
Mybatis源码解析(二) —— 加载 Configuration
Mybatis源码解析(二) —— 加载 Configuration
正如上文所看到的 Configuration 对象保存了所有Mybatis的配置信息,也就是说mybatis-config.xml 以及 mapper.xml 中的所有信息
都可以在 Configuration 对象中获取到。所以一般情况下,Configuration 对象只会存在一个。通过上篇文章我们知道了mybatis-config.xml 和 mapper.xml
分别是通过 XMLConfigBuilder 和 XMLMapperBuilder 进行解析存储到Configuration的。但有2个问题需要我们去了解:
-
1、 XMLConfigBuilder 和 XMLMapperBuilder 是如何解析xml信息的?
-
2、 Configuration 内部结构是怎样的?它是如何存储 xml信息的?
那么,我们就带着这2个问题去分析下源码吧!
一、 Configuration 属性
Configuration包含了会深深影响 MyBatis 行为的设置和属性信息。 配置文档的顶层结构如下:
- configuration
- properties(属性)
- settings(设置)
- typeAliases(类型别名)
- typeHandlers(类型处理器)
- objectFactory(对象工厂)
- plugins(插件)
- environments(环境配置)
- environment(环境变量)
- transactionManager(事务管理器)
- dataSource(数据源)
- databaseIdProvider(数据库厂商标识)
- mappers(映射器)
其中我们最常配置的是 settings 。一个配置相对完整的 settings 元素的示例如下:
<settings>
<!-- 全局地开启或关闭配置文件中的所有映射器已经配置的任何缓存 -->
<setting name="cacheEnabled" value="true"/>
<!-- 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态。 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 是否允许单一语句返回多结果集(需要驱动支持) -->
<setting name="multipleResultSetsEnabled" value="true"/>
<!-- 使用列标签代替列名 -->
<setting name="useColumnLabel" value="true"/>
<!-- 允许 JDBC 支持自动生成主键,需要驱动支持。 如果设置为 true 则这个设置强制使用自动生成主键,尽管一些驱动不能支持但仍可正常工作(比如 Derby) -->
<setting name="useGeneratedKeys" value="false"/>
<!-- 指定 MyBatis 应如何自动映射列到字段或属性。 NONE 表示取消自动映射;PARTIAL 只会自动映射没有定义嵌套结果集映射的结果集。 FULL 会自动映射任意复杂的结果集(无论是否嵌套)-->
<setting name="autoMappingBehavior" value="PARTIAL"/>
<!-- 指定发现自动映射目标未知列(或者未知属性类型)的行为。
NONE: 不做任何反应
WARNING: 输出提醒日志 ('org.apache.ibatis.session.AutoMappingUnknownColumnBehavior' 的日志等级必须设置为 WARN)
FAILING: 映射失败 (抛出 SqlSessionException) -->
<setting name="autoMappingUnknownColumnBehavior" value="WARNING"/>
<!-- 配置默认的执行器。SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(prepared statements); BATCH 执行器将重用语句并执行批量更新 -->
<setting name="defaultExecutorType" value="SIMPLE"/>
<!-- 设置超时时间,它决定驱动等待数据库响应的秒数 -->
<setting name="defaultStatementTimeout" value="25"/>
<!-- 为驱动的结果集获取数量(fetchSize)设置一个提示值。此参数只可以在查询设置中被覆盖 -->
<setting name="defaultFetchSize" value="100"/>
<!-- 允许在嵌套语句中使用分页(RowBounds)。如果允许使用则设置为 false-->
<setting name="safeRowBoundsEnabled" value="false"/>
<!-- 是否开启自动驼峰命名规则(camel case)映射,即从经典数据库列名 A_COLUMN 到经典 Java 属性名 aColumn 的类似映射 -->
<setting name="mapUnderscoreToCamelCase" value="false"/>
<!-- MyBatis 利用本地缓存机制(Local Cache)防止循环引用(circular references)和加速重复嵌套查询。 默认值为 SESSION,这种情况下会缓存一个会话中执行的所有查询。 若设置值为 STATEMENT,本地会话仅用在语句执行上,对相同 SqlSession 的不同调用将不会共享数据-->
<setting name="localCacheScope" value="SESSION"/>
<!-- 当没有为参数提供特定的 JDBC 类型时,为空值指定 JDBC 类型。 某些驱动需要指定列的 JDBC 类型,多数情况直接用一般类型即可,比如 NULL、VARCHAR 或 OTHER-->
<setting name="jdbcTypeForNull" value="OTHER"/>
<!-- 指定哪个对象的方法触发一次延迟加载-->
<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/>
<!-- 指定 MyBatis 所用日志的具体实现,未指定时将自动查找。-->
<setting name="logImpl" value="STDOUT_LOGGING" />
</settings>
查看 Configuration 源码,我们可以轻松的找到上面配置对应的字段属性:
protected Environment environment;
protected boolean safeRowBoundsEnabled = false;
protected boolean safeResultHandlerEnabled = true;
protected boolean mapUnderscoreToCamelCase = false;
protected boolean aggressiveLazyLoading = true;
protected boolean multipleResultSetsEnabled = true;
protected boolean useGeneratedKeys = false;
protected boolean useColumnLabel = true;
protected boolean cacheEnabled = true;
protected boolean callSettersOnNulls = false;
protected String logPrefix;
protected Class <? extends Log> logImpl;
protected LocalCacheScope localCacheScope = LocalCacheScope.SESSION;
protected JdbcType jdbcTypeForNull = JdbcType.OTHER;
protected Set<String> lazyLoadTriggerMethods = new HashSet<String>(Arrays.asList(new String[] { "equals", "clone", "hashCode", "toString" }));
protected Integer defaultStatementTimeout;
protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE;
protected AutoMappingBehavior autoMappingBehavior = AutoMappingBehavior.PARTIAL;
protected Properties variables = new Properties();
protected ObjectFactory objectFactory = new DefaultObjectFactory();
protected ObjectWrapperFactory objectWrapperFactory = new DefaultObjectWrapperFactory();
protected MapperRegistry mapperRegistry = new MapperRegistry(this);
protected boolean lazyLoadingEnabled = false;
protected ProxyFactory proxyFactory;
protected String databaseId;
protected Class<?> configurationFactory;
protected final InterceptorChain interceptorChain = new InterceptorChain();
protected final TypeHandlerRegistry typeHandlerRegistry = new TypeHandlerRegistry();
protected final TypeAliasRegistry typeAliasRegistry = new TypeAliasRegistry();
protected final LanguageDriverRegistry languageRegistry = new LanguageDriverRegistry();
上面的字段属性对应的是mybatis-config.xml 配置文件,那么对应mapper.xml的字段属性如下:
protected final Map<String, MappedStatement> mappedStatements = new StrictMap<MappedStatement>("Mapped Statements collection");
protected final Map<String, Cache> caches = new StrictMap<Cache>("Caches collection");
protected final Map<String, ResultMap> resultMaps = new StrictMap<ResultMap>("Result Maps collection");
protected final Map<String, ParameterMap> parameterMaps = new StrictMap<ParameterMap>("Parameter Maps collection");
protected final Map<String, KeyGenerator> keyGenerators = new StrictMap<KeyGenerator>("Key Generators collection");
protected final Map<String, XNode> sqlFragments = new StrictMap<XNode>("XML fragments parsed from previous mappers");
其中 我们最需要关注的是 mappedStatements 、 resultMaps 以及 sqlFragments:
-
resultMaps: 不难理解就是 保存了 mapper.xml 中的 resultMap 节点信息
-
mappedStatements: 保存了 Mapper 配置文件中得 select/update/insert/delete节点信息
-
sqlFragments: 保存了 Mapper 配置文件中得 sql 节点信息
上面3种是我们在平时项目开发中使用最多的,我们可以发现其 都是 StrictMap 这个 内部类 的 value,那我们来具体分析下 StrictMap 与普通Map有什么不一样的地方:
public V put(String key, V value) {
if (containsKey(key))
throw new IllegalArgumentException(name + " already contains value for " + key);
