Oracle建立全文索引详解
Oracle建立全文索引详解
1.全文检索和普通检索的区别
不使用Oracle text功能,当然也有很多方法可以在Oracle数据库中搜索文本,比如INSTR函数和LIKE操作:
SELECT *FROM mytext WHERE INSTR (thetext, 'Oracle') > 0;
SELECT * FROM mytext WHERE thetext LIKE '%Oracle%';
有很多时候,使用instr和like是很理想的, 特别是搜索仅跨越很小的表的时候。然而通过这些文本定位的方法将导致全表扫描,对资源来说消耗比较昂贵,而且实现的搜索功能也非常有限,因此对海量的文本数据进行搜索时,建议使用oralce提供的全文检索功能。
附:这里顺带记录一下INSTR和LIKE:
Oracle中,可以使用 Instr 函数对某个字符串进行判断,判断其是否含有指定的字符。其语法为:Instr(string, substring, position, occurrence)。
string:代表源字符串(写入字段则表示此字段的内容)。
substring:代表想从源字符串中查找的子串。
position:代表查找的开始位置,该参数可选的,默认为1。
occurrence:代表想从源字符中查找出第几次出现的substring,该参数也是可选的,默认为1。
position 的值为负数,那么代表从右往左进行查找。
instr和like的性能比较
其实从效率角度来看,谁能用到索引,谁的查询速度就会快。
like有时可以用到索引,例如:name like ‘李%’,而当下面的情况时索引会失效:name like ‘%李’。所以一般我们查找中文类似于‘%字符%’时,索引都会失效。与其他数据库不同的是,oracle支持函数索引。例如在name字段上建个instr索引,查询速度就比较快了,这也是为什么instr会比like效率高的原因。
注:instr(title,’手册’)>0 相当于like‘%手册%’
instr(title,’手册’)=0 相当于not like‘%手册%’
2.设置全文检索
步骤步骤一:检查和设置数据库角色
首先检查数据库中是否有CTXSYS用户和CTXAPP脚色。如果没有这个用户和角色,意味着你的数据库创建时未安装intermedia功能(10G默认安装都有此用户和角色)。你必须修改数据库以安装这项功能。默认安装情况下,ctxsys用户是被锁定的,因此要先启用ctxsys的用户。
--设置词法分析器(lexer)
Oracle实现全文检索,其机制其实很简单。即通过Oracle专利的词法分析器(lexer),将文章中所有的表意单元(Oracle 称为 term)找出来,记录在一组以dr$开头的表中,同时记下该term出现的位置、次数、hash值等信息。检索时,Oracle从这组表中查找相应的term,并计算其出现频率,根据某个算法来计算每个文档的得分(score),即所谓的‘匹配率’。而lexer则是该机制的核心,它决定了全文检索的效率。Oracle针对不同的语言提供了不同的lexer,而我们通常能用到其中的三个:
basic_lexer:针对英语。它能根据空格和标点来将英语单词从句子中分离,还能自动将一些出现频率过高已经失去检索意义的单词作为‘垃圾’处理,如if,is等,具有较高的处理效率。但该lexer应用于汉语则有很多问题,由于它只认空格和标点,而汉语的一句话中通常不会有空格,因此,它会把整句话作为一个term,事实上失去检索能力。以‘中国人民站起来了’这句话为例,basic_lexer分析的结果只有一个term,就是‘中国人民站起来了’。此时若检索‘中国’,将检索不到内容。
chinese_vgram_lexer:专门的汉语分析器,支持所有汉字字符集(ZHS16CGB231280 ZHS16GBK ZHT32EUC ZHT16BIG5 ZHT32TRIS ZHT16MSWIN950 ZHT16HKSCS UTF8 )。该分析器按字为单元来分析汉语句子。‘中国人民站起来了’这句话,会被它分析成如下几个term:‘中’,‘中国’,‘国人’,‘人民’,‘民站’,‘站起’,起来’,‘来了’,‘了’。可以看出,这种分析方法,实现算法很简单,并且能实现‘一网打尽’,但效率则是差强人意。
chinese_lexer:这是一个新的汉语分析器,只支持utf8字符集。上面已经看到,chinese vgram lexer这个分析器由于不认识常用的汉语词汇,因此分析的单元非常机械,像上面的‘民站’,‘站起’在汉语中根本不会单独出现,因此这种term是没有意义的,反而影响效率。chinese_lexer的最大改进就是该分析器能认识大部分常用汉语词汇,因此能更有效率地分析句子,像以上两个愚蠢的单元将不会再出现,极大提高了效率。但是它只支持utf8,如果你的数据库是zhs16gbk字符集,则只能使用笨笨的那个Chinese vgram lexer。如果不做任何设置,Oracle缺省使用basic_lexer这个分析器。
3.测试全文检索
--测试用户为oratext,建立此用户和对应表空间的内容就不写了:
步骤一:授权,ctxsys登陆并对oratext用户授权:
alter user ctxsys identified by oracle account unlock;
create user oratext identified by oracle;
GRANT resource, connect, ctxapp TO oratext;
GRANT execute ON ctxsys.ctx_cls TO oratext;
GRANT execute ON ctxsys.ctx_ddl TO oratext;
GRANT execute ON ctxsys.ctx_doc TO oratext;
GRANT execute ON ctxsys.ctx_output TO oratext;
GRANT execute ON ctxsys.ctx_query TO oratext;
GRANT execute ON ctxsys.ctx_report TO oratext;
GRANT execute ON ctxsys.ctx_thes TO oratext;
GRANT execute ON ctxsys.ctx_ulexer TO oratext;
步骤二:设置词法分析器,使用chinese_vgram_lexer作为分析器:
conn oratext/oracle@service_name
BEGIN --设置词法分析器
ctx_ddl.create_preference ('oratext_lexer', 'chinese_vgram_lexer');
END;
/
--可以通过下面的语句查看系统默认及设置的oracle text参数:
SELECT pre_name, pre_object FROM ctx_preferences;
可以看到我刚刚设置的语法分析器参数oratext_lexer,(默认的有一个MY_LEXER的语法分析器参数)。
步骤三:建立测试表,插入测试数据:
CREATE TABLE textdemo(
id number NOT NULL PRIMARY KEY,
book_author varchar2(20),--作者
publish_time date,--发布日期
title varchar2(400),--标题
book_abstract varchar2(2000),--摘要
path varchar2(200)--路径
);
INSERT INTO textdemo VALUES(1,'宫琦峻',to_date('2008-10-07','yyyy-mm-dd'),' 移动城堡','故事发生在19世纪末的欧洲,善良可爱的苏菲被恶毒的女巫施下魔咒,从18岁的女孩变成90岁的婆婆,孤单无助的她无意中走入镇外的移动城堡,据说它的主人哈尔以吸取女孩的灵魂为乐,但是事情并没有人们传说的那么可怕,性情古怪的哈尔居然收留了苏菲,两个人在四脚的移动城堡中开始了奇妙的共同生活,一段交织了爱与痛、乐与悲的爱情故事在战火中悄悄展开','E:\textsearch\moveingcastle.doc');
INSERT INTO textdemo VALUES(2,'莫贝克曼贝托夫',to_date('2008-10-07','yyyy-mm-dd'),' 子弹转弯','这部由俄罗斯导演提莫贝克曼贝托夫执导的影片自6 月末在北美上映以来,已经在全球取得了超过3亿美元的票房收入。在亚洲上映后也先后拿下日本、韩国等地的票房冠军宝座。虽然不少网友在此之前也相继通过各种渠道接触到本片,但相信影片凭着在大银幕上呈现出的超酷的视听效果,依然能够吸引大量影迷前往影院捧场。','E:\textsearch\catch.pdf');
INSERT INTO textdemo VALUES(3,'袁泉',to_date('2008-10-07','yyyy-mm-dd'),'主演吴彦祖和袁泉现身','电影《如梦》在上海同乐坊拍摄,主演吴彦祖和袁泉现身。由于是深夜拍摄,所以周围并没有过多的fans注意到,给了剧组一个很清净的拍摄环境,站在街头的袁泉低着头,在寒冷的夜里看上去还真有些像女鬼,令人毛骨悚然。','E:\textsearch\dream.txt');
