redis内存回收
Redis内存回收
Redsi之所以性能强,最主要的原因就是基于内存存储。然而单节点的redis其内存大小不宜过大,会影响持久化或者主从同步性。
我们可以通过修改配置文件来设置redis的最大内存:

当内存使用达到上限时,就无法存储更多数据了
过期策略
在学习redis缓存的时候我们说过,可以通过expire命令给redis的key设置TTL(存活时间):
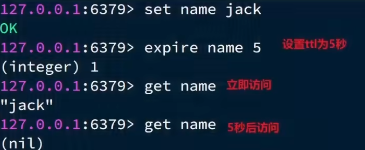
可以发现,当key的TTL到期以后,再次访问name返回的nil,说明这个key已经不存在了,对应的内存也得到释放。从而起到内存回收的目的。
这里有两个问题需要我们思考:
① Redis是如何知道一个key是否过期呢?
ü 利用两个Dict分别记录key-value对以及key-ttl对
② 是不是TTL到期就立即删除了呢?
ü 惰性删除
ü 周期删除
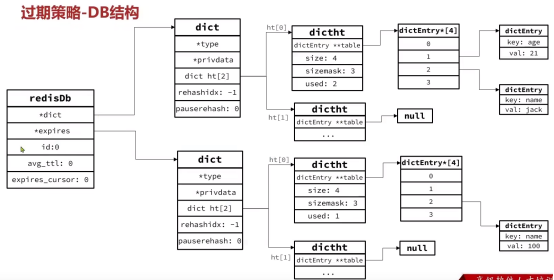
过期策略-DB结构
Redis本身是一个典型的key-value内存存储数据库,因此所有的key、value都保存在之前学习过的Dict结构中。不过在其database结构体中,有两个Dict:一个用来记录key-value;另一个用来记录key-TTL。

过期策略-惰性删除
惰性删除:顾名思义并不是在TTL到期后就立刻删除,而是在访问一个key的时候,检查该key的存活时间,如果已经过期才执行删除。


问题在于,如果一直不访问这个key,那么就永远不可能会删除。
过期策略-周期删除
周期删除:顾名思义是通过一个定时任务,周期性的抽样部分过期的key,然后执行删除。执行周期有两种:
Redis会设置一个定时任务serverCorn(),按照server.hz的频率来执行过期key清理,模式为SLOW
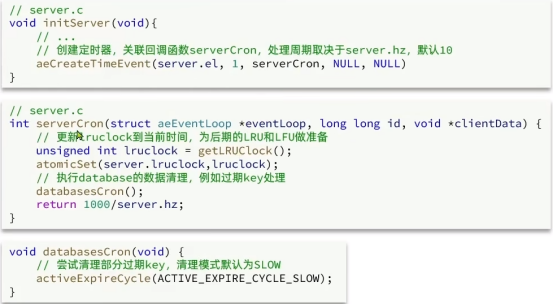
Redis的每个事件循环前会调用beforeSleep()函数,执行过期key清理,模式为FAST


Fast是高频少量的清理,最多不超过1毫秒
SLOW模式是低频长时间的清理,清理效果会更好一些,但是会阻塞几十毫秒影响效率
SLOW模式规则:
① 执行频率受server.hz影响,默认为10,即每秒执行10次,每个执行周期100ms
② 执行清理耗时不超过一次执行周期的25%,剩下的时间什么也不做,确保执行频率固定,不会对主线程造成太多影响
③ 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
④ 如果没达到时间上线(25ms)并且过期key比例大于10%,再进行一次抽样,否则结束
FAST模式规则(过期key比例小于10%不执行):
① 执行频率受beforeSleep()调用频率影响,但两次FAST模式间隔不低于2ms
② 执行清理耗时不超过1ms
③ 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
④ 如果没达到时间上线(1ms)并且过期key比例大于10%,再进行一次抽样,否则结束
内存淘汰策略
内存淘汰:就是当Redis内存使用达到设置的阈值时,redis主动挑选部分key删除以释放更多内存的流程。
Redis会在处理客户端命令的方法processCommand()中尝试做内存淘汰:

