爬虫综合大作业
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
热门微博— —996与日剧《我要准时下班》

至此,“996话题”在微博上被传得沸沸扬扬。微博上关于“996”的话题已超过千个,甚至更多。其中 “#如何鉴别996公司#”阅读量高达8181.5万,关于“996”的话题还有“#996奋斗者的日常#”、“#996者不配养宠物#”、“#996的护胃计划#”、“#古人笑对996#”、“去你的996”。

工作时间周期长,上班几乎完全占据了一整个星期的时间。一周又一周,周而复始,新的一周又是工作的一周。996工作制就是压榨劳动力。

即便《劳动法》规定,但仍有大部分公司、企业打着“加班”的旗号,实则是被迫性劳动。
“过劳死”事件层出不穷,“工作996,生病ICU”。前段时间,程序员猝死在工作岗位上的新闻日益增多。“996抵制行动”的话题一下子被赤裸裸地推到风口浪尖。
展示几条关于“996”热门微博内容:
- 在广袤的代码森林里,996程序猿的生存状况如何?欢迎走进本期《动物世界》。(点赞数:26473)
- 面对职场,面对996,如果你愿意跪着去适应它,你可能一辈子就站不起来了。(点赞数:6978)
- 马云和刘强东谈996引发争议,网友神评论:月薪5w, 996像呼吸一样自然;月薪10w,办公室的甲醛让我着魔;月薪20w,公司就是家;月薪50w,我与公司共存亡;月薪100w,要亡公司先亡我。(点赞数:5536)
- “996工作制”是奋斗还是剥削?李永乐老师讲加班机会成本】最近996工作制突然成了热议的话题。从个人角度讲,加班可以让自己的收入增加、职位提升,但也会牺牲了休息、读书、健身、恋爱的时间。任何收益都有机会成本,这就是所谓的鱼与熊掌不可兼得。经济学研究认为,随着某种收益增加,它的边际成本会递增, 而边际效用会递减。边际成本等于边际效用的点是最优解,如果过分追求高收益,就会陷入自我剥削的陷阱。所以,适当加班有助于提升自己的生活品质,但是过分加班则是自我剥削的过程,是得不偿失的。(点赞数:3094)
- #996奋斗者们的日常# 996刷屏,不如看看这部日剧《我,到点下班》,剧如其名,这是你的心声吗?(点赞数:2637)

热门微博的内容提到几个敏感的词— —剥削、过度加班、牺牲休息等。词云一眼望去便是工作、工作、996与加班。
加班到底是剥削还是奋斗呢?但是,一定有一点要清楚,生活不仅只有工作,还有充分的休息与学习、娱乐等。仅仅只有工作的生活是乏味的,并且会局限了自身的发展和思想。
在热门微博中提及到了今年的春季日剧《我要准时下班》,体现了当代社会工作制度的诟病与工作者对理想职场的追求。这部日剧的出现无疑是对"996"的反击。
展示几条关于“日剧《我要准点下班》”热门微博内容:
- 分享一个最近追的日剧【我要准时下班】和我们现在所争议的996不同,女主东山是一个六点准时要下班赶着和半价啤酒的人"比起升职 朝九晚六 吃小笼包比较幸福"。她现在只想珍惜有人陪在身边的生活分享日常,周末可以一个人去享受温泉时光吃好吃的食物(这点我是真的很喜欢很喜欢了!)在听到有人因为过度劳累而死亡后,更加明白"人死了 就什么都没有了"。与她形成鲜明对比的是她的同事,一个努力勤奋到全年无休就连生病也坚持工作的三谷。后来一次新人的"造反"使得三谷感觉自己怎么努力都无效继而回家旷工,女主来到她家讲述了她以前的经历。(点赞数:3120)
- #我要准时下班# 第一话 你是否已经厌倦了#996#的上班模式?你是否也曾担心过突然暴毙于公司?你是否发现工作已经慢慢占据了你全部的生活?(点赞数:3084)
- 《我要准时下班》——又名「我的理想职场生活」(点赞数:1280)
- 日剧 #我要准时下班# 真是正巧的应景了最近的996话题。各种意义上的社畜真实。能在职场贯彻自己的原则,每天都能准时下班大概是每个上班人的理想状态吧(点赞数:1282)
- 《我要准时下班》这个剧还真是正巧的应景了最近的996话题。各种意义上的社畜真实。佩服吉高这个角色在经历了过劳之后能再站起来,活的这么洒脱。能在职场贯彻自己的原则,每天都能准时下班大概是每个上班的人最羡慕的东西了吧。(点赞数:1165)

而关于日剧《我要准时下班》的热门微博中提到最多的则是准时、下班。这完完全全给"996"一个下马威。这部日剧展示了生活不仅只有工作,还有小笼包(美食)......能够准时准点下班,去做自己想做的事、享受生活、不局限于职场的小小范围内,这几乎是所有人的愿景。但现实往往与理想状态背道而驰,剧中提到女主经常准时准点六点下班,却被勤奋的同事误会怠惰。但并非如此,女主每天高效率地完成了当日的工作,没有一刻是偷懒的。但是在现实中,即便能够准时准点下班,也很少有人踩点下班,通常会拖个半个小时。因为别人还在上班,你居然下班了。这种想法不可取。微博里看到的一句话——"千万不要用战术上的勤奋掩饰战略上的懒惰。提高效率与能力即正确之道。
996与日剧《我要准时下班》关键词条形图对比:
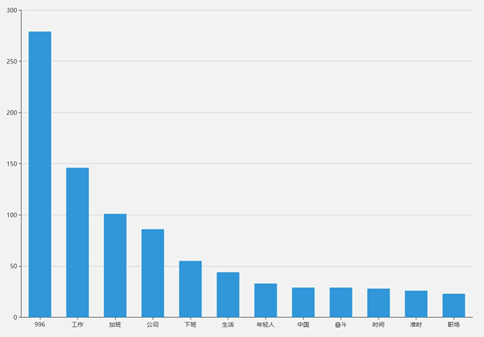
热门微博关于”996“的关键字的条形图
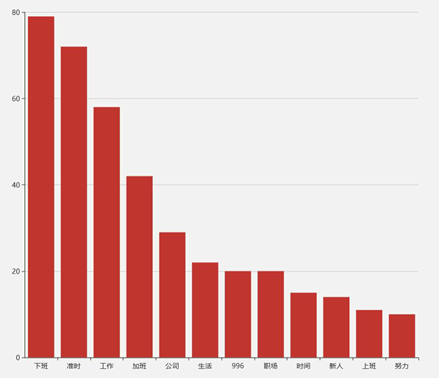
热门微博关于日剧《我要准时下班》关键字的条形图
根据以上的两个条形图的数据直观地看出微博上的内容大多是发表“996”的工作制的公司的加班,而不同的是日剧《我要准时下班》所表达的是准时下班。所以说,日剧《我要准时下班》是对"996"工作制的拒绝。不要去适应它,对"996"说不,是这部日剧对当下社会的一些公司压榨劳动力的现状的反击。
996与日剧《我要准时下班》微博文章发表的用户所在地分布条形图对比:
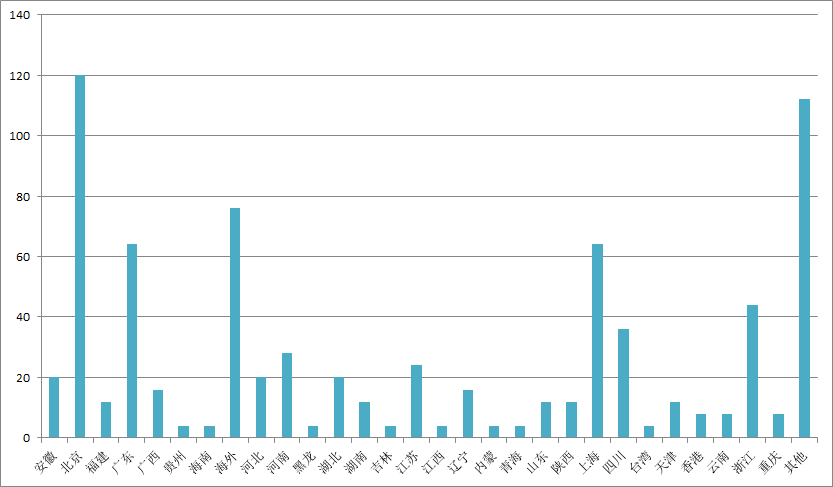
热门微博关于发表”996“的内容的用户所在地分布条形图
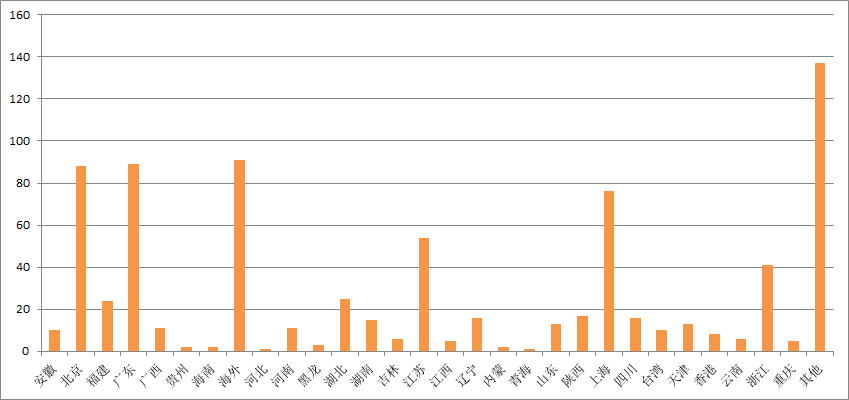
热门微博关于发表日剧《我要准时下班》的内容的用户所在地分布条形图
如上二图所示,不管是“996”话题还是日剧《我要准时下班》,用户大多分布在北上广深或者一些较为繁华的省份、地区。
996与日剧《我要准时下班》微博文章发表的用户性别条形图对比:
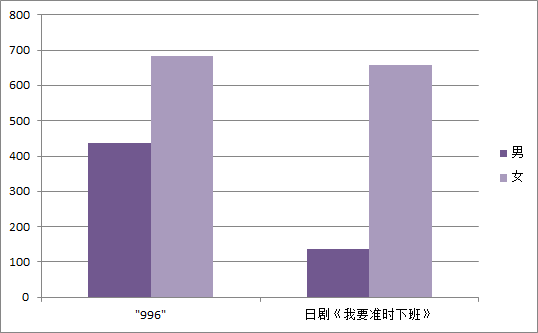
如图显示,微博用户关于“996”话题和日剧《我要准时下班》的讨论女性居多,也可以从中看出使用微博的用户中频率最多的还是女性。但是在“996”话题中,男性讨论活跃度明显增高。
996与日剧《我要准时下班》韦恩图:
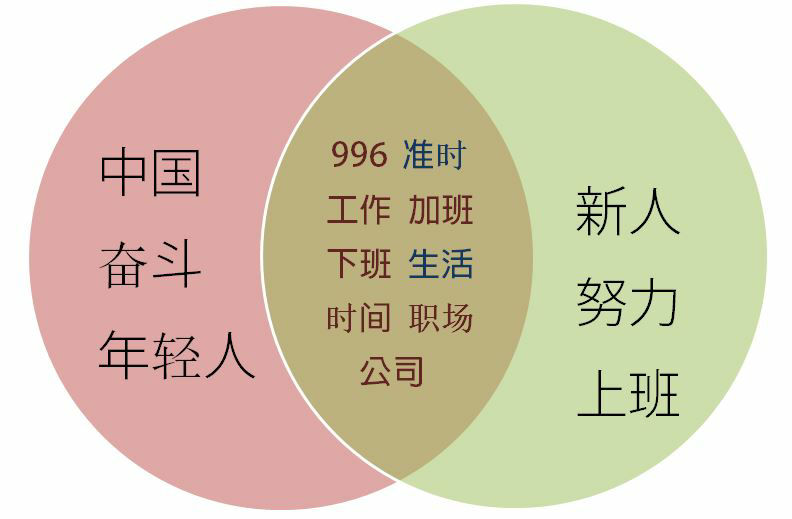
不管是"996"话题还是日剧《我要准点下班》的话题,其中的共同点都有加班、上班、工作、职场、公司等,艺术源于生活。同时,不管是在中国的"996“中年轻人、奋斗的关键字,还是日剧中新人、努力,它们都有共通之处— —奋斗工作的中国年轻人,努力工作的日本职场新人他们都接受着职场的"996",他们都是社会热点的主体。公司宣扬的努力说奋斗论不过就是被迫要求加班的借口。奋斗与努力本身没有错,错的是以之为理由进行剥削与自我催眠— —只要奋斗与努力就一定会成功。然而,奋斗与努力仅仅是成功的必要非充分条件。
如今,我们必须深刻明白对"996"适应即软弱。软弱即社畜(指在公司很顺从的工作,被公司当作牲畜一样压榨的员工)。
人死皆空。
抓取数据代码如下:


1 # coding=utf-8
2 import requests
3 import random
4 import time
5 import jieba
6 import operator
7 import pandas as pd
8 from urllib.parse import urlencode, quote, unquote
9 from pyquery import PyQuery as pq
10
11 UserAgent = [
12 "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
13 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
