Hawk 3.1 动态页面,ajax,瀑布流
不少朋友反映,Hawk的手气不错,好像没法处理动态页面。其实很容易,比其他软件都容易,让我慢慢道来。
1. 什么是动态页面
很多网站,在刷新的时候会返回页面的全部内容,但实际上只需要更新一部分,这样可大大节约带宽。这种方式一般叫ajax,服务器传递xml或者json到浏览器,浏览器的js代码执行,并将这些数据渲染到页面上。
所以,真正获取数据的url,不一定是你在浏览器上看到的,而且里面会涉及到一些js调用,本质上,js启动了一些新的web请求来获取数据,只要你能模拟这些web请求(我们称之为隐藏请求),就能同样获取json格式的数据。
2.通过嗅探来获取隐藏请求
通过浏览器和抓包工具,可以获取这些隐藏请求,但这需要对web请求的原理比较熟悉,不适合于初学者,但是!Hawk可以采用自动嗅探的方式来进行。
Json处理
Json是最为常见的数据传输格式,也是一棵树。里面包含键值对(字典)和数组,详细信息可以参考文档。
步骤1: 将Json合法化
有时候,网站传过来的json并不是非常合法的json,一些带回调的地址返回的数据,会是如下的形式:
var datas=此处是json;
此时就需要通过字符首尾抽取,或正则表达式和字符串分割等方法,把真正合法的json提取出来。
步骤2: 将字符串转换为文档
上一步获取的结果,依然是个字符串,你需要将其转换为json。 拖入json转换器即可。常见的json有三种模式,我们依次讲解。
- 类型1:
数据可能位于'data'字段。此处,json转换器应当选择“不进行转换”,转换器本身就不进行任何操作,而是将该json作为整体传到新列里。
之后使用python转换器,脚本内容填写value['data']. value就是当前列所对应的内容,后面的部分是获取其data。 如果嵌套的更深,你可能需要 value['data1']['data2']
{
'total':12
'data':
[
{ 'key':'value'}
{ 'key':'value'}
