
兜底方案只能用来兜底,而不能完全依靠它---记一次数据库唯一索引DuplicateKeyException异常的优化
任务领取单服务类 -- TaskApplyService
创建任务领取单 -- TaskApplyService#save(TaskApplyVo)
任务领取单表 -- task_apply
我们的共享服务平台,当用户签约完成后,系统会根据企业配置生成任务领取单。最初TaskApplyService#save方法的逻辑仅仅是向task_apply表insert记录。
随着系统业务的复杂度增加,发现task_apply表里出现了重复记录。为了快速解决,就在删掉重复数据之后,在task_apply表里为6个关键字段创建了联合的唯一索引。
再之后,发现log文件里DuplicateKeyException越来越多。
验证数据唯一性,也就是数据的判[fáng]重[chóng],通常应该由程序来控制。靠数据库唯一索引只能是兜底方案。一旦完全靠数据库来控制,那么,数据库乃至应用服务的性能开销会很大。

开发team的伙伴们近期忙于需求开发,鉴于不影响数据存储,大家对这样的异常也视而不见了。
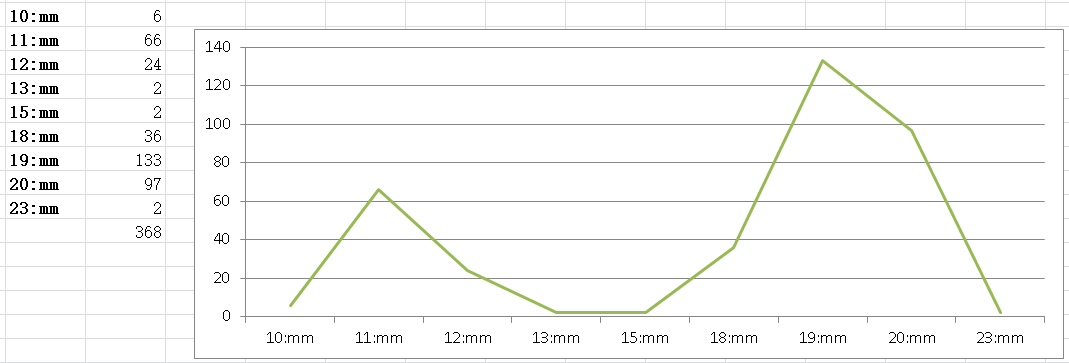
这周四(8月5日)下班后,我在运维刚搭建的JumpServer终端查看log文件时,无意中发现,log文件里竟然充斥着DuplicateKeyException,异常堆栈信息一直刷屏。当天,两个节点的log文件总数达到了300多个,其中19:00~20:00之间有133个。每个文件50Mb,总日志量1.5G,是个惊人的数字!
是时候优化我们的代码了!
“是哪块业务在调用这个save方法?那块业务是不是出问题了?”——对于任何人来说,我想首先肯定是有这个疑问。
找还是要找的。
不过,当务之急,也是最重要的,是完善这个save方法。
最初的TaskApplyService#save代码:
@Override public Result save(TaskApplyVO vo) { log.info("添加任务领取单,VO:{}", vo); try { Task task = taskManager.getById(vo.getTaskId()); if (task == null) { return Result.err("任务不存在 \\taskId=" + vo.getTaskId()); } TaskApply taskApply = BeanMapper.map(vo, TaskApply.class); taskApply.setApplyId(null); Long workTypeId = task.getWorkTypeId(); Long industryTypeId = task.getIndustryTypeId(); buildWorkTypeAndIndustryType(taskApply, workTypeId, industryTypeId); taskApplyManager.save(taskApply); vo.setApplyId(taskApply.getApplyId()); return Result.success(vo); } catch (Exception e) { log.error("添加任务领取单失败, VO:{},异常:", vo, e); return Result.err("添加任务领取单失败" + e.getMessage()); } }
task_apply表数据量目前达到了7,000,000条,每天在以3万多的量级递增。
改造后的TaskApplyService#save代码如下。即先判断是否存在记录,存在就不走后面的insert了。
@Override public Result<TaskApplyVO> save(TaskApplyVO vo) { log.info("添加任务领取单,VO:{}", vo); if (vo == null || !ObjectUtils.allNotNull(vo.getTaskId(), vo.getUserId(), vo.getProviderId(), vo.getEnterpriseId())) { return Result.err("必填属性不能为空!"); } TaskApply entity = new TaskApply().setTaskId(vo.getTaskId()).setEnterpriseId(vo.getEnterpriseId()) .setProviderId(vo.getProviderId()).setUserId(vo.getUserId()); List<TaskApply> list = CacheUtil.getCache("taskApply:".concat(MD5Util.MD5Encode(entity.toString())), 60 * 60, () -> taskApplyManager.list(Wrappers.query(entity))); if (list.stream().anyMatch(p -> p.getApplyStatus().equals(vo.getApplyStatus()))) { log.info("任务领取单已存在"); return Result.success(BeanMapper.map(list.get(0), TaskApplyVO.class)); } try { Task task = taskManager.getById(vo.getTaskId()); if (task == null) { return Result.err("任务不存在 \\taskId=" + vo.getTaskId()); } TaskApply taskApply = BeanMapper.map(vo, TaskApply.class); taskApply.setApplyId(null); Long workTypeId = task.getWorkTypeId(); Long industryTypeId = task.getIndustryTypeId(); buildWorkTypeAndIndustryType(taskApply, workTypeId, industryTypeId); taskApplyManager.save(taskApply); vo.setApplyId(taskApply.getApplyId()); return Result.success(vo); } catch (Exception e) { log.error("添加任务领取单失败, VO:{},异常:", vo, e); return Result.err("添加任务领取单失败" + ExceptionUtils.getMessage(e)); } }
