Python的垃圾回收机制
# python采用的是以引用计数为主,以分代回收和标记清除为辅的垃圾回收机制 # 1 引用计数 """ 在python中,每创建一个对象,那么python解释器会自动为其设置一个特殊的变量,这个变量称为引用计数(初始值默认是1)。一旦有一个新变量指向这个对象,那么这个引用计数的值就会加1。如果引用计数的值为0。那么python解释器的内存管理系统就会自动回收这个对象所占的内存空间,删除掉这个对象。 引用计数+1的情况: 对象被创建,例如a = "yuan" 对象被引用,例如b = a 对象被作为参数,传入到一个函数中,例如fun(a) 对象作为一个元素,存储在容器中,例如data_list=[a,b] 引用计数-1的情况: 对象的别名被显式销毁,例如del a 对象的别名被赋予新的对象,例如a = 24 一个对象离开它的作用域,例如func函数执行完毕时,func函数中的局部变量(全局变量不会) 对象所在的容器被销毁,或从容器中删除对象 """ # 2 分代回收 """ 既然已经有引用计数了,那么为什么还要提出分代回收呢?原因就是引用计数没办法解决“循环引用”的情况。 a = ["yuan", ] # 语句1 b = ["rain", ] # 语句2 a.append(b) # 语句3 b.append(a) # 语句4 # 此时对象的值:a = ["yuan", b] b = ["rain", a] del a # 语句5 del b # 语句6 # 执行完语句5和语句6是希望同时删除掉a对象和b对象 在执行"del a"语句之后,只是删除了对象的引用,也就是此时a变量这个名字被删除,也就是此时对象["yuan",b]的引用计数减1;执行"del b"语句也是同样的情况。但是,此时,由于显式指向它们的变量已经不存在了,所以也没办法删除了,就会导致它们一直存在于内存空间中。 这就是循环引用出现的问题。 此时,单靠引用计数没办法解决问题。所以便提出了分代回收 注意:在分代回收中,如果某对象的引用计数为0,那么它所占的内存空间同样也会被python解释器回收。 a、此时在python中每创建一个对象,那么就会把对象添加到一个特殊的“链表”中,这个链表称为"零代链表"。每当创建一个新的对象,那么就会将其添加到零代链表中。