redis自学(32)增量同步
如果slave重启后同步,则执行增量同步

什么情况下无法做增量同步
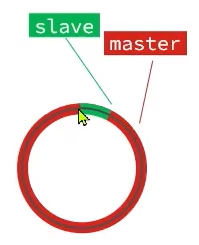
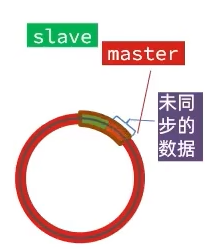
repl_baklog是个数组,它会循环覆盖之前的数据。如果master记录的数量超出这个环,覆盖了slave的offset,找不到了,就只能去做全量同步了

可以从以下几个方面来优化redis主从集群:
l 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。也就是说,RDB文件不落磁盘了,直接网络发走了,就不存在IO读写了。
l Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO。说白了,传的RDB文件小了,不耽误事。
l 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步。
l 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力


 浙公网安备 33010602011771号
浙公网安备 33010602011771号