
服务商系统集中高频交易CPU飙升问题解决优化过程
通过创建数据表索引,有效提升系统性能。
一、问题背景
在11月10日下午5点,出现channel异步下发消息队列消息积压报警,经排查分析是因为channel请求鑫某亿服务商落单时间过长,导致了channel消费消息队列的消息变慢的情况。所以,专项对鑫某亿系统相关业务进行优化。
一(1)、现场
如下是grafana监控平台上,鑫某亿服务商当时的服务器CPU使用率,如下所示:
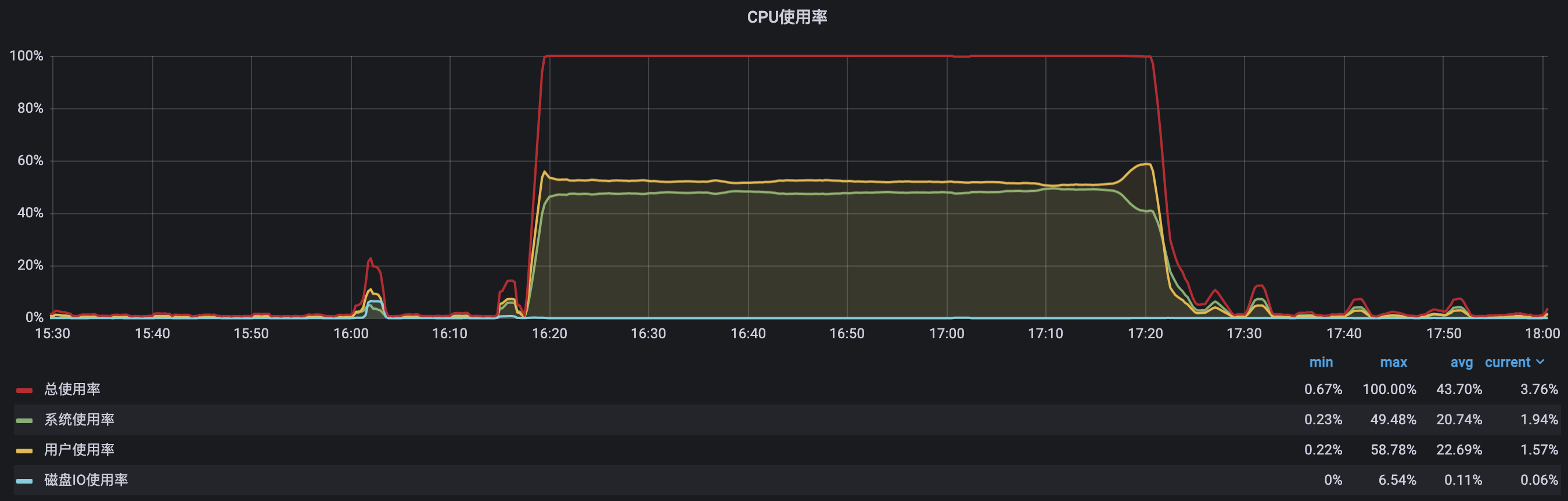
图中可见,当时鑫某亿的CPU很长一段时间都是满负荷的状态,以至于服务器出现了卡顿的现象,间接的导致了落单慢的问题。
一(2)、分析
鑫某亿服务商系统和数据库部署在同一台服务器上,服务器配置:阿里云虚拟服务器8核16G。CPU持续飙高一般都是由于CPU进行着满负荷的计算:
1)程序出现了死循环,导致CPU一直在计算。目前来看只是大量下发的时候出现这个问题,所以可以排除死循环的问题;
2)程序存在大量的计算工作,导致CPU一直在计算。结合业务场景分析,可以排除这个猜想
3)数据库进行了大量的查询计算,导致CPU一直持续飙高。正好符合目前的场景,在大量的下发的时候必然会进行大量的数据库操作;
一(3)、紧急修复