commit;
--步骤四:在book_abstract字段建立索引使用刚刚设置的ORATEXT_LEXER :chinese_vgram_lexer作为分析器。
CREATE INDEX demo_abstract ON textdemo(book_abstract) indextype IS ctxsys.context parameters('lexer ORATEXT_LEXER');
--之后如上所述多出很多dr$开头的表和索引,系统会创建四个相关的表:
DR$DEMO_ABSTRACT$I(分词后的TOKEN表)\
DR$DEMO_ABSTRACT$K\
DR$DEMO_ABSTRACT$N \
DR$DEMO_ABSTRACT$R
--下面的语句可以查看索引创建过程中是否发生了错误:
SELECT * FROM ctx_USER_index_errors
附:对于建立索引的类型(例如ctxsys.context),包括四种:context,ctxcat,ctxrule,ctxxpath。
CONTEXT用于对含有大量连续文本数据进行检索。支持word、html、xml、text等很多数据格式。支持范围(range)分区,支持并行创建索引(Parallel indexing)的索引类型。
支持类型:VARCHAR2, CLOB, BLOB, CHAR, BFILE, XMLType, and URIType.DML。操作后,需要CTX_DDL.SYNC_INDEX手工同步索引如果有查询包含多个词语,直接用空格隔开(如 oracle itpub)。
查询标识符CONTAINS
CTXCAT适用于混合查询语句(如查询条件包括产品id,价格,描述等)。适合于查询较小的具有一定结构的文本段。具有事务性。DML 操作后,索引会自动进行同步。
操作符:and,or,>,;<, =,between,in
查询标识符CATSEARCH
CTXRULE查询标识符MATCHES。
CTXXPATH(这两个索引没有去更多搜索相关内容)
一般来说我们建立CONTEXT类型的索引(CONTAINS来查询)。
--步骤五:查询测试
--查询或
SELECT score(20),t.* FROM textdemo t WHERE contains(book_abstract,'移动城堡 or 俄罗斯',20)>0;
SELECT score(20),t.* FROM textdemo t WHERE contains(book_abstract,'移动城堡 or 欧洲',20)>0;
--基本查询
SELECT score(20),t.* FROM textdemo t WHERE contains(book_abstract,'移动城堡',20)>0;
--查询包含多个词语and测试通过
SELECT score(20),t.* FROM textdemo t WHERE contains(book_abstract,'移动城堡 and 欧洲',20)>0;
4.对多字段建立全文索引(还在揣摩中)
很多时候需要从多个文本字段中查询满足条件的记录,这时就需要建立针对多个字段的全文索引,例如需要从pmhsubjects(专题表)的 subjectname(专题名称)和briefintro(简介)上进行全文检索,则需要按以下步骤进行操作:
--建立多字段索引的preference,以ctxsys登录,并执行:
BEGIN
ctx_ddl.create_preference('ctx_demo_abstract_title','MULTI_COLUMN_DATASTORE');
END;
/
--建立preference对应的字段值(以ctxsys登录) 对应title path book_abstract三个字段建立索引:
BEGIN
ctx_ddl.set_attribute('ctx_demo_abstract_title ','columns','title,path');
END;
/
--建立全文索引:
create table textdemo1 as SELECT * FROM textdemo;
--ORA-29855:执行ODCIINDEXCREATE例行程序出错
CREATE INDEX demo_abstract_title ON textdemo1(book_abstract) indextype IS ctxsys.context parameters('DATASTORE ctxsys. ctx_demo_ abstract_title lexer ORATEXT_LEXER');
--测试
SELECT score(20),t.* FROM textdemo1 t WHERE contains(book_abstract,'移动城堡 or 俄罗斯',20)>0;
--5.对大字段进行检索测试
CREATE TABLE mytable(
id number PRIMARY KEY,
docs clob);
INSERT INTO mytable VALUES(111555,'this text will be indexed');
INSERT INTO mytable VALUES(111556,'this is a direct_datastore example');
Commit;
CREATE INDEX myindex ON mytable(docs) indextype IS ctxsys.context parameters ('datastore ctxsys.default_datastore');
SELECT * FROM mytable WHERE contains(docs, 'text') > 0;
-------------------------------------------------------------------------------------------------------------------------------------------------------
oracle 全文索引
--模糊查询的两种方式
select * from dj_nsrxx where contains(nsrmc,'和谦亨') > 0;
select * from dj_nsrxx where nsrmc like '%康仁如快餐店%';
--建立分词器
BEGIN
ctx_ddl.create_preference ('my_chinese_vgram_lexer', 'chinese_vgram_lexer');
END;
--建立索引
CREATE INDEX IDX_DJ_NSRXX_NSRMC_QW ON dj_nsrxx(nsrmc) indextype is ctxsys.context parameters('lexer my_chinese_vgram_lexer');
--使用实时同步(DML提交时同步全文索引)
CREATE INDEX IDX_DJ_NSRXX_NSRMC_QW ON dj_nsrxx(nsrmc) indextype is ctxsys.context PARAMETERS ('LEXER my_chinese_vgram_lexer SYNC (ON COMMIT)');
--刷新索引
BEGIN
ctx_ddl.sync_index('IDX_DJ_NSRXX_NSRMC_QW');
end;
/
--定时job刷新索引,未测试
BEGIN
DBMS_JOB.SUBMIT(:jobno,ctx_ddl.sync_index('IDX_DJ_NSRXX_NSRMC_QW'),SYSDATE, SYSDATE + (1/24/4));
commit;
END;
/
--查询索引产生的表
select * from dba_tables where table_name like '%IDX_DJ_NSRXX_NSRMC_QW%'
select count(*) from DR$IDX_DJ_NSRXX_NSRMC_QW$I
--删除索引
drop index IDX_DJ_NSRXX_NSRMC_QW;
--删除分词器
begin
ctx_ddl.drop_preference('my_chinese_vgram_lexer');
end;
--查询索引
select * from dba_indexes;
item chinese_vgram chinese comments
测试数据量 80万 80万
创建时间 37s 370S
刷新时间(0条跟新) 0s 0s 增量刷新,刷新速度较快
刷新时间(3条跟新) 0.031S 0.031S
索引条数 123万 68万
==注:
如果一个列没有使用全文索引,而使用了contains的话会报错 column is not indexed
select * from dj_nsrxx where contains(nsrmc,’易家联快餐店’) > 0;==
以下为网上摘取的内容,简单的描述了oracle全文索引的原理
Oracle实现全文检索。
创建即通过Oracle专利的词法分析器(lexer),将文章中所有的表意单元(Oracle称为term)找出来,记录在一组以dr$开头的表中,同时记下该term出现的位置、次数、hash值等信息。
检索
检索时,Oracle从这组表中查找相应的term,并计算其出现频率,根据某个算法来计算每个文档的得分(score),即所谓的‘匹配率’。而lexer则是该机制的核心,它决定了全文检索的效率。
Oracle针对不同的语言提供了不同的lexer,而我们通常能用到其中的三个:
basic_lexer:针对英语。它能根据空格和标点来将英语单词从句子中分离,还能自动将一些出现频率过高已经失去检索意义的单词作为‘垃圾’处理,如if , is等,具有较高的处理效率。但该lexer应用于汉语则有很多问题,由于它只认空格和标点,而汉语的一句话中通常不会有空格,因此,它会把整句话作为一个term,事实上失去检索能力。以‘中国人民站起来了’这句话为例,basic_lexer分析的结果只有一个term ,就是‘中国人民站起来了’。此时若检索‘中国’,将检索不到内容。
chinese_vgram_lexer:专门的汉语分析器,支持所有汉字字符集(ZHS16CGB231280ZHS16GBKZHT32EUCZHT16BIG5ZHT32TRISZHT16MSWIN950ZHT16HKSCSUTF8)。该分析器按字为单元来分析汉语句子。‘中国人民站起来了’这句话,会被它分析成如下几个term: ‘中’,‘中国’,‘国人’,‘人民’,‘民站’,‘站起’,起来’,‘来了’,‘了’。可以看出,这种分析方法,实现算法很简单,并且能实现‘一网打尽’,但效率则是差强人意。
chinese_lexer:这是一个新的汉语分析器,只支持utf8字符集。上面已经看到,chinese vgram lexer这个分析器由于不认识常用的汉语词汇,因此分析的单元非常机械,像上面的‘民站’,‘站起’在汉语中根本不会单独出现,因此这种term是没有意义的,反而影响效率。chinese_lexer的最大改进就是该分析器能认识大部分常用汉语词汇,因此能更有效率地分析句子,像以上两个愚蠢的单元将不会再出现,极大提高了效率。但是它只支持utf8,如果你的数据库是zhs16gbk字符集,则只能使用笨笨的那个Chinese vgram lexer.
==如果不做任何设置,Oracle缺省使用basic_lexer这个分析器。要指定使用哪一个lexer,可以这样操作:==
BEGIN
ctx_ddl.create_preference ('my_lexer', 'chinese_vgram_lexer');
END;
其中my_lexer是分析器名。
在索引建好后,我们可以在该用户下查到Oracle自动产生了以下几个表:(假设索引名为myindex):
DRmyindexI、DRmyindexK、DRmyindexR、DRmyindexN其中以I表最重要,可以查询一下该表,看看有什么内容:
SELECT token_text, token_count FROM drirsk1I WHERE ROWNUM <= 20;
这里就不列出查询接过了。可以看到,该表中保存的其实就是Oracle 分析你的文档后,生成的term记录在这里,包括term出现的位置、次数、hash值等。当文档的内容改变后,可以想见这个I表的内容也应该相应改变,才能保证Oracle在做全文检索时正确检索到内容(因为所谓全文检索,其实核心就是查询这个表)。这就用到sync(同步) 和 optimize(优化)了。
同步(sync): 将新的term 保存到I表;
优化(optimize): 清除I表的垃圾,主要是将已经被删除的term从I表删除。
当基表中的被索引文档发生insert、update、delete操作的时候,基表的改变并不能马上影响到索引上直到同步索引。可以查询视图 CTX_USER_PENDING查看相应的改动。例如:
SELECT pnd_index_name, pnd_rowid,
TO_CHAR (pnd_timestamp, 'dd-mon-yyyy hh24:mi:ss') timestamp
FROM ctx_user_pending;
该语句的输出类似如下:
PND_INDEX_NAME PND_ROWID TIMESTAMP
MYINDEX AAADXnAABAAAS3SAAC 06-oct-1999 15:56:50
--------------------------------------------------------------------------------
同步和优化方法:
可以使用Oracle提供的ctx_ddl包同步和优化索引
一. 对于CTXCAT类型的索引来说, 当对基表进行DML操作的时候,Oracle自动维护索引。对文档的改变马上反映到索引中。CTXCAT是事务形的索引。
索引的同步
在对基表插入,修改,删除之后同步索引。推荐使用sync同步索引。 语法:
ctx_ddl.sync_index(
idx_name IN VARCHAR2 DEFAULT NULL
memory IN VARCHAR2 DEFAULT NULL,
part_name IN VARCHAR2 DEFAULT NULL
parallel_degree IN NUMBER DEFAULT 1);
idx_name 索引名称
memory 指定同步索引需要的内存。默认是系统参数DEFAULT_INDEX_MEMORY 。
指定一个大的内存时候可以加快索引效率和查询速度,且索引有较少的碎片
part_name 同步哪个分区索引。
parallel_degree 并行同步索引。设置并行度。
例如:
同步索引myindex:Exec ctx_ddl.sync_index (‘myindex’);
实施建议:建议通过oracle的job对索引进行同步
instr函数在Oracle/PLSQL中是返回要截取的字符串在源字符串中的位置。instr是一个非常好用的字符串处理函数,几乎所有的字符串分隔都用到此函数。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Oracle全文索引
原创 Oracle 作者:lhrbest 时间:2017-05-13 19:22:43 953 0
Oracle全文索引
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
一、设置词法分析器
Oracle实现全文检索,其机制其实很简单。即通过Oracle专利的词法分析器(lexer),将文章中所有的表意单元(Oracle 称为 term)找出来,记录在一组 以dr$开头的表中,同时记下该term出现的位置、次数、hash 值等信息。检索时,Oracle 从这组表中查找相应的term,并计算其出现频率,根据某个算法来计算每个文档的得分(score),即所谓的‘匹配率’。而lexer则是该机制的核心,它决定了全文检索的效率。Oracle 针对不同的语言提供了不同的 lexer, 而我们通常能用到其中的三个:
n basic_lexer: 针对英语。它能根据空格和标点来将英语单词从句子中分离,还能自动将一些出现频率过高已经失去检索意义的单词作为‘垃圾’处理,如if , is 等,具有较高的处理效率。但该lexer应用于汉语则有很多问题,由于它只认空格和标点,而汉语的一句话中通常不会有空格,因此,它会把整句话作为一个term,事实上失去检索能力。以‘中国人民站起来了’这句话为例,basic_lexer 分析的结果只有一个term ,就是‘中国人民站起来了’。此时若检索‘中国’,将检索不到内容。
n chinese_vgram_lexer: 专门的汉语分析器,支持所有汉字字符集(ZHS16CGB231280 ZHS16GBK ZHT32EUC ZHT16BIG5 ZHT32TRIS ZHT16MSWIN950 ZHT16HKSCS UTF8 )。该分析器按字为单元来分析汉语句子。‘中国人民站起来了’这句话,会被它分析成如下几个term: ‘中’,‘中国’,‘国人’,‘人民’,‘民站’,‘站起’,起来’,‘来了’,‘了’。可以看出,这种分析方法,实现算法很简单,并且能实现‘一网打尽’,但效率则是差强人意。
n chinese_lexer: 这是一个新的汉语分析器,只支持utf8字符集。上面已经看到,chinese vgram lexer这个分析器由于不认识常用的汉语词汇,因此分析的单元非常机械,像上面的‘民站’,‘站起’在汉语中根本不会单独出现,因此这种term是没有意义的,反而影响效率。chinese_lexer的最大改进就是该分析器 能认识大部分常用汉语词汇,因此能更有效率地分析句子,像以上两个愚蠢的单元将不会再出现,极大 提高了效率。但是它只支持 utf8, 如果你的数据库是zhs16gbk字符集,则只能使用笨笨的那个Chinese vgram lexer.