]
}
- 类型2:
这种类型比较少见,是一种纯键值对的字典,我们通常想做的操作,是把内部的键值对都列出来,比如新添key1,key2两个列,内容是value。
方法很简单,json转换器选择"单文档"模式即可。不需要python转换器。
{
'key1':'value'
'key2':'value'
}
类型3:
[
{ 'key':'value'}
{ 'key':'value'}
]
json选择器选择“文档列表”模式即可,不需要python转换器。
所以,看出来了么?json和python转换器的三种工作模式都是一个意思,当你要处理一个数组,就选择文档列表,一个字典,就选择单文档,如果还要取内部更深的信息,就选择不进行转换。
json在Hawk的表示问题
由于Hawk的可视化列表中,只能显示字符串和数字,而Json是一棵树,在Hawk中就很难显示.后期会考虑对这块做优化。
如果显示System.Object[], 这表示是一个数组。
如果显示System.Generic.Dictionary... 表示为字典。 也就是文档。
这一块设计得确实非常糟糕,对于一般人来说理解起来太匪夷所思,也是我做得不够好的地方。。。希望能帮到大家。
用python转换器处理Json
案例. 专利网站的ajax实例
步骤1:嗅探
我们以某政府网站的专利检索为例来说明如何使用:
http://www.pss-system.gov.cn/sipopublicsearch/patentsearch/showNavigationClassifyNum-showBasicClassifyNumPageByIPC.shtml?params=D7B3D1618C9AC685055FF6612F62529676324C8B6E7F92197ECA1C4E4212C394
示例图如下:
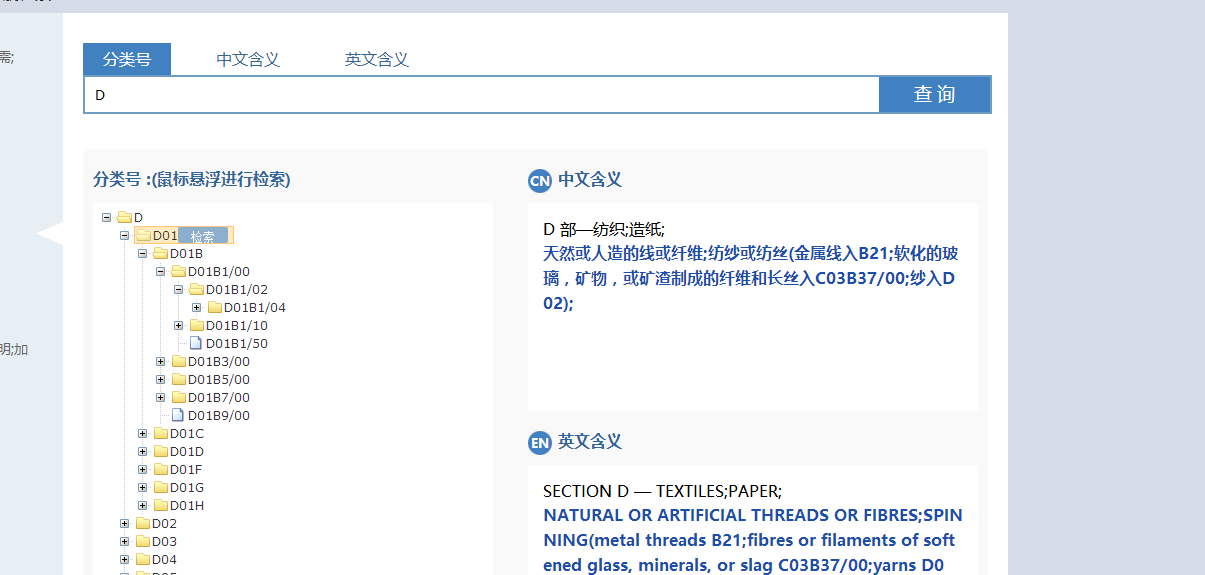
不论你点什么样的下拉菜单,url是不变的。我们可以断定这是一个ajax页面。
