redis自学(3)Dict
redis的键和值的映射关系是通过Dict来实现的。
Dict由三部分组成,分别是哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)。
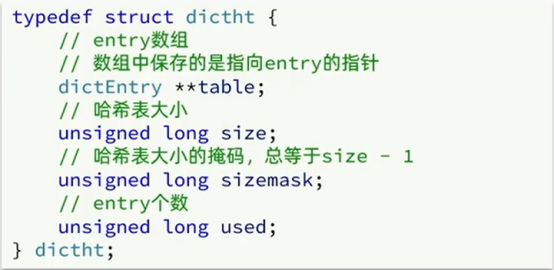
size的大小总是2的N次方
sizemask的大小是size-1
used因为哈希的存储特性(不同元素相同的哈希值,即哈希冲突),所以是有可能大于size的
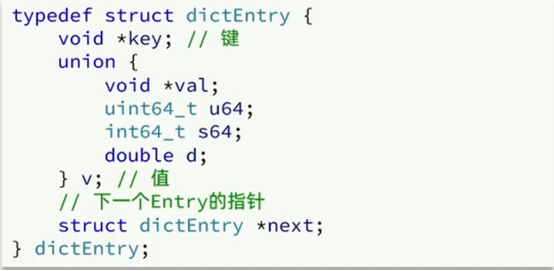
*key是指针,也就是键
v是C语言的一个联合体,可以是四个类型的任何一个,但不会同时是任何两个或者三个四个。只能是一个。
*next 指向哈希冲突单向链表里面的下一个entry。
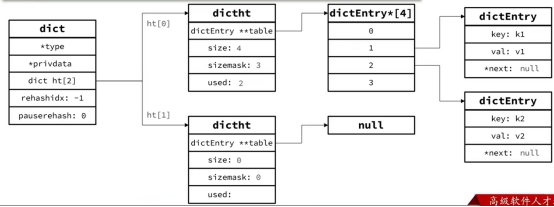
当向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用h&sizemask来计算元素应该存储到数组中的哪个索引位置。
哈希冲突的存储过程,先存储k1=v1的元素,假设k1的哈希值h =1,则1&3 =1,因此k1=v1要存储到数组角标1的位置,后来又存储k2=v2的元素,假设k2的哈希值h 也是=1,则1&3 =1,因此k2=v2要存储到数组角标1的位置,而k2的dictEntry的*next则存储k1的指针(新元素使用的可能性更大,所以放到队首更方便)

