库表操作(DDL)
内容目录
- 库的增删改查
- 表的增删改查
强调:讲解内容以5.7版本为例
1 库的增删改查
这里的库指的数据库,也就是我们所谓的那个文件夹,一般情况下,我们在开发项目前,会先设计数据库中相关表结构,一个项目中所有表都会放在同一个文件夹下,对于库的操作属于SQL分类中的DDL,也就是数据库定义语言。
1.1 创建数据库
# 创建数据库并制定编码
create database 库名 charset 字符编码
create database db1 charset utf8;
# 不指定字符编码
create database db1;
# 使用数据库
use 库名
use db1;
# 查看当前库
select database();1.2 查询数据库
# 查看所有的数据库
show databases;
# 查看其中一个数据库
show create database 库名
show create database db1;
# 查看数据库编码
show variables like '%char%'1.3 修改数据库
数据库的名称一旦创建好之后就无法修改
# 修改数据库一般只修改编码
alter database 库名 charset 字符编码
alter database db1 charset utf8;1.4 删除数据库
drop database 库名
drop database db1;相信很多人做数据的同行,看到这些之后会说,这些语句都没啥用,我在工作中很少用,一般使用Navicate就可以通过菜单实现,说的没错,对于数据分析而言,我们不需要像程序员那样全程使用终端徒手敲代码,我们完全可以使用可视化工具来通过菜单的右击操作实现,上节课我们已经引入了Navicate,那接下来我就演示一下如何使用它操作数据库。
ps:是不是很简单,但是我个人还是喜欢在终端使用命令实现,接下来,我再演示一下在终端如何操作。
2 表的增删改查
2.1创建表
create table 表名(
字段名1 类型(宽度) 约束条件,
字段名2 类型(宽度) 约束条件,
字段名3 类型(宽度) 约束条件,
);
注意:
1.字段名不能重复
2.宽度和约束条件可选
3.字段名和类型是必须的查看表结构
1.两种查看表结构的方式
desc 表名; # describe 表名 二者是一样的
show create table 表名; # show create table 表名 \G 数据库(文件夹)中包含多张表,跟Excel的表很像,但是它包含了两部分,一部分是表结构,一部分是表数据。
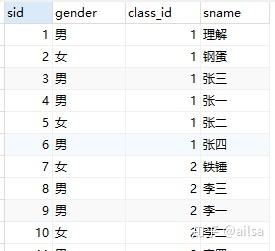
我们先看一下数据库中的表长什么样子?
表数据
表结构

之前学过SPSS的同学若没有学过,点击这里 https://zhuanlan.zhihu.com/p/123845239
我们知道SPSS也有自己的数据表结构,叫做视图
对于上述内容,大家肯定不太理解数据类型和约束条件这部分,下面就详细展开讲一下
2.2 数据类型
2.1.1字符串
顾名思义,就是存储的一连串的字符,例如文字
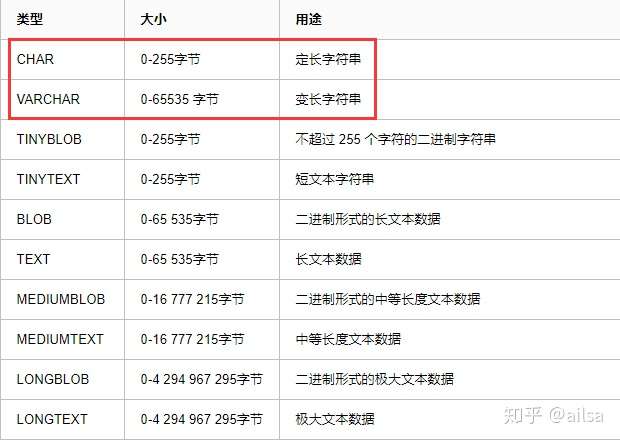
我们主要用到的是char和varchar这两种字符串类型,二者的区别是面试经常考的内容
区别1:定长和变长
char 固定长度,例如你定义了char(8),则这一列中存储的内容长度都为8,不足8则会用空格补充(但是我们在查询的时候是不会带空格的,mysql会对此进行处理)
varchar 变长存储,则根据实际的字符长度存储,例如varchar(8),则不足8按照实际存储,
ps: 对于上述两个类型,如果超过8则会根据你设置的sql_mode而定,默认是【| NO_ENGINESUBSTITUTION】-非严格模式,这种情况下,超过8会被截断;如果你的sql_mode是 【strict_trans_tables】则超过8会报错

那就借此补充一下如何修改sql_mode
# 查看模式
show variables like '%mode%'
默认是非严格模式
+----------------------------+------------------------+
| Variable_name | Value |
+----------------------------+------------------------+
| binlogging_impossible_mode | IGNORE_ERROR |
| block_encryption_mode | aes-128-ecb |
| gtid_mode | OFF |
| innodb_autoinc_lock_mode | 1 |
| innodb_strict_mode | OFF |
| pseudo_slave_mode | OFF |
| slave_exec_mode | STRICT |
| sql_mode | NO_ENGINE_SUBSTITUTION |
+----------------------------+------------------------+
# 修改成严格模式
set global sql_mode="strict_trans_tables";
改完之后需要退出重登
# 显示实际长度(字符串中char类型自动去掉空格)
set global sql_mode="strict_trans_tables,pad_char_to_full_length"区别2:存储方式
char直接存储字符内容
varchar 开头由1-2个字节存储该字符的总长度,后面接着存储字符内容
总结:char的存取速度很快,但是由于是定长,当大部分内容没有达到规定长度时,会浪费不少空间资源;varchar则不会,它根据实际长度存储,但是由于存储的特殊形式造成存取速度不及char,当char存储的内容都为一个定值时,则char不仅不浪费空间还提高存取效果,因为varchar还要留出一部分存储字符串的长度。很早之前,大家都觉得varchar好,节省资源,但是到现在,磁盘资源已经不成问题,因此我更倾向于选择char,也就是所谓的以空间换时间了。