赶紧紧急进行排查分析,当晚发现有两点问题待紧急优化,如下文细述。
二、问题解决(三板斧)
1、第一斧 – 增加联合索引,让频繁的全表查询变为精准定位 (全表扫描 → 索引精准定位)
服务商下发单在记账时,会从商户账户冻结交易金额,为了确保防重,会先校验该笔订单是否已经冻结过,如果已经冻结过,就不能重复冻结,如下图所示:
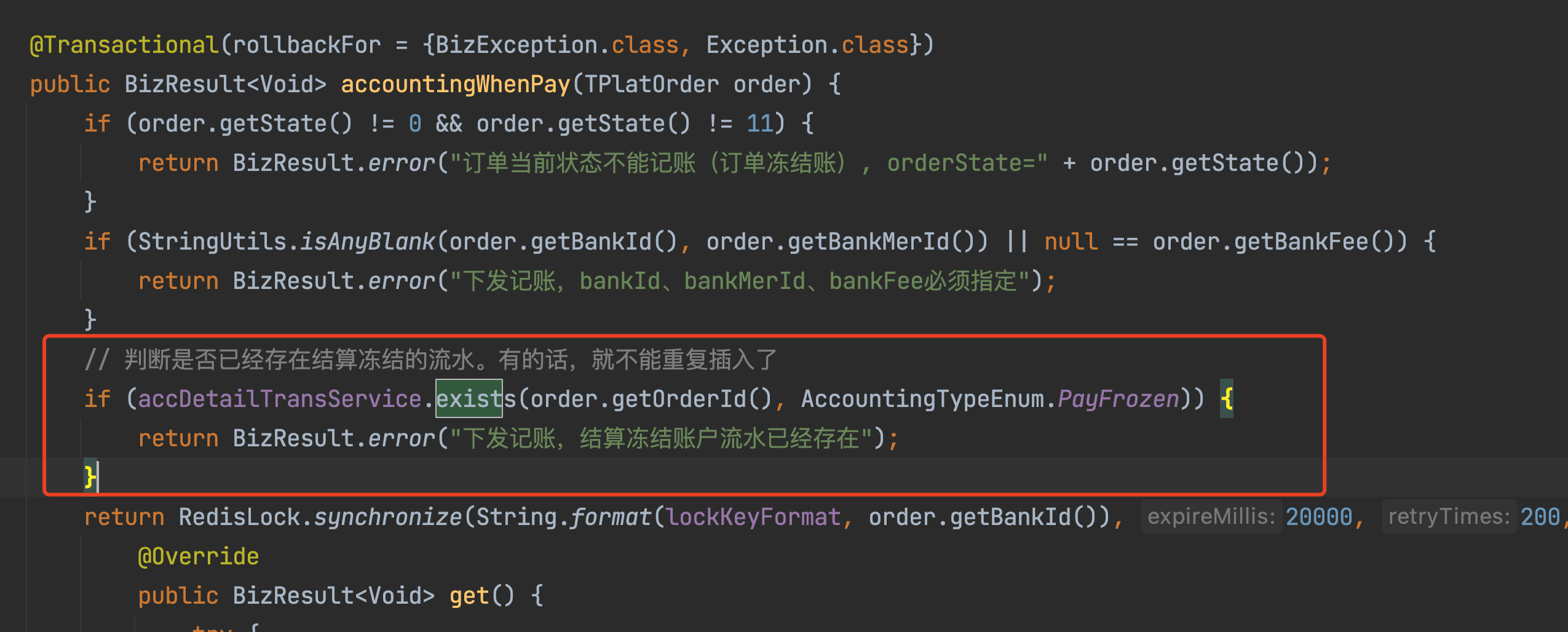
这个防重冻结的SQL是:

可见,使用到了order_id和type这2个字段作为where条件去查询记账流水表t_acc_detail_trans。如果有一个索引,包含了order_id和type,是不是就可以很快得到查询结果。依据这个就建立了一个联合索引,uni_order_id_type。这样的话,能快速的知道符合这个条件的账务流水存不存在,加上这个索引之后避免了全表扫描,而且P99的情况下都不会回表确认,因为索引明确的就告诉了是否存在。
2、第二斧 – 转换查询方式,通过等价变换利用索引 (全表扫描 → 索引范围扫描)
在下发的时候需要判断自由职业者有没有与服务商签约,所以要查服务商的签约表T_SOHO,表中存在一个唯一索引( unique index UNI_T_SOHO (ID_CARD, NAME, CARD_NO, MER_ID)),在下发时需要对存在签约信息做一个判断,如下图所示SQL,但是这个SQL并没有命中这个索引:

先解释一下这里用到的upper函数,是因为有一部分人的身份证是带有字母“X” 的,但是在录入的时候没有判断是录入的是“x" 还是“X”,所以这里利用upper来做兼容。由于在字段上使用了函数,导致无法走这个字段索引,最后只能全表扫描去判断有没有符合条件的签约记录。针对这种情况,做了如下更改:

通过等价转换,将字段上面的函数去掉,使之可以走索引,美中不足就是需要走两次索引,不过相对于全表扫描在性能上已经是天壤之别了。
TODO:经对近期下发交易进一步分析,发现存在同人同日有多次下发的情况,考虑到T_SOHO表的签约数据在发生后几乎不会有变化,所以,后续可进一步优化,使用本地缓存或redis缓存,来有效减少数据库请求次数。
3、第三斧 – 大量频繁执行的SQL进行重点分析 (全表扫描 → 索引范围扫描)
第二天观察优化效果,鑫某亿服务商依然存在CPU持续过高的问题,开始分析最近上的需求,发现有一个需求是增加下发时效,由于时间紧急,第一步是减少channel请求服务商查询下发结果的延迟队列查询时间,可见现在查询的次数会变多,由于CPU过高导致的下发时效变慢,但是channel又一直查询下发结果,必然会雪上加霜,所以分析订单查询的代码,发现存在这样一个查询:

