redis主从
搭建主从架构
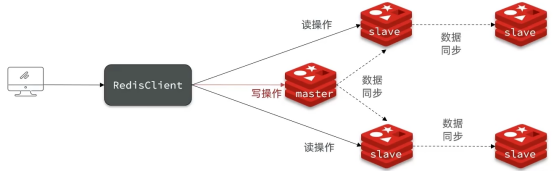
单节点redis的并发能力是有上限的,要进一步提高redis的并发能力,就需要搭建主从集群,实现读写分离。
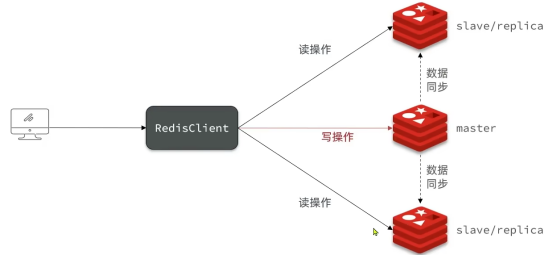
搭建主从的注意事项(仅注意,是否需要修改看实际情况)
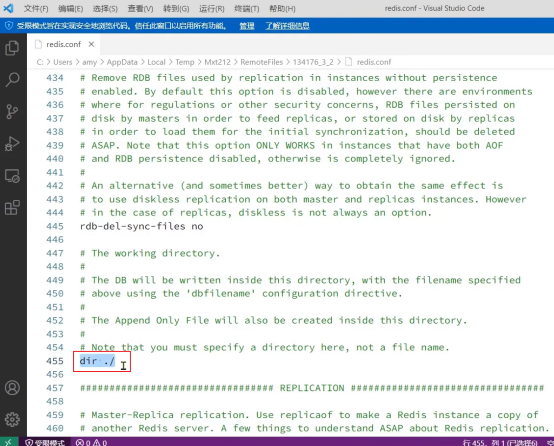
端口修改

目录修改
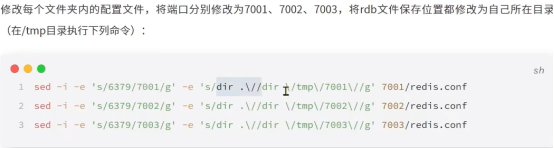
也可以通过命令的方式修改文档
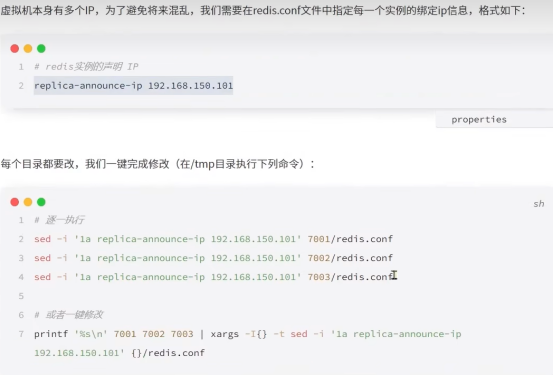
声明绑定实例ip
开启主从关系(不同服务器的情况下,可以直接执行这一步就行)
可以使用replicalof或者slaveof(5.0以前)的命令。
有临时和永久两种模式:
修改配置文件(永久生效)
在redis.conf中添加一行配置:slaveof<masterip><masterport> 成为指定节点的slave
使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof <masterip><masterport>
注意:在5.0以后新增命令replicaof,与slaveof效果一致。
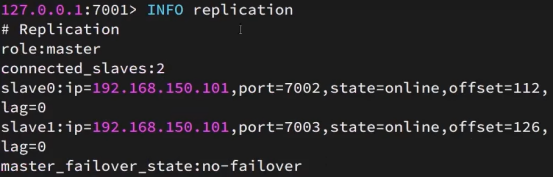
INFO replication 命令查看集群状态信息
全量同步
数据同步原理
主从的第一次同步是全量同步:
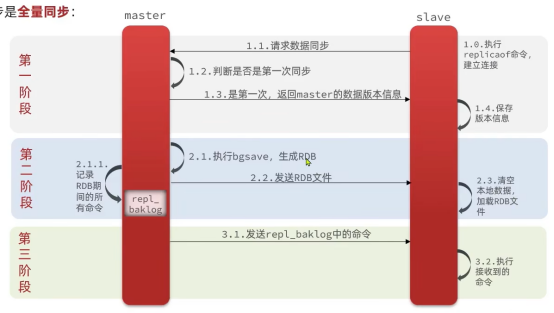
Master如何判断slave是不是第一次来同步数据?这里会用到两个很重要的概念:
- Replication id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。Slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的Replication id和Offset,master才可以判断到底需要同步哪些数据。
是不是第一次,是根据replid是否一致判断的。


增量同步
如果slave重启后同步,则执行增量同步

什么情况下无法做增量同步
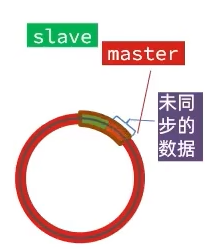
repl_baklog是个数组,它会循环覆盖之前的数据。如果master记录的数量超出这个环,覆盖了slave的offset,找不到了,就只能去做全量同步了

可以从以下几个方面来优化redis主从集群:
l 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。也就是说,RDB文件不落磁盘了,直接网络发走了,就不存在IO读写了。
l Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO。说白了,传的RDB文件小了,不耽误事。
l 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步。
l 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力


 浙公网安备 33010602011771号
浙公网安备 33010602011771号