现在的目标是,通过一个分类号,如D01B1/00,来获取它的中文含义和英文含义,也就是右边的内容:
我们启动Hawk,新建一个网页采集器,把刚才的那串url拷贝到网页采集器的地址栏里,发现获取的数据根本不包含这些中文含义。
怎么办呢?
你可以用嗅探,我们将天然或人造的线或纤维作为关键字,填写到网页采集器的内容筛选里:
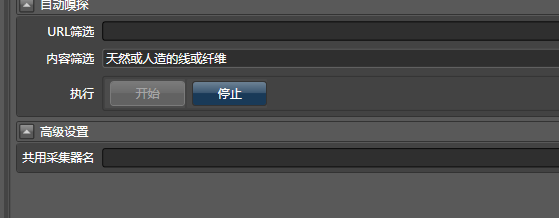
之后点击开始。然后在你的浏览器上点击下拉菜单,展开分类号。发现Hawk已经成功嗅探到了字段:

此时,打开请求属性,就能看到真正请求的相关信息:
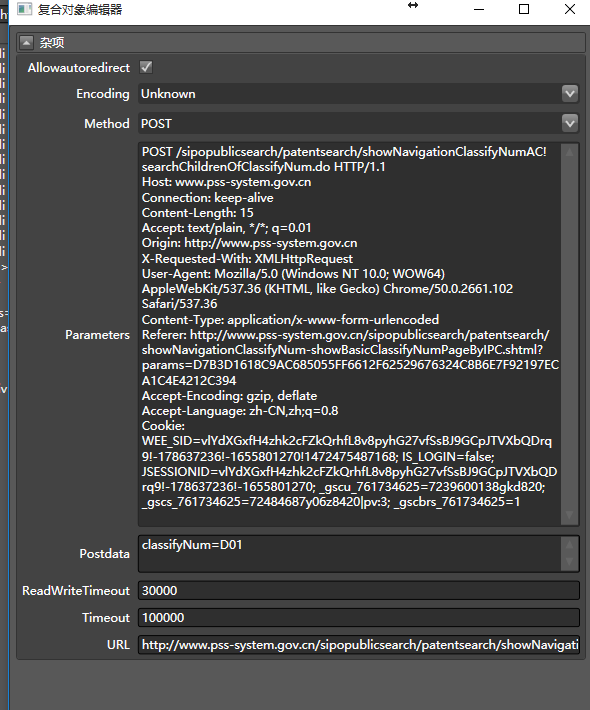
这是一次Post请求, (真实地址)url
http://www.pss-system.gov.cn/sipopublicsearch/patentsearch/showNavigationClassifyNumAC!searchChildrenOfClassifyNum.do
post的内容是classifyNum=D01
有了这些,我们把这个采集器命名为专利查询,下一步就好办了。
步骤2: 数据清洗流
此处我简单描述一下,你可以新建一个数据清洗,生成所有要查询的专利号的ID。这个相对容易。比如拖入从文本生成:
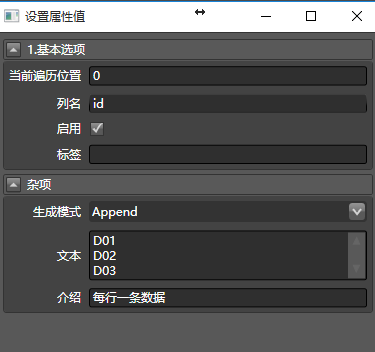
再拖入合并多列,把这一串ID转换为要post的一列数据:
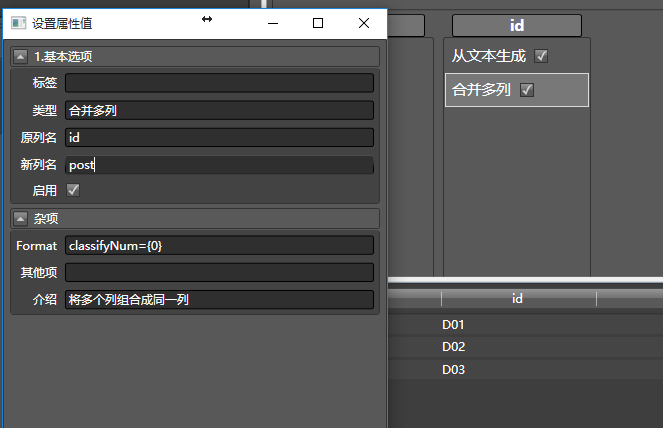
再拖入添加新列,因为要让网页采集器访问那个真实数据的url,所以把上面提到的真实地址填进去:
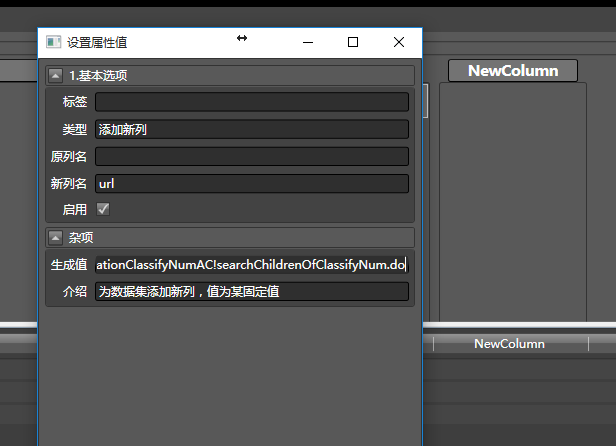
见证奇迹的时刻到了,拖入从爬虫转换到刚才的url列,之后如下配置:
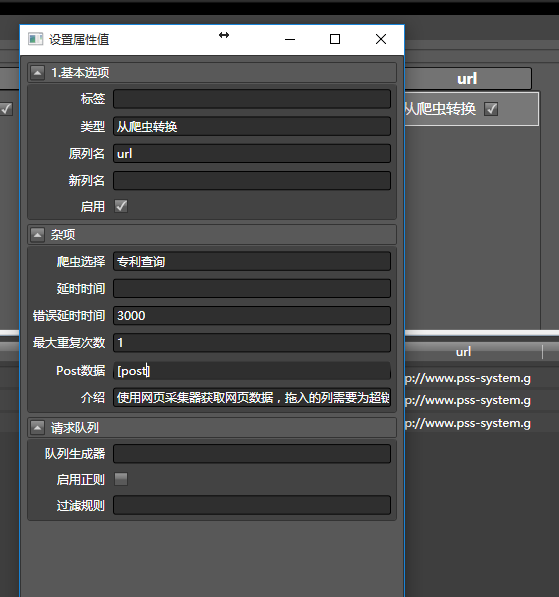
由于post数据要从post列读入,所以用方括号括起来,像这样[post].