if (key.contains(".")) {
final String shortKey = getShortName(key);
if (super.get(shortKey) == null) {
// 存简称 key
super.put(shortKey, value);
} else {
// 重复的 key 时存的value 为 Ambiguity ,在 get 时会判断 value 是否为 Ambiguity,是则抛异常
super.put(shortKey, (V) new Ambiguity(shortKey));
}
}
// 存全称 key
return super.put(key, value);
}
public V get(Object key) {
V value = super.get(key);
if (value == null) {
throw new IllegalArgumentException(name + " does not contain value for " + key);
}
// 判断类型是否为 Ambiguity
if (value instanceof Ambiguity) {
throw new IllegalArgumentException(((Ambiguity) value).getSubject() + " is ambiguous in " + name
+ " (try using the full name including the namespace, or rename one of the entries)");
}
return value;
}
// 截取最后一个"."符号后面的字符串做为shortName
private String getShortName(String key) {
final String[] keyparts = key.split("\\.");
final String shortKey = keyparts[keyparts.length - 1];
return shortKey;
}
从源码中我们可以看出,其重写了 put 和 get 2个方法 ,其中 put方法针对 key 做了3个方面的处理:
-
1、 截取最后一个"."符号后面的字符串做为 key 存储一次value
-
2、 key 重复时,存储的value是一个 Ambiguity 对象。get 获取时会判断value是否未 Ambiguity 类型,如果是则抛出异常
-
3、 直接调用 super.put(key, value) 存储同一 value 一次(此时key未做任何操作处理)
也就是说,针对 :
StrictMap.put("com.xxx.selectId","select * from user where id=?")
这一次put请求, StrictMap 中有 2个不同的key,但value相同的元素:
com.xxx.selectId = select * from user where id=?
selectId = select * from user where id=?
以上就是 Configuration 内部属性的大致分析,其中关键的属性分别是: mappedStatements、 resultMaps、 sqlFragments,接下来我们会分析这3。
二、 XMLConfigBuilder.parse()
XMLConfigBuilder.parse() 主要用于解析mybatis-config.xml 配置文件的信息,其本身没有多大的意义去分析,我这边还是给出部分源码吧,有想进一步去了解的同学可以自行深入分析:
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
private void parseConfiguration(XNode root) {
try {
// 解析 properties(参数配置) 节点
propertiesElement(root.evalNode("properties"));
// 解析 typeAliases(别名) 节点
typeAliasesElement(root.evalNode("typeAliases"));
// 解析 plugins(插件) 节点
pluginElement(root.evalNode("plugins"));
// 解析 objectFactory(数据库返回结果集使用) 节点
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
// 解析 settings 节点
settingsElement(root.evalNode("settings"));
// 解析 environments 节点
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
// 解析 mappers 节点
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
三、 XmlMapperBuilder.parse()
如果拿电脑做比喻的话,前面 XMLConfigBuilder.parse() 就好比主机,但是仅仅有主机是不行的,我们还得需要鼠标、键盘、显示器等等组件才玩组装成一个完整的电脑。而 XmlMapperBuilder.parse() 所做的事儿就是组装各种组件(Mapper)。我们来看下 XmlMapperBuilder.parse() 的源码:
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
// 解析方法源头
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingChacheRefs();
parsePendingStatements();
}
// 最核心解析方法
private void configurationElement(XNode context) {
try {
// 我们都知道 Mapper 的 namespace 是与 Mapper接口路径对应的,所以进来需要判断下 namespace
String namespace = context.getStringAttribute("namespace");
if (namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
// 为 MapperBuilderAssistant 设置 namespace
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