2.1.2数值型
常用的有:int double float decimal
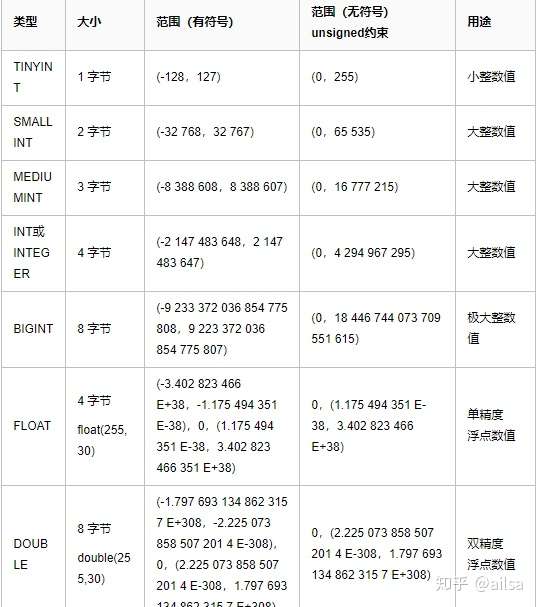

整数型:int 基本int能够处理日常工作中大部分整数存储问题
小数型:double float decimal
下面通过例子来分析一下三者的区别
设置数据类型的长度约束
# 创建表num,三个字段分别设置为三个不同数据类型,强调一下float(5,2)
其中5代表总长度,2代表小数长度,这个意思是整数是3位,小数是2位
create table num(num1 float(5,2),double(5,2),decimal(5,2));
# 插入一条数据
insert into num(1.234,1.234,1.234);
# 结果
mysql> select * from num;
+------+------+------+
| num1 | num2 | num3 |
+------+------+------+
| 1.23 | 1.23 | 1.23 |
+------+------+------+
1 row in set (0.00 sec)三者都会根据数据类型设置的长度进行四舍五入的数据显示
若都使用默认值,不设置条件
alter table num modify num1 float;
alter table num modify num2 double;
alter table num modify num3 decimal;
insert into num values(1.232323232323232,1.232323232323232,1.232323232323232);
mysql> select * from num;
+---------+-------------------+------+
| num1 | num2 | num3 |
+---------+-------------------+------+
| 1.23 | 1.23 | 1 |
| 1.23 | 1.23 | 1 |
| 1.23232 | 1.232323232323232 | 1 |
+---------+-------------------+------+
3 rows in set (0.00 sec)我们可以看出,如果使用默认值,则double比float显示的更精确,而decimal则默认以decimal(10,0)来显示,因此会是整数。
并且,decimal是定点型,默认存储的是字符串格式,double和float属于浮点型
日常工作中float足以解决小数问题了。
2.1.3 日期型
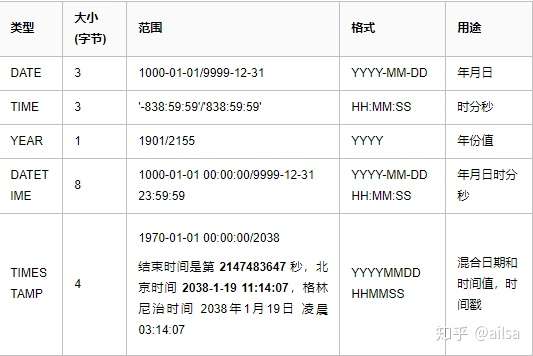
举例说明
create table t(date1 date,time,datetime);
insert into t(now(),now(),now());
mysql> select * from t;
+------------+----------+---------------------+
| date1 | date2 | date3 |
+------------+----------+---------------------+
| 2020-04-15 | 16:02:43 | 2020-04-15 16:02:43 |
+------------+----------+---------------------+
1 row in set (0.00 sec)2.1.4 ENUM和SET类型
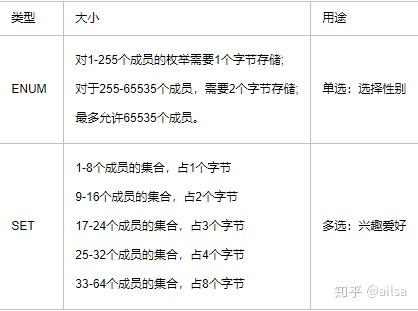
这里的类似于下拉字段,在进行数据插入的时候,必须选择事先设置的内容
create table t1(id int,name char(6),gender enum('female','male'),hobby set('抽烟','喝酒','烫头'));
insert into t1 values(1,'张三','男','喝酒');
insert into t1 values(1,'张三','female','喝酒');
mysql> select * from t1;
+------+--------+--------+--------+
| id | name | gender | hobby |
+------+--------+--------+--------+
| 1 | 张三 | | 喝酒 |
| 1 | 张三 | female | 喝酒 |
+------+--------+--------+--------+
2 rows in set (0.00 sec)
# 男不属于enum的枚举内容,因此不显示
对于set而言,可以多选,但是enum只能单选
mysql> insert into t1 values(1,'张三','男','喝酒,烫头');
Query OK, 1 row affected, 1 warning (0.00 sec)
mysql> select * from t1;
+------+--------+--------+---------------+
| id | name | gender | hobby |
+------+--------+--------+---------------+
| 1 | 张三 | | 喝酒 |
| 1 | 张三 | female | 喝酒 |
| 1 | 张三 | | 喝酒,烫头 |
+------+--------+--------+---------------+
3 rows in set (0.00 sec)2.3 约束条件
为了防止不符合规范的数据进入数据库,在用户对数据进行插入、修改、删除等操作时,DBMS自动按照一定的约束条件对数据进行监测,使不符合规范的数据不能进入数据库,以确保数据库中存储的数据正确、有效、相容。
约束条件与数据类型的宽度一样,都是可选参数,主要分为以下几种:
NOT NULL :非空约束,指定某列不能为空;
UNIQUE : 唯一约束,指定某列或者几列组合不能重复
PRIMARY KEY :主键,指定该列的值可以唯一地标识该列记录