可以注意到,我用了CacheUtil#getCache,这个方法巧妙地利用jdk常用函数式接口 Supplier 封装了redis缓存数据的操作。Supplier<T>是 java.util.function包下的主要成员,它表示泛型数据的提供者程序,通过其唯一方法get来返回泛型对象。CacheUtil代码如下


@Slf4j @Component public class CacheUtil { private static RedisUtil redisUtil; @Autowired public void setRedisUtil(RedisUtil value) { redisUtil = value; } /** * 获取缓存。如果没有,则设置 * * @param key * @param seconds * @param supplier 缓存数据提供者 * @param <T> * @return */ public static <T> T getCache(String key, int seconds, Supplier<T> supplier) { Object obj = redisUtil.get(key); if (null == obj) { T value = supplier.get(); if (null == value) { log.info("设置缓存--缓存设置失败--value为null key={}", key); return null; } if (value instanceof Collection) { if (((Collection) value).size() == 0) { log.info("设置缓存--缓存设置失败--集合为空 key={}", key); return value; } } log.info("设置缓存 key={}", key); redisUtil.set(key, value, seconds); return value; } else { return (T) obj; } } }
同样,也有必要对里面的taskManager#getById、以及读的其他基础数据做缓存,以减小数据库开销,提高响应。
【附】DuplicateKeyException异常的详细信息
2021-08-05 11:39:34.977[] [] [TaskApplyServiceImpl_save1628134774972] ERROR c.e.b.m.taskapply.provider.TaskApplyServiceImpl:626 - 添加任务领取单失败,VO:TaskApplyVO(applyId=1628134774972873, userId=2498481, taskId=1623981559337834, applyStatus=TASKAPPLY_PASS, applyTime=Thu Aug 05 11:39:34 CST 2021, enterpriseId=1612700449967926, userName=何*利, userMobile=152****274, idCardNo=341******180, receiveBankNo=null, enterpriseName=车车****江苏分司, providerName=山东瑞***有限公司, providerId=31720, taskName=信息服务),异常:
org.springframework.dao.DuplicateKeyException:
### Error updating database. Cause: java.sql.SQLIntegrityConstraintViolationException: Duplicate entry '1623981559337834-TASKAPPLY_PASS-4F310E302A059B140D26BE4BB2DFF192' for key 'task_apply_unique_2'
关于里面的entry值 '1623981559337834-TASKAPPLY_PASS-4F310E302A059B140D26BE4BB2DFF192', mysql会针对索引涉及到的字段为索引定义一个值。
先贴上task_apply表DDL语句,其中有联合唯一索引task_apply_unique_2。