当这个"零代链表"中的对象个数达到某一个指定的阀值的时候,python解释器就会对这个"零代链表"进行一次“扫描操作”。这个“扫描操作”所做的工作是查找链表中是否存在循环引用的对象,如果在扫描过程中,发现有互相引用的对象,那么会让这些对象的引用计数都减少1。此时,如果某些对象引用计数变成0,那么就会被python解释器回收其所占用的内存空间;如果对象的引用计数仍然不为0,那么会把此时存活的对象迁移到“一代链表”中。 b、同样,python解释器也会在一定的情况下,也扫描“一代链表”,判断其中是否存在互相引用的对象。如果存在,那么同样也是让这些对象的引用计数都减少1。此时,如果某些对象引用计数变成0,那么就会被python解释器回收其所占用的内存空间;如果对象的引用计数仍然不为0,那么会把此时存活的对象迁移到“二代链表”中。 c、同样,python解释器也会在一定的情况下,也会扫描"二代链表",判断其中是否存在互相引用的对象。如果存在,那么同样也是让这些对象的引用计数都减少1。此时,如果某些对象引用计数变成0,那么就会被python解释器回收其所占用的内存空间;如果对象的引用计数仍然不为0,那么会把此时存活的对象迁移到一个新的特殊的内存空间。此时重新进行"零代链表 -> 一代链表 -> 二代链表"的循环。 这就是python的分代回收机制。 """ # 标记清除 """ 那么既然已经有分代回收了,那么为什么又要提出标记-清除呢? 原因就是分代回收没办法解决“误删”的情况。 a = ["yuan", ] # 语句1 b = ["rain", ] # 语句2 a.append(b) # 语句3 b.append(a) # 语句4 # 此时对象的值:a = ["yuan", b] b = ["rain", a]. ["yuan", b] 、["rain", a]的引用计数都为2 del a # 语句5 # 此时["yuan", b]的引用计数为1, ["rain", a]的引用计数为2 # 执行完语句5只希望删除a对象,保留b对象 如果按照分代回收的方式来处理上述语句。那么,python解释器在执行完语句5之后。在一定的情况下进行查找循环引用对象的时候,会发现此时["rain", a]对象和["yuan", b]对象存在互相引用的情况。所以此时就会让这两个对象的引用计数减1。此时,["yuan", b]对象的引用计数为0,所以["yuan", b]对象被真正删除,但是其实此时["rain", a]对象中是有一个变量引用原来的["yuan", b]对象的。如果["yuan", b]对象被真正删除的话,那么此时时["rain", a]对象中的a变量就没有用了,就没有办法访问了。但是其实我们是希望它有用的,所以这个时候就出现“误删”的情况了。所以此时就需要结合“标记-清除”来解决问题了。 标记-清除: 此时同样是检测链表中的相互引用的对象,然后让它们的引用计数减1之后; 但是此时会将所有的对象分为两组:死亡组(death_group)和存活组(survival_group),把引用计数为0的对象添加进死亡组,其它的对象添加进存活组; 此时会对存活组的对象进行分析,只要对象存活,那么其内部的对象当然也必须存活。如果发现内部对象死亡,那么就会想方设法让其活过来,通过这样子就能保证不会删错对象了。 题目的重新分析: 在检查死亡组的时候,会发现["rain", a]对象中的a所指向的对象存在于死亡组中,所以就会想方设法让其复活,此时就能够保证["rain", a]对象中所有的对象都是存活的。 """
引用计数器为主、分代回收和标记清除为辅
1.1 大管家refchain
在Python的C源码中有一个名为refchain的环状双向链表,这个链表比较牛逼了,因为Python程序中一旦创建对象都会把这个对象添加到refchain这个链表中。也就是说他保存着所有的对象。例如:
age = 18 name = "武沛齐"

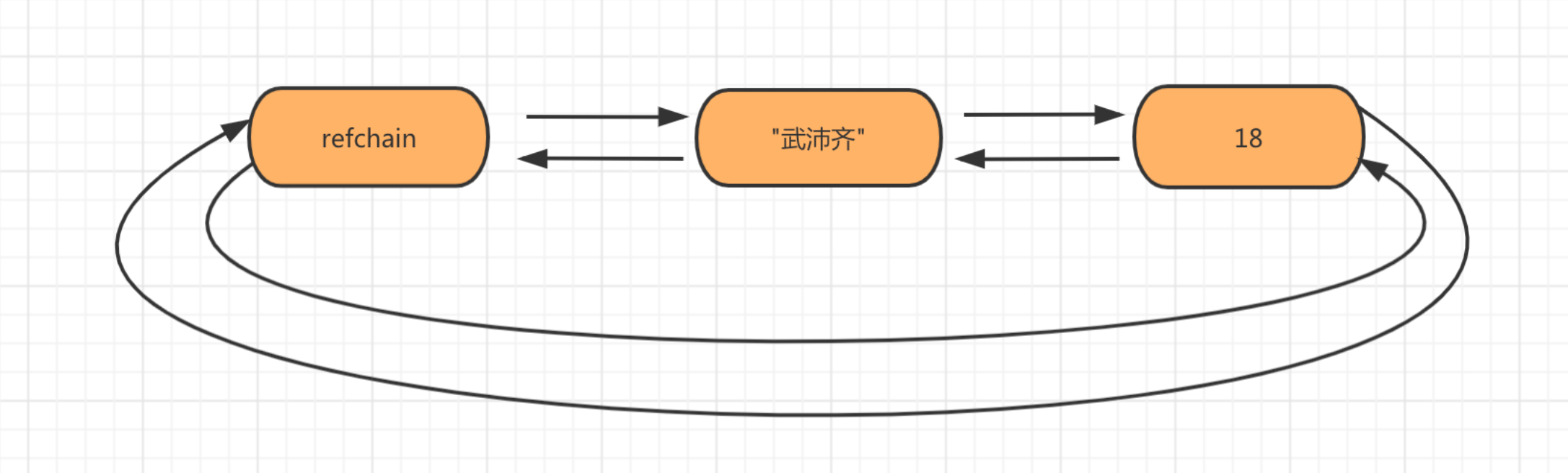
1.2 引用计数器
在refchain中的所有对象内部都有一个ob_refcnt用来保存当前对象的引用计数器,顾名思义就是自己被引用的次数,例如:
age = 18 name = "武沛齐" nickname = name
上述代码表示内存中有 18 和 “武沛齐” 两个值,他们的引用计数器分别为:1、2 。
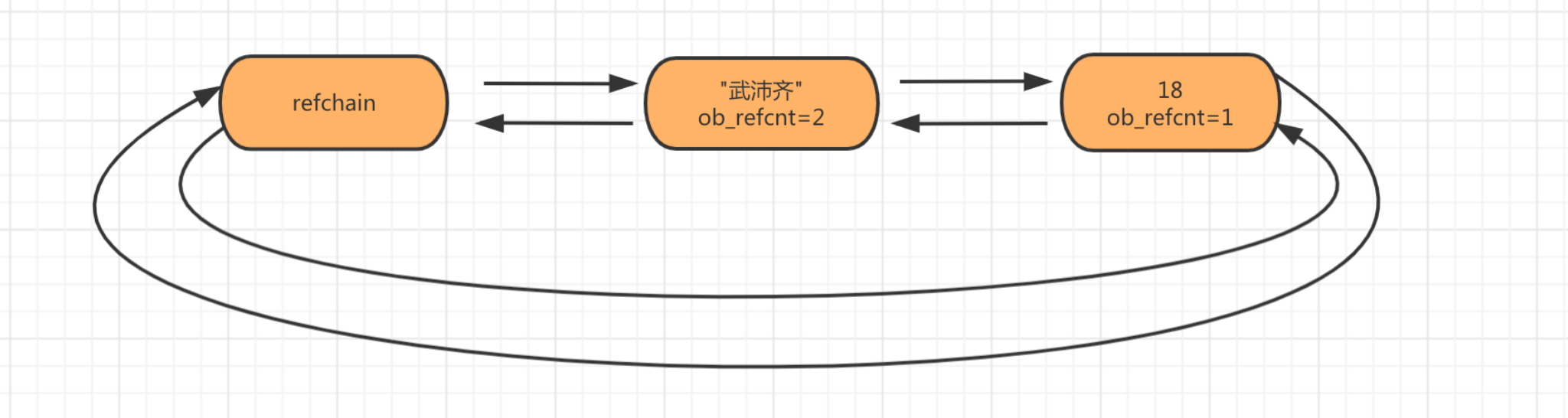

当值被多次引用时候,不会在内存中重复创建数据,而是引用计数器+1 。 当对象被销毁时候同时会让引用计数器-1,如果引用计数器为0,则将对象从refchain链表中摘除,同时在内存中进行销毁(暂不考虑缓存等特殊情况)。
age = 18 number = age # 对象18的引用计数器 + 1 del age # 对象18的引用计数器 - 1 def run(arg): print(arg) run(number) # 刚开始执行函数时,对象18引用计数器 + 1,当函数执行完毕之后,对象18引用计数器 - 1 。 num_list = [11,22,number] # 对象18的引用计数器 + 1
1.3 标记清除&分代回收
基于引用计数器进行垃圾回收非常方便和简单,但他还是存在循环引用的问题,导致无法正常的回收一些数据,例如:
v1 = [11,22,33] # refchain中创建一个列表对象,由于v1=对象,所以列表引对象用计数器为1. v2 = [44,55,66] # refchain中再创建一个列表对象,因v2=对象,所以列表对象引用计数器为1. v1.append(v2) # 把v2追加到v1中,则v2对应的[44,55,66]对象的引用计数器加1,最终为2. v2.append(v1) # 把v1追加到v1中,则v1对应的[11,22,33]对象的引用计数器加1,最终为2. del v1 # 引用计数器-1 del v2 # 引用计数器-1
对于上述代码会发现,执行del操作之后,没有变量再会去使用那两个列表对象,但由于循环引用的问题,他们的引用计数器不为0,所以他们的状态:永远不会被使用、也不会被销毁。项目中如果这种代码太多,就会导致内存一直被消耗,直到内存被耗尽,程序崩溃。
为了解决循环引用的问题,引入了标记清除技术,专门针对那些可能存在循环引用的对象进行特殊处理,可能存在循环应用的类型有:列表、元组、字典、集合、自定义类等那些能进行数据嵌套的类型。
标记清除:创建特殊链表专门用于保存 列表、元组、字典、集合、自定义类等对象,之后再去检查这个链表中的对象是否存在循环引用,如果存在则让双方的引用计数器均 - 1 。
分代回收:对标记清除中的链表进行优化,将那些可能存在循引用的对象拆分到3个链表,链表称为:0/1/2三代,每代都可以存储对象和阈值,当达到阈值时,就会对相应的链表中的每个对象做一次扫描,除循环引用各自减1并且销毁引用计数器为0的对象。