14 "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0",
15 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
16 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36",
17 "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0"]
18
19 base_url = "https://m.weibo.cn/api/container/getIndex?";
20 keyword = quote(input("请输入微博搜索的关键字:").strip(), safe=";/?:@&=+$,", encoding="utf-8")
21 print("请耐心等待...");
22 referer= "https://m.weibo.cn/search?containerid=100103type%3D1%26q%3D".format(keyword);
23 containerid="100103type%3D60%26q%3D{}%26t%3D0".format(keyword);
24 header = {"Host": "m.weibo.cn",
25 "Referer":referer,
26 "User-Agent": UserAgent[random.randint(0,5)],
27 "X-Requested-With": "XMLHttpRequest"};
28
29 #获取页面
30 def get_page(page):
31 params = {
32 "containerid": containerid,
33 "page_type": "searchall",
34 "page": page
35 };
36 url = base_url + urlencode(params);
37 try:
38 respose=requests.get(url,headers=header);
39 time.sleep(random.random() * 3);
40 if respose.status_code==200:
41 return respose.json();
42 except requests.ConnectionError as e:
43 print("错误信息",e.args);
44
45 #解析动态页面
46 def parse_one_page(json):
47 if json:
48 items=json.get("data").get("cards")
49 if items:
50 for item in items:
51 card_group = item.get("card_group");
52 for card in card_group:
53 dict_info = {};
54 mblog = card.get("mblog");
55 dict_info["id"] = mblog.get("id"); #获取微博的id
56 dict_info["attitudes_count"] = mblog.get("attitudes_count"); # 获取微博的点赞数;
57 if mblog.get("longText"):
58 dict_info["text"] = mblog.get("longText").get("longTextContent");
59 else:
60 dict_info["text"] = pq(mblog.get("text")).text(); #获取微博的内容,利用pq将html标签去掉
61 pics = mblog.get("pics"); #获取微博的图片
62 if pics:
63 urls = [];
64 for pic in pics:
65 url = pic.get("url");
66 urls.append(str(url));
