redis自学(12)Hash
Hash
Hash结构与Redis中的Zset非常类似:
l 都是键值存储
l 都需要根据键获取值
l 键必须唯一
区别如下:
l zset的键是member,值是score;hash的键和值都是任意值
l zset要根据score排序,hash则无需排序
因此,Hash底层采用的编码与Zset也基本一致,只需要把排序有关的SkipList去掉即可:
u Hash结构默认采用ZipList编码,用以节省内存。ZipList中相邻的两个entry分别保存field和value
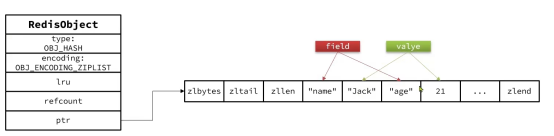
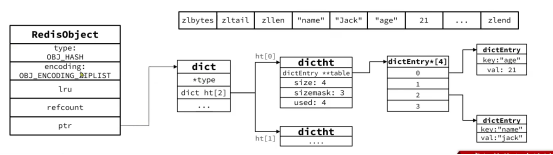
u 当数据量较大时,Hash结构会转为HT编码,也就是Dict,触发条件有两个:
① ZipList中的元素数量超过了hash-max-ziplist-entries(默认512)
② ZipList中的任意entry大小超过了hash-max-ziplist-value(默认64字节)
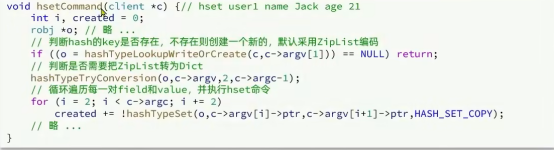
加值
判断是否存在,不存在新建,新建默认是ZipList编码
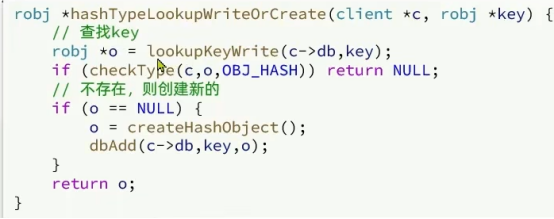
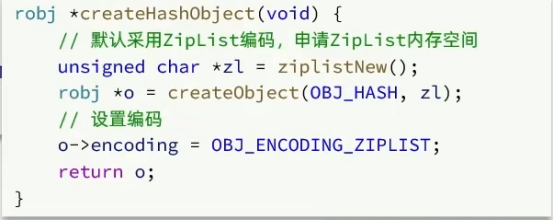
根据元素大小判断是否需要转换为Dict,不判断数量是因为键的唯一性,不确定数量是否会超过限定值
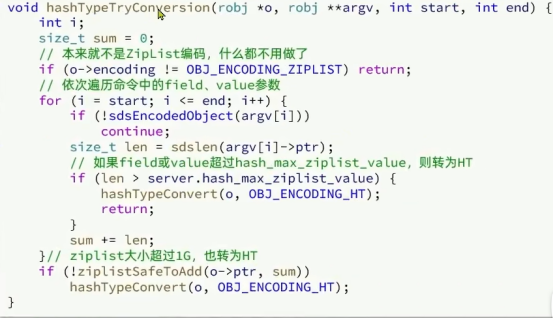
添加的同时判断数量是否超过限定值转换为Dict


 浙公网安备 33010602011771号
浙公网安备 33010602011771号