
pyspider的主要架构如下图
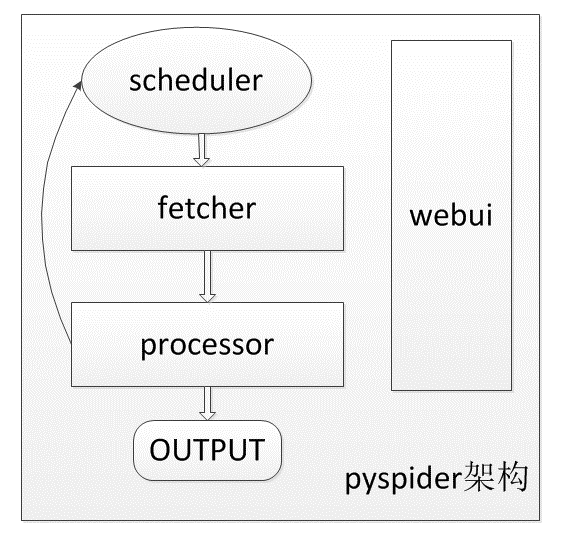
1. webui
在线编写、调试爬虫脚本;
在线监控任务执行情况;
2. scheduler
调度任务,粗浅的理解就是定时执行爬虫脚本;
这是一个核心部件;不止是定时爬取那么简单。
爬取的时候要递归爬取网页,
爬取网页的时候要设置优先级,优先爬取列表页。
爬虫任务爬取时要判断当前网页是否过期;
如果当前网页过期,要支持"HTTP 304"的请求方式,减轻对方压力。
("HTTP 304"是个人的说法,也就是请求时带上If-Modified-Since、If-None-Match字段,如果文件未变更对方返回304)
来看具体的代码
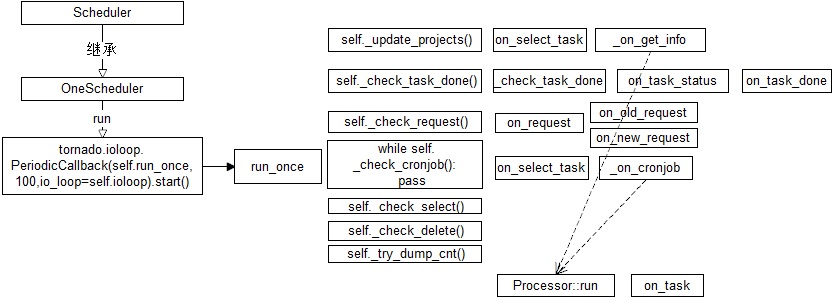
也就是说:pyspider通过tornado来做的事件驱动。
任务前: 要读取任务数据,
任务后: 要将新数据入库。
任务中: 产生的新任务要放到任务队列中去。
事件驱动库:简单理解就是通过io复用的方式,关联一个回调函数,再加一些定时事件封装的库。
事件驱动的好处就是不用来个任务就给分配一个线程,避免了频繁的CPU上线文切换,提高了性能,支持更大的并发。
3. fetcher
抓取网页
并不只是下载网页那么简单,更类似于一个浏览器;
支持修改和控制method, header, cookie, proxy, etag, last_modified, timeout等字段;
支持dataURL
可以通过适配类似phantomjs的webkit引擎支持渲染
目标一般不希望爬虫总是去访问它。不伪装一下自己,别人不一定让你爬的。
4. processor
对返回的网页进行解析。
执行你写的脚本对网页内容进行解析,解析出来的链接还可以重新放到scheduler中轮回。
总结
对scheduler、fetcher的干预,通常通过配置和注解实现;
你写的代码部分是通过processor执行的。
从另一个角度讲scheduler和fetcher也都算是任务。processor执行的不单是你写的代码。
对于普通的使用方法,官网写得很全,可以参考官网:http://docs.pyspider.org/en/latest/apis/self.crawl/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号