二、
1、指令调度,对于多条指令怎样调度让他们运行更快。
对于有冲突的两条指令,采用寄存器重命名技术。
2、指令重排 乱序执行,为了获取最大的吞吐率。 增大功耗 增加芯片面积。
3、缓存,容量越大速度越慢。把数据放在尽可能接近的位置。时间邻近性 空间邻近性。CPU芯片里,缓存就占了很大位置。
4、CPU内部的并行
指令级并行、数据级并行(矢量)、线程级并行。
三、
scalability 可扩展性 在100核心的基础上设计的程序,放在1000核心上,是不是有更好的加速。
五、GPU体系结构
GPU型的核心 和 CPU型的核心 有啥区别?
GPU小处理器
1、取址译码器 2、ALU 3、上下文
延迟隐藏:等待的过程中,切换到其他的线程执行。切换无成本。
上下文要存储起来,GPU提供一块128kb的上下文存储空间。
上下文的切换,可以软件也可以硬件。GPU是硬件管理,上下文贼多。
1、把分支预测 乱序执行之类的部件精简掉
2、多个core 多个ALU
3、大量任务、延迟隐藏
480个 Stream Processor 就是ALU 也叫CUDA Core
分成了15个 cores,每个core分成2组 16个 ALU。15个core,每个叫做一个SM。
另一个架构:
每个SM里有192个CUDA core,
CPU的缓存巨大,多级缓存。
GPU访存带宽非常宝贵。150GB/s,大概是CPU的6倍。但是GPU的吞吐比CPU高出数量级的。
一个SM里分好几组的处理单元,每个处理单元内是32个ALU。
warp是一个线程束。一个warp = 32个连续线程。
grid block warp都是软件层面的概念。都是线程的划分。
同一个block内的线程可以共享shared memory.
线程有local memory,当寄存器不够的时候,就放在local memory,local memory实际上在Global memory。
CPU 缓存 + 控制 + ALU,主要是缓存控制
GPU 主要是ALU
GPU通过硬件创建线程和管理。
问题:线程是怎么排布的?
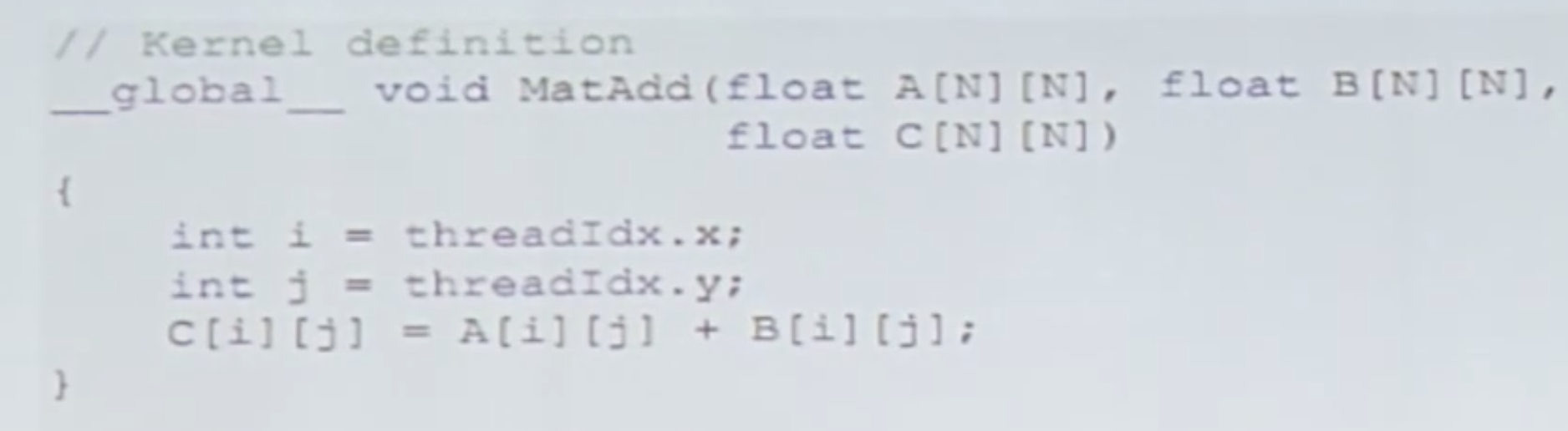
你怎么知道这是对齐访问的?
SM是硬件层面的概念。

会导致死锁
有的人在楼前门集合,有的在后门集合。这样永远没法集合。
SM中有ALU、上下文的存储空间、shared memory
每个SM可以驻扎巨多的线程,这些线程放在哪里?放在上下文空间里。warp调度,零开销。
SM上同一时刻只有一个warp在执行???一个SM有多少个cuda core?
一个SM里如果只有8个cuda core, 怎么办?每个warp分四批上去
每个SM有几千个寄存器。


local memory 每个thread 都有,用于存储自动变量数组。
第九集,有个矩阵乘,要写一下。 矩阵乘 用shared memory 怎么写,居然忘了都!!
第11集。并行规约,求和的运算,基础的CUDA并行算法,需要补充。
Global Memory访问 有几百个时钟周期。
half warp的所有线程 访问同一地址,有广播。没有冲突。
第12集,矩阵转置,要写代码。23分钟。记得补上。
Occupancy:激活的warp数与最大可容纳warp数的比值?没懂什么意思。

P12, 57分钟的优化
从13集以后不用看了 Fortran 和 cudnn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号