// 分代的C源码 #define NUM_GENERATIONS 3 struct gc_generation generations[NUM_GENERATIONS] = { /* PyGC_Head, threshold, count */ {{(uintptr_t)_GEN_HEAD(0), (uintptr_t)_GEN_HEAD(0)}, 700, 0}, // 0代 {{(uintptr_t)_GEN_HEAD(1), (uintptr_t)_GEN_HEAD(1)}, 10, 0}, // 1代 {{(uintptr_t)_GEN_HEAD(2), (uintptr_t)_GEN_HEAD(2)}, 10, 0}, // 2代 };
特别注意:0代和1、2代的threshold和count表示的意义不同。
- 0代,count表示0代链表中对象的数量,threshold表示0代链表对象个数阈值,超过则执行一次0代扫描检查。
- 1代,count表示0代链表扫描的次数,threshold表示0代链表扫描的次数阈值,超过则执行一次1代扫描检查。
- 2代,count表示1代链表扫描的次数,threshold表示1代链表扫描的次数阈值,超过则执行一2代扫描检查。
1.4 情景模拟
根据C语言底层并结合图来讲解内存管理和垃圾回收的详细过程。
第一步:当创建对象age=19时,会将对象添加到refchain链表中。
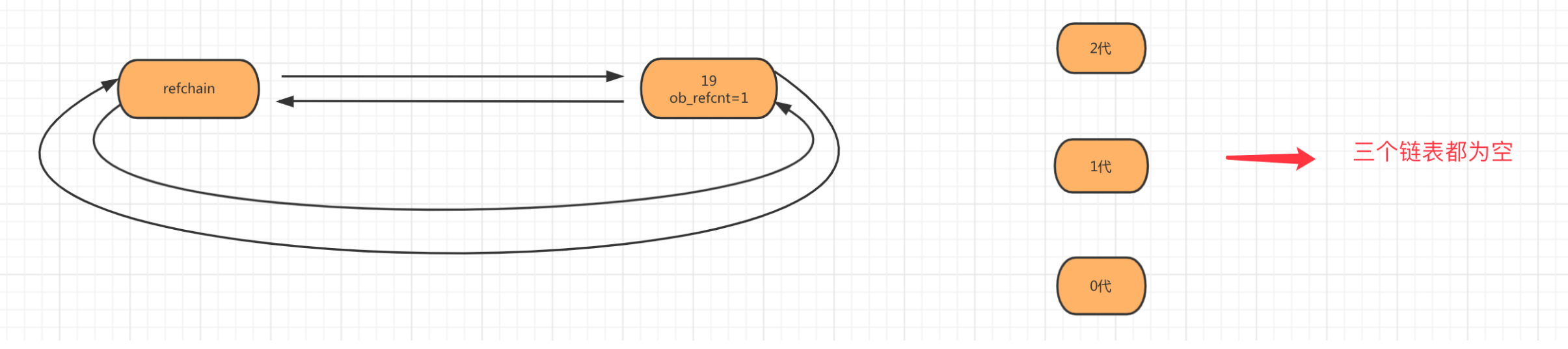

第二步:当创建对象num_list = [11,22]时,会将列表对象添加到 refchain 和 generations 0代中。
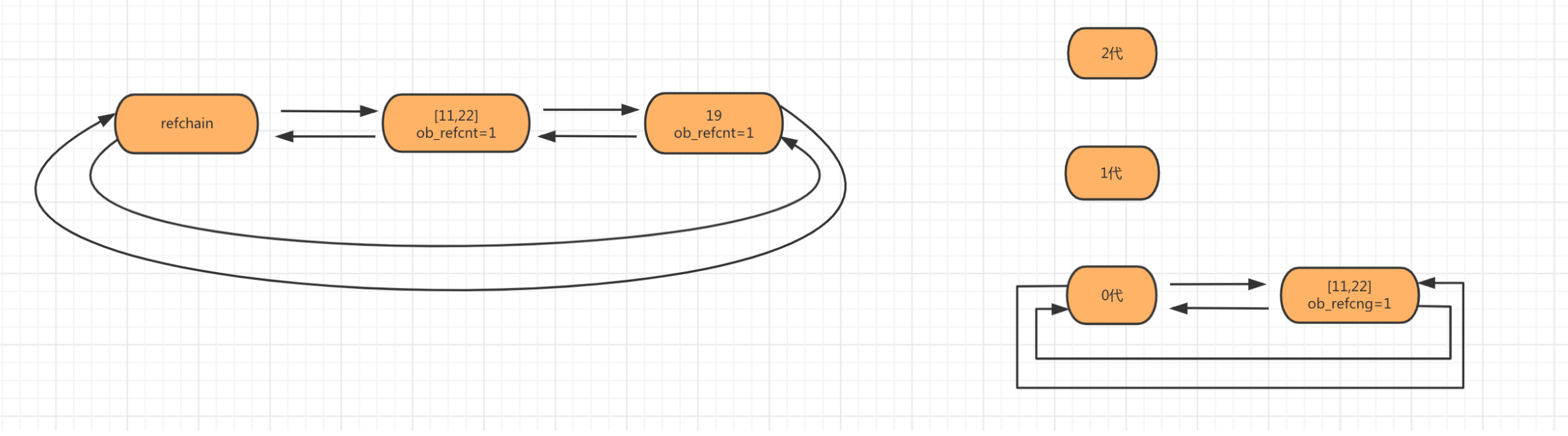

第三步:新创建对象使generations的0代链表上的对象数量大于阈值700时,要对链表上的对象进行扫描检查。
当0代大于阈值后,底层不是直接扫描0代,而是先判断2、1是否也超过了阈值。
- 如果2、1代未达到阈值,则扫描0代,并让1代的 count + 1 。
- 如果2代已达到阈值,则将2、1、0三个链表拼接起来进行全扫描,并将2、1、0代的count重置为0.
- 如果1代已达到阈值,则讲1、0两个链表拼接起来进行扫描,并将所有1、0代的count重置为0.