CREATE TABLE `task_apply` ( `apply_id` bigint(20) NOT NULL COMMENT '任务领取单号', `user_id` bigint(20) DEFAULT NULL COMMENT '人员编号', `task_id` bigint(20) DEFAULT NULL COMMENT '任务编号', `apply_status` varchar(30) DEFAULT NULL COMMENT '领取状态 TASKAPPLY_UNCLAIMED:待领取,TASKAPPLY_AUDITED:待审核,TASKAPPLY_PASS:审核通过,TASKAPPLY_REFUSE:审核拒绝', `apply_time` datetime DEFAULT NULL COMMENT '领取时间', `enterprise_id` bigint(20) DEFAULT NULL COMMENT '企业编号', `audit_time` datetime DEFAULT NULL COMMENT '企业审核时间', ... `id_card_no` varchar(128) DEFAULT NULL, ... `provider_name` varchar(64) DEFAULT NULL COMMENT '服务商名称', `create_time` datetime DEFAULT NULL COMMENT '创建时间', `create_by` varchar(255) DEFAULT NULL COMMENT '创建人', `update_time` datetime DEFAULT NULL COMMENT '修改时间', `update_by` varchar(255) DEFAULT NULL COMMENT '修改人', `task_name` varchar(64) DEFAULT NULL COMMENT '任务名称', `provider_id` bigint(20) DEFAULT NULL COMMENT '服务商ID', PRIMARY KEY (`apply_id`) USING BTREE, UNIQUE KEY `task_apply_unique_2` (`task_id`,`apply_status`,`id_card_no`,`enterprise_id`,`provider_id`,`user_id`), KEY `user_id_index` (`user_id`), KEY `enterprise_id_and_provider_id` (`enterprise_id`,`provider_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='任务领取表';
如下是测试Duplicate entry .. for key ..
INSERT INTO `emax_task_apply` VALUES (1417422528648880129, 1626774839350848, 1626773826894100, 'TASKAPPLY_PASS', '2021-07-20 17:57:03', 1626769691952966, NULL, NULL, '史千龙', '12300000000', '130432200002150319', '【生产测试】-bosskg(二期)', '品牌宣传', '网络直播', '青岛德瑞信息科技有限公司', '2021-07-20 17:54:00', '12300000000', '2021-07-20 17:57:03', '12300000000', '【生产测试】- 2.0', 30481)
1062 - Duplicate entry '1417422528648880129' for key 'PRIMARY'
INSERT INTO `emax_task_apply` VALUES (141742252864888012, 1626774839350848, 1626773826894100, 'TASKAPPLY_PASS', '2021-07-20 17:57:03', 1626769691952966, NULL, NULL, '史千龙', '12300000000', '130432200002150319', '【生产测试】-bosskg(二期)', '品牌宣传', '网络直播', '青岛德瑞信息科技有限公司', '2021-07-20 17:54:00', '12300000000', '2021-07-20 17:57:03', '12300000000', '【生产测试】- 2.0', 30481)
1062 - Duplicate entry '1626773826894100-TASKAPPLY_PASS-130432200002150319-1626769691952' for key 'task_apply_unique_2'
INSERT INTO `emax_task_apply` VALUES (14174225286488802, 66, 11, '22TASKAPPLY_PASS', '2021-07-20 17:57:03', 44, NULL, NULL, '史千龙', '12300000000', '33', '【生产测试】-bosskg(二期)', '品牌宣传', '网络直播', '青岛德瑞信息科技有限公司', '2021-07-20 17:54:00', '12300000000', '2021-07-20 17:57:03', '12300000000', '【生产测试】- 2.0', 55)
1062 - Duplicate entry '11-22TASKAPPLY_PASS-33-44-55-66' for key 'task_apply_unique_2'
看来,① mysql主键值直接是主键字段的值,比如'1417422528648880129';② 联合索引的情况下,当每个索引字段的值比较短的时候,mysql是拼起来的,比如 '11-22TASKAPPLY_PASS-33-44-55-66' ;③ 而当每个索引字段的值比较长的时候,mysql做了处理了,比如 '1626773826894100-TASKAPPLY_PASS-130432200002150319-1626769691952' 和'1623981559337834-TASKAPPLY_PASS-4F310E302A059B140D26BE4BB2DFF192'。
当看到一些不好的代码时,会发现我还算优秀;当看到优秀的代码时,也才意识到持续学习的重要!--buguge
本文来自博客园,转载请注明原文链接:https://www.cnblogs.com/buguge/p/15113553.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号