// 解析 resultMap 节点信息
resultMapElements(context.evalNodes("/mapper/resultMap"));
// 解析 sql 节点信息
sqlElement(context.evalNodes("/mapper/sql"));
// 解析 select|insert|update|delete 节点信息
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. Cause: " + e, e);
}
}
我们可以看到核心的解析方法内部分别针对 不同的节点 进行加载,我们先看下 resultMap 的解析加载:
加载 resultMap节点
正如官方所描述的一样 : resultMap 是最复杂也是最强大的元素(用来描述如何从数据库结果集中来加载对象)。 所以其解析复杂度也是最复杂的,我们先看一个简单的resultMap 节点配置:
<resultMap id="selectUserById" type="User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="phone" column="phone"/>
</resultMap>
结合中上面的配置, 我们再看下面其解析源码会更加清晰明了:
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings) throws Exception {
ErrorContext.instance().activity("processing " + resultMapNode.getValueBasedIdentifier());
// 获取 resultMap 节点中的 id 配置信息,也就是上面示列的 id="selectUserById"
String id = resultMapNode.getStringAttribute("id",
resultMapNode.getValueBasedIdentifier());
// 获取 resultMap 节点中的 type 配置信息,也就是上面示列的 type="User"
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType",
resultMapNode.getStringAttribute("javaType"))));
String extend = resultMapNode.getStringAttribute("extends");
Boolean autoMapping = resultMapNode.getBooleanAttribute("autoMapping");
Class<?> typeClass = resolveClass(type);
Discriminator discriminator = null;
List<ResultMapping> resultMappings = new ArrayList<ResultMapping>();
resultMappings.addAll(additionalResultMappings);
// 获取到所有字节的信息,即 id 节点、result节点等等
List<XNode> resultChildren = resultMapNode.getChildren();
for (XNode resultChild : resultChildren) {
if ("constructor".equals(resultChild.getName())) {
processConstructorElement(resultChild, typeClass, resultMappings);
} else if ("discriminator".equals(resultChild.getName())) {
discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings);
} else {
ArrayList<ResultFlag> flags = new ArrayList<ResultFlag>();
if ("id".equals(resultChild.getName())) {
flags.add(ResultFlag.ID);
}
// 将获取到的 子节点信息封装到 resultMapping 对象中。
resultMappings.add(buildResultMappingFromContext(resultChild, typeClass, flags));
}
}
ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id, typeClass, extend, discriminator, resultMappings, autoMapping);
try {
// 实际调用的是 MapperBuilderAssistant.addResultMap() 方法
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
}
从源码分析来看,整个解析流程分4步走:
-
1、 获取 resultMap 节点中的 id 配置信息,也就是上面示列的 id="blogPostResult"
-
2、 获取 resultMap 节点中的 type 配置信息,也就是上面示列的 type="User" ( Class 名)
-
3、 将获取到的 子节点信息封装到 resultMapping 对象中。
-
4、 实际调用的是 MapperBuilderAssistant.addResultMap() 方法 将上面3步获取到的数据生成 resultMap 保存到 Configuration 中。
上面有2 个关键对象: ResultMapping 和 MapperBuilderAssistant。其中 MapperBuilderAssistant 贯穿了整个Mapper的解析,所以先不分析,我们先看下 ResultMapping ,其源码内部的字段属性有以下:
ResultMapping 类属性
private Configuration configuration;
private String property;
private String column;
private Class<?> javaType;
private JdbcType jdbcType;
private TypeHandler<?> typeHandler;
private String nestedResultMapId;
