redis自学(42)JVM进程缓存
前置数据库的表规划:数据库的表尽量做分离,是因为一个商品的数据事实上是非常多的,需要对商品的数据进行解耦,字段太多查询的效率会比较低;另一方面,系统需要给数据加缓存,如果都在一张表里,那么作为缓存的话,就只有一整条数据作为缓存,一旦一条数据里的任意一个字段做了修改,整个商品的缓存就全都失效了,这样缓存失效的频率太高了,导致缓存经常性的未命中,所以要数据分离,把经常修改的和不经常修改的分开,做成好几张表,好几个不同的缓存
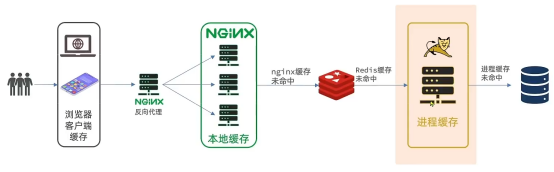
商品的查询页面需要放在反向代理的Nginx服务器中(充当静态资源服务器),而页面需要的数据通过ajax想服务端(nginx业务集群)查询

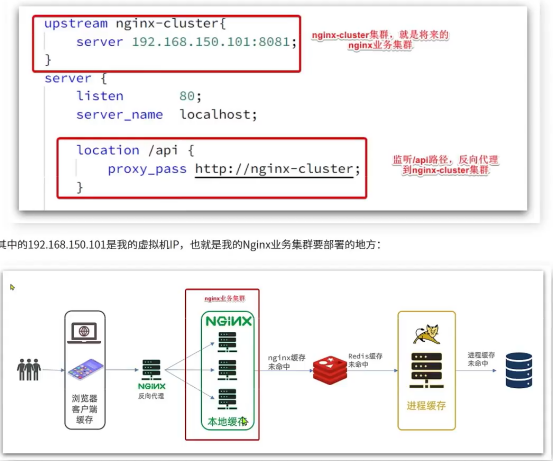
反向代理配置
本地进程缓存
缓存在日常开发中启至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
分布式缓存,例如reids:
优点:存储容量更大、可靠性更好、可以在集群间共享
缺点:访问缓存有网络开销
场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
进程本地缓存,例如HashMap、GuavaCache:
优点:读取本地内存,没有网络开销,速度更快
缺点:存储容量有限、可靠性较低、无法共享
场景:性能要求较高,缓存数据量较小
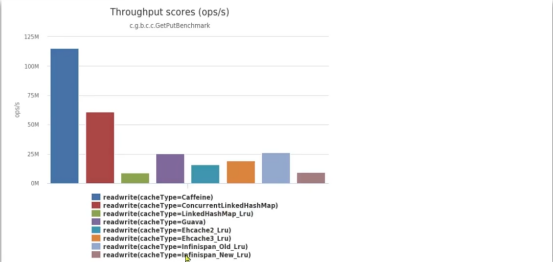
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能 的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。
下图是工作效率

驱逐策略

在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作,或者在空闲时间完成对失效数据的驱逐。
测试:

定义两个缓存

注入两个cache对象
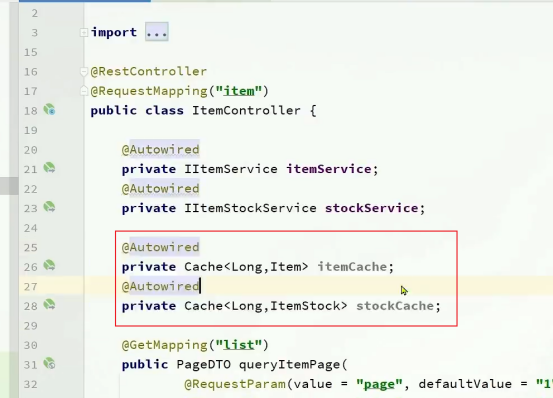
方法进行修改
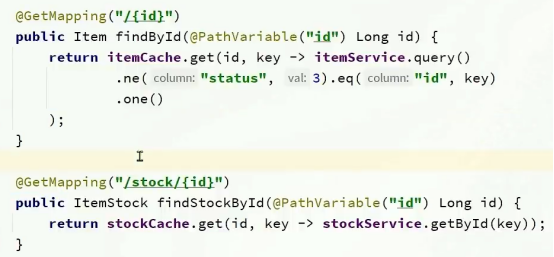
之后的操作,第一次肯定是要查询数据库的,同时寸入了缓存,第二次就发现没有走数据库了,而是走缓存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号