redis自学(1) 动态字符串SDS
字符串是redis最常见的数据结构,但redis并没有直接使用C语言的字符串,是因为C语言本身其实是没有字符串的,所谓的字符串其实是字符数组(Java语言中的字符串是一个对象),所以C语言的字符串有很多问题:
① 获取字符串长度需要通过运算
C语言的字符串数组都是以’\0’结尾,这是一个字符串的结束标识,表示字符串到此为止。但是要想获取这个字符串的长度,就只能运算减去’\0’以后才能获得字符串的长度。或者就是一个一个遍历,用计数器计数直到’\0’停止。这样时间复杂度会很高,有可能会达到O(N)。
② 非二进制安全
如果因为需求,需要字符串中间包含’\0’,那么C语言的字符串就不能用了,因为C语言的字符串中间不能包含’\0’这样的特殊字符,所以C语言的字符串是非二进制安全的。
③ 不可修改
C语言的字符串是存在常量池里的,要想拼接需要申请新的内存空间,很麻烦。(Java中的字符串是不可变的,也就是说,一旦创建了字符串对象,其内容是不可修改的。如果对一个字符串进行修改,实际上是生成了一个新的字符串对象。当我们对一个字符串进行修改时,Java会先检查这个字符串是否与其他对象共享同一块内存,即是否存在其他的字符串对象与其指向同一块内存地址。如果存在,则不是在原来的字符串对象中直接进行修改,而是创建一个新的字符串对象,将修改后的值存储在新的字符串对象中。如果不存在,那么直接在原字符串对象中进行修改,并返回该对象的引用。这种操作被称为"String共享优化",可以提高字符串性能和节约内存。)
因此redis自己构建了一个新的字符串结构,简单动态字符串SDS(simply dynamic string)

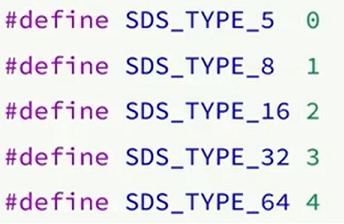
SDS本质是一个结构体,类似于java里面的类
uint8_t 的意思是无符号整型8个比特位 能存2的8次方减1=255个字节
len 保存的是buf数组的字节数,因为buf数组其实还是有’\0’这个特殊字符,所以实际上buf能存的字节到不了255个 而是254个,这是为了兼容C语言字符串,实际读取的时候’\0’用不上。长度已经在len存储了,读取的时候读取len长度的字节就行了,也保证了二进制安全。同样的获取字符串长度,直接取len就行了,不用运算。
alloc是buf申请的总字节数,C语言的内存空间是手动申请的,而buf的内存申请有多大是存在alloc里的。因为数组申请的空间和使用的空间不一定一样,所以才会有len和alloc两个变量。
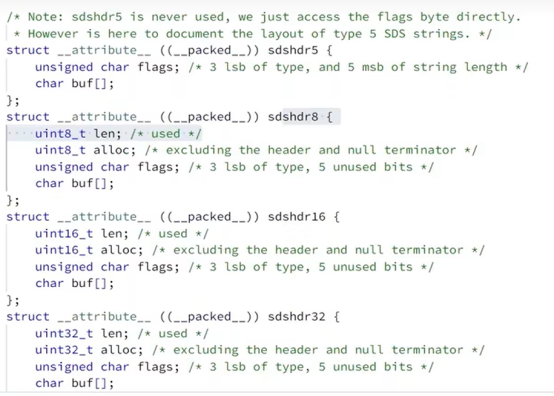
flags表示这个SDS是什么类型的,上面的SDS只是多种SDS的一种。如下
uint8_t和uint64_t的内存空间大小不同,是因为它们定义了不同位数的整型变量。
uint8_t是一种8位无符号整数类型,占用1个字节(8位)的内存空间,可以存储0~255之间的整数。
而uint64_t是一种64位无符号整数类型,占用8个字节(64位)的内存空间,可以存储0~18446744073709551615之间的整数。
flag的类型
SDS结构

SDS具备动态扩容能力
内存预分配规则:
1、如果新字符串小于1M,则新空间为扩展后字符串长度的两倍+1。(这个+1是留给’\0’的)
2、如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1。
为什么要有内存预分配:
Linux分为用户态和内核态,申请内存需要从用户态切换到内核态,但申请内存这个动作非常消耗资源。而内存预分配减少了之后变动申请内存的次数,提高性能。
SDS优势
① 获取字符串长度的时间复杂度O(1)
② 支持动态扩容
③ 减少内存分配次数
④ 二进制安全

 浙公网安备 33010602011771号
浙公网安备 33010602011771号