你可以使用 Collectors.toCollection() ,它以supplier作为参数来创建集合,你将在其中收集处理的元素。以下代码使用此模式创建初始容量为 10,000 的 ArrayList 实例。
Stream<String> strings = ...;
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toCollection(() -> new ArrayList<>(10_000)));
在不可变List中收集
在某些情况下,您需要在不可变列表中累积元素。这听起来可能自相矛盾,因为收集意味着将元素添加到必须可变的容器中。实际上,这就是Collector API 的工作方式,本教程后面将详细介绍。在此累加操作结束时,Collector API 可以继续执行最后一个可选操作,本例中,在返回之前密封这个列表。
为此,您只需使用以下模式。
Stream<String> strings = ...;
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toUnmodifiableList()));
在此示例中,result是一个不可变列表。
从 Java SE 16 开始,有一种更好的方法可以在不可变列表中收集数据,这在某些情况下可能更有效。模式如下。
Stream<String> strings = ...;
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.toList();
如何提高效率的?第一种模式是建立在使用collector的基础上的,首先在普通 ArrayList 中收集元素,然后将其密封,使其在处理完成后不可变。您的代码看到的只是从此 ArrayList 构建的不可变列表。
如您所知,ArrayList 的实例是在具有固定大小的内部数组上构建的。此列表可能已满。这种情况下,ArrayList 实现会检测到并将其复制到更大的数组中。此机制对使用者是透明的,但会带来开销:复制此数组需要一些时间。
在某些情况下,在消费所有流之前,Stream API 可以跟踪要处理的元素数量。这种情况下,创建大小合适的内部数组更有效,因为它避免了将小数组到较大数组的开销。
Stream.toList() 方法已添加到 Java SE 16 中。如果您需要的是不可变的列表,那么您应该使用此模式。
在自制List中收集
如果您需要在自己的列表或 JDK 之外的第三方List中收集数据,则可以使用 Collectors.toCollection() 模式。用于调整 ArrayList 初始大小的supplier也可用于构建 Collection 的任何实现,包括不属于 JDK 的实现。您所需要的只是一个supplier。在以下示例中,我们提供了一个supplier来创建 LinkedList 的实例。
Stream<String> strings = ...;
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toCollection(LinkedList::new));
在Set中收集
由于 Set 接口是 Collection 接口的扩展,因此可以使用 Collectors.toCollection(HashSet::new) 在 Set 实例中收集数据。这很好,但 Collector API 仍然为您提供了一个更简洁的模式:Collectors.toSet()。
Stream<String> strings = ...;
Set<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toSet());
您可能想知道这两种模式之间是否有任何区别。答案是肯定的,存在细微的区别,您将在本教程后面看到。
如果你需要的是一个不可变的集合,Collector API 还有另一种模式:Collectors.toUnmodifiableSet()。
Stream<String> strings = ...;
Set<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toUnmodifiableSet());
在数组中收集
Stream API 也有自己的一组 toArray() 方法重载。其中有两个。
第一个是普通的 toArray() 方法,它返回Object[] .使用此模式会丢失元素的确切类型。
第二个参数接收 IntFunction<A[]> 类型的参数,按照size返回一个数组。乍一看可能很吓人,但编写此函数的实现实际上非常容易。如果需要构建一个字符串数组,则此函数的实现为 String[]::new。
Stream<String> strings = ...;
String[] result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.toArray(String[]::new);
System.out.println("result = " + Arrays.toString(result));
运行此代码将生成以下结果。
result = [ONE, TWO]
提取流的最大值和最小值
Stream API 为此提供了几种方法,具体取决于您当前正在使用的流。
我们已经介绍了来自专用数字流的 max() 和 min() 方法:IntStream、LongStream 和 DoubleStream。您知道这些操作没有幺元,因此所有都将返回Optional。