Dict结构

Dict整体图
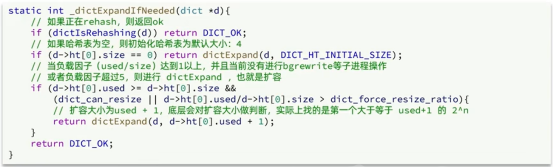
Dict的扩容
同java一样,hash冲突过多,会导致链表过长,降低查询效率,所以也会有哈希扩容。
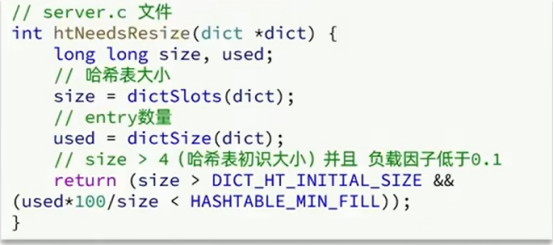
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size),满足以下两种情况时会触发哈希表扩容:
- l 哈希表的LoadFactor >=1 ,并且服务器没有执行BGSAVE或者BGREWRITEAOF等后台进程(后台进程对CPU的使用是非常的高的,而且还会有大量的IO读写,可能会影响性能甚至导致命令阻塞,进而主系统一起阻塞);
- l 哈希表的LoadFactor >5;(太大了,不管那么多了。不得不做哈希扩容了)
另:
java的哈希表初始容量为16,负载因子为0.75,也就是说,当元素达到12时就会触发扩容,扩容到32个。需要注意的是,当我们使用哈希表时,可以通过构造函数或方法等方式来自定义初始容量和负载因子等参数。可以根据具体场景和需求来调整参数,以达到更好的性能和效率。
在Java的哈希表中,当发生哈希冲突时,即多个元素被映射到同一个桶时,这些元素将会以链表的形式存储在同一个桶中。当链表的长度达到一定阈值(默认为8),链表会转化为红黑树,以提高查找、插入和删除等操作的效率。
链表的变化主要包括两个方面:
- 链表转红黑树:当链表长度超过阈值时,桶中的链表会被转化为红黑树。这个转化过程会提高查找元素的效率,从链表的O(n)的线性查找时间复杂度变为红黑树的O(log n)的对数查找时间复杂度。
- 红黑树转链表:当红黑树中的元素较少,只有一部分时(默认为6),红黑树会被转化为链表。这个转化过程是为了节省内存空间,因为红黑树需要额外的空间来存储节点的颜色和引用等信息,相比之下链表更节省空间。
需要注意的是,链表和红黑树的转化过程是相对耗时的,因为涉及到节点的复制和重新连接等操作。当发生链表转红黑树或红黑树转链表的操作时,可能会带来一定的性能开销。因此,在使用哈希表时,合理选择初始容量、负载因子和其他参数等,可以尽量减少链表和红黑树的转化,提高哈希表的性能和效率。
哈希扩容后是怎么保证分散元素的?
哈希扩容过程中,会重新计算已有 key 的哈希值,并将其插入到新的更大的哈希表中。因为哈希函数计算出来的哈希值依赖于哈希表大小、键的值以及哈希算法等因素,所以在扩容前后,key 的哈希值会发生改变。
在哈希表扩容前,元素的哈希值是通过以下方式计算的:
h = key.hashCode();
其中,key是要添加到哈希表中的元素。
在哈希表扩容后,元素的哈希值计算方式为:
h = key.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
h ^= (h >>> 7) ^ (h >>> 4);
其中,第二行和第三行是操作哈希值的扰动函数,目的是为了散列更均匀,减少哈希碰撞。这个扰动函数的设计是基于经验和测试得到的。
Dict的收缩
Dict除了扩容以外,每次删除元素时,也会对负载因子做检查,当LoadFactor<0.1时,会做哈希表收缩。

Dict的rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这就是rehash。
Dict的rehash并不是一次性完成的。如果Dict包含数百万的entry,要在一次rehash完成,极有可能导致线程阻塞。因此Dict的rehash是分多次、渐进式的完成,成为渐进式rehash。
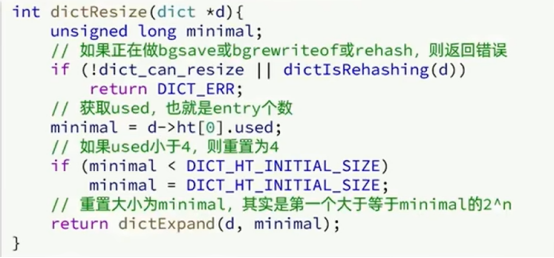
① 计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩
- u 如果是扩容,则新size为第一个大于等于dict.ht[0].used+1的2的n次方
- u 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2的n次方(不得小于4)
② 按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
③ 设置dict.rehashidx = 0,表示开始rehash
④ 每次执行新增、查询、修改、删除操作时,都检查一下dict.rehashidx是否大于-1,如果是则将dict.ht[0].table[rehashidx]的entry链表rehash到dict.ht[1],并且将rehashidx++。直到dict.ht[0]的所有数据都rehash到dict.ht[1]
⑤ 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[1]的内存。
⑥ 将rehashidx赋值为-1,代表rehash结束
⑦ 在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空

 浙公网安备 33010602011771号
浙公网安备 33010602011771号