FOREIGN KEY :外键,指定该行记录从属于主表中的一条记录,主要用于参照完整性2.3.1 not null
不为空,当你设置一个字段时,不允许它为空,可以使用此约束条件
create table t3(id int not null);
insert into t3 values(1);default 默认值
例如:对于性别一列,如果大部分都是男性,可以设置成默认值,不填则取默认值,填写了则覆盖默认值
alter table t3 add sex default "female";
# 创建时也可以使用默认值,create table t5(id int,sex char(6) not null default "female");
insert into t3(id) values(1);
insert into t3(id) values(2,"male");
mysql> select * from t3;
+----+--------+
| id | sex |
+----+--------+
| 0 | female |
| 0 | female |
| 1 | female |
| 2 | male |
+----+--------+
4 rows in set (0.00 sec)2.3.2 unique 唯一
当有一列字段你不想让它有重复值时,可以设置为唯一
单字段设置唯一约束
# 方法1
create table t4(id int not null,name char(8) unique);
# 方法2
create table t4(id int not null,name char(8),unique(name));
mysql> create table t4(id int not null,name char(8) unique);
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t4 values(1,"张三");
Query OK, 1 row affected (0.00 sec)
mysql> insert into t4 values(1,"张三");
ERROR 1062 (23000): Duplicate entry '张三' for key 'name'
mysql> select * from t4;
+----+--------+
| id | name |
+----+--------+
| 1 | 张三 |
+----+--------+
1 row in set (0.00 sec)联合唯一
只有当你设置的这些字段同时重复时才会报错
create table t6(id int,name char(6),depment char(10),unique(name,depment));
mysql> insert into t6 values(1,"张三","咨询部");
Query OK, 1 row affected (0.01 sec)
mysql> insert into t6 values(1,"李四","咨询部");
Query OK, 1 row affected (0.01 sec)
mysql> insert into t6 values(1,"张三","咨询部");
ERROR 1062 (23000): Duplicate entry '张三-咨询部' for key 'name'
mysql> select * from t6;
+------+--------+-----------+
| id | name | depment |
+------+--------+-----------+
| 1 | 张三 | 咨询部 |
| 1 | 李四 | 咨询部 |
+------+--------+-----------+
2 rows in set (0.00 sec)
2.3.3 primary key
主键为了保证表中的每一条数据的该字段都是表格中的唯一值。换言之,它是用来独一无二地确认一个表格中的每一行数据。
主键可以包含一个字段或多个字段。当主键包含多个栏位时,称为组合键 (Composite Key),也可以叫联合主键。
主键可以在建置新表格时设定 (运用 CREATE TABLE 语句),或是以改变现有的表格架构方式设定 (运用 ALTER TABLE)。
主键必须唯一,主键值非空;可以是单一字段,也可以是多字段组合。
单字段主键
mysql> create table t7(id int primary key,name char(6));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t7 values(1,"wanger");
Query OK, 1 row affected (0.00 sec)
mysql> insert into t7 values(1,"wang");
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
mysql> select * from t7;
+----+--------+
| id | name |
+----+--------+
| 1 | wanger |
+----+--------+
1 row in set (0.00 sec)联合主键
mysql> create table t8(id int,name char(8),primary key(id,name));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t8 values(1,'zhang');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t8 values(2,'zhang');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t8 values(2,'zhang');
ERROR 1062 (23000): Duplicate entry '2-zhang' for key 'PRIMARY'