顺便说一下,同样来自数字流的 average() 方法也返回一个Optional对象,因为 average 操作也没有幺元。
Stream 接口也有两个方法 max() 和 min(),它们也返回一个Optional对象。与数字流的区别在于,Stream的元素实际上可以是任何类型的。为了能够计算最大值或最小值,实现需要比较这些对象。这就是您需要为这些方法提供comparator的原因。
这是 max() 方法的实际应用。
Stream<String> strings = Stream.of("one", "two", "three", "four");
String longest =
strings.max(Comparator.comparing(String::length))//对象Stream
.orElseThrow();
System.out.println("longest = " + longest);
它将打印以下内容。
longest = three
请记住,尝试打开空的Optional对象会抛出 NoSuchElementException,这是您不希望在应用程序中看到的内容。仅当您的流没有任何要处理的数据时,才会这样。在这个简单的示例中,你有一个流,它处理多个字符串,没有filter操作。此流不会为空,因此您可以安全地打开。
在流中查找元素
Stream API 为您提供了两个末端操作来查找元素:findFirst() 和 findAny()。这两个方法不接受任何参数,并返回流的单个元素。为了正确处理空流的情况,此元素包装在Optional对象中。如果流为空,则此Optional也为空。
了解返回哪个元素需要您了解流可能是顺序的。顺序流只是一种流,其中元素的顺序很重要,并由Stream API 保存。默认情况下,在任何顺序源(例如 List 接口的实现)上创建的流本身都是顺序的。
在这样的流上,称呼第一个、第二个或第三个元素是有意义的。找到这样一个流的第一个元素也是完全有意义的。
如果您的流无序,或者如果顺序在流处理中丢失了,则查找第一个元素是无法定义的,并且调用 findFirst() 实际上会返回流的任何元素。您将在本教程后面看到有关顺序流的更多详细信息。
请注意,调用 findFirst() 会在流实现中触发一些检查,以确保在对该流进行排序时获得该流的第一个元素。如果您的流是并行流,这可能代价很高。在许多情况下,获取的是不是第一个元素并无所谓,比如流仅处理单个元素的情况。在所有这些情况下,您应该使用 findAny() 而不是 findFirst()。
让我们看看 findFirst() 的实际效果。
Collection<String> strings =
List.of("one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten");
String first =
strings.stream()
// .unordered()
// .parallel()
.filter(s -> s.length() == 3)
.findFirst()
.orElseThrow();
System.out.println("first = " + first);
此流是在 List 的实例上创建的,这使它成为顺序流。请注意,在第一个版本中注释了 unordered() 和 parallel() 两行。
多次运行此代码将始终得到相同的结果。
first = one
unordered() 中继方法调用使顺序流成为无序流。这种情况下,它没有任何区别,因为您的流是按顺序处理的。您的数据是从始终以相同顺序遍历其元素的列表中提取的。出于同样的原因,将 findFirst() 方法调用替换为 findAny() 方法调用也没有任何区别。
可以对此代码进行的第一个修改是取消注释 parallel() 方法调用。现在,您有一个并行处理的顺序流。多次运行此代码将始终得到相同的结果:one。这是因为您的流是顺序的,因此无论您的流是如何处理的,第一个元素都是确定的。
要使此流无序,您可以取消注释 unordered() 方法调用,或者将(List.of)替换为 Set.of()。在这两种情况下,使用 findFirst() 终止流将从该并行流返回一个随机元素。并行流的处理方式使其如此。
您可以在此代码中进行的第二个修改是将 List.of() 替换为 Set.of()。现在不再是顺序的。此外,Set.of() 返回的实现,使得集合元素的遍历以随机顺序发生。多次运行此代码会显示 findFirst() 和 findAny() 都返回一个随机字符串,即使 unordered() 和 parallel() 都注释掉。查找无序源的第一个元素无法定义,结果是随机的。
从这些示例中,您可以推断出在并行流的实现中采取了一些预防措施来跟踪哪个元素是第一个。这造成了开销,因此,只有在确实需要时才应调用 findFirst()。
检查流的元素是否与Predicate匹配
在某些情况下,在流中查找元素或未能在流中找到元素可能是您真正需要的。您查找的元素不一定与您的应用程序有关;但是否存在非常重要。
以下代码将用于检查给定元素是否存在。
boolean exists =
strings.stream()
.filter(s -> s.length() == 3)
.findFirst()
.isPresent();
实际上,此代码检查返回的Optional是否为空。
