

redis自学(4)ZipList
ZipList是一种特殊的“双端链表”,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作,并且该操作的时间复杂度为O(1)。
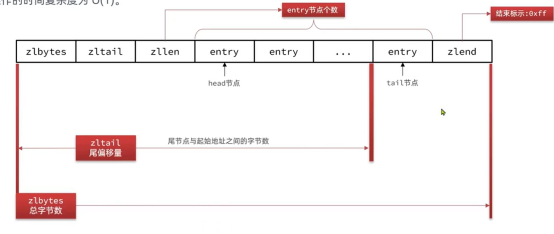
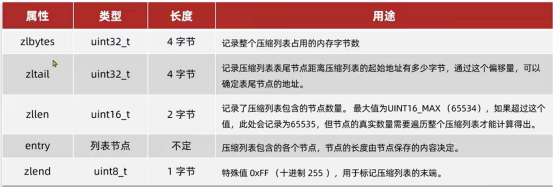
ZipListEntry
ZipList中的Entry并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。而是采用了下面的结构:

Previous_entry_length:前一节点的长度,占1个或5个字节。
如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0Xfe,后四个字节才是真实长度数据
encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节
contents:负责保存节点的数据,可以是字符串或整数
ZipList中寻址方式:
正序寻址:当前元素加上自己的Previous_entry_length+encoding+contents的字节长度,就是下一个元素的地址。
倒序寻址,当前元素减去Previous_entry_length离的前一节点长度,就是上一个元素。
ZipList中所有存储长度的数值均采用小端字节序,即低位字节在前,高位字节在后。例如:数值0x1234,采用小端字节序后实际存储值为:0x3412。
Encoding编码
ZipListEntry中的encoding编码分为字符串和整数两种:
字符串:如果encoding是以“00”、“01”或者“10”开头,则证明content是字符串,不同的开头代表不同的字节长度


整数:如果encoding是以“11”开始,则证明content是整数,且encoding固定只占用1个字节。
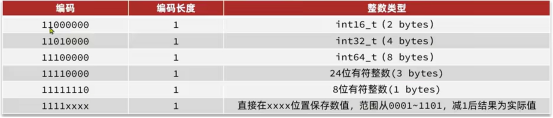
不同的编码对应不同的整数类型,但是特别小的数据,则是使用1111xxxx来存储。表达范围从0001~1101,1~13,减一之后是0~12,使用这个的好处是省去了content,从而省去了一个字节。
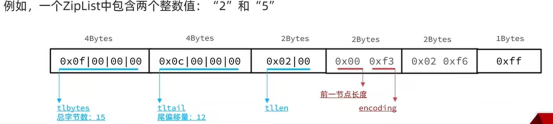
ZipLise的目的是尽可能的节省内存,但是使用限制是只能前序或者后序遍历,所以数据特别多的时候,查询效率较低,所以使用的时候要对节点的个数进行限制。
ZipList的连锁更新问题
假设有N个连续的长度为250~253字节之间的entry,因此entry的Previous_entry_length属性用一个字节表示就行,但是如果往队首放一个大于253字节的entry,那么原先的元素就会变成第二个,而它的Previous_entry_length占中的字节也要改变,因为前一个大于253,所以它的Previous_entry_length占中字节是5,以此类推,下一个元素还要改,下下一个元素也是要改。
ZipList这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发生。这种修改,每次都会往后迁移数据,而如果内存不足,就要申请新的内存,销毁,还有数据迁移的动作,但是下一个还是会发生,最影响性能。(因为要求有连续的长度为250~253字节之间的entry,所以概率很低,还有就是ZipList用的很多,修改影响较大,所以作者并未解决此问题)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!