也就是说,redis是在任何命令执行之前,做内存的检查或者说尝试去淘汰一部分内存。
Redis支持8种不同策略来选择要删除的key:
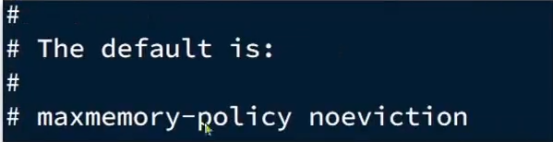
noeviction:不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
volatile-ttl:对设置了TTL的key,比较key剩余的TTL值,TTL越小越先被淘汰
allkeys-random:对全体key,随机进行淘汰。也就是直接从db->dict中随机挑选
volatile-random:对设置TTL的key,随机进行淘汰。也就是从db->expires中随机挑选
Allkeys-lru:对全体key,基于LRU算法进行淘汰。
Volatile-lru:对设置TTL的key,基于LRU算法进行淘汰。
Allkeys-lfu:对全体key,基于LFU算法进行淘汰。
Volatile-lfu:对设置TTL的key,基于LFU算法进行淘汰。
比较容易混淆的有两个:
LRU(Least Recently Used),最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
LFU(Least Frequently Used),最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。

根据策略不同,记录的信息也不一样
LFU的访问次数之所以叫做逻辑访问次数,是因为并不是每次key被访问都计数,而是通过运算:
① 生成0~1之间的随机数R
② 计算1/(旧次数*lfu_log_factor+1),记录为P,lfu_log_factor默认为10
③ 如果R<P,则计数器+1,且最大不超过255
④ 访问次数会随时间衰减,距离上一次访问时间每隔lfu_decay_time分钟(默认1),计数器-1
8个比特位只能记录255个数,也就不可能记录真实的访问次数,所以采用了逻辑访问次数,用一个概率行的增加,上面的意思是,访问了,除了第一次,访问次数有可能不增加,但是只要访问次数多,逻辑计数的值大于其他访问次数少的可能性还是很高的。但是长时间不访问的话,它的次数也是一点点的随时间减少的。
lfu_log_factor和lfu_decay_time都可通过配置文件或者命令行配置。
策略在配置文件设定
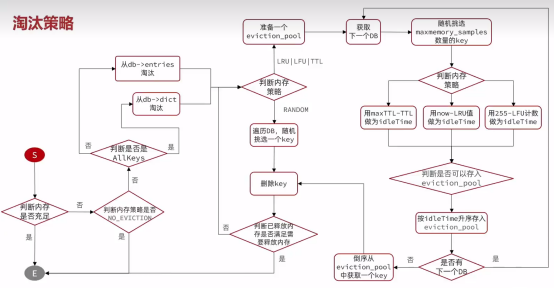
LRU和LFU以及TTL,不是一个一个去比较的,这样如果redis的缓存数量很大的话,挨个遍历消耗的时间和资源是很恐怖的,所以,搞了一个eviction_pool,随机找一堆,比较谁最应该被淘汰,虽然准确率不如挨个遍历,但是也够满足使用了,最主要是性能好。
随机数maxmemory_samples的默认值是5个,随机到后经过筛选才有可能按照idleTime升序放入eviction_pool,因为eviction_pool满了的情况下,如果idleTime比池子里的最小的idleTime还要小的话,就没有必要放入了,大的话,放入就把原先池子里最小的挤出去了。而idleTime根据策略不同计算方式不同(now是指现在时间,maxTTL是指long的最大值即9223372036854775807)。删除的时候倒序从eviction_pool中获取一个key删除。随着循环的次数越来越多,eviction_pool里面的idleTime会越来越大,那么准确率就会越来越高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号