mysql> select * from t8;
+----+-------+
| id | name |
+----+-------+
| 1 | zhang |
| 2 | zhang |
+----+-------+
2 rows in set (0.00 sec)了解内容
auto_increment 自增字段,对于id而言,往往我们可以设置为自增字段,不用手动填写
mysql> create table t9(id int primary key auto_increment,name char(6));
Query OK, 0 rows affected (0.04 sec)
mysql> insert into t9(name) values ("张三"),("李四"),("王五");
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from t9;
+----+--------+
| id | name |
+----+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+----+--------+
3 rows in set (0.00 sec)2.3.4 foreign key
多表 :
假设我们要描述所有公司的员工,需要描述的属性有这些 : 工号 姓名 部门
公司有3个部门,但是有1个亿的员工,那意味着部门这个字段需要重复存储,部门名字越长,越浪费
解决方法: 我们完全可以定义一个部门表 然后让员工信息表关联该表,如何关联,即foreign key
前提条件:#
类型必须是innodb存储引擎,且被关联的字段,即references指定的另外一个表的字段,必须保证唯一
# 首先创建部门表
mysql> create table depment1(id int primary key,name char(10) not null);
Query OK, 0 rows affected (0.02 sec)
# 创建用户表并关联部门表
mysql> create table empment(id int primary key auto_increment,name char(6),dep_id int,
foreign key(dep_id) references depment1(id));
Query OK, 0 rows affected (0.02 sec)级联删除,级联更新
两张表建立关联之后,如果部门表某个部门的砍掉了,那对应的人员表中的那些部门的人员相应的该怎么处理呢?可以保存,也可以随之一起删除
如果要保证两表一致,则需要在设置外键时添加on delete cascade
如果部门id更新了,要一起更新的话,则添加on update cascade
举个例子
mysql> create table depment2(id int primary key,name char(10) not null);
Query OK, 0 rows affected (0.02 sec)
mysql> create table empment2(id int primary key auto_increment,name char(6),dep_id int,
foreign key(dep_id) references depment1(id) on delete cascade on update cascade);
Query OK, 0 rows affected (0.03 sec)2.4 修改表
# 创建库
create database db4;
# 创建表
create table dep(
id int primary key auto_increment,
name char(16) not null,
age int,
gender enum("male","female")
);
# 1.修改表名
alter table 旧表名 rename 新表名
alter table dep rename dep_new;
# 修改表字段的数据类型
alter table 表名 modify 字段 新数据类型
alter table dep modify name varchar(16);
# 修改表字段
alter table 表名 change 字段 旧数据类型 [约束条件]
alter table dep_new change name new_name varchar(10);
# 修改表字段及数据类型
alter table 表名 change 字段 新数据类型 [约束条件]
alter table dep_new change new_name name char(16) not null;
# 新增表字段
alter table 表名
add 字段名 数据类型 [完整性约束条件],
add 字段名 数据类型 [完整性约束条件];
alter table dep_new add class char(10) not null;
# 指定位置添加字段
# 添加到首位
alter table 表名 add 字段名 数据类型 [完整性约束条件] first
alter table dep_new add my_id int not null first;
# 添加到中间的某个位置
alter table 表名 add 字段名 数据类型 [约束条件] after 字段名
alter table dep_new add my_name char(10) not null after name;
alter table dep_new change my_name new_name varchar(18) not null first;
alter table dep_new modify new_name varchar(18) not null after id;
# 修改约束条件
外键
2.单独增加外键
# 添加外键字段
alter table dep_new add dep_id int;
# 添加外键关系[指定外键名称]
alter table dep_new add