如果不做任何设置,Oracle 缺省使用basic_lexer这个分析器。要指定使用哪一个lexer, 可以这样操作:
BEGIN
ctx_ddl.create_preference ('my_lexer', 'chinese_vgram_lexer');
END;
/
其中my_lexer是分析器名。
二、建立全文索引
在建立intermedia索引时,指明所用的lexer:
CREATE INDEX myindex ON mytable(mycolumn) indextype is ctxsys.context parameters('lexer my_lexer');
※个人体会:全文索引建立后,用pl/sql developer工具view table,在index这一栏是看不到索引信息的。
而本人在删除全文索引时遇到过一下报错:
SQL> drop index searchkeytbl_key;
drop index searchkeytbl_key
ORA-29868: cannot issue DDL on a domain index marked as LOADING
解决方法:
ORA-29868: cannot issue DDL on a domain index marked as LOADING
说明:在创建索引的时候断开、重启等导致索引中断没有执行成功,之后再drop或者rebuild等操作的时候都会报此错误
解决:只能drop index ind_name force强行删除,然后再重建
三、索引同步维护
用以下的两个job来完成(该job要建在和表同一个用户下) :
VARIABLE jobno number;
BEGIN
DBMS_JOB.SUBMIT(:jobno,'ctx_ddl.sync_index(''index_name'');',
SYSDATE, 'SYSDATE + (1/24/4)');
commit;
END; //同步
VARIABLE jobno number;
BEGIN
DBMS_JOB.SUBMIT(:jobno,'ctx_ddl.optimize_index(''myindex'',''FULL'');',
SYSDATE, 'SYSDATE + 1');
commit; //优化
建完后手动运行下:
exec dbms_job.run(jobno);
※个人体会:运行job可能会有问题,此时可以单独运行索引,尝试一下
exec ctx_ddl.sync_index('index_name');
如果单独运行没有问题,则检查job是否写错或者当前操作的oracle数据库用户有无运行存储过程的权限
SQL> exec dbms_job.run(190);
begin dbms_job.run(190); end;
ORA-12011: execution of 1 jobs failed
ORA-06512: at "SYS.DBMS_IJOB", line 406
ORA-06512: at "SYS.DBMS_JOB", line 272
ORA-06512: at line 1
以上报错就是用户没有运行任何存储过程造成的,此时需要对用户加上这个权限:
SQL> grant execute any procedure to oracle_username;
再看一下job的情况
select * from user_jobs;
四、测试
关联查询: select * from table_name where contains (column_name,'keyword') >0;
SQL> select * from searchkeytbl where type='城市' and contains (key,'杨浦') >0;
USERNAME TYPE KEY
-------------------- ---------------------------------------- --------------------------------------------------------------------------------
mujian80 城市 上海市杨浦区
五、问题
加全文索引遇到的问题(不断更新)
SQL> create index gh_ghname_idx on gh(ghname) indextype is ctxsys.context parameters('lexer gh_ghname_lexer');
create index gh_ghname_idx on gh(ghname) indextype is ctxsys.context parameters('lexer gh_ghname_lexer')
ORA-24795: Illegal COMMIT attempt made
ORA-29855: error occurred in the execution of ODCIINDEXCREATE routine
ORA-20000: Oracle Text error:
DRG-50857: oracle error in drvddl.IndexCreate
ORA-20000: Oracle Text error:
DRG-50857: oracle error in drvdml.MaintainKTab
ORA-24795: Illegal COMMIT attempt made
ORA-06512: at "CTXSYS.DRUE", line 160
ORA-06512: at "CTXSYS.TEXTINDEXMETHODS", line 364
To avoid the error, please use one of the following solutions
1. Don't use a 32k-blocksized tablespace to store the internal index objects
- or -
2. Download Patch 5596325 from Metalink and apply it as described in the README file.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
通过案例学调优之--Oracle 全文索引
全文检索(oracle text)
Oracle Text使Oracle9i具备了强大的文本检索能力和智能化的文本管理能力,Oracle Text 是 Oracle9i 采用的新名称,在 oracle8/8i 中被称为 oracle intermedia text,oracle8 以前是 oracle context cartridge。Oracle Text 的索引和查找功能并不局限于存储在数据库中的数据。 它可以对存储于文件系统中的文档进行检索和查找,并可检索超过 150 种文档类型,包括 Microsoft Word、PDF和XML。Oracle Text查找功能包括模糊查找、词干查找(搜索mice 和查找 mouse)、通配符、相近性等查找方式,以及结果分级和关键词突出显示等。你甚至 可以增加一个词典,以查找搭配词,并找出包含该搭配词的文档。
Oracle text 需要为可检索的数据项建立索引,用户才能够通过搜索查找内容,索引进 程是根据管道建模的,在这个管道中,数据经过一系列的转换后,将其关键字会添加到索引 中。该索引进程分为多个阶段,如下图
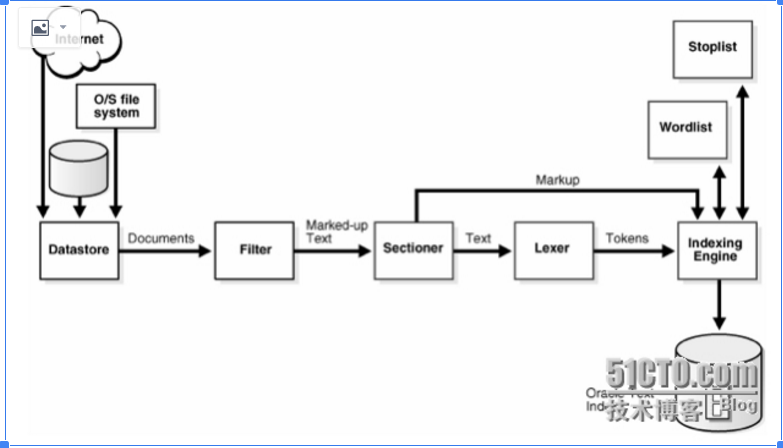
1.数据检索(Datastore):只是将数据从数据存储(例如 web 页面、数据库大型对象或本 地文件系统)中取出,然后作为数据流传送到下一个阶段。
2. 过滤(Filter):过滤器负责将各种文件格式的数据转换为纯文本格式,索引管道中的其 他组件只能处理纯文本数据,不能识别 Ms word 或 excel 等文件格式。
3. 分段(Sectioner):分段器添加关于原始数据项结构的元数据。
4. 词法分析(Lexer):根据数据项的语言将字符流分为几个字词。 5. 索引(Index):最后一个阶段将关键字添加到实际索引中。
全文检索和普通检索的区别
不使用Oracle text功能,当然也有很多方法可以在Oracle数据库中搜索文本,比如INSTR函数和LIKE操作:
1 、SELECT *FROM mytext WHERE INSTR (thetext, 'Oracle') > 0;
2 、SELECT * FROM mytext WHERE thetext LIKE '%Oracle%';
有很多时候,使用instr和like是很理想的, 特别是搜索仅跨越很小的表的时候。然而通过这些文本定位的方法将导致全表扫描,对资源来说消耗比较昂贵,而且实现的搜索功能也非常有限,因此对海量的文本数据进行搜索时,建议使用oralce提供的全文检索功能。
附:这里顺带记录一下INSTR和LIKE:
Oracle中,可以使用 Instr 函数对某个字符串进行判断,判断其是否含有指定的字符。其语法为:Instr(string, substring, position, occurrence)。
string:代表源字符串(写入字段则表示此字段的内容)。
substring:代表想从源字符串中查找的子串。
position:代表查找的开始位置,该参数可选的,默认为1。
occurrence:代表想从源字符中查找出第几次出现的substring,该参数也是可选的,默认为1。
position 的值为负数,那么代表从右往左进行查找。
instr和like的性能比较
其实从效率角度来看,谁能用到索引,谁的查询速度就会快。
like有时可以用到索引,例如:name like ‘李%’,而当下面的情况时索引会失效:name like ‘%李’。所以一般我们查找中文类似于‘%字符%’时,索引都会失效。与其他数据库不同的是,oracle支持函数索引。例如在name字段上建个instr索引,查询速度就比较快了,这也是为什么instr会比like效率高的原因。
注:instr(title,’手册’)>0 相当于like‘%手册%’
instr(title,’手册’)=0 相当于not like‘%手册%’
Oracle Text 索引原理
Oracle text 索引将文本中所有的字符转化成记号(token),如 www.taobao.com 会转化 成 www,taobao,com 这样的记号。
Oracle10g 里面支持四种类型的索引:
context、ctxcat、ctxrule、ctxxpath
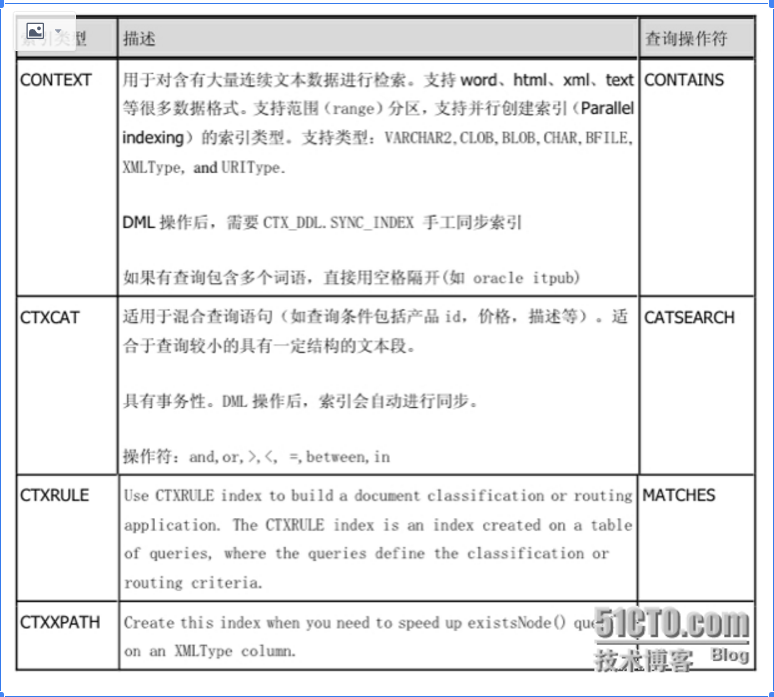
CONTEXT
用于对含有大量连续文本数据进行检索。支持 word、html、xml、text 等很多数据格式。支持范围(range)分区,支持并行创建索引(Parallel indexing)的索引类型。支持类型:VARCHAR2, CLOB, BLOB, CHAR, BFILE, XMLType, and URIType.
DML 操作后,需要 CTX_DDL.SYNC_INDEX 手工同步索引 如果有查询包含多个词语,直接用空格隔开(如 oracle itpub)
案例分析:
设置全文检索
步骤步骤一:检查和设置数据库角色
首先检查数据库中是否有CTXSYS用户和CTXAPP脚色。如果没有这个用户和角色,意味着你的数据库创建时未安装intermedia功能(10G默认安装都有此用户和角色)。你必须修改数据库以安装这项功能。默认安装情况下,ctxsys用户是被锁定的,因此要先启用ctxsys的用户。
11:53:13 SYS@ prod >select username,account_status from dba_users where username like 'CTX%';
USERNAME ACCOUNT_STATUS
------------------------------ --------------------------------
CTXSYS EXPIRED & LOCKED
11:54:17 SYS@ prod >alter user ctxsys identified by oracle account unlock;
User altered.
11:55:07 SYS@ prod >select username,account_status from dba_users where username like 'CTX%';
USERNAME ACCOUNT_STATUS
------------------------------ --------------------------------
CTXSYS OPEN
12:00:13 SYS@ prod >select role from dba_roles
12:00:23 2 where role like 'CTX%';
ROLE
------------------------------
CTXAPP
步骤二:赋权
在ctxsys用户下,授予测试用户scott以下权限:
[oracle@RH6 ~]$ cat t.sql
GRANT resource, CONNECT, ctxapp TO scott;
GRANT EXECUTE ON ctxsys.ctx_cls TO scott;
GRANT EXECUTE ON ctxsys.ctx_ddl TO scott;
GRANT EXECUTE ON ctxsys.ctx_doc TO scott;
GRANT EXECUTE ON ctxsys.ctx_output TO scott;
GRANT EXECUTE ON ctxsys.ctx_query TO scott;
GRANT EXECUTE ON ctxsys.ctx_report TO scott;
GRANT EXECUTE ON ctxsys.ctx_thes TO scott;
GRANT EXECUTE ON ctxsys.ctx_ulexer TO scott;
11:58:04 SYS@ prod >@/home/oracle/t.sql
Grant succeeded.
Elapsed: 00:00:00.15
Grant succeeded.
Elapsed: 00:00:00.21
Grant succeeded.
Elapsed: 00:00:00.09
Grant succeeded.
Elapsed: 00:00:00.09
Grant succeeded.
Elapsed: 00:00:00.13
Grant succeeded.
Elapsed: 00:00:00.07
Grant succeeded.
Elapsed: 00:00:00.09
Grant succeeded.
Elapsed: 00:00:00.10
Grant succeeded.
Elapsed: 00:00:00.07
步骤三:设置词法分析器(lexer)
Oracle实现全文检索,其机制其实很简单。即通过Oracle专利的词法分析器(lexer),将文章中所有的表意单元(Oracle 称为 term)找出来,记录在一组以dr$开头的表中,同时记下该term出现的位置、次数、hash值等信息。检索时,Oracle从这组表中查找相应的term,并计算其出现频率,根据某个算法来计算每个文档的得分(score),即所谓的‘匹配率’。而lexer则是该机制的核心,它决定了全文检索的效率。Oracle针对不同的语言提供了不同的lexer,而我们通常能用到其中的三个:
[cpp] view plain copy
print?
basic_lexer:
针对英语。它能根据空格和标点来将英语单词从句子中分离,还能自动将一些出现频率过高已经失去检索意义的单词作为‘垃圾’处理,如if,is等,具有较高的处理效率。但该lexer应用于汉语则有很多问题,由于它只认空格和标点,而汉语的一句话中通常不会有空格,因此,它会把整句话作为一个term,事实上失去检索能力。以‘中国人民站起来了’这句话为例,basic_lexer分析的结果只有一个term,就是‘中国人民站起来了’。此时若检索‘中国’,将检索不到内容。
chinese_vgram_lexer:
专门的汉语分析器,支持所有汉字字符集(ZHS16CGB231280 ZHS16GBK ZHT32EUC ZHT16BIG5 ZHT32TRIS ZHT16MSWIN950 ZHT16HKSCS UTF8 )。该分析器按字为单元来分析汉语句子。‘中国人民站起来了’这句话,会被它分析成如下几个term:‘中’,‘中国’,‘国人’,‘人民’,‘民站’,‘站起’,起来’,‘来了’,‘了’。可以看出,这种分析方法,实现算法很简单,并且能实现‘一网打尽’,但效率则是差强人意。
chinese_lexer:
这是一个新的汉语分析器,只支持utf8字符集。上面已经看到,chinese vgram lexer这个分析器由于不认识常用的汉语词汇,因此分析的单元非常机械,像上面的‘民站’,‘站起’在汉语中根本不会单独出现,因此这种term是没有意义的,反而影响效率。chinese_lexer的最大改进就是该分析器能认识大部分常用汉语词汇,因此能更有效率地分析句子,像以上两个愚蠢的单元将不会再出现,极大提高了效率。但是它只支持utf8,如果你的数据库是zhs16gbk字符集,则只能使用笨笨的那个Chinese vgram lexer。如果不做任何设置,Oracle缺省使用basic_lexer这个分析器。
[java] view plain copy
print?
12:05:01 SYS@ prod >select userenv('language') from dual;
USERENV('LANGUAGE')
----------------------------------------------------
AMERICAN_AMERICA.ZHS16GBK
12:08:05 SCOTT@ prod >desc ctx_ddl
PROCEDURE CREATE_PREFERENCE
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
PREFERENCE_NAME VARCHAR2 IN
OBJECT_NAME VARCHAR2 IN
12:12:25 SCOTT@ prod >EXEC ctx_ddl.create_preference ('my_lexer', 'chinese_vgram_lexer');
PL/SQL procedure successfully completed.
创建表
12:13:15 SCOTT@ prod >CREATE TABLE textdemo(
12:15:47 2 id NUMBER NOT NULL PRIMARY KEY,
12:15:47 3 book_author varchar2(100),--作者
12:15:47 4 publish_time DATE,--发布日期
12:15:47 5 title varchar2(400),--标题
12:15:47 6 book_abstract varchar2(2000),--摘要
12:15:47 7 path varchar2(200)--路径
12:15:47 8 );
Table created.
插入数据
14:53:20 SCOTT@ prod >insert into textdemo values (10,'luyao',sysdate,'pingfan de world','zhen shi de gushi','/home/1.txt');
1 row created.
14:54:32 SCOTT@ prod >commit;
步骤四:在book_abstract字段建立索引使用刚刚设置的ORATEXT_LEXER :chinese_vgram_lexer作为分析器。
12:16:15 SCOTT@ prod >CREATE INDEX demo_abstract ON textdemo(book_abstract) indextype IS ctxsys.context parameters('lexer my_LEXER');
之后如上所述多出很多dr$开头的表和索引,系统会创建四个相关的表:
DR$DEMO_ABSTRACT$I(分词后的TOKEN表)
DR$DEMO_ABSTRACT$K
DR$DEMO_ABSTRACT$N
DR$DEMO_ABSTRACT$R
14:56:16 SCOTT@ prod >select * from tab;
TNAME TABTYPE CLUSTERID
------------------------------ ------- ----------
BONUS TABLE
DEPT TABLE
DR$DEMO_ABSTRACT$I TABLE
DR$DEMO_ABSTRACT$K TABLE
DR$DEMO_ABSTRACT$N TABLE
DR$DEMO_ABSTRACT$R TABLE
EMP TABLE
SALGRADE TABLE
TEXTDEMO TABLE
9 rows selected.
14:56:36 SCOTT@ prod >desc DR$DEMO_ABSTRACT$I
Name Null? Type
----------------------------------------------------------------- -------- --------------------------------------------
TOKEN_TEXT NOT NULL VARCHAR2(64)
TOKEN_TYPE NOT NULL NUMBER(3)
TOKEN_FIRST NOT NULL NUMBER(10)
TOKEN_LAST NOT NULL NUMBER(10)
TOKEN_COUNT NOT NULL NUMBER(10)
TOKEN_INFO BLOB
14:57:45 SCOTT@ prod >desc DR$DEMO_ABSTRACT$K
Name Null? Type
----------------------------------------------------------------- -------- --------------------------------------------
DOCID NUMBER(38)
TEXTKEY NOT NULL ROWID
14:57:57 SCOTT@ prod >desc DR$DEMO_ABSTRACT$N
Name Null? Type
----------------------------------------------------------------- -------- --------------------------------------------
NLT_DOCID NOT NULL NUMBER(38)
NLT_MARK NOT NULL CHAR(1)
14:58:11 SCOTT@ prod >desc DR$DEMO_ABSTRACT$R
Name Null? Type
----------------------------------------------------------------- -------- --------------------------------------------
ROW_NO NUMBER(3)
DATA BLOB
14:58:26 SCOTT@ prod >select index_name,index_type,table_name from user_indexes;
INDEX_NAME INDEX_TYPE TABLE_NAME
------------------------------ --------------------------- ------------------------------
DEMO_ABSTRACT DOMAIN TEXTDEMO
SYS_C0013418 NORMAL TEXTDEMO
PK_EMP NORMAL EMP
SYS_IL0000076525C00002$$ LOB DR$DEMO_ABSTRACT$R
SYS_IOT_TOP_76528 IOT - TOP DR$DEMO_ABSTRACT$N
SYS_IOT_TOP_76523 IOT - TOP DR$DEMO_ABSTRACT$K
SYS_IL0000076520C00006$$ LOB DR$DEMO_ABSTRACT$I
DR$DEMO_ABSTRACT$X NORMAL DR$DEMO_ABSTRACT$I
PK_DEPT NORMAL DEPT
9 rows selected.
下面的语句可以查看索引创建过程中是否发生了错误:
[cpp] view plain copy
print?
SELECT * FROM ctx_USER_index_errors
附:对于建立索引的类型(例如ctxsys.context),包括四种:context,ctxcat,ctxrule,ctxxpath。
CONTEXT用于对含有大量连续文本数据进行检索。支持word、html、xml、text等很多数据格式。支持范围(range)分区,支持并行创建索引(Parallel indexing)的索引类型。
支持类型:VARCHAR2, CLOB, BLOB, CHAR, BFILE, XMLType, and URIType.DML。操作后,需要CTX_DDL.SYNC_INDEX手工同步索引如果有查询包含多个词语,直接用空格隔开(如 oracle itpub)。
查询标识符CONTAINS
CTXCAT适用于混合查询语句(如查询条件包括产品id,价格,描述等)。适合于查询较小的具有一定结构的文本段。具有事务性。DML 操作后,索引会自动进行同步。
操作符:and,or,>,;<, =,between,in
查询标识符CATSEARCH
CTXRULE查询标识符MATCHES。
CTXXPATH(这两个索引没有去更多搜索相关内容)
一般来说我们建立CONTEXT类型的索引(CONTAINS来查询)。
步骤五:查询测试
查看执行计划
15:04:36 SCOTT@ prod >r
1* select * from textdemo where contains(book_abstract,'gushi')>0
Elapsed: 00:00:00.02
Execution Plan
----------------------------------------------------------
Plan hash value: 2570915478
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1392 | 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEXTDEMO | 1 | 1392 | 4 (0)| 00:00:01 |
|* 2 | DOMAIN INDEX | DEMO_ABSTRACT | | | 4 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("CTXSYS"."CONTAINS"("BOOK_ABSTRACT",'gushi')>0)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
29 recursive calls
0 db block gets
33 consistent gets
0 physical reads
0 redo size
796 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
15:04:37 SCOTT@ prod >
通过sql trace查看详细计划(部分内容)
SQL ID: 2rsr1z6zkp24p
Plan Hash: 2570915478
select *
from
textdemo where contains(book_abstract,:"SYS_B_0")>:"SYS_B_1"
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.01 0.01 0 250 0 0
Fetch 2 0.00 0.00 0 2 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.01 0.01 0 252 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 101
Rows Row Source Operation
------- ---------------------------------------------------
1 TABLE ACCESS BY INDEX ROWID TEXTDEMO (cr=12 pr=0 pw=0 time=0 us cost=4 size=1392 card=1)
1 DOMAIN INDEX DEMO_ABSTRACT (cr=11 pr=0 pw=0 time=0 us cost=4 size=0 card=0)
declare
cost sys.ODCICost := sys.ODCICost(NULL, NULL, NULL, NULL);
arg0 VARCHAR2(1) := null;
begin
:1 := "CTXSYS"."TEXTOPTSTATS".ODCIStatsFunctionCost(
sys.ODCIFuncInfo('CTXSYS',
'CTX_CONTAINS',
'TEXTCONTAINS',
2),
cost,
sys.ODCIARGDESCLIST(sys.ODCIARGDESC(2, 'TEXTDEMO', 'SCOTT', '"BOOK_ABSTRACT"', NULL, NULL, NULL), sys.ODCIARG
DESC(1, NULL, NULL, NULL, NULL, NULL, NULL))
, arg0, :5,
sys.ODCIENV(:6,:7,:8,:9));
if cost.CPUCost IS NULL then
:2 := -1.0;
else
:2 := cost.CPUCost;
end if;
if cost.IOCost IS NULL then
:3 := -1.0;
else
:3 := cost.IOCost;
end if;
if cost.NetworkCost IS NULL then
:4 := -1.0;
else
:4 := cost.NetworkCost;
end if;
exception
when others then
raise;
end;
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.00 0.00 0 0 0 0
Execute 2 0.00 0.00 0 18 0 2
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.00 0 18 0 2
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 101 (recursive depth: 1)
全文索引和DML操作
Insert 操作:
15:19:21 SCOTT@ prod >insert into textdemo values (20,'huoda',sysdate,'musilin de zangli','meili de rensheng','/home/2.txt');
1 row created.
15:20:10 SCOTT@ prod >commit;
15:21:35 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo where BOOK_ABSTRACT like '%rensheng%'
ID BOOK_ABSTRACT
---------- --------------------------------------------------
20 meili de rensheng
15:23:12 SCOTT@ prod >set autotrace on
15:23:38 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo where contains(BOOK_ABSTRACT,'rensheng')>0
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 2570915478
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1027 | 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEXTDEMO | 1 | 1027 | 4 (0)| 00:00:01 |
|* 2 | DOMAIN INDEX | DEMO_ABSTRACT | | | 4 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("CTXSYS"."CONTAINS"("BOOK_ABSTRACT",'rensheng')>0)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
23 recursive calls
0 db block gets
33 consistent gets
0 physical reads
0 redo size
349 bytes sent via SQL*Net to client
404 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
15:26:40 SYS@ prod >select * from ctxsys.dr$pending;
PND_CID PND_PID PND_ROWID PND_TIMES P
---------- ---------- ------------------ --------- -
1082 0 AAASrlAAEAAAAI1AAB 21-NOV-14 N
15:26:26 SCOTT@ prod >alter index demo_abstract rebuild parameters('sync');
Index altered.
15:30:10 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo where contains(BOOK_ABSTRACT,'rensheng')>0;
ID BOOK_ABSTRACT
---------- --------------------------------------------------
20 meili de rensheng
在做Insert操作时,Oracle会把一条信息放入到CTXSYS.DR$PENDING表里,必须手工进行同步才能更新全文索引。
Delete 操作:
15:30:37 SCOTT@ prod >delete from textdemo where id=20;
1 row deleted.
15:33:06 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo;
ID BOOK_ABSTRACT
---------- --------------------------------------------------
10 zhen shi de gushi
15:33:39 SCOTT@ prod >rollback;
Rollback complete.
15:33:50 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo;
ID BOOK_ABSTRACT
---------- --------------------------------------------------
10 zhen shi de gushi
20 meili de rensheng
Delete 操作后,索引会立刻更新。
Update 操作:
15:38:14 SCOTT@ prod >update textdemo set BOOK_ABSTRACT='meili de gushi' where id=20;
1 row updated.
15:39:48 SYS@ prod >select * from ctxsys.dr$delete;
no rows selected
15:39:59 SYS@ prod >select * from ctxsys.dr$pending;
no rows selected
15:43:03 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo where contains(BOOK_ABSTRACT,'gushi')>0;
ID BOOK_ABSTRACT
---------- --------------------------------------------------
10 zhen shi de gushi
15:43:14 SCOTT@ prod >alter index demo_abstract rebuild parameters('sync');
Index altered.
15:43:39 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo where contains(BOOK_ABSTRACT,'gushi')>0;
ID BOOK_ABSTRACT
---------- --------------------------------------------------
10 zhen shi de gushi
20 meili de gushi
对于update操作,应该是包含了Delete和Insert的操作,需要手工同步后才能更新索引。
对多字段建立全文索引
很多时候需要从多个文本字段中查询满足条件的记录,这时就需要建立针对多个字段的全文索引,例如需要从pmhsubjects(专题表)的 subjectname(专题名称)和briefintro(简介)上进行全文检索,则需要按以下步骤进行操作:
建立多字段索引的preference,以ctxsys登录,并执行:
BEGIN
ctx_ddl.create_preference('ctx_demo_abstract_title','MULTI_COLUMN_DATASTORE');
END;
建立preference对应的字段值(以ctxsys登录) 对应title path book_abstract三个字段建立索引:
BEGIN
ctx_ddl.set_attribute('ctx_demo_abstract_title ','columns','title,path');
END;
建立全文索引:
CREATE INDEX demo_abstract_title ON textdemo(book_abstract) indextype IS ctxsys.context parameters(' DATASTORE ctxsys. ctx_demo_ abstract_title lexer ORATEXT_LEXER');
commit;
测试
SELECT score(20),t.* FROM textdemo t WHERE contains(book_abstract,'移动城堡 or 俄罗斯',20)>0;
对大字段进行检索测试
CREATE TABLE mytable(id NUMBER PRIMARY KEY, docs CLOB);
INSERT INTO mytable VALUES(111555,'this text will be indexed');
INSERT INTO mytable VALUES(111556,'this is a direct_datastore example');
Commit;
CREATE INDEX myindex ON mytable(docs)
indextype IS ctxsys.context
parameters ('datastore ctxsys.default_datastore');
SELECT * FROM mytable WHERE contains(docs, 'text') > 0;
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
1. 创建数据存储定义(Datastore),使用多列数据存储在多列上创建全文索引
BEGIN
CTX_DDL.CREATE_PREFERENCE('INFOGRID_COM_DATASTORE','MULTI_COLUMN_DATASTORE');
CTX_DDL.SET_ATTRIBUTE('INFOGRID_COM_DATASTORE','columns','NAME,ADDRESS,BUSINESS_ZONE,FAREN,FUND,INTRODUCTION');
END;
2.创建词法分析器(Lexer)
BEGIN
CTX_DDL.CREATE_PREFERENCE('INFOGRID_LEXER', 'CHINESE_LEXER');
END;
3.创建全文索引(索引在DML提交后自动同步更新)
CREATE INDEX INFOGRID_COM_FULL_IDX ON g2b_com(NAME)
INDEXTYPE IS CTXSYS.CONTEXT
PARAMETERS (
'LEXER INFOGRID_LEXER
DATASTORE INFOGRID_COM_DATASTORE
SYNC (ON COMMIT)' --使用实时同步(DML提交时同步全文索引)
)
--手工同步索引(如果使用自动同步,这步可省略)
begin
ctx_ddl.sync_index('INFOGRID_COM_FULL_IDX');
end;
4.使用全文索引查询(按照出现频率排序)
select score(0),t.* from g2b_com t where contains(NAME,'条件一,条件二',0)>0 order by score(0) desc
5.删除全文索引(删除词法分析器,删除数据存储定义,删除索引)
begin
ctx_ddl.drop_preference('INFOGRID_COM_DATASTORE');--删除数据储存定义DataStore
ctx_ddl.drop_preference('INFOGRID_LEXER');--删除词法分析器
end;
drop index INFOGRID_COM_FULL_IDX;--删除索引
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
ORA-06553: PLS-907: cannot load library unit XDB.XDB_FUNCIMPL during export
文档 ID: 785728.1 类型: PROBLEM Modified Date: 25-FEB-2009 状态: REVIEWED
In this Document
Symptoms
Cause
Solution
References
--------------------------------------------------------------------------------
Applies to:Oracle Server Enterprise Edition - Version: 10.1.0.2 to 10.2.0.4
This problem can occur on any platform.
SymptomsExport is failing with below errors:
EXP-00056: ORACLE error 29900 encountered
ORA-29900: operator binding does not exist
ORA-06540: PL/SQL: compilation error
ORA-06553: PLS-907: cannot load library unit XDB.XDB_FUNCIMPL (referenced by XDB.UNDER_PATH)
EXP-00000: Export terminated unsuccessfullyCause
It seems you have some invalid objects in XDB schema or XDB installation is INVALID.
Solution-- check DBA Registry for status of installed components
set pages 1000
column comp_id format A10
column version like comp_id
column comp_name format A35
col status for a15
select comp_id, status, version, comp_name from dba_registry order by 1;
-- check for invalid XDB objects
col owner for a15
col object_name for a30
col object_type for a30
select owner,object_name,object_type from dba_objects
where status != 'VALID'
and wner = 'XDB'
/
You can try to recompile all invalid objects using:
SQL> connect / as sysdba
SQL> @?/rdbms/admin/utlrp.sql
Then check the invalid XDB objects again. If there are no invalid XDB objects then try the export again.
If you still have invalid XDB objects which cannot be compiled then you may have to re-install XDB as described in the note specified below:
Note 243554.1 - How to Deinstall and Reinstall XML Database (XDB)
ReferencesNote 243554.1 - How to Deinstall and Reinstall XML Database (XDB)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号