出现了这样的结果:
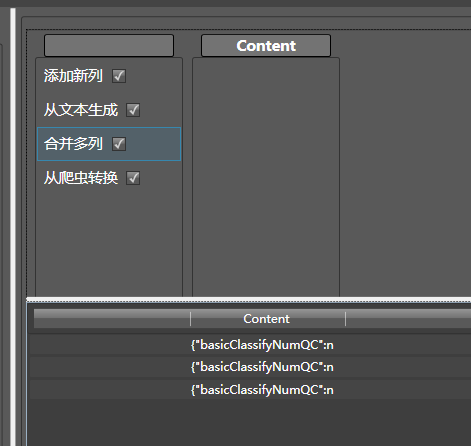
这是个Json,因此我们拖入转换为json到content列:并将生成模式改为单文档,因为这只是一个字典,而不是字典数组:
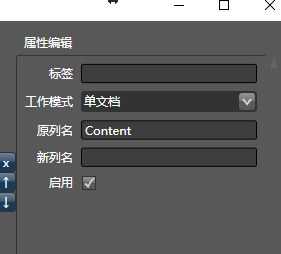
你会发现只有一列有值:
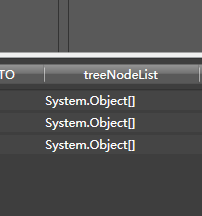
是个数组。那么,再拖入python转换器,生成模式配置为文档列表:
你要的数据就都有了:
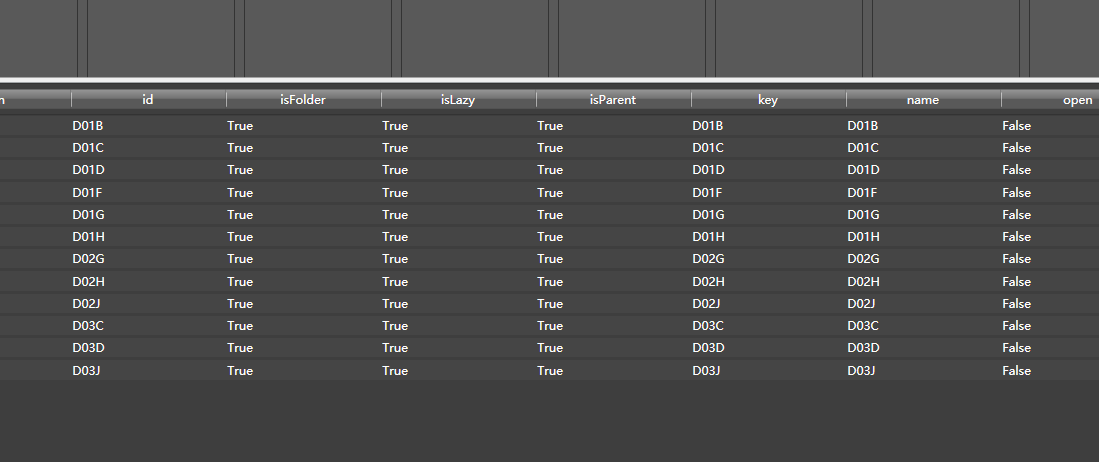
点评:这种请求,虽然可以用Hawk来配置,不过还是建议使用python,能获取更大的灵活性
案例2:未完待续
作者:热情的沙漠
出处:http://www.cnblogs.com/buptzym/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号