流式计算非 Flink 莫属?
在本文中,通过一个真实的实时流处理系统的改造过程来说明:在流式计算领域,Flink 并不是唯一的选择,而需要根据多个维度来评估流式处理框架,按具体应用场景来做出合适的选择,“适合自己的才是最好的”。
背景介绍
业务背景
这里介绍的真实案例来自于一个 代理商实时分润 的业务。在这个业务中,需要对每笔交易按照设定的分润规则计算出代理商应得的收益并计入其账户。
看似简单的需求,实际上在该业务中还有两个额外的要求:
- 代理商是分层级的,有一代、二代、总代等等,因此一笔交易实际上要顺着代理链条分润到各代理手上。
- 对于每个代理商的分润结果要按照多个维度(实时)汇总,如按日、按月、按季度、按年等等。
最初的系统实现正是因为未意识到这两点对技术实现的潜在要求,结果性能极其低下而无法满足上线要求。
技术实现
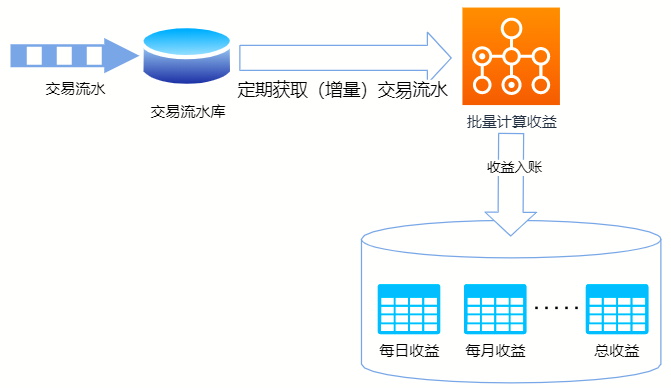
在最初的实现中,核心步骤是这样的:
- 系统从交易流水库中定期获取新增的交易流水
- 对于每批交易流水中的每一笔进行分润计算,算出相关代理商的收益
- 将代理商每笔交易中所获收益入账
问题分析
按照最初的系统实现,经实测每秒所能处理的交易笔数 不足 100。经分析,性能低下的主要原因是:
- 以轮询方式获取新增交易流水,压缩了系统处理时间
- 收益入账出现的数据库写入冲突
- 为加快收益计算和入账,系统采用了并行处理交易流水的方式,但不同的交易可能涉及相同的代理商,因此导致收益库出现大量的写入冲突;
- 在顶层的总代上写入冲突表现得更为明显,因为每笔交易的分润都涉及到为数不多的那几个总代。
改造过程
设计思路
要解决最初系统实现中性能低下的第一个主要原因:即轮询和批量处理,很自然的就想到了流式计算。而在流式计算领域,似乎 Flink 就是不二之选。实际上,研发团队最初也正是打算引入 Flink 来进行系统改造的。
但在研发团队深入交流后,我问了这么几个问题:
- 分润计算的规则是不是很复杂,必须依赖 Flink 的计算框架才能实现?
- 团队中是否有人对 Flink 比较精通?
- 团队是否打算自行管理 Flink 集群 和 部署 Flink 任务?
- 分润的业务规则是否经常需要改变?
