深度学习推理加速TensorRT简介
一、概括
TensorRT作为英伟达深度学习系列SDK的一部分,是一个高性能(HP)的深度学习推理优化器,可以为深度学习应用提供一个低延迟、高吞吐量的推理部署。基于TensorRT的应用推理性能上是只用CPU时的40多倍(版本TensorRT 7.0)。使用TensorRT,你可以优化现在几乎所有主流深度学习框架(tensorflow、caffe、pytorch、mxnet等)。TensorRT建立在NVIDIA的并行编程模型CUDA的基础上,使你能够利用CUDA-X中的库、开发工具和技术,为人工智能、自动机器、高性能计算和图形优化所有深度学习框架的推理。为减少应用程序的延迟,TensorRT提供低精度INT8和FP16的部署。
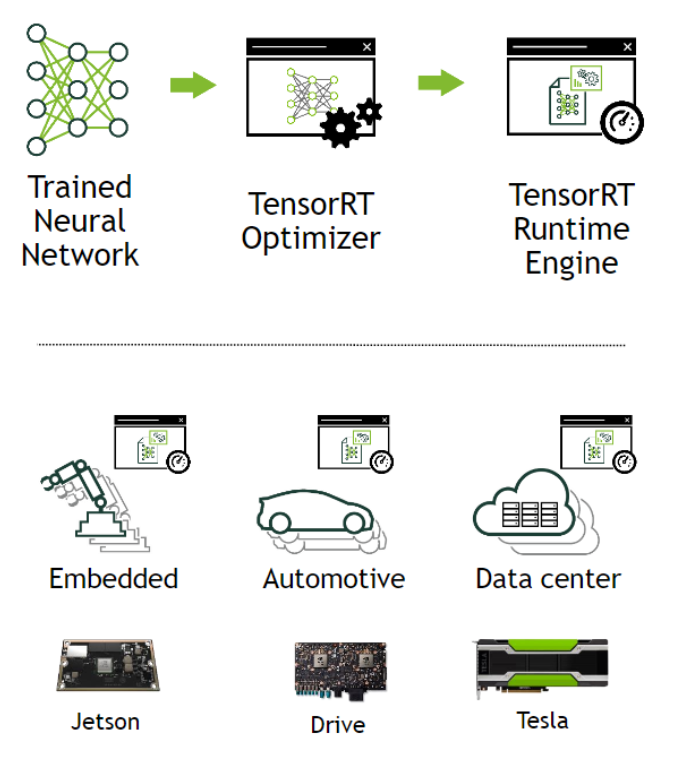
二、优化机理

1、权重、激活精度校准:通过将模型量化为INT8,同时保持准确性,最大化吞吐量
2、层、张量融合:通过融合内核中的节点优化GPU内存和带宽的使用
3、内核自动调整:基于目标GPU平台选择最佳数据层和算法
4、动态张量内存:最小化内存占用并有效地重新使用张量的内存
5、多流执行:并行处理多个输入流的可扩展设计
三、基于tensorflow的推理优化方式
TensorRT优化的模型必须是训练好的,比如用TF框架训练
1、使用tensorflow内置的TensorRT
参考 https://github.com/tensorflow/tensorrt
2、将计算图转换为UFF格式(网络层的定义、权重、偏差等数据)
参考 https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#working_tf
四、安装
参考 https://arleyzhang.github.io/articles/7f4b25ce/