private String nestedQueryId;
private Set<String> notNullColumns;
private String columnPrefix;
private List<ResultFlag> flags;
private List<ResultMapping> composites;
private String resultSet;
private String foreignColumn;
private boolean lazy;
ResultMap 类属性
private String id;
private Class<?> type;
private List<ResultMapping> resultMappings;
private List<ResultMapping> idResultMappings;
private List<ResultMapping> constructorResultMappings;
private List<ResultMapping> propertyResultMappings;
private Set<String> mappedColumns;
private Discriminator discriminator;
private boolean hasNestedResultMaps;
private boolean hasNestedQueries;
private Boolean autoMapping;
相信大多数同学对其中的 property、column、javaType、jdbcType、typeHandler 这几个相对熟悉很多,正如看到的一样 ResultMapping 主要用于封装 resultMap 节点的所有子节点(子节点嵌套也是一样的) 的 信息。它与 ResultMap 的关系如下:
-
1、 ResultMap 是由 id、type以及大量的 ResultMapping 对象 组合而成。
-
2、 ResultMapping对象 是 结果集(数据库操作结果集)与 java Bean对象 属性的 对应关系。 即一个 ResultMapping对象 对应一个 Bean 对象中某个字段属性。
-
3、 ResultMap 对象是 结果集 与 java Bean对象的 对应关系。即一个 ResultMap 对象 对应一个 Bean对象。
加载 select|insert|update|delete节点
我们先看一个简单的 select 节点元素的配置:
<select id="selectPerson" parameterType="int" resultType="hashmap">
SELECT * FROM PERSON WHERE ID = #{id}
</select>
我们再来分析下 其实如何被加载的, 我们来分析下 加载这4个节点的方法 buildStatementFromContext() 源码:
private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
for (XNode context : list) {
// 创建 XMLStatementBuilder
final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
try {
// 通过 XMLStatementBuilder的 parseStatementNode() 方法进行加载。
statementParser.parseStatementNode();
} catch (IncompleteElementException e) {
configuration.addIncompleteStatement(statementParser);
}
}
}
我们可以看到其内部创建了一个 XMLStatementBuilder 对象,然后再调用其 parseStatementNode() 进行加载的。仔细发现,我们可以看到创建 XMLStatementBuilder 对象需要 的3跟 关系构造参数:configuration、 builderAssistant(是不是很熟悉,没错就是 MapperBuilderAssistant ) 、context(节点信息)
XMLStatementBuilder.parseStatementNode()
parseStatementNode() 方法是加载 select|insert|update|delete节点 信息的核心,那么我们深入分析其内部实现:
// 省略了一些相对不重要的代码
public void parseStatementNode() {
// 以下几个获取的配置信息,我们都应该很熟悉吧
String id = context.getStringAttribute("id");
String parameterMap = context.getStringAttribute("parameterMap");
String parameterType = context.getStringAttribute("parameterType");
Class<?> parameterTypeClass = resolveClass(parameterType);
String resultMap = context.getStringAttribute("resultMap");
String resultType = context.getStringAttribute("resultType");
Class<?> resultTypeClass = resolveClass(resultType);
// 读取 <include> 信息
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
includeParser.applyIncludes(context.getNode());
// 将每个<select/>, <update/>,<insert/>,<delete/> 加载(通过 createSqlSource()方法)为一个 DynamicSqlSource (SqlSource 最常用子类 ):内部存在 getBoundSql() 方法 会从XML文件读取的映射语句的内容 并封装成 BoundSql。
String lang = context.getStringAttribute("lang");
LanguageDriver langDriver = getLanguageDriver(lang);
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
.....
// 通过 MapperBuilderAssistant 的 addMappedStatement() 添加 MappedStatement 信息。
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
根据源码我们大致可以把整个流程分成4个部分:
-
1、 读取 select|insert|update|delete 节点的属性信息,比如: id、resultMap等等我们常用到的信息
-
2、 处理
节点信息 ,通过 XMLIncludeTransformer.applyIncludes() 方法将 Sql 中的 替换成真实的SQl -
3、 通过 LanguageDriver.createSqlSource()方法 将每个 select|insert|update|delete 节点 内部信息(即SQL语句) 加载(通过 )为一个 SqlSource:内部存在 getBoundSql() 方法会将SQL 替换(主要替换 #{ } 和 ${ }) 并封装成 BoundSql。
-
4、 通过 MapperBuilderAssistant 的 addMappedStatement() 方法往 Configuration 添加 MappedStatement 信息。
上面中涉及到了几个我们首次见面的类,我们先从 SqlSource 开始分析,我们来看下用得最多的子类 DynamicSqlSource 的源码:
public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
return builder.parseScriptNode();
}
其内部是通过 XMLScriptBuilder.parseScriptNode() 方法 来进行创建 SqlSource,继续查询该方法内部源码:
public SqlSource parseScriptNode() {
// 将一个SQL内容加载成对个 SqlNode
List<SqlNode> contents = parseDynamicTags(context);
// 通过组合模式将多个 SqlNode 组合成一个 SqlNode
MixedSqlNode rootSqlNode = new MixedSqlNode(contents);
SqlSource sqlSource = null;
if (isDynamic) {
// 创建动态的 SqlSource
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
// 创建原始(静态)的 SqlSource
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}
上面源码中关于 SqlNode 以及它的大量子类之间的设计是很了不起,但是由于篇幅有限,这里大致解释下为什么需要把 SQL 语句 拆分成多个 SqlNode,我们先看下示列:
<select id="selectStudents" parameterType="int" resultType="hashmap">
select
stud_id as studId, name, phone
from students
<where>
name = #{name}
<if test="phone != null">
AND phone = #{phone}
</if>
</where>
</select>
正如上面的sql一样,如果我们一次性把SQL保存到一个 SqlNode 中,那是不是在获取生成 BoundSql 时 解析相对困难了呢?如果我们把一些关键点给做个分割是不是相对好解析点呢?所以出现了 IfSqlNode、WhereSqlNode等等,不用看,大家应该也能明白 IfSqlNod 就是用于 存储 :
<if test="phone != null">
AND phone = #{phone}
</if>
当然不是直接存储的,大致结构可以看下图:
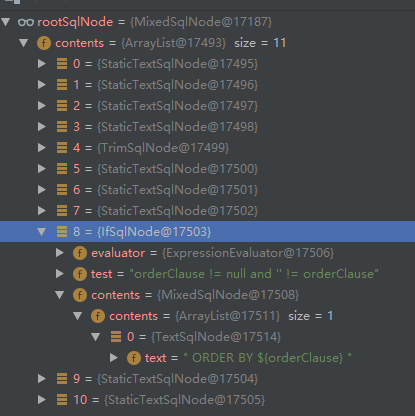
我们获取 BoundSql 时 IfSqlNode 就会判断 是否满足条件。所以整个 SqlNode 体系是很庞大的,它们分别有不同的职责。从上面我们看到最后将 SqlNode 作为 创建 DynamicSqlSource 对象的参数。 我们来查看下 DynamicSqlSource 源码。看看其是如何获取到 BoundSql的:
public class DynamicSqlSource implements SqlSource {
private Configuration configuration;
// 存放了SQL片段信息
private SqlNode rootSqlNode;
public DynamicSqlSource(Configuration configuration, SqlNode rootSqlNode) {
this.configuration = configuration;
this.rootSqlNode = rootSqlNode;
}
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
// 每个SqlNode的 apply方法调用时,都将解析好的sql加到context中,最终通过context.getSql()得到完整的sql
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
for (Map.Entry<String, Object> entry : context.getBindings().entrySet()) {
boundSql.setAdditionalParameter(entry.getKey(), entry.getValue());
}
return boundSql;
}
}
正如上面所示一样, 每个SqlNode都会取调用 apply方法 自行解析并拼接到context。可能有人会问,getBoundSql() 什么时候会被调用呢? 我这里提前 解释下: 当我们请求Mapper接口时(即一个SqlSession会话访问数据库时)会调用到。
BoundSql 内部主要时封装好了请求sql,以及请求参数,这是其源码内部属性:
// 一个完整的sql,此时的sql 就是 JDBC 那种,即 select * from user where id = ?
private String sql;
// 参数列表
private List<ParameterMapping> parameterMappings;
private Object parameterObject;
private Map<String, Object> additionalParameters;
private MetaObject metaParameters;
至此, 加载 select|insert|update|delete节点 的流程已经非常清晰了。但我们还有一个 MapperBuilderAssistant 没解析。其实 MapperBuilderAssistant 类如其,它就是 MapperBuilderXml 的 助理。
MapperBuilderXml 对象负责从XML读取配置,而 MapperBuilderAssistant 负责创建对象并加载到Configuration中。
四、个人总结
整个 Configuration 的加载主要分2部分:
- 1、 mybatis-config.xml 的加载
- 2、 mapper.xml 的加载
其中 mapper.xml 的加载 是 最为复杂的,本文也主要解析了它的加载。下面的序列图讲述其加载流程:
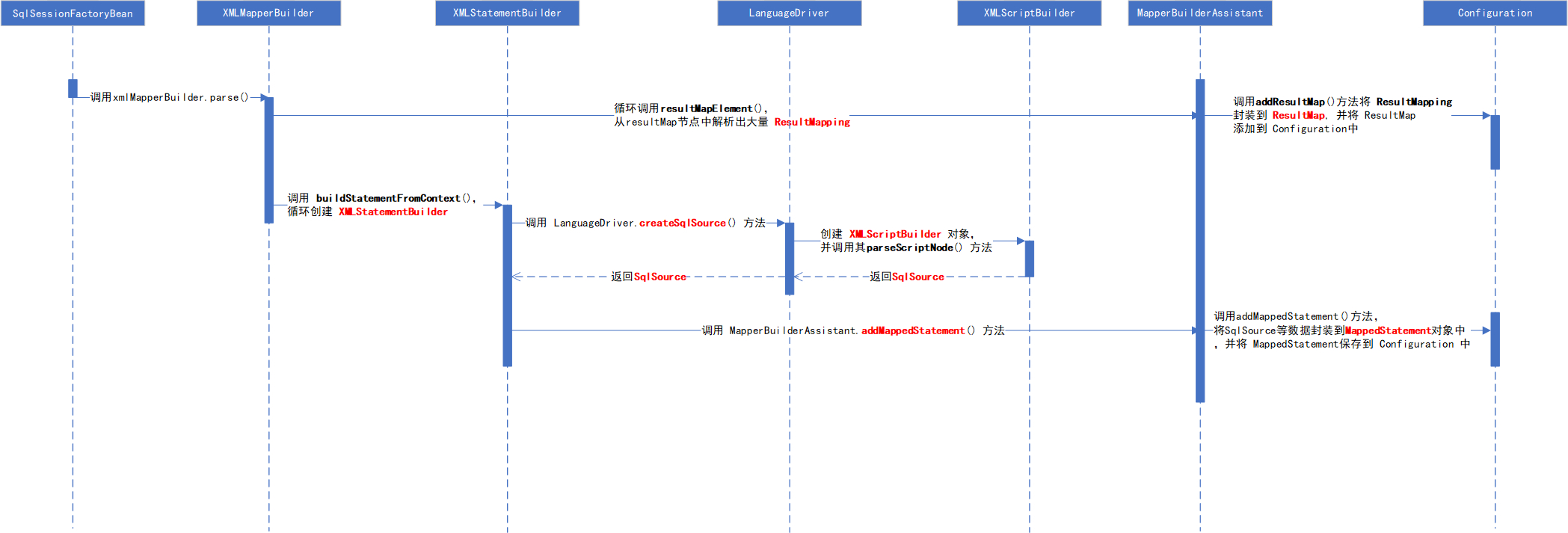
如果您对这些感兴趣,欢迎star、follow、收藏、转发给予支持!
本文由博客一文多发平台 OpenWrite 发布!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号