对于这几个问题的答案是:
- 规则不复杂,在最初的系统中就是在应用中实现的
- 这个可以有,但现在没有😀
- 这个最好还是交给大数据团队来做比较好😁
- 业务团队一天一个想法,规则必须得经常变啊
所以综合以上回答,对于该系统的流式计算解决方案最好能有轻量级的解决方案。该方案需要:
- 学习成本低,方便研发团队迅速掌握和落地
- 研发团队能完全把控相关技术组件的管理和任务部署,减少团队间的协作以提高敏捷度
针对这两点要求,最贴合的流式计算框架 Kafka Streams 就呼之欲出了。在将其与 Flink 进行对比之前,我们先来看看最终的解决方案。
改造方案
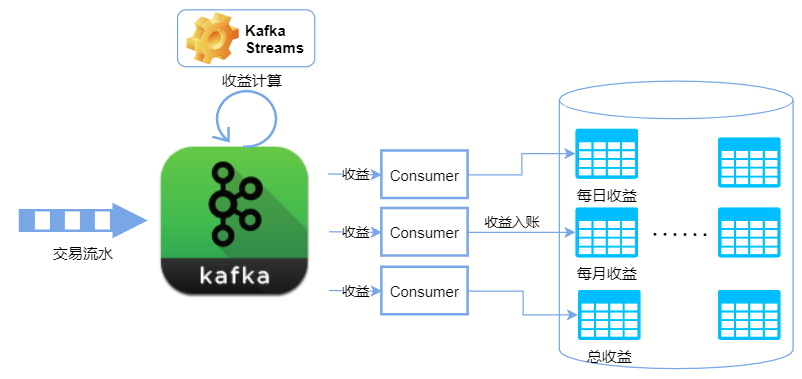
按照流式计算的要求,我们对系统架构进行了改造,改造后的核心步骤是这样的:
- 交易流水写入 Kafka
- 使用 Kafka Streams 从 Kafka 中读取交易流水并逐笔计算各相关代理商的收益(即,一个代理商在一笔交易中应得的收益),再将收益写入 Kafka
- 针对每个收益汇总维度建立相对应的消费者组,消费者从 Kafka 中读取收益,并累加存入对应的汇总表。
结果分析
经过上述系统改造后,整个实时分润系统的质量特性得到明显的改善,表现在如下几个方面。
性能改进
经过压测,新系统在性能上有了明显的改善,从之前每秒所能处理的交易笔数 不足 100,提升到了现在的 2000。借助 Kafka 的 partition,同一个代理商的收益出现在同一个 partition,并由相应消费者单线程累加存入对应的汇总表,从而消除了写入冲突的问题。实际上处理性能的瓶颈现在已转移到了数据库的写入性能上,提高数据库单机性能、分库分表 或者 使用分布式数据库,还能进一步提高系统的处理性能。
可维护性
通过将 收益计算 实现在 Kafka Streams 上,将 收益汇总 实现在不同的消费者上,实现了代码实现上的关注点分离。因此,收益计算 和 收益汇总 变得更加简单和纯粹,极大地方便了维护和更新迭代,特别是对于收益计算这个应业务需求经常需要改动的模块;对于收益汇总而言,如需增加新的汇总维度则仅需要增加一个对应的消费者组,而原有的汇总逻辑不变。
稳定性
在架构中引入 Kafka 后,实际上为这个系统实现了削峰填谷,为汇总库的稳定运行提供了保障。
对 Flink 的反思
现如今一谈到流式计算,大家的直觉反应就是 Flink,但是这种独立计算平台一向都存在着使用成本高的问题:一方面需要占用独立的硬件资源来运行,另一方面还需要专门的团队(一般是大数据团队)来维护和管理。而对于本文中所述的业务场景而言,其业务复杂度低,并不是非 Flink 不可;同时如果选择了 Flink 则必然引出应用研发团队和大数据团队间的协作问题,很多时候这比技术问题本身还难以解决。就本文所述案例,Flink 相对于 Kafka Streams 方案明显存在着投入产出比低的问题。实际上,Kafka Streams 正是瞄准着低成本流式计算的场景而诞生的。
相对于 Flink,Kafka Streams 的低成本表现在:
- Streams API 只是一个 Java 库,通常可以将其内嵌在我们的应用程序中。这意味着不需要独立的硬件资源来运行它。
- 用户的流处理代码在其应用中运行,而不必像 Flink 那样提交专门的 Job。这意味着测试和调试容易。
- 由应用研发团队全程掌控。这意味着避免了跨团队协作,很多时候这是一个巨大的成本。
因此,如果相关业务逻辑不是很复杂的话,其实完全可以通过 Kafka streams 来解决,应用研发团队可以完全掌控相关的代码和部署,从而能够快速响应需求变化。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号