上面的模式工作正常,但Stream API 提供了一种更有效的方法。实际上,构建此Optional对象是一种开销,如果您使用以下三种方法之一,则无需支付该开销。这三种方法将Predicate作为参数。
anyMatch(Predicate):如果找到与给定Predicate匹配的一个元素,则返回trueallMatch(Predicate):如果流的所有元素都与Predicate匹配,则返回truenoneMatch(Predicate):相反
让我们看看这些方法的实际应用。
Collection<String> strings =
List.of("one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten");
boolean noBlank =
strings.stream()
.allMatch(Predicate.not(String::isBlank));
boolean oneGT3 =
strings.stream()
.anyMatch(s -> s.length() == 3);
boolean allLT10 =
strings.stream()
.noneMatch(s -> s.length() > 10);
System.out.println("noBlank = " + noBlank);
System.out.println("oneGT3 = " + oneGT3);
System.out.println("allLT10 = " + allLT10);
运行此代码将生成以下结果。
noBlank = true
oneGT3 = true
allLT10 = true
短路流的处理
您可能已经注意到我们在此处介绍的不同末端操作之间的重要差异。
其中一些需要处理流消费的所有数据。COUNT、MAX、MIN、AVERAGE操作以及forEach()、toList()或toArray()方法调用就是这种情况。
我们介绍的最后一个末端操作并非如此。一旦找到元素,findFirst() 或 findAny() 方法就会停止处理您的数据,无论还有多少元素需要处理。anyMatch()、allMatch() 和 noneMatch() 也是如此:它们可能会中断流的处理并得到结果,而不必消费源所有元素。
这些方法在Stream API 中称为短路方法,因为它们可以半路生成结果,而无需处理流的所有元素。
在某些情况下,这些最后的方法仍然可能处理所有元素:
findFirst()和findAny()返回了空的Optional,只能在所有元素都已处理后。anyMatch()返回了false。- allMatch() 和
noneMatch()返回 了true。
查找流的特征
流的特征
Stream API 依赖于一个特殊的对象,即 Spliterator 接口的实例。此接口的名称来源于这样一个事实,即Stream API 中spliterator的角色类似于iterator在集合 API 中的角色。此外,由于Stream API 支持并行处理,因此spliterator对象还控制流在处理并行化时,不同 CPU 之间如何拆分其元素。名称是split和iterator的组合。
详细介绍此spliterator对象超出了本教程的范围。您需要知道的是,此spliterator对象具有流的特征。这些特征不是您经常使用到的,但了解它们是什么将帮助您在某些情况下编写更好、更高效的管道。
流的特征如下。
| 特征 | 评论 |
|---|---|
| ORDERED | 顺序的,处理流元素的顺序很重要。 |
| DISTINCT | 去重的,该流处理的元素中没有重复出现。 |
| NONNULL | 该流中没有空元素。 |
| SORTED | 排序的,对该流的元素已经进行排序。 |
| SIZED | 有数量的,此流处理的元素数是已知的。 |
| SUBSIZED | 拆分此流会产生两个 SIZED 流。 |
有两个特征,不可变 IMMUTABLE和并发的 CONCURRENT,本教程未介绍。
每个流在创建时都设置或取消设置了所有这些特征。
请记住,可以通过两种方式创建流。
- 您可以从数据源创建流,我们介绍了几种不同的模式。
- 每次对现有流调用中继操作时,都会创建一个新流。
给定流的特征取决于创建它的源,或者创建它的流的特征,以及创建的操作。如果您的流是使用源创建的,则其特征取决于该源,如果您使用另一个流创建它,则它们将取决于该其他流以及您正在使用的操作类型。
让我们更详细地介绍每个特征。
ORDERED流
顺序流是使用顺序数据源创建的。可能想到的第一个示例是 List 接口的任何实例。还有其他的:Files.lines(path) 和 Pattern.splitAsStream(string) 也生成 ORDERED 流。
跟踪流元素的顺序可能会导致并行流的开销。如果不需要此特性,则可以通过在现有流上调用 unordered() 中继方法来删除它。这将返回没有此特征的新流。你为什么要这样做?在某些情况下,保持流 ORDERED 可能会很昂贵,例如,当您使用并行流时。
SORTED流
SORTED的流是已排序的流。可以从已排序的源(如 TreeSet 实例)或通过调用 sorted() 方法创建此流。知道流已被排序可能会被流的某些实现拿来用,以避免再次进行排序。但排序后的顺序可能会变,因为 SORTED 流可能会使用与第一次不同的comparator再次排序。
有一些中继操作可以清除 SORTED 特征。在下面的代码中,您可以看到strings,filteredStream两者都是 SORTED 流,而lengths不是。
Collection<String> stringCollection = List.of("one", "two", "two", "three", "four", "five");
Stream<String> strings = stringCollection.stream().sorted();
Stream<String> filteredStrings = strings.filtered(s -> s.length() < 5);
Stream<Integer> lengths = filteredStrings.map(String::length);
mapping或flatmapping SORTED 流会从生成的流中删除此特征。
DISTINCT流
DISTINCT 流是它正在处理的元素之间没有重复项的流。例如,当从 HashSet 构建流时,或者从对 distinct() 中继方法调用的调用中构建流时,可以获得这样的特征。
DISTINCT 特征在filtering流时保留,但在mapping或flatmapping流时丢失。
让我们检查以下示例。
Collection<String> stringCollection = List.of("one", "two", "two", "three", "four", "five");
Stream<String> strings = stringCollection.stream().distinct();
Stream<String> filteredStrings = strings.filtered(s -> s.length() < 5);
Stream<Integer> lengths = filteredStrings.map(String::length);
stringCollection.stream()不是 DISTINCT 的,因为它是从List的实例构建的。strings是 DISTINCT 的,因为此流是通过调用distinct()中继方法创建的。filteredStrings仍然是 DISTINCT:从流中删除元素不会创造重复项。length已被map,因此 DISTINCT 特征丢失。
NONNULL 流
非空流是不包含null值的流。集合框架中的一些结构不接受空值,包括 ArrayDeque 和并发结构,如 ArrayBlockingQueue、ConcurrentSkipListSet 和调用 ConcurrentHashMap.newKeySet() 返回的并发Set。使用 Files.lines(path) 和 Pattern.splitAsStream(line) 创建的流也是非空流。
至于前面的特征,一些中继操作可以产生具有不同特征的流。
- filtering或排序非空流将返回非空流。
- 在 NONNULL 流上调用
distinct()也会返回一个 NONNULL 流。 - mapping或flatmapping NONNULL 流将返回没有此特征的流。
SIZED和SUBSIZED流
SIZED流
当您想要使用并行流时,最后一个特征非常重要。本教程稍后将更详细地介绍并行流。
SIZED 流是知道它将处理多少个元素的流。从 Collection 的任何实例创建的流都是这样的流,因为 Collection 接口具有 size() 方法,因此获取此数字很容易。
另一方面,在某些情况下,您知道流的元素是有限数的,但除非您处理流本身,否则您无法知道此数量。
对于使用 Files.lines(path) 模式创建的流,情况就是如此。您可以获取文本文件的大小(以字节为单位),但此信息不会告诉您此文本文件有多少行。您需要分析文件以获取此信息。
Pattern.splitAsStream(line) 模式也是。知道您正在分析的字符串中的字符数并不能给出任何关于此模式将产生多少元素的提示。
SUBSIZED流
SUBSIZED 特征,与并行流的拆分方式有关。简单说,并行化机制将流分成两部分,并在 CPU 正在执行的不同可用内核之间分配计算。此拆分由流使用的 Spliterator 实例实现。具体实现取决于您使用的数据源。
假设您需要在 ArrayList 上打开一个流。此列表的所有数据都保存在 ArrayList 实例的内部数组中。也许您还记得 ArrayList 对象上的内部数组是一个紧凑数组,每当数组中删除元素时,所有后续元素都会向左移动一个单元格,不会留下任何空位。
这使得拆分 ArrayList 变得简单明了。要拆分 ArrayList 的实例,您可以将此内部数组拆分为两部分,两部分中的元素数量相同。这使得在 ArrayList 实例上创建的流具有 SUBSIZED特性:您甚至可以设定拆分后每个部分中将保留多少个元素。
假设现在您需要在 HashSet 实例上打开一个流。HashSet 将其元素存储在数组中,但此数组的使用方式与 ArrayList 使用的数组不同。实际上,多个元素可以存储在此数组的一个单元格中。拆分这个数组没有问题,但是如果不计算一下,就无法提前知道每个部分中将保留多少个元素。即使你把这个数组从中间分开,也无法保证两半的元素数量就是相同。这就是为什么在 HashSet 实例上创建的流是 SIZED而不是 SUBSIZED 。
map流可能会更改返回流的 SIZED 和 SUBSIZED 特征。
- mapping和排序流会保留 SIZED 和 SUBSIZED特征。
- flatmapping、filtering和调用
distinct()会擦除这些特征。