这个是每次查询都会查询通道订单,用于告知业务系统通道返回的详细信息,每次channel查询订单状态都会执行一下这个查询,经查看这个查询并没有创建相应的索引,而是进行了全表扫描,所以加上order_id的索引,将全表扫描变为为索引范围扫描,再少量的几次回表。
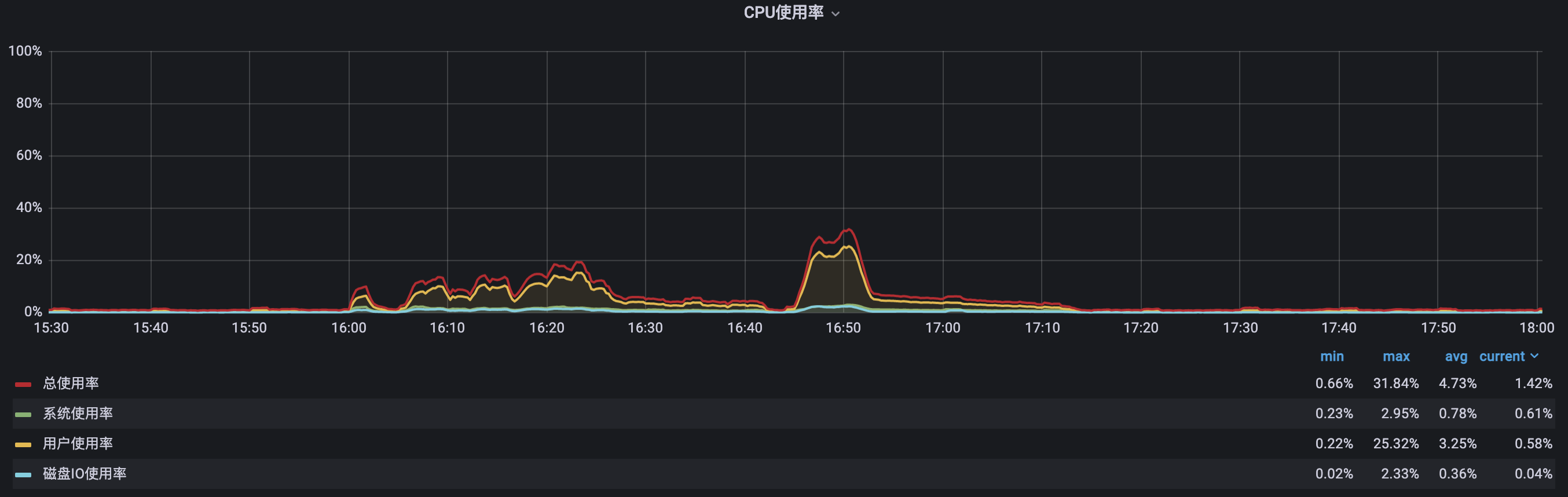
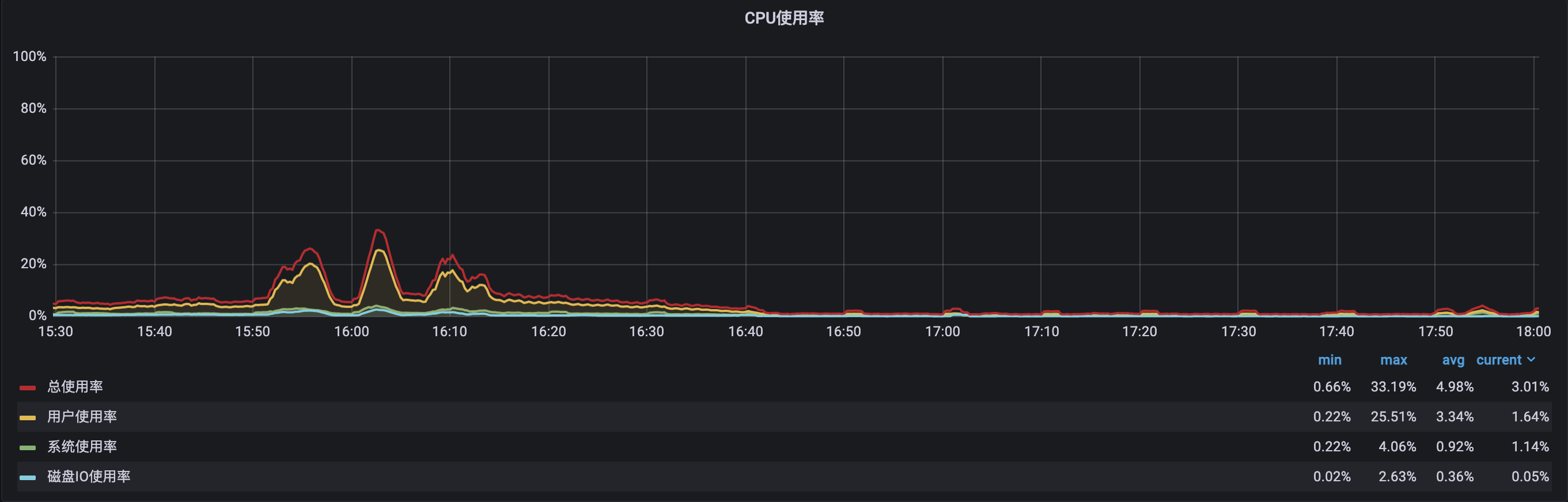
三、优化成效验证
11月14日下发:
11月16日下发:
四、经验总结
- 一定要充分理解业务和系统流程,只有知道自己在做什么才能知道如何更好地去做;
- 出现问题可以先从主流程上进行充分的优化,只有没有任何优化的地方,才采取考虑引入其他框架或者扩硬件;
- 理论知识很重要,付诸实践更重要,不规避问题才能更好地成长;
当看到一些不好的代码时,会发现我还算优秀;当看到优秀的代码时,也才意识到持续学习的重要!--buguge
本文来自博客园,转载请注明原文链接:https://www.cnblogs.com/buguge/p/16900966.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号