安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161
一、简述Hadoop平台的起源、发展历史与应用现状。
列举发展过程中重要的事件、主要版本、主要厂商;
1.重要的事件:
HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2003年开始谷歌陆续发表的三篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
——BigTable 数据库:OLTP 联机事务处理 Online Transaction Processing 增删改
OLAP 联机分析处理 Online Analysis Processing 查询
真正的作用:提供了一种可以在超大数据集中进行实时CRUD操作的功能
Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
2004年 Doug Cutting 和 Mike Caferella实现了HDFS和MapReduce的初版
2005年12月 Nutch移植到新框架,Hadoop在20个节点上稳定运行
2006年1月 Doug Cutting加入雅虎
2006年2月 Apache Hadoop项目正式启动,支持MapReduce和HDFS独立发展
2006年2月 雅虎的网格计算团队采用Hadoop
2006年4月 在188个节点上(每个节点10GB)运行排序测试集需要47.9个小时
2006年5月 雅虎建立了300个节点的Hadoop研究集群
2006年5月 在500个节点上运行排序测试集需要42个小时(硬件比4月份的更好)
2006年11月 研究集群增加到600个节点
2006年12月 排序测试集在20个节点运行了1.8个小时,100个节点运行了3.3个小时,500个节点上运行了5.2个小时,900个节点上运行7.8个小时
2007年1月 研究集群增加到900个节点
2007年4月 研究集群增加到两个集群1000个节点
2008年4月 在900个节点上运行1TB排序测试集仅需209秒,成为全球最快
2008年10月 研究集群每天加载10TB的数据
2009年3月 17个集群共24000个节点
2009年4月 在每分钟排序中胜出,59秒排序500GB(在1400个节点上)和173分钟内排序100TB数据(在3400个节点上)
2009年5月 Yahoo的团队使用Hadoop对1 TB的数据进行排序只花了62秒时间。
2010年5月 IBM提供了基于Hadoop 的大数据分析软件——InfoSphere BigInsights,包括基础版和企业版。
2011年5月 Mapr Technologies公司推出分布式文件系统和MapReduce引擎——MapR Distribution for Apache Hadoop。
2012年3月 企业必须的重要功能HDFS NameNode HA被加入Hadoop主版本。
2012年10月 第一个Hadoop原生MPP查询引擎Impala加入到了Hadoop生态圈。
2.主要版本
①Hadoop1.X即第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中HDFS由一个NameNode和多个DateNode组成,MapReduce由一个JobTracker和多个TaskTracker组成。
②Hadoop 2.X指的是版本为Apache Hadoop 0.23.x、2.x或者CDH4系列的Hadoop,内核主要由HDFS、MapReduce和YARN三个系统组成,其中,YARN是一个资源管理系统,负责集群资源管理和调度,MapReduce则是运行在YARN上离线处理框架,它与Hadoop 1.0中的MapReduce在编程模型(新旧API)和数据处理引擎(MapTask和ReduceTask)两个方面是相同的。
---------------------
作者:weiyanzi07
来源:CSDN
原文:https://blog.csdn.net/wyz0516071128/article/details/80955837
版权声明:本文为博主原创文章,转载请附上博文链接!
3.主要厂商
①CLOUDERA(规模最大、知名度最高,最早将Hadoop作为商用的公司);