对拼接起来的链表在进行扫描时,主要就是剔除循环引用和销毁垃圾,详细过程为:
- 扫描链表,把每个对象的引用计数器拷贝一份并保存到
gc_refs中,保护原引用计数器。 - 再次扫描链表中的每个对象,并检查是否存在循环引用,如果存在则让各自的
gc_refs减 1 。 - 再次扫描链表,将
gc_refs为 0 的对象移动到unreachable链表中;不为0的对象直接升级到下一代链表中。 - 处理
unreachable链表中的对象的 析构函数 和 弱引用,不能被销毁的对象升级到下一代链表,能销毁的保留在此链表。- 析构函数,指的就是那些定义了
__del__方法的对象,需要执行之后再进行销毁处理。 - 弱引用,
- 析构函数,指的就是那些定义了
- 最后将
unreachable中的每个对象销毁并在refchain链表中移除(不考虑缓存机制)。
至此,垃圾回收的过程结束。
1.5 缓存机制
从上文大家可以了解到当对象的引用计数器为0时,就会被销毁并释放内存。而实际上他不是这么的简单粗暴,因为反复的创建和销毁会使程序的执行效率变低。Python中引入了“缓存机制”机制。
例如:引用计数器为0时,不会真正销毁对象,而是将他放到一个名为 free_list 的链表中,之后会再创建对象时不会在重新开辟内存,而是在free_list中将之前的对象来并重置内部的值来使用。
-
float类型,维护的free_list链表最多可缓存100个float对象。
-
v1 = 3.14 # 开辟内存来存储float对象,并将对象添加到refchain链表。 print( id(v1) ) # 内存地址:4436033488 del v1 # 引用计数器-1,如果为0则在rechain链表中移除,不销毁对象,而是将对象添加到float的free_list. v2 = 9.999 # 优先去free_list中获取对象,并重置为9.999,如果free_list为空才重新开辟内存。 print( id(v2) ) # 内存地址:4436033488 # 注意:引用计数器为0时,会先判断free_list中缓存个数是否满了,未满则将对象缓存,已满则直接将对象销毁。
-
int类型,不是基于free_list,而是维护一个small_ints链表保存常见数据(小数据池),小数据池范围:
-5 <= value < 257。即:重复使用这个范围的整数时,不会重新开辟内存。 -
v1 = 38 # 去小数据池small_ints中获取38整数对象,将对象添加到refchain并让引用计数器+1。 print( id(v1)) #内存地址:4514343712 v2 = 38 # 去小数据池small_ints中获取38整数对象,将refchain中的对象的引用计数器+1。 print( id(v2) ) #内存地址:4514343712 # 注意:在解释器启动时候-5~256就已经被加入到small_ints链表中且引用计数器初始化为1,代码中使用的值时直接去small_ints中拿来用并将引用计数器+1即可。另外,small_ints中的数据引用计数器永远不会为0(初始化时就设置为1了),所以也不会被销毁。
-
str类型,维护
unicode_latin1[256]链表,内部将所有的ascii字符缓存起来,以后使用时就不再反复创建。 -
v1 = "A" print( id(v1) ) # 输出:4517720496 del v1 v2 = "A" print( id(v1) ) # 输出:4517720496 # 除此之外,Python内部还对字符串做了驻留机制,针对那么只含有字母、数字、下划线的字符串(见源码Objects/codeobject.c),如果内存中已存在则不会重新在创建而是使用原来的地址里(不会像free_list那样一直在内存存活,只有内存中有才能被重复利用)。 v1 = "wupeiqi" v2 = "wupeiqi" print(id(v1) == id(v2)) # 输出:True
- list类型,维护的free_list数组最多可缓存80个list对象。
-
v1 = [11,22,33] print( id(v1) ) # 输出:4517628816 del v1 v2 = ["武","沛齐"] print( id(v2) ) # 输出:4517628816
- tuple类型,维护一个free_list数组且数组容量20,数组中元素可以是链表且每个链表最多可以容纳2000个元组对象。元组的free_list数组在存储数据时,是按照元组可以容纳的个数为索引找到free_list数组中对应的链表,并添加到链表中。
-
v1 = (1,2) print( id(v1) ) del v1 # 因元组的数量为2,所以会把这个对象缓存到free_list[2]的链表中。 v2 = ("武沛齐","Alex") # 不会重新开辟内存,而是去free_list[2]对应的链表中拿到一个对象来使用。 print( id(v2) )
- dict类型,维护的free_list数组最多可缓存80个dict对象。
-
v1 = {"k1":123} print( id(v1) ) # 输出:4515998128 del v1 v2 = {"name":"武沛齐","age":18,"gender":"男"} print( id(v1) ) # 输出:4515998128

 浙公网安备 33010602011771号
浙公网安备 33010602011771号