67 dict_info["urls"] = urls;
68 yield dict_info;
69 #获取20个页面
70 def parse_page():
71 list_info=[];
72 text_info="";
73 for page in range(1,21):
74 json = get_page(page);
75 results = parse_one_page(json);
76 for result in results:
77 list_info.append(result);
78 for info in list_info:
79 text_info=text_info+str(info["text"]);
80 filename="996.txt";
81 with open(filename,"w",encoding="utf-8") as f:
82 f.write(text_info)
83 return filename,list_info;
84
85 #点赞数排行
86 def sort_atitudes(list_info):
87 sort_list=sorted(list_info,key=operator.itemgetter('attitudes_count'),reverse=True);
88 #sort_list = sorted(list_info, key=operator.itemgetter('attitudes_count'));
89 for i in range(20):
90 print(sort_list[i]);
91 pd.DataFrame(data=sort_list).to_csv('{0}点赞排行.csv'.format(unquote(keyword, encoding='utf-8')), encoding='utf_8_sig'); # 保存为.csv格式
92
93
94 #创建停用词list
95 def stopwordslist(filepath):
96 stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]#一行一行读取
97 return stopwords;
98
99 #切割文本
100 def cut_text(filename):
101 stopwords = stopwordslist("stops_chinese.txt");
102 with open(filename,"r",encoding="utf-8") as f:
103 text=f.read();
104 for r in stopwords:
105 text = text.replace(r, "");
106 word= jieba.lcut(text);
107 return text,word;
108
109 #统计词频
110 def count_word(text, word):
111 d={};
112 for i in word:
113 if len(i)==1:
114 word.remove(i);
115 else:
116 d[i] = text.count(i);
117 d=sorted(d.items(),reverse=True,key=lambda d:d[1]);
118 pd.DataFrame(data=d).to_csv('{0}词频.csv'.format(unquote(keyword, encoding='utf-8')), encoding='utf_8_sig'); # 保存为.csv格式
119 return d;
120
121
122 #主函数
123 def main():
124 filename,list_info=parse_page();
125 text,word=cut_text(filename);
126 count_word(text, word);
127 sort_atitudes(list_info);
128
129 main();