②Hortonworks(主打产品Hortonworks Data Platform);
③IBM(BigInsights);
④Oracle(Oracle Big Data);
⑤EMC(Apache Hadoop发行版——Pivptal HD);
4.国内外Hadoop应用的典型案例。
①国外
- Yahoo是Hadoop的最大支持者,截至2012年,Yahoo的Hadoop机器总节点数目超过42000个,有超过10万的核心CPU在运行Hadoop。最大的一个单Master节点集群有4500个节点(每个节点双路4核心CPUboxesw,4×1TB磁盘,16GBRAM)。总的集群存储容量大于350PB,每月提交的作业数目超过1000万个,在Pig中超过60%的Hadoop作业是使用Pig编写提交的。
- Facebook使用Hadoop存储内部日志与多维数据,并以此作为报告、分析和机器学习的数据源。目前Hadoop集群的机器节点超过1400台,共计11?200个核心CPU,超过15PB原始存储容量,每个商用机器节点配置了8核CPU,12TB数据存储,主要使用StreamingAPI和JavaAPI编程接口。Facebook同时在Hadoop基础上建立了一个名为Hive的高级数据仓库框架,Hive已经正式成为基于Hadoop的Apache一级项目。此外,还开发了HDFS上的FUSE实现。
- EBay:单集群超过532节点集群,单节点8核心CPU,容量超过5.3PB存储。大量使用的MapReduce的Java接口、Pig、Hive来处理大规模的数据,还使用HBase进行搜索优化和研究。
- IBM蓝云也利用Hadoop来构建云基础设施。IBM蓝云使用的技术包括:Xen和PowerVM虚拟化的Linux操作系统映像及Hadoop并行工作量调度,并发布了自己的Hadoop发行版及大数据解决方案。
②国内
- 百度在2006年就开始关注Hadoop并开始调研和使用,在2012年其总的集群规模达到近十个,单集群超过2800台机器节点,Hadoop机器总数有上万台机器,总的存储容量超过100PB,已经使用的超过74PB,每天提交的作业数目有数千个之多,每天的输入数据量已经超过7500TB,输出超过1700TB。
- 阿里巴巴的Hadoop集群截至2012年大约有3200台服务器,大约30?000物理CPU核心,总内存100TB,总的存储容量超过60PB,每天的作业数目超过150?000个,每天hivequery查询大于6000个,每天扫描数据量约为7.5PB,每天扫描文件数约为4亿,存储利用率大约为80%,CPU利用率平均为65%,峰值可以达到80%。阿里巴巴的Hadoop集群拥有150个用户组、4500个集群用户,为淘宝、天猫、一淘、聚划算、CBU、支付宝提供底层的基础计算和存储服务
- 腾讯也是使用Hadoop最早的中国互联网公司之一,截至2012年年底,腾讯的Hadoop集群机器总量超过5000台,最大单集群约为2000个节点,并利用Hadoop-Hive构建了自己的数据仓库系统TDW,同时还开发了自己的TDW-IDE基础开发环境。腾讯的Hadoop为腾讯各个产品线提供基础云计算和云存储服务
- 华为公司也是Hadoop主要做出贡献的公司之一,排在Google和Cisco的前面,华为对Hadoop的HA方案,以及HBase领域有深入研究,并已经向业界推出了自己的基于Hadoop的大数据解决方案。
- 中国移动于2010年5月正式推出大云BigCloud1.0,集群节点达到了1024。中国移动的大云基于Hadoop的MapReduce实现了分布式计算,并利用了HDFS来实现分布式存储,并开发了基于Hadoop的数据仓库系统HugeTable,并行数据挖掘工具集BC-PDM,以及并行数据抽取转化BC-ETL,对象存储系统BC-ONestd等系统,并开源了自己的BC-Hadoop。
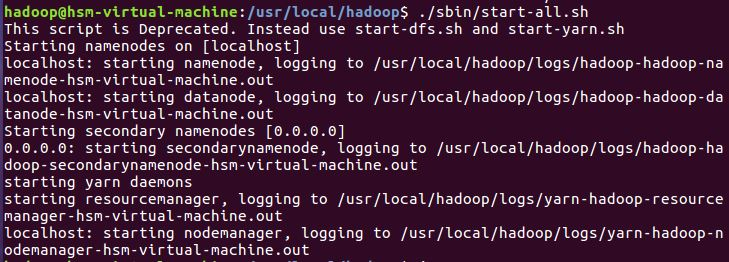
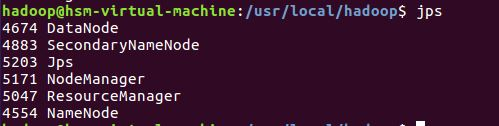
二、Hadoop的安装与配置
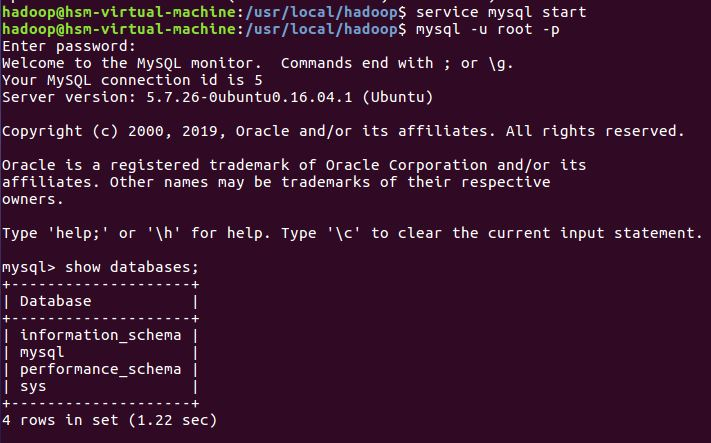
1.关系型数据库mysql:
2.java环境变量配置安装结果:

3.ubuntu与windows主机共享文件:
4.hadoop配置安装结果: