一、漫谈,数据库的发展史
观今宜鉴古,无古不成今 要了解一数据库的现在及将来,要首先了解数据库的过去……. 我们记录信息大致经历了以下几个历史…….
无库时代——文件系统
无论是通过石头、龟壳、羊皮卷、竹签记录信息的能力及其有限。当纸张出现后,虽然得到改善,但无法适应时代的发展。因为随着计算机的大范围应用,信息的产生、操作、共享、传输都呈现爆发式增长。这个时候,人们大多将数据信息保存到文件中。通过操作文件的形式,来处理数据信息。
层状数据库
 顾名思义,层次状数据库使用树形结构表示实体间的关系,层次清晰,但是对于复杂的数据结构模型,树形深度比较大,较深结构会使数据形成冗余。
顾名思义,层次状数据库使用树形结构表示实体间的关系,层次清晰,但是对于复杂的数据结构模型,树形深度比较大,较深结构会使数据形成冗余。
网状数据库
 网状结构数据库将数据库管理向前迈了一步,网状结构能够表示数据之间的联系,但是这也带了另一个问题,实体之间往往关系复杂且有相互纠缠,随着网越大,这种弊端越发凸显。
网状结构数据库将数据库管理向前迈了一步,网状结构能够表示数据之间的联系,但是这也带了另一个问题,实体之间往往关系复杂且有相互纠缠,随着网越大,这种弊端越发凸显。
关系型数据库
层状数据库和网状数据库欢快的使用着,直到——关系型数据库的出现。 虽然层状和网状结构解决了数据集中和数据共享的问题,但在数据独立性和抽象方面仍有很大的欠缺,直到1970年埃德加·科特提出了关系模型的概念,关系模型从此横行江湖。 关系模型将数据放在一种二维的存储结构中,整个数据库由若干个相互关联的二维表组成。关系型数据库解决了数据冗余问题,操作更加简化。
其他类型的数据库
数据库的分类

二、MySQL
为什么选择MySQL?
我将从以下几个角度来简要说明,数据库软件那么多,但为什么选择MySQL?
数据库排行榜
DB-Engines:https://db-engines.com/en/ranking
DB-Engines排名根据其受欢迎程度对数据库管理系统进行排名。排名每月更新一次,下图是截取日期是2021年2月份。
开源
开源就意味着免费!在中国,免费意味着什么?还用我多说吗? 当然,自从MySQL被Oracle收购后,就不太好了,但是我们还有mariaDB。
健壮的社区
这是一个要命的话题!MySQL有着健壮的社区,有专门的人员在维护这个社区。 一个资源丰富的社区,是一个软件成功的关键,这点从Python就可以看出来,Python的社区做的可以说是非常的好,大家可以在这个社区找到自己想要的东西,碰到问题能很快的找到解决办法,有了新的见解,也愿意写成博客之类的供大家参考,良性发展下,Python也越发展越好,这个道理同样适用于各个软件,包括MySQL,MySQL在世界范围内有着庞大的用户群,这些用户都在为MySQL的发展提供了直接或间接的力量。
稳定
没错,对于一个公司,尤其是互联网公司而言,开发出来的软件稳定肯定是要放在第一位的。更何况重中之重的数据库。MySQL经过几十年的发展,已经越来越稳定,极少出现宕机情况。
跨平台
MySQL支持AIX、FreeBSD、HP-UX、Linux、Mac OS、NovellNetware、OpenBSD、OS/2 Wrap、Solaris、Windows等多种操作系统
丰富的API接口
不管你数据库再厉害,那也是要搭配编程语言来实现具体的功能,丰富的API接口意味着有更多的编程语言可以与MySQL无缝协作,完成高效的开发。这些编程语言包括C、C++、Python、Java、Perl、PHP、Eiffel、Ruby和Tcl等
支持标准的SQL语句
世界范围内,有那么多的数据库软件,你有你的一套操作规则,他有他的一套操作规则,那么,一个公司在选择一个数据库,还要专门的学习这门数据库的相关规则,查询语法什么的,这就增了生产成本。为了解决这个问题,在1970年的埃德加·科德的一篇相当有影响力的论文中《一个对于大型共享型数据库的关系模型》描述了SQL这个结构化查询语言,主要应用与数据库的管理。后来这玩意儿成了数据库语言的标准。MySQL使用这种标准的SQL语言。
多种存储引擎
是的,MySQL有不同的引擎来支持不同的应用场景。
MySQL的模糊历史
MySQL的发展历程
让我们牢记一个人:天才少年蒙提。 MySQL的历史最早可以追溯到1979年,那时候,蒙提用BASIC设计了一个报表工具,没过多久,就用C语言重写了该工具,移植到了Unix平台,在当时,他只是一个很底层的面向报表的存储引擎,这个工具叫做Unireg。
- 1985年,他与Allan Larsson一起创办了TCX DataKonsult AB(一家瑞典数据仓库公司)。
- 1990年,在最初,他们只是自己设计了一个利用索引顺序取数据的方法,也就是ISAM(Indexed Sequential Access Method)存储引擎核心算法的前身,利用ISAM结合mSQL来实现需求。早期的时候,该公司主要为瑞典的一些大型零售商提供数据仓库服务,但是随着数据量增大、系统复杂度越来越高,ISAM和mSQL的组合逐渐不堪重负。在分析性能的瓶颈后,问题出现在mSQL上,后来他们抛弃了mSQL,重新开发一套功能类似的数据存储引擎,这就是ISAM存储引擎。
- 1995年,蒙提使用David Axmark编写第一版MySQL数据库,于1996年发布。需要说明的蒙提和David Axmark及Allan Larsson在同年创立了MySQL AB公司。
- 1996年,MySQL的1.0版本发布,当时真是面向一部分人,直到同年的10月,MySQL的3.11.1发布!是的,这群不按套路的天才们,直接跳过了2.x版本!最开始,只是提供了Solaris下的二进制版本。一个月后,有了Linux版本。 在接下来的两年里,MySQL不断的移植到各个平台下。
- 1999年至2000年,MySQL AB与Sleepycat合作开发Berkeley DB引擎,因为该引擎支持事物处理。
- 2000年,MySQL对旧的存储引擎进行了整理,命名为MyISAM。
- 2001年,Innobase公司与MySQL AB达成合作,共同开发InnoDB引擎,该引擎同样支持事物,并且支持行级锁。同年MySQL发布MySQL4.0版本,该版本正式支持InnoDB引擎。
- 2005年,MySQL发布了经典的5.0版本,MySQL在该版本中加入了游标、触发器、存储过程、视图等功能。同年,Oracle公司以迅雷不及掩耳之势收购了innobase公司。
- 2008年,Sun公司以10亿美金收购了MySQL AB公司。
- 2010年,可惜,Sun公司好景不长,因为2010年,Oracle公司又收购了Sun公司。从此,MySQL归Oracle所有。Oracle公司对MySQL分为社区版和企业版,社区版免费,企业版收费,当然,也提供更多的功能!同年4月22日MySQL5.5和MySQL Cluster7.1版本发布。
- 2013年,2013年2月6日MySQL5.6发布,InnoDB性能和复制一致性加强。
- 2014年,2014年4月4日Oracle发布MySQL里程碑式的版本MySQL5.7版本,此版本满足网络、云和嵌入式需求,性能更强、扩展性和可靠性得到提高。
- 2016年,2016年9月12日,Oracle正式发布MySQL8.0版本。没错,直接跳过了6.x、7.x版本。
sakila
我们都知道MySQL的logo是海豚(sakila),而sakila的由来则是来自MySQL AB公司创始人从"海豚命名"竞赛中得来的,这个sakila是来自于坦桑尼亚的Arusha的一个小镇的名字。
目前主流的MySQL版本及分支
目前较为主流的MySQL版本:
其他版本:
- Oracle: - MySQL官方版
- 红帽: - MariaDB,MySQL被Oracle收购后,MySQL的开发者就搞了个MariaDB继续开源!感谢大佬!!!
- Percona: - PerconaDB,了解即可。
建议版本选择:
- Oracle的官方版本,5.6和5.7,当然,目前还是推荐5.7。
- GA(稳定发布)
如何获取MySQL:
- 企业版Enterprise,互联网行业一般不选择
- 社区版,推荐
- 源码包,通用二进制
如何学好MySQL
SQL介绍
SQL历史
SQL是一种结构化的查询语言。
关于SQL的历史:

图片来自维基百科:https://zh.wikipedia.org/wiki/SQL。
MySQL5.7以后符合SQL92标准的严格模式,通过sql_mode参数来控制。
常用的SQL分类
- DDL(Data Definition Language):数据定义语言,就是我们在创建表的时候用到的一些sql,比如说:CREATE、ALTER、DROP等。DDL主要是用在定义或改变表的结构,数据类型,表之间的链接和约束等初始化工作上。
- DCL(Data Control Language):数据控制语言,是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。这个比较少用到。
- DML(Data Manipulation Language):数据操作语言,就是我们最经常用到的 SELECT、UPDATE、INSERT、DELETE。 主要用来对数据库的数据进行一些操作。
MySQL相关概念
连接
MySQL提供了两种连接方式:
- TCP/IP方式(本地、远程):
mysql -uroot -p123 -h 10.0.0.1 -P330
- Socket方式(仅本地):
mysql -uroot -p123 -S /tmp/mysql.sock
当我们本地连接MySQL的时候,默认用的是socket方式,一般在配置文件中有体现:
1
2
3
4
5
6
7
8
9
10
11
|
[root@cs /]# cat /etc/my.cnf
[mysqld]
user=mysql
basedir=/opt/mysql
datadir=/data/mysql
server_id=6
port=3306
socket=/tmp/mysql.sock
[mysql]
socket=/tmp/mysql.sock
prompt=3306 [\\d]>
|
如上socket指向的/tmp/mysql.sock文件就是socket文件,通过这个文件进行连接;我们也能在本地找到这个文件:
[root@cs /]# ll /tmp/mysql.sock
srwxrwxrwx 1 mysql mysql 0 8月 14 16:28 /tmp/mysql.sock
实例
MySQL实例由以下几部分组成:
- MySQL后台守护进程
- Master Thread
- Work Thread
- 预分配的内存
一台物理机上,通常可以部署一个实例;当然为了最大化的利用硬件性能,也可以部署多个实例。
MySQL架构

MySQL架构总共四层:
-
首先,最上层的服务并不是MySQL独有的,大多数给予网络的客户端/服务器的工具或者服务都有类似的架构。比如:连接处理、授权认证、安全等。
-
第二层的架构包括大多数的MySQL的核心服务。包括:查询解析、分析、优化、缓存以及所有的内置函数(例如:日期、时间、数字和加密函数)。同时,所有的跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。
-
第三层包含了存储引擎。存储引擎负责MySQL中数据的存储和提取。服务器通过API和存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明化。存储引擎API包含十几个底层函数,用于执行“开始一个事务”等操作。但存储引擎一般不会去解析SQL(InnoDB会解析外键定义,因为其本身没有实现该功能),不同存储引擎之间也不会相互通信,而只是简单的响应上层的服务器请求。
-
第四层包含了文件系统,所有的表结构和数据以及用户操作的日志最终还是以文件的形式存储在硬盘上。
MySQL中一条SQL的执行过程:
-
由客户端向mysqld发送SQL语句
-
连接层
- 提供连接协议:TCP/IP、SOCKET
- 提供验证:用户、密码、IP、SOCKET
- 提供专用连接线程:接收SQL、返回结果,我们可以通过下面的语句来查看到当前有几个客户端连接:
1
2
3
4
5
6
7
8
|
mysql> show processlist;
+----+------+-----------+------+---------+------+----------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------+------+---------+------+----------+------------------+
| 3 | root | localhost | NULL | Sleep | 20 | | NULL |
| 4 | root | localhost | NULL | Query | 0 | starting | show processlist |
+----+------+-----------+------+---------+------+----------+------------------+
2 rows in set (0.00 sec)
|
-
SQL层:
- 接收上层传送过来的SQL语句
- 语法验证模块:验证语句语法,是否满足
SQL_MODE
- 语义检查:判断SQL语句的类型
- DDL:数据定义语言
- DCL:数据控制语言
- DML:数据操作语言
- DQL:数据查询语言
- ………
- 权限检查:用户对库表有没有相关权限
- 解析器:进行SQL预处理,产生执行计划
- 优化器:根据解析器得出多种执行计划,进行选择最优的执行计划
- 代价模型:资源(CPU、IO、MEM)的损耗评估性能情况
- 执行器:根据最优执行计划,执行SQL语句,产生执行结果,数据在磁盘的某个位置上
- 根据查询缓存(默认是关闭的),会使用redis、tair替代查询缓存功能
- 提供日志记录:binlog,默认是关闭的
-
存储引擎层(类似Linux中的文件系统):根据SQL层执行的结果,从磁盘上拿数据,将16进制的磁盘数据,交由SQL结构化成表,由连接层的专用线程返回给用户
逻辑结构
在MySQL中,逻辑结构由库和表组成,并且各自有各自的规范:
库的物理结构
库相当于目录(文件夹)。
表的物理结构
在磁盘上,表的物理存储根据存储引擎的不同而有所不同,目前常用的有两种:
MyIASM:
- user.frm:存储列相关信息
- user.MYD:存储记录
- user.MYI:索引
INNODB:
[root@cs mysql]# ll user.*
-rw-r----- 1 mysql mysql 10816 6月 8 09:25 user.frm
-rw-r----- 1 mysql mysql 396 6月 8 09:51 user.MYD
-rw-r----- 1 mysql mysql 4096 6月 8 09:51 user.MYI
[root@cs mysql]# ll time_zone.*
-rw-r----- 1 mysql mysql 8636 6月 8 09:25 time_zone.frm
-rw-r----- 1 mysql mysql 98304 6月 8 09:25 time_zone.ibd
如上示例是两种不同存储引擎的表的物理结构。

我们可以对应来理解:
- 数据库相当于文件夹。
- 数据表相当于文件夹内的Excel表。
- 记录相当于Excel表中的一行行数据。
只不过MySQL对这些有更严格的规范。
各平台安装MySQL
本小节将介绍,如何下载MySQL和安装MySQL。
download
这里先告诉大家怎么下载MySQL。
打开官网下载地址:https://downloads.mysql.com/archives/community/,按照截图所示下载即可。
Windows

centos

请先下载好安装包,再往下看如何进行安装和相关配置的。
for Windows
win10 + mysql-5.7.20-winx64.zip
注意:后续所有在Windows终端中的操作,都必须是以管理员身份运行的终端。
install
下载到本地的安装包是zip包,选择一个指定目录进行解压,解压的过程就是安装的过程,解压后的位置就是MySQL的安装位置。 注意,安装目录不允许有中文、空格和其他特殊字符。 如下截图,我将MySQL解压并安装到C盘的根目录:

配置环境变量
拷贝安装目录内的bin路径,并将其添加到系统的环境变量中。

执行初始化 在任意路径下,以管理员的身份打开终端执行:
1
|
mysqld --initialize-insecure
|
--initialize-insecure,表示不安全的初始化。这个参数来自于--initialize参数,在MySQL5.7版本中,在初始化过程中,会生成一个临时密码(临时密码文件在data目录内的"你的主机名.err"文件),后续处理相对麻烦,所以这里改为--initialize-insecure,初始化时将root用户的登录密码设置为空。 注意,如果报错:提示缺少MSVCP120.dll文件的话,后面有解决办法。 初始化成功如下图: 初始化成功的另一个标志是,在MySQL的安装目录中,会多个data目录,这个data目录是是MySQL在初始化过程中创建的数据目录。
初始化成功的另一个标志是,在MySQL的安装目录中,会多个data目录,这个data目录是是MySQL在初始化过程中创建的数据目录。

如果你没有发现data目录,说明初始化过程有些问题,重新以管理员的身份打开终端执行初始化命令:

如上图中的ERROR报错,说初始化过程中,data目录内存在文件,初始化被终止。这是因为之前初始化成功了,data目录被创建,期内也有了文件。 当然有了这些提示,说明整个初始化过程成功了。
添加MySQL服务到系统的服务中并启动MySQL 这一步是将MySQL服务添加到系统的服务中,并且设置为自动。然后,我们就可以使用net命令来管理MySQL服务了。注意,也必须是在以管理员身份运行的终端中才能使用net命令管理MySQL服务。
 现在系统的服务中就可以找到MySQL了。
现在系统的服务中就可以找到MySQL了。 但此时MySQL服务还没有启动,你可以在服务中点击启动,也可以在终端中使用net命令来启动/关闭MySQL服务。
但此时MySQL服务还没有启动,你可以在服务中点击启动,也可以在终端中使用net命令来启动/关闭MySQL服务。 ok,现在MySQL服务正常启动了,并且,由于系统服务中的MySQL服务设置的是自动,下次系统启动时,MySQL服务也默认启动了。
ok,现在MySQL服务正常启动了,并且,由于系统服务中的MySQL服务设置的是自动,下次系统启动时,MySQL服务也默认启动了。
测试 当MySQL服务正常启动后,我们就可以尝试使用客户端连接并操作MySQL了。 PS:后续使用客户端连接M操作MySQL时,终端就没有"以管理员身份运行终端"这个要求了,普通终端也可以。
PS:后续使用客户端连接M操作MySQL时,终端就没有"以管理员身份运行终端"这个要求了,普通终端也可以。
创建密码 以管理员的身份打开终端执行:
1
|
mysqladmin -uroot -p password 123
|

ok,在Windows平台安装MySQL完事了。
可能的报错,缺少MSVCP120.dll文件
当执行初始化的时候,提示缺少MSVCP120.dll文件。
一般新的系统容易缺少一些依赖库。这个报错(可能)就是系统缺少Visual C ++可再发行组件包。
扩展:什么是Visual C ++可再发行组件包?
Visual C ++可再发行组件是使用Microsoft的Visual Studio软件开发环境构建的程序或游戏所需的DLL(动态链接库)文件。当程序需要DLL或其他支持文件才能运行时,这称为依赖项。
原文链接:https://www.groovypost.com/howto/fix-visual-c-plus-plus-redistributable-windows-10/
解决办法
-
打开microsoft官网:https://www.microsoft.com/en-us/download/details.aspx?id=40784,点击下载:
-
根据系统位数选择下载:
-
以管理员的身份运行,然后默认安装即可。
-
重新以管理员身份打开终端,执行初始化步骤吧!
1
|
mysqld --initialize-insecure
|
for centos
install
在安装之前,如果你的系统曾经安装过Mariadb,请先卸载:
好了,开始吧!
- 安装依赖包:
yum install -y epel-release
yum update -y
yum install -y cmake gcc-c++ ncurses-devel perl-Data-Dumper boost-doc boost-devel libaio-devel
- 下载、解压缩、重命名,当然,你也可以把原来的压缩包删除掉:
[root@cs ~]# cd /opt/
[root@cs opt]# wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.20-linux-glibc2.12-x86_64.tar.gz
[root@cs opt]# tar -xvf mysql-5.7.20-linux-glibc2.12-x86_64.tar.gz
[root@cs opt]# mv mysql-5.7.20-linux-glibc2.12-x86_64 mysql
[root@cs opt]# rm -rf mysql-5.7.20-linux-glibc2.12-x86_64.tar.gz
[root@cs opt]# ls
mysql
- 添加环境变量:
[root@cs opt]# vim /etc/profile
# 添加如下内容
export PATH=/opt/mysql/bin:$PATH
# 然后source生效
[root@cs opt]# source /etc/profile
- (如果已有请忽略)建立mysql用户、用户组,后续使用该用户用来管理MySQL:
[root@cs opt]# useradd mysql
- 创建相关目录并授权:
[root@cs opt]# mkdir /data/mysql -p
[root@cs opt]# chown -R mysql:mysql /opt/mysql/*
[root@cs opt]# chown -R mysql:mysql /data/*
其中:
/opt/mysql/是MySQL软件所在目录。/data/mysql是将来存放MySQL数据的目录。
- 初始化数据库:
# 保证/data/mysql/目录是空的,避免不必要的问题
rm -rf /data/mysql/*
mysqld --initialize-insecure --user=mysql --basedir=/opt/mysql --datadir=/data/mysql
[root@cs opt]# rm -rf /data/mysql/*
[root@cs opt]# mysqld --initialize-insecure --user=mysql --basedir=/opt/mysql --datadir=/data/mysql
2020-06-08T01:25:34.199239Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details).
2020-06-08T01:25:34.357149Z 0 [Warning] InnoDB: New log files created, LSN=45790
2020-06-08T01:25:34.381441Z 0 [Warning] InnoDB: Creating foreign key constraint system tables.
2020-06-08T01:25:34.436113Z 0 [Warning] No existing UUID has been found, so we assume that this is the first time that this server has been started. Generating a new UUID: f352c664-a926-11ea-a90d-000c29872edd.
2020-06-08T01:25:34.437057Z 0 [Warning] Gtid table is not ready to be used. Table 'mysql.gtid_executed' cannot be opened.
2020-06-08T01:25:34.438213Z 1 [Warning] root@localhost is created with an empty password ! Please consider switching off the --initialize-insecure option.
上述参数,并不难理解:
--initialize-insecure,表示不安全的初始化。这个参数来自于--initialize参数,在MySQL5.7版本中,在初始化成功后,会生成一个临时密码,相对比较麻烦,所以这里改为--initialize-insecure,初始化成功后,密码为空。--user=mysql,管理MySQL的用户是mysql。--basedir=/opt/mysql,是你MySQL的安装目录。--datadir=/data/mysql,是管理数据的目录。
在初始化完成后,你的MySQL的数据目录,应该有这些文件:
1
2
3
4
5
6
7
8
9
10
|
[root@CS opt]# ll /data/mysql/
总用量 110628
-rw-r----- 1 mysql mysql 56 11月 27 14:21 auto.cnf
-rw-r----- 1 mysql mysql 419 11月 27 14:21 ib_buffer_pool
-rw-r----- 1 mysql mysql 12582912 11月 27 14:21 ibdata1
-rw-r----- 1 mysql mysql 50331648 11月 27 14:21 ib_logfile0
-rw-r----- 1 mysql mysql 50331648 11月 27 14:21 ib_logfile1
drwxr-x--- 2 mysql mysql 4096 11月 27 14:21 mysql
drwxr-x--- 2 mysql mysql 8192 11月 27 14:21 performance_schema
drwxr-x--- 2 mysql mysql 8192 11月 27 14:21 sys
|
- 编写配置文件,编辑
vim /etc/my.cnf,内容如下:
1
2
3
4
5
6
7
8
9
10
|
[mysqld]
user=mysql
basedir=/opt/mysql
datadir=/data/mysql
server_id=6
port=3306
socket=/tmp/mysql.sock
[mysql]
socket=/tmp/mysql.sock
prompt=3306 [\\d]>
|
prompt参数为登录进MySQL客户端的提示信息,当你use到指定的数据库中,该库名将显示在中括号内。
管理MySQL服务的几种方式
第一种,使用MySQL自带的mysql.server启动/停止/重启MySQL服务。
mysql.server在哪呢?在MySQL安装目录中的support-files目录中:
1
2
3
|
[root@CS opt]# cd /opt/mysql/support-files/
[root@CS support-files]# ls
magic mysqld_multi.server mysql-log-rotate mysql.server
|
我们用mysql.server来管理MySQL:
[root@CS support-files]# ./mysql.server start
Starting MySQL.Logging to '/data/mysql/CS.err'.
SUCCESS!
[root@CS support-files]# ./mysql.server restart
Shutting down MySQL.. SUCCESS!
Starting MySQL. SUCCESS!
[root@CS support-files]# ./mysql.server stop
Shutting down MySQL.. SUCCESS!
第二种,使用service管理MySQL服务。
在centos6中使用service管理服务,所以,我们来演示下如何使用service来管理MySQL服务:
1
2
3
4
5
6
7
8
|
[root@cs opt]# cp /opt/mysql/support-files/mysql.server /etc/init.d/mysqld
[root@CS opt]# service mysqld start
Starting MySQL. SUCCESS!
[root@CS opt]# service mysqld restart
Shutting down MySQL.. SUCCESS!
Starting MySQL.
[root@CS opt]# service mysqld stop
Shutting down MySQL.. SUCCESS!
|
第三种,配置systemctl管理MySQL服务,也是推荐使用的方式。
在centos7版本中,可以使用systemctl来替代service了。
编辑vim /etc/systemd/system/mysqld.service文件,内容如下:
[Unit]
Description=MySQL Server
Documentation=man:mysqld(8)
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target
After=syslog.target
[Install]
WantedBy=multi-user.target
[Service]
User=mysql
Group=mysql
ExecStart=/opt/mysql/bin/mysqld --defaults-file=/etc/my.cnf
LimitNOFILE = 5000
编辑内容中,只需要将ExecStart=/opt/mysql/bin/mysqld的路径改为你的MySQL安装目录即可,其他的照抄。
完事之后,你就可以使用systemctl命令来管理MySQL服务了,可用命令:
systemctl start mysqld
systemctl restart mysqld
systemctl stop mysqld
systemctl status mysqld
systemctl enable mysqld
此时,你可以在任意位置执行mysql来进入MySQL客户端了,但是此时登录还不要密码。
创建密码 此时,我们能正常的启动/停止MySQL服务了,但在初始化MySQL的时候,我们还没有配置登录密码,现在,我们来创建密码。 为root用户(该用户为本地用户)创建密码:
mysqladmin -uroot -p password 123
-p password后面跟你要为root用户设置的密码。
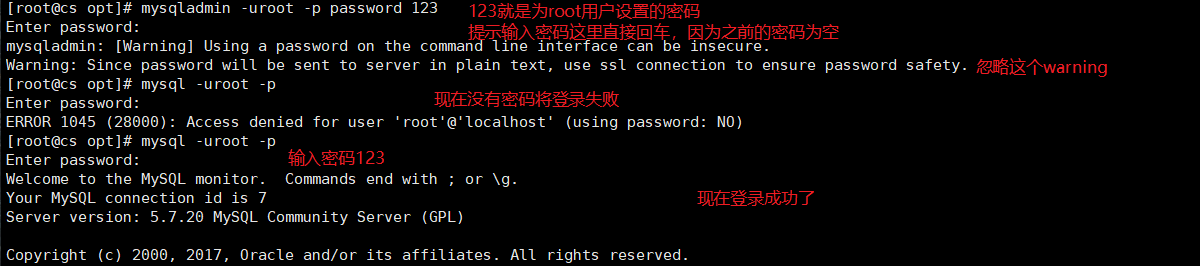
(可选),你也可以使用以下命令查看MySQL监听端口
netstat -lnp|grep 3306
ss -lnp|grep 3306
ps -ef|grep mysqld
用户管理
用户名@白名单
MySQL支持用户名@白名单的方式连接,有以下几种方式:
| 连接方式 | 描述 |
|---|
wordpress@'10.0.0.%' |
只允许10网段连接 |
wordpress@'%' |
所有地址 |
wordpress@'10.0.0.200' |
只允许某一个地址链接 |
wordpress@'localhost' |
只允许本地连接 |
wordpress@'db03' |
只允许别名是db03连接 |
wordpress@'10.0.0.5%' |
只允许IP地址末尾51~59的连接 |
wordpress@'10.0.0/255.255.254.0' |
只允许254这个网段的连接 |
白名单用户管理操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
mysql> create user zhangkai@'localhost' identified by '123';
Query OK, 0 rows affected (0.00 sec)
mysql> select user,host from mysql.user;
+---------------+-----------+
| user | host |
+---------------+-----------+
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
| zhangkai | localhost |
+---------------+-----------+
4 rows in set (0.00 sec)
mysql> alter user zhangkai@'localhost' identified by '1234';
Query OK, 0 rows affected (0.00 sec)
mysql> drop user zhangkai@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> select user,host from mysql.user;
+---------------+-----------+
| user | host |
+---------------+-----------+
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+---------------+-----------+
3 rows in set (0.00 sec)
|
上面示例演示了白名单用户的增删改查的操作。不过这个白名单用户仅能用来登录到MySQL,权限有限!
常用的权限:
ALL:
SELECT,INSERT, UPDATE, DELETE, CREATE, DROP, RELOAD, SHUTDOWN,
PROCESS, FILE, REFERENCES, INDEX, ALTER, SHOW DATABASES, SUPER,
CREATE TEMPORARY TABLES, LOCK TABLES, EXECUTE, REPLICATION SLAVE,
REPLICATION CLIENT, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE,
CREATE USER, EVENT, TRIGGER, CREATE TABLESPACE
ALL : 以上所有权限,一般是普通管理员拥有的
with grant option:超级管理员才具备的,给别的用户授权的功能
创建用户并授权:
1
2
3
4
5
6
7
|
mysql> grant all on database_name.* to zhangkai@'localhost' identified by '123';
-- grant:授权命令
-- all:权限
-- on:为什么对象设置权限
-- wordpress.*:wordpress库下的所有表;需要注意的是,wordpress库如果不存在,该语句也能执行
-- zhangkai@'localhost':指定的用户
-- 修改权限还是使用grant命令来做,grant命令可以反复使用
|
一般的,应用用户的权限应该是有限的,常用的也就是select insert update delete。
PS:在MySQL8.0之后,grant命令有了新特性:
- 创建用户和授权分开
grant命令不再支持创建用户,也不支持修改密码- 授权之前,必须要创建用户
也就是,以后创建用户和授权操作要分开来做。
另外,权限范围有几种写法:
| 权限 | 描述 |
|---|
*.* |
所有库下的所有表,使用与管理员用户 |
wordpress.* |
指定库下的所有表,适用于开发和应用用户 |
wordpress.t1 |
指定库下的指定表,用的不多 |
那么,如何查看用户的权限信息和如何回收权限呢?
1
2
3
4
|
-- 查看用户权限
show grants for zhangkai@'localhost';
-- 回收权限
revoke delete,drop on database@table from zhangkai@'localhost';
|
关于查看用户权限,需要补充一些内容。
- 使用
create user root@'%' identified by '123'创建的用户,仅能用来登录MySQL,别的啥也干不了。
1
2
3
4
5
6
7
|
mysql> show grants for root@'192.168.85.%';
+---------------------------------------------+
| Grants for root@192.168.85.% |
+---------------------------------------------+
| GRANT USAGE ON *.* TO 'root'@'192.168.85.%' |
+---------------------------------------------+
1 row in set (0.00 sec)
|
正如上例的关键字USAGE表示该用户只有登录MySQL权限。想要别的权限,需要自己用有grant权限的账号为该账号授权,因为这个账号此时也没有授权这个权限。
- 关于
WITH GRANT OPTION,当你查看权限时,发现账号拥有ALL权限外,还有 WITH GRANT OPTION权限。
1
2
3
4
5
6
7
8
|
mysql> show grants for root@'localhost';
+---------------------------------------------------------------------+
| Grants for root@localhost |
+---------------------------------------------------------------------+
| GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' WITH GRANT OPTION |
| GRANT PROXY ON ''@'' TO 'root'@'localhost' WITH GRANT OPTION |
+---------------------------------------------------------------------+
2 rows in set (0.00 sec)
|
WITH GRANT OPTION表示该用户可以将自己拥有的权限授权给别人。
注意,如果在授权时没有加WITH GRANT OPTION参数,就表示该账户的权限只能自己用,而不能赋予别人,所以你在授权时要考虑好加不加WITH GRANT OPTION参数。
1
2
|
grant all on *.* to root@'%' identified by '123';
grant all on *.* to root@'%' identified by '123' with grant option;
|
也就是,上面两条命令你要事情况而选择。
本地管理员用户密码忘记了怎么办
解决思路是:
- 关闭MySQL服务
mysqld_safe模式启动,即关闭MySQL的用户密码验证模块,也就是不加载授权表,然后禁止远程连接,仅能通过本地socket链接- 无密码登登录到MySQL
- 修改密码
- 重启MySQL
流程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
[root@cs mysql]# systemctl stop mysqld
[root@cs mysql]# mysqld_safe --skip-grant-tables --skip-networking &
[root@cs mysql]# mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.7.20 MySQL Community Server (GPL)
Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> alter user root@'localhost' identified by '123';
Query OK, 0 rows affected (0.00 sec)
mysql> exit;
Bye
[root@cs mysql]# pkill mysqld
[root@cs mysql]# systemctl start mysqld
|
相关参数解释:
--skip-grant-tables:关闭授权表,这样就可以无验证登录了。--skip-networking:关闭TCP/IP,该参数的目的是只能本地通过socket连接登录,保证修改密码时的安全性。&是后台执行。- 至于在修改密码前的
flush privileges操作是因为修改密码还是要使用授权表,但是由于mysqld_safe模式启动授权表没有从磁盘加载到内存,所以直接执行alter命令会失败,所以要使用flush privileges命令将授权表加载到内存中,才能修改密码成功。
连接管理
连接参数
前文中已经说过,MySQL支持socket和TCP/IP两种连接方式。
[root@cs mysql]# mysql -uroot -p -S /tmp/mysql.sock
Enter password:
-S指定socket来连接;一般我们不加-S就可以登录到MySQL中,是因为MySQL使用的socket文件默认的存放在/tmp/mysql.sock中,或者你在配置文件中指定,这样我们不指定也能找到socket文件。另外,一般使用socket登录都是本地登录,所以,你要保证你的登录用户是有localhost的权限的。
而使用TCP/IP的方式就是:
[root@cs mysql]# mysql -uroot -p -h192.168.85.133 -P3306
Enter password:
其他常用的参数:
-u:用户名。-p:密码。-h:IP。-P:port。-S:socket文件。-e:免交互执行命令。<:导入SQL脚本。
PS:
- 参数和值之间可以挨着也可以空格分割。
- 如果
TCP/IP和socket连接同时使用,默认TCP/IP方式优先。
1
2
3
4
5
6
7
8
9
|
[root@cs mysql]# mysql -uzhangkai -p -h 192.168.85.133 -P3306 -S /tmp/mysql.sock
Enter password:
mysql> show processlist;
+----+----------+----------+------+---------+------+----------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+----------+----------+------+---------+------+----------+------------------+
| 7 | zhangkai | cs:59128 | NULL | Query | 0 | starting | show processlist |
+----+----------+----------+------+---------+------+----------+------------------+
1 row in set (0.00 sec)
|
在外部执行MySQL的内部命令,如shell脚本中,可以使用-e参数:
1
2
3
4
5
6
7
|
[root@cs mysql]# mysql -uzhangkai -p123 -h 192.168.85.133 -P3306 -e "show processlist;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+----+----------+----------+------+---------+------+----------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+----------+----------+------+---------+------+----------+------------------+
| 8 | zhangkai | cs:59130 | NULL | Query | 0 | starting | show processlist |
+----+----------+----------+------+---------+------+----------+------------------+
|
-e后跟引号,引号内可以写想要执行的命令。
如果有一些SQL脚本要执行,可以使用<符号来处理,首先准备一个data.sql文件,文件内容如下:
1
|
create database data_test;
|
然后导入到数据库中即可:
[root@cs home]# ls
data.sql
[root@cs home]# cat data.sql
create database data_test;
[root@cs home]# mysql -uroot -p <data.sql
Enter password:
[root@cs home]# mysql -uroot -p -e"show databases;"
Enter password:
+--------------------+
| Database |
+--------------------+
| information_schema |
| data_test |
| mysql |
| performance_schema |
| sys |
+--------------------+
此时,如果你进入MySQL中,就可以查询到SQL脚本创建的data_test数据库了。
多种启动方式

如上图,在centos6中,我们可以通过service来调用mysql.server脚本来启动MySQL,而mysql.server脚本内部会调用mysqld_safe脚本来调用mysqld这个启动程序脚本来 启动MySQL服务。mysqld_safe的作用是监控mysqld的运行状态。我们也可以通过./bin/mysqld_safe &临时启动mysqld_safe来完成一些操作。
另外在centos7中,可以直接是使用systemctl来直接调用mysqld启动MySQL,而且centos7中也可以配置service的启动方式。
当然,无论是systemctl,还是service的启动方式,都是相对固定的start、stop这些操作,那有些情况下需要临时维护或者做其他的操作,就需要用到mysqld_safe模式或者直接启动mysqld了。
初始化配置
初始化配置的目的是:干预MySQL的启动,或者干预客户端的连接,说白了就是让MySQL按照我们的意愿来启动。
初始化配置都有哪些方法:
- 预编译,这个方法可以pass掉了,因为我们一般都是下载二进制的源码包。
- 配置文件,也就是
/etc/my.cnf文件,适用于所有的启动方式。
- 命令行,直接在命令行启动时添加各种参数,当然,这种参数仅限于
mysqld_safe、mysqld这两种方式。
综上所述,推荐使用配置文件的的方式来做数据库初始化启动。
先来看,MySQL在启动时,都(默认)读取了哪些配置文件:
[root@cs ~]# mysqld --help --verbose | grep my.cnf
/etc/my.cnf /etc/mysql/my.cnf /usr/local/mysql/etc/my.cnf ~/.my.cnf
my.cnf, $MYSQL_TCP_PORT, /etc/services, built-in default
如果多个配置文件有相同的参数,那就会以最后读取到的为准,也就是~/.my.cnf文件为准。但是如果启动时加入--defaults=/etc/my.cnf时,会以你defaultsd的路径为准,其他的文件就不读取了。
配置文件的介绍
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
[标签]
配置项=xxxx
# 标签的类型主要包括,服务端和客户端的定义
# 服务端包括以下几类:
[mysqld]
[mysqld_safe]
[server] # 所有服务端的统称,不过不建议使用
# 客户端包括:
[mysql]
[mysqldump] # 备份用
[client]
# 来个示例
[root@cs ~]# cat /etc/my.cnf
[mysqld]
user=mysql # mysql工作时的用户
basedir=/opt/mysql # mysql所在的目录,必须设定的参数
datadir=/data/mysql # mysql数据存放的目录,必须设定的参数
server_id=6
port=3306
socket=/tmp/mysql.sock # 服务器端socket所在路径
log_error=/data/mysql/mysql.log # 错误日志
[mysql]
socket=/tmp/mysql.sock # 必须参数
# prompt=3306 [\\d]> # 提示符
# user=root # 登录的用户名和密码,这里不建议用,不安全
# password=123
|
需要补充的是,带下划线的参数,如server_id,在MySQL5.5版本以前可以写成中横线的形式,但是中横线这种方式存在问题,所以后续版本都统一使用下划线这种连接方式(当然,为了兼容,也支持中横线的形式)。
另外,关于socket可能的报错,就是找不到socket文件,该报错的原因:
- 数据库没启动,没启动没有生成socket文件。
- 启动时,指定的socket文件路径不对,也可能是配置文件中的路径写错了。
server_id参数,主从复制用,可以简单理解在MySQL5.7以后必加的一个参数,值是1~65535之间的任意数字,并且跟其他的实例区分开。
DDL操作
本小节主要介绍MySQL中的库和表的操作。
库操作
MySQL自带的数据库
先来看MySQL中自带的库有哪些:
1
2
3
4
5
6
7
8
9
10
|
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.01 sec)
|
各库解释如下:
-
information_schema,虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息、列信息、权限信息、字符信息等。
-
performance_schema, MySQL 5.5开始新增一个数据库,主要用于收集数据库服务器性能参数,记录处理查询请求时发生的各种事件、锁等现象 。
-
mysql,授权库,主要存储系统用户的权限信息。
-
sys库所有的数据源来自performance_schema,目标是把performance_schema的把复杂度降低,让DBA能更好的阅读这个库里的内容。让DBA更快的了解数据库的运行情况。
-
test,MySQL数据库系统自动创建的测试数据库。test库在MySQL中特殊存在,一般部署完mysql后应当删除该库,并规定不能创建以test和test_字符开头的数据库。因为在MySQL中,test库对任意用户都有管理员权限,因此,线上数据库不要用test。如果已有test,添加用户时想要禁止对test库的权限,可以在mysql.db表中添加这个新用户,禁止所有权限,或者删除该表中user为空的记录,并刷新权限
select * from mysql.db where db='test' \G ;
创建数据库
创建数据库语法:
1
|
CREATE DATABASE database_name;
|
一般的,在MySQL中,关键字等信息推荐大写…….
数据库的命名规范:
- 可以由字母、数字、下划线、@、#、$组成。
- 区分大小写,库名不能大写,也不建议以大写字母开头。
- 首字母不能是数字。
- 数据库名具有唯一性,也就是不能重名。
- 应该避开关键字,如select等。
- 不能单独使用数字。
- 最长不超过128位。
- 一般库名应该和业务相关。
- 也不要创建以
test火test_开头的数据库,原因在前面说过了。
关于字符集,在MySQL中,数据库默认的字符集是拉丁语:
1
2
3
4
5
6
7
|
mysql> show create database mysql;
+----------+------------------------------------------------------------------+
| Database | Create Database |
+----------+------------------------------------------------------------------+
| mysql | CREATE DATABASE `mysql` /*!40100 DEFAULT CHARACTER SET latin1 */ |
+----------+------------------------------------------------------------------+
1 row in set (0.00 sec)
|
但我们用的更多的是utf8或者是utf8mb4,所以我们一般在创建数据库库的时候还需要指定字符集:
1
2
3
4
5
6
7
8
9
10
|
mysql> CREATE DATABASE t1 CHARSET utf8;
Query OK, 1 row affected (0.00 sec)
mysql> show create database t1;
+----------+-------------------------------------------------------------+
| Database | Create Database |
+----------+-------------------------------------------------------------+
| t1 | CREATE DATABASE `t1` /*!40100 DEFAULT CHARACTER SET utf8 */ |
+----------+-------------------------------------------------------------+
1 row in set (0.00 sec)
|
除了utf8和utf8mb4,MySQL还支持其他的字符集,我们来查看MySQL中支持的所有字符集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
mysql> SHOW CHARSET;
+----------+---------------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+---------------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
| cp850 | DOS West European | cp850_general_ci | 1 |
| hp8 | HP West European | hp8_english_ci | 1 |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
| ascii | US ASCII | ascii_general_ci | 1 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 |
| tis620 | TIS620 Thai | tis620_thai_ci | 1 |
| euckr | EUC-KR Korean | euckr_korean_ci | 2 |
| koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
| greek | ISO 8859-7 Greek | greek_general_ci | 1 |
| cp1250 | Windows Central European | cp1250_general_ci | 1 |
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 |
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
| cp866 | DOS Russian | cp866_general_ci | 1 |
| keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 |
| macce | Mac Central European | macce_general_ci | 1 |
| macroman | Mac West European | macroman_general_ci | 1 |
| cp852 | DOS Central European | cp852_general_ci | 1 |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
| cp1251 | Windows Cyrillic | cp1251_general_ci | 1 |
| utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
| utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 |
| cp1256 | Windows Arabic | cp1256_general_ci | 1 |
| cp1257 | Windows Baltic | cp1257_general_ci | 1 |
| utf32 | UTF-32 Unicode | utf32_general_ci | 4 |
| binary | Binary pseudo charset | binary | 1 |
| geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
| gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 |
+----------+---------------------------------+---------------------+--------+
41 rows in set (0.00 sec)
|
ci是case insensitive即"大小写不敏感", a 和 A 会在字符判断中会被当做一样的。
借此机会我们再来简单说说字符集中的校验规则(排序规则)。
查询字符集校验规则:
SHOW COLLATION;
这里以utf8来简单说说:
utf8_unicode_ci和utf8_general_ci对中英文来说没有实质的差别。utf8_general_ci::校对速度快,但准确度稍差。utf8_unicode_ci: 准确度高,但校对速度稍慢;若数据库中有德语、法语或者俄语需求,需使用utf8_unicode_ci。utf8_bin:将字符串中的每一个字符用二进制数据存储,区分大小写。
创建大小写敏感的数据库:
1
|
CREATE DATABASE database_name CHARSET utf8mb4 COLLATE utf8mb4_bin;
|
关于utf8和utf8mb4的区别:
MySQL在 5.5.3 之后增加了 utf8mb4 字符编码,mb4即 most bytes 4。简单说 utf8mb4 是 utf8 的超集并完全兼容utf8,能够用四个字节存储更多的字符。
但抛开数据库,标准的 UTF-8 字符集编码是可以用 1~4 个字节去编码21位字符,这几乎包含了是世界上所有能看见的语言了。然而在MySQL里实现的utf8最长使用3个字节,也就是只支持到了 Unicode 中的 基本多文本平面(U 0000至U FFFF),包含了控制符、拉丁文,中、日、韩等绝大多数国际字符,但并不是所有,最常见的就算现在手机端常用的表情字符 emoji和一些不常用的汉字,如 “墅” ,这些需要四个字节才能编码出来。
注:QQ里面的内置的表情不算,它是通过特殊映射到的一个gif图片。一般输入法自带的就是。
也就是当你的数据库里要求能够存入这些表情或宽字符时,可以把字段定义为 utf8mb4,同时要注意连接字符集也要设置为utf8mb4,否则在 严格模式 下会出现 Incorrect string value: /xF0/xA1/x8B/xBE/xE5/xA2… for column 'name'这样的错误,非严格模式下此后的数据会被截断。
create database & create schema
你在一些地方,可能会看到如下建库语句:
不要迷惑,关于create database和create schema语句,在MySQL中是等价的;下面摘自MySQL8.0官网:https://dev.mysql.com/doc/refman/8.0/en/create-database.html的解释:
CREATE DATABASE creates a database with the given name. To use this statement, you need the CREATE privilege for the database. CREATE SCHEMA is a synonym for CREATE DATABASE.
删除数据库
注意,生产中开发人员"禁止删库",这种操作应该交给专门的人员来操作,或者向上级申请。
修改
1
|
alter database t1 charset utf8;
|
注意,修改字符集时,修改后的字符集一定是原字符集的严格超集。
查看数据库
1
2
3
4
|
show create databse database_name; # 查看数据库创建信息
show databases; # 查看所有的数据库
use database_name; # 进入创建的数据库
use database_name; # 切换数据库,且进入某个数据库无法回退
|
表操作
MySQL中的表你可以理解为是一个有严格规范的excel表格:

表中的id、name、age、gender是字段,其余每一行称为记录。
创建表
基本语法:
1
2
3
4
5
6
|
-- 语法:
CREATE TABLE 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);
|
关于数据类型和约束,我们在下个章节会展开学习。
注意:
- 在同一张表中,字段名是不能相同。
- 宽度和约束条件可选。
- 字段名和类型是必须的。
示例:
1
2
3
4
5
6
7
8
9
|
USE school;
CREATE TABLE stu(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(255) NOT NULL COMMENT '姓名',
sage TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '年龄',
sgender ENUM('m','f','n') NOT NULL DEFAULT 'n' COMMENT '性别',
sfz CHAR(18) NOT NULL UNIQUE COMMENT '身份证',
intime TIMESTAMP NOT NULL DEFAULT NOW() COMMENT '入学时间'
) ENGINE=INNODB CHARSET=utf8 COMMENT '学生表';
|
USE语句相当于进入一个目录,然后CREATE TABLE语句相当于创建一个excel表格,然后再这个表格中,针对每个字段有不同的规定和注释,最后再指定这个表格的文件系统(存储引擎)和字符编码。
注意,最后一个字段后无需跟逗号。
建表规范
- 表名小写
- 不能是数字开头
- 注意字符集和存储引擎
- 表名和业务有关
- 选择合适的数据类型
- 每个列都要有注释
- 每个列设置为非空,无法保证非空,用0来填充
查看表结构
首先,我们应该进入某个数据库中use database_name;
1
2
3
4
5
6
7
|
show tables; # 查看所有表
show create table score; # 查看指定表的表结构,信息比较全面
show create table score \G # 上同,格式化整理
show create table score \G; # 上同,结尾加分号也行,但会提示No query specified,忘掉它吧
desc score; # 查看表的字段信息
describe score; # 上同,desc为其缩写。
create table t1 like t2; -- 复制结构一样的空表
|
删除
1
2
|
use school;
drop table t1;
|
注意,生产中"禁止"使用,小心造成事故。
修改
修改这里无非就是修改表和其中的字段。
修改表操作
- 修改表名:
1
|
ALTER TABLE <旧表名> RENAME [TO] <新表名>;
|
其中TO为可选参数,使用与否均不影响结果。
- 修改表字符集:
1
|
ALTER TABLE t1 DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
|
- 修改表引擎(慎重使用):
1
|
ALTER TABLE table_name engine=innodb;
|
修改字段操作
- 修改字段名称和属性:
1
2
|
ALTER TABLE stu CHANGE sgender sg ENUM('m','f','n') NOT NULL DEFAULT 'm' COMMENT '性别';
-- change操作在修改字段名称的同时也可以修改其属性
|
- 添加字段:
1
2
3
4
5
6
|
-- 默认添加到最后
ALTER TABLE stu ADD qq VARCHAR(20) NOT NULL UNIQUE COMMENT 'QQ号';
-- 添加到最前面
ALTER TABLE stu ADD nickname VARCHAR(32) NOT NULL COMMENT '昵称' FIRST;
-- 添加到指定字段之后,注意,并没有添加到指定字段之前的操作
ALTER TABLE stu ADD wechat VARCHAR(64) NOT NULL UNIQUE COMMENT '微信号' AFTER sname;
|
- 删除字段(慎重操作):
1
2
3
|
ALTER TABLE stu DROP qq;
ALTER TABLE stu DROP wechat;
ALTER TABLE stu DROP nickname;
|
- 修改字段的属性:
1
2
3
|
ALTER TABLE stu MODIFY sname VARCHAR(128) NOT NULL COMMENT '姓名';
-- 注意,该操作会覆盖掉原来的所有属性,所以该操作一定要把原来不变的属性都加上
-- modify操作只用来修改字段属性
|
- 修改字段字符集:
1
|
ALTER TABLE t1 CHANGE title title VARCHAR(100) CHARACTER SET utf8 COLLATE utf8_general_ci;
|
注意,修改表结构的操作,MySQL8.0之前的版本默认是会锁表的,所以,不要在业务高峰期做这些操作,而是选择在晚间进行操作,当然,我们也可以在晚间使用在线的DDL工具来处理这些事情,避免锁表对业务造成影响。
常用的在线DDL工具:
- MySQL的Online。
- pt-osc,推荐使用。
复制表
最后,再来看看复制表相关的操作:
- 复制一份一摸一样的表:
1
2
|
-- 创建一个a2表,表结构跟a1一样,这里复制的a2表跟a1的表结构是一样的,但不会复制a1表中的记录
CREATE TABLE a2 LIKE a1;
|
- 创建一个表,复制另一张表的指定字段和记录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
-- 注意,自己创建的表字段一定要跟被复制表字段一致
CREATE TABLE a3(
HOST CHAR(60),
USER CHAR(16),
PRIMARY KEY(HOST,USER) -- 注意,key不会复制: 主键、外键和索引,所以这里需要自己建立主键
)
SELECT
HOST,USER
FROM mysql.user;
-- 如果出现自己创建的表字段跟被复制的表字段不一致的情况,那么创建的表就是自己创建的字段和被复制的表的指定字段同时存在
CREATE TABLE a4(
ip CHAR(60) DEFAULT '1.1.1.1',
username CHAR(16) DEFAULT 'root'
-- primary key(ip,username) -- 因为新表会拷贝记录,所以上面两个字段有默认值,但是由于建立联合主键,默认值都一样又建不了,所以,这也是要考虑的地方
)
SELECT HOST,USER
FROM mysql.user;
-- 最终,a4表会有4个字段,ip,username,host,user,即当复制的字段不一致时,被复制的表字段会追加到当前表中
|
- 创建一个表,复制另一张表的指定字段和记录,但是创建的表字段又想不跟被复制表字段不一致:
1
2
3
4
5
6
7
|
CREATE TABLE a5(
ip CHAR(60),
username CHAR(16),
PRIMARY KEY(ip,username)
)
SELECT HOST AS ip,USER AS username
FROM mysql.user;
|
记录操作(DML)
现在,就要对表中的记录进行增删改这些操作了。
还是那张表:
1
2
3
4
5
6
7
8
9
|
USE school;
CREATE TABLE stu(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(255) NOT NULL COMMENT '姓名',
sage TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '年龄',
sgender ENUM('m','f','n') NOT NULL DEFAULT 'n' COMMENT '性别',
sfz CHAR(18) NOT NULL UNIQUE COMMENT '身份证',
intime TIMESTAMP NOT NULL DEFAULT NOW() COMMENT '入学时间'
) ENGINE=INNODB CHARSET=utf8 COMMENT '学生表';
|
insert
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
-- 按照指定的字段顺序插入一条数据,也是标准的插入数据格式
INSERT INTO stu(id,sname,sage,sg,sfz,intime) VALUE (1,'张三',18,'m','1100',NOW());
-- 如果按照字段顺序插入的话,可以省略字段,直接插入值
INSERT INTO stu VALUE(2,'张三2',18,'n','1101',NOW());
-- 针对性的插入,根据字段的属性发现,要么是自增长,要么是有默认值,所以这里直接插入必须插入的字段即可
INSERT INTO stu(sname,sage,sfz) VALUE('张三3',18,'1102');
-- 一次插入多条数据
INSERT INTO stu(sname,sage,sfz)
VALUES
('张三4',18,'1103'),
('张三5',18,'1104'),
('张三6',18,'1105'); -- 最后一个括号后不用逗号,直接跟结尾符号很分号即可
-- 可以使用下面语句查询插入的数据
SELECT * FROM stu;
|
update
首先来说一个不要轻易使用的命令,即对指定字段进行全表更新:
1
|
UPDATE stu SET sname='李四';
|
经过set之后,全表的sname都会变成李四,如果数据量较大,非常影响性能。
根据条件更新:
1
2
3
4
|
UPDATE stu SET sname='王五' WHERE id=3;
-- 修改id<3的记录中的sname的值,还可以使用大于符号,不等于符号
UPDATE stu SET sname='赵六' WHERE id<3;
|
条件选择一般选择具有唯一性的,如果条件不唯一,则所有符合条件的记录都将受影响,如:
1
|
UPDATE stu SET sname='赵六' WHERE sg='m';
|
注意,update必须要加where条件,而且操作要慎重。
delete
危险命令!
1
2
|
DELETE FROM stu; -- 表中所有的记录都将被逐行删除,性能差,不要用
DELETE FROM stu WHERE id=1;
|
注意,delete命令删除是逻辑删除,不会释放磁盘空间!
现在我们再说另一条命令:
1
2
|
TRUNCATE TABLE stu;
-- 该命令不支持where条件
|
truncate命令清空表后会释放磁盘空间。
小结:
delete命令(DML操作)只是在逻辑层面删除了记录,但是占用的磁盘空间并没有释放;另外该表的建表结构还在。truncate命令(DDL操作)清空表的数据页,保留表的建表结构。drop删表操作就是逻辑和磁盘上都会删除。
为了解决delete的缺点,我们采用伪删除来解决,即使用update来代替delete,思路是为表添加一个状态字段,如果有需要删除的,就改下状态,后续的查询也根据状态来查看:
1
2
3
4
5
6
7
8
|
-- 1. 添加状态字段
ALTER TABLE stu ADD state TINYINT NOT NULL DEFAULT 1;
-- 2. update替代delete
UPDATE stu SET state=0 WHERE id=3;
-- 3. 业务查询语句
SELECT * FROM stu WHERE state=1;
|
数据类型
从本小节开始,就开始为学习如何操作记录做准备了。
我们先来学习,MySQL中常用的数据类型。
在MySQL中,我们需要了解的数据类型共有以下几种:
- 数值类型。
- 日期类型。
- 字符串类型。
- ENUM和SET类型。
我们一一来看看吧。
数值类型
MySQL支持所有标准SQL数值类型。包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)。
关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。
MySQL支持的整数类型有TINYINT、SMALLINT、MEDIUMINT、INT和BIGINT。下面的表显示了需要的每个整数类型的存储和范围。
对于小数的表示,MYSQL分为两种方式:浮点数和定点数。浮点数包括float(单精度)和double(双精度),而定点数只有decimal一种,在mysql中以字符串的形式存放,比浮点数更精确,适合用来表示货币等精度高的数据。
BIT数据类型保存位字段值,并且支持MyISAM、MEMORY、InnoDB和BDB表。
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|
| TINYINT |
1字节 |
(-128, 127) |
(0, 255) |
小整数值 |
| SMALLINT |
2字节 |
(-32768, 327667) |
(0, 65535) |
大整数值 |
| MEDIUMINT |
3字节 |
(-8388608, 8388697) |
(0, 16777215) |
大整数值 |
| INT or INTEGER |
4字节 |
(-2147483648, 2147483647) |
(0, 4294967295) |
大整数值 |
| BIGINT |
8字节 |
(-9 233 372 036 854 775 808,9 223 372 036 854 775 807) |
(0,18 446 744 073 709 551 615) |
极大整数值 |
| FLOAT |
4 字节 float(255,30) |
(-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) |
0,(1.175 494 351 E-38,3.402 823 466 E+38) |
单精度浮点数值 |
| DOUBLE |
8 字节double(255,30) |
(-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) |
0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) |
双精度浮点数值 |
| DECIMAL |
对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 |
依赖于M和D的值 |
依赖于M和D的值 |
小数值 |
int类型
这里我们先以int为例展开讨论。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
create table t1(n1 int(4));
desc t1;
+-------+--------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------+------+-----+---------+-------+
| n1 | int(4) | YES | | NULL | |
+-------+--------+------+-----+---------+-------+
insert into t1 values(11);
insert into t1 values(111111);
select n1 from t1;
+--------+
| n1 |
+--------+
| 11 |
| 111111 |
+--------+
|
由最后的查看结果,我们为int类型设定的宽度为4,结果插入一个6位的也行。这是怎么回事?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
create table t2(n1 int(4) zerofill);
desc t2;
+-------+--------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------------------+------+-----+---------+-------+
| n1 | int(4) unsigned zerofill | YES | | NULL | |
+-------+--------------------------+------+-----+---------+-------+
insert into t2 values(11);
insert into t2 values(111111);
select n1 from t2;
+--------+
| n1 |
+--------+
| 0011 |
| 111111 |
+--------+
|
可以看到,我们在创建表的时候,为n1字段加上zerofill,表示不够4位就填充0。而最后的查询结果告诉我们,如果为int类型指定宽度,则是显示字符的宽度(字符数量),超过这个限制也会显示。
而查询表结构的时候,有个unsigned,这是无符号的类型。那这是什么意思呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
create table t3(n1 int);
desc t3;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| n1 | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
insert into t3 values(11111111111111111111111111);
insert into t3 values(-11111111111111111111111111);
select n1 from t3;
+-------------+
| n1 |
+-------------+
| 2147483647 |
| -2147483648 |
+-------------+
|
首先,desc告诉我们int类型的默认显示宽度是11位,而最大表示数值范围是2147483647,如果你插入的数据是超过这个范围的话。而2147483647的显示宽度是10位,为什么不是默认的11位呢?这是因为int类型默认类型是有符号的,而有符号的就要考虑正号和负号,而符号仅用1位就能表示。
原因如下:
int的存储宽度是4个Bytes,即32个bit,即2^32
无符号最大值为:4294967296-1
有符号最大值:2147483648-1
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完全,所以int类型默认的显示宽度为11是非常合理的。
那么如何设置一个无符号的呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
create table t4(n1 int unsigned);
desc t4;
+-------+------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------+------+-----+---------+-------+
| n1 | int(10) unsigned | YES | | NULL | |
+-------+------------------+------+-----+---------+-------+
insert into t4 values(11111111111111111111111111);
select n1 from t4;
+------------+
| n1 |
+------------+
| 4294967295 |
+------------+
|
无符号的需要在int类型指定unsigned。结果也是没错的。都最开始列举的表中数据一致。
最后:int类型,其实没有必要指定显示宽度,使用默认的就行;如果你的整数范围超过int类型范围,请选用别的数据类型;并且默认的,我们创建的int类型是有符号类型。
float类型
先来看定义:
FLOAT[M, D] [UNSIGNED] [ZEROFILL]
DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
DECIMAL[(m[,d])] [unsigned] [zerofill]
float表示单精度浮点数(非准确小数值),M表示数字总个数,最大值是255;D是小数点后的数字个数,最大值30。也就是说,如果float(255,30)意思是,小数位是30位,而整数位就不是255了,而是255-30=225位。它的精准度:随着小数的增多,精度变得不准确。
双精度(double)浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30。它的精准度:随着小数的增多,精度比float要高,但也会变得不准确。
而decimal的准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。它的精准度:随着小数的增多,精度始终准确;对于精确数值计算时需要用此类型。decaimal能够存储精确值的原因在于其内部按照字符串存储。
1
2
3
4
5
6
7
8
9
10
11
|
create table f1(weight float(256,30));
ERROR 1439 (42000): Display width out of range for column 'weight' (max = 255) # 说显示宽度超过了255
create table f2(weight float(255,31));
ERROR 1425 (42000): Too big scale 31 specified for column 'weight'. Maximum is 30. # 告诉我们小数点后的位数最多30位
create table f3(weight float(255,30)); # 这样就没问题了
desc f3;
+--------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------+------+-----+---------+-------+
| weight | float(255,30) | YES | | NULL | |
+--------+---------------+------+-----+---------+-------+
|
首先,我们创建的float类型是有符号类型。
同样的,你想创建一个无符号的,也要指定unsigned。
1
2
3
4
5
6
7
8
|
create table f4(weight float(255,30) unsigned);
desc f4;
+--------+------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+------------------------+------+-----+---------+-------+
| weight | float(255,30) unsigned | YES | | NULL | |
+--------+------------------------+------+-----+---------+-------+
1 row in set (0.01 sec)
|
在使用浮点型的数据时,我们考虑的核心是关注它们的精度。来看对比。
1
2
3
4
5
6
|
create table f5(weight float(255,30) unsigned);
create table f6(weight double(255, 30) unsigned);
create table f7(weight decimal(65, 30) unsigned);
insert into f5 values(1.111111111111111111111111111111111111111111111111111);
insert into f6 values(1.111111111111111111111111111111111111111111111111111);
insert into f7 values(1.111111111111111111111111111111111111111111111111111);
|
我们创建三张不同类型的表,并插入一些数据,并且这些小数位都超过30位。来观察他们的精度:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
select weight from f5;
+----------------------------------+
| weight |
+----------------------------------+
| 1.111111164093017600000000000000 |
+----------------------------------+
select weight from f6;
+----------------------------------+
| weight |
+----------------------------------+
| 1.111111111111111200000000000000 |
+----------------------------------+
select weight from f7;
+----------------------------------+
| weight |
+----------------------------------+
| 1.111111111111111111111111111111 |
+----------------------------------+
|
由各自的查询结果可以看到,float类型的精度只有前7位是精确的;double类型的精度是15位;而decimal则保留完整的精度,毕竟是字符串形式的存储么。 但是decimal虽然精度较高,但是它也是有限制的,因为它的数字总大小为65位,所以抛出小数位的30位,还剩30位整数位。
最后,最后,这里只是说的显示宽度仅是在int中使用,其他数据类型宽度是存储限制。比如BIT类型。
BIT
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
create table b1(b bit(1));
desc b1;
+-------+--------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------+------+-----+---------+-------+
| b | bit(1) | YES | | NULL | |
+-------+--------+------+-----+---------+-------+
insert into b1 values(0);
insert into b1 values(1);
insert into b1 values(2);
select b from b1;
+------+
| b |
+------+
| |
| � |
| � |
+------+
|
首先了解,字段b的类型是bit,宽度是1,那能表示多少数值呢,一个bit,只能表示0和1两个。但是通过查询发现,跟我们想要的结果不一样。
这是为什么,bit类型存储是以二进制存储到硬盘上的。所以,我们想要查询到我们想要的值,还要借助MySQL提供给我们的函数bin()和hex(),意思是返回二进制值的字符串形式表示和十六进制的表示形式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
select bin(b) from b1;
+--------+
| bin(b) |
+--------+
| 0 |
| 1 |
| 1 |
select hex(b) from b1;
+--------+
| hex(b) |
+--------+
| 0 |
| 1 |
| 1 |
+--------+
|
可以看到,字段b的bit(1)类型只能表示0和1,而插入的2超出了范围。所以,你在用的时候,需要注意:
1
2
3
4
5
6
7
8
|
create table b2(b bit(2));
insert into b2 values(2);
select bin(b) from b2;
+--------+
| bin(b) |
+--------+
| 10 |
+--------+
|
可以看到,2的二进制形式是10。
时间类型
日期类型有:
- DATE(YYYY-MM-DD(1000-01-01/9999-12-31)),2019-07-31,出生年月日
- TIME(HH:MM:SS('-838:59:59'/‘838:59:59’)),16:40:40,下班时间
- DATETIME(YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y))、2019-07-31 16:40:40,注册时间、文章发布时间、员工入职时间
- TIMESTAMP(YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时))、2019-07-31 16:40:40
- YEAR(YYYY(1901/2155))、2019,历史大事件,出生年
来个示例:
1
2
3
4
5
6
7
8
9
10
11
12
|
create tabled1(
born_date date,
get_time time,
reg_time datetime,
born_year year # 最后一个字段后面不要有逗号
);
insert into d1 values(
'1999-11-11',
'18:30:00',
'2018-11-11 11:11:11',
'1999' # 不要写成18/30/30
);
|
来查询:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
desc d1;
+-----------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+----------+------+-----+---------+-------+
| born_date | date | YES | | NULL | |
| get_time | time | YES | | NULL | |
| reg_time | datetime | YES | | NULL | |
| born_year | year(4) | YES | | NULL | |
+-----------+----------+------+-----+---------+-------+
select * from d1;
+------------+----------+---------------------+-----------+
| born_date | get_time | reg_time | born_year |
+------------+----------+---------------------+-----------+
| 1999-11-11 | 18:30:00 | 2018-11-11 11:11:11 | 1999 |
+------------+----------+---------------------+-----------+
|
再来掌握一个now()函数:
1
2
3
4
5
6
7
|
insert into d1 values(now(), now(), now(), now());
select * from d1;
+------------+----------+---------------------+-----------+
| born_date | get_time | reg_time | born_year |
+------------+----------+---------------------+-----------+
| 1999-11-11 | 18:30:00 | 2018-11-11 11:11:11 | 1999 |
| 2019-07-31 | 16:57:51 | 2019-07-31 16:57:51 | 2019 |
|
由第二行记录可以发现,各类型都按照自己的规则截取所需的日期数据。
了解:datetime与timestamp的区别
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
create table d2(x datetime, y timestamp);
desc d2;
+-------+-----------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------+------+-----+-------------------+-----------------------------+
| x | datetime | YES | | NULL | |
| y | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+-------+-----------+------+-----+-------------------+-----------------------------+
insert into d2 values(Null, Null);
insert into d2 values('1111-11-11','1111-11-11');
select * from d2;
+---------------------+---------------------+
| x | y |
+---------------------+---------------------+
| NULL | 2019-07-31 17:05:43 |
| 1111-11-11 00:00:00 | 0000-00-00 00:00:00 |
+---------------------+---------------------+
|
通过上述验证分析,虽然这两种日期格式,都能满足我们大多数使用场景,但是在某些情况下,它们也有自己的优劣之分,来看看它们的区别:
- DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年。
- DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。在mysql服务器,操作系统以及客户端连接都有时区的设置。
- DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP比DATETIME的空间利用率更高。
- DATETIME的默认值为null,TIMESTAMP的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP),如果不做特殊处理,并且update语句中没有指定该列的更新值,则默认更新为当前时间。
字符串类型
字符串类型这里需要重点掌握的就是char和varchar两个,存放名字、性别、密码、文本内容等等。
先看它们的区别,注意,长度指的是字符的长度:
-
char,定长,简单粗暴,浪费空间,存取速度快。
- 字符长度范围:0~255,一个汉字是一个字符,utf8编码一个普通汉字占用3个字节。
- 存储:如果存储的值,不满足指定的长度时,会往右填充空格来满足长度,例如指定长度为10,存储大于10个字符报错,小于10个字符会用空格填充,凑够十个字符。
- 查询(或称检索):查询出的结果会自动删除尾部的空格,除非我们打开
pad_char_to_full_length SQL模式
1
|
set sql_mode = 'PAD_CHAR_TO_FULL_LENGTH'
|
char VS varchar:存储范围验证
1
2
3
4
5
6
7
|
create table c1(s char(256));
ERROR 1074 (42000): Column length too big for column 's' (max = 255); use BLOB or TEXT instead
create table c2(s char(255));
create table c3(s varchar(21845));
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
create table c4(s varchar(21844));
create table c5(s varchar(65534));
|
通过打印结果,可以看到,char类型,如果长度超过255,就提示我们字段长度最大是255;varchar的列长度如果超过21844,提示我们varchar类型的最大行大小为65535。
但是最后的c5却成功创建,这是为什么呢?我们来看它的表结构:
1
2
3
4
5
6
7
8
9
10
11
12
|
desc c4;
+-------+----------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------------+------+-----+---------+-------+
| s | varchar(21844) | YES | | NULL | |
+-------+----------------+------+-----+---------+-------+
desc c5;
+-------+------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------+------+-----+---------+-------+
| s | mediumtext | YES | | NULL | |
+-------+------------+------+-----+---------+-------+
|
可以看到,c5表的字段类型已经变成了mediumtext,而不是varchar类型。
char VS varchar:存储长度验证
1
2
3
4
5
6
|
create table c6(s char(3));
create table c7(s varchar(3));
insert into c6 values('abcd');
insert into c6 values('生存还是毁灭');
insert into c7 values('abcd');
insert into c7 values('生存还是毁灭');
|
再来看查询结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
select s from c6;
+-----------+
| s |
+-----------+
| abc |
| 生存还 |
+-----------+
select s from c7;
+-----------+
| s |
+-----------+
| abc |
| 生存还 |
+-----------+
|
可以看到,无论是char还是varchar;无论是中文还是其他,它们限制的是字符个数。
char VS varchar:定长与可变长度
再来研究它们之间的特点的区别,也就是定长和可变长度的区别。
我们通过表格来看看他们的存储关系:
| Value | CHAR(4) | 存储需求 | VARCHAR(4) | 存储需求 |
|---|
| '' |
' ' |
4 bytes |
'' |
1 bytes |
| ‘ab’ |
‘ab ' |
4 bytes |
‘ab’ |
3 bytes |
| ‘abcd’ |
‘abcd’ |
4 bytes |
‘abcd’ |
5 bytes |
| ‘abcdefg’ |
‘abcd’ |
4 bytes |
‘abcd’ |
5 bytes |
不要被5bytes所迷惑,abcd占4个字节,还有一个字节存储该字符串的长度。
先了解两个函数:
- length:查看字节数。
- char_length:查看字符数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
create table c8(s1 char(3), s2 varchar(3));
desc c8;
+-------+------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------+------+-----+---------+-------+
| s1 | char(3) | YES | | NULL | |
| s2 | varchar(3) | YES | | NULL | |
+-------+------------+------+-----+---------+-------+
insert into c8 values('a', 'b');
select s1, s2 from c8;
+------+------+
| s1 | s2 |
+------+------+
| a | b |
+------+------+
|
现在看是啥也看不出来,所以,我们用上char_length函数:
1
2
3
4
5
6
|
select char_length(s1), char_length(s2) from c8;
+-----------------+-----------------+
| char_length(s1) | char_length(s2) |
+-----------------+-----------------+
| 1 | 1 |
+-----------------+-----------------+
|
这也看不出来啥呀,a和b不就是各占用一个字符长度么。
这是因为啊,我们在查询char类型数据的时候,MySQL会默默的删除尾部的空格(装作我并没有浪费空间!),我们来让它现原形:
1
2
3
4
5
6
7
|
SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';
select char_length(s1), char_length(s2) from c8;
+-----------------+-----------------+
| char_length(s1) | char_length(s2) |
+-----------------+-----------------+
| 3 | 1 |
+-----------------+-----------------+
|
这个时候再看,是不是现原形了,char类型占用指定的3个字符宽度,当然,一个英文字符也占用一个字节。而varchar就占用一个字符。
中文也一样:
1
2
3
4
5
6
7
8
|
insert into c8 values('你', '好');
select char_length(s1), char_length(s2) from c8;
+-----------------+-----------------+
| char_length(s1) | char_length(s2) |
+-----------------+-----------------+
| 3 | 1 |
| 3 | 1 |
+-----------------+-----------------+
|
这就是我们使用char和varchar时需要注意的点。
小结:
InnoDB存储引擎:建议使用VARCHAR类型 单从数据类型的实现机制去考虑,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。
但对于InnoDB数据表,内部的行存储格式没有区分固定长度和可变长度列(所有数据行都使用指向数据列值的头指针),因此在本质上,使用固定长度的CHAR列不一定比使用可变长度VARCHAR列性能要好。因而,主要的性能因素是数据行使用的存储总量。由于CHAR平均占用的空间多于VARCHAR,因此使用VARCHAR来最小化需要处理的数据行的存储总量和磁盘I/O是比较好的。 其他字符串系列(效率:char>varchar>text)
- TEXT系列 TINYTEXT TEXT MEDIUMTEXT LONGTEXT
- BLOB 系列 TINYBLOB BLOB MEDIUMBLOB LONGBLOB
- BINARY系列 BINARY VARBINARY
text:text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。
枚举与集合
有些情况,我们需要在一堆选项中选择一个,或者选择多个,如单选框和复选框。 那,在MySQL的字段中,字段的类型也可以有单选和多选。
- enum单选,只能在给定范围内选一个值,如果性别;适用于给定范围后续不会发生变化的场景;另外数字类型不适用枚举。
- set多选,在给定的范围聂选择多个值,如爱好。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
create table user1(
id int,
name char(5),
sex enum('male', 'female', 'unknow'),
hobby set('eat', 'sleep', 'play mobile phone')
);
desc user1;
+-------+----------------------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------------------------------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | char(5) | YES | | NULL | |
| sex | enum('male','female','unknow') | YES | | NULL | |
| hobby | set('eat','sleep','play mobile phone') | YES | | NULL | |
+-------+----------------------------------------+------+-----+---------+-------+
insert into user1 values(1, '张三', 'male', 'eat,sleep');
select * from user1;
+------+-----------+------+-----------+
| id | name | sex | hobby |
+------+-----------+------+-----------+
| 1 | 张三 | male | eat,sleep |
+------+-----------+------+-----------+
|
如果是set类型,多个参数以逗号隔开。 这里,我们也可以设置默认值,如果用户不填写的话:
1
2
3
4
5
6
7
8
9
10
|
create table user2 (id int, sex enum('male', 'female', 'unknow') default 'male');
insert into user2(id) values(1);
insert into user2 values(2, 'female');
select * from user2;
+------+--------+
| id | sex |
+------+--------+
| 1 | male |
| 2 | female |
+------+--------+
|
根据查询结果可以看到,如果性别字段传值就用我们传的值,不传就用默认的。
约束
约束条件与数据类型一样的宽度一样,都是可选参数。
作用是用于保证数据的完整性和一致性,以免不符合规范的数据写入数据库。
在MySQL中,主要约束有:
PRIMARY KEY (PK),标识字段为该表的主键,可以唯一标识某一条记录,及设置字段非空且唯一。FOREIGN KEY (PK),标识该字段为该表的外键。NOT NULL:约束字段不能为空。UNIQUE,标识该字段的值是唯一的。AUTO_INCREMENT,标识该字段的值自动增长(整数类型,而且为主键)。DEFAULT,为字段设置默认值,比如设置性别默认为男。UNSIGNED,设置整形类型为无符号类型。ZEROFILL,使用0填充。
not null
是否可空,null表示空,非字符串。
not null 不可空,null可空。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
create table n1(
id int not null,
name char(5) not null,
age int
);
desc n1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
| name | char(5) | NO | | NULL | |
| age | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
insert into n1 values(1, '张开1', 18);
insert into n1 values(2, null, 20);
ERROR 1048 (23000): Column 'name' cannot be null
insert into n1 values(null, '张开2', 30);
ERROR 1048 (23000): Column 'id' cannot be null
select * from n1;
+----+---------+------+
| id | name | age |
+----+---------+------+
| 1 | 张开1 | 18 |
+----+---------+------+
|
可以看到,当字段设置了not null的后,我们就必须为该字段传值。
not null的坑
来,做个试验,刚才不是说not null的作用是约束字段不能为空么?我们再来创建个表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
create table n2(
id int not null,
name char(5) not null,
age int
);
insert into n2 values(1, '张开1', 20);
insert into n2 values(2, null, 21);
insert into n2 values(null, '张开2', 22);
select * from n2;
+----+---------+------+
| id | name | age |
+----+---------+------+
| 1 | 张开1 | 20 |
+----+---------+------+
|
如果你查询的话,会发现跟之前的n1表一模一样,哪有问题呀?那好,我们再来插入数据:
1
2
3
4
5
6
7
8
9
10
11
12
|
insert into n2 values(null, null, null), (2, null, 23), (null, '张开腿', 24);
Query OK, 3 rows affected, 4 warnings (0.05 sec)
Records: 3 Duplicates: 0 Warnings: 4
select * from n2;
+----+-----------+------+
| id | name | age |
+----+-----------+------+
| 1 | 张开1 | 20 |
| 0 | | NULL |
| 2 | | 23 |
| 0 | 张开腿 | 24 |
+----+-----------+------+
|
这是什么情况?not null也不管用了啊!参照官网的解释说,MySQL服务器可以在不同的SQL模式下运行,并且可以针对不同的客户端以不同的方式应用这些模式,具体取决于sql_mode系统变量的值。所以,机缘巧合下,发生了这种事情。那么就从sql_mode下手,先来看当前的sql_mode:
1
2
3
4
5
6
|
show variables like "sql_mode";
+---------------+------------------------+
| Variable_name | Value |
+---------------+------------------------+
| sql_mode | NO_ENGINE_SUBSTITUTION |
+---------------+------------------------+
|
可以看到,sql_mode只有一个关于NO_ENGINE_SUBSTITUTION设置,意思是MySQL在创建表的时候,可以指定engine子句,也就是指定表的存储引擎。
ps:如果你的结果不是这样的, 你可手动将sql_mode设置为空,来演示这个效果:
抛开这个不管,我们发现并没有什么关于约束之类的设置(我们称为设置严格模式)。那我们就给它设置上,设置有两种方式。第一是在当前客户端设置:
1
|
set sql_mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION";
|
这么一设置,立马见效:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
create table n3(
id int not null,
name char(5) not null,
age int
);
insert into n3 values(1, '张开1', 20);
insert into n3 values(null, null, null), (2, null, 23), (null, '张开腿', 24);
ERROR 1048 (23000): Column 'id' cannot be null
select * from n3;
+----+---------+------+
| id | name | age |
+----+---------+------+
| 1 | 张开1 | 20 |
+----+---------+------+
|
可以看到,只有第一次的插入生效了。完美!但是,这么着,如果服务器重启就生效了,想要一劳永逸的话,还是要从配置文件下手,我们可以修改MySQL的配置文件my.ini:
1
2
|
[mysqld]
sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
|
然后重启服务。
default
如果某一列字段经常用重复的内容,在我们频发插入的时候,就比较麻烦。所以,我们要是使用default默认值来减少麻烦。比如一个班级内有95%的都是男生,只有5%的女生,那么在插入学生数据的时候,我们就可以为性别这一列给一个默认值是男生:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
create table d1(
id int not null,
name char(5) not null,
gender enum('male', 'female', 'unknow') not null default 'male'
);
insert into d1 values(1, '小明', 'male');
insert into d1 values(2, '小红', 'female');
insert into d1 values(1, '小李');
ERROR 1136 (21S01): Column count doesn't match value count at row 1
select * from d1;
+----+--------+--------+
| id | name | gender |
+----+--------+--------+
| 1 | 小明 | male |
| 2 | 小红 | female |
+----+--------+--------+
|
我们原本以为gender字段是有默认值,就可以不写,但是,如上那么写,出了错。这是因为MySQL并不能理解我们是想要使用gender的默认值。而是认为你少了一个字段没有填写。怎么办呢,怎么应用上默认值呢:
1
2
3
4
5
6
7
8
9
|
insert into d1(id, name) values(3, '小李');
select * from d1;
+----+--------+--------+
| id | name | gender |
+----+--------+--------+
| 1 | 小明 | male |
| 2 | 小红 | female |
| 3 | 小李 | male |
+----+--------+--------+
|
比如按照上面的方式,告诉MySQL指定字段传值,gender字段不传值,就使用默认值吧。
default可以这么用:
1
2
3
4
5
6
|
create table d1(
id int not null,
name char(5) not null,
age int default 18,
gender enum('male', 'female', 'unknow') not null default 'male'
);
|
比如直接为age字段设置默认值,而无需指定not null。但是我们一般是default和not null连用。
auto_increment
针对数字列,顺序的自动填充数据,默认从1开始,也可以设置步长和偏移量;常用来设置自增id。
1
2
3
4
5
6
7
8
9
|
create table a0(
id int primary key auto_increment,
name char(5)
);
desc a0;
insert into a0(name) values ("张开"), ("李开"), ("张不开");
select * from a0;
|
上面是默认的自增长配置,现在来一个修改初始自增id初始值的配置:
1
2
3
4
5
6
7
8
9
10
|
-- 创建表时指定
CREATE TABLE a1(id INT PRIMARY KEY AUTO_INCREMENT, NAME CHAR(3)) ENGINE='innodb' AUTO_INCREMENT=5;
-- 或者使用alter语句修改
ALTER TABLE tbl AUTO_INCREMENT = 100;
SHOW CREATE TABLE a1;
INSERT INTO a1(name) VALUES('11'),('22');
-- id值将会从5开始
SELECT * FROM a1;
|
再来了解一个不常用的配置,就是修改自增id的初始值和步长:
- 设置自增初始值:
auto_increment_offset。
- 设置自增步长:
auto_increment_increment。
比如自增id从2开始,然后步长是2,怎么设置呢?有两种方式可以设置。
基于session级别的配置
也就是针对本次会话有效,来看示例:
1
2
3
4
5
6
7
8
9
10
|
set session auto_increment_increment=2;
set session auto_increment_offset=4;
create table a2(
id int primary key auto_increment,
name char(5)
);
insert into a2(name) values ('张开'),('李开');
select * from a2;
|
但是,这仅仅是针对本次会话,当前会话关闭后,就失效了。
基于全局级别的配置
1
2
3
4
5
6
7
8
9
10
11
|
-- 也可以在配置文件中配置
set global auto_increment_increment=2;
set global auto_increment_offset=2;
create table a3(
id int primary key auto_increment,
name char(5)
);
insert into a3(name) values ('张开'),('李开');
select * from a3;
|
如果你是终端执行的,请quit退出重新登录才能生效。
另外,auto_increment_increment和auto_increment_offset这两个变量会相互影响,来自官网:
When the value of auto_increment_offset is greater than that of auto_increment_increment, the value of auto_increment_offset is ignored.
当auto_increment_offset的值大于auto_increment_increment时,auto_increment_offset的值将被忽略,也就是说只有步长生效,初始值还是从1开始。
来个不生效的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
mysql> set session auto_increment_increment=2;
Query OK, 0 rows affected (0.00 sec)
mysql> set session auto_increment_offset=3;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like '%incre%';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| auto_increment_increment | 2 |
| auto_increment_offset | 3 |
| div_precision_increment | 4 |
| innodb_autoextend_increment | 64 |
+-----------------------------+-------+
4 rows in set (0.01 sec)
mysql> create table a4(id int primary key auto_increment,name char(10));
Query OK, 0 rows affected (0.00 sec)
mysql> insert into a4(name) values('aa'),('bb');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from a4;
+----+------+
| id | name |
+----+------+
| 1 | aa |
| 3 | bb |
+----+------+
2 rows in set (0.00 sec)
|
注意,这两个值不常用,记得改回来。
通常,一个表中只能有一个自增长字段,并且该字段必须被约束为key,这个key可以是unique或者primary key。
key
约束中的key我们学习三种:
- unique
- primary key
- foreign key
其中unique和primary key可以提高查询速度,而foreign key用来表与表之间的关系的。
unique
1
2
3
4
5
6
|
create table u1(
id int unique,
name char(5) unique
);
insert into u1(name) values ('张开'),('李开');
select * from u1;
|
如果id或name字段有重复则会报错。
primary key
primary key指主键,主键的效果非空且唯一,可以加速查询。
1
2
3
4
5
|
create table p1(
id int primary key,
name char(3)
);
desc p1;
|
primary key等价于 not null unique:
1
2
3
4
5
|
create table p2(
id int not null unique primary key,
name char(3)
);
desc p2;
|
也可以使用constraint定义约束:
constraint 约束名称 约束类型 (约束字段)
示例:
1
2
3
4
5
6
|
create table p3(
id int,
name char(3),
constraint primary_id primary key (id)
);
desc p3;
|
当然,也可以省略constraint关键字:
1
2
3
4
5
6
|
create table p4(
id int,
name char(3),
primary key (id)
);
show create table p4;
|
注意,一张表中,只能有一个主键,但是可以有多个not null unique。
1
2
3
4
5
|
create table p5(
id int not null unique ,
name char(3) not null unique
);
show create table p5;
|
联合唯一:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
create table p6(
id int primary key auto_increment,
ip char(15) not null ,
port int not null ,
unique (ip, port)
);
show create table p6;
insert into p6(ip, port) values
('1.1.1.1', 3306),
('1.1.1.0', 3306),
('1.1.1.1', 8080);
select * from p6;
|
将ip和端口设置为联合唯一,保证数据唯一性。
foreign key
为了快速理解foreign key,我们这准备两张表来进行关联:
- 部门表,也称被关联表,父表,一个部门可以关联多个员工。
- 员工表(工号,姓名,所属部门),子表,一个员工只属于一个部门。
首先来分析表与表之间的关系,分析步骤:
-
先站在左表的角度去找
- 是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段(通常是id)
-
再站在右表的角度去找
- 是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段foreign key 左表一个字段(通常是id)
-
总结:
-
多对一:
- 如果只有步骤1成立,则是左表多对一右表
- 如果只有步骤2成立,则是右表多对一左表
-
多对多:
- 如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,需要定义一个这两张表的关系表来专门存放二者的关系
-
一对一:
- 如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可
来看如何使用foreign key:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
-- 表类型必须是innodb存储引擎,且被关联的字段,即references指定的另外一个表的字段,必须保证唯一
CREATE TABLE department(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME CHAR(32) NOT NULL
)ENGINE=INNODB CHARSET=utf8;
-- 父表先插入数据,便于子表关联
INSERT INTO department(NAME) VALUES
('人事部'),
('财务部'),
('行政部');
-- department_id外键关联到父表的id字段,并且指定同步更新和删除
CREATE TABLE employee(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(32) NOT NULL,
department_id INT,
CONSTRAINT fk_name FOREIGN KEY(department_id) REFERENCES department(id) ON DELETE CASCADE ON UPDATE CASCADE
)ENGINE=INNODB CHARSET=utf8;
INSERT INTO employee(NAME, department_id) VALUES
('zhang3',1),
('li4',2),
('wang5',3),
('zhao6',2),
('wang7',1),
('qian9',3),
('sun10',2),
('zhou11',1);
|
来看示例:
1
2
3
4
5
6
7
|
-- 当父表的数据被修改,同时子表的相关数据也同步修改
UPDATE department SET id=4 WHERE id=1; -- 将id为1的修改为4,
SELECT * FROM employee; -- 子表的关联id也随之改变
-- 当父表的数据被删除,子表的相关记录也被同步删除
DELETE FROM department WHERE id=4;
SELECT * FROM employee; -- 子表的关联字段也被随之删除
|
一对多/多对一/多对多之间建立关系示例
三张表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
-- 出版社表
CREATE TABLE publisher(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(32)
)ENGINE=INNODB CHARSET=utf8;
INSERT INTO publisher(id,NAME) VALUES
(1,'清华出版社'),
(2,'北大出版社'),
(3,'机械工业出版社'),
(4,'邮电出版社'),
(5,'电子工业出版社'),
(6,'人民大学出版社');
-- 书籍表,该表和出版社的关系是多对一,一家出版社可以出版多本书,所以,foreign key要在书籍表中建立,绑定到出版社表的id字段
CREATE TABLE book(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(32),
pub_id INT NOT NULL,
FOREIGN KEY(pub_id) REFERENCES publisher(id) ON DELETE CASCADE ON UPDATE CASCADE
)ENGINE=INNODB CHARSET=utf8;
INSERT INTO book(NAME,pub_id) VALUES
('book1',1),
('book2',2),
('book3',3),
('book4',2),
('book5',3),
('book6',6),
('book7',1),
('book8',3);
-- 作者表,由于一本书可以有多个作者,一个作者也可以写多本书,所以,作者表和书籍表的关系是多对多,需要使用第三张表来建立多对多关系
CREATE TABLE author(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(32) NOT NULL
)ENGINE=INNODB CHARSET=utf8;
INSERT INTO author(NAME) VALUES
('张开1'),
('张开2'),
('张开3'),
('张开4'),
('张开5'),
('张开6');
-- 作者表和书籍表的多对多关系,建立的第三张表
CREATE TABLE author2book(
id INT NOT NULL UNIQUE AUTO_INCREMENT,
author_id INT NOT NULL,
book_id INT NOT NULL,
FOREIGN KEY(author_id) REFERENCES author(id) ON UPDATE CASCADE ON DELETE CASCADE,
FOREIGN KEY(book_id) REFERENCES book(id) ON UPDATE CASCADE ON DELETE CASCADE
)ENGINE=INNODB CHARSET=utf8;
INSERT INTO author2book(author_id,book_id) VALUES
(1,1),
(1,2),
(2,1),
(3,3),
(3,4),
(1,3);
|
一对一建立关系
两张表:
- 学生表,学生一定是客户。
- 客户表,客户不一定是学生,但学生一定是客户。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
-- 客户表
CREATE TABLE customer(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(32) NOT NULL COMMENT '客户姓名'
)ENGINE=INNODB CHARSET=utf8;
INSERT INTO customer(NAME) VALUES
('张开1'),
('张开2'),
('张开3'),
('张开4'),
('张开5'),
('张开6');
-- 学生表,学生表的姓名字段从关联表中获取
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT,
class_name VARCHAR(32) NOT NULL COMMENT '班级',
customer_id INT NOT NULL UNIQUE,
FOREIGN KEY(customer_id) REFERENCES customer(id) ON DELETE CASCADE ON UPDATE CASCADE -- 外键字段必须是唯一的
)ENGINE=INNODB CHARSET=utf8;
INSERT INTO student(class_name,customer_id) VALUES
('python',1),
('linux',2),
('mysql',3);
|
了解数据类型和约束,我们就可以来学习最重要的部分,那就是对于记录的查询了。
单表查询
准备数据,由于数据数量太大,这里难以展示,请去该地址获取:https://www.cnblogs.com/Neeo/articles/13561090.html
select单独使用
select @@xxx
select语句单独使用一般是搭配@@语句查询一些系统信息之类的:
1
2
3
4
5
|
SELECT @@port;
SELECT @@version;
SELECT @@basedir;
SELECT @@datadir;
SELECT @@server_id;
|
@@后必须跟参数的全名,当然对于一些特别长的,你可能记不住:
1
2
|
SELECT @@innodb_flush_log_at_trx_commit;
SHOW VARIABLES LIKE 'innodb_flush%';
|
太长了记不住,可以使用SHOW语句进行模糊匹配查询。
select调用函数
select语句也可以直接调用函数:
1
2
3
4
5
6
7
8
|
SELECT NOW();
SELECT DATABASE(); -- 当前所在数据库
SELECT USER();
SELECT CONCAT("hello world"); -- 拼接字符串,如下是拼接的用法,了解即可
-- SELECT USER,HOST FROM mysql.user;
-- SELECT CONCAT(USER,"@",HOST) FROM mysql.user;
-- SELECT GROUP_CONCAT(USER,"@",HOST) FROM mysql.user;
-- SELECT CONCAT_WS('@', USER,HOST) FROM mysql.user;
|
更多内置函数参考:SQL Function and Operator Reference
from
from的两种常用方式:
1
2
|
SELECT col1,col2 FROM 表; -- 查询指定列
SELECT * FROM 表; -- 全表查询,不要在生产中使用,性能太差
|
一般在生产中,select语句不加where语句是不允许通过的。
在查询中也可以使用四则运算:
1
|
SELECT population*20,population FROM city;
|
where
where是过滤的意思,可以加各种过滤条件,基本语法:
1
|
SELECT col1,col2 FROM TABLE WHERE col 条件;
|
来看常用的用法。
where配合等值查询
等值查询也就是col=xx的操作:
1
2
3
4
5
6
7
8
|
-- 查询中国(CHN)所有城市信息
SELECT * FROM city WHERE countrycode='CHN';
-- 查询中国郑州市信息
SELECT * FROM city WHERE NAME='zhengzhou';
-- 查询中国河南省所有城市信息
SELECT * FROM city WHERE district='henan';
|
where配合比较操作符
比较运算符也就是>、>=、<、<=、!=(<>)这些操作了:
1
2
3
4
5
6
7
8
9
|
-- 查询世界上人口小于十万人的城市
SELECT * FROM city WHERE population<100000;
-- 查询世界上人口大于一千万人的城市
SELECT * FROM city WHERE population>10000000;
-- 不等于这里,用 <> 和 != 都可以
SELECT * FROM city WHERE countrycode='CHN' AND DISTRICT!='shanghai';
SELECT * FROM city WHERE countrycode='CHN' AND DISTRICT<>'shanghai';
|
where配合逻辑运算符
逻辑运算符这里常用的有and or,not用的少,这里就不说了:
1
2
3
4
5
|
-- 查询中国人口数大于800万的城市
SELECT * FROM city WHERE countrycode='CHN' AND population>8000000;
-- 查询中国或美国城市信息
SELECT * FROM city WHERE countrycode='CHN' OR countrycode='USA';
|
where配合模糊查询
1
2
|
-- 查询中国以"hu"开头省的城市信息
SELECT * FROM city WHERE district LIKE 'hu%';
|
like查询中,支持下面两种符号:
%,任意长度字符,注意,条件左边不能使用%,因为这样查询时不走索引(索引遵循最左原则)。_,任意一个字符。
where配合in语句
1
2
3
|
-- 查询中国或美国城市信息
SELECT * FROM city WHERE countrycode='CHN' OR countrycode='USA';
SELECT * FROM city WHERE countrycode IN ('CHN', 'USA');
|
上面两条语句是等价的,性能也是一样的,虽然性能都不怎么样!
where配合between and语句
1
2
3
|
-- 查询世界上人口数量在100万-200万之间的城市
SELECT * FROM city WHERE population<=2000000 AND population>=1000000;
SELECT * FROM city WHERE population BETWEEN 1000000 AND 2000000;
|
where配合is语句
判断一个字段是否为空不用等号,而是使用is语句:
1
2
|
-- 返回city表中countrycode是CHN的,并且district字段不为空的前10条数据
SELECT * FROM city WHERE countrycode='CHN' AND district IS NOT NULL LIMIT 10;
|
group by+聚合函数
根据by后面的(一个或多个)条件进行分组,便于统计。
常用聚合(统计)函数
max():最大值。min():最小值。avg():平均值。sum():总和。count():个数。
另外再加一个函数:
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
-- 统计世界上每个国家的总人口数量
SELECT countrycode,SUM(population) FROM city GROUP BY countrycode;
-- 统计中国每个省的总人口数量
SELECT district,SUM(population) FROM city WHERE countrycode='CHN' GROUP BY district;
-- 统计世界上每个国家的城市数量
SELECT countrycode,COUNT(NAME) FROM city GROUP BY countrycode;
SELECT countrycode,COUNT(id) FROM city GROUP BY countrycode;
-- 统计中国每个省的城市列表
SELECT district,GROUP_CONCAT(NAME) FROM city WHERE countrycode='CHN' GROUP BY district;
-- 统计中国每个省的平均人口
SELECT district,AVG(population) FROM city WHERE countrycode='CHN' GROUP BY district;
|
在MySQL的SQL执行逻辑中,where条件必须放在group by前面!也就是先通过where条件将结果查询出来,再交给group by去分组,完事之后进行统计。
除此之外,如果使用unique字段作为分组依据,这样的话每条记录都自成一组,这么做是没有意义的。
having
1
2
3
4
5
6
|
-- 统计中国每个省的总人数,只打印人口数量小于50万的省份
SELECT district,SUM(population)
FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)<500000;
|
注意,having子句是后过滤语句,在group by后面再进行过滤,并且having子句不走索引,针对这个问题,我们一般采用临时表来解决。
order by + limit
order by通常和limit搭配使用。 order by在having语句后面执行。 学到这里,我们也能发现,MySQL中的SQL语句的执行顺序:
1
|
SELECT FROM WHERE GROUP BY HAVING ORDER BY LIMIT
|
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
-- 查询中国的城市信息,并且按照人口数量降序排序
SELECT * FROM city WHERE countrycode='CHN' ORDER BY population DESC;
-- 查询美国的城市信息,并且按照人口数量升序排序
SELECT * FROM city WHERE countrycode='USA' ORDER BY population ASC;
-- 统计中国每个省的总人口,找出大于500万的,并按照人口数量降序排序
SELECT district,SUM(population)
FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC;
-- 统计中国每个省的总人口,找出大于500万的,并按照人口数量降序排序,只打印前3条结果
SELECT district,SUM(population)
FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 3;
|
MySQL中默认排序是升序ASC;降序是DESC,还有一种情况是,比如说按照年龄排序,但是有的年龄是相同的,该怎么排序,这里我们可以这样处理:
1
2
|
-- 根据age升序排序,如果age相同,这按照id降序排序
SELECT * FROM employee ORDER BY age,id desc;
|
下来来解释LIMIT语句为什么通常和ORDER BY一起使用,因为有序的或经过筛选的数据更有意义,无序的数据使用LIMIT在实际生产中意义不大; 再来说说LIMIT的常用用法:
1
2
3
4
|
LIMIT N -- 返回前N行
LIMIT N,M -- 跳过前N行,返回M行,如LIMIT 5,5,意思是跳过前5行,从第6行开始显式5条
-- 上下两个用法相反,推荐使用上面的
LIMIT M OFFSET N -- 显式M行,跳过N行,如LIMIT 5,3,意思是跳过前3行,从第4行开始,显式5行
|
正则表达式查询
1
2
|
-- 查询中国重庆
SELECT * FROM city WHERE countrycode='CHN' AND district REGEXP '^C.*g$';
|
distinct
distinct去重,来看示例:
1
2
3
|
-- 查询世界上所有国家码
SELECT countrycode FROM city; -- 返回结果有重复
SELECT DISTINCT(countrycode) FROM city; -- DISTINCT 去重
|
联合查询-union
联合查询的意思就是将两个同类型的结果集合并成一个,比如:
1
2
|
-- 查询中国和美国的城市信息
SELECT countrycode,NAME FROM city WHERE countrycode IN ('CHN','USA');
|
示例的意思是将查询到的中国城市信息的结果加上美国的城市信息加一起再返回,除了上述使用 IN 语句来完成也可以使用联合查询来完成,这里也更推荐使用联合查询:
1
2
3
4
|
-- 查询中国和美国的城市信息
SELECT countrycode,NAME FROM city WHERE countrycode='CHN'
UNION ALL
SELECT countrycode,NAME FROM city WHERE countrycode='USA';
|
上述UNION ALL就是拼接了两个同类型的结果,当然,你还可以继续拼接:
1
2
3
4
5
6
7
8
|
-- 查询中国(CHN)、美国(USA)、日本(JPN)、英国(GBR)的城市信息
SELECT countrycode,NAME FROM city WHERE countrycode='CHN'
UNION ALL
SELECT countrycode,NAME FROM city WHERE countrycode='USA'
UNION ALL
SELECT countrycode,NAME FROM city WHERE countrycode='JPN'
UNION ALL
SELECT countrycode,NAME FROM city WHERE countrycode='GBR';
|
注意,UNION ALL的性能高于IN、OR语句;所以,如果可以的话,我们尽量使用UNION ALL语句来代替IN、OR语句。
另外,在MySQL中,不是SQL语句越短性能越高!
最后,再来补充一下,联合查询有两种写法:
UNION:在拼接结果集时,带有去重功能,当然,去重就意味着会有性能消耗。UNION ALL:没有去重功能。
以上就是单表查询中常用的语句用法了。
连表查询
所谓的连表查询就是所需要的数据来自于多张有关系的表,也叫多表查询。
准备数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
CREATE TABLE department(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '自增id',
NAME VARCHAR(32) NOT NULL COMMENT '部门姓名'
)ENGINE=INNODB CHARSET=utf8 COMMENT '部门表';
INSERT INTO department(id,NAME) VALUES
(1, '人事部'),
(2, '财务部'),
(3, '行政部'), -- 该部门没有员工
(4, '运营部');
CREATE TABLE employee(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '自增id',
NAME VARCHAR(32) NOT NULL COMMENT '员工姓名',
age INT NOT NULL COMMENT '员工年龄',
gender ENUM('male', 'female') NOT NULL DEFAULT 'male',
dep_id INT NOT NULL COMMENT '所在部门id' -- 这里故意不绑定外键,为了后续展开讲接
)ENGINE=INNODB CHARSET=utf8 COMMENT '员工表';
INSERT INTO employee(NAME,age,gender,dep_id) VALUES
('小黄',18, 'male', 1),
('小李',19, 'male', 2),
('小红',20, 'female', 2),
('小兰',20, 'female', 1),
('小六',32, 'male', 1),
('小王',23, 'male', 4),
('小华',52, 'male', 5); -- 实际上id为5的部门并不存在
|
多表连接查询
多表连接,就是将几张表拼接为一张表,然后进行查询,先来看基本语法:
1
2
3
4
|
SELECT col1, col2
FROM t1 INNER/LEFT/RIGHT JOIN t2
ON 连接条件(t1.col=t2.col)
;
|
接下来,来研究连接时的几种情况。
交叉连接
交叉连接时,不使用任何匹配条件,生成笛卡尔积:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
SELECT * FROM employee,department;
+----+--------+-----+--------+--------+----+-----------+
| id | NAME | age | gender | dep_id | id | name |
+----+--------+-----+--------+--------+----+-----------+
| 1 | 小黄 | 18 | male | 1 | 1 | 人事部 |
| 1 | 小黄 | 18 | male | 1 | 2 | 财务部 |
| 1 | 小黄 | 18 | male | 1 | 3 | 行政部 |
| 1 | 小黄 | 18 | male | 1 | 4 | 运营部 |
| 2 | 小李 | 19 | male | 2 | 1 | 人事部 |
| 2 | 小李 | 19 | male | 2 | 2 | 财务部 |
| 2 | 小李 | 19 | male | 2 | 3 | 行政部 |
| 2 | 小李 | 19 | male | 2 | 4 | 运营部 |
| 3 | 小红 | 20 | female | 2 | 1 | 人事部 |
| 3 | 小红 | 20 | female | 2 | 2 | 财务部 |
| 3 | 小红 | 20 | female | 2 | 3 | 行政部 |
| 3 | 小红 | 20 | female | 2 | 4 | 运营部 |
| 4 | 小兰 | 20 | female | 1 | 1 | 人事部 |
| 4 | 小兰 | 20 | female | 1 | 2 | 财务部 |
| 4 | 小兰 | 20 | female | 1 | 3 | 行政部 |
| 4 | 小兰 | 20 | female | 1 | 4 | 运营部 |
| 5 | 小六 | 32 | male | 1 | 1 | 人事部 |
| 5 | 小六 | 32 | male | 1 | 2 | 财务部 |
| 5 | 小六 | 32 | male | 1 | 3 | 行政部 |
| 5 | 小六 | 32 | male | 1 | 4 | 运营部 |
| 6 | 小王 | 23 | male | 4 | 1 | 人事部 |
| 6 | 小王 | 23 | male | 4 | 2 | 财务部 |
| 6 | 小王 | 23 | male | 4 | 3 | 行政部 |
| 6 | 小王 | 23 | male | 4 | 4 | 运营部 |
| 7 | 小华 | 52 | male | 5 | 1 | 人事部 |
| 7 | 小华 | 52 | male | 5 | 2 | 财务部 |
| 7 | 小华 | 52 | male | 5 | 3 | 行政部 |
| 7 | 小华 | 52 | male | 5 | 4 | 运营部 |
+----+--------+-----+--------+--------+----+-----------+
28 rows in set (0.00 sec)
|
由展示结果可以看到,笛卡尔积的结果是左表的每条记录都跟右表的每条记录都连接一次,这就是所谓的笛卡尔积的结果。虽然看起来没啥用,但它确是一切连接的基础。
内连接
内连接(INNER JOIN)是找几张表的交集,即根据条件筛选出来正确的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
SELECT emp.id,emp.name,emp.age,emp.dep_id,emp.gender,dep.id,dep.name
FROM employee AS emp INNER JOIN department AS dep
ON emp.dep_id=dep.id;
+----+--------+-----+--------+--------+----+-----------+
| id | name | age | dep_id | gender | id | name |
+----+--------+-----+--------+--------+----+-----------+
| 1 | 小黄 | 18 | 1 | male | 1 | 人事部 |
| 2 | 小李 | 19 | 2 | male | 2 | 财务部 |
| 3 | 小红 | 20 | 2 | female | 2 | 财务部 |
| 4 | 小兰 | 20 | 1 | female | 1 | 人事部 |
| 5 | 小六 | 32 | 1 | male | 1 | 人事部 |
| 6 | 小王 | 23 | 4 | male | 4 | 运营部 |
+----+--------+-----+--------+--------+----+-----------+
6 rows in set (0.00 sec)
|
由于部门表中没有id=5的部门,所以员工表dep_id=5的这条记录没有返回;而由于行政部没有员工,所以这条记录也没返回。
外连接之左连接
左连接(LEFT JOIN)是以左表为准,如果右表中没有合适的记录,用NULL补全;其本质是在内连接的基础上增加左表有结果而右表没有的记录(内连接时,这种情况的记录会忽略)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
SELECT emp.id,emp.name,emp.age,emp.dep_id,emp.gender,dep.id,dep.name
FROM employee AS emp LEFT JOIN department AS dep
ON emp.dep_id=dep.id;
+----+--------+-----+--------+--------+------+-----------+
| id | name | age | dep_id | gender | id | name |
+----+--------+-----+--------+--------+------+-----------+
| 1 | 小黄 | 18 | 1 | male | 1 | 人事部 |
| 4 | 小兰 | 20 | 1 | female | 1 | 人事部 |
| 5 | 小六 | 32 | 1 | male | 1 | 人事部 |
| 2 | 小李 | 19 | 2 | male | 2 | 财务部 |
| 3 | 小红 | 20 | 2 | female | 2 | 财务部 |
| 6 | 小王 | 23 | 4 | male | 4 | 运营部 |
| 7 | 小华 | 52 | 5 | male | NULL | NULL |
+----+--------+-----+--------+--------+------+-----------+
7 rows in set (0.00 sec)
|
可以看到,员工小华所在的id=5的部门并不存在,但是左连接时,这种缺省使用NULL补全了。
外连接之右连接
跟左连接正好相反,右连接(RIGHT JOIN)是以右表为准,如果左表中某些字段没有合适的结果,用NULL补全;其本质是在内连接的基础上增加右表有结果而左表没有的记录(内连接时,这种情况的记录会忽略)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
SELECT emp.id,emp.name,emp.age,emp.dep_id,emp.gender,dep.id,dep.name
FROM employee AS emp RIGHT JOIN department AS dep
ON emp.dep_id=dep.id;
+------+--------+------+--------+--------+----+-----------+
| id | name | age | dep_id | gender | id | name |
+------+--------+------+--------+--------+----+-----------+
| 1 | 小黄 | 18 | 1 | male | 1 | 人事部 |
| 2 | 小李 | 19 | 2 | male | 2 | 财务部 |
| 3 | 小红 | 20 | 2 | female | 2 | 财务部 |
| 4 | 小兰 | 20 | 1 | female | 1 | 人事部 |
| 5 | 小六 | 32 | 1 | male | 1 | 人事部 |
| 6 | 小王 | 23 | 4 | male | 4 | 运营部 |
| NULL | NULL | NULL | NULL | NULL | 3 | 行政部 |
+------+--------+------+--------+--------+----+-----------+
7 rows in set (0.00 sec)
|
由结果可知,记录展示以右表为准,因为右表没有id=5的部门,所以,左表中dep_id=5的记录不展示。
全外连接
全外连接,在内连接的基础上,展示左右表的所有的记录,而左右表中缺省记录以NULL补全。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
SELECT emp.id,emp.name,emp.age,emp.dep_id,emp.gender,dep.id,dep.name
FROM employee AS emp LEFT JOIN department AS dep
ON emp.dep_id=dep.id
UNION -- 全外连接使用 union
SELECT emp.id,emp.name,emp.age,emp.dep_id,emp.gender,dep.id,dep.name
FROM employee AS emp RIGHT JOIN department AS dep
ON emp.dep_id=dep.id;
+------+--------+------+--------+--------+------+-----------+
| id | name | age | dep_id | gender | id | name |
+------+--------+------+--------+--------+------+-----------+
| 1 | 小黄 | 18 | 1 | male | 1 | 人事部 |
| 4 | 小兰 | 20 | 1 | female | 1 | 人事部 |
| 5 | 小六 | 32 | 1 | male | 1 | 人事部 |
| 2 | 小李 | 19 | 2 | male | 2 | 财务部 |
| 3 | 小红 | 20 | 2 | female | 2 | 财务部 |
| 6 | 小王 | 23 | 4 | male | 4 | 运营部 |
| 7 | 小华 | 52 | 5 | male | NULL | NULL |
| NULL | NULL | NULL | NULL | NULL | 3 | 行政部 |
+------+--------+------+--------+--------+------+-----------+
8 rows in set (0.00 sec)
|
注意,MySQL中并没有全外连接的FULL JOIN语法,而是借助UNION语句实现。 这里复习下union和union all的区别,union具有去重功能。 使用连表查询示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- 找出年龄大于20岁的员工及员工所在部门
SELECT emp.name,emp.age,dep.name
FROM employee AS emp INNER JOIN department AS dep
ON emp.dep_id=dep.id
WHERE emp.age>20;
-- 查询世界上人口数量小于100人的城市名和国家名
SELECT country.name,city.name,city.population
FROM city INNER JOIN country
ON city.countrycode=country.code
WHERE city.population<100;
-- 查询城市shenyang的城市人口,所在国家(name)及国土面积(surfacearea)
SELECT city.name,city.population,country.name,country.surfacearea
FROM city INNER JOIN country
ON city.countrycode=country.code
WHERE city.name='shenyang';
|
子查询
子查询是将一个查询语句嵌套再另一个查询语句中的查询方式:
- 子查询的内层查询结果,可以作为外层查询语句提供查询条件。
- 子查询中可以包含
IN、NOT IN、AND、ALL、EXISTS、NOT EXISTS等关键字。
- 子查询中还可以包含比较运算符,如
=、!=、>、<等。
来看示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
-- 查询平均年龄在20以上的部门名称
SELECT NAME
FROM department
WHERE id IN (
SELECT dep_id
FROM employee
GROUP BY dep_id
HAVING AVG(age) > 20);
-- 查询财务部员工姓名
SELECT NAME
FROM employee
WHERE dep_id IN (
SELECT id
FROM department
WHERE NAME='财务部');
-- 查询所有大于平均年龄的员工的年龄和姓名
SELECT NAME,age
FROM employee
WHERE age > (
SELECT AVG(age) FROM employee);
|
查询中别名的应用
虽然之前也在使用别名,这里再次回顾下别名相关的知识。 别名共分为两类:
先来看列别名:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
-- 使用别名之前
SELECT city.name,city.population,country.name,country.surfacearea
FROM city INNER JOIN country
ON city.countrycode=country.code
WHERE city.name='shenyang';
+----------+------------+-------+-------------+
| name | population | name | surfacearea |
+----------+------------+-------+-------------+
| Shenyang | 4265200 | China | 9572900.00 |
+----------+------------+-------+-------------+
1 row in set (0.00 sec)
-- 使用别名之后
SELECT
city.name AS 城市名,
city.population AS 城市人口,
country.name AS 国家名,
country.surfacearea AS 国土面积
FROM city INNER JOIN country
ON city.countrycode=country.code
WHERE city.name='shenyang';
+-----------+--------------+-----------+--------------+
| 城市名 | 城市人口 | 国家名 | 国土面积 |
+-----------+--------------+-----------+--------------+
| Shenyang | 4265200 | China | 9572900.00 |
+-----------+--------------+-----------+--------------+
1 row in set (0.01 sec)
|
列别名的优点就是自定义返回的字段名称,主要是显式好看些!不过不推荐如上文中使用中文,可能会出现意外情况!
当然,AS也可以省略不写,效果一样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
SELECT
city.name 城市名,
city.population 城市人口,
country.name 国家名,
country.surfacearea 国土面积
FROM city INNER JOIN country
ON city.countrycode=country.code
WHERE city.name='shenyang';
+-----------+--------------+-----------+--------------+
| 城市名 | 城市人口 | 国家名 | 国土面积 |
+-----------+--------------+-----------+--------------+
| Shenyang | 4265200 | China | 9572900.00 |
+-----------+--------------+-----------+--------------+
1 row in set (0.00 sec)
|
再来看表别名:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
SELECT a.name,a.population,b.name,b.surfacearea
FROM city AS a INNER JOIN country AS b
ON a.countrycode=b.code
WHERE a.name='shenyang';
-- 表别名和列别名一起使用
SELECT
a.name AS 城市名,
a.population AS 城市人口,
b.name AS 国家名,
b.surfacearea AS 国土面积
FROM city AS a INNER JOIN country AS b
ON a.countrycode=b.code
WHERE a.name='shenyang';
|
别名的优点就是简化了编写SQL时的复杂性,因为有的表名和列名又臭又长!
函数
MySQL提供了丰富的内置函数自定义函数。
而我们也对这些函数有所了解,比如聚合函数。
本篇再来了解一些内置函数和自定义函数的编写。
写在前面的话:默认情况下,函数名称和其后的括号之间必须没有空格。这有助于MySQL解析器区分函数调用和对与函数名称相同的表或列的引用。但是,函数参数周围可以有空格。
内置函数
更多MySQL内置函数及用法参考MySQL5.7官网:https://dev.mysql.com/doc/refman/5.7/en/functions.html
字符串相关
1
2
3
4
5
6
7
8
9
10
11
12
13
|
SELECT CONCAT('root','@','127.0.0.1');
SELECT CONCAT(USER,'@',HOST) FROM mysql.user; -- 在合适的位置添加分隔符,较为灵活
SELECT CONCAT_WS('@',USER,HOST) FROM mysql.user; -- 第一个参数为分隔符
SELECT USER,GROUP_CONCAT(HOST) FROM mysql.user GROUP BY USER; -- 适用于分组,行转列
SELECT CHAR_LENGTH('ABCD'); -- 返回字符串的长度
SELECT CHARACTER_LENGTH('ABCD'); -- 和 CHAR_LENGTH 的同义词
SELECT LOWER('ABCD'); -- 以小写形式返回字符串
SELECT UPPER('abcd'); -- 以大写形式返回字符串, UPPER 是 UCASE 的同义词
SELECT TRIM(' ABCD '); -- 去除字符串两边的空格
SELECT BIN(12); -- 返回十进制数字的二进制表示
SELECT OCT(12); -- 返回十进制数字的八进制表示
SELECT HEX(12), HEX('ABCD'); -- 返回十进制数字或者字符串的十六进制的表示形式
SELECT UNHEX(HEX('ABCD')); -- 返回被转化为十六进制表示的原始数字或字符串
|
更多参考:https://dev.mysql.com/doc/refman/5.7/en/STRING-functions.html
数值相关
1
2
3
4
5
|
SELECT ABS(123); -- 返回数值的绝对值
SELECT 5 / 2,5 DIV 2; -- 向下整除
SELECT TRUNCATE(1.1234,2),TRUNCATE(-1.1234,2); -- 包括指定位数小数,数值可为负数
SELECT PI(); -- 返回6为小数的 Π 值
SELECT SQRT(2); -- 返回参数的平方根
|
更多参考:https://dev.mysql.com/doc/refman/5.7/en/numeric-functions.html
加密相关
先来说AES加密:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- AES_ENCRYPT:加密函数,第一个参数是需要加密的字符串,第二个参数是key
SELECT AES_ENCRYPT('ABCD', 'KEY'); -- 返回结果为乱码,表的字符集为拉丁或者utf8mb4可解决
SELECT CHAR_LENGTH(AES_ENCRYPT('ABCDE', 'KEY')); -- 加密字符串长度取决于原始字符串的长度
SELECT AES_DECRYPT(AES_ENCRYPT('ABCDE', 'KEY'), 'KEY')
-- AES_DECRYPT:解密函数,第一个参数是AES_ENCRYPT加密后的字符串,第二个参数是key
-- 示例
CREATE TABLE t2(
id INT PRIMARY KEY AUTO_INCREMENT,
USER VARCHAR(32) NOT NULL,
pwd VARCHAR(512) DEFAULT NULL
)ENGINE=INNODB CHARSET=utf8mb4;
-- 由于ASE加密后的字符串长度不定,这里使用 HEX函数强转为16进制字符串
INSERT INTO t2(USER,pwd) VALUE('张开', HEX(AES_ENCRYPT('加密字符串','KEY')));
-- 再通过 UNHEX 函数转换16进制字符串为加密后的字符,再AES_DECRYPT解密
SELECT USER,AES_DECRYPT(UNHEX(pwd),'KEY') AS pwd FROM t2;
|
再来说MD5和SHA系列:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
-- MD5加密
SELECT MD5('ABCD'),CHAR_LENGTH(MD5('ABCD')); -- MD5没啥好说的
-- SHA1
SELECT SHA1('ABCD'),CHAR_LENGTH(SHA1('ABCD')); -- 以40个十六进制数字的字符串形式返回
-- SHA1 是 SHA 的同义词
-- SHA2系列
SELECT SHA2('ABCD', 0),CHAR_LENGTH(SHA2('ABCD',0)); -- 64
SELECT SHA2('ABCD', 224),CHAR_LENGTH(SHA2('ABCD',224)); -- 56
SELECT SHA2('ABCD', 256),CHAR_LENGTH(SHA2('ABCD',256)); -- 64
SELECT SHA2('ABCD', 384),CHAR_LENGTH(SHA2('ABCD',384)); -- 96
SELECT SHA2('ABCD', 512),CHAR_LENGTH(SHA2('ABCD',512)); -- 128
SELECT SHA2('ABCD', 5122),CHAR_LENGTH(SHA2('ABCD',5122)); -- NULL
|
SHA2函数的第一个参数是需要加密的字符串,第二个参数必须是:
0/256:·0等于256,返回64位加密字符串224:返回56位加密字符串384:返回96位加密字符串512:返回128位加密字符串- 如果是其它数值,返回
NULL
参考:https://dev.mysql.com/doc/refman/5.7/en/encryption-functions.html
日期时间相关
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
SELECT NOW(); -- 返回当前日期时间
SELECT CURRENT_TIME(); -- 返回当前时间
SELECT CURRENT_DATE(); -- 返回当前日期
SELECT UNIX_TIMESTAMP() -- 返回时间戳时间
SELECT DAYOFMONTH(NOW()); -- 返回月份中的一天(0-31)
SELECT DAYOFYEAR(NOW()); -- 返回当前天位于一年中的第多少天
SELECT YEAR(NOW()); -- 提取年
SELECT HOUR(NOW()); -- 提取小时
SELECT DAY(NOW()); -- 提取天
SELECT MINUTE(NOW()); -- 提取分钟
SELECT MONTHNAME(NOW()); -- 返回当前月份
SELECT QUARTER(NOW()); -- 根据日期返回当前位于第几个季度
SELECT LAST_DAY(NOW()), LAST_DAY('2020-09-30'); -- 返回参数的月份的最后一天
SELECT DAYNAME(NOW()); -- 返回工作日的名称
SELECT WEEK(NOW()); -- 返回当前位于一年中位于第几个星期
SELECT WEEKDAY(NOW()); -- 返回工作日索引,0:星期一、1:星期二.....
SELECT WEEKOFYEAR(NOW()); -- 返回日期的日历周,范围是从1到的数字53
|
再来看日期时间的格式化转换:

1
2
3
4
5
6
7
|
SELECT DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%s'); -- 2020-09-17 15:18:53
SELECT DATE_FORMAT(NOW(), '%y-%m-%d %H:%i:%s'); -- 20-09-17 15:19:40
SELECT DATE_FORMAT('2009-10-04 22:23:00', '%W %M %Y'); -- Sunday October 2009
SELECT DATE_FORMAT('1900-10-04 22:23:00','%D %y %a %d %m %b %j'); -- 4th 00 Thu 04 10 Oct 277
SELECT DATE_FORMAT('1997-10-04 22:23:00','%H %k %I %r %T %S %w'); -- 22 22 10 10:23:00 PM 22:23:00 00 6
SELECT DATE_FORMAT('1999-01-01', '%X %V'); -- 1998 52
SELECT DATE_FORMAT('2006-06-00', '%d'); -- 00
|
上面是关于日期格式化的常见用法,而时间格式化参考日期格式化即可:
1
|
SELECT TIME_FORMAT(NOW(), '%H:%i:%s'); -- 15:18:26
|
TIME_FORMAT的用法类似于DATE_FORMAT,但是格式字符串可能只包含小时、分钟、秒和微秒的格式说明符。其他说明符生成空值或0。
其他
1
2
3
|
SELECT UUID(); -- 返回 UUID
SELECT SLEEP(3); -- 睡指定秒数
ISNULL() -- 在查询中,可以用来判断值是否为null
|
自定义函数
除了内置函数,MySQL还支持自定义函数。
创建
1
2
3
4
5
6
7
8
9
10
11
12
13
|
-- 创建一个函数,返回两个整数之和
DELIMITER //
CREATE FUNCTION f1(
n1 INT,
n2 INT) -- 创建函数 f1 参数可以是MySQL支持的那些类型
RETURNS INT -- 该函数的返回值也是 int 类型
BEGIN -- 标识函数体开始
DECLARE num INT; -- 定义一个int类型的变量
SET num = n1 + n2;
RETURN(num);
END // -- 标识函数体结束
DELIMITER ;
|
另外,函数中不能有SELECT语句
执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
SELECT f1(1,1);
-- 在查询中使用
CREATE TABLE t3(
n1 INT NOT NULL DEFAULT 0,
n2 INT NOT NULL DEFAULT 0
)ENGINE=INNODB CHARSET=utf8mb4;
INSERT INTO t3(n1,n2) VALUES(2,3),(3,4);
SELECT n1,n2,f1(n1,n2) AS '两数相加' FROM t3;
+----+----+--------------+
| n1 | n2 | 两数相加 |
+----+----+--------------+
| 2 | 3 | 5 |
| 3 | 4 | 7 |
+----+----+--------------+
2 rows in set (0.01 sec)
|
修改
函数的修改只能修改一些如COMMENT的选项,不能修改内部的SQL语句和参数列表,所以直接删了重建就完了。
查看
1
2
3
4
|
SHOW FUNCTION STATUS; -- 返回所有自定义函数
SHOW FUNCTION STATUS LIKE 'f%' -- 过滤
SHOW CREATE FUNCTION f1; -- 返回自定义函数的创建信息
SHOW CREATE FUNCTION tt.f1; -- 指定数据库下的自定义函数
|
删除
无需多说:
视图
视图是虚拟表,是从数据库中一个或多个表中导出来的表,其内容由查询定义;同真实表(基表)一样,视图包含一系列带有名称的字段和记录,在使用视图时动态生成。视图的数据变化会影响到基表,基表的数据变化也会影响到视图(insert、update、delete)。
另外,创建视图需要有create view权限,并且查询的列有select权限,使用create or update or alter修改视图,还需要有相应的drop权限。
视图可以查询、修改和删除,但不允许通过视图向基表插入数据。
视图的做用
对其中所引用的基础表来说,视图的做用类似于筛选,定义视图的筛选可以来自当前或者其他数据库的一个或多个表,也可以是其他视图;通过视图进行查询没有任何限制,通过它们进行数据修改时的限制也很少。
使用视图的优点
-
安全性,视图的安全性可以防止未授权用户查看特定的行或列,使有权限用户只能看到表中特定行的方法,如下:
-
在表中增加一个标志用户名的列。
-
建立视图,使用户只能看到标有自己用户名的行。
-
把视图授权给其他用户。
-
简单性,看到的就是需要的。视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
-
逻辑数据独立性,视图可以使应用程序和数据库表在一定程度上独立。如果没有视图,程序一定是建立在表上的。有了视图之后,程序可以建立在视图之上,从而程序与数据库表被视图分割开来。视图可以在以下几个方面使程序与数据独立。
-
如果应用建立在数据库表上,当数据库表发生变化时,可以在表上建立视图,通过视图屏蔽表的变化,从而使应用程序可以不动。
-
如果应用建立在数据库表上,当应用发生变化时,可以在表上建立视图,通过视图屏蔽应用的变化,从而使数据库表不动。
-
如果应用建立在视图上,当数据库表发生变化时,可以在表上修改视图,通过视图屏蔽表的变化,从而使应用程序可以不动。
-
如果应用建立在视图上,当应用发生变化时,可以在表上修改视图,通过视图屏蔽应用的变化,从而使数据库可以不动。
视图基本操作
创建视图
1
2
3
4
5
6
|
-- 基本语法
CREATE VIEW 视图名称 AS SQL语句;
-- 示例:查询中国所有城市信息,只展示前10条
CREATE VIEW v1 AS
SELECT * FROM city WHERE countrycode='CHN' LIMIT 10;
|
查询视图
1
2
|
-- 查询 v1 视图
SELECT * FROM v1;
|
修改视图
1
|
ALTER VIEW 视图名称 as SQL语句;
|
删除视图
information_schema是视图库(虚拟库):
1
2
|
USE information_schema;
SHOW TABLES; -- 返回了一堆视图
|
表由两部分组成:
- 元数据,表相关信息+字段信息(属性,约束)。
- 数据行,就是普通的记录了。
元数据单独存储在"基表"中,是我们无法直接访问的。但MySQL提供了DDL、DCL来进行对元数据修改;提供了information_schema和SHOW语句查询元数据。
MySQL5.7版本中,共有information_schema、performance_schema、sys三张视图库。但在MySQL早期版本中,只有information_schema视图库,后来方便,就把一些复杂的操作封装了一下,这就是performance_schema视图库,再后来又有了sys库,直到如今的版本中的三张视图库。
常用操作
这次,我们主要对information_schema.TABLES表进行学习,这个表存储了整个数据库中所有表的元数据。
1
2
3
4
5
6
7
8
|
-- information_schema.TABLES中常用的字段
DESC infoRmation_schema.TABLES;
TABLE_SCHEMA -- 库名
TABLE_NAME -- 表名
NEGINE -- 引擎
TABLE_ROWS -- 表行数
AVG_ROW_LENGTH -- 表中行平均长度(字节)
INDEX_LENGTH -- 索引的占用空间大小(字节)
|
知道了上面常用的字段之后,来看看我们平常用它来做什么:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
-- 查询information_schema.TABLES表信息
SELECT TABLE_SCHEMA,TABLE_NAME,ENGINE,TABLE_ROWS,AVG_ROW_LENGTH,INDEX_LENGTH
FROM information_schema.TABLES;
-- 查询整个数据库中所有库和对应的表信息
SELECT TABLE_SCHEMA, GROUP_CONCAT(TABLE_NAME)
FROM information_schema.TABLES
GROUP BY TABLE_SCHEMA;
-- 统计所有库下表的个数
SELECT TABLE_SCHEMA,COUNT(TABLE_NAME)
FROM information_schema.TABLES
GROUP BY TABLE_SCHEMA;
-- 查询所有使用innodb引擎的表及所在的库
SELECT TABLE_SCHEMA,TABLE_NAME,ENGINE
FROM information_schema.TABLES
WHERE ENGINE='innodb';
-- 统计指定数据库(world)下每张表的磁盘空间占用
SELECT TABLE_SCHEMA,TABLE_NAME,(TABLE_ROWS * AVG_ROW_LENGTH + INDEX_LENGTH) / 1024 AS 'size(KB)'
FROM information_schema.TABLES
WHERE TABLE_SCHEMA='world';
-- 统计所有数据库的总磁盘空间占用
SELECT COUNT(TABLE_SCHEMA) AS '数据库个数',SUM((TABLE_ROWS * AVG_ROW_LENGTH + INDEX_LENGTH) / 1024) AS 'size(KB)'
FROM information_schema.TABLES;
|
生成备份语句
如果有个需求是,生成全部数据库下所有表的备份语句,也就是生成一个bak.sh文件,其内存放的是一条条的备份语句,完事使用sh bak.sh就能批量的执行备份语句得到最终的备份文件。这整个流程该怎么做?
- 首先要先了解一个备份命令:
1
2
3
|
-- 注意其中的空格也是特殊字符(分隔符)
mysqldump -uroot -p123 world city >/bak/world_city.sql
-- 上面的例子是生成world.city表的备份,并且将备份导出到/bak/world_city.sql中
|
- 查询出来全部(这里以指定数据库为例)数据库下所有表,并且使用
CONCAT()函数进行拼接备份命令:
1
2
3
4
5
6
7
8
9
10
11
12
|
-- 生成指定(world)数据库下所有表的单独备份语句
SELECT CONCAT('mysqldump -uroot -p123 ',TABLE_SCHEMA,' ',TABLE_NAME,' >/bak/',TABLE_SCHEMA,'_',TABLE_NAME,'.sql')
FROM information_schema.TABLES
WHERE TABLE_SCHEMA='world'; -- 去掉 where 语句,就是整个数据库下所有表的备份语句
+------------------------------------------------------------------------------------------------------------+
| CONCAT('mysqldump -uroot -p123 ',TABLE_SCHEMA,' ',TABLE_NAME,' >/bak/',TABLE_SCHEMA,'_',TABLE_NAME,'.sql') |
+------------------------------------------------------------------------------------------------------------+
| mysqldump -uroot -p123 world city >/bak/world_city.sql |
| mysqldump -uroot -p123 world country >/bak/world_country.sql |
| mysqldump -uroot -p123 world countrylanguage >/bak/world_countrylanguage.sql |
+------------------------------------------------------------------------------------------------------------+
3 rows in set (0.00 sec)
|
- 拼接的备份命令完事了,现在使用
INTO OUTFILE '/tmp/xxx.sh'往本地磁盘上生成.sh文件了,这里还要做个设置,就是INTO OUTFILE后的tmp目录需要设置为安全路径(不然后续执行会报错),修改/etc/my.cnf配置文件,添加如下字段:
1
2
|
[mysqld]
secure-file-priv=/tmp
|
完事重启(systemctl restart mysqld.service)MySQL服务,下面是没有配置安全路径就执行命令报的错:
The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
- 生成
.sh文件:
1
2
3
4
5
6
7
8
|
-- 生成指定(world)数据库下所有表的单独备份语句
SELECT CONCAT('mysqldump -uroot -p123 ',TABLE_SCHEMA,' ',TABLE_NAME,' >/bak/',TABLE_SCHEMA,'_',TABLE_NAME,'.sql')
FROM information_schema.TABLES
WHERE TABLE_SCHEMA='world' -- 去掉 where 语句,就是整个数据库下所有表的备份语句
INTO OUTFILE '/tmp/mysql_bak.sh';
-- 这里要保证 /tmp 和 /bak 两个目录都存在
-- /tmp/mysql_bak.sh 是最终的脚本文件,里面存放的是一个个备份命令
-- /bak/ 该目录下面是当执行 /tmp/mysql_bak.sh 后生成的备份文件目录
|
- 执行
.sh文件,即执行备份命令:
[root@cs data]# ls /tmp/mysql_bak*
/tmp/mysql_bak.sh
[root@cs data]# sh /tmp/mysql_bak.sh
mysqldump: [Warning] Using a password on the command line interface can be insecure.
mysqldump: [Warning] Using a password on the command line interface can be insecure.
mysqldump: [Warning] Using a password on the command line interface can be insecure.
- 生成的备份文件在
/bak目录中:
[root@cs data]# ls /bak/
world_city.sql world_countrylanguage.sql world_country.sql
在整个流程中,需要注意的点:
/tmp and /bak目录要存在。mysqldump命令要熟悉。CONCAT()函数拼接要玩的溜,尤其注意其中的空格分隔符别忘了。my.cnf配置文件要记得配置安全路径,相关参数(secure-file-priv=/tmp)要知道。- 还要记得
INTO OUTFILE '/tmp/mysql_bak.sh'命令。
show命令
前面,我们使用SELECT命令对information_schema.TABLES表一顿操作;那么SHOW命令就是对常用的视图操作进行封装,便于操作,其实它本质上也是对information_schema库进行操作。
下面列举一些常用的SHOW命令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
show databases; -- 查看所有数据库
show tables; -- 查看当前库的所有表
show TABLES FROM -- 查看某个指定库下的表
show create database world -- 查看建库语句
show create table world.city -- 查看建表语句
show grants for root@'localhost' -- 查看用户的权限信息
show charset; -- 查看字符集
show collation -- 查看校对规则
show processlist; -- 查看数据库连接情况
show index from -- 表的索引情况
show status -- 数据库状态查看
show STATUS LIKE '%lock%'; -- 模糊查询数据库某些状态
show VARIABLES -- 查看所有配置信息
show variables LIKE '%lock%'; -- 查看部分配置信息
show engines -- 查看支持的所有的存储引擎
show engine innodb status\G -- 查看InnoDB引擎相关的状态信息
show binary logs -- 列举所有的二进制日志
show master status -- 查看数据库的日志位置信息
show binlog evnets in -- 查看二进制日志事件
show slave status \G -- 查看从库状态
show RELAYLOG EVENTS -- 查看从库relaylog事件信息
desc (show colums from city) -- 查看表的列定义信息
-- 不知道更多,请使用help
help show
|
更多SHOW命令参考:http://dev.mysql.com/doc/refman/5.7/en/show.html
最后,我们需要精通SHOW命令,因为我们对于视图的操作有6、70%都可以使用SHOW命令来完成;剩下的使用SELECT也就OK了。
触发器
触发器是与表有关的数据库对象,在满足特定的条件触发,并执行触发器中定义的语句集。
说白了,触发器就像一个牛皮糖,依附于某个表上,当表的行记录有增/删/改的操作时,可以触发触发器内提前写好的语句集的执行。
注意,查询时没有触发器的操作。
创建触发器的四大要素
- 监视谁:
table
- 监视什么事件:表中记录执行
insert/update/delete前后
- 触发条件:
after/before
- 要触发什么事件:
insert/update/delete
另外,还需要注意触发频率:针对每一行记录的操作都会触发触发器的执行。
还有:触发器无法与临时表或视图关联。
再来看触发器的类型:
| 触发器类型 | 适用语句 |
|---|
| INSERT型触发器 |
INSERT/LOAD DATA/REPLACE |
| UPDATE型触发器 |
UPDATE |
| DELETE型触发器 |
DELETE/REPLACE |
LOAD DATA语句是将文件的内容插入到表中,相当于是INSERT语句,而REPLACE语句在一般的情况下和INSERT差不多,但是如果表中存在PRIMARY 或者UNIQUE索引的时候,如果插入的数据和原来的PRIMARY KEY或者UNIQUE相同的时候,会删除原来的数据,然后增加一条新的数据,所以有的时候执行一条REPLACE语句相当于执行了一条DELETE和INSERT语句。
在触发器中,还有NEW和OLD语句可用:
| 触发器类型 | NEW和OLD的使用 | 备注 |
|---|
| INSERT型触发器 |
NEW表示将要或者已经新增的数据 |
没有OLD |
| UPDATE型触发器 |
OLD表示原数据;NEW表示修改后的数据 |
|
| DELETE型触发器 |
OLD表示将要或者已经删除的数据 |
没有NEW |
创建触发器
基本语法:
1
2
3
4
5
|
CREATE TRIGGER 触发器名 [BEFORE|AFTER] 触发事件
ON 表名 FOR EACH ROW -- FOR EACH ROW:基于每一行记录变动而触发
BEGIN -- 表示被触发的事件开始
-- 要执行的语句
END -- 表示被触发的事件结束
|
但是,由于MySQL默认以;作为语句的结束符,而在触发器内部的语句集中难免有语句以;结束,为了保证触发器内部语句逻辑完整性和不影响其他SQL的正常执行,通常使用DELIMITER语句来临时修改默认的语句结束符,所以,触发器的一般形式是这样的:
1
2
3
4
5
6
7
|
DELIMITER // -- 将MySQL的默认分隔符修改为 // 当然,你也可以指定别的符号
CREATE TRIGGER 触发器名 [BEFORE|AFTER] 触发事件
ON 表名 FOR EACH ROW -- FOR EACH ROW:基于每一行记录变动而触发
BEGIN
-- 要执行的语句
END // -- 这个 // 表示触发器部分逻辑执行完毕
DELIMITER ; -- 最后将默认分隔符再修改回来,不影响其他SQL的正常执行
|
少说多练,来上示例,首先我们模拟一个场景,就是,往user表中新增用户,都将会在log表中记录日志。
1
2
3
4
5
6
7
8
9
10
11
|
CREATE TABLE t_user(
id INT PRIMARY KEY AUTO_INCREMENT,
t_name VARCHAR(32) NOT NULL
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE t_log(
id INT PRIMARY KEY AUTO_INCREMENT,
t_log VARCHAR(32) NOT NULL,
t_log_type VARCHAR(32) NOT NULL,
t_log_time DATETIME
)ENGINE=INNODB CHARSET=utf8;
|
before/after insert
创建触发器,每当user表插入一条数据,就往log表写入2条记录:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- 插入前执行触发器
DELIMITER //
CREATE TRIGGER user_log_t1 BEFORE INSERT
ON t_user FOR EACH ROW
BEGIN
INSERT INTO t_log(t_log,t_log_type,t_log_time) VALUE(NEW.t_name, 'before insert', NOW());
END //
DELIMITER ;
-- 插入后执行触发器
DELIMITER //
CREATE TRIGGER user_log_t2 AFTER INSERT
ON t_user FOR EACH ROW
BEGIN
INSERT INTO t_log(t_log,t_log_type,t_log_time) VALUE(NEW.t_name, 'after insert', NOW());
END //
DELIMITER ;
|
我们往user表插入一条数据,在查看下log表:
1
2
3
4
5
6
7
8
9
10
11
|
mysql> INSERT INTO t_user(t_name) VALUE('张开');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM t_log;
+----+--------+---------------+---------------------+
| id | t_log | t_log_type | t_log_time |
+----+--------+---------------+---------------------+
| 1 | 张开 | before insert | 2020-09-15 21:32:57 |
| 2 | 张开 | after insert | 2020-09-15 21:32:57 |
+----+--------+---------------+---------------------+
2 rows in set (0.00 sec)
|
OK,没问题,触发器执行成功。
before/after update
啥也不说,创建触发器吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- 更新前执行触发器
DELIMITER //
CREATE TRIGGER user_log_t3 BEFORE UPDATE
ON t_user FOR EACH ROW
BEGIN
INSERT INTO t_log(t_log,t_log_type,t_log_time) VALUE(CONCAT(NEW.t_name, '|', OLD.t_name), 'before update', NOW());
END //
DELIMITER ;
-- 更新后执行触发器
DELIMITER //
CREATE TRIGGER user_log_t4 AFTER UPDATE
ON t_user FOR EACH ROW
BEGIN
INSERT INTO t_log(t_log,t_log_type,t_log_time) VALUE(CONCAT(NEW.t_name, '|', OLD.t_name), 'after update', NOW());
END //
DELIMITER ;
|
更新记录看效果吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
mysql> UPDATE t_user SET t_name='张开腿' WHERE t_name='张开';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * FROM t_log;
+----+------------------+---------------+---------------------+
| id | t_log | t_log_type | t_log_time |
+----+------------------+---------------+---------------------+
| 1 | 张开 | before insert | 2020-09-15 21:32:57 |
| 2 | 张开 | after insert | 2020-09-15 21:32:57 |
| 3 | 张开腿|张开 | before update | 2020-09-15 21:42:39 |
| 4 | 张开腿|张开 | after update | 2020-09-15 21:42:39 |
+----+------------------+---------------+---------------------+
4 rows in set (0.00 sec)
|
是不是很完美!
before/after delete
创建触发器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- 删除前执行触发器
DELIMITER //
CREATE TRIGGER user_log_t5 BEFORE DELETE
ON t_user FOR EACH ROW
BEGIN
INSERT INTO t_log(t_log,t_log_type,t_log_time) VALUE(OLD.t_name, 'before delete', NOW());
END //
DELIMITER ;
-- 删除后执行触发器
DELIMITER //
CREATE TRIGGER user_log_t6 AFTER DELETE
ON t_user FOR EACH ROW
BEGIN
INSERT INTO t_log(t_log,t_log_type,t_log_time) VALUE(OLD.t_name, 'after delete', NOW());
END //
DELIMITER ;
|
效果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
mysql> DELETE FROM t_user WHERE t_name='张开腿';
Query OK, 1 row affected (0.01 sec)
mysql> SELECT * FROM t_log;
+----+------------------+---------------+---------------------+
| id | t_log | t_log_type | t_log_time |
+----+------------------+---------------+---------------------+
| 1 | 张开 | before insert | 2020-09-15 21:32:57 |
| 2 | 张开 | after insert | 2020-09-15 21:32:57 |
| 3 | 张开腿|张开 | before update | 2020-09-15 21:42:39 |
| 4 | 张开腿|张开 | after update | 2020-09-15 21:42:39 |
| 5 | 张开腿 | before delete | 2020-09-15 21:48:47 |
| 6 | 张开腿 | after delete | 2020-09-15 21:48:47 |
+----+------------------+---------------+---------------------+
6 rows in set (0.00 sec)
|
演示到这里,基本上触发器的常用方式也演示完了,通过几个例子,可以发现,一个表中可以建立多个触发器。
查看触发器
查看我们上面创建的几个触发器该怎么办?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
SHOW TRIGGERS;
+-------------+--------+--------+--------------------------------------------------------------------------------------------------------------------------------+--------+------------------------+-------------------------------------------------------------------------------------------------------------------------------------------+-------------------+----------------------+----------------------+--------------------+
| Trigger | Event | Table | Statement | Timing | Created | sql_mode | Definer | character_set_client | collation_connection | Database Collation |
+-------------+--------+--------+--------------------------------------------------------------------------------------------------------------------------------+--------+------------------------+-------------------------------------------------------------------------------------------------------------------------------------------+-------------------+----------------------+----------------------+--------------------+
| user_log_t1 | INSERT | t_user | begin
insert into t_log(t_log,t_log_type,t_log_time) value(new.t_name, 'before insert', now());
end | BEFORE | 2020-09-15 21:32:44.24 | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION | root@192.168.85.% | utf8 | utf8_general_ci | utf8_general_ci |
| user_log_t2 | INSERT | t_user | BEGIN
INSERT INTO t_log(t_log,t_log_type,t_log_time) VALUE(new.t_name, 'after insert', NOW());
end | AFTER | 2020-09-15 21:32:47.70 | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION | root@192.168.85.% | utf8 | utf8_general_ci | utf8_general_ci |
| user_log_t3 | UPDATE | t_user | BEGIN
INSERT INTO t_log(t_log,t_log_type,t_log_time) VALUE(concat(NEW.t_name, '|', OLD.t_name), 'before update', NOW());
END | BEFORE | 2020-09-15 21:41:21.76 | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION | root@192.168.85.% | utf8 | utf8_general_ci | utf8_general_ci |
| user_log_t4 | UPDATE | t_user | BEGIN
INSERT INTO t_log(t_log,t_log_type,t_log_time) VALUE(CONCAT(NEW.t_name, '|', OLD.t_name), 'after update', NOW());
END | AFTER | 2020-09-15 21:41:17.00 | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION | root@192.168.85.% | utf8 | utf8_general_ci | utf8_general_ci |
| user_log_t5 | DELETE | t_user | BEGIN
INSERT INTO t_log(t_log,t_log_type,t_log_time) VALUE(OLD.t_name, 'before delete', NOW());
END | BEFORE | 2020-09-15 21:47:17.24 | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION | root@192.168.85.% | utf8 | utf8_general_ci | utf8_general_ci |
| user_log_t6 | DELETE | t_user | BEGIN
INSERT INTO t_log(t_log,t_log_type,t_log_time) VALUE(OLD.t_name, 'after delete', NOW());
END | AFTER | 2020-09-15 21:47:20.81 | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION | root@192.168.85.% | utf8 | utf8_general_ci | utf8_general_ci |
+-------------+--------+--------+--------------------------------------------------------------------------------------------------------------------------------+--------+------------------------+-------------------------------------------------------------------------------------------------------------------------------------------+-------------------+----------------------+----------------------+--------------------+
6 rows in set (0.00 sec)
|
SHOW TRIGGERS返回了所有的触发器概要信息,无法查看指定的触发器信息,但可以通过视图表来查看:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
-- 所有的触发器都在 information_schema.triggers 表中
SELECT * FROM information_schema.triggers;
-- 可以跟 where条件过滤指定的触发器
SELECT * FROM information_schema.triggers WHERE trigger_name='user_log_t1';
-- 触发器返回字段过多,可以过滤指定字段
SELECT trigger_name,event_manipulation,event_object_table,created
FROM information_schema.triggers
WHERE trigger_name='user_log_t1';
+--------------+--------------------+--------------------+------------------------+
| trigger_name | event_manipulation | event_object_table | created |
+--------------+--------------------+--------------------+------------------------+
| user_log_t1 | INSERT | t_user | 2020-09-15 21:32:44.24 |
+--------------+--------------------+--------------------+------------------------+
1 row in set (0.00 sec)
|
删除触发器
无需多说,关门上drop:
1
2
3
4
5
|
-- 语法
DROP TRIGGER 触发器名;
-- 示例
DROP TRIGGER user_log_t1;
|
另外,当触发器依附的表被删除后,该表相关的触发器也就没了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
mysql> SELECT trigger_name,event_manipulation,event_object_table,created FROM information_schema.triggers WHERE event_object_table='t_user';
+--------------+--------------------+--------------------+------------------------+
| trigger_name | event_manipulation | event_object_table | created |
+--------------+--------------------+--------------------+------------------------+
| user_log_t1 | INSERT | t_user | 2020-09-16 09:43:15.66 |
| user_log_t2 | INSERT | t_user | 2020-09-16 09:43:18.55 |
| user_log_t3 | UPDATE | t_user | 2020-09-16 09:43:24.40 |
| user_log_t4 | UPDATE | t_user | 2020-09-16 09:43:33.31 |
| user_log_t5 | DELETE | t_user | 2020-09-16 09:43:37.27 |
| user_log_t6 | DELETE | t_user | 2020-09-16 09:43:39.95 |
+--------------+--------------------+--------------------+------------------------+
6 rows in set (0.00 sec)
mysql> DROP TABLE t_user;
Query OK, 0 rows affected (0.01 sec)
mysql> SELECT trigger_name,event_manipulation,event_object_table,created FROM information_schema.triggers WHERE event_object_table='t_user';
Empty set (0.00 sec)
|
小结
限制和注意事项
触发器会有以下两种限制:
-
触发程序不能调用将数据返回客户端的存储程序,也不能使用采用CALL语句的动态SQL语句,但是允许存储程序通过参数将数据返回触发程序,也就是存储过程或者函数通过OUT或者INOUT类型的参数将数据返回触发器是可以的,但是不能调用直接返回数据的过程。
-
不能在触发器中使用以显示或隐式方式开始或结束事务的语句,如START TRANS-ACTION,COMMIT或ROLLBACK。
注意事项:MySQL的触发器是按照BEFORE触发器、行操作、AFTER触发器的顺序执行的,其中任何一步发生错误都不会继续执行剩下的操作,如果对事务表进行的操作,如果出现错误,那么将会被回滚,如果是对非事务表进行操作,那么就无法回滚了,数据可能会出错。
触发器是基于行触发的,所以删除、新增或者修改操作可能都会激活触发器,所以不要编写过于复杂的触发器,也不要增加过得的触发器,这样会对数据的插入、修改或者删除带来比较严重的影响,同时也会带来可移植性差的后果,所以在设计触发器的时候一定要有所考虑。
触发器是一种特殊的存储过程,它在插入,删除或修改特定表中的数据时触发执行,它比数据库本身标准的功能有更精细和更复杂的数据控制能力。
数据库触发器有以下的作用:
-
安全性,可以基于数据库的值使用户具有操作数据库的某种权利。
- 可以基于时间限制用户的操作,例如不允许下班后和节假日修改数据库数据。
- 可以基于数据库中的数据限制用户的操作,例如不允许股票的价格的升幅一次超过10%。
-
审计,可以跟踪用户对数据库的操作。
- 审计用户操作数据库的语句。
- 把用户对数据库的更新写入审计表。
-
实现复杂的数据完整性规则
- 实现非标准的数据完整性检查和约束。触发器可产生比规则更为复杂的限制。与规则不同,触发器可以引用列或数据库对象。例如,触发器可回退任何企图吃进超过自己保证金的期货。
- 提供可变的缺省值。
-
实现复杂的非标准的数据库相关完整性规则。触发器可以对数据库中相关的表进行连环更新。
- 在修改或删除时级联修改或删除其它表中的与之匹配的行。
- 在修改或删除时把其它表中的与之匹配的行设成NULL值。
- 在修改或删除时把其它表中的与之匹配的行级联设成缺省值。
- 触发器能够拒绝或回退那些破坏相关完整性的变化,取消试图进行数据更新的事务。当插入一个与其主健不匹配的外部键时,这种触发器会起作用。
-
同步实时地复制表中的数据。
-
自动计算数据值,如果数据的值达到了一定的要求,则进行特定的处理。例如,如果公司的帐号上的资金低于5万元则立即给财务人员发送警告数据。
执行计划
现在,让我们回想一下SQL的执行过程:
- 客户端将SQL发送到
mysqld。
- 经过连接层。
- 在SQL层,会经过、语法、语意检查、权限检查后经过解析器预处理后,产生计划(可能产生多个执行计划),优化器根据解析器得出的多种执行计划,选择一个最优执行计划,然后执行器执行
SQL产生执行结果。
- 经过存储引擎层一顿操作后通过专用线程将结果返回给客户端。
而本篇就来研究执行计划,通过执行计划可以了解MySQL选择了什么执行计划来执行SQL,并且SQL的执行过程到此结束,即并不会真正的往下交给执行器去执行;最终的目的还是优化MySQL的性能。
我们通过EXPLAIN语句来查看查看MySQL如何执行语句的信息;EXPLAIN语句可以查看SELECT、DELETE、INSERT、REPLACT和UPDATE语句。
而我们这里重点关注查询时时的执行计划。
1
2
3
4
5
6
7
8
9
10
11
|
-- 基本用法
EXPLAIN SQL语句;
-- 示例
EXPLAIN SELECT * FROM city WHERE id<3;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 2 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
|
返回中的重要参数:
| 字段 | 描述 | 备注 |
|---|
id |
该SELECT标识符 |
|
select_type |
该SELECT类型 |
|
table |
输出结果的表 |
|
partitions |
匹配的分区 |
|
type |
表的连接类型 |
|
possible_keys |
查询时可能的索引选择 |
只是有可能选择的索引,但是也能最后选择的索引不在该字段中 |
key |
实际选择的索引 |
需要重点了解的 |
key_len |
所选KEY的长度 |
|
ref |
列与索引的比较 |
|
rows |
表示MySQL认为执行查询必须检查的行数 |
innodb中是个估算值 |
filtered |
按表条件过滤的行百分比 |
|
Extra |
执行情况的附加信息 |
需要重点了解的 |
这里我们重点掌握KEY和Extra字段。其他的就参考:EXPLAIN Output Format
其次,EXPLAIN为SELECT语句中使用到的每个表都返回一行信息,并且按照MySQL在处理语句时读取它们的顺序列出了输出中的表:
1
2
3
4
5
6
7
8
9
10
|
DESC SELECT city.name,city.population,country.code,country.name
FROM city INNER JOIN country
ON city.countrycode = country.code;
+----+-------------+---------+------------+------+---------------------+-------------+---------+--------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------------+-------------+---------+--------------------+------+----------+-------+
| 1 | SIMPLE | country | NULL | ALL | PRIMARY | NULL | NULL | NULL | 239 | 100.00 | NULL |
| 1 | SIMPLE | city | NULL | ref | CountryCode,inx_c_p | CountryCode | 3 | world.country.Code | 18 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------------+-------------+---------+--------------------+------+----------+-------+
2 rows in set, 1 warning (0.00 sec)
|
MySQL使用嵌套循环连接方法解析所有连接。这意味着MySQL从第一个表中读取一行,然后在第二个表,第三个表中找到匹配的行,依此类推。处理完所有表后,MySQL通过表列表输出选定的列和回溯,直到找到一个表,其中存在更多匹配的行。从该表中读取下一行,然后继续下一个表。
参见:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#jointype_system
另外,DESCRIBE和EXPLAIN是同义词,同样可以查看语句的执行计划:
1
2
3
4
|
-- 下面三条语句是等价的
EXPLAIN SELECT * FROM city WHERE id<3;
DESCRIBE SELECT * FROM city WHERE id<3;
DESC SELECT * FROM city WHERE id<3;
|
实际上,DESCRIBE关键字通常用于获取有关表结构的信息,而EXPLAIN用于获取查询执行计划(即,有关MySQL如何执行查询的说明)。
rows
rows官方文档:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain_rows
为了更好的理解EXPLAIN,rows参数也是一个很好的参考,以下来自官网对rows的解释:
The rows column indicates the number of rows MySQL believes it must examine to execute the query.
For InnoDB tables, this number is an estimate, and may not always be exact.
这个字段表示MySQL认为执行查询必须检查的行数。
对于存储引擎是innodb的表,这个数值是个估计值,并不是精确值。
type
type的官方文档:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-join-types
type的官方全称是join type,意思是"连接类型",这容易让人误会是联表的连接类型,其实不然,这里的join type事实上是数据库引擎查找表的一种方式,我们这里可以像在《高性能MySQL》中作者称呼join type为访问类型更贴切些。
该type列输出介绍如何联接表,接下来列举常见联接类型,性能从最佳到最差排序:
我们挑重点的说!为了便于理解,这里从性能最差到最佳排序一一说明。
all
all便是所谓的全表扫描了,如果出现了all类型,通常意味着你的SQL处于一种最原始的状态,还有很大的优化空间!为什么这么说,因为all是一种非常原始的查找方式,低效且耗时,用all查找相当于你去一个2万人的学校找"张开",all的方式是把这2万人全找个遍,即便你踩了狗屎找的第一个人就叫"张开",那你也不能停,因为无法确定这两万人中是否还有"张开"存在,直到把2万人找完为止。所以除了极端情况,我们应该避免这种情况出现。
我们来看常见出现all的情况。
- 查询条件字段是非索引字段:
1
2
3
4
5
6
7
|
EXPLAIN SELECT * FROM city WHERE district='henan';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | ALL | NULL | NULL | NULL | NULL | 4188 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
|
- 查询条件中,包含
!=、not in、like。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
-- 注意,以下情况适用于辅助索引
EXPLAIN SELECT * FROM city WHERE countrycode NOT IN ('CHN','USA');
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | ALL | CountryCode | NULL | NULL | NULL | 4188 | 82.19 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
EXPLAIN SELECT * FROM city WHERE countrycode != 'CHN';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | ALL | CountryCode | NULL | NULL | NULL | 4188 | 88.73 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
-- 而聚集索引来说,还是会走索引
EXPLAIN SELECT * FROM city WHERE id != 10;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 2103 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
-- 而针对于like情况,% 放在首位不会走索引,放在后面会走索引
EXPLAIN SELECT * FROM city WHERE countrycode LIKE 'CH%'; -- 走索引
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | city | NULL | range | CountryCode | CountryCode | 3 | NULL | 397 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
EXPLAIN SELECT * FROM city WHERE countrycode LIKE '%H%'; -- 不走索引
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | ALL | NULL | NULL | NULL | NULL | 4188 | 11.11 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
|
index
index是另一种形式上的all类型,只不过index是全索引扫描(但索引也是建立在全表记录上的),index根据条件扫描索引然后回表取数据。index和all相比,它们都扫描了全表的数据,而且index要先扫索引再回表取数据,这么一说,还不如all快呢(在同样的工况下)!但是为啥官方说index比all效率高呢?原因(我经过严格的逻辑推理和分析得来的)在于索引是有序的,所以index效率高些,来看排序示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
EXPLAIN SELECT * FROM city ORDER BY id; -- id 是主键
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| 1 | SIMPLE | city | NULL | index | NULL | PRIMARY | 4 | NULL | 4188 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
EXPLAIN SELECT * FROM city ORDER BY population; -- 普通字段
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | city | NULL | ALL | NULL | NULL | NULL | NULL | 4188 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
|
首先要注意观察rows字段,都是全表扫描。
可以看到根据population排序走的是ALL访问类型,但Extra字段说使用Using filesort;而根据主键id排序的访问类型是index,并且Extra字段是NULL,即没有额外的排序,所以这可能就是官方说index比all性能好的原因。
还有一种情况需要我们注意,那就是Extra字段是Using index,并且type是index:
1
2
3
4
5
6
7
|
EXPLAIN SELECT id FROM city;
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | index | NULL | CountryCode | 3 | NULL | 4188 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
|
如上这种情况我们称为"索引覆盖",那什么是"索引覆盖"?举个例子:我们从字典(一张表)的目录(索引)中找到所有的字,而无需查每个字的实际位置,因为我们想要的数据都在索引中,这就是"索引覆盖",稍微正式点的解释:只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
range
range是基于索引的范围扫描,包含>,<,>=,<=,!=,like,in,not in,or,!=,not in的情况会走range;
出现range的条件是:查询条件列是非PRIMARY KEY和UNIUQE KEY的索引列,也就是说条件列使用了索引,但该索引列的值并不是唯一的,这样的话,即使很快的找到了第一条数据,但仍然不能停止的在指定的范围内继续找。
range的优点是不需要扫描全表,因为索引是有序的,即使有重复值,但也被限定在指定的范围内。
1
2
3
4
5
6
|
-- 首先为 population 字段建立一个普通索引,现在 population 和 countrycode 是普通索引,而 id 是主键
ALTER TABLE city ADD INDEX idx_p(population);
-- 示例
EXPLAIN SELECT * FROM city WHERE population < 100000; -- 走索引的范围查找
EXPLAIN SELECT * FROM city WHERE countrycode LIKE 'CH%'; -- 因为索引是有序的,也走索引的范围查找
|
注意,上面前两个例子可以享受到B+树带来的查询优势(查询连续);而下面的例子是无法享受的(查询不连续):
1
2
3
4
5
6
7
|
EXPLAIN SELECT * FROM city WHERE countrycode IN ('CHN','USA');
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | city | NULL | range | CountryCode | CountryCode | 3 | NULL | 637 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)
|
对此,我们可以做些优化:
1
2
3
4
5
6
7
8
9
10
|
EXPLAIN SELECT * FROM city WHERE countrycode='CHN'
UNION ALL
SELECT * FROM city WHERE countrycode='USA';
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| 1 | PRIMARY | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | NULL |
| 2 | UNION | city | NULL | ref | CountryCode | CountryCode | 3 | const | 274 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
2 rows in set, 1 warning (0.00 sec)
|
ref
ref出现的条件是: 查找条件列使用了索引但不是PRIMARY KEY和UNIQUE KEY。其意思就是虽然使用了索引,但该索引列的值并不唯一,有重复。这样即使使用索引快速查找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描。但它的好处是它并不需要扫全表,因为索引是有序的,即便有重复值,也是在一个非常小的范围内扫描。
1
2
3
4
5
6
7
|
EXPLAIN SELECT * FROM city WHERE countrycode='CHN';
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
|
eq_ref
在多表连接时,连接条件(ON)使用了唯一索引(UNIQUE NOT NULL,PRIMARY KEY)时,走eq_ref。
1
2
3
4
5
6
7
8
9
10
11
12
|
-- 查询世界上人口小于100人的城市名字
EXPLAIN SELECT city.name,city.population,country.code,country.name
FROM city INNER JOIN country
ON city.countrycode = country.code -- country表的code字段是 pk
WHERE city.population<100;
+----+-------------+---------+------------+--------+---------------+---------+---------+------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+--------+---------------+---------+---------+------------------------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | ALL | CountryCode | NULL | NULL | NULL | 4188 | 33.33 | Using where |
| 1 | SIMPLE | country | NULL | eq_ref | PRIMARY | PRIMARY | 3 | world.city.CountryCode | 1 | 100.00 | NULL |
+----+-------------+---------+------------+--------+---------------+---------+---------+------------------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
|
这里如果使用的单表来测试eq_ref,经常会出现const,后来想想是对的!UNIQUE NOT NULL和PRIMARY KEY都具有唯一性,而匹配结果是唯一的可不就是const么!所以eq_ref多出现在联表查询中,因为联接条件通常都是具有唯一性或者主键!
除了 system和 const类型,eq_ref是最好的联接类型。
const,system
首先,system是最优的,它的意思是表只有一行(但效果我没演示出来),是const类型的一种特例,所以就把这两个列一块了。
1
2
3
4
5
6
7
|
EXPLAIN SELECT * FROM city WHERE id=3;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | city | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
|
const表示:该表最多具有一个匹配行,该行在查询开始时读取。因为又只有一行,所以优化器的其余部分可以将这一行中的列的值视为一个常量。
我们将const看作是最快的,因为只有一行匹配结果。
EXPLAIN输出的extra列包含有关MySQL如何解析查询的其他信息,帮助我们进一步了解执行计划的细节信息。
这里我们也是挑些常用的说。
Using where
查询语句中使用WHERE条件过滤数据。出现WHERE情况有点复杂,我们来举几个例子。
- 当
WHERE条件是索引列时:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
EXPLAIN SELECT id FROM city WHERE id<10;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | city | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 9 | 100.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
EXPLAIN SELECT * FROM city WHERE id<10;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 9 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
|
两个查询条件一致,就是返回的结果字段不一样,第一个返回id字段,这个id字段是个主键,所以在Using where的基础上又Using index,这表示,id字段的值在索引上就查到了,没有进行回表查询;而第二个返回的是所有字段,其它字段不包含索引列,所以要回表查询,也就没有了Using index,所以,第一个性能高些。
- 当
WHERE条件是非索引列时:
1
2
3
4
5
6
7
8
9
10
|
EXPLAIN SELECT * FROM city WHERE district='henan';
EXPLAIN SELECT id FROM city WHERE district='henan';
EXPLAIN SELECT countrycode FROM city WHERE district='henan';
EXPLAIN SELECT district FROM city WHERE district='henan';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | ALL | NULL | NULL | NULL | NULL | 4188 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
|
上面几个查询语句中的查询条件不变,并且district字段时非索引字段,所以,无论是是返回所有字段、还是只返回主键、普通索引字段、普通非索引字段,都是Using where,并且观察type栏是ALL,所以,可以对district字段做优化,也就是添加个索引,性能会好些:
1
2
3
4
5
6
7
8
|
ALTER TABLE city ADD INDEX idx_d(district);
EXPLAIN SELECT district FROM city WHERE district='henan';
+----+-------------+-------+------------+------+---------------+-------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | ref | idx_d | idx_d | 20 | const | 18 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+-------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
|
性能立马就上来了!
通过几个示例,我们也能看到,当Extra栏出现Using where时,可以参考type栏做适当优化:
- 当
type栏是ALL时,说明SQL语句有很大的优化空间。
- 当
Extra栏是Using index时,参考type栏的情况,可以看看是不是建个索引。
- 如果出现回表查询情况,尽量避免使用
select *,而是选择返回指定字段,然后为指定字段尝试是否可以建个联合索引。
Using index
当Extra栏出现Using index表示使用覆盖索引进行数据返回,没有回表查询。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
EXPLAIN SELECT countrycode FROM city WHERE countrycode='CHN';
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
EXPLAIN SELECT * FROM city WHERE countrycode='CHN';
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
|
上面第二个示例,就出现了回表查询的情况,因为有的字段不在索引中。
Using index condition
当Extra栏出现Using index condition时,表示先使用索引条件过滤数据,然后根据其他子句进行回表查询操作:
1
2
3
4
5
6
7
8
|
ALTER TABLE city ADD INDEX inx_p(Population); -- 首先为population字段建立一个索引
EXPLAIN SELECT name,population FROM city WHERE population<100;
+----+-------------+-------+------------+-------+---------------+-------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | city | NULL | range | inx_p | inx_p | 4 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+-------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
|
上例的population字段是索引字段,先走索引把符合条件的结果过滤出来,然后select语句还需要查询name字段,就又回表查询了。
Using temporary
当Extra栏出现Using temporary时,表示MySQL需要创建临时表来保存临时结果;如果查询包含不同列的GROUP BY和ORDER BY子句时,通常会需要临时表:
1
2
3
4
5
6
7
|
EXPLAIN SELECT Population FROM city GROUP BY Population;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| 1 | SIMPLE | city | NULL | ALL | NULL | NULL | NULL | NULL | 4188 | 100.00 | Using temporary; Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
1 row in set, 1 warning (0.00 sec)
|
Using filesort
刚才出现了Using filesort,这个是啥意思呢?先来看个示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
EXPLAIN SELECT * FROM city ORDER BY population; -- population 为普通索引字段
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | city | NULL | ALL | NULL | NULL | NULL | NULL | 4188 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set, 1 warning (0.01 sec)
EXPLAIN SELECT * FROM city WHERE countrycode='CHN' ORDER BY population; -- countrycode 和 population 都为索引列
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+---------------------------------------+
| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | Using index condition; Using filesort |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+---------------------------------------+
1 row in set, 1 warning (0.00 sec)
|
由上例的查询语句可以看到,Extra栏是Using index condition; Using filesort,走索引我们可以理解,毕竟countrycode字段是索引字段,而Using filesort则要好好来聊聊了。
这个filesort并不是说通过磁盘文件进行排序,而是告诉我们在查询时进行了一个排序操作,即在查询优化器(MySQL Query Optimizer)所给出的执行计划中被称为文件排序(filesort)。
文件排序是通过相应的排序算法,将取得的数据在内存中进行排序。MySQL需要将数据在内存中进行排序,所使用的内存区域(通过系统变量sort_buffer_size设置的排序区),这个排序区是每个Thread独享的,所以说可能在同一时刻,MySQL中可能会存在多个sort buffer内存区域。
我们来看下filesort的排序过程,加深理解:
- 根据表的索引或者全表扫描,读取所有满足条件的记录。
- 对于每一行,存储一对值(排序列,行行为记录指针)到缓冲区;排序的索引列的值,即
ORDER BY用到的列值和指向该行数据的行指针;缓冲区的大小为sort_buffer_size大小。
- 当缓冲区满后,运行一个快速排序(
quick sort)来将缓冲区中的数据排序,并将排序完的数据存储到一个临时文件(存储块)中,并保存一个存储块的指针;当然,如果缓冲区不满,也就不用搞什么临时文件了。
- 重复以上步骤,直到将所有行读完,并建立相应的有序的临时文件。
- 使用归并排序(貌似是,如果错误可以指正)对存储块进行排序,只通过两个临时文件的指针来不断的交换数据,最终达到两个文件都是有序的。
- 重复步骤5过程,直到所有的数据都排序完毕。
- 采用顺序读取的方式,将每行数据读入内存,并取出数据传到客户端,注意,这里的读数据并不是一行一行的读,读的缓存大小由
read_rnd_buffer_size来决定。
以上就是filesort的过程,采取的方法为快排加归并;但我们应该注意到,一行数据会被读两次,第一次是WHERE条件过滤时;第二个是排序完毕后还要用行指针去读一次(发给客户端)。所以,这里也有一个优化方案,那就是直接读入数据,在sort_buffer中排序完事后,直接发送到客户端了,大致过程如下:
- 读取满足条件的记录。
- 对于每一行,记录排序的
KEY和数据行指针,并且把要查询的列也读出来。
- 根据索引
KEY进行排序。
- 读取排序完成的数据,并且直接根据数据位置读取数据返回客户端。
但问题也来了,在查询的在字段很多,数据量很大时,排序起来就很占用空间,因此max_length_for_sort_data变量就决定了是否能使用这个排序算法。
我们可以总结一下上面的两种方案:
- 双路排序:首先根据相应的条件取出相应的排序字段和可以直接定位行数据的行指针信息,然后在
sort buffer中进行排序,排序后在把查询字段依照行指针取出,共执行两次磁盘I/O。
- 双路排序由于有大量的随机
I/O,效率不高,但是节约内存;排序使用快排(quick sort)算法,但是如果内存不够则会使用块排序(block sort),将排序结果写入磁盘,然后再将结果合并。
- 单路排序:一次性取出满足条件行的所有字段,然后在
sort buffer中进行排序,执行一次磁盘你I/O;当然,遇到内存不足时仍然会使用临时文件。
MySQL主要通过比较我们所设定的系统参数max_length_for_sort_data的大小和Query语句所取出的字段类型大小总和来判断需要使用哪种排序算法;如果max_length_for_sort_data更大,则使用优化后的单路排序,反之使用双路排序。
另外,在连表查询中,如果ORDER BY的子句只引用了第一个表,那么MySQL会先对第一个表进行排序,然后再连表,此时执行计划中的Extra就是Using filesort,否则MySQL会先把结果保存到临时表中,然后再对临时表进行排序,此时执行计划中的Extra就是Using filesort
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
-- 查询世界上人口小于100人的城市名字
DESC SELECT city.name,city.population,country.code,country.name
FROM city INNER JOIN country
ON city.countrycode = country.code
WHERE city.population<100 -- 先把条件过滤出来,再连表操作
ORDER BY city.population;
+----+-------------+---------+------------+--------+---------------+---------+---------+------------------------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+--------+---------------+---------+---------+------------------------+------+----------+-----------------------------+
| 1 | SIMPLE | city | NULL | ALL | CountryCode | NULL | NULL | NULL | 4188 | 33.33 | Using where; Using filesort |
| 1 | SIMPLE | country | NULL | eq_ref | PRIMARY | PRIMARY | 3 | world.city.CountryCode | 1 | 100.00 | NULL |
+----+-------------+---------+------------+--------+---------------+---------+---------+------------------------+------+----------+-----------------------------+
2 rows in set, 1 warning (0.00 sec)
-- 查询世界上人口小于100人的城市名字
DESC SELECT city.name,city.population,country.code,country.name
FROM city INNER JOIN country
ON city.countrycode = country.code
-- where city.population<100 -- 没有where条件,直接连表然后生成临时表,完事再排序
ORDER BY city.population;
+----+-------------+---------+------------+------+---------------+-------------+---------+--------------------+------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+-------------+---------+--------------------+------+----------+---------------------------------+
| 1 | SIMPLE | country | NULL | ALL | PRIMARY | NULL | NULL | NULL | 239 | 100.00 | Using temporary; Using filesort |
| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | world.country.Code | 18 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+-------------+---------+--------------------+------+----------+---------------------------------+
2 rows in set, 1 warning (0.00 sec)
|
一般的,在如下的几种情况中,也会使用文件排序:
WHERE语句于ORDER BY语句使用了不同的索引。- 检查的行数据过多,且没有使用覆盖索引。
- 对索引列使用了
ASC和 DESC。
WHERE语句或者ORDER BY语句中索引列使用了表达式,包括函数表达式。WHERE语句与ORDER BY语句组合满足最左前缀,但WHERE语句中查找的是范围。
所以,想要加快ORDER BY的排序速度,可以:
- 增加
sort_buffer_size的大小,如果大量的查询较小的话,这个很好,在缓冲区就直接搞定了。
- 增加
read_rnd_buffer_size的大小,可以一次性的将更多的数据读入到内存中去。
- 列长度尽量小些。
再来个示例:
1
2
3
4
5
6
7
8
9
|
-- 先看下当前表的索引情况,心里有底
SHOW INDEX FROM city;
+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| city | 0 | PRIMARY | 1 | ID | A | 4188 | NULL | NULL | | BTREE | | |
| city | 1 | CountryCode | 1 | CountryCode | A | 232 | NULL | NULL | | BTREE | | |
+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
|
现在做个查询操作:
1
2
3
4
5
6
7
|
DESC SELECT * FROM city WHERE countrycode='CHN' ORDER BY Population;
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+---------------------------------------+
| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | Using index condition; Using filesort |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+---------------------------------------+
1 row in set, 1 warning (0.00 sec)
|
可以看到了使用了索引也使用了文件排序,遇到这种情况,我们可以通过以下思路来解决:
- 观察需要排序(
ORDER BY,GROUP BY ,DISTINCT )的条件,有没有索引。
- 如果没有,可以根据子句的执行顺序,去创建联合索引。
按照上述思路,我们可以先为ORDER BY语句的population字段和countrycode添加一个联合索引:
1
2
3
4
5
6
7
8
9
10
|
-- 添加一个联合索引
ALTER TABLE city ADD INDEX inx_c_p(CountryCode,Population);
-- 可以看到走了联合索引,然后没有了文件排序
DESC SELECT * FROM city WHERE countrycode='CHN' ORDER BY Population;
+----+-------------+-------+------------+------+---------------------+---------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------------+---------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | city | NULL | ref | CountryCode,inx_c_p | inx_c_p | 3 | const | 363 | 100.00 | Using index condition |
+----+-------------+-------+------------+------+---------------------+---------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
|
小结
执行计划算是MySQL优化部分的内容了,想要弄懂首先要对SQL语句非常熟练,并且也要非常熟练索引相关的知识,还需要熟悉存储引擎,因为有些情况是基于指定存储引擎下的结果;除此之外,想要弄懂Extra栏,需要同时结合表的索引情况、查询语句、优化器(MySQL会优化我们的SQL)、以及EXPLAIN的type栏和rows栏等综合分析出现的各种情况。
这里单独对Extra的几种情况做下总结:
Using index:表示使用索引,如果只有Using index,表示使用覆盖索引返回数据而没有回表查询的操作。Using index;Using where:说明在使用索引的基础上还需要回表查询记录,可以考虑只返回指定的字段和建立联合索引来尝试避免回表查询情况。Using index condition:说明会先根据走索引过滤结果,然后再根据其他子句的情况做回表查询操作。Using where:表示在查询中很可能出现了回表查询的情况,可以观察是否加个索引来优化。Using temporary:表示MySQL需要创建临时表来保存临时结果;通常出现在包含不同列的GROUP BY和ORDER BY子句时,另外也时常跟Using filesort一起出现。Using filesort:表示在使用索引之外,还需要额外的排序操作,也可以根据具体情况添加索引来解决。
咳咳,有没有发现一个问题,如果SQL性能不行,第一想法就是加个索引试试……..这里只有一句话,索引虽好,但需要具体情况具体分析。
索引
索引,在MySQL中也被称为"键(key)",是存储引擎提高查询性能的一种数据结构,它的主要作用:
MySQL支持的索引的类型(算法):
- B树索引
- hash索引
- R树,空间数据索引
- full text,全文索引
- 其他索引类型
索引情况比较复杂,这里仅以MySQL5.7版本和innodb引擎展开,且环境是基于centos7.9的。
B树?B+树?
https://dev.mysql.com/doc/internals/en/innodb-fil-header.html
说到innodb表的索引,就离不开B树,也离不开B+树,我们就先来研究下innodb存储引擎到底是怎么组织数据的,了解了这些我们才好更好的学习索引。
在MySQL官方文档中的InnoDB Page Structure部分,有相关介绍,参见:https://dev.mysql.com/doc/internals/en/innodb-fil-header.html:

是的,MySQL的innodb存储引擎基于B树来组织的数据,但是为了提升范围查询性能,它更像一棵B+树,但同时又是一棵很特别的B+树。
下图是一个B树:

下图是一棵B+树:

而MySQL的B+树长这样:

是的,相对于B+树来说,MySQL的B+树的叶子节点存储了完整的记录,且存储了左右节点的指针,方便范围查找。
页和局部性原理
局部性原理是指CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。
例如我要访问磁盘中a b c d中a,那么CPU经过一次io读取a到内存中,紧接着又要访问b,那CPU再经过一次io读取b到内存中,如果在需要读取c和d就又要两次io操作才能完成。
这是低效的操作,通常Linux以页为逻辑单位来组织数据,对于32位的系统每页通常是4kb;64位系统则是8kb,而CPU在读取数据时也是以页为单位来处理,比如读取a那么它会一次性将a b c d所在整页数据读取到内存中,后续再有读取b、c、d的,就直接在内存中进行读取,减少io操作。
这种思想也应用到了软件中,MySQL中的innodb引擎也是以页为逻辑单位组织数据,只不过默认每页的大小是16kb,可以通过下面参数查看:
1
2
3
4
5
6
7
|
mysql> select @@innodb_page_size,@@innodb_page_size/1024 as kb;
+--------------------+---------+
| @@innodb_page_size | kb |
+--------------------+---------+
| 16384 | 16.0000 |
+--------------------+---------+
1 row in set (0.00 sec)
|
B树索引适用于全键值、键值范围或者键前缀查找,其中键前缀查找只使用与根据最左前缀的查找。
- 全值匹配,全值匹配值得是和索引中的所有列进行匹配:
1
2
|
-- 有组合索引 idx(name,age,phone)
select * from tb where name="zhangkai" and age=23 and phone="15592925142";
|
1
2
3
|
-- 有组合索引 idx(name,age,phone)
select * from tb where name="zhangkai" and age=23;
select * from tb where name="zhangkai" and age=23 and phone="15592925142";
|
1
2
|
select * from tb where name like "zhang%";
select * from tb where name like "%kai";
|
1
|
select * from tb where age > 18;
|
- 精确匹配某一列并范围匹配另一列,全值匹配第一列,范围匹配第二列:
1
|
select * from tb where name="zhangkai" and age > 25;
|
- 只访问索引的查询,查询的指定字段是索引列,而不是所有字段,本质上就是索引覆盖:
1
|
select name from tb where name="zhangkai";
|
索引管理
为了更好的研究索引,这里先学习索引的相关命令。
MySQL提供了三种创建索引的方法。
使用 CREATE INDEX 语句创建索引
该语句在一个已有的表上创建索引,但是不能创建主键:
1
2
3
4
5
|
-- 基本语法
CREATE INDEX <索引名> ON <表名> (<列名> [<长度>] [ ASC | DESC])
-- 示例,为 userinfo 表的 name 字段创建一个名为 id_name 的普通索引,默认为 ASC
CREATE INDEX id_name ON userinfo(name);
|
语法说明如下:
<索引名>:指定索引名。一个表可以创建多个索引,但每个索引在该表中的名称是唯一的。<表名>:指定要创建索引的表名。<列名>:指定要创建索引的列名。通常可以考虑将查询语句中在 JOIN 子句和 WHERE 子句里经常出现的列作为索引列。<长度>:可选项。指定使用列前的 length 个字符来创建索引。使用列的一部分创建索引有利于减小索引文件的大小,节省索引列所占的空间。在某些情况下,只能对列的前缀进行索引。索引列的长度有一个最大上限 255 个字节(MyISAM 和 InnoDB 表的最大上限为 1000 字节),如果索引列的长度超过了这个上限,就只能用列的前缀进行索引。另外,BLOB 或 TEXT 类型的列也必须使用前缀索引。ASC|DESC:可选项。ASC指定索引按照升序来排列,DESC指定索引按照降序来排列,默认为ASC。
使用 CREATE TABLE 语句创建索引
这种语句是在创建表的时候,同时创建创建索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
CREATE TABLE t1(
id INT,
-- id int PRIMARY KEY auto_increment, -- 等价下面使用 constraint 语句
NAME CHAR(32) NOT NULL COMMENT '姓名',
CONSTRAINT PRIMARY KEY(id) -- 创建主键索引
-- CONSTRAINT pk_name PRIMARY KEY(id) -- 创建自定义主键名称索引
-- PRIMARY KEY(id,name) -- 创建联合索引,可以省略 constraint 语句
);
-- 使用 UNION 创建唯一索引
CREATE TABLE t2(
id INT,
NAME CHAR(32) UNIQUE COMMENT '姓名',
PRIMARY KEY(id) -- 唯一索引与主键并不冲突
);
|
使用 ALTER TABLE 语句创建索引
该语句在已有的表上修改索引,其实也是创建索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
-- 创建单列辅助索引
ALTER TABLE 表名 ADD INDEX 索引名称(字段);
-- ALTER TABLE 表名 ADD KEY 索引名称(字段); -- MySQL中,index 就是 key,所以也可以ADD KEY
-- 创建联合索引
ALTER TABLE 表名 ADD INDEX 索引名称(字段1,字段2);
-- 创建唯一索引
ALTER TABLE 表名 ADD UNIQUE [ INDEX | KEY] [<索引名>] [<索引类型>] (<列名>,…)
-- 创建前缀索引,只取指定字段的前几个字符来创建索引
ALTER TABLE 表名 ADD INDEX 索引名称(字段(length));
-- 关联外键,不过用的不多,因为外键关系,建表时也都关联好了
ALTER TABLE 表名 ADD FOREIGN KEY [<索引名>] (<列名>,…)
|
注意:在一张表中,索引名称是唯一的;但是一个字段上可以建立多个索引(但生产中基本不用);也没必要在多个列上建立多个索引;一般的,我们在建表时,基本上都会设置主键和设置唯一约束。所以,以上的命令都是在创建辅助索引;主键索引都在建表时同时指定了。
查看和删除索引
至于修改命令,就直接使用ALTER或者DROP语句来修改即可,再来看其他命令:
1
2
3
4
5
6
7
|
-- 删除索引
ALTER TABLE 表名 DROP INDEX 索引名称;
DROP INDEX 索引名称 ON 表名;
-- 查看索引
DESC 表名;
SHOW INDEX FROM 表名; -- 输出相对详细信息
|
另外,如果使用DESC命令查看表的索引信息,在Key栏,有三种索引:
- PRI:主键
- UNI:唯一键索引
- MUL:辅助索引
聚簇索引
准备数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
create table userinfo(
id int not null primary key,
name varchar(32) default "zhangkai",
age tinyint default 18,
phone varchar(32) default "13202512591",
addr varchar(128) default "北京",
email varchar(128) default "",
birth date
)engine=innodb charset=utf8;
insert into userinfo(id,name,age,phone,addr,email,birth) values
(1, '王秀华', 67, '13202512591', '甘肃省莹县朝阳许街C座 934491', 'pinglai@caotan.cn', '2002-04-15'),
(2, '党敏', 74, '13139383427', '上海市福州市友好合肥街F座 562347', 'yang59@shen.cn', '1977-02-13'),
(3, '陈桂花', 81, '15670720985', '吉林省莹县吉区乌鲁木齐路s座 424624', 'jingqiao@guiyingzhu.cn', '1986-01-31'),
(4, '徐娟', 68, '14530781109', '北京市秀华县孝南长沙街L座 180057', 'hdong@yahoo.com', '1982-05-16'),
(5, '陈强', 13, '13861616932', '安徽省北京市山亭潮州街M座 397960', 'nading@gmail.com', '1984-02-28'),
(6, '刘淑英', 75, '13833925643', '台湾省沈阳县梁平太原街v座 494700', 'yili@tianyao.cn', '2002-03-21'),
(7, '卢建华', 89, '15893082836', '浙江省南京市闵行台北路j座 822249', 'guiyingshi@jundeng.cn', '2003-05-03'),
(8, '马楠', 31, '18948071089', '北京市哈尔滨县南长佛山路a座 574046', 'yang97@gmail.com', '1996-08-11'),
(9, '曾宇', 6, '18565097633', '天津市利县江北香港路O座 863353', 'cyu@yahoo.com', '1983-05-24'),
(10, '吴飞', 9, '13109375333', '青海省俊市梁平高街z座 868705', 'pmo@haozhao.cn', '2017-06-09');
|
聚簇
聚簇是一种术语,表示数据行和相邻的键值紧凑的存储在一起。因为无法同时把数据行存放在不同的地方,所以一个表只能由一个聚簇索引。
聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式,也是一类索引的统称。
说白了,一张InnoDB表的数据都被组织在聚簇索引这棵特殊B+树上。那到底是如何组织的呢?在创建一张InnoDB的表时,如果没有指定主键,InnoDB会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB会隐式的创建一个6字节的主键来作为聚簇索引,然后后续插入的数据都被组织在这棵聚簇索引树上。
问题来了,主键索引一定是聚簇索引么?思考一下,假如创建表的时候,没有设置主键索引和唯一索引,而在添加数据之后,设置了主键,那么原隐式创建的聚簇索引会和新创建的主键索引合并么?答案是会的。因为一个表只能有一个聚簇索引树,而这棵树的叶子节点存储了全部的记录,没有必要再重新为主键索引再创建一份数据,所以,它会合并。
这也就意味着,聚簇索引可以是主键索引、唯一索引的统称。当一张表设置了主键或者唯一键,那么InnoDB就会以以主键索引或者唯一索引的方式组织数据。
下图是一个以id为主键的表的存储结构:

聚簇索引树的叶子节点页包含了全部的数据,而节点页只包含了索引列。
另外,聚簇索引树在组织数据时,会按照一定的顺序对数据进行排序,比如按照主键进行升序排序。
由于数据的聚集性,聚簇索引也叫做聚集索引。
这里一直强调,基于InnoDB的表,一个张表只能有一个聚簇索引,所以,索引可以简单粗暴的分为聚簇索引和非聚簇索引。
非聚簇索引也叫做辅助索引、二级索引等等,又根据索引的不同特点,也有了更多的称呼,比如具有唯一约束的唯一索引;具有非空且唯一特点的主键索引,多个字段组合而成的索引——联合索引,当联合索引又具有唯一性时,这个联合索引又可以被称为联合唯一索引;为单个字段创建的索引叫做单列索引,它的作用只用来加速查询时,所以它又被称为普通的单列辅助索引;针对索引列数据较长的字段,通常截取前若干字段建立的索引叫做前缀索引……..
聚簇索引和辅助索引构成区别
- 聚簇索引只能有一个(主键),非空且唯一
- 辅助索引可以有多个,主要配合聚集索引使用的
- 聚集索引的叶子节点,就是磁盘数据行存储的数据页
- MySQL是根据聚簇索引来组织数据,即数据存储时,就是按照聚簇索引的顺序进行存储数据。
- 辅助索引只会提取索引键值,进行自动排序生成B树
由于聚簇索引的特点,通常在创建表的时候,设置id字段为聚簇索引,当然,这里一般称为主键索引,它具有非空且唯一、自增的特性。这里不在展开演示其具体创建过程了。
接下来,我们来研究下不同索引特点和相关特性。
前缀索引
准备数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
import re
import faker
import random
import pymysql
from pymysql.connections import CLIENT
conn = pymysql.Connect(
host='10.0.0.200', user='root', password='123',
database='my_idb', charset='utf8', client_flag=CLIENT.MULTI_STATEMENTS)
cursor = conn.cursor()
fk = faker.Faker(locale='en_US')
def create_table():
""" 创建表 """
sql = """
DROP TABLE IF EXISTS prefix_tb;
CREATE TABLE prefix_tb (
id int(11) NOT NULL AUTO_INCREMENT,
text varchar(255) DEFAULT NULL,
email varchar(64) DEFAULT NULL,
suffix_email varchar(64) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
"""
# 注意,一次性执行多行sql,必须在连接时,指定client_flag=CLIENT.MULTI_STATEMENTS
cursor.execute(sql)
conn.commit()
def gen(num, tmp_list):
for i in range(num):
tmp = fk.paragraph() if random.randint(0, 1) else tmp_list[random.randint(0, (tmp_list.__len__() - 1))]
email = fk.email()
yield tmp, email, ''.join(reversed(re.split('(@)', email)))
def insert_many(num):
""" 批量插入 """
tmp_list = [fk.paragraph() for i in range(100)]
sql = "insert into prefix_tb(text, email, suffix_email) values(%s, %s, %s);"
cursor.executemany(sql, gen(num, tmp_list))
conn.commit()
if __name__ == '__main__':
num = 10000
create_table()
insert_many(num)
# 数据长这样
"""
mysql> select * from prefix_tb limit 2\G
*************************** 1. row ***************************
id: 1
text: Practice cost maintain drive walk. Chance treat should conference officer audience. Similar event agree away.
email: bmata@davis-harris.info
suffix_email: davis-harris.info@bmata
*************************** 2. row ***************************
id: 2
text: Child across those. Admit especially try I.
email: jeffrey64@rodriguez.biz
suffix_email: rodriguez.biz@jeffrey64
2 rows in set (0.00 sec)
"""
|
要对一个字符列很长的字段,建立索引,通常会让索引变得大而且慢,而解决办法可以仅对字符的开始部分建立索引,这样节省了索引空间,也提高了索引效率,对于这类索引,通常称为——前缀索引。
但这也会引发一个问题,就是降低了索引的选择性,什么是索引的选择性?索引的选择性指:
不重复的索引值(也称为基数,cardinality)和数据表的记录总数(#T)的比值,范围从1/#T到1之间。说白了就是一个表中,不重复的记录和总记录的比值。
索引的选择性越高则查询效率越高,因为选择性高的索引可以让给MySQL在查询时过滤掉更多的行,就像唯一索引的选择性是1,这是最好的选择性,性能也是最好的。
对于BLOB、TEXT或者很长的VARCHAR类型的列,必须使用前缀索引,因为MySQL不允许索引这些列的完整长度。
诀窍在于要选择足够长的前缀以保证较高的选择性,同时不能太长(以便节约空间)。前缀索引的长度处于什么范围?才能让前缀索引的选择性接近整个列,换句话说,前缀的"基数"应该接近于完整的"基数"。
为了解决前缀的合适长度,我们一般通过简单的公式来测试,最终筛选出前缀的选择性接近完整列的选择性。
1
|
SELECT COUNT(DISTINCT text) / count(*) as "最优选择性" from prefix_tb;
|
有了公式,我们就可以来计算尝试计算出一个合适的索引长度:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
SELECT
COUNT(DISTINCT text) / count(*) as "最优选择性",
COUNT(DISTINCT left(text,10)) / count(*) as len10,
COUNT(DISTINCT left(text,12)) / count(*) as len12,
COUNT(DISTINCT left(text,14)) / count(*) as len14,
COUNT(DISTINCT left(text,16)) / count(*) as len16,
COUNT(DISTINCT left(text,18)) / count(*) as len18,
COUNT(DISTINCT left(text,20)) / count(*) as len20,
COUNT(DISTINCT left(text,22)) / count(*) as len22,
COUNT(DISTINCT left(text,24)) / count(*) as len24,
COUNT(DISTINCT left(text,26)) / count(*) as len26
from prefix_tb;
-- 结果如下
+-----------------+--------+--------+--------+--------+--------+--------+--------+--------+--------+
| 最优选择性 | len10 | len12 | len14 | len16 | len18 | len20 | len22 | len24 | len26 |
+-----------------+--------+--------+--------+--------+--------+--------+--------+--------+--------+
| 0.5116 | 0.4667 | 0.5013 | 0.5098 | 0.5114 | 0.5114 | 0.5116 | 0.5116 | 0.5116 | 0.5116 |
+-----------------+--------+--------+--------+--------+--------+--------+--------+--------+--------+
|
由上例结果发现,当前缀长度为20时,最接近(这里刚好是等于)最优的选择性,而再增加长度时,值已经不在变化,所以,前缀的长度为20时,比较合适。
算出了合适的前缀长度,我们来创建前缀索引:
1
2
3
4
5
|
-- 为text列创建一个名为pre_idx的前缀索引,前缀长度为20
alter table prefix_tb add index pre_idx(text(20));
-- 查看
show index FROM prefix_tb;
|
来看应用:
1
2
3
4
5
6
7
|
mysql> explain select * from prefix_tb where text like "you%";
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | prefix_tb | NULL | range | pre_idx | pre_idx | 63 | NULL | 19 | 100.00 | Using where |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
|
前缀索引是一种能使索引更小、更快的有效办法,但前缀索引也有自己的缺点:
- MySQL无法使用前缀索引进行order by和group by,因为前缀索引的数据结构是按照前缀排序的,和完整的字段排序不一样。
- 无法使用前缀索引做覆盖扫描,如下图,前缀索引的叶子节点存储的并不是完整的列值,所以当查询时,还是需要回表。

后缀索引?
有时候,后缀索引(suffix index),或者说是反向索引也很用,例如找到某个域名的所有email。而MySQL原生并不支持后缀索引(suffix index),但可以通过字符串"反转"的方式,如将ryanlove@yahoo.com“反转"为yahoo.com@ryanlove,然后建立前缀索引达到加速查询的目的。
在本小节的prefix_tb表中,suffix_email字段就是为了email字段的"反转"后的值,我们为suffix_email建立前缀索引,进而过滤出想要的记录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
-- 通过为suffix_email字段建立前缀进行结果过滤
alter table prefix_tb add index suffix_idx(suffix_email(28));
-- 下面两个查询语句的性能是不一样的
mysql> explain select count(email) from prefix_tb where email like "%yahoo.com";
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | prefix_tb | NULL | ALL | NULL | NULL | NULL | NULL | 9968 | 11.11 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select count(email) from prefix_tb where suffix_email like "yahoo.com%";
+----+-------------+-----------+------------+-------+---------------+------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+------------+---------+------+------+----------+-------------+
| 1 | SIMPLE | prefix_tb | NULL | range | suffix_idx | suffix_idx | 87 | NULL | 1642 | 100.00 | Using where |
+----+-------------+-----------+------------+-------+---------------+------------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
|
联合索引
https://dev.mysql.com/doc/refman/5.7/en/multiple-column-indexes.html
MySQL可以创建复合索引(Multiple column indexes),即同时为多个列创建索引,一个复合索引最多可以包含16列。
当然,我们通常更习惯将复合索引叫做联合索引或组合索引,当多个索引列具有唯一性时,你可以称它为联合唯一索引。
最左原则
在联合索引中,需要重点掌握——最左(前缀匹配)原则,所谓最左原则,即当你创建如下联合索引时:
1
2
3
4
5
6
7
8
9
10
11
12
|
create table t1(
id int not null primary key auto_increment,
a int not null,
b int not null,
c int not null,
d int not null,
index mul_idx(a,b,c)
)engine=innodb charset=utf8;
insert into t1 values
(1, 1, 1, 1, 1),(2, 2, 2, 2, 2),(3, 3, 3, 3, 3),(4, 4, 4, 4, 4),(5, 5, 5, 5, 5),
(6, 6, 6, 6, 6),(7, 7, 7, 7, 7),(8, 8, 8, 8, 8),(9, 9, 9, 9, 9),(10, 10, 10, 10, 10);
|
如上创建一个联合索引mul_idx,相当于:
- 创建了
a列索引、ab列索引、ac列索引(这个要是情况而定)。因为这个几个索引都有a开头,也就是向左具有聚集性,所以被称为最左前缀。
- 按道理说,因为
b列、bc列、ba列、ca列、cb列不符合最左原则,所以无法应用联合索引。但事实上,MySQL的优化器会在某些情况下,调整where条件的先后顺序,以尽可能的应用上索引,如ca列where c=1 and a=1,就会被优化器调整为where a=1 and c=1,然后它就符合最左前缀原则,走索引;ba列同理。所以,再次强调,索引情况非常复杂,还是尽可能的通过执行计划的结果,来具体情况具体考虑。
由上面的总结来看,我们在创建联合索引时,一定要将最常被查询的列放在联合索引的最左侧。接下来的示例,要关注一个key_len参数,关于ken_len参数,参考:https://www.cnblogs.com/Neeo/articles/13644285.html#key_len。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
-- 单独将a作为条件,走索引
explain select * from t1 where a=1;
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ref | mul_idx | mul_idx | 4 | const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+
-- ab作为条件,走索引
explain select * from t1 where a=1 and b=1;
+----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ref | mul_idx | mul_idx | 8 | const,const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------------+
-- ac作为条件,走索引
explain select * from t1 where a=1 and c=1;
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+--------------------------+
| 1 | SIMPLE | t1 | NULL | ref | mul_idx | mul_idx | 4 | const | 1 | 10.00 | Using where; Using index |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+--------------------------+
-- 单独将b作为条件,不走索引
explain select * from t1 where b=1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
-- ba作为条件,按照上面的说法,MySQL优化器将 b=1 and a=1 调整为 a=1 and b=1,然后就符合最左原则,走索引了
explain select * from t1 where b=1 and a=1;
+----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------+
| 1 | SIMPLE | t1 | NULL | ref | mul_idx | mul_idx | 8 | const,const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------+
-- bc作为条件,不走索引
explain select * from t1 where b=1 and c=1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
-- ca作为条件,按理说,不应该走索引,但实际上MySQL优化器会优化查询条件,将 c=1 and a=1 两个条件进行交换顺序为 a=1 and c=1,然后就符合最左原则,走索引了
explain select * from t1 where c=1 and a=1;
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | t1 | NULL | ref | mul_idx | mul_idx | 4 | const | 1 | 10.00 | Using index condition |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+
-- cb作为条件,不走索引
explain select * from t1 where c=1 and b=1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
|
通过上面的示例,我们演示了最左前缀的应用,接下来再看看其他情况。
索引截断
在联合索引中,where条件遇到大于、小于时,会阻断后续条件的索引的使用,但等于不会,这点是需要我们注意的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
-- 通过 key_len(a、b、c的索引长度都为4,加一块等于12) 的结果发现,a、b、c三个索引列都被应用,一切正常,我们往下看
explain select * from t1 where a=1 and b=1 and c=1;
+----+-------------+-------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | t1 | NULL | ref | mul_idx | mul_idx | 12 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
-- 通过 key_len 的结果发现,当大于小于在最后的时候,索引没有被阻断
explain select * from t1 where a=1 and b=2 and c>3;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | t1 | NULL | range | mul_idx | mul_idx | 12 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
-- 通过 key_len 的结果发现,只有a、b两个索引列被应用,c索引列被阻断
explain select * from t1 where a=1 and b>2 and c=3;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | t1 | NULL | range | mul_idx | mul_idx | 8 | NULL | 1 | 10.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
-- 通过 key_len 的结果发现,a、b、c三个索引列都没有被应用
explain select * from t1 where a>1 and b=2 and c=3;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ALL | mul_idx | NULL | NULL | NULL | 10 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
-- 通过 key_len 的结果发现,a、b、c三个索引列都没有被应用
explain select * from t1 where a>=1 and b>2 and c=3;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ALL | mul_idx | NULL | NULL | NULL | 10 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
|
联合索引中的索引列是表的所有列的话,它不一定符合最左匹配原则
按照前面说的最左原则,ab、abc、ac走索引;ba、ca被优化器优化后走索引,但bc、cb不走索引,我们已经通过前面的示例证明了。
但联合索引中的索引列是表的所有列的话,最左原则就不灵了,来看示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
-- 联合索引的索引列示表的所有列,来看,按照最左原则本不该走的bc、cb的情况,虽然优化器会优化,但bc调整为cb那不一样么.....
create table t2(a int not null, b int not null, c int not null, index mul_idx(a,b,c));
-- bc作为索引列,走了索引
explain select * from t2 where b=1 and c=1;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | t2 | NULL | index | NULL | mul_idx | 12 | NULL | 1 | 100.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
-- 同理,bc作为索引列,也会走索引
explain select * from t2 where c=1 and b=1;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | t2 | NULL | index | NULL | mul_idx | 12 | NULL | 1 | 100.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
|
这种情况,我们也要能考虑到才好。
覆盖索引
通常大家都会根据查询的where条件来创建合适的索引,不过这只是索引优化的一个方向面。设计优秀的索引应该考虑到整个查询,而不是单单是where条件部分。索引确实是一种查找数据的高效方式,但是MySQL也可以使用索引来直接获取列的数据,这样就不再需要读取数据行。如果索引的叶子节点中已经包含了要查询的数据,那么还有必要再回表查询么?
如果一个索引包含或者说覆盖所有要查询的字段的值,我们就称之为"覆盖索引(也称索引覆盖)"。覆盖索引极大的提高了查询性能,且索引条目远小于完整记录行的大小,所以如果只需要读取索引,MySQL就会极大的减少数据访问量。
当发起一个被索引覆盖的查询(也叫做索引覆盖查询)时,再explain的extra字段,会看到"Using index"的信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
explain select name,phone from userinfo where name="王秀华"\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: userinfo
partitions: NULL
type: ref
possible_keys: com_idx
key: com_idx
key_len: 99
ref: const
rows: 1
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
|
这也是我们在刚开始学习MySQL时,会提到尽量不要使用select *而是建议使用select id等指定字段,这就是希望能走覆盖索引,进一步提高查询语句的性能。
比如同样的where条件,select *就不会走索引覆盖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
explain select * from userinfo where name="王秀华"\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: userinfo
partitions: NULL
type: ref
possible_keys: com_idx
key: com_idx
key_len: 99
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
|
回表查询
索引的叶子节点中已经包含了要查询的数据,就会走覆盖索引,否则就需要进行回表查询了。

根据上图,如果一个表,只有主键索引和联合索引时。查询字段是索引字段时,就会走覆盖索引,因为索引的叶子节点中已经包含了要查询的数据,如下示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
explain select name,phone from userinfo where name="王秀华"\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: userinfo
partitions: NULL
type: ref
possible_keys: com_idx
key: com_idx
key_len: 99
ref: const
rows: 1
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
|
而下面的查询则需要回表查询,因为索引的叶子节点不包含addr字段的值,需要通过主键id进行回表查询。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
explain select name,phone,addr from userinfo where name="王秀华"\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: userinfo
partitions: NULL
type: ref
possible_keys: com_idx
key: com_idx
key_len: 99
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
|
索引下推
详情参见MySQL5.6官方文档:
https://dev.mysql.com/doc/refman/5.6/en/index-condition-pushdown-optimization.html
MySQL5.7的中文文档:
https://www.docs4dev.com/docs/zh/mysql/5.7/reference/index-condition-pushdown-optimization.html
MySQL5.6版本开始,新增"索引下推(IPC)“功能来优化查询。索引下推也被称为索引条件下推、索引条件推送(Index condition pushdown),SQL下推、谓词下推。
当EXPLAIN的输出在Extra列中显示Using index condition时,表示使用了索引下推。
如我们对idb_tb表进行查询:
1
2
3
4
5
|
-- 首先这里会用到联合索引
alter table userinfo add index com_idx(name,addr,phone);
-- 查询条件如下
explain select * from userinfo where name="王秀华" and phone like "155%";
|
在使用索引下推之前,也就是MySQL5.6版本之前,上面的SQL语句执行:
- MySQL会先使用联合索引查询出所有
name="王秀华"的索引,然后回表查询出相应的全行数据。
- 然后再根据后面的条件筛选结果。
但在使用索引下推后,上面的SQL语句执行:
- MySQL根据联合索引过滤所有
name="王秀华"索引,再回表查询相应的全行数据之前,先对phone条件进行筛选,再进行回表查询,将最终的结果发返回。
很明显,索引下推会减少回表次数,进而减少总的查询量,达到优化查询的功能。
注意:
- 索引下推可应用于innodb和myisam表,且MySQL 5.6中的分区表不支持索引下推,但在 MySQL 5.7中已解决此问题。
- 对于innodb表来说,索引下推仅适用于二级索引。
默认情况下,索引条件下推处于启用状态。可以optimizer_switch通过设置index_condition_pushdown 标志使用系统变量 进行控制 :
1
2
3
4
5
|
SET optimizer_switch = 'index_condition_pushdown=off';
SET optimizer_switch = 'index_condition_pushdown=on';
-- 查看该参数
SELECT @@optimizer_switch;
|
更好的使用索引
冗余和重复索引
MySQL允许在相同的列上创建多个索引,但MySQL需要单独维护这些索引,并且优化器在优化查询时,也要逐个的对这些索引进行考虑,这就会一定程度上影响性能和磁盘占用。
重复索引
重复索引指在相同列上按照相同的方式创建的相同类型的索引,对于这样的重复索引,应该及时进行移除。
如下面的示例,在不经意间,就创建了重复索引:
1
2
3
4
5
6
7
|
create table tb(
id int not null primary key,
col1 int not null,
col2 int not null,
unique(id),
index(id)
)engine=innodb;
|
在MySQL中,唯一限制和主键限制都是通过索引实现的,上面的写法,相当于在相同的列上创建了三个重复的索引,我们应该避免这种情况出现。
对于相同列,如果多个索引类型不同,则不算是重复索引,比如创建key(col2)和full text(col2)这两种索引类型。
冗余索引
冗余索引和重复索引有些不同,如下:
1
2
3
|
alter table tb add index com_idx(col1,col2);
alter table tb add index idx_1(col1);
alter table tb add index idx_2(col2,col1);
|
如果创建了联合索引com_idx,再创键idx_1,那么idx_1就是冗余索引,因为idx_1相当于com_idx索引的前缀索引。
而idx_2则不是冗余索引,因为col2列不是com_idx的最左前缀列。
解决冗余和重复索引可以有以下几种办法。
- 使用infomation_schema来过滤,下面贴出示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
SELECT
a.TABLE_SCHEMA AS '数据名',
a.TABLE_NAME AS '表名',
a.INDEX_NAME AS '索引1',
b.INDEX_NAME AS '索引2',
a.COLUMN_NAME AS '重复列名'
FROM
STATISTICS a
JOIN STATISTICS b ON a.TABLE_SCHEMA = b.TABLE_SCHEMA
AND a.TABLE_NAME = b.TABLE_NAME
AND a.SEQ_IN_INDEX = b.SEQ_IN_INDEX
AND a.COLUMN_NAME = b.COLUMN_NAME
WHERE
a.SEQ_IN_INDEX = 1
AND a.INDEX_NAME <> b.INDEX_NAME;
|
-
可以使用Shlomi Noach的common_schema中的一些视图来定位,common_schema是一系列可以安装到服务器上的常用的存储和视图。
-
可以使用Percona Toolkit中的pt_duplicate-key-checker,该工具通过分析表结构来找出冗余和重复的索引。
查询索引的使用情况
我们可以通过一些参数或者专业工具来查看索引的使用情况。
这里推荐使用Percona Toolkit中的pt-index-usage,该工具可以读取查询日志,并对日志中的每条查询进行explain操作,然后打印出关于索引和查询的报告,这个工具不仅可以找出哪些索引是未使用的,也可以了解查询的执行计划。
但这里不在过多展开介绍。
索引效果压力测试
这里选择mysqlslap,mysqlslap是MySQL5.1.4之后自带的基准(benchmark)测试工具,该工具可以模拟多个客户端同时并发的向服务器发出查询更新,给出了性能测试数据而且提供了多种引擎的性能比较。
准备数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
-- MYSQL version 5.7.20
DROP DATABASE IF EXISTS pp;
CREATE DATABASE pp CHARSET=utf8mb4 collate utf8mb4_bin;
USE pp;
-- SET AUTOCOMMIT=0;
DROP TABLE IF EXISTS pressure;
CREATE TABLE pressure(
id INT,
num INT,
k1 CHAR(2),
k2 CHAR(4),
dt TIMESTAMP
);
DELIMITER //
CREATE PROCEDURE rand_data(IN num INT)
BEGIN
DECLARE str CHAR(62) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE str2 CHAR(2);
DECLARE str4 CHAR(4);
DECLARE i INT DEFAULT 0;
WHILE i<num DO
SET str2=CONCAT(SUBSTRING(str,1+FLOOR(RAND()*61),1),SUBSTRING(str,1+FLOOR(RAND()*61),1));
SET str4=CONCAT(SUBSTRING(str,1+FLOOR(RAND()*61),2),SUBSTRING(str,1+FLOOR(RAND()*61),2));
SET i=i+1;
INSERT INTO pressure VALUES (i,FLOOR(RAND()*num),str2,str4,NOW());
END WHILE;
END //
DELIMITER ;
call rand_data(1000000);
commit;
|
然后执行:
1
2
3
4
5
6
7
8
|
mysqlslap --defaults-file=/etc/my.cnf \
--concurrency=100 \
--iterations=1 \
--create-schema='pp' \
--query="select * from pp.pressure where k1='oa';" \
--engine=innodb \
--number-of-queries=2000 \
-uroot -p123 -verbose
|
各项参数:
--defaults-file:默认的配置文件。--concurrency:并发用户数。--iterations:要运行这些测试多少次。--create-schema:被压测数据库名。--query:执行压力测试时的SQL语句。--number-of-queries:SQL语句执行次数。
相当于,模拟100个用户并发,每个用户执行20次查询操作。
我们针对pressure做个简单的查询操作,来看SQL的执行时间:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
[root@cs home]# mysqlslap --defaults-file=/etc/my.cnf \
> --concurrency=100 \
> --iterations=1 \
> --create-schema='pp' \
> --query="select * from pp.pressure where k1='oa';" \
> --engine=innodb \
> --number-of-queries=2000 \
> -uroot -p123 -verbose
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 272.527 seconds
Minimum number of seconds to run all queries: 272.527 seconds
Maximum number of seconds to run all queries: 272.527 seconds
Number of clients running queries: 100
Average number of queries per client: 20
|
有执行结果可以看到,100个并发,共2000次查询,平均耗时272.527秒,非常的慢了。我们来分析一下慢的原因:
1
2
3
4
5
6
7
8
9
10
11
12
|
-- 没有索引
mysql> SHOW INDEX FROM pressure;
Empty set (0.00 sec)
-- type是all,rows大约是95万
mysql> EXPLAIN SELECT * FROM pressure WHERE k1='oa';
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | pressure | NULL | ALL | NULL | NULL | NULL | NULL | 955377 | 10.00 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
|
既然没有索引,我们现在为查询字段建立上索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
-- 添加索引
mysql> ALTER TABLE pressure ADD INDEX idx_k1(k1);
Query OK, 0 rows affected (1.54 sec)
Records: 0 Duplicates: 0 Warnings: 0
-- 再次查看执行计划,发现type:ref,而rows:267
mysql> EXPLAIN SELECT * FROM pressure WHERE k1='oa';
+----+-------------+----------+------------+------+---------------+--------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+--------+---------+-------+------+----------+-------+
| 1 | SIMPLE | pressure | NULL | ref | idx_k1 | idx_k1 | 9 | const | 267 | 100.00 | NULL |
+----+-------------+----------+------------+------+---------------+--------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
|
再来执行同一个压力测试语句,看效果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
[root@cs home]# mysqlslap --defaults-file=/etc/my.cnf \
> --concurrency=100 \
> --iterations=1 \
> --create-schema='pp' \
> --query="select * from pp.pressure where k1='oa';" \
> --engine=innodb \
> --number-of-queries=2000 \
> -uroot -p123 -verbose
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 0.612 seconds
Minimum number of seconds to run all queries: 0.612 seconds
Maximum number of seconds to run all queries: 0.612 seconds
Number of clients running queries: 100
Average number of queries per client: 20
|
看平均执行时间,从原来的270多秒到现在的零点几秒,这性能提升多少倍,算不过来……..
再来点稍微复杂的语句,加个ORDER BY:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysqlslap --defaults-file=/etc/my.cnf \
--concurrency=100 \
--iterations=1 \
--create-schema='pp' \
--query="SELECT * FROM pressure WHERE k2='oa' ORDER BY k1;" \
--engine=innodb \
--number-of-queries=2000 \
-uroot -p123 -verbose
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 271.739 seconds
Minimum number of seconds to run all queries: 271.739 seconds
Maximum number of seconds to run all queries: 271.739 seconds
Number of clients running queries: 100
Average number of queries per client: 20
|
耗时也不短!
先来看当前的索引和SQL语句的执行计划:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
mysql> SHOW INDEX FROM pressure;
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| pressure | 1 | idx_k1 | 1 | k1 | A | 3772 | NULL | NULL | YES | BTREE | | |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
mysql> EXPLAIN SELECT * FROM pressure WHERE k2='oa' ORDER BY k1;
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
| 1 | SIMPLE | pressure | NULL | ALL | NULL | NULL | NULL | NULL | 955377 | 10.00 | Using where; Using filesort |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
1 row in set, 1 warning (0.01 sec)
|
情况非常糟糕,查询甚至走了文件排序,性能也糟糕透了,再来添加一个索引,看看效果:
1
2
|
-- 由于k1有了索引,这次我们为k1和k2建立一个联合索引
ALTER TABLE pressure ADD INDEX idx_k2_k1(k2,k1);
|
根据WHERE条件,在建立联合索引中,k2要在k1前面,此时以下情况都会走该联合索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
-- 示例,仔细观察,根据字段的位置不同,MySQL选择的索引也不同
mysql> EXPLAIN SELECT * FROM pressure WHERE k2='oa' ORDER BY k1; -- 走联合索引
+----+-------------+----------+------------+------+---------------+-----------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+-----------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | pressure | NULL | ref | idx_k2_k1 | idx_k2_k1 | 17 | const | 1 | 100.00 | Using index condition |
+----+-------------+----------+------------+------+---------------+-----------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> EXPLAIN SELECT * FROM pressure WHERE k1='oa' ORDER BY k2; -- 走之前创建的索引
+----+-------------+----------+------------+------+---------------+--------+---------+-------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+--------+---------+-------+------+----------+---------------------------------------+
| 1 | SIMPLE | pressure | NULL | ref | idx_k1 | idx_k1 | 9 | const | 267 | 100.00 | Using index condition; Using filesort |
+----+-------------+----------+------------+------+---------------+--------+---------+-------+------+----------+---------------------------------------+
1 row in set, 1 warning (0.00 sec)
|
上面的联合索引的一种情况,其实联合索引非常复杂,除了上面的情况,还要考虑优化器是否优化了SQL语句、根据查询的字段不同,要考虑是否进行了回表查询等等。
再来看性能:
1
2
3
4
5
6
7
8
9
|
[root@cs home]# mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='pp' --query="SELECT * FROM pressure WHERE k2='oa' ORDER BY k1;" --engine=innodb --number-of-queries=2000 -uroot -p123 -verbose
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 0.058 seconds
Minimum number of seconds to run all queries: 0.058 seconds
Maximum number of seconds to run all queries: 0.058 seconds
Number of clients running queries: 100
Average number of queries per client: 20
|
性能提升也非常明显!
索引无法命中的情况
准备点数据,通过pymysql录入一百万条数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
import time
import faker
import pymysql
from pymysql.connections import CLIENT
fk = faker.Faker(locale='zh_CN')
conn = pymysql.Connect(
host='10.0.0.200', user='root', password='123',
database='', charset='utf8', client_flag=CLIENT.MULTI_STATEMENTS)
cursor = conn.cursor()
def create_table(databaseName, tableName):
""" 创建表 """
sql = """
DROP DATABASE IF EXISTS {databaseName};
CREATE DATABASE {databaseName} CHARSET utf8;
USE {databaseName};
DROP TABLE IF EXISTS {tableName};
CREATE TABLE {tableName}(
id int not null primary key unique auto_increment,
name varchar(32) not null default "张开",
addr varchar(128) not null default "",
phone varchar(32) not null,
email varchar(64) not null
) ENGINE=INNODB CHARSET=utf8;
""".format(databaseName=databaseName, tableName=tableName)
# 注意,一次性执行多行sql,必须在连接时,指定client_flag=CLIENT.MULTI_STATEMENTS
cursor.execute(sql)
conn.commit()
def insert_many(num, tableName):
""" 批量插入 """
gen = ((i, fk.name(), fk.address(), fk.phone_number(), fk.email()) for i in range(1, num + 1))
sql = "insert into {tableName}(id, name, addr, phone, email) values(%s, %s, %s, %s, %s);".format(
tableName=tableName)
cursor.executemany(sql, gen)
conn.commit()
if __name__ == '__main__':
num = 1000000
database = "my_idb"
table = 'idb_tb'
create_table(database, table)
insert_many(num, table)
cursor.close()
conn.close()
|
这里要明确一点,创建的索引不一定被应用;不合理的索引不会加速查询。
另外由于查询语句非常的复杂,导致索引命中情况也非常复杂,这里只是根据当前环境下,列举一些查询语句,有索引但无法命中情况。
在往下看之前,请务必对示例中的表结构和记录烂熟于心。
类型不一致
如果要查询的列是字符串类型,那么查询条件也必须是字符串,否则无法命中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
-- 创建辅助索引
ALTER TABLE idb_tb ADD KEY phone_idx(phone);
-- 这里的phone字段类型是varchar
-- 查询条件是字符串,走索引
mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone = "123";
+----+-------------+--------+------------+------+---------------+-----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+-----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | idb_tb | NULL | ref | phone_idx | phone_idx | 98 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+-----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
-- 如果是整形,不走索引,MySQL内部会使用函数将整形条件转换为字符串后进行查询
mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone = 123;
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | idb_tb | NULL | ALL | phone_idx | NULL | NULL | NULL | 994224 | 10.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 3 warnings (0.00 sec)
|
or
当where条件中,索引列和非索引列同时作为查询条件时,可能走也可能不走索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
-- 这里的id是主键索引,email是非索引列
explain select * from idb_tb where id=1 or email="yongqian@yahoo.com";
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | idb_tb | NULL | ALL | PRIMARY,id | NULL | NULL | NULL | 994224 | 10.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
-- id主键,name是辅助索引列,email是非索引列,走索引
explain select * from idb_tb where id=1 or name="余秀芳" and email="yongqian@yahoo.com";
+----+-------------+--------+------------+-------------+--------------------------+---------------+---------+------+------+----------+-----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------------+--------------------------+---------------+---------+------+------+----------+-----------------------------------------+
| 1 | SIMPLE | idb_tb | NULL | index_merge | PRIMARY,id,com_idx,idx_1 | PRIMARY,idx_1 | 4,98 | NULL | 44 | 100.00 | Using union(PRIMARY,idx_1); Using where |
+----+-------------+--------+------------+-------------+--------------------------+---------------+---------+------+------+----------+-----------------------------------------+
|
对于辅助索引来说,!=、NOT IN也不走索引
phone字段已经创建了辅助索引phone_idx。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
-- 不走索引
mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone NOT IN ("15592925142", "13449332638", "18257778732");
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | idb_tb | NULL | ALL | phone_idx | NULL | NULL | NULL | 994224 | 100.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
-- 但下面这种情况,会走辅助索引,因为查询语句只需要phone字段,而phone字段是索引字段,这是索引覆盖现象
mysql> EXPLAIN SELECT phone FROM idb_tb WHERE phone NOT IN ("15592925142", "13449332638", "18257778732");
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+--------------------------+
| 1 | SIMPLE | idb_tb | NULL | index | phone_idx | phone_idx | 98 | NULL | 994224 | 100.00 | Using where; Using index |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
-- 这些情况只是针对于辅助索引,如主键索引就没事
mysql> EXPLAIN SELECT * FROM idb_tb WHERE id NOT IN (155, 134, 182);
+----+-------------+--------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | idb_tb | NULL | range | PRIMARY,id | PRIMARY | 4 | NULL | 497291 | 100.00 | Using where |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
|
在索引列上,使用函数及运算操作(+、-、*、/等),不走索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
-- 走索引
mysql> EXPLAIN SELECT * FROM idb_tb WHERE id = 123;
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | idb_tb | NULL | const | PRIMARY,id | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
-- 由于有运算,不走索引
mysql> EXPLAIN SELECT * FROM idb_tb WHERE id + 1 = 123;
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | idb_tb | NULL | ALL | NULL | NULL | NULL | NULL | 994224 | 100.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
-- 但把运算放到值上,就可以走索引
mysql> explain select * from idb_tb where id=4+1;
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | idb_tb | NULL | const | PRIMARY,id | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
|
某些情况下,查询结果集如果超过了表中记录的25%,优化器就觉得没有必要走索引了
如下面两条查询语句,根据结果集大小,索引命中也不一样。
查询以 “155” 开头的手机号:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- 结果集小于表记录的25%
mysql> SELECT COUNT(*) FROM idb_tb WHERE phone LIKE "155%";
+----------+
| COUNT(*) |
+----------+
| 33390 |
+----------+
1 row in set (0.02 sec)
-- 走索引
mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "155%";
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+-------+----------+-----------------------+
| 1 | SIMPLE | idb_tb | NULL | range | phone_idx | phone_idx | 98 | NULL | 61282 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+-------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
|
查询以 “15” 开头的手机号:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- 结果集大于表记录的25%
mysql> SELECT COUNT(*) FROM idb_tb WHERE phone LIKE "15%";
+----------+
| COUNT(*) |
+----------+
| 300102 |
+----------+
1 row in set (0.13 sec)
-- 不走索引
mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "15%";
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | idb_tb | NULL | ALL | phone_idx | NULL | NULL | NULL | 994224 | 50.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
|
针对这种情况,可以使用limit来解决,并且我发现,只要加上limit,就走索引,无论限制的记录条数是多少。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "15%" limit 20000;
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+
| 1 | SIMPLE | idb_tb | NULL | range | phone_idx | phone_idx | 98 | NULL | 497112 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "15%" limit 250000;
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+
| 1 | SIMPLE | idb_tb | NULL | range | phone_idx | phone_idx | 98 | NULL | 497112 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "15%" limit 400000;
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+
| 1 | SIMPLE | idb_tb | NULL | range | phone_idx | phone_idx | 98 | NULL | 497112 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
|
由上例可以发现,哪怕最后的limit限制条数大于实际结果集的大小,最后也都走了索引。
对于like来说,%开头,不走索引,%在后事情况而定
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
-- %开头,不走索引
mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "%778732";
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | idb_tb | NULL | ALL | NULL | NULL | NULL | NULL | 994224 | 11.11 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
-- %灾后,要根据结果集和其他情况而定,如下面结果集的大小决定是否走索引
mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "155%";
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+-------+----------+-----------------------+
| 1 | SIMPLE | idb_tb | NULL | range | phone_idx | phone_idx | 98 | NULL | 61282 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+-------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "15%";
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | idb_tb | NULL | ALL | phone_idx | NULL | NULL | NULL | 994224 | 50.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
|
我们来进行一个总结:
- 建表时一定要有主键,一般是一个无关列,如
id
- 选择唯一性索引,唯一性索引的值是唯一的,能快速的通过索引来确定某条记录
- 为经常需要
WHERE、ORDER BY、GROUP BY、JOIN、ON这些长操作的字段,根据业务建立索引
- 如果索引字段的值很长,最好选择建立前缀索引
- 对于重复值较多的列,可以选择建立联合索引
- 降低索引的数量,一方面不要创建没用的索引,另外对于不常用的索引及时清理
- 索引的数目不是越多越好,因为随着索引数量的增多,可能带来的问题:
- 每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大
- 修改表时,对于索引的重构和更新就越麻烦;越多的索引,会使更新表时浪费更多的时间
- 优化器的负担会加重,有可能会影响到优化器的选择
- 删除不再使用或者很少使用的索引,当表中的数据被大量更新,或者数据的使用方式发生改变后,原有的索引可能不在需要,数据库管理员应定期找出并删除这些索引,从而减少索引对更新操作的影响
- 我们可以通过percona toolkit这个工具来分析索引是否有用
- 对于索引的维护要避开业务繁忙期
- 大表加索引,也要避开业务繁忙期
- 尽量少在经常更新的列上建立索引
- 查询结果集如果超过了表中记录的25%,优化器就觉得没有必要走索引了,可能的解决方法:
- 如果业务允许,可以使用limit加以控制
- 如果在MySQL中没有更好的解决方案,可以考虑放到redis中
- 索引失效,导致统计的数据不真实,索引本身有自我维护的能力,但对于表记录变化比较频繁的情况下,有可能会出现索引失效,解决办法一般是删除重建索引
- 不要再索引列上,进行函数及运算操作(
+、-、*、/等)
- 对于模糊查询的搜索需求,可以使用elasticsearch加mongodb来搭配实现
InnoDB
参考:https://www.cnblogs.com/Neeo/articles/13883976.html
本小节主要介绍MySQL的InnoDB存储引擎的细节。 说在前面:由于版本不一致和大家对一些实现理解不同,本篇也是搜集了官网和网上的资料加自己的理解整理而来,如果有不对的地方,望指正。
存储引擎的主要功能 MySQL的存储引擎大致提供了以下几个大的方面的功能:
- 数据读写
- 数据安全和一致性
- 提高性能
- 热备份
- 自动故障恢复
- 高可用方面支持
MySQL存储引擎的种类 下列是Oracle的MySQL支持的存储引擎的种类,包括目前在用和停用的:
- InnoDB
- MyISAM
- MEMORY
- ARCHIVE
- FEDERATED
- EXAMPLE
- BLACKHOLE
- MERGE
- NDBCLUSTER
- CSV
第三方引擎:
- Xtradb
- RocksDB
- MyRocks
TokuDB
TokuDB、RocksDB、MyRocks的共同点:压缩比高,数据插入性能极高。
存储引擎的相关操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
-- 查看当前版本中支持的引擎
SHOW ENGINES;
-- 查看当前版本中使用指定引擎的表有哪些,比如查看都有哪些表使用了 CSV 引擎
SELECT table_name,engine FROM information_schema.tables WHERE engine='CSV';
-- 查看MySQL当前版本支持的默认引擎
SELECT @@default_storage_engine;
-- 修改系统默认引擎
SET default_storage_engine=MyISAM; -- Session级别,影响当前会话
SET GLOBAL default_storage_engine=MYISAM; -- 全局级别,仅影响新会话,重启之后,参数均失效
-- 想要永久生效,编辑配置文件 vim /etc/my.conf
[mysqld]
default_storage_engine=myisam
|
存储引擎是作用于表级别的,表创建时,可以指定不同的存储引擎,但我们一般建议统一存储引擎为InnoDB。
1
2
3
4
5
6
7
8
9
10
11
|
-- 查看指定库中表的引擎
SHOW TABLE STATUS FROM world;
-- 查看所有表的引擎
SELECT table_schema,table_name,ENGINE FROM information_schema.tables;
-- 过滤一下非系统表
SELECT table_schema,table_name,ENGINE
FROM information_schema.tables
WHERE table_schema
NOT IN ('sys', 'mysql', 'information_schema', 'performance_schema');
|
修改指定表的存储引擎:
1
2
3
4
5
6
7
8
|
-- 等价
ALTER TABLE tt.a1 ENGINE=MYISAM;
ALTER TABLE tt.a2 ENGINE INNODB;
-- 另外,需要注意的是,上面的命令也可以用来进行innodb表的碎片整理
-- 扩展,如果innoob的表有外键关系,那么修改时,需要删除外键后再修改
alter table city drop FOREIGN KEY city_ibfk_1;
alter table city engine myisam;
|
问题来了,如果有1000张表都需要修改存储引擎该怎么办?
来个示例:将world和 tt 数据库中所有myisam引擎的表修改为innodb
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
-- 先将符合条件的表过滤出来
SELECT table_schema,table_name,ENGINE
FROM information_schema.tables
WHERE table_schema IN ("world", "tt") AND ENGINE='myisam';
+--------------+------------+--------+
| table_schema | table_name | ENGINE |
+--------------+------------+--------+
| tt | a1 | MyISAM |
| tt | a2 | MyISAM |
| tt | a3 | MyISAM |
| world | t1 | MyISAM |
+--------------+------------+--------+
4 rows in set (0.00 sec)
-- 拼接命令并导出,如果报错参考:https://www.cnblogs.com/Neeo/articles/13047216.html
SELECT CONCAT('ALTER TABLE ',table_schema,'.',table_name,' engine=innodb;')
FROM information_schema.tables
WHERE table_schema IN ("world", "tt") AND ENGINE='myisam'
INTO OUTFILE '/tmp/check_engine.sql';
-- 导出成功
[root@cs ~]# cat /tmp/check_engine.sql
ALTER TABLE tt.a1 engine=innodb;
ALTER TABLE tt.a2 engine=innodb;
ALTER TABLE tt.a3 engine=innodb;
ALTER TABLE world.t1 engine=innodb;
-- 接下来,就可以执行这个脚本了
[root@cs ~]# mysql -uroot -p </tmp/check_engine.sql
Enter password:
-- 此时,就成功了
SELECT table_schema,table_name,ENGINE
FROM information_schema.tables
WHERE table_schema IN ("world", "tt");
|
接下来就是本篇的主角了,关于InnoDB那些事儿。
about innodb
从MySQL5.5版本开始,InnoDB替代MyISAM成为MySQL的默认存储引擎,提高了可靠性和性能。
InnoDB主要功能
| 功能 | 支持 | 功能 | 支持 |
|---|
| 存储限制 |
64TB |
索引高速缓存 |
是 |
| 多版本并发控制(MVCC) |
是 |
数据高速缓存 |
是 |
| B树索引 |
是 |
自适应散列索引 |
是 |
| 群集索引 |
是 |
复制 |
是 |
| 数据压缩 |
是 |
更新数据字典 |
是 |
| 数据加密 |
是 |
地理空间数据类型 |
是 |
| 查询高速缓存 |
是 |
地理空间索引 |
否 |
| 事务 |
是 |
全文搜索索引 |
是 |
| 锁粒度 |
行 |
群集数据库 |
否 |
| 外键 |
是 |
备份(热备)和恢复 |
是 |
| 文件格式管理 |
是 |
快速索引创建 |
是 |
| 多个缓冲池 |
是 |
performance_schema |
是 |
| 更改缓冲 |
是 |
自动故障恢复(A CSR) |
是 |
InnoDB存储引擎物理存储结构
最直观的物理存储结构,我们能看到的,就是MySQL的存储目录data:
[root@cs ~]# ll /data/mysql
总用量 188468
-rw-r----- 1 mysql mysql 56 6月 8 09:25 auto.cnf
-rw-r----- 1 mysql mysql 7386 8月 17 17:06 cs.err
-rw-r----- 1 mysql mysql 4 9月 21 11:24 cs.pid
drwxr-x--- 2 mysql mysql 20 8月 17 18:00 data_test
-rw-r----- 1 mysql mysql 596 9月 1 03:11 ib_buffer_pool
-rw-r----- 1 mysql mysql 79691776 9月 22 16:35 ibdata1
-rw-r----- 1 mysql mysql 50331648 9月 22 16:35 ib_logfile0
-rw-r----- 1 mysql mysql 50331648 9月 15 16:25 ib_logfile1
-rw-r----- 1 mysql mysql 12582912 9月 22 16:35 ibtmp1
drwxr-x--- 2 mysql mysql 4096 6月 8 09:25 mysql
drwxr-x--- 2 mysql mysql 8192 6月 8 09:25 performance_schema
drwxr-x--- 2 mysql mysql 60 9月 17 21:22 pp
drwxr-x--- 2 mysql mysql 160 8月 26 00:02 school
drwxr-x--- 2 mysql mysql 8192 6月 8 09:25 sys
drwxr-x--- 2 mysql mysql 4096 9月 22 16:35 tt
drwxr-x--- 2 mysql mysql 172 9月 22 16:20 world
其中:
ib_logfile0 ~ ib_logfile1:REDO日志文件,事务日志文件ibdata1:系统数据字典(统计信息),UNDO表空间等数据ibtmp1:临时表空间磁盘位置,存储临时表
基于InnoDB的表都会建立:
frm:存储表的字段信息ibd:表的数据行和索引
表空间
https://dev.mysql.com/doc/refman/5.7/en/innodb-tablespace.html
MySQL在5.5版本(能够上生产环境,稳定的版本)才有了表空间(Table space)的概念,恰好这个时间节点是在被Oracle收购后…..
这里简单说说表空间。虽然MySQL将数据存储到段、区、页中,但是这其中还经历了一个逻辑层 ,物理层面的逻辑层!这里称之为表空间。
PS:一般提到表空间的概念,基本上都是说的是Oracle表空间,这里MySQL可能借鉴了……你有兴趣也可以参考LVM的原理,都类似。

如上图左侧部分,如果MySQL将ibd文件直接从内存中写入到sdb1磁盘中,如果有一天该sdb1磁盘满了怎么办?一般来说可以将sdb1中的数据导入到磁盘空间更大的磁盘sdb2中,然后MySQL后续直接往sdb2中写入数据即可,直到有一天………
MySQL为了解决这个问题,也可能是借鉴了Oracle…….在MySQL层和磁盘层中间再加上一层逻辑层,即表空间,MySQL将ibd文件都存储到table space层,后续的磁盘都可以动态的挂载到table space层……….
而在MySQL中的表空间,经过发展现在有共享表空间和独立表空间两个概念。
共享表空间
Innodb的所有数据保存在一个单独的表空间里面,而这个表空间可以由很多个文件组成,一个表可以跨多个文件存在,所以其大小限制不再是文件大小的限制,而是其自身的限制。从Innodb的官方文档中可以看到,其表空间的最大限制为64TB,也就是说,Innodb的单表限制基本上也在64TB左右了,当然这个大小是包括这个表的所有索引和其他相关数据。
随着MySQL初始化时,默认的共享表空间也随之建立,即数据目录中的ibdata1文件(后续可以是多个),并且初始就一个ibdata1文件,且文件的初始大小为12MB,然后随着数据量的推移,以64MB为单位增加。
可以通过以下参数来查看该ibdata1文件:
1
2
3
|
SELECT @@innodb_data_file_path;
-- SHOW VARIABLES LIKE 'innodb_data_file%';
SELECT @@innodb_autoextend_increment;
|
也可以vim /etc/my.cnf配置文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# ---------- 在默认的datadir目录下设置多个 ibdata 文件 ----------
[mysqld]
innodb_data_file_path=ibdata1:1G;ibdata2:12M:autoextend:max:512M # 自增长到最大512MB
# innodb_data_file_path=ibdata1:1G;ibdata2:12M:autoextend # 初始12M,自增长直到64TB
# 另外,自增长只针对后面的ibdata文件,上面的ibdata1就是写死的1GB大小了
# ---------- 在指定目录设置多个 ibdata 文件 ----------
innodb_data_home_dir= /data/mysql/mysql3307/data
innodb_data_file_path=ibdata1:1G;ibdata2:12M:autoextend # 会在 innodb_data_home_dir 目录下设置多个 ibdata 文件
# ---------- 在指定目录设置多个 ibdata 文件 ----------
innodb_data_home_dir= # innodb_data_home_dir的值保留为空,但该参数不能不写
innodb_data_file_path=ibdata1:12M;/data/mysql/mysql3307/data/ibdata2:12M:autoextend
# 如上例子会在 datadir 下创建 ibdata1;会在 /data/mysql/mysql3307/data/ 目录创建 ibdata2
|
还有另一种情况就是:当没有配置innodb_data_file_path时,默认innodb_data_file_path = ibdata1:12M:autoextend;当需要改为1G时,不能直接在配置文件把 ibdata1 改为 1G ;而应该再添加一个 ibdata2:1G ,如innodb_data_file_path = ibdata1:12M;ibdata2:1G:autoextend。
另外,一般,对于共享表空间的设置,再MySQL初始化之前就设计好了,那么在MySQL初始化的时候,按照你的设置,就自动的建立好相应的文件了。
MySQL5.6版本,共享空间虽然得以保留,但也只用来存储:数据字典、UNDO、临时表
而在5.7版本,临时表被独立出去了….
8.0版本,UNDO也被独立出去了…..
点击以下链接查看架构演示:
5.6 InnoDB架构 5.7 Innodb架构 8.0 InnoDB架构
独立表空间
从5.6开始,默认表空间不再使用共享表空间,替换为独立表空间,主要存储的是用户数据。
存储特点:每个表都有自己的表空间,表空间内存放着ibd文件,idb文件被称之为表空间的数据文件,主要用来存储数据行以及索引信息;而基本的表结构和元数据存储在frm文件中。
除了上述的frm和ibd文件之外,还搭配的有:
Redo Log,重做日志。Undo Log,存储在共享表空间中,回滚日志。ibtmp,临时表,存储在JOIN和UNION操作产生的临时数据,用完自动删除。
独立表空间/共享表空间切换
我们可以对表的元数据、数据、索引信息进行单独管理,那么也能单独对表空间进行管理,比如设置表使用共享表空间。
通过innodb_file_per_table参数来控制MySQL对表使用共享表空间还是独立表空间,而默认值1表示使用独立表空间(一个表就是一个独立的idb文件),而改成0就是使用共享表空间。
1
2
3
4
5
6
7
|
mysql> select @@innodb_file_per_table;
+-------------------------+
| @@innodb_file_per_table |
+-------------------------+
| 1 |
+-------------------------+
1 row in set (0.00 sec)
|
现在我们测试一下,将innodb_file_per_table的值改为0,然后新建一张表(修改操作对原来建立的表没有影响,只会影响修改值后新建的表):
1
2
3
4
5
6
7
8
9
10
11
12
13
|
mysql> set global innodb_file_per_table=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select @@innodb_file_per_table;
+-------------------------+
| @@innodb_file_per_table |
+-------------------------+
| 0 |
+-------------------------+
1 row in set (0.00 sec)
mysql> create table tt.t6(id int);
Query OK, 0 rows affected (0.03 sec)
|
现在,我们来看磁盘上的关于tt数据库下t6表的物理存储结构:
[root@cs ~]# ll /data/mysql/tt/t6*
-rw-r----- 1 mysql mysql 8556 10月 20 16:59 /data/mysql/tt/t6.frm
[root@cs ~]# ^C
[root@cs ~]# ll /data/mysql/tt/t5*
-rw-r----- 1 mysql mysql 8608 9月 29 10:14 /data/mysql/tt/t5.frm
-rw-r----- 1 mysql mysql 98304 9月 29 10:16 /data/mysql/tt/t5.ibd
上述结果中,t5表是之前建立的表,它有ibd和frm两个文件分别存储数据、索引和元数据信息;而innodb_file_per_table=0后创建的t6表,它的物理存储结构中,就只剩下了frm文件,用来存储元数据信息,而数据和索引信息不在存储自己的独立表空间中,即自己的idb文件中了,而是存储到了共享表空间中了(idbata)。
这里我们只是进行测试,生产中很少用到,所以,别忘了将innodb_file_per_table值改回来。
表空间迁移
1
2
|
alter table tt.t1 discard tablespace;
alter table tt.t2 import tablespace;
|
buffer pool
MySQL使用缓冲池(buffer pool)来进一步提高InnoDB的性能。
你也可以称缓冲池为缓冲区池、缓冲区、缓存区,都是一个意思。
先来了解一个概念:
- 数据页(data page),MySQL记录在磁盘上以页的形式存储
- 脏页,内存脏页,磁盘数据页在内存中发生了修改,在刷写到磁盘数据页之前,我们把内存中的数据页成之为脏页;脏页产生的过程称为之构建脏页
buffer pool缓冲池缓存了什么?
buffer pool中缓存了包括索引、一些表相关数据、锁信息。
buffer pool同样采用了页(默认每页16KB)的形式在内存中管理数据,并且每个页设置一个控制信息块对应一个控制块,这个控制块记录了该页所属的表空间号、页号、缓存页在bufferpool中的地址等信息,它的结构如下:

预读
那InnoDB是如何管理buffer pool呢?在具体介绍之前,先来了解下"预读"的概念。
什么是预读?
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K),如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
预读为什么有效?
数据访问,通常都遵循"集中读写"的原则,使用一些数据,大概率会使用附近的数据,这就是所谓的"局部性原理”,它表明提前加载是有效的,确实能够减少磁盘IO。
按页(4K)读取,和InnoDB的缓冲池设计有啥关系?
- 磁盘访问按页读取能够提高性能,所以缓冲池一般也是按页缓存数据。
- 预读机制启示了我们,能把一些"可能要访问"的页提前加入缓冲池,降低未来的磁盘IO操作。
InnoDB使用两种预读算法来提高I/O性能:线性预读(linear read-ahead)和随机预读(randomread-ahead):
- 线性预读(linear read-ahead):线性预读有一个很重要的参数
innodb_read_ahead_threshold,它控制是否将下一个extent预读到buffer pool中。
- 如果一个extent中被顺序读取的page大于等于参数时,Innodb会异步的将下一个extent读取到buffer pool中。innodb_read_ahead_threshold可以设置为0-64的任何值,默认值为56,值越高,访问模式检查越严格。
- 例如,如果将值设置为48,则InnoDB只有在顺序访问当前extent中的48个page时才触发线性预读请求,将下一个extent读到内存中。反之如果设置为2,即使当前extent中只有2个page被连续访问,Innodb也会异步的将下一个extent读取到buffer pool中。
- 如果禁用该变量,只有当顺序访问到extent的最后一个page的时候,Innodb才会将下一个extent放入到buffer pool中。
- 随机预读(randomread-ahead):随机预读方式则是表示当同一个extent中的一些(可以不连续)page被读取到buffer pool中时,Innodb会将该extent中的剩余page一并读到buffer pool中,由于随机预读方式给Innodb code带来了一些不必要的复杂性,同时在性能也存在不稳定性,在5.5中已经将这种预读方式废弃。要启用此功能,请将配置变量设置innodb_random_read_ahead为ON。
线性预读着眼于将下一个extent提前读取到buffer pool中,而随机预读着眼于将当前extent中的剩余的page提前读取到buffer pool中。
相关参数:
1
2
3
4
5
6
7
8
|
mysql> mysql> show variables like "%read_ahead%";
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| innodb_random_read_ahead | OFF |
| innodb_read_ahead_threshold | 56 |
+-----------------------------+-------+
2 rows in set (0.00 sec)
|
了解了预读相关 概念,再来看InnoDB用了什么算法来管理buffer pool。
传统的LRU算法对缓冲页进行管理
在缓存技术中,最常见的缓存管理算法就是LRU算法了,例如memcache就是采用LRU算法来进行缓存页置换管理,但MySQL并没有原样采用LRU算法,而是在LRU算法基础上做了优化。
那么传统的LRU算法如何进行缓冲页管理的呢?
最常见的用法就是把缓冲池的页放到LRU(链表)的头部,作为最近访问的元素,从而最晚被淘汰,这里又分为两种情况:
- 页已经在缓冲池里,那就只做"移至"LRU头部的动作,而没有页被淘汰。
- 页不在缓冲池里,除了做"放入"LRU头部的动作,还要做"淘汰"LRU尾部页的动作。
来个例子,如下图,缓冲池中LRU的长度为10,并且缓冲了页号如图所示的这些页。

现在,我们要访问的数据在4号页中,那要做的动作:
- 首先,判断4号页在不在缓冲池中。
- 如上图很明显是在的,就把4号页移动到LRU的头部,此时并没有页被淘汰,其结果如下图所示。

现在,我们访问数据在50号页内:
- 首先,页号为50的页并不在LRU内。
- 把50号页放到LRU的头部,同时淘汰尾部7号页,如下图所示。

由上面两个例子可以看到,传统的LRU算法十分直观,也有很多软件在采用,那么MySQL为啥不直接使用呢?我们继续探讨。
MySQL优化LRU算法对脏页进行管理
接上小节,为啥MySQL不直接使用传统LRU算法管理脏页呢?因为这里存在两个问题:
分别来说两个问题。
什么是预读失败?
经过预读(read-ahead),提前把页放入了缓冲池中,但最终MySQL并没有从这些预读的页中读取数据,我们称之为预读失效。
那如何对预读失败进行优化?
- 让预读失败的页,停留在缓冲池LRU里的时间尽可能短。也就是说,让这些数据放在LRU的尾部,尽快淘汰掉。
- 让真正被读取的页,才放入LRU的头部。
这样来保证真正被读取的热点数据留在缓冲池中的时间尽可能的长。
InnoDB的具体优化是,将传统的LRU算法中的一个链表,抽象为两个链表:
- 新生代(new sublist)链表。
- 老生代(old sublist)链表。
然后将新/老生代的两个链表首尾相连,即新生代的尾部tail连接老生代的头部head,并且新生代和老生代的分配比例一般是7:3。其实就是一个循环链表,只不过抽象为两部分。
此时如果有预读的页加入缓冲池中,它此时只能加入到老生代的头部,接下来的它面临着:
- 如果数据真整被读取,即预读成功,才会从老生代的头部移动到新生代的头部。
- 如果数据没有被读取,即预读失败,则不会从老生代移动到新生代,这样这些数据将更早的被淘汰。
举个例子,如下图,LRU的长度为10,前70%为新生代,后30%为老生代,且新老生代首尾相连。

例如,有一个页号为50的新页被加载到缓冲池中:
- 50号页首先被插入到老生代的头部,老生代的尾部(也是整个链表的尾部)的页会被淘汰掉。
- 假如50号页最终预读失败,那么它将比新生代的数据更早的淘汰。

假如,50号页预读成功了,例如SQL最终访问了该页内的某行记录:
- 50号页将会从老生代头部移动到新生代的头部。
- 原新生代的尾部页会被挤到老生代的头部,此时没有页从整个LRU中被淘汰。

有上例可以看到,InnoDB优化后的LRU能够很好的解决预读失败的问题。
现在InnoDB需要解决传统LRU的第二个问题——缓冲池污染的问题。
那么什么是缓冲池污染?
当某个SQL语句,要批量扫描大量数据甚至是全表扫描时,如果把这些数据一股脑都缓冲到缓冲池中,可能导致把缓冲池的所有页都置换出去,即导致大量的热点数据被置换,此时MySQL的性能会急剧下降,这种情况叫做缓冲池污染。
例如,执行下面的SQL:
1
|
select * from userinfo where name like "%zhangkai%";
|
虽然,结果集可能只有少量的数据,但要知道在like语句中首位使用%是不会走索引的,必须全表扫描,此时就需要访问大量的页,那将会:
- 把页加载到缓冲池中,此时插入老生代头部。
- 从页中读取相关row,插入到新生代的头部。
- 匹配row的name字段,把符合条件的,加入到结果集中。
- 一直重复上述步骤,直到扫描完所有页中的row…….
如此一来,虽然结果集拿到了,但这些数据很可能只会被访问一次,而真正的热点数据被大量置换出去了……
为了解决这类扫描大量数据导致缓冲池污染的问题,MySQL在缓冲池中加入一个老生代停留时时间窗口机制:
- 假设老生代停留时间为T。
- 插入老生代头部的页,即使立刻被访问,但也不会立刻被放入到新生代的头部。
- 只有满足被访问且在老生代停留时间大于T,才会被放入到新生代的头部。
如下图,在原LRU基础上,有页号为51、52、53、54、55的页将被一次被访问:

如下图,如果此时没有老生代停留时间策略,那么这些批量被访问的页将大量的替换原有的热点数据:

如下图,当加入老生代停留时间策略后,短时间内被大量加载的页,并不会被立刻插入新生代头部,而是优先淘汰那些不满足在老生代停留时间大于T的页,而那些在老生代里停留时间大于T的页,才会被插入到新生代的头部:

buffer pool相关参数
了解了buffer pool的原理和算法原理,接下来就大致说说相关的参数和设置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> show variables like "%innodb_buffer_pool%";
+-------------------------------------+----------------+
| Variable_name | Value |
+-------------------------------------+----------------+
| innodb_buffer_pool_chunk_size | 134217728 |
| innodb_buffer_pool_dump_at_shutdown | ON |
| innodb_buffer_pool_dump_now | OFF |
| innodb_buffer_pool_dump_pct | 25 |
| innodb_buffer_pool_filename | ib_buffer_pool |
| innodb_buffer_pool_instances | 1 |
| innodb_buffer_pool_load_abort | OFF |
| innodb_buffer_pool_load_at_startup | ON |
| innodb_buffer_pool_load_now | OFF |
| innodb_buffer_pool_size | 134217728 |
+-------------------------------------+----------------+
10 rows in set (0.00 sec)
|
其中:
innodb_buffer_pool_size,缓存区大小,默认是128MBinnodb_buffer_pool_chunk_size,当增加或者减少innodb_buffer_pool_size时,操作以块(chunk)形式执行。默认块大小是128MBinnodb_buffer_pool_instances,当buffer pool设置的较大时(超过1G或者更大),innodb会把buffer pool划分为几个instances,这样提高读写操作的并发,减少竞争。
我们知道当增加或者减少buffer pool大小的时候,实际上是操作的chunk。所以buffer pool的大小必须是innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances,如果配置的innodb_buffer_pool_size不是innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的倍数,buffer pool的大小会自动调整为innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的倍数,自动调整的值不少于指定的值。例如指定的buffer pool size是9G,instances的个数是16,chunk默认的大小是128M,那么buffer会自动调整为10G。
PS:一般建议 innodb_buffer_pool_size 大小设置为物理内存的 75-80%。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
mysql> show engine innodb status\G -- 查询MySQL buffer pool 的使用状态
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992
Dictionary memory allocated 116177
Buffer pool size 8192 -- 单位:页 16字节 8192 * 16 / 1024 = 128 MB
Free buffers 7728
Database pages 464
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 429, created 35, written 37
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 464, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
|
see also : MySQL5.7 14.8.3.1 Configuring InnoDB Buffer Pool Size
buffer pool刷写策略
buffer pool中的脏页何时刷写到磁盘这个问题!
这里用到的一些参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
mysql> show variables like "%innodb_io_cap%";
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_io_capacity | 200 |
| innodb_io_capacity_max | 2000 |
+------------------------+-------+
2 rows in set (0.00 sec)
mysql> show variables like "%innodb_max_dirty%";
+--------------------------------+-----------+
| Variable_name | Value |
+--------------------------------+-----------+
| innodb_max_dirty_pages_pct | 75.000000 |
| innodb_max_dirty_pages_pct_lwm | 0.000000 |
+--------------------------------+-----------+
2 rows in set (0.00 sec)
mysql> select @@innodb_lru_scan_depth;
+-------------------------+
| @@innodb_lru_scan_depth |
+-------------------------+
| 1024 |
+-------------------------+
1 row in set (0.00 sec)
mysql> select @@innodb_flush_neighbors;
+--------------------------+
| @@innodb_flush_neighbors |
+--------------------------+
| 1 |
+--------------------------+
|
innodb_io_capacity参数指定刷新脏页的数量,innodb_io_capacity_max是最大值,在I/O能力允许的情况下可以调高innodb_io_capacity值来提高每次刷新脏页的值,提高性能。另外,innodb_max_dirty_pages_pct参数控制脏页的比例,默认是75%,当脏页比例超过75%,就会触发checkpoint刷盘,刷盘到innodb_max_dirty_pages_pct_lwm参数时,改为自适应刷写策略,简单理解为当脏页占比越高,刷脏页的强度越大,否则慢慢变小。
innodb_lru_scan_depth指定每次刷新脏页的数量。
这里再看一个有趣的策略。一旦一个查询请求需要在执行过程中先 flush 掉一个脏页时,这个查询就可能要比平时慢了。而 MySQL 中的一个机制,可能让你的查询会更慢:在准备刷一个脏页的时候,如果这个数据页旁边的数据页刚好是脏页,就会把这个“邻居”也带着一起刷掉;而且这个把“邻居”拖下水的逻辑还可以继续蔓延,也就是对于每个邻居数据页,如果跟它相邻的数据页也还是脏页的话,也会被放到一起刷。
在 InnoDB 中,innodb_flush_neighbors参数就是用来控制这个行为的,值为1的时候会有上述的"连坐"机制,值为0时表示不找邻居,自己刷自己的。找"邻居"这个优化在机械硬盘时代是很有意义的,可以减少很多随机 I/O。机械硬盘的随机 IOPS(每秒的读写次数) 一般只有几百,相同的逻辑操作减少随机 I/O 就意味着系统性能的大幅度提升。而如果使用的是 SSD 这类 IOPS 比较高的设备的话,建议把 innodb_flush_neighbors的值设置成 0。因为这时候 IOPS 往往不是瓶颈,而"只刷自己”,就能更快地执行完必要的刷脏页操作,减少 SQL 语句响应时间。 在 MySQL 8.0 中,innodb_flush_neighbors参数的默认值已经是0了。
double write
buffer pool中的脏页刷盘时,还采用了double write机制,来保证数据的安全性,想要了解double write,我们先来了解一下partial page write。
partial page write
innodb page size 是16KB,如果在写入磁盘数据页时,遇到断电或者系统崩溃,很可能导致16KB的数据页只有部分写入到了磁盘上,另外的丢了,这就是partial page write的问题。
innodb为了解决partial page write的问题,采用double write机制。
double write功能由innodb_doublewrite参数控制是否开启,MySQL5.7中,默认值为1是开启的,你也可以设置为0关闭它:
1
2
3
4
5
6
7
|
mysql> select @@innodb_doublewrite;
+----------------------+
| @@innodb_doublewrite |
+----------------------+
| 1 |
+----------------------+
1 row in set (0.00 sec)
|
double write也有自己的内存区域double write buffer和磁盘文件两部分组成:
1
2
|
[root@cs ~]# ll /data/mysql/ibdata*
-rw-r----- 1 mysql mysql 79691776 11月 17 20:58 /data/mysql/ibdata1
|
PS:double write和undo log一样都存放于共享表空间中。
double write的工作流程
当buffer pool的脏页需要刷写到磁盘数据页时,先使用memcopy将脏页拷贝到double write buffer,之后double write bffer再分为2次写入磁盘:
- 第一次,从double write buffer顺序写入(fsync)到共享表空间中,留作备份。
- 第二次,从double write buffer再离散写入各个表空间中,此时如果断电或者意外宕机,就可以从共享表空间中恢复数据了。

double write保证了数据的安全性,但也因此多了很多的fsync操作,对性能有一定的影响,这在实际工作中要根据应用场景决定是否开启。
事务
首先,只有存储引擎是innodb的表才支持事务……..
事务就是一组原子性的SQL查询,或者说是一个独立的工作单元,如果数据库引擎能够成功地对数据库应用该组查询的全部语句,那么就执行该组语句。如果其中有任何一条语句因为崩溃或者其他原因无法执行,那么所有的语句都不会执行。即事务内的语句,要么全部执行成功,要么全部执行失败。
事务的ACID特性
ACID表示原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability),一个运行良好的事务处理系统,必须具备这些标准特性。
- 原子性(atomicity):一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
- 一致性(consistency):数据库总是从一个一致性状态转换到另一个一致性状态。
- 隔离性(isolation):通常来说,一个事务所做的修改在最终提交之前,对其他事务是不可见的。也可以说事务之间不相互影响。
- 持久性(durability):一旦事务提交,则其所做的修改就会永久的保存到数据库中,此时即使系统崩溃,修改的数据也不会丢失。
多说一点,持久性是一个有点模糊的概念,因为实际上持久性也分很多不同的级别,有些持久性策略能提供非常强的安全保证,而有些则未必,而且不可能有能够做到100%的持久性保证的策略,不然还要备份干啥?
事务的生命周期(事务控制语句)
事务的开始
begin
说明,在5.5以后的版本,不需要手动begin,只要你执行的是一个DML语句,会自动在前面加一个begin命令。
事务的结束
commit:提交事务,完成一个事务,一旦事务提交成功,就具备了ACID的特性了。
rollback:回滚事务,将内存中,已执行过的操作,回滚到事务开始之前。
自动提交策略(autocommit)
为了避免有些事务没有提交的情况,MySQL5.6开始有了自动提交策略,即自动帮我们commit,通过autocommit参数可以发现该策略是否打开,1是默认打开,0是关闭;但我们一般的,不管有没有事务需求,都将该值设置为0,可以很大程度上提高数据库的性能。
1
2
3
4
5
6
7
|
select @@autocommit;
set session autocommit=0; -- 等价于 set autocommit=0;
set global autocommit=0;
-- 配置文件修改 vim /etc/my.cnf
[mysqld]
autocommit=0
|
当在autocommit=0时,我们可以动手来练习一下事务,过程就是begin之后,执行一个操作,然后rollback和commit操作来观察事务的执行和回滚:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
-- 确保 autocommit=0
mysql> select @@autocommit;
+--------------+
| @@autocommit |
+--------------+
| 0 |
+--------------+
1 row in set (0.00 sec)
-- 现在,t2表有一条记录
mysql> select * from t2;
+----+--------+----------------------------------+
| id | user | pwd |
+----+--------+----------------------------------+
| 1 | 张开 | 9B9FC7A9EA433FB08DA3AB8EB22BDAF1 |
+----+--------+----------------------------------+
1 row in set (0.00 sec)
|
来演示begin-->rollback操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
mysql> begin; -- 开始事务
Query OK, 0 rows affected (0.00 sec)
mysql> delete from t2 where id=1; -- 执行删除操作
Query OK, 1 row affected (0.00 sec)
mysql> select * from t2; -- 删除成功
Empty set (0.00 sec)
mysql> rollback; -- 回滚
Query OK, 0 rows affected (0.01 sec)
mysql> select * from t2; -- 数据恢复
+----+--------+----------------------------------+
| id | user | pwd |
+----+--------+----------------------------------+
| 1 | 张开 | 9B9FC7A9EA433FB08DA3AB8EB22BDAF1 |
+----+--------+----------------------------------+
1 row in set (0.00 sec)
|
上面的事务执行到删除成功,其实事务并没有执行完毕,所以可以rollback。
再来看begin-->commit操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
-- 还是之前的t2表,还是那一条数据
mysql> begin; -- 开始事务
Query OK, 0 rows affected (0.00 sec)
mysql> delete from t2 where id=1; -- 删除操作
Query OK, 1 row affected (0.00 sec)
mysql> commit; -- 事务提交成功。注意,已经提交的事务无法回滚
Query OK, 0 rows affected (0.01 sec)
mysql> select * from t2; -- 再查就没有数据了
Empty set (0.00 sec)
mysql> rollback; -- 此时,再rollback也不行了,因为上一个事务结束了
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t2; -- 仍然是空的
Empty set (0.00 sec)
|
最后,别忘了将autocommit的值改为1。
隐式提交语句
无论是begin还是autocommit都算是显式的事务提交,但有些情况也会自动的触发事务并提交,来看都有哪些情况或者语句:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
-- 隐式提交的sql语句
begin
语句1
语句2
begin -- 当上一个事务没有提交完成,又开始了一个begin,那在本次begin之前,上一个begin会自动提交
-- 当在事务中执行了下面语句也会将之前的事务提交
set autocommit=1
-- 导致提交的非事务语句:
DDL语句:(alter,create,drop)
DCL语句:(grant,revoke,set password)
锁定语句:(lock tables,unlock tables)
-- 其他导致隐式提交的语句示例:
truncate table
load data infile
select for update
|
所以,在执行自己的事务期间,要尽量的避免上述的隐式提交语句出现,避免干扰自己的事务逻辑。
InnoDB事务如何保证ACID?
事务的工作流程

如上图,现在有这样一条事务要执行update t1 set name='A' where name='B';。

如上图,就是一条事务的执行过程,而我们本小节就是研究在其过程中的细节,进而理解Innodb是如何保证事务的ACID的。
完整的架构:https://dev.mysql.com/doc/refman/5.7/en/innodb-architecture.html
首先,你应该留意的概念:
- redo log,重做日志,主要在事务中实现持久性
- redo log file,磁盘上的redo log
- red log buffer,redo log的缓存
- undo log,提供事务的回滚和MVCC
- buffer pool,缓冲区池,缓冲数据和索引
- LSN,日志序列号,在事务的不同阶段,LSN号页在递增,在CSR时提供依据
- WAL(Write-Ahead LOG),日志优先写,先写日志,再写磁盘,实现持久化
- CKPT(checkpoint),检查点,根据不同的策略将脏页刷写到磁盘
- TXID,innodb为每个事务都会生成一个事务号,伴随整个事务的过程
现在我们来大致了解事务的执行过程:
现在有一个update t1 set name="B" where name="A";这样的一个事务被提交到MySQL内存:
begin开始后,将加载到内存的数据页内的name="B"的位置修改为name="A"。- 根据WAL策略,update操作不会第一时间刷写到磁盘数据页,而是将这一更改变化进行记录,记录的是对磁盘上的某个表空间的某个数据页的偏移量为xxx处的xx数据做了修改,修改后的值为多少,另外记录LSN和TXID等其他信息。将这个记录写入到redo log buffer。这个redo log的状态设置为
prepare,意味准备提交的事务。
- 当这个事务
commit后,再将这条记录的状态设置为commit,并且由redo log buffer刷写到了磁盘的ib_logfile中。
- redo log buffer和磁盘上的redo log file之间还要经过system os buffer,所以
innodb_flush_log_at_trx_commit和innodb_flush_method这两个参数决定了redo log buffer中的日志何时刷写到磁盘的redo log file中,是否经过system os buffer。
- 当redo log被刷写到磁盘上时,根据不同的条件触发了checkpoint机制,此时由相关线程将记录状态为
commit的记录真正的刷写到对应的磁盘数据页,也就完成了真正的一条事务。在这个过程中对于记录状态为prepare的事务,直接丢掉即可,因为事务没提交嘛。
- 在数据没有被刷写到磁盘数据页之前的过程,我们称之为构建脏页,这些数据也称之为脏数据。
- checkpoint就是将脏页按照一定的规则刷写到磁盘数据页。
根据上图,当事务执行到第4步时,就无惧宕机或者其他的意外情况了, 因为我们将对数据页的更改已经保存到了磁盘上,当MySQL执行CSR时,直接将redo file中记录的更改操作重新执行一次就完了,所以这也是redo log被称为重做日志的原因,执行重做的过程称之为基于redo的"前滚操作"。
既然有前滚操作,就有回滚操作,这是undo log负责的部分,后续会展开讲解。
我们现在了解一下redo log过程中哪些不为人知的细节。
在这之前大致了解下MySQL中的三种日志类型:
redo log:是存储引擎层生成的日志,主要为了保证数据的可靠性和持久性。bin log:是数据库层面生成的日志,主要用于日志恢复和主从复制。undo log:主要用于日志回滚和MVCC中。
基于redo——前滚
什么是redo log?
redo log(重做日志)是事务日志的一种。
其主要的做用是在事务中实现持久化,当然也保证了事务的原子性和一致性。之前说redo log是存储引擎的层面生成的日志,是因为redo log 记录的是对磁盘上的某个表空间的某个数据页的偏移量为xxx处的xx数据做了修改,修改后的值为多少,它记录的是对物理磁盘上数据的修改,它本质上是16进制的修改,因此称之为物理日志。每当执行一个事务就会产生这样的一条物理日志。
redo log文件是持久化在磁盘上的,由多个具体的日志文件共同组成逻辑上的redo log。MySQL默认有2个redo log文件(分别叫做ib_logfile0、ib_logfile1),每个文件的大小是48MB,这两个文件默认存储在MySQL的数据文件目录内:
1
2
3
|
[root@cs ~]# ll /data/mysql/ib_log*
-rw-r----- 1 mysql mysql 50331648 11月 2 10:11 /data/mysql/ib_logfile0
-rw-r----- 1 mysql mysql 50331648 9月 15 16:25 /data/mysql/ib_logfile1
|
该文件的相关参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
mysql> show variables like "innodb_log%";
+-----------------------------+----------+
| Variable_name | Value |
+-----------------------------+----------+
| innodb_log_buffer_size | 16777216 |
| innodb_log_checksums | ON |
| innodb_log_compressed_pages | ON |
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
| innodb_log_group_home_dir | ./ |
| innodb_log_write_ahead_size | 8192 |
+-----------------------------+----------+
7 rows in set (0.02 sec)
|
其中:
innodb_log_files_in_group,定义日志组中的日志文件数。默认值和推荐值为2。innodb_log_file_size,定义日志组中每个日志文件的大小(以字节为单位)。日志文件的总大小innodb_log_file_size*innodb_log_files_in_group不能超过512GB的最大值。innodb_log_group_home_dir定义InnoDB日志文件的目录路径。默认的 InnoDB在MySQL数据目录中创建日志文件。
redo log的工作方式
innodb每执行一条事务产生的redo log会以循环的方式写入到磁盘,如下图所示:

其中,write pos(position)表示redo log当前记录的位置,当ib_logfile0写满后,会从ib_logfile1文件头部继续覆盖写(前提是被覆盖的日志操作都已经刷写到磁盘的数据页上了);check point表示将日志记录的修改真正的刷写的对应的磁盘数据页中,完成数据落盘;数据落盘后check orint会将这部分日志记录擦除,所以write pos和check point之间部分是redo log的空着的部分,用于记录新的日志;而check point和write pos是redo log待落盘的数据修改记录。
当write pos追上check point时(表示没有空间写记录了),要停止新的记录,先推动check point往前走(数据落盘后,位置就空出来了),空出位置共新记录的写入。
redo log buffer
如果在内存中执行一个事务,那么产生的日志直接刷写到磁盘的redo log文件中也不太合适,这样也会产生大量的I/O操作,而且磁盘的运行速度远慢于内存,所以,redo log也有自己的缓存——redo log buffer,简称log buffer或者innodb log buffer。
MySQL在启动时,就会向系统申请一块空间作为redo log的buffer cache,默认大小是16MB,由redo_log_buffer_size控制:
1
2
3
4
5
6
7
|
mysql> select @@innodb_log_buffer_size 字节,(select @@innodb_log_buffer_size)/1024/1024 MB;
+----------+-------------+
| 字节 | MB |
+----------+-------------+
| 16777216 | 16.00000000 |
+----------+-------------+
1 row in set (0.00 sec)
|
redo log buffer内存的存储方式是以block为单位进行存储的,每个block块的大小是512字节,同磁盘的扇区大小一致,这样设计可以保证后续的写入都是原子性的。
另外,也正是以块的方式写入redo log file,且每个block大小为512字节(磁盘I/O的最小单位),所以不会出现数据损坏的问题,这也是为啥redo log中不采用double write机制的原因。
block的构成如下:

redo log持久化过程
每当产生一条redo log时,先被写入到redo log buffer,然后在某个"合适的时候"将整块的block刷写到redo log文件。那这个"合适的时候"是啥时候呢?
-
MySQL正常关闭时。
-
MySQL的后台master thread每隔一段时间(1s)将redo log buffer的block刷写到redo log file。
-
当redo log buffer中记录的写入量大于redo log buffer内存的一半时。
-
根据innodb_flush_log_at_trx_commit参数设置的规则。
接下来,聊一聊innodb_flush_log_at_trx_commit这个参数是如何控制redo log刷写磁盘的。
innodb_flush_log_at_trx_commit
innodb_flush_log_at_trx_commit是双一标准之一!
那该参数是干嘛的呢?innodb_flush_log_at_trx_commit主要控制innodb将log buffer中的数据写入日志文件并flush磁盘的时间点,取值分别为0、1、2,默认值是1:
1
2
3
4
5
6
7
|
mysql> select @@innodb_flush_log_at_trx_commit;
+----------------------------------+
| @@innodb_flush_log_at_trx_commit |
+----------------------------------+
| 1 |
+----------------------------------+
1 row in set (0.01 sec)
|

根据上图:
- 当
innodb_flush_log_at_trx_commit=0时,master thread每秒将redo log buffer中的日志往os buffer写入,os buffer再刷写(fsync)到磁盘的redo文件中。该模式速度最快,但安全性较差,因为MySQL宕机的话, 会丢失上一秒所有的事务。
- 当
innodb_flush_log_at_trx_commit=1时,每次事物的提交都会执行redo log buffer▶os buffer▶disk的过程。该模式最安全,但速度最慢,当MySQL宕机时最多可能丢失一个事务的redo log。
- 当
innodb_flush_log_at_trx_commit=2时,每次事务的提交都会从redo log buffer往os buffer写入,但os buffer会每秒完成一次fsync操作。该模式速度适中,只有在操作系统崩溃或者断电时,上一秒的redo log在os buffer中没来得及写入磁盘,导致丢失。
上面三种模式的日志刷写,都有os buffer的参与,那么有没有直接从redo log buffer写入到磁盘,从而绕过os buffer这样的策略或者设置,答案是有的,往下看。
Innodb_flush_method
innodb_flush_method参数控制log buffer和buffer pool在刷写磁盘时是否经过os buffer。
通过select查看当前系统中使用的模式:
1
2
3
4
5
6
7
|
mysql> select @@innodb_flush_method;
+-----------------------+
| @@innodb_flush_method |
+-----------------------+
| NULL |
+-----------------------+
1 row in set (0.00 sec)
|
If innodb_flush_method is set to NULL on a Unix-like system, the fsync option is used by default

在Linux系统中,常用三种刷写模式:
fsync:调用fsync函数刷写数据文件和redo log,两者都走os buffer.O_DSYNC:数据文件走os buffer,redo log不走os buffer.O_DIRECT:数据文件直接刷写到磁盘,不走os buffer;redo log走os buffer.
最高安全模式
1
2
|
innodb_flush_log_at_trx_commit=1
Innodb_flush_method=O_DIRECT
|
最高性能
1
2
|
innodb_flush_log_at_trx_commit=0
Innodb_flush_method=fsync
|
checkpoint
检查点(checkpoint)指得是脏页何时刷写到磁盘数据页的节点。在innodb中,无论是buffer pool中的数据页刷盘还是redo log刷盘都是通过checkpoint来完成的,只不过触发checkpoint执行的规则有所不同罢了。
innodb的checkpoint分为两类:
- sharp checkpoint,完全检查点,它用来在MySQL正常关闭时,触发checkpoint将所有的脏页都刷写到磁盘对应的数据页,包括redo log中的。
- sharp checkpoint只发生在MySQL正常关闭时。
- 运行时的刷写磁盘不用sharp checkpoint,而是使用fuzzy checkpoint。
- fuzzy checkpoint,模糊检查点,一次只刷一部分redo log到磁盘,而非将所有的redo log刷写到磁盘。由以下几种情况触发fuzzy checkpoint:
- master thread checkpoint,由master thread线程控制,每秒或者每10秒刷入一定比例的脏页到磁盘。
- flush_lru_list_checkpoint,MySQL需要保证LRU链表中大约有100页的空闲页可用,如果没有这么多空闲页,就会将LRU的尾部淘汰一部分页,如果这些页中有脏数据需要落盘,就会触发checkpoint进行刷盘操作。PS:在MySQL5.6版本之后,可以通过
innodb_page_cleaners参数来指定负责刷盘的线程数。
- async/sync flush checkpoint,当redo log file快满了的时候,会触发checkpoint刷盘,这个过程又有两种情况:
- 当不可覆盖(数据没有落盘)的redo log站redo log file比值的75%时,采用异步刷盘。此时不会阻塞用户查询。
- 当不可覆盖(数据没有落盘)的redo log站redo log file比值的90%时,采用同步刷盘。此时会阻塞用户查询。
- 当上述两种情况有任何一种情况发生时,都会写入到errlog中,一旦errorlog有这种提示时,意味着你要考虑是否要加大redo log file了,还是做其他的优化。
- 当然了,从MySQL5.6版本开始,这部分刷新的操作同样有单独的page clear thread来完成,所以,不会阻塞用户查询了。
- dirty page too much checkpoint,buffer pool中脏页太多,强制触发checkpoint刷盘,目的是保证buffer pool中有足够的空闲页。
LSN
PS:你应该拿着"事务的工作流程"部分的图来对比学习这部分内容。
LSN(Log Sequence Number)日志序列号,在innodb中,LSN是单调递增的整型数,占用8个字节,LSN值随着日志不断写入而增大,LSN号出现在每一个数据页、redo log中、checkpoint中,在事务执行的不同阶段LSN号也不同,我们可以通过下面命令查看:
1
2
3
4
5
6
7
8
|
mysql> show engine innodb status\G
---
LOG
---
Log sequence number 124983029
Log flushed up to 124983029
Pages flushed up to 124983029
Last checkpoint at 124983020
|
其中:
Log sequence number是当前的redo log buffer中的LSN号Log flushed up to是刷写到redo log file中的LSN号Pages flushed up to是刷写到磁盘数据页上的LSN号Last checkpoint at是上一次检查点所在位置的LSN号
以上四个LSN号是递减的,Log sequence number≥Log flushed up to≥Pages flushed up to≥Last checkpoint at,而我们在工作中重点关注的是Last checkpoint at和Log flushed up to这两个LSN号。
在MySQL的CSR过程中,必须保证redo log和磁盘数据页中的LSN号是一致的,否则无法正常启动,所以innodb会扫描redo log file到buffer pool,然后检查对比Last checkpoint at和Log flushed up to这两个LSN号,Last checkpoint at到Log flushed up to这两个LSN号之间的数据就是需要做数据恢复的,即MySQL将这部分redo日志在buffer pool中重做一边,直到Last checkpoint at追平Log flushed up to,数据恢复完毕,MySQL正常启动。
基于undo——回滚
当有多个事务在buffer pool中,其中有的立马commit了,有的最终没有commit,对于这些未提交的事务该如何处理?rollback怎么实现的?在CSR时,怎么处理这些prepare的事务?这个时候就需要引入undo log了。
关于undo log
与redo log记录物理日志不一样的是,undo log主要记录的是数据页的逻辑变化,简单立即理解为当delete一条记录时,undo log中会记录一个对应的insert记录,反之亦然;当update时,undo log会记录一个相反update记录…..故,我们称undo log是逻辑日志。
undo log也有自己的log buffer,另外,undo log也会被记录在redo log中,保证undo log的持久化。
undo log的主要作用是:
undo log的存储
默认的,innodb对于undo采用段(segment)的方式,rollback segment称为回滚段,每个回滚段中有1024个undo log segment。
相关参数如下,需要说明的是,由于MySQL版本不同,参数也不尽相同,这里以MySQL5.7为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
[root@cs ~]# ll /data/mysql/ibdata*
-rw-r----- 1 mysql mysql 79691776 11月 2 10:11 /data/mysql/ibdata1
mysql> show variables like "%rollback_segment%";
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_rollback_segments | 128 |
+--------------------------+-------+
1 row in set (0.00 sec)
mysql> show variables like "%undo%";
+--------------------------+------------+
| Variable_name | Value |
+--------------------------+------------+
| innodb_max_undo_log_size | 1073741824 |
| innodb_undo_directory | ./ |
| innodb_undo_log_truncate | OFF |
| innodb_undo_logs | 128 |
| innodb_undo_tablespaces | 0 |
+--------------------------+------------+
5 rows in set (0.00 sec)
|
其中:
- 在MySQL5.7以后,
innodb_rollback_segments已更名为innodb_undo_logs,都是表示回滚段的个数。至于innodb_rollback_segments参数仍然保留是为了版本兼容
innodb_max_undo_log_size默认的undo log文件大小是1024MBinnodb_undo_tablespaces默认为0时,表示undo log都在一个文件中,存放在共享表空间中,并且该参数是静态参数,即如果要修改该参数,需要停止MySQL实例innodb_undo_directory表示undo log的默认存位置,它默认存储在共享表空间中,也就是ibdata1中。./`表示MySQL的数据目录。innodb_undo_log_truncate表示是否开启在线收缩undo log文件大小,默认是关闭的,如果设置为1表示开启,当undo log超过innodb_max_undo_log_size定义的大小时,undo log会被标记为可truncate,意味着可在线收缩undo log的大小。注意,设置开启只对开启了undo log分离的有效,不会对共享表空间的undo log有效。因为在线收缩undo log时,会截断undo log的写入,这意味着要有另一个或者多个undo log文件在工作,即需要设置参数innodb_undo_tablespaces>=2和innodb_undo_logs>=35,详见官方文档
undo log和redo log的事务的完整流程

现在有两个事务要执行:
1
2
3
4
5
|
-- TXID:110
update t1 set name="A" where name"B";
-- TXID:111
update t1 set name="D" where name"C";
|
其记录redo log和undo log过程:
begin开始- 记录
name="B"到undo log
- 修改
name="A"
- 记录
name="A" where name"B"到redo log
- 记录
name="C"到undo log
- 修改
name="D"
- 记录
name="D" where name"C"到redo log
- 将redo log刷写到redo log file
- TXID110,commit了,故该条redo log的状态是commit
- TXID111,没有commit,所以该条redo log的状态是prepare
现在,当你进行rollback时,就可以根据事务ID去undo log中做回滚操作。CSR时也可以根据undo log做回滚操作。
undo log的类型
在innodb中,undo log分为:
- insert undo log,指在insert操作中产生的undo log,因为insert操作的记录,只对事务本身可见(当然要设置对应的隔离级别),对其他事务不可见,故该undo log可以在事务提交后直接删除,不需要进行purge操作。
- update undo log,记录的是对delete和update操作产生的undo log,因为该undo log可能需要提供MVCC机制或者rollback操作,所以不能在事务提交后直接删除,而是提交时放入undo log链表中,未来通过purge线程来删除。
- 而update操作又可以分为两种:
- 如果更新的列不是主键列,在undo log中直接记录一个相反update记录,然后直接update。
- 如是主键列,首先执行的操作是删除该行(原记录);完事再插入一条更新后的记录。
- delete操作实际上也不会直接删除,而是将delete的记录打个tag,标记为删除,然后这个事务对应的undo log被放到了删除列表中。
PS:purge线程主要作用就是清理undo页和清除page中带有删除标记的数据行。
隔离级别
事务的隔离性其实比想象的要复杂。
在SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改,哪些在事务内和事务间是可见的,哪些是不可见的。
通常,较低级别的隔离可以执行更高的并发,系统的开销也更低。
下面简单介绍以一下四种隔离级别。
未提交读(RU,read uncommitted)
在RU级别,事务中的修改,即使没有提交,对其他事务也都是可见的,事务可以读取未提交的数据,这被称为脏读(dirty read)。这个级别会导致很多问题,从性能上来说,RU不会比其他级别好太多,但却缺乏其他级别的很多好处,除非真的有非常必要的理由,在实际应用中一般很少使用。
提交读(RC,read committed)
大多数数据库系统的默认隔离级别都是RC(但MySQL不是!),RC满足前面提到的隔离性的简单定义:一个事务开始时,只能"看见"已经提交的事务所做的修改。换句话说,一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的。这个级别有时候也叫做不可重复读(nonrepeatable read),因为两次执行同样的查询,可能会得到不一样的结果。
可重复读(RR,repeatable read)
RR级别解决了脏读问题并和MVCC一起解决"幻读"问题,该级别保证了在同一个事物中多次读取同样记录的结果是一致的。
该级别是MySQL的默认事务隔离级别。
可串行化(Serializable)
serializable是最高的隔离级别,它通过强制事务串行执行,避免了前面说的"幻读"问题。简单来说,serializable会在读取每一行数据上都加锁,所以可能导致大量的超时和锁争用问题。实际应用也很少用到这个隔离级别。只有在非常需要确保数据的一致性而且可以接受没有并发的情况下,才考虑采用该级别。
| 隔离级别 | 脏读可能性 | 不可重复读可能性 | 幻读可能性 | 加锁读 |
|---|
| RU |
Yes |
Yes |
Yes |
No |
| RC |
No |
Yes |
Yes |
No |
| RR |
No |
No |
Yes |
No |
| Serializable |
No |
No |
No |
Yes |
在MySQL中,可以通过tx_islation参数来查看:
1
2
3
4
5
6
7
8
|
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set, 1 warning (0.00 sec)
|
这四种级别通过transction_isolation参数来修改:
1
2
3
4
5
6
7
8
9
|
-- 支持 session 和 global 级别设置
set transaction_isolation='READ-UNCOMMITTED';
set transaction_isolation='READ-COMMITTED';
set transaction_isolation='REPEATABLE-READ';
set transaction_isolation='SERIALIZABLE';
-- 也支持配置文件设置 vim /etc/my.cnf
[mysqld]
transaction_isolation=READ-COMMITTED
|
上述四种隔离级别最常用的就是RU和RC,所以,我们接下来就单独来研究一下这两种隔离级别。
RR
RR保证了在同一个事物中多次读取同样记录的结果是一致的。我们来个示例演示一下。
首先保证自动提交关闭和隔离级别设置为RR。

然后,我们在左侧终端执行一个事务,右侧终端也同样执行一个事务,两个事务操作同一行记录,观察:

通过上述示例的结果对比,发现现象符合定义:RR保证了在同一个事物中多次读取同样记录的结果是一致的,这样避免了同一行数据出现"幻读"现象。
RC
首先保证自动提交关闭和隔离级别设置为RC。

然后,我们在左侧终端执行一个事务,右侧终端也同样执行一个事务,两个事务操作同一行记录,观察:

由右侧终端的结果可以证明之前的定义没错,右侧终端能立即读到左侧终端事务已提交的结果,但这因此产生了"幻读"现象,因为右侧查询结果随着左侧终端的更改而无法确定拿到的值到底是什么!
那在RC级别如何保证读一致性的问题?通常在查询时添加for update语句来保证读一致性,也就是我读该行数据的时候,加个锁,那别人也就无法修改这行数据,直到我读完后,别人才能修改这行数据。

上述的超时时间通过innodb_lock_wait_timeout参数可以查询到:
1
2
3
4
5
6
7
|
mysql> select @@innodb_lock_wait_timeout;
+----------------------------+
| @@innodb_lock_wait_timeout |
+----------------------------+
| 50 |
+----------------------------+
1 row in set (0.00 sec)
|
最后,在使用完for update后,一定要commit,否则容易产生大量的锁等待。
锁
上面的RC级别的演示中,我们也引出了锁的概念。
在InnoDB的事务中,“锁"和"隔离级别"一起保证了事务的一致性和隔离性,当然也有其他技术参数,比如redo也有参与。
在MySQL中,有很多种锁,包括悲观锁、乐观锁、排它锁、GAP、Next-Lock等等。
RC中用的悲观锁,何为悲观?就是总有刁民想害朕的那种感觉。RC中,读数据的时候,总觉得别人可能也来操作这行数据,那不行,没安全感,怎么办?加把锁,我搞完你再来………
另外,这里还需要补充一把死锁。
死锁是指两个或者多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环的现象。当多个事务试图以不同的顺序锁定资源时,就可能产生死锁;多个事务同时锁定同一资源时,也会产生死锁。死锁发生后,只有部分或者完全回滚其中一个事务,才能打破死锁。
为了解决死锁问题,InnoDB引擎实现了各种死锁检测和死锁超时机制,当检测到由死锁的循环依赖产生时,会立即返回一个错误;另一种处理方式就是当查询的时间达到锁等待的超时时间的设定后放弃锁请求,但这种方式不太好。InnoDB目前处理死锁的方法时,将持有最少行级排它锁的事务进行回滚。
InnoDB和MyISAM的区别
- innodb支持行级锁,而myisam仅支持表级锁
- innodb支持事务,而myisam不支持事务
- innodb支持热备份
pymysql
在Python2.x中,Python连接MySQL服务器使用mysqldb库,但是它只支持到Python2.x,在Python3.x中由pymysql模块代替。
PyMySQL 遵循 Python 数据库 API v2.0 规范,并包含了 pure-Python MySQL 客户端库。
Install
pip install pymysql
pip install -i https://pypi.doubanio.com/simple pymysql==1.0.2
准备
在正式操作前,这里默认你有了一个良好的环境,包括MySQL服务,Python环境。
建立连接
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import pymysql
conn = pymysql.connect(
host='localhost', # 连接的服务器ip
user='username', # 用户名
password='password', # 密码
database='day31', # 你想连接的数据库
charset='utf8' # 指定字符编码,不要加杠,如:utf-8
)
cursor = conn.cursor() # 获取游标
# 一顿操作后......别忘了
cursor.close() # 关闭游标
conn.close() # 关闭连接对象
|
创建数据库
首先,我们要手动在MySQL中创建表:
1
2
3
4
5
|
create table info(
id int primary key auto_increment,
user varchar(10) not null,
pwd varchar(10)
);
|
快速上手
增
法1
1
2
3
4
5
6
7
|
cursor = conn.cursor() # 获取游标
cursor.execute('insert into info (user,pwd) values ("张开腿", "zhangkai1");')
conn.commit()
cursor.close() # 关闭游标
conn.close() # 关闭连接对象
|
相当于我们写原生的SQL语句。 法2
1
2
3
4
5
6
7
8
|
cursor = conn.cursor() # 获取游标
sql = 'insert into info (user,pwd) values ("%s", "%s");' % ('张开2', 'zhangkai2')
cursor.execute(sql)
conn.commit()
cursor.close() # 关闭游标
conn.close() # 关闭连接对象
|
我们把sql语句提出来,用Python处理一下,相当于拼接字符串。 法3
1
2
3
4
5
6
7
8
|
cursor = conn.cursor() # 获取游标
sql = 'insert into info (user,pwd) values (%s, %s);'
cursor.execute(sql, ('张开3', 'zhangkai3')) # 第二个参数可以是元组也可以是列表
conn.commit()
cursor.close() # 关闭游标
conn.close() # 关闭连接对象
|
我们将值放到元组(或列表)中,交给execute帮我们处理,其实,execute本质上也是拼接字符串,然后再执行。
注意,在sql语句中,%s那里不要使用"%s"这种形式,因为MySQL会把引号当成普通的数据写入到数据库中。不信来看:
1
2
3
4
5
6
7
8
|
cursor = conn.cursor() # 获取游标
sql = 'insert into info (user,pwd) values ("%s", "%s");'
cursor.execute(sql, ['张开4', 'zhangkai4']) # 这里我们使用列表进行验证
conn.commit()
cursor.close() # 关闭游标
conn.close() # 关闭连接对象
|
来看输出结果:
1
2
3
4
5
6
|
mysql> select * from info where id = 4;
+----+-----------+------------+
| id | user | pwd |
+----+-----------+------------+
| 4 | '张开4' | 'zhangkai4 |
+----+-----------+------------+
|
很明显,带着引号的不是我们想要的结果。
法4
不能总是一条一条插入,那岂不是费老劲了啊,能不能一次插入多条呢?答案是可以的:
1
2
3
4
5
6
7
8
9
10
|
cursor = conn.cursor() # 获取游标
info_list = [('张开{}'.format(i), 'zhangkai{}'.format(i)) for i in range(5, 101)]
sql = 'insert into info (user,pwd) values (%s, %s);'
cursor.executemany(sql, info_list)
conn.commit()
cursor.close() # 关闭游标
conn.close() # 关闭连接对象
|
生成器可能是更优的选择:
1
2
3
4
5
6
7
8
9
10
|
cursor = conn.cursor() # 获取游标
info_list = (('张开{}'.format(i), 'zhangkai{}'.format(i)) for i in range(101, 201))
sql = 'insert into info (user,pwd) values (%s, %s);'
cursor.executemany(sql, info_list)
conn.commit()
cursor.close() # 关闭游标
conn.close() # 关闭连接对象
|
删
删改查没啥好说,都是写SQL语句就完了。
1
2
3
4
5
6
7
|
cursor = conn.cursor()
sql = 'delete from info where user = %s;'
cursor.execute(sql, '张开200')
conn.commit()
cursor.close()
conn.close()
|
改
1
2
3
4
5
6
7
8
|
cursor = conn.cursor()
sql = 'update info set pwd = %s where user = %s'
cursor.execute(sql, ('张开一九九', '张开199'))
conn.commit()
cursor.close()
conn.close()
|
查
1
2
3
4
5
6
7
8
9
|
cursor = conn.cursor() # 获取游标
sql = 'select id, user, pwd from info;'
rows = cursor.execute(sql)
print(rows)
conn.commit()
cursor.close() # 关闭游标
conn.close() # 关闭连接对象
|
直接打印返回值rows,得到的是所有记录的条数。
想要得到记录内容可以使用fetch系列:
1
2
3
4
5
6
7
8
9
10
|
cursor = conn.cursor() # 获取游标
sql = 'select id, user, pwd from info;'
cursor.execute(sql)
print(cursor.fetchone())
print(cursor.fetchone())
conn.commit()
cursor.close() # 关闭游标
conn.close() # 关闭连接对象
|
fetchone一条一条取。
1
2
3
4
5
6
7
8
9
10
|
cursor = conn.cursor() # 获取游标
sql = 'select id, user, pwd from info;'
cursor.execute(sql)
# print(cursor.fetchmany()) # 默认取第一条
print(cursor.fetchmany(3)) # 默认从开始取指定条数
conn.commit()
cursor.close() # 关闭游标
conn.close() # 关闭连接对象
|
fetchmany默认从开始取指定条数。
1
2
3
4
5
6
7
8
9
|
cursor = conn.cursor() # 获取游标
sql = 'select id, user, pwd from info;'
cursor.execute(sql)
print(cursor.fetchall())
conn.commit()
cursor.close() # 关闭游标
conn.close() # 关闭连接对象
|
fetchall取所有。
pymysql.cursors.DictCursor
如果你每次看打印结果的话,结果都是以元组套元组的形式返回。
1
2
3
|
cursor = conn.cursor()
cursor.execute('select * from info;')
print(cursor.fetchmany(2)) # ((1, '张开腿', 'zhangkai1'), (2, '张开2', 'zhangkai2'))
|
我们也可以控制返回形式,比如以列表套字典的形式:
1
2
3
4
5
6
|
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 需要在实例化游标对象的时候,传个参数
cursor.execute('select * from info;')
print(cursor.fetchmany(2)) # [{'id': 1, 'user': '张开腿', 'pwd': 'zhangkai1'}, {'id': 2, 'user': '张开2', 'pwd': 'zhangkai2'}]
conn.commit()
cursor.close()
conn.close()
|
scroll
先来看相对定位,根据当前的游标位置移动。
1
2
3
4
5
6
7
8
9
10
|
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute('select * from info;')
print(cursor.fetchone()) # 此时游标在第一行
cursor.scroll(1, 'relative') # 光标按照相对位置移动一位,此时在2
print(cursor.fetchone()) # 取第3行记录
conn.commit()
cursor.close()
conn.close()
|
接下来看绝对定位:
1
2
3
4
5
6
7
8
9
10
|
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute('select * from info;')
print(cursor.fetchone()) # 此时游标在第一行
cursor.scroll(1, 'absolute') # 光标按照绝对位置移动一位,此时在1
print(cursor.fetchone()) # 取第2行记录
conn.commit()
cursor.close()
conn.close()
|
SQL注入
什么是SQL注入呢?先来看个示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import pymysql
def connection(user=None, password=None, database=None, host='localhost', charset='utf8'):
""" 建立连接并将游标返回 """
conn = pymysql.connect(
host=host,
user=user,
password=password,
database=database,
charset=charset
)
return conn.cursor()
def login():
user = input('username: ').strip()
pwd = input('password: ').strip()
sql = 'select user, pwd from info where user= "%s" and pwd = "%s";' % (user, pwd)
print(sql)
result = cursor.execute(sql) # 查询结果自带布尔值,查询成功返回1,查询失败返回0
if result:
print('login successful')
else:
print('login error')
if __name__ == '__main__':
cursor = connection(user='root', password='root!admin', database='day31')
login()
conn.commit()
cursor.close()
conn.close()
|
在上述的登录示例中了,我们输入正确的用户名和密码肯定都没问题:
username: 张开2
password: zhangkai2
select user, pwd from info where user="张开2" and pwd = "zhangkai2";
login successful
但是,如果有人在输入用户名和密码时,做了手脚:
username: 张开2"; -- aswesasa
password:
select user, pwd from info where user="张开2"; -- aswesasa" and pwd = "";
login successful
可以看到,再输入用户名的时候,在用户名后面跟了"; -- aswesasa这些东西,再看打印的SQL语句,不难发现。判断语句现在变成了,只要是用户名对了就算成功。后面的密码部分,被--注释掉了,你写啥都无所谓了。
这就是SQL注入的方式之一。另外一种情况,就是用户名和密码都有问题,也能登录成功:
username: xxx" or 1 -- xxx
password:
select user, pwd from info where user="xxx" or 1 -- xxx" and pwd = "";
login successful
当用户名错误和密码错误时,依然登录成功。什么原因呢?由打印的SQL语句可以看到,用户名错了不要紧,我们使用or语句,后跟一个真值,这样用户名无论如何都会成立。当然,后面的密码部分已经被注释掉了。
以上就是SQL注入的两种方式,那么怎么解决呢?解决办法,就是我们不手动的拼接SQL字符串,而是交给pymysql来完成:
1
2
3
4
5
6
7
8
9
|
def login():
user = input('username: ').strip()
pwd = input('password: ').strip()
sql = 'select user, pwd from info where user = %s and pwd = %s;' # 注意,%s这里要去掉引号,因为pymysql会帮我们加上的
result = cursor.execute(sql, (user, pwd))
if result:
print('login successful')
else:
print('login error')
|
上述代码修改后,无论我们输入什么,pymysql都会把输入内容拼成普通的字符串,然后校验。所以,以后碰到这种拼接SQL语句的事情,都交给pymysql来做,而不是我们手动的拼接。
事物
也就是回滚机制,将一连串的执行当成一个原子性的操作,要么全部执行成功,要么全部执行失败。
我们演示执行两条命令,一条执行成功,一条执行失败,执行失败的话,就回滚到之前最开始的状态。
先来看正常的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql1 = 'insert into info(user, pwd) values(%s, %s);'
sql2 = 'insert into info(user, pwd) values(%s, %s);'
try:
cursor.execute(sql1, (("小王", "123")))
cursor.execute(sql2, (("小李", "123")))
except Exception as e:
print(e)
conn.rollback()
cursor.execute('select * from info where user like %s;', '小%')
print(cursor.fetchall()) # [{'id': 210, 'user': '小王', 'pwd': '123'}, {'id': 211, 'user': '小李', 'pwd': '123'}]
conn.commit()
cursor.close()
conn.close()
|
如果try语句中的两个SQL语句都执行成功,则最终执行成功。
我们把刚才插入的删掉再测试。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql1 = 'insert into info(user, pwd) values(%s, %s);'
sql2 = 'insert into info(user, pwd) values(%s, %s);'
cursor.execute('delete from info where user like "小_"')
conn.commit()
try:
cursor.execute(sql1, (("小王", "123")))
cursor.execute(sql2, (("小李", "123")))
raise 1
except Exception as e:
print(e) # exceptions must derive from BaseException
conn.rollback()
cursor.execute('select * from info where user like %s;', '小%')
print(cursor.fetchall()) # ()
conn.commit()
cursor.close()
conn.close()
|
可以看到,在一串的执行中,遇到了错误,就回滚到之前的状态。
存储过程
接下来来看在pymysql中使用存储过程。
创建存储过程
1
2
3
4
5
6
|
delimiter\\
CREATE PROCEDURE t1 ()
BEGIN
SELECT * FROM t1;
END\\
delimiter ;
|
使用存储过程
1
2
3
4
5
6
7
|
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.callproc('t1')
conn.commit()
print(cursor.fetchall())
cursor.close()
conn.close()
|
疯狂练习题
准备数据:
- world.sql:https://www.cnblogs.com/Neeo/articles/13561090.html
- school.sql:https://www.cnblogs.com/Neeo/articles/13565900.html
表结构如下:

练习题:
1、自行创建测试数据
2、查询“生物”课程比“物理”课程成绩高的所有学生的学号;
3、查询平均成绩大于60分的同学的学号和平均成绩;
4、查询所有同学的学号、姓名、选课数、总成绩;
5、查询姓“李”的老师的个数;
6、查询没学过“叶平”老师课的同学的学号、姓名;
7、查询学过“001”并且也学过编号“002”课程的同学的学号、姓名;
8、查询学过“叶平”老师所教的所有课的同学的学号、姓名;
9、查询课程编号“002”的成绩比课程编号“001”课程低的所有同学的学号、姓名;
10、查询有课程成绩小于60分的同学的学号、姓名;
11、查询没有学全所有课的同学的学号、姓名;
12、查询至少有一门课与学号为“001”的同学所学相同的同学的学号和姓名;
13、查询至少学过学号为“001”同学所选课程中任意一门课的其他同学学号和姓名;
14、查询和“002”号的同学学习的课程完全相同的其他同学学号和姓名;
15、删除学习“叶平”老师课的SC表记录;
16、向SC表中插入一些记录,这些记录要求符合以下条件:①没有上过编号“002”课程的同学学号;②插入“002”号课程的平均成绩;
17、按平均成绩从低到高显示所有学生的“语文”、“数学”、“英语”三门的课程成绩,按如下形式显示: 学生ID,语文,数学,英语,有效课程数,有效平均分;
18、查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分;
19、按各科平均成绩从低到高和及格率的百分数从高到低顺序;
20、课程平均分从高到低显示(现实任课老师);
21、查询各科成绩前三名的记录:(不考虑成绩并列情况)
22、查询每门课程被选修的学生数;
23、查询出只选修了一门课程的全部学生的学号和姓名;
24、查询男生、女生的人数;
25、查询姓“张”的学生名单;
26、查询同名同姓学生名单,并统计同名人数;
27、查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列;
28、查询平均成绩大于85的所有学生的学号、姓名和平均成绩;
29、查询课程名称为“数学”,且分数低于60的学生姓名和分数;
30、查询课程编号为003且课程成绩在80分以上的学生的学号和姓名;
31、求选了课程的学生人数
32、查询选修“杨艳”老师所授课程的学生中,成绩最高的学生姓名及其成绩;
33、查询各个课程及相应的选修人数;
34、查询不同课程但成绩相同的学生的学号、课程号、学生成绩;
35、查询每门课程成绩最好的前两名;
36、检索至少选修两门课程的学生学号;
37、查询全部学生都选修的课程的课程号和课程名;
38、查询没学过“叶平”老师讲授的任一门课程的学生姓名;
39、查询两门以上不及格课程的同学的学号及其平均成绩;
40、检索“004”课程分数小于60,按分数降序排列的同学学号;
41、删除“002”同学的“001”课程的成绩;
参考答案:https://www.cnblogs.com/Neeo/articles/13599973.html
疯狂面试题
参考:https://www.cnblogs.com/Neeo/articles/11303149.html
三、MongoDB
简介
关于NoSQL
NoSQL(Not Only SQL)泛指非关系型的数据库。
我们通过下表来简单了解NoSQL和SQL的区别:
| SQL | NoSQL |
|---|
| SQL是关系数据库管理系统(RDBMS) |
NoSQL是非关系数据库系统 |
| SQL数据库需要预先开发一个架构,并且所有数据都根据该架构存储 |
NoSQL数据库具有动态架构 |
| 在SQL中,数据以表的形式存储在数据库中 |
在NoSQL中,数据以对象、文档、图形、键值对等形式存储数据 |
| SQL使用标准化SQL语法命令来管理数据 |
NoSQL使用非标准化语句来管理数据 |
关于MongoDB
MongoDB 是由C++语言编写并基于分布式文件存储的开源数据库。
MongoDB 是一款介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的NOSQL数据库。它面向文档存储,而且安装和操作起来都比较简单和容易,而且它支持各种流行编程语言进行操作,如Python,Node.js,Java,C++,PHP,C#,Ruby等。
目前在大数据、内容管理、持续交付、移动应用、社交应用、用户数据管理、数据中心等领域皆有广泛被使用。
MongoDB的特点
MongoDB具有以下特点:
- 高性能,MongoDB提供高性能的数据持久化,尤其是支持嵌入式数据模型,减少数据库系统级别的I/O操作,并支持索引加速查询。
- 丰富的语言查询类型,MongoDB支持丰富的查询语言来支持读写操作,以及数据汇总、文本搜索和地理空间位置索引。
- 高可用性,MongoDB的复制工具,提供自动故障转移和数据冗余。
- 水平可扩展性,MongoDB提供了分片机制来提高其扩展性能。
- 支持多种存储引擎,WiredTiger存储引擎、MMAPv1存储引擎和InMemory存储引擎。
- 面向文档,我们知道,关系型数据库以表和记录行的形式存储数据,但是在MongoDB中,是以文档的形式存储数据。区别在于,文档要比数据表的行更加灵活。因为文档可以是多层次的,它(文档)鼓励你将属于一个逻辑实体的数据保存在同一个文档中,而不是散落在各个表的不同行中,这样查询效率很高,因为我们无需连接其他的表。
MongoDB是如何组织数据的
为了更好的理解MongoDB是如何组织数据的,我们可以通过逻辑设计物理设计两个方面来观察。
逻辑设计
我们可以把MongoDB与关系型数据做个客观对比:
| Relational DB | MongoDB |
|---|
| 数据库(database) |
库(database) |
| 表(tables) |
集合(collection) |
| 行(rows) |
文档(documents) |
| 列(columns) |
字段/键(fields) |
| 主键(primary key) |
对象ID(objectId) |
| 索引(index) |
索引(index) |
一个MongoDB实例(一个MongoDB进程)中,包含多个数据库,每个数据库中包含多个集合,每个集合中存储多个文档,每个文档中包含多个字段,且库与库之间、集合与集合之间、文档与文档之间都是是相互独立的。
那么你一定很好奇文档是如何存储的,这就要来介绍MongoDB的物理设计了。
物理设计
多个MongoDB实例可以组成一个复制集,用于提高数据的安全性;多个复制集又可以组成一个集群,用于横向扩展,在集群中,每个复制集可以理解为一个节点,不同的节点存储的数据不同。而文档是以bson的格式存储在集群的某个节点中。
那么什么是bson呢?MongoDB中的文档被设计为标准的json字符串,这样便于与编程语言进行通信和操作。但json也有其自身的缺陷,比如json结构过大,会导致数据遍历较慢。
后来有了bson作为MongoDB的物理存储结构,bson(Binary Serialized Document Format)是一种二进制形式的存储格式,可以理解为二进制形式的json,它和json一样支持文档对象和数据对象,同时它还支持Date和BinDate类型的数据。bson提高了json的遍历速度,在内部操作也更为简单。
MongoDB的版本选择
截至到本书编写时,MongoDB最新版本已经到了MongoDB4.4.3,但市场上的主流版本是3.4和3.6两个版本,所以,这后续所有的示例及配置都以3.6为主。
PS:至于小版本都无所谓了啊,比如3.6.12还是3.6.21都行!!!
各平台安装MongoDB
安装包下载
无论你下载哪个平台的MongoDB安装包,都可以在这个链接:https://www.mongodb.com/try/download/community选择择下载:

Windows平台安装MongoDB
win10 + mongodb3.6.12
首先,在 MongoDB2.2 版本后已经不再支持 Windows XP 系统。
另外,MongoDB为Windows平台提供msi和zip两种安装方式:
msi方式,一路一下一步,方便快捷,但只推荐MongoDB4.0及以上版本采用msi方式安装,因为MongoDB4.x版本对msi安装方式进行了优化,随着提示就可以完成配置,但3.x和更低的版本则仍旧需要在安装完毕后,手动做配置,所以低版本不推荐msi方式。zip方式,解压即安装,可以将其安装到任意目录,后续都可以手动进行配置,比较灵活,推荐采用这种方式进行安装。
install
将zip包进行解压,其实解压后的目录就是MongoDB的安装目录,我这里已解压并重命名,并且手动在这个目录内创建:
data目录保存数据文件。log目录保存日志文件。mongodb.conf文件,是MongoDB的配置文件。

在bin目录内,我们暂时需要了解两个文件:
1
2
|
mongo.exe # MongoDB客户端软件
mongod.exe # MongoDB服务端软件
|
配置环境变量
这一步的目的是,后续我们可以直接通过终端操作MongoDB。
步骤是此电脑–鼠标右键选择属性–高级系统设置–环境变量–系统变量选项,找到Path,选择新建,将C:\mongodb\bin目录添加进去,如下图:

最后选择保存即可。
编写配置文件
编写配置文件的目的是便于后续以配置文件的方式启动MongoDB服务。
打开mongodb.conf文件,写入如下内容,然后保存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# 系统日志相关
systemLog:
destination: file # 使用文件存储日志
path: C:\mongodb\log\mongodb.log # 日志位置
logAppend: true # 是否以追加的形式记录日志
# 数据相关
storage:
journal: # 回滚日志
enabled: true
dbPath: C:\mongodb\data # 数据存储目录
# 网络配置相关
net:
port: 27017 # 默认端口
bindIp: 127.0.0.1 # 绑定ip, 多个ip以逗号分隔
|
上面配置中的bindIp设置为127.0.0.1表示只能本地访问MongoDB,如果需要远程访问,还需要设置本机IP,然后重启服务。
将MongoDB服务添加Windows的服务
这一步的目的是将来在终端中通过net来管理MongoDB。
以管理员的身份打开终端,输入:
1
|
mongod --config C:\mongodb\mongodb.conf --install
|
上面的命令执行成功后,此时Windows的服务中就有了MongoDB的服务了。

你可以在Windows的服务中管理MongoDB,比如设置开机启动、手动等设置。
而我们现在则可以在终端中使用net来start和stop MongoDB了。

注意,只有以管理员身份打开的终端才能执行net命令。
测试MongoDB是否按照成功
前提是MongoDB服务正在运行。
终端(可以是非管理员身份打开的终端)输入mongo即可开启MongoDB客户端,输入相应命令来使用MongoDB服务了:

OK,安装完毕。
centos中安装MongoDB
cenots7.9 + mongodb3.6.12
系统要求
- Redhat或者centos6.2以上系统,当然,centos7以上都无所谓了。
- 系统开发包完整,因为MongoDB是C++编写,依赖C的环境
- IP地址和hosts文件解析正常
- iptables防火墙和SElinux关闭
- 关闭大叶内存机制
关于大页内存:https://linux.cn/article-9450-1.html
centos系统关闭大页内存
vim /etc/rc.local追加如下内容,然后重新运行一下sh /etc/rc.local即可:
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@cs software]# pwd
/opt/software
[root@cs software]# vim /etc/rc.local
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
[root@cs software]# sh /etc/rc.local
|
完事检查是否设置成功,都是never即可:
1
2
3
4
|
[root@cs software]# cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never]
[root@cs software]# cat /sys/kernel/mm/transparent_hugepage/defrag
always madvise [never]
|
PS:rc.local控制开机自启动。
注意,仅适用于centos系统,其他系统,如Ubuntu等参考官档
由于MongoDB通常都以非root用户操作,所以后续的操作示例中,如何判断是以什么用户操作的呢?
1
2
3
|
# 可以通过示例中的 "#" 和 "$" 来判断
[root@cs software]# # 这是root用户的操作
[mongod@cs mongodb]$ # 这是非root用户的操作
|
安装必要的依赖
1
|
yum install libcurl openssl gcc -y
|
创建mongod用户
MongoDB建议使用非root用户进行管理,所以我们创建一个mongod用户/用户组来管理MongoDB:
1
2
3
4
5
6
7
|
[root@cs software]# useradd mongod
[root@cs software]# passwd mongod
Changing password for user mongod.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
|
记录下,用户名是mongod,密码是1234。
注意,此时我们还是以root用户在操作。
install
1
|
[root@cs software]# mkdir -p /data/mongodb_data/27017/{conf,log,data}
|
见名知意,conf是配置文件目录,log是日志目录,data是数据目录。而为了后续搭建MongoDB复制集和集群,这里的数据目录以端口号作为分割,一个端口号代表一个MongoDB实例。
[root@cs software]# pwd
/opt/software
[root@cs software]# wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-3.6.12.tgz
[root@cs software]# ls
mongodb-linux-x86_64-rhel70-3.6.12.tgz redis
1
2
3
|
[root@cs software]# tar xf mongodb-linux-x86_64-rhel70-3.6.12.tgz
[root@cs software]# ls
mongodb-linux-x86_64-rhel70-3.6.12 mongodb-linux-x86_64-rhel70-3.6.12.tgz redis
|
解压后的目录内只有bin目录对我们来说是有用的:
1
2
3
4
5
|
[root@cs software]# ls mongodb-linux-x86_64-rhel70-3.6.12
bin LICENSE-Community.txt MPL-2 README THIRD-PARTY-NOTICES
[root@cs software]# ls mongodb-linux-x86_64-rhel70-3.6.12/bin/
bsondump mongo mongodump mongofiles mongoperf mongorestore mongostat
install_compass mongod mongoexport mongoimport mongoreplay mongos mongotop
|
我们将MongoDB的bin目录从新拷贝到/opt/software目录作为MongoDB的安装目录:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
[root@cs software]# cp -r mongodb-linux-x86_64-rhel70-3.6.12/bin/ /opt/software/mongodb
[root@cs software]# ll mongodb/
total 310768
-rwxr-xr-x. 1 mongod mongod 13598456 Jan 13 11:50 bsondump
-rwxr-xr-x. 1 mongod mongod 7770 Jan 13 11:50 install_compass
-rwxr-xr-x. 1 mongod mongod 33775680 Jan 13 11:50 mongo # client
-rwxr-xr-x. 1 mongod mongod 59656584 Jan 13 11:50 mongod # server
-rwxr-xr-x. 1 mongod mongod 14463896 Jan 13 11:50 mongodump # 备份恢复
-rwxr-xr-x. 1 mongod mongod 14024312 Jan 13 11:50 mongoexport # 备份恢复
-rwxr-xr-x. 1 mongod mongod 13896704 Jan 13 11:50 mongofiles
-rwxr-xr-x. 1 mongod mongod 14165112 Jan 13 11:50 mongoimport # 备份恢复
-rwxr-xr-x. 1 mongod mongod 59161264 Jan 13 11:50 mongoperf
-rwxr-xr-x. 1 mongod mongod 18735472 Jan 13 11:50 mongoreplay # 备份恢复
-rwxr-xr-x. 1 mongod mongod 14499216 Jan 13 11:50 mongorestore # 备份恢复
-rwxr-xr-x. 1 mongod mongod 34249592 Jan 13 11:50 mongos
-rwxr-xr-x. 1 mongod mongod 14170648 Jan 13 11:50 mongostat
-rwxr-xr-x. 1 mongod mongod 13796144 Jan 13 11:50 mongotop
|
现在,我们需要记住两个目录:
1
2
3
4
5
6
|
# MongoDB软件的安装位置
[root@cs mongodb]# pwd
/opt/software/mongodb
# MongoDB的数据及log、配置文件目录
[root@cs mongodb]# ls /data/mongodb_data/27017
conf data log
|
并且对这两个目录进行授权:
1
2
|
[root@cs mongodb]# chown -R mongod:mongod /opt/software/mongodb
[root@cs mongodb]# chown -R mongod:mongod /data/mongodb_data/27017
|
因为将来我们需要使用mongod用户来管理MongoDB,所以,只需要设置用户的私有变量即可。首先要切换到mongod用户,然后再设置:
1
2
3
4
5
6
7
8
|
[mongod@cs mongodb]# su - mongod
Password:
Last login: Wed Jan 13 11:57:48 CST 2021 on pts/1
[mongod@cs ~]$ vim .bash_profile
export PATH=/opt/software/mongodb:$PATH
[mongod@cs ~]$ source .bash_profile
|
注意,此时我们是mongod用户来操作的。
1
2
3
4
|
[mongod@cs ~]$ mongod --dbpath=/data/mongodb_data/27017/data --logpath=/data/mongodb_data/27017/log/mongodb.log --logappend --port=27017 --fork
about to fork child process, waiting until server is ready for connections.
forked process: 8287
child process started successfully, parent exiting
|
其中:
--dbpath是数据存储目录。--logpath是日志存储目录。--logappend以追加的形式记录日志。--port,端口号。--fork后台运行。
创建配置文件
vim /data/mongodb_data/conf/mongodb.conf:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# 系统日志相关
systemLog:
destination: file # 使用文件存储日志
path: "/data/mongodb_data/27017/log/mongodb.log" # 日志位置
logAppend: true # 是否以追加的形式记录日志
# 数据相关
storage:
journal: # 回滚日志
enabled: true
dbPath: "/data/mongodb_data/27017/data/" # 数据存储目录
# 进程相关
processManagement:
fork: true # 后台运行
# 网络配置相关
net:
port: 27017 # 默认端口
bindIp: 127.0.0.1,10.0.0.200 # 绑定ip, 多个ip以逗号分隔
|
开启/关闭MongoDB
1
2
|
[mongod@cs ~]$ mongod -f /data/mongodb_data/27017/conf/mongodb.conf --shutdown
[mongod@cs ~]$ mongod -f /data/mongodb_data/27017/conf/mongodb.conf
|
使用systemd管理MongoDB的配置
使用root用户创建vim /etc/systemd/system/mongod.service。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
[mongod@cs mongodb]$ su root
Password:
[root@cs mongodb]# vim /etc/systemd/system/mongod.service
[Unit]
Description=mongodb
After=network.target remote-fs.target nss-lookup.target
[Service]
User=mongod
Type=forking
ExecStart=/opt/software/mongodb/mongod --config /data/mongodb_data/27017/conf/mongodb.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/opt/software/mongodb/mongod --config /data/mongodb_data/27017/conf/mongodb.conf --shutdown
PrivateTmp=true
[Install]
WantedBy=multi-user.target
|
现在,就可以使用systemctl来管理MongoDB了:
1
|
systemctl start/restart/stop/status mongod
|
现在,就有两套命令可以管理MongoDB的启停了,以root用户使用:
1
|
systemctl start/restart/stop/status mongod
|
使用普通用户mongod启停MongoDB:
1
2
|
[mongod@cs ~]$ mongod -f /data/mongodb_data/27017/conf/mongodb.conf --shutdown
[mongod@cs ~]$ mongod -f /data/mongodb_data/27017/conf/mongodb.conf
|
当然,你也可以mongod得身份使用systemctl来管理MongoDB,只需要根据提示输入密码就可以了:
1
2
3
4
5
6
7
|
[mongod@cs ~]$ systemctl restart mongod
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to manage system services or units.
Authenticating as: root # 需要root身份才能使用 systemctl
Password: # 输入root用的密码就可以了
==== AUTHENTICATION COMPLETE ===
[mongod@cs ~]$
|
测试,是否安装成功
无论是哪个用户启动了MongoDB服务,我们都以普通用户操作MongoDB,在任意路径下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
[mongod@cs mongodb]$ mongo
MongoDB shell version v3.6.12
connecting to: mongodb://127.0.0.1:27017/?gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("4b23a3f9-8942-43c7-ac45-ed94dbf2bae6") }
MongoDB server version: 3.6.12
Welcome to the MongoDB shell.
For interactive help, type "help".
For more comprehensive documentation, see
http://docs.mongodb.org/
Questions? Try the support group
http://groups.google.com/group/mongodb-user
Server has startup warnings:
2021-01-13T15:20:31.612+0800 I CONTROL [initandlisten]
2021-01-13T15:20:31.612+0800 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database.
2021-01-13T15:20:31.612+0800 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted.
2021-01-13T15:20:31.612+0800 I CONTROL [initandlisten]
> show databases;
admin 0.000GB
config 0.000GB
local 0.000GB
> use admin
switched to db admin
> show tables;
system.version
|
如果是复制集环境或者集群环境,可以通过端口号来指定启动不同的MongoDB实例:
1
|
[mongod@cs mongodb]$ mongo --port 27017
|
数据类型和运算符
为了更好的学习MongoDB的相关操作,这里先了解MongoDB中的常用运算符和常用的数据类型。
数据类型
| Type | 描述 |
|---|
| ObjectID |
用于存储文档的ID,相当于主键 |
| String |
字符串是最常用的数据类型,MongoDB中的字符串必须是UTF-8编码 |
| Symbol |
与字符串用法相同,常用于某些使用特殊符号的语言 |
| Integer |
整数类型用于存储数值,整数可以是32位,也可以是64位,这取决于你的系统 |
| Double |
MongoDB将所有浮点类型的数据以双精度类型进行存储 |
| Boolean |
布尔类型用于存储布尔值(小写的true和false) |
| Arrays |
将数组、列表或多个值存储到一个键 |
| Timestamp |
时间戳时间,用于记录文档何时被修改或创建 |
| Object |
用于嵌入文档中,相当于嵌套结构是另一个json |
| Null |
空值,相当于Python中的None |
| Binary data |
二进制数据 |
| Code |
用于将JavaScript代码存储到文档中 |
| Regular expression |
正则表达式 |
运算符
更多运算符参考官档:https://docs.mongodb.com/v3.6/reference/operator/
在MongoDB的各种操作中,运算符无处不在,这里将列出常用的运算符,便于查找。
以下整理自MongoDB3.6版本的官档手册:https://docs.mongodb.com/v3.6/reference/operator/
比较查询运算符
https://docs.mongodb.com/manual/reference/operator/query/#comparison
| 名称 | 描述 |
|---|
$eq |
匹配等于指定值的值。 |
$gt |
匹配大于指定值的值。 |
$gte |
匹配大于或等于指定值的值。 |
$in |
匹配数组中指定的任何值。 |
$lt |
匹配小于指定值的值。 |
$lte |
匹配小于或等于指定值的值。 |
$ne |
匹配所有不等于指定值的值。 |
$nin |
不匹配数组中指定的任何值。 |
逻辑查询运算符
https://docs.mongodb.com/manual/reference/operator/query/#logical
| 名称 | 描述 |
|---|
$and |
用逻辑联接查询子句AND返回与两个子句条件都匹配的所有文档。 |
$not |
反转查询表达式的效果,并返回与查询表达式不匹配的文档。 |
$nor |
用逻辑联接查询子句NOR将返回两个子句均不匹配的所有文档。 |
$or |
用逻辑联接查询子句OR将返回符合任一子句条件的所有文档。 |
元素查询运算符
https://docs.mongodb.com/manual/reference/operator/query/#element
数组查询运算符
https://docs.mongodb.com/manual/reference/operator/query/#array
投影运算符
https://docs.mongodb.com/v3.6/reference/operator/query/#projection-operators
字段更新运算符
https://docs.mongodb.com/v3.6/reference/operator/update-field/#field-update-operators
数组更新运算符
https://docs.mongodb.com/v3.6/reference/operator/update-array/#array-update-operators
条件表达式运算符
https://docs.mongodb.com/v3.6/reference/operator/aggregation/#conditional-expression-operators
| 名称 | 描述 |
|---|
$cond |
一个三元运算符,它对一个表达式求值,并根据结果返回其他两个表达式之一的值。接受有序列表中的三个表达式或三个命名参数。 |
$ifNull |
如果第一个表达式的结果为空,则返回第一个表达式的非空结果或第二个表达式的结果。空结果包含未定义值或缺少字段的实例。接受两个表达式作为参数。第二个表达式的结果可以为空。 |
$switch |
计算一系列案例表达式。当它找到一个计算结果为的表达式时true,$switch执行一个指定的表达式并退出控制流程。 |
用于聚合分组中的运算符
https://docs.mongodb.com/v3.6/reference/operator/aggregation/#accumulators-group
| 名称 | 描述 |
|---|
$avg |
返回数值的平均值。忽略非数字值。 |
$first |
为每个组从第一个文档返回一个值。仅当文档按定义的顺序定义顺序。 |
$last |
从每个组的最后一个文档返回一个值。仅当文档按定义的顺序定义顺序。 |
$max |
返回每个组的最高表达式值。 |
$min |
返回每个组的最低表达式值。 |
$push |
返回每个组的表达式值的数组。 |
$sum |
返回数值的总和。忽略非数字值。 |
快速上手
通过本小结,你将快速的学会MongoDB的基本操作。
MongoDB默认的库
当你登录到MongoDB Shell中时,默认进入的是test库,另外,它还有三个默认库。
1
2
3
4
5
6
7
|
[mongod@cs mongodb]$ mongo
db // 等价于 select database();
db.getName() // 也是查看当前所在的数据库
show dbs; // 等价于 show databases;
admin 0.000GB
config 0.000GB
local 0.000GB
|
其中:
- test,登录时默认进入的库。
- admin,系统预留库,是MongoDB系统管理用。
- local,本地预留库,存储关键日志。
- config,MongoDB配置信息库。
当你use到某个库中,可以通过下面两个命令来查看所有的集合:
1
2
3
|
use admin
show tables;
show collections;
|
另外,你可以使用use到一个不存在的库,而只有真正的在这个库中添加数据时,这个库才被创建。
MongoDB命令的种类
在MongoDB中,命令是以函数形式调用的,而我们可以将大部分的命令都划分为三大类:
db,对象(库,集合,文档)相关命令。rs,复制级相关命令。sh,分片集群相关。
上面的几个命令都支持tab键,比如db.按两下tab,就返回所有db类的命令;或者使用db.help()返回所有db命令的帮助信息。
所谓的对象,就是对对象进行操作,即对库、集合、文档的操作,而开发中,这些从操作通常都会由开发人员通过某门语言连接到MongoDB进行操作,所以,这里只做相关操作的示例。
库相关
MongoDB的库操作,非常简单,记住下面这两条命令就好了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
use test // 切换到指定库
db.dropDatabase() // 删除当前库,如果库不存在也会返回 { "ok" : 1 }
{ "ok" : 1 }
// 查看当前数据库
db
db.getName()
// 查看当前数据状态信息
db.stats()
{
"db" : "test",
"collections" : 0,
"views" : 0,
"objects" : 0,
"avgObjSize" : 0,
"dataSize" : 0,
"storageSize" : 0,
"numExtents" : 0,
"indexes" : 0,
"indexSize" : 0,
"fileSize" : 0,
"fsUsedSize" : 0,
"fsTotalSize" : 0,
"ok" : 1
}
|
你或许有点迷惑,创建库操作怎么没有?稳住,后续会说。
集合操作
关于集合的常用的命令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// 切换到库 t1 中,注意,此时 t1 还未真正的创建
use t1
// 创建集合 s1,此时,t1已存在
db.createCollection('s1')
{ "ok" : 1 }
// 添加文档时,如果库和集合不存在,MongoDB会自动创建库和集合,然后再添加文档
db.s2.insert({"name": "张开"})
// 返回集合 s1 中文档的个数
db.s1.count()
0
// 集合中索引+数据压缩存储之后的大小
db.s1.totalSize()
8192
// 删除集合
db.s1.drop()
// 返回当前数据库下所有集合
db.getCollectionNames()
show collections
show tables
|
文档操作
文档操作就是如何在集合中管理文档了。
MongoDB中的文档,可以理解为json类型的对象,集合中的每个文档对象都是独立的,并且MongoDB会为每个文档建立索引加速查询。
添加文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// 添加数据 方式1 先创建集合,在使用集合的inset方法插入文档
db.createCollection('s2')
db.s2.insert({"name": "zhangkai", "age": 18})
db.s2.insert({"name": "likai", "age": 20})
// 添加数据 方式2 当插入一篇文档的时候,集合会自动地创建
db.s3.insert({"name": "wangkai", "age": 22})
// 在介绍两个添加文档的方法
// 一次添加一条
db.s4.insertOne({"name": "zhangkai1", "age": 18})
// 一次添加多条
db.s4.insertMany([
{"name": "zhangkai2", "age": 18},
{"name": "zhangkai3", "age": 19},
])
// 添加数据 方式3 批量录入(用的较多)
for(i=0;i<1000;i++){db.s4.insert({"num": i, "k": "v", "date": new Date()})}
WriteResult({ "nInserted" : 1 })
// 可以通过下面的设置,控制每页显式得结果条数,然后输入it翻页
DBQuery.shellBatchSize=50
|
另外,需要注意的是,如果在添加文档时没有指定_id,MongoDB会自动为这篇为文档生成一个_id作为索引:
1
2
3
4
5
6
7
|
db.s5.insertMany([
{"id": 1, "name": "zhangkai2", "age": 18},
{"_id": 2, "name": "zhangkai3", "age": 19},
])
db.s5.find()
{ "_id" : ObjectId("600831c86b2f4b4cf9a9e929"), "id" : 1, "name" : "zhangkai2", "age" : 18 }
{ "_id" : 2, "name" : "zhangkai3", "age" : 19 }
|
如上,第一篇文档的id字段只是普通的字段,MongoDB会自动生成一个_id字段作为索引;第二篇文档我们手动指定了_id,那么MongoDB就不会再创建_id字段了。在实际开发中,要尽量避免这两种情况同时出现。
查询查询
查询可以分为,基本查询和复杂查询,复杂查询也就是搭配运算符进行条件过滤查询。
先来看基本查询。
查询文档通常使用下面两个方法:
1
2
3
4
|
// 查询所有文档
db.s4.find(<查询条件>, <其他过滤条件>)
// 查询一篇文档
db.s4.findOne(<查询条件>, <其他过滤条件>)
|
来看具体怎么使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// find用法
db.s4.find() // 无条件则查询所有文档
db.s4.find({}) // {} 相当于无条件,也返回所有文档
db.s4.find({"name": "zhangkai1"}) // 按条件查询
{ "_id" : ObjectId("600830666b2f4b4cf9a9e926"), "name" : "zhangkai1", "age" : 18 }
// 其他过滤条件中,可以指定返回结果,都返回哪些字段,或者哪些字段不返回
// 0:不返回指定字段
// 1:返回指定字段
db.s4.find({"name": "zhangkai1"}, {"name": 1, "age": 1, "_id": 0})
{ "name" : "zhangkai1", "age" : 18 }
// findOne用法
db.s4.findOne() // 返回所有结果的第一条
db.s4.findOne().pretty() // 格式化返回
db.s4.findOne({"name": "zhangkai1"}, {"name": 1, "age": 1, "_id": 0}) // 根据条件过滤
{ "name" : "zhangkai1", "age" : 18 }
|
sort和limit:
1
2
3
4
5
6
7
8
9
10
|
// 排序, 1:升序,默认升序 -1:降序
db.s4.find().sort({"age": 1})
db.s4.find().sort({"age": -1})
// 多条件排序,以 age 进行降序排序,如果遇到 age 相同的,以 _id 升序排序
db.s4.find().sort({"age": -1, "_id": 1})
// 使用 limit 对结果条数进行限制
db.s4.find().limit() // 不跟参数返回所有
db.s4.find().limit(3) // 返回匹配结果的前3条
db.s4.find().limit(1, 3) // 不支持的写法
|
复杂查询
运算符参考:https://www.cnblogs.com/Neeo/articles/14306535.html#operator
复杂查询主要掌握如何结合各种运算符过滤出符合条件的结果。
比较运算符:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// t1 数据库下有集合 s4,现对该集合中的文档进行查询
// 等于
db.s4.find({"name": "zhangkai1"})
db.s4.find({"name":{$eq:"zhangkai1"}}) // 操作符支持 $eq 和 "$eq" 这两种写法,推荐带引号的写法
// 小于、小于等于
db.s4.find({"age":{$lt:18}})
db.s4.find({"age":{$lte:18}})
// 大于、大于等于
db.s4.find({"age":{$gt:18}})
db.s4.find({"age":{$gte:18}})
// 包含 where age in (18, 19)
db.s4.find({"age":{$in:[18, 19]}})
// 查询不等于指定值的文档
db.s4.find({"age":{$ne:18}})
|
逻辑运算符:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
// t1 数据库下有集合 s4,现对该集合中的文档进行查询
// and 下面两个语句等价
db.s4.find({"name": "zhangkai1", "age": 18})
db.s4.find({
$and:[
{"name": "zhangkai1"},
{"age": 18}
]
})
// or
db.s4.find({
$or:[
{"name": "zhangkai1"},
{"age": 18}
]
})
// not 注意,$not操作符不支持$regex正则表达式操作
db.s4.find({
"age":{
$not:{$lte:18}
}
})
db.s4.find({
"name":{
$not:{$eq:"zhangkai1"}
}
})
// where name != zhangkai1 and age = 19
db.s4.find({
$nor:[
{"name": "zhangkai1"},
{"age": 19}
]
})
|
元素查询运算符:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// $exists:true 如果指定的key不存在,则返回该文档
// $exists:false 如果指定的key不存在,则返回该文档
db.s4.find({"mobile": {$exists: true}})
db.s4.find({"mobile": {$exists: false}})
// $type 如果指定key的值是指定类型,则返回该文档
db.s4.insert({"name": "likai", "age": 18, "money": 8.8, "hobby": ['guitar', 'read'], 'gender': true, "date": new Date()})
db.s4.find({"name":{$type:"string"}})
db.s4.find({"age":{$type:"integer"}})
db.s4.find({"money":{$type:"double"}})
db.s4.find({"hobby":{$type:"array"}})
db.s4.find({"gender":{$type:"bool"}})
db.s4.find({"date":{$type:"date"}})
// 以上列出常用的用于 $type 判断的类型,更多参考:https://docs.mongodb.com/manual/reference/operator/query/type/#available-types
|
评估查询运算符:
$regex为查询中的模式匹配字符串提供正则表达式功能 。MongoDB使用支持UTF-8的Perl兼容正则表达式(即“ PCRE”)版本8.42。
1
2
3
4
5
6
7
8
9
10
11
|
// 正则匹配
db.s4.insertMany([
{"name": "wangkai1", "age": 18, "mobile": "15011110000"},
{"name": "WANGKAI2", "age": 18, "mobile": "15011110000"},
{"name": "wangkai3", "age": 18, "mobile": "15111110000"},
])
db.s4.find({"mobile":{$regex:/^150/}})
db.s4.find({"name":{$regex:/^wang/}})
// 下面两条语句等价
db.s4.find({"name":{$regex:/^wang/i}})
db.s4.find({"name":{$regex:/^wang/, $options:"i"}})
|
$options有以下几个选项可用于正则表达式:
| 选项 | 描述 | 语法限制 |
|---|
i |
不区分大小写,以匹配大小写。有关示例,请参见执行不区分大小写的正则表达式匹配。 |
|
m |
对于包含锚点的模式(即^开始, $结束),请在每行的开头或结尾匹配具有多行值的字符串。没有此选项,这些锚点将在字符串的开头或结尾匹配。有关示例,请参见以指定模式开头的行的多行匹配。如果模式不包含锚点,或者字符串值不包含换行符(例如\n),则该m选项无效。 |
|
x |
“扩展”功能可忽略模式中的所有空白字符,$regex除非转义或包含在字符类中。此外,它会忽略介于两者之间的字符,包括未转义的井号/磅(#)字符和下一个新行,因此您可以在复杂模式中添加注释。这仅适用于数据字符;空格字符可能永远不会出现在图案的特殊字符序列中。该x选项不影响VT字符(即代码11)的处理。 |
需要$regex与$options语法 |
s |
允许点字符(即.)匹配所有字符,包括换行符。有关示例,请参阅使用。点字符以匹配换行符。 |
需要$regex与$options语法 |
注意:该$regex运营商不支持全局搜索修改g。
更多细节参考:https://docs.mongodb.com/manual/reference/operator/query/regex/#op._S_regex
分组聚合
准备数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
db.s5.insertMany([
{'_id': 1, 'name': '陆莉', 'age': 36, 'department': '研发', 'city': '哈尔滨', 'salary': 34276},
{'_id': 2, 'name': '田玉', 'age': 23, 'department': '研发', 'city': '济南', 'salary': 44056},
{'_id': 3, 'name': '张荣', 'age': 55, 'department': '行政', 'city': '澳门', 'salary': 2243},
{'_id': 4, 'name': '张红梅', 'age': 43, 'department': '财务', 'city': '哈尔滨', 'salary': 39400},
{'_id': 5, 'name': '李娜', 'age': 53, 'department': '教学', 'city': '北镇', 'salary': 25965},
{'_id': 6, 'name': '杨建华', 'age': 28, 'department': '行政', 'city': '太原', 'salary': 37192},
{'_id': 7, 'name': '庞桂芳', 'age': 24, 'department': '财务', 'city': '柳州', 'salary': 25049},
{'_id': 8, 'name': '陈云', 'age': 56, 'department': '行政', 'city': '六盘水', 'salary': 4067},
{'_id': 9, 'name': '李玉英', 'age': 51, 'department': '教学', 'city': '广州', 'salary': 30600},
{'_id': 10, 'name': '杨慧', 'age': 23, 'department': '研发', 'city': '关岭', 'salary': 48794},
{'_id': 11, 'name': '孙琴', 'age': 46, 'department': '研发', 'city': '梧州', 'salary': 16250},
{'_id': 12, 'name': '张桂芳', 'age': 20, 'department': '财务', 'city': '呼和浩特', 'salary': 31412},
{'_id': 13, 'name': '丁秀梅', 'age': 28, 'department': '行政', 'city': '郑州', 'salary': 2439},
{'_id': 14, 'name': '万小红', 'age': 24, 'department': '行政', 'city': '西安', 'salary': 6153},
{'_id': 15, 'name': '钱建华', 'age': 47, 'department': '行政', 'city': '乌鲁木齐', 'salary': 3198},
{'_id': 16, 'name': '雷健', 'age': 56, 'department': '教学', 'city': '香港', 'salary': 3622},
{'_id': 17, 'name': '尤柳', 'age': 51, 'department': '财务', 'city': '哈尔滨', 'salary': 48016},
{'_id': 18, 'name': '刘莹', 'age': 46, 'department': '教学', 'city': '哈尔滨', 'salary': 18605},
{'_id': 19, 'name': '李秀梅', 'age': 35, 'department': '行政', 'city': '太原', 'salary': 5378},
{'_id': 20, 'name': '张淑英', 'age': 26, 'department': '财务', 'city': '大冶', 'salary': 36854},
{'_id': 21, 'name': '林红霞', 'age': 36, 'department': '财务', 'city': '拉萨', 'salary': 5292},
{'_id': 22, 'name': '周芳', 'age': 48, 'department': '财务', 'city': '荆门', 'salary': 3433},
{'_id': 23, 'name': '周芳', 'age': 30, 'department': '财务', 'city': '天津', 'salary': 4056},
{'_id': 24, 'name': '赵淑华', 'age': 50, 'department': '行政', 'city': '南宁', 'salary': 37898},
{'_id': 25, 'name': '何凤英', 'age': 45, 'department': '财务', 'city': '杭州', 'salary': 24429},
{'_id': 26, 'name': '司欣', 'age': 38, 'department': '教学', 'city': '长沙', 'salary': 49713},
{'_id': 27, 'name': '王亮', 'age': 27, 'department': '行政', 'city': '深圳', 'salary': 15875},
{'_id': 28, 'name': '颜柳', 'age': 51, 'department': '财务', 'city': '昆明', 'salary': 45560},
{'_id': 29, 'name': '卢柳', 'age': 39, 'department': '财务', 'city': '大冶', 'salary': 24864},
{'_id': 30, 'name': '刘秀芳', 'age': 52, 'department': '行政', 'city': '通辽', 'salary': 4741},
{'_id': 31, 'name': '王建军', 'age': 50, 'department': '财务', 'city': '齐齐哈尔', 'salary': 1625},
{'_id': 32, 'name': '霍红', 'age': 39, 'department': '财务', 'city': '北京', 'salary': 24373},
{'_id': 33, 'name': '葛倩', 'age': 44, 'department': '研发', 'city': '银川', 'salary': 8491},
{'_id': 34, 'name': '李秀梅', 'age': 27, 'department': '财务', 'city': '太原', 'salary': 26553},
{'_id': 35, 'name': '李红', 'age': 31, 'department': '教学', 'city': '呼和浩特', 'salary': 42143},
{'_id': 36, 'name': '宁凤英', 'age': 59, 'department': '行政', 'city': '南宁', 'salary': 18488},
{'_id': 37, 'name': '张秀珍', 'age': 53, 'department': '教学', 'city': '海口', 'salary': 19217},
{'_id': 38, 'name': '赵鑫', 'age': 23, 'department': '研发', 'city': '永安', 'salary': 13666},
{'_id': 39, 'name': '徐桂珍', 'age': 54, 'department': '行政', 'city': '澳门', 'salary': 8870},
{'_id': 40, 'name': '倪艳', 'age': 34, 'department': '教学', 'city': '澳门', 'salary': 47225},
{'_id': 41, 'name': '丁玉英', 'age': 48, 'department': '财务', 'city': '马鞍山', 'salary': 23588},
{'_id': 42, 'name': '何杰', 'age': 30, 'department': '财务', 'city': '呼和浩特', 'salary': 19936},
{'_id': 43, 'name': '班俊', 'age': 22, 'department': '行政', 'city': '巢湖', 'salary': 30159},
{'_id': 44, 'name': '邱红梅', 'age': 43, 'department': '研发', 'city': '惠州', 'salary': 34269},
{'_id': 45, 'name': '黄红梅', 'age': 51, 'department': '财务', 'city': '汕尾', 'salary': 46937},
{'_id': 46, 'name': '王凤英', 'age': 52, 'department': '财务', 'city': '重庆', 'salary': 23413},
{'_id': 47, 'name': '覃璐', 'age': 54, 'department': '财务', 'city': '六安', 'salary': 28359},
{'_id': 48, 'name': '黄瑜', 'age': 55, 'department': '教学', 'city': '海门', 'salary': 24756},
{'_id': 49, 'name': '孟丽娟', 'age': 39, 'department': '教学', 'city': '辛集', 'salary': 47526},
{'_id': 50, 'name': '王丽', 'age': 34, 'department': '财务', 'city': '海门', 'salary': 24091},
{'_id': 51, 'name': '王桂珍', 'age': 44, 'department': '教学', 'city': '杭州', 'salary': 23686},
{'_id': 52, 'name': '刘燕', 'age': 52, 'department': '行政', 'city': '西宁', 'salary': 22643},
{'_id': 53, 'name': '陈俊', 'age': 53, 'department': '教学', 'city': '银川', 'salary': 48200},
{'_id': 54, 'name': '廖丽丽', 'age': 35, 'department': '教学', 'city': '辛集', 'salary': 13419},
{'_id': 55, 'name': '董婷', 'age': 48, 'department': '财务', 'city': '西宁', 'salary': 20368},
{'_id': 56, 'name': '何桂荣', 'age': 24, 'department': '教学', 'city': '北京', 'salary': 25127},
{'_id': 57, 'name': '郭凯', 'age': 22, 'department': '研发', 'city': '辛集', 'salary': 8079},
{'_id': 58, 'name': '张博', 'age': 57, 'department': '行政', 'city': '张家港', 'salary': 25686},
{'_id': 59, 'name': '颜凯', 'age': 20, 'department': '研发', 'city': '乌鲁木齐', 'salary': 2194},
{'_id': 60, 'name': '李小红', 'age': 49, 'department': '财务', 'city': '福州', 'salary': 28882},
{'_id': 61, 'name': '吴倩', 'age': 52, 'department': '财务', 'city': '柳州', 'salary': 13382},
{'_id': 62, 'name': '祁玉珍', 'age': 36, 'department': '行政', 'city': '太原', 'salary': 28242},
{'_id': 63, 'name': '吴桂兰', 'age': 45, 'department': '行政', 'city': '济南', 'salary': 21206},
{'_id': 64, 'name': '曹建华', 'age': 50, 'department': '财务', 'city': '拉萨', 'salary': 25650},
{'_id': 65, 'name': '张雷', 'age': 41, 'department': '财务', 'city': '上海', 'salary': 11749},
{'_id': 66, 'name': '张淑兰', 'age': 29, 'department': '教学', 'city': '昆明', 'salary': 33699},
{'_id': 67, 'name': '徐琳', 'age': 36, 'department': '教学', 'city': '阜新', 'salary': 10631},
{'_id': 68, 'name': '黄红', 'age': 59, 'department': '研发', 'city': '东莞', 'salary': 26985},
{'_id': 69, 'name': '秦秀荣', 'age': 27, 'department': '财务', 'city': '乌鲁木齐', 'salary': 22490},
{'_id': 70, 'name': '何秀梅', 'age': 52, 'department': '财务', 'city': '昆明', 'salary': 6254},
{'_id': 71, 'name': '杨艳', 'age': 33, 'department': '研发', 'city': '海口', 'salary': 40186},
{'_id': 72, 'name': '汪桂英', 'age': 25, 'department': '研发', 'city': '嘉禾', 'salary': 6814},
{'_id': 73, 'name': '郭鹏', 'age': 37, 'department': '教学', 'city': '台北', 'salary': 20298},
{'_id': 74, 'name': '邓萍', 'age': 28, 'department': '教学', 'city': '潮州', 'salary': 27718},
{'_id': 75, 'name': '陈明', 'age': 50, 'department': '研发', 'city': '香港', 'salary': 41881},
{'_id': 76, 'name': '贺金凤', 'age': 43, 'department': '财务', 'city': '荆门', 'salary': 28221},
{'_id': 77, 'name': '梁旭', 'age': 32, 'department': '行政', 'city': '拉萨', 'salary': 9921},
{'_id': 78, 'name': '张阳', 'age': 55, 'department': '行政', 'city': '兴城', 'salary': 23353},
{'_id': 79, 'name': '吕坤', 'age': 54, 'department': '财务', 'city': '阜新', 'salary': 23551},
{'_id': 80, 'name': '胡飞', 'age': 20, 'department': '行政', 'city': '海门', 'salary': 19774},
{'_id': 81, 'name': '张俊', 'age': 24, 'department': '财务', 'city': '合山', 'salary': 14928},
{'_id': 82, 'name': '戴建', 'age': 33, 'department': '财务', 'city': '大冶', 'salary': 39383},
{'_id': 83, 'name': '刘娟', 'age': 40, 'department': '教学', 'city': '东莞', 'salary': 22757},
{'_id': 84, 'name': '盛丽娟', 'age': 28, 'department': '财务', 'city': '潮州', 'salary': 19360},
{'_id': 85, 'name': '马辉', 'age': 40, 'department': '研发', 'city': '广州', 'salary': 36599},
{'_id': 86, 'name': '刘秀兰', 'age': 33, 'department': '教学', 'city': '银川', 'salary': 27751},
{'_id': 87, 'name': '田莹', 'age': 52, 'department': '研发', 'city': '东莞', 'salary': 49509},
{'_id': 88, 'name': '林志强', 'age': 32, 'department': '行政', 'city': '石家庄', 'salary': 2703},
{'_id': 89, 'name': '曹红霞', 'age': 20, 'department': '研发', 'city': '乌鲁木齐', 'salary': 20836},
{'_id': 90, 'name': '熊莹', 'age': 22, 'department': '研发', 'city': '合肥', 'salary': 42514},
{'_id': 91, 'name': '侯超', 'age': 23, 'department': '行政', 'city': '荆门', 'salary': 32676},
{'_id': 92, 'name': '陈瑜', 'age': 42, 'department': '教学', 'city': '杭州', 'salary': 40729},
{'_id': 93, 'name': '李丽丽', 'age': 47, 'department': '财务', 'city': '成都', 'salary': 33203},
{'_id': 94, 'name': '朱淑华', 'age': 35, 'department': '财务', 'city': '北京', 'salary': 8754},
{'_id': 95, 'name': '王兰英', 'age': 26, 'department': '行政', 'city': '东莞', 'salary': 18682},
{'_id': 96, 'name': '石刚', 'age': 42, 'department': '教学', 'city': '上海', 'salary': 27357},
{'_id': 97, 'name': '高刚', 'age': 52, 'department': '研发', 'city': '太原', 'salary': 29452},
{'_id': 98, 'name': '李秀荣', 'age': 41, 'department': '财务', 'city': '长沙', 'salary': 48755},
{'_id': 99, 'name': '李志强', 'age': 56, 'department': '研发', 'city': '香港', 'salary': 15993},
{'_id': 100, 'name': '王平', 'age': 45, 'department': '行政', 'city': '马鞍山', 'salary': 15113}
])
|
match和match和group:
$match和$group相当于SQL中的where和group by,在聚合后还可以搭配使用$min、$max、$avg、$sum这些聚合函数,也可以搭配使用排序使用,基本语法参考:
1
2
3
4
|
db.collection.aggregate([
{$match: {"字段": "条件"}}, // 可以跟常用的查询操作符,如 $gt $lt $in
{$group: {"_id": "分组字段", "新的字段": "聚合操作符"}}
])
|
聚合函数的应用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
// t1 数据库下有集合 s5,现对该集合中的文档进行查询
// 查询 department="财务" 的文档 where department = "财务"
db.s5.aggregate([
{"$match": {"department": "财务"}}
])
// 查询 id > 10 的文档,且以 department 分组 where id > 3 group by department
db.s5.aggregate([
{"$match": {"_id": {"$gt": 10}}},
{"$group": {"_id": "$department"}}
])
// 查询 id > 10 的文档,且以 department 分组,并查看每个部门的平均薪水
db.s5.aggregate([
{"$match": {"_id": {"$gt": 10}}},
{"$group": {
"_id": "$department", // 第一个参数必须是 _id
"avg_salary": {"$avg": "$salary"},
// "min_age": {"$min": "$age"} // 可以跟多个聚合条件
}
}
])
// 查询 id > 10 的文档,且以 department 分组,并查看每个部门的平均薪水,然后过滤平均薪水大于 25000 的
db.s5.aggregate([
{"$match": {"_id": {"$gt": 10}}},
{"$group": {
"_id": "$department", // 第一个参数必须是 _id
"avg_salary": {"$avg": "$salary"},
// "min_age": {"$min": "$age"} // 可以跟多个聚合条件
}
},
{"$match": {"avg_salary": {"$gt": 25000}}} // 直接引用上条结果中的 avg_salary
])
// 以 department 分组,并求出每个分组的最高薪水、最低薪水、最大年龄和最小年龄
db.s5.aggregate([
{"$group": { // 注意,分组内的结果不一定是有序的,但最大最小操作符都能处理
"_id": "$department",
"max_salary": {"$max": "$salary"},
"min_salary": {"$min": "$salary"},
"max_age": {"$max": "$age"},
"min_age": {"$min": "$age"},
}}
])
|
排序的使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
// 如果是分组聚合的结果是有序的,请用 $first 和 $last 代替 $max 和 $min,因为 $first 和 $last 效率更高
// 按 department 分组,并且求最大和最小薪水
db.s5.aggregate([
{"$sort": {"salary": 1}}, // 首先要排序, 1 表示升序
{"$group": {
"_id": "$department",
"max_salary": {"$max": "$salary"},
"min_salary": {"$min": "$salary"},
"last_salary": {"$last": "$salary"}, // 最后一个,相当于取有序集合的最后一个
"first_salary": {"$first": "$salary"}, // // 第一个,相当于取有序集合的第一个
}}
])
// $sum 求每个部门的总薪水,并根据每个部门的总薪水进行升序排序
db.s5.aggregate([
// 先分组
{"$group": {
"_id": "$department",
"count_salary": {
"$sum": "$salary"
}
}},
// 根据分组结果进行排序
{"$sort": {
"count_salary": 1
}}
])
// $sum 求每个部门的人数,并根据每个部门的总人数进行降序排序
db.s5.aggregate([
{"$group": {
"_id": "$department",
"count_pepole": {
"$sum": 1 // 不用跟具体的条件,每出现一条记录就加一
}
}},
{"$sort": {
"count_pepole": -1
}}
])
|
数组操作符:
数组操作符这里,掌握两个操作符:
$push:如果文档有重复,将其中一个也添加到数组中。$addToSet:只将不重复的文档添加到数组中。
1
2
3
4
5
6
7
8
9
|
// 查询各部门及各部门的人员姓名
db.s5.aggregate([
{"$group": {
"_id": "$department",
"name_list": {
"$push": "$name"
}
}}
])
|
$project:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// 通过为指定键设置 1/0 来决定是否显式
db.s5.aggregate([
{
"$project": {
"_id": 0, // _id字段是默认显式的,可以通过 0 设置取消显式
"name": 1,
"age": 1,
"new_age": {
"$add": ["$age", 1] // 所有 age 自加一
}
}
}
])
|
limit、limit、skip和$sample相关:
$limit用于过滤结果条数。
$skip用于跳过多少篇文档。
$sample表示随机选取几篇文档。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
// 获取平均工资最高的前三个部门
db.s5.aggregate([
{"$group": {
"_id": "$department",
"avg_salary": {"$avg": "$salary"}
}},
{"$sort": {
"avg_salary": -1
}},
{"$limit": 3}
])
// 取平均工资最高的前三个部门中的第二个部门
db.s5.aggregate([
{"$group": {
"_id": "$department",
"avg_salary": {"$avg": "$salary"}
}},
{"$sort": {
"avg_salary": -1
}},
{"$limit": 2}, // 返回前两条数据
{"$skip": 1} // 跳过第一条
])
// 随机返回5篇文档
db.s5.aggregate([
{"$sample": {
"size": 5
}}
])
|
concat、concat、substr、toLower、toLower、toUpper相关:
$concat将指定的表达式或者字符串拼接后返回。
$substr截取字符串。
$toLower字符串转小写。
$toUpper字符串转大写。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
// 添加一条数据
db.s6.insert({"name": "Anthony"})
// 拼接字符串
db.s6.aggregate([
{"$project": {
"_id": 0,
"name": {
"$concat": ["$name", "$name", "$name"] // 将数组内的每个元素都进行拼接
}
}}
])
// 截取
db.s6.aggregate([
{"$project": {
"_id": 0,
"name": {
"$substr": ["$name", 0, 2] // 返回索引为 0, 1 的字符
}
}}
])
// 转大写/转小写
db.s6.aggregate([
{"$project": {
"_id": 0,
"toUpper": {
"$toUpper": "$name" // 将 name 值的小写字母转da写
},
"toLower": {
"$toLower": "$name" // 将 name 值的大写字母转小写
}
}}
])
|
更新文档
更新文档使用以下两个方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 更新一条
db.collection.update(
<query>, // update的查询条件,一般写法:{"属性":{条件:值}}
<update>, // update的更新数据,一般写法 { $set:{"属性":"值"} } 或者 { $inc:{"属性":"值"} }
{
upsert: <boolean>, // 可选参数,如果文档不存在,是否插入, true为插入,默认是false,不插入
multi: <boolean>, // 可选参数,是否把满足条件的所有数据全部更新
writeConcern: <document> // 可选参数,抛出异常的级别。
}
)
// 更新多条
db.collection.updateMany(
<query>, // update的查询条件,一般写法:{"属性":{条件:值}}
<update>, // update的对象,一般写法 { $set:{"属性":"值"} } 或者 { $inc:{"属性":"值"} }
{
upsert: <boolean>, // 可选参数,如果文档不存在,是否插入objNew, true为插入,默认是false,不插入
multi: <boolean>, // 可选参数,是否把满足条件的所有数据全部更新
writeConcern: <document> // 可选参数,抛出异常的级别。
}
)
|
更新操作通常可以结合更新相关的运算符结合使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
// t1 数据库下有集合 s4,现对该集合中的文档进行更新操作
// 更新一篇文档的指定字段,将 _id = ObjectId("600a32c1a20e39fe696c73d1") 的文档的 age 更新为20
db.s4.update(
{"_id": ObjectId("600a32c1a20e39fe696c73d1")},
{$set:
// 只更新文档中的 age 字段,不影响其他字段,如果字段不存在就添加
{"age": 22, "name": "wangkai2"},
// {"age": 22, "name": "wangkai2"} // 更新多个字段值
}
)
// 覆盖更新,只保留更新后的字段
db.s4.update(
{"_id": ObjectId("600a32c1a20e39fe696c73d1")},
// 这么写,相当于覆盖更新文档,即更新后的文档,只保留 age 和 _id 字段(_id字段也是MongoDB自动生成的)
{"age": 20}
)
// 更新多篇文档中的指定字段
db.s4.updateMany(
{"name": {$regex: /^zhangkai/i}}, // where name like "zhangkai%"
{$set:
{"gender": "男"} // 如果字段不存在则添加,存在则修改
}
)
// 自增/自减,可以指定任意正负整数值
db.s4.update(
{"_id": ObjectId("600a32c1a20e39fe696c73d1")},
{$inc:
{"age": 1} // age 自增 1
// {"age": -1} // age 自减 1
// {"age": 3} // age 自增 3
// {"age": -3} // age 自减 3
}
)
// 指定字段重命名
db.s4.updateMany(
{"name": {$regex: /^wangkai/i}}, // 匹配以 wangkai 开头的 name
{$rename:
{"mobile": "tel"} // 将 mobile 字段重命名为 tel
}
)
// 添加一个字段
db.s4.updateMany(
{"tel": {$exists:false}}, // 匹配 tel 字段不存在的文档
{$set:
{"tel": "15011101112"} // 添加 tel 字段
}
)
// 删除指定字段
db.s4.updateMany(
{"tel": {$regex: /^150/}}, // 匹配以 150 开头的 tel
{$unset:
{"tel": ""} // 将 tel 字段删除
}
)
|
还有关于array的操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// 准备些数据
db.s4.insertMany([
{"name": "sunkai1", "age": 18, "friends": ["anthony", "maggie", "tom", "neeo"]},
{"name": "sunkai2", "age": 18, "friends": ["jack", "maggie", "ben"]},
])
// 为数组添加一个成员
db.s4.update(
{"name": "sunkai2"},
{$push:
{"friends": "mary"}
}
)
// 为数组移除指定成员
db.s4.update(
{"name": "sunkai2"},
{$pull:
{"friends": "mary"}
}
)
// 移除数组索引为 0 或者 -1 的成员
db.s4.update(
{"name": "sunkai1"},
{$pop:
{"friends": 1}, // 1 移除索引为 -1 的成员
// {"friends": -1} // -1 移除索引为 0 的成员
}
)
|
更多的更新操作运算符,参考:https://www.cnblogs.com/Neeo/articles/14306535.html
删除文档
删除使用remove方法:
1
2
3
4
5
6
7
|
db.collection.remove(
<query>, // remove的查询条件,一般写法:{"属性":{条件:值}},如果不填写条件,删除所有文档
{
justOne: <boolean>, // 可选删除,是否只删除查询到的第一个文档,默认为false,删除所有
writeConcern: <document> // 可选参数,抛出异常的级别。
}
)
|
一般用法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// 删除指定文档,通过query条件和justOone来控制删除的数量
db.s4.remove(
{"_id": ObjectId("600a32c1a20e39fe696c73d1")}, // 精确匹配到一篇文档
{"justOne": true} // justOne:true 删除一个, 如果只匹配一篇文档,可以不写这个参数
)
// 删除多篇文档
db.s4.remove(
{"name": {$regex:/^zhangkai/i}}, // 匹配结果可能有多个
// {"justOne": true}, // justOne:true 删除一个
{"justOne": false} // 将匹配到的文档全部删除
)
// 清空集合中的文档
db.s4.remove({})
|
基于角色的访问控制
MongoDB3.6.12 + centos7.9
MongoDB提供了各种功能,例如身份验证,访问控制,加密,以保护MongoDB的数据安全。
这里我们重点介绍基于角色的访问控制,也就是MongoDB中的用户管理。
MongoDB使用基于角色的访问控制(RBAC)来管理对MongoDB系统的访问。授予用户一个或多个角色,这些角色确定用户对数据库资源和操作的访问权限。
启用访问控制
MongoDB默认情况下不启用访问控制。但可以使用--auth或 security.authorization设置启用授权。
启用访问控制后,用户必须对自己进行身份验证。
用户和角色
我们可以在创建用户时,同时指定角色,明确用户对于哪些资源可以进行操控。
我们也可以为现有用户授权或者撤销角色,后续会具体展开讲解。
内置角色和权限
MongoDB提供了内置角色,可提供数据库系统中通常所需的不同访问级别。
接下来简要介绍MongoDB中的内置角色和内置权限。
内置权限
| Permission | Description |
|---|
| root |
只在admin数据库中可用。拥有对MongoDB的所有权限 |
| read |
允许用户读取指定数据库 |
| readWrite |
允许用户读写指定数据库 |
| dbAdmin |
允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile |
| dbOwner |
允许用户对指定库的所有能力,包含readWrite、dbAdmin、userAdmin这些角色的权限 |
| userAdmin |
允许用户向system.users集合写入,可以找指定数据库里创建、删除和管理用户 |
| clusterAdmin |
只在admin数据库中可用,赋予用户所有分片和复制集相关函数的管理权限 |
| readAnyDatabase |
只在admin数据库中可用,赋予用户所有数据库的读权限 |
| readWriteAnyDatabase |
只在admin数据库中可用,赋予用户所有数据库的读写权限 |
| userAdminAnyDatabase |
只在admin数据库中可用,赋予用户所有数据库的userAdmin权限 |
| dbAdminAnyDatabase |
只在admin数据库中可用,赋予用户所有数据库的dbAdmin权限 |
内置角色
| Role | Description |
|---|
| 超级用户角色 |
root |
| 数据库用户角色 |
read、readWrite |
| 数据库管理角色 |
dbAdmin、dbOwner、userAdmin |
| 集群管理角色 |
clusterAdmin、clusterManager、clusterMonitor、hostManager |
| 备份恢复角色 |
backup、restore |
| 所有数据库角色 |
readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase |
更多关于内置角色和权限参考官网:https://docs.mongodb.com/v3.6/core/security-built-in-roles/
注意,如果内置的角色无法满足一些特定的场景,MongoDB还允许我们自定义角色。
用户管理
我们通常先创建具有userAdmin或者userAdminAnyDatabase角色的admin用户后,再开启访问控制。
当开启访问控制后,MongoDB会强制执行访问用户的身份认证。
在展开讲解之前,需要了解一些概念。
认证库的概念
认证库(Authentication Database)也叫验证库,是MongoDB在用户安全方面的重要一部分,用户在登录时,必须加上认证库才能操作。
建议,请将认证库指定为使用的库。
用户管理的相关方法
详情参考官档:https://docs.mongodb.com/v3.6/reference/method/js-user-management/#user-management-methods
创建用户
创建用户语法参考:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
{
user: "<name>",
pwd: "<cleartext password>",
customData: { <any information> },
roles: [
{ role: "<role>", db: "<database>" },
{ role: "<role>", db: "<database>" },
"role", "role",
],
authenticationRestrictions: [
{
clientSource: ["<IP>" | "<CIDR range>", ...],
serverAddress: ["<IP>" | "<CIDR range>", ...]
},
...
]
}
|
其中:
user是用户名。pwd是密码,且密码必须是字符串。customData可以备注一些自定义的信息,比如说这个用户哪个员工在使用。roles对应一个列表,列表套字典:
role是角色。db是要从操作的库,同时也是认证库。
authenticationRestrictions限制身份,用的较少。
在创建用户时,我们通常先创建root超级用户,然后通过root用户来创建其他的用户。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
# 创建admin用户,赋予userAdminAnyDatabase角色对应的权限,用于管理所有用户信息
use admin
db.createUser({
user: "admin",
pwd: "1234",
roles: [
{ role: "userAdminAnyDatabase", db: "admin" }
]
})
# 创建超级管理员用户,拥有所有权限
use admin
db.createUser({
user: "root",
pwd: "1234",
roles: [
{ role: "root", db: "admin" }
]
})
# 创建普通用户, 认证库是 admin, 对 t1 库具有 read 角色对应的权限,同时具有 backup角色对应的权限
use admin
db.createUser({
user: "zhangkai1",
pwd: "1234",
roles: [
{ role: "read", db: "t1" },
"backup"
]
})
# 创建普通用户, 认证库是 t1, 对 t1 库具有 readWrite 角色对应的权限,同时具有 backup角色对应的权限
use t1
db.createUser({
user: "zhangkai2",
pwd: "1234",
roles: [
{ role: "readWrite", db: "t1" },
"backup"
]
})
# 创建普通用户, 认证库是 t1,尚未分配角色
use t1
db.createUser({
user: "zhangkai3",
pwd: "1234",
roles: []
})
|
注意:
- 创建用户时,必须先use到某个数据库下,而且该数据库将作为用户的认证库。
- 创建管理员类的用户时,必须先
use admin后再创建用户,且用户的认证库就是admin。
- 创建普通的用户时:
use admin后在创建用户,该用户的认证库就是admin。use到一个普通数据库下创建的用户,该用户的认证库就是这个普通数据库。
- 一般建议管理员类的用户认证库为admin,普通用户将认证库和要操作的数据库设置为同一个即可。
- 当用户登录时,必须指定认证库。
另外要说明的是,由于root权限比admin大,操作起来也更便捷,后续的所有用户管理的操作,我都以root用户来操作。
开启认证
开启认证有两种方式。
第一种就是通过在启动时配置--auth参数开启用户认证:
1
|
[mongod@cs ~]$ mongod -f /data/mongodb_data/27017/conf/mongodb.conf --fork --auth
|
第二种,则是直接在配置文件中进行配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
[mongod@cs ~]$ vim /data/mongodb_data/27017/conf/mongodb.conf
# 安全配置相关
security:
# 当开启该配置时,登录需要用户认证,如果你没有可用的用户,请勿配置该参数
authorization: enabled
[mongod@cs ~]$ systemctl restart mongod
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to manage system services or units.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
|
当开启认证之后,登录就要加认证了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
[mongod@cs ~]$ mongo # 无认证,可以登录,但啥也做不了
> use admin
switched to db admin
> show tables
2021-01-20T15:02:19.518+0800 E QUERY [thread1] Error: listCollections failed: {
"ok" : 0,
"errmsg" : "there are no users authenticated",
"code" : 13,
"codeName" : "Unauthorized"
} :
_getErrorWithCode@src/mongo/shell/utils.js:25:13
DB.prototype._getCollectionInfosCommand@src/mongo/shell/db.js:941:1
DB.prototype.getCollectionInfos@src/mongo/shell/db.js:953:19
DB.prototype.getCollectionNames@src/mongo/shell/db.js:964:16
shellHelper.show@src/mongo/shell/utils.js:853:9
shellHelper@src/mongo/shell/utils.js:750:15
@(shellhelp2):1:1
# 此时,就需要通过一个内置方法来进行认证
> db.auth("root", "1234")
1
> show tables
system.users
system.version
> exit
|
不推荐上面的认证方式,通常在登录时加上认证:
1
2
3
4
5
6
|
# 标准登录语法,当然,你不要在 -p 后直接跟密码 /admin 是认证库
[mongod@cs ~]$ mongo -uroot -p1234 127.0.0.1:27017/admin
# 如果是默认端口,可以省略不写
[mongod@cs ~]$ mongo -uroot -p1234 127.0.0.1/admin
# 如果是远程登录
[mongod@cs ~]$ mongo -uroot -p1234 10.0.0.200:27017/admin
|
认证成功,可以通过以下几个命令来查看用户了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# 所有的用户都存在admin库下的system.users集合中
> use admin
switched to db admin
> show tables
system.users
system.version
# 查看所有用户
> db.system.users.find()
> db.system.users.find().pretty()
# 查看指定用户
> db.system.users.find({"user":"root"})
# 查看跟当前所在库绑定的用户/所有用户
> show users
> db.getUser("root")
> db.getUsers()
|
更改用户
如果仅更改用户密码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 首先use到对应的库
> use t1
switched to db t1
# 通过show命令查看当前库绑定的用户
> show users
{
"_id" : "t1.zhangkai3",
"user" : "zhangkai3",
"db" : "t1",
"roles" : [ ]
}
# db.changeUserPassword("要修改的用户名", "新的密码")
> db.changeUserPassword("zhangkai3", "abc")
> exit
bye
[mongod@cs ~]$ mongo -uzhangkai3 -pabc 127.0.0.1/t1
|
更改用户其他信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
> use t1
switched to db t1
> show users
{
"_id" : "t1.zhangkai3",
"user" : "zhangkai3",
"db" : "t1",
"roles" : [ ]
}
> db.updateUser("zhangkai3",{
customData: {"info": "除了用户名不能更改,其他的都可以更改"},
pwd: "1234",
roles: [
{ role: "read", db: "t1" }
]
})
> show users
{
"_id" : "t1.zhangkai3",
"user" : "zhangkai3",
"db" : "t1",
"roles" : [
{
"role" : "read",
"db" : "t1"
}
],
"customData" : {
"info" : "除了用户名不能更改,其他的都可以更改"
}
}
|
注意,db.updateUser方法中, roles参数用来更新用户的角色信息,比如为一个无角色用户添加角色,更改角色都用该参数指定。
删除用户
删除用户有以下几种方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
# 首先 db.removeUser() 在MongoDB2.6版本开始被弃用,
# 使用 db.dropUser() 删除用户
# 删除当前库下的用户
[mongod@cs ~]$ mongo -uroot -p1234 127.0.0.1/admin
> use t1
> show users
{
"_id" : "t1.zhangkai3",
"user" : "zhangkai3",
"db" : "t1",
"roles" : [ ]
}
{
"_id" : "t1.zhangkai4",
"user" : "zhangkai4",
"db" : "t1",
"roles" : [ ]
}
> db.dropUser("zhangkai4")
true
> show users
{
"_id" : "t1.zhangkai3",
"user" : "zhangkai3",
"db" : "t1",
"roles" : [ ]
}
# 也可以从 system.users 集合中删除
> db.system.users.remove({"user": "zhangkai3"})
WriteResult({ "nRemoved" : 2 })
# 删除当前库下所有用户
# 先创建两个用户
> use t2
switched to db t2
> db.createUser({user: "zhangkai5", pwd: "1234", roles: []})
Successfully added user: { "user" : "zhangkai5", "roles" : [ ] }
> db.createUser({user: "zhangkai6", pwd: "1234", roles: []})
Successfully added user: { "user" : "zhangkai6", "roles" : [ ] }
> show users
{
"_id" : "t2.zhangkai5",
"user" : "zhangkai5",
"db" : "t2",
"roles" : [ ]
}
{
"_id" : "t2.zhangkai6",
"user" : "zhangkai6",
"db" : "t2",
"roles" : [ ]
}
# 删除当前库绑定的所有用户
> db.dropAllUsers()
NumberLong(2) # 结果提示有两个用户被删除
|
角色管理
角色管理的相关方法
详情参考官档:https://docs.mongodb.com/v3.6/reference/method/js-role-management/#role-management-methods
查看角色
查看角色有两个方法:
1
2
|
db.getRoles() # 查看当前库下所有的自定义角色
db.getRole("read") # 查看所有内置或者自定义角色
|
默认的, MongoDB为每个可用的数据库,绑定所有内置的角色:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
[mongod@cs ~]$ mongo -uroot -p1234 127.0.0.1/admin
> use t3
switched to db t3
> db.getUsers() # 此时 t3 还没有绑定用户
[ ]
> db.getRoles() # 查看当前库下所有的自定义角色
[ ]
> db.getRole("read") # 查看所有内置或者自定义角色
{
"role" : "read",
"db" : "t3",
"isBuiltin" : true, # 可以发现read角色时内置角色
"roles" : [ ],
"inheritedRoles" : [ ]
}
|
创建和添加角色
当内置角色不能满足特定场景时,可以通过db.createRole方法来创建自定义角色,相关语法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# 语法参考
{
role: "<name>",
privileges: [
{ resource: { <resource> }, actions: [ "<action>", ... ] },
...
],
roles: [
{ role: "<role>", db: "<database>" } | "<role>",
...
],
authenticationRestrictions: [
{
clientSource: ["<IP>" | "<CIDR range>", ...],
serverAddress: ["<IP>" | "<CIDR range>", ...]
},
...
]
}
# 示例参考
use admin
db.createRole(
{
role: "myClusterwideAdmin", # 自定义角色名字
privileges: [ # 拥有哪些特权
{ resource: { cluster: true }, actions: [ "addShard" ] },
{ resource: { db: "config", collection: "" }, actions: [ "find", "update", "insert", "remove" ] },
{ resource: { db: "users", collection: "usersCollection" }, actions: [ "update", "insert", "remove" ] },
{ resource: { db: "", collection: "" }, actions: [ "find" ] }
],
roles: [ # 对 admin 库有 read 权限
{ role: "read", db: "admin" }
]
},
{ w: "majority" , wtimeout: 5000 } # 写确认和写超时
)
|
来个示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
[mongod@cs ~]$ mongo -uroot -p1234 127.0.0.1/admin
# 创建一个无角色用户
> use t3
> db.createUser({user: "zhangkai6", pwd: "1234", roles: []})
> db.getUser("zhangkai6")
{
"_id" : "t3.zhangkai6",
"user" : "zhangkai6",
"db" : "t3",
"roles" : [ ]
}
# 创建一个自定义的角色 myRole1,拥有的特权:可以对 t3 库下所有集合进行 "find", "update", "insert", "remove" 操作
# 拥有对 t3 的 readWrite 权限
> db.createRole(
{
role: "myRole1",
privileges: [
{ resource: { db: "t3", collection: "" }, actions: [ "find", "update", "insert", "remove" ] }
],
roles: [
{ role: "readWrite", db: "t3" }
]
}
)
> db.getRole("myRole1")
{
"role" : "myRole1",
"db" : "t3",
"isBuiltin" : false,
"roles" : [
{
"role" : "readWrite",
"db" : "t3"
}
],
"inheritedRoles" : [
{
"role" : "readWrite",
"db" : "t3"
}
]
}
# 将自定义角色赋予用户
> db.updateUser("zhangkai6", {"roles": [{"role": "myRole1", "db": "t3"}]})
> db.getUser("zhangkai6")
{
"_id" : "t3.zhangkai6",
"user" : "zhangkai6",
"db" : "t3",
"roles" : [
{
"role" : "myRole1",
"db" : "t3"
}
]
}
|
更改角色
为现有的自定义角色授予新的特权:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
# 先创建一个自定义角色
db.createRole(
{
role: "myRole2",
privileges: [
{ resource: { db: "t3", collection: "" }, actions: [ "find" ] }
],
roles: [
{ role: "readWrite", db: "t3" }
]
}
)
# 此时该自定义角色的 privileges 是这样的
> db.getRole("myRole2", {"showPrivileges":true})["privileges"]
[
{
"resource" : {
"db" : "t3",
"collection" : ""
},
"actions" : [
"find"
]
}
]
# 通过下面方法添加新特权
> db.grantPrivilegesToRole(
"myRole2",
[
{ resource: { db: "t3", collection: "" }, actions: ["update", "insert"] }
]
)
> db.getRole("myRole2", {"showPrivileges":true})["privileges"]
[
{
"resource" : {
"db" : "t3",
"collection" : ""
},
"actions" : [
"find",
"insert",
"update"
]
}
]
|
为现有自定义角色删除指定特权:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
# 现在,自定义角色具有以下特权
> db.getRole("myRole2", {"showPrivileges":true})["privileges"]
[
{
"resource" : {
"db" : "t3",
"collection" : ""
},
"actions" : [
"find",
"insert",
"update"
]
}
]
# 通过 删除 update 特权
> db.revokePrivilegesFromRole(
"myRole2",
[
{resource : {db : "t3",collection : ""}, actions : ["update"]}
]
)
> db.getRole("myRole2", {"showPrivileges":true})["privileges"]
[
{
"resource" : {
"db" : "t3",
"collection" : ""
},
"actions" : [
"find",
"insert"
]
}
]
# 删除多个特权
> db.revokePrivilegesFromRole(
"myRole2",
[
{resource : {db : "t3",collection : ""}, actions : ["update"]},
{resource : {db : "t3",collection : ""}, actions : ["find", "insert"]}
]
)
|
将内置或自定义角色赋予自定义的角色:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
# myRole1是现有的自定义角色,可以在列表中写多个自定义角色
> db.grantRolesToRole(
"myRole1",
["myRole2"]
)
> db.getRole("myRole1")
{
"role" : "myRole1",
"db" : "t3",
"isBuiltin" : false,
"roles" : [
{
"role" : "readWrite",
"db" : "t3"
},
{
"role" : "myRole2",
"db" : "t3"
}
],
"inheritedRoles" : [
{
"role" : "myRole2",
"db" : "t3"
},
{
"role" : "readWrite",
"db" : "t3"
}
]
}
|
从现有自定义角色中删除内置或自定义角色:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 现在,myRole1 角色有如下角色
> db.getRole("myRole1")["roles"]
[
{
"role" : "myRole2",
"db" : "t3"
},
{
"role" : "readWrite",
"db" : "t3"
}
]
> db.revokeRolesFromRole("myRole1", ["readWrite", "myRole2"])
> db.getRole("myRole1")["roles"]
[ ]
|
更新角色:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
# 现在的 myRole2 的角色信息
> db.getRole("myRole2")
{
"role" : "myRole2",
"db" : "t3",
"isBuiltin" : false,
"roles" : [
{
"role" : "readWrite",
"db" : "t3"
}
],
"inheritedRoles" : [
{
"role" : "readWrite",
"db" : "t3"
}
]
}
# db.updateRole 将完全覆盖指定自定义角色的所有角色信息,慎用
> db.updateRole(
"myRole2",
{
privileges: [
{ resource: { db: "t3", collection: "" }, actions: ["find"] }
],
roles: [
{ role: "read", db: "t3" }
]
}
)
> db.getRole("myRole2")
{
"role" : "myRole2",
"db" : "t3",
"isBuiltin" : false,
"roles" : [
{
"role" : "read",
"db" : "t3"
}
],
"inheritedRoles" : [
{
"role" : "read",
"db" : "t3"
}
]
}
|
删除角色
删除角色非常简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
# 现在 t3 下有两个自定义角色
> db
t3
> db.getRoles()
[
{
"role" : "myRole1",
"db" : "t3",
"isBuiltin" : false,
"roles" : [ ],
"inheritedRoles" : [ ]
},
{
"role" : "myRole2",
"db" : "t3",
"isBuiltin" : false,
"roles" : [
{
"role" : "read",
"db" : "t3"
}
],
"inheritedRoles" : [
{
"role" : "read",
"db" : "t3"
}
]
}
]
# 删除当前库下的指定自定义角色
> db.dropRole("myRole1")
true
> db.getRoles() # 此时还剩一个自定义角色
[
{
"role" : "myRole2",
"db" : "t3",
"isBuiltin" : false,
"roles" : [
{
"role" : "read",
"db" : "t3"
}
],
"inheritedRoles" : [
{
"role" : "read",
"db" : "t3"
}
]
}
]
# 删除当前库下的所有自定义角色
> db.dropAllRoles()
NumberLong(1)
> db.getRoles() # 一个不剩
[ ]
|
执行计划
MongoDB提供了执行计划来帮助我们分析,一条语句执行情况,但这条语句不会真正的被执行,只是为优化或者其他操作提供依据。
一般的,执行计划通常在索引中应用较多,通过执行计划查看创建的索引的应用情况。
由于MongoDB在3.0版本后对执行计划做了优化,这里也仅针对MongoDB3.0以后的执行计划进行讨论,而接下来的示例中以MongoDB3.6.12版本为例。
Query Plan
Query Plan
query shape:即查询谓词,排序和投影规范的组合。投影意味着仅选择必要的数据,而不是选择文档的整个数据。 如果文档有5个字段,而我们只需要显示3个字段,则仅从其中选择3个字段。 MongoDB提供了一些投影运算符,可以帮助我们实现该目标。
对于查询来说,MongoDB查询优化器处理查询,并在给定可用索引的情况下为查询选择最有效的查询计划。然后,查询系统将在每次查询运行时使用此查询计划。
查询优化器仅缓存那些具有多个可行计划的查询形状的计划。
对于每个查询,查询计划者都会在查询计划缓存中搜索适合query shape的条目。如果没有匹配的条目,查询计划器将生成候选计划,试用该候选计划并在试用期内进行评估。查询计划器选择一个获胜计划并进行缓存,然后使用它来生成结果文档。
如果存在匹配的计划,则查询计划程序将基于该条目生成计划,并通过一种replanning机制评估其性能。该机制pass/fail根据计划的性能做出决定,并保留或逐出缓存条目。逐出时,查询计划者将使用常规计划过程选择一个新计划并将其缓存。查询计划者执行计划并返回查询的结果文档。
下图说明了查询计划程序逻辑:

图片来源:https://docs.mongodb.com/v3.6/core/query-plans/#query-plans
基本使用
MongoDB中的执行计划基本用法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// 语法参考
db.collection.explain(verbosity).<method(...)>
// method 支持查看以下语句的执行计划
aggregate()
count()
distinct()
find()
group()
remove()
update()
// 通过help查看帮助信息
db.collection.explain().help()
db.collection.explain().find().help()
// 你也可以这样使用执行计划,如查询某个集合的find语句的执行计划
db.collection.<method(...)>.explain()
db.collection.find().explain()
|
知道了如何使用执行计划,接下来,我们就该来学习执行计划的结果都在"说些什么”。
执行计划的返回结果的详细程度由可选参数verbosity参数决定,通常有三种模式:
| 模式 | 描述 |
|---|
| queryPlanner |
默认模式,MongoDB运行查询优化器对当前的查询进行评估并选择一个最佳的查询计划。 |
| executionStats |
MongoDB运行查询优化器对当前的查询进行评估并选择一个最佳的查询计划进行执行,在执行完毕后返回这个最佳执行计划执行完成时的相关统计信息,对于那些被拒绝的执行计划,不返回其统计信息。 |
| allPlansExecution |
该模式包括上述2种模式的所有信息,即按照最佳的执行计划执行以及列出统计信息,如果存在其他候选计划,也会列出这些候选的执行计划。 |
准备数据:
1
2
3
4
5
6
7
8
9
10
11
12
|
// 准备数据
db.s4.drop()
db.s4.insertMany([
{"name": "zhangkai", "age": 18},
{"name": "wangkai", "age": 28},
{"name": "likai", "age": 10},
{"name": "zhaokai", "age": 21}
])
// 为了后续的执行结果信息更全面,这里再创建两个索引 s4_id1 和 s4_id2,两个索引都为age字段创建索引,1表示升序, -1表示降序
db.s4.createIndex({"age": 1}, {"name": "s4_id1"})
db.s4.createIndex({"age": -1}, {"name": "s4_id2"})
|
接下来,分别使用三种模式查看一条语句的执行计划,观察结果有什么不同。
queryPlanner
queryPlanner是我们最关注的部分,通过这部分信息,我们就能大概的知道语句的执行情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
// 下面两条执行计划等价
db.s4.explain("queryPlanner").find({"age": {"$gt": 20}})
db.s4.explain().find({"age": {"$gt": 20}})
{
"queryPlanner" : {
"plannerVersion" : 1, // 查询计划版本
"namespace" : "t1.s4", // 被查询对象,也就是被查询的集合
"indexFilterSet" : false, // 决定了查询优化器对于某一类型的查询将如何使用index,后面会展开来说
"parsedQuery" : { // 解析查询,即过滤条件是什么,此处是 age > 20
"age" : {
"$gt" : 20
}
},
"winningPlan" : { // 查询优化器针对该query所返回的最优执行计划的详细内容
"stage" : "FETCH", // 最优执行计划的stage,这里返回是FETCH,可以理解为通过返回的index位置去检索具体的文档
"inputStage" : {
"stage" : "IXSCAN", // 此时的stage是IXSCAN,表示进行的是 index scanning
"keyPattern" : {
"age" : 1 // 所扫描的index内容
},
"indexName" : "s4_id1", // 最优计划选择的索引名称
"isMultiKey" : false, // 是否是多键索引,因为这里用到的索引是单列索引,所以这里是false
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward", // 此query的查询顺序,forward是升序,降序则是backward
"indexBounds" : { // 最优计划所扫描的索引范围
"age" : [
"(20.0, inf.0]" // [MinKey,MaxKey],最小从20.0开始到无穷大
]
}
}
},
"rejectedPlans" : [ ] // 其他计划,因为不是最优而被查询优化器拒绝(reject),这里为空
},
"serverInfo" : { // 服务器信息,包括主机名和ip,MongoDB的version等信息
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
|
executionStats
executionStats返回的是最优计划的详细的执行信息。
注意,必须是executionStats或者allPlansExecution模式中,才返回executionStats结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
|
db.s4.explain("executionStats").find({"age": {"$gt": 20}})
{
"queryPlanner" : {
"plannerVersion" : 1, // 查询计划版本
"namespace" : "t1.s4", // 被查询对象,也就是被查询的集合
"indexFilterSet" : false, // 决定了查询优化器对于某一类型的查询将如何使用index,后面会展开来说
"parsedQuery" : { // 解析查询,即过滤条件是什么,此处是 age > 20
"age" : {
"$gt" : 20
}
},
"winningPlan" : { // 查询优化器针对该query所返回的最优执行计划的详细内容
"stage" : "FETCH", // 最优执行计划的stage,这里返回是FETCH,可以理解为通过返回的index位置去检索具体的文档
"inputStage" : {
"stage" : "IXSCAN", // 此时的stage是IXSCAN,表示进行的是 index scanning
"keyPattern" : {
"age" : 1 // 所扫描的index内容
},
"indexName" : "s4_id1", // 最优计划选择的索引名称
"isMultiKey" : false, // 是否是多键索引,因为这里用到的索引是单列索引,所以这里是false
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward", // 此query的查询顺序,forward是升序,降序则是backward
"indexBounds" : { // 最优计划所扫描的索引范围
"age" : [
"(20.0, inf.0]" // [MinKey,MaxKey],最小从20.0开始到无穷大
]
}
}
},
"rejectedPlans" : [ ] // 其他计划,因为不是最优而被查询优化器拒绝(reject),这里为空
},
"executionStats" : {
"executionSuccess" : true, // 是否执行成功
"nReturned" : 2, // 此query匹配到的文档数
"executionTimeMillis" : 0, // 查询计划选择和查询执行所需的总时间,单位:毫秒
"totalKeysExamined" : 2, // 扫描的索引条目数
"totalDocsExamined" : 2, // 扫描的文档数
"executionStages" : { // 最优计划完整的执行信息
"stage" : "FETCH", // 根据索引结果扫描具体文档
"nReturned" : 2, // 由于是 FETCH,这里的结果跟上面的nReturned结果一致
"executionTimeMillisEstimate" : 0,
"works" : 3, // 查询执行阶段执行的“工作单元”的数量。 查询执行阶段将其工作分为小单元。 “工作单位”可能包括检查单个索引键,从集合中提取单个文档,将投影应用于单个文档或执行内部记账
"advanced" : 2, // 返回到父阶段的结果数
"needTime" : 0, // 未将中间结果返回给其父级的工作循环数
"needYield" : 0, // 存储层请求查询系统产生锁定的次数
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1, // 执行阶段是否已到达流的结尾
"invalidates" : 0,
"docsExamined" : 2, // 跟totalDocsExamined结果一致
"alreadyHasObj" : 0,
"inputStage" : { // 一个小的工作单元,一个执行计划中,可以有一个或者多个inputStage
"stage" : "IXSCAN",
"nReturned" : 2,
"executionTimeMillisEstimate" : 0,
"works" : 3,
"advanced" : 2,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"age" : 1
},
"indexName" : "s4_id1",
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"(20.0, inf.0]"
]
},
"keysExamined" : 2,
"seeks" : 1,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0
}
}
},
"serverInfo" : {
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
|
执行计划的结果是以阶段树的形式呈现,每个阶段将其结果(文档或者索引键)传递给父节点,叶子节点访问集合或者索引,中间节点操纵由子节点产生的文档或者索引键,最后汇总到根节点。
上例的执行计划返回结果中,queryPlanner.winningPlan.stage参数,常用的有:
| 类型 | 描述 |
|---|
| COLLSCAN |
全表扫描 |
| IXSCAN |
索引扫描 |
| FETCH |
根据索引检索指定的文档 |
| SHARD_MERGE |
将各个分片的返回结果进行merge |
| SORT |
表明在内存中进行了排序 |
| LIMIT |
使用limit限制返回结果数量 |
| SKIP |
使用skip进行跳过 |
| IDHACK |
针对_id字段进行查询 |
| SHANRDING_FILTER |
通过mongos对分片数据进行查询 |
| COUNT |
利用db.coll.explain().count()进行count运算 |
| COUNTSCAN |
count不使用用index进行count时的stage返回 |
| COUNT_SCAN |
count使用了Index进行count时的stage返回 |
| SUBPLA |
未使用到索引的$or查询的stage返回 |
| TEXT |
使用全文索引进行查询时候的stage返回 |
| PROJECTION |
限定返回字段时候stage的返回 |
上表中,加粗部分为最常用的。
allPlansExecution
allPlansExecution模式返回了更为详细的执行计划结果,这里不再赘述。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
|
db.s4.explain("allPlansExecution").find({"age": {"$gt": 20}})
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "t1.s4",
"indexFilterSet" : false,
"parsedQuery" : {
"age" : {
"$gt" : 20
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : 1
},
"indexName" : "s4_id1",
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"(20.0, inf.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 2,
"executionTimeMillis" : 0,
"totalKeysExamined" : 2,
"totalDocsExamined" : 2,
"executionStages" : {
"stage" : "FETCH",
"nReturned" : 2,
"executionTimeMillisEstimate" : 0,
"works" : 3,
"advanced" : 2,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"docsExamined" : 2,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 2,
"executionTimeMillisEstimate" : 0,
"works" : 3,
"advanced" : 2,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"age" : 1
},
"indexName" : "s4_id1",
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"(20.0, inf.0]"
]
},
"keysExamined" : 2,
"seeks" : 1,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0
}
},
"allPlansExecution" : [ ]
},
"serverInfo" : {
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
|
IndexFilter
https://docs.mongodb.com/v3.6/core/query-plans/#index-filters
索引过滤器(IndexFilter)决定了查询优化器对于某一类型的查询将如何使用index,且仅影响指定的查询类型。
来个示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
// 首先,集合 s4 有三个索引
db.s4.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_", // MongoDB自动创建的索引
"ns" : "t1.s4"
},
{
"v" : 2,
"key" : {
"age" : 1
},
"name" : "s4_id1", // 我们手动创建的索引
"ns" : "t1.s4"
},
{
"v" : 2,
"key" : {
"age" : -1
},
"name" : "s4_id2", // 我们手动创建的索引
"ns" : "t1.s4"
}
]
// 在查询时,MongoDB会自动的帮我们选择使用哪个索引
// 以下两种查询查询优化器都会选择使用 s4_id2 索引
db.s4.explain().find({"age": {"$gt":18}})
db.s4.explain().find({"age": 18})
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "t1.s4",
"indexFilterSet" : false, // 注意这个值是false
"parsedQuery" : {
"age" : {
"$eq" : 18
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : -1
},
"indexName" : "s4_id2", // 查询优化器选择了s4_id2这个索引
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"[18.0, 18.0]"
]
}
}
},
"rejectedPlans" : [
{
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : 1
},
"indexName" : "s4_id1", // 并将s4_id1索引排除
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"[18.0, 18.0]"
]
}
}
}
]
},
"serverInfo" : {
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
|
问题来了,如果有些应用场景下需要特定索引,而不是用查询优化器帮助我们选择的索引,该怎么办?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
// 通过 hint 明确指定索引
db.s4.explain().find({"age": {"$gt":18}}).hint("s4_id1")
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "t1.s4",
"indexFilterSet" : false,
"parsedQuery" : {
"age" : {
"$gt" : 18
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : 1
},
"indexName" : "s4_id1", // hint告诉查询优化器选择使用指定的索引s4_id1
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"(18.0, inf.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
|
问题解决了。
但我们还有其他的解决方式,就是提前声明为某一类查询指定特定的索引(索引必须存在),当有这类查询时,自动使用特定索引,或者从指定的几个索引中选择一个,而不是通过hint显式指定,且不影响其他类型的查询,这就用到了IndexFilter。
1
2
3
4
5
6
7
|
// 创建IndexFilter
db.runCommand({
planCacheSetFilter: "s4",
query: {"age": 18}, // 只要查询类型是 age等于某个值,该IndexFilter就会被应用,并不特指18
// indexes:[{age: 1}] // 跟下面一行等价
indexes:["s4_id1"] // 可以有多个备选索引
})
|
上面的IndexFilter的意思是,当查询集合s4时,且查询类型是age等于某个值时(只作用于该类型的查询),就从indexes数组中选择一个索引,或者从多个备选索引中,选择一个最优的索引,当然,你也可以像示例中一样,只写一个索引s4_id1。
来看应用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
// 对于查询是 age 等于某个值这种类型的查询,查询优化器都会选择我们指定的IndexFilter
db.s4.explain().find({"age": 18})
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "t1.s4",
"indexFilterSet" : true, // IndexFilter被应用
"parsedQuery" : {
"age" : {
"$eq" : 18
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : 1
},
"indexName" : "s4_id1", // 使用了IndexFilter指定的索引
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"[18.0, 18.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
|
注意,如果某一类型的查询设定了IndexFilter,那么执行时通过hint指定了其他的index,查询优化器将会忽略hint所设置index,仍然使用indexfilter中设定的查询计划,也就是下面这种情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
db.s4.explain().find({"age": 18}).hint("s4_id2") // 希望在查询时使用 s4_id2 索引
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "t1.s4",
"indexFilterSet" : true, // 创建的indexFilter被应用
"parsedQuery" : {
"age" : {
"$eq" : 18
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : 1
},
"indexName" : "s4_id1", // 忽略hint指定的s4_id2,选择IndexFilter指定的索引
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"[18.0, 18.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
|
另外,IndexFilter不会影响其他类型的查询,如下面的查询类型,查询优化器还是按照原来的规则选择最优计划:
1
2
|
db.s4.explain().find({"age": {"$gt":18}})
db.s4.explain().find({"age": {"$gt":18}}).hint("s4_id1")
|
IndexFilter的其他操作:
1
2
3
4
5
6
7
8
9
|
// 查看指定集合中的IndexFilter数组
db.runCommand({planCacheListFilters: "s4"})
// 删除IndexFilter
db.runCommand({
planCacheClearFilters: "s4",
// query: {"age": 18}, // 对应创建IndexFilter时的注释的那一行
indexes:["s4_id1"]
})
|
当然,在有些情况下,你删除指定的IndexFilter会失败,终极的解决办法是——重启MongoDB服务。
小结:
- IndexFilter为指定类型的查询提前设置使用某一个或者从多个备选索引中选择指定索引。
- IndexFilter指定的索引必须存在,如果索引不存在——也没事!全表扫描呗!
- IndexFilter的优先级高于hint,这点是在生产中要注意的。
- IndexFilter一定程度上解决了某些问题,但它使用相对麻烦,谨慎使用!
PS:虽然我着重的介绍了这部分,但执行计划的重点还是queryPlanner和executionStats部分。
索引
索引的主要作用就是提高查询效率。
MongoDB中的索引有以下特点:
- MongoDB索引使用
B-Tree树作为数据结构。
- MongoDB的索引也是一个集合,但它要比原文档集合小得多。
- MongoDB使用索引中的排序返回结果。
在后续的示例中用到了执行计划,执行计划指的是MongoDB将会如何执行我们的相关语句,关于执行计划,点我
索引类型
MongoDB中支持以下几种索引类型:
- 单列索引(Single Field)。
- 复合索引(Compound Indexes)。
- 多键索引(Multikey Indexes)。
- 文本索引(Text Indexes)。
- 哈希索引(Hashed Indexes)。
在了解每种索引的细节之间,先来简单的了解索引的基本管理。
索引管理
索引管理部分主要了解如何创建、查看、删除索引。
你可能会有疑问,为啥没有修改索引?答案是除了TTL索引之外,修改索引就是删除并重新创建索引。
创建索引
在MongoDB3.0.0版本之间,使用ensureIndex方法来创建索引,而在之后的版本中,虽然ensureIndex方法还能使用,但推荐使用createIndex方法来代替,其语法参考如下:
1
|
db.collection.createIndex({"key": 1},options)
|
参数解释:
| Parameter | Type | Description |
|---|
keys |
document |
key:value格式的文档,其中key表示索引键,value描述了索引类型,1表示升序,-1表示降序。 |
options |
document |
可选参数,包含一组控制索引创建的选项文档,有关详细信息请参见options详情表。 |
options参数列表:
| Parameter | Type | Description |
|---|
background |
Boolean |
建索引过程会阻塞其他数据库操作,background可指定以后台方式创建索引,默认值为false。 |
unique |
Boolean |
建立的索引是否唯一,指定为true创建唯一索引,默认为false。 |
name |
String |
索引的名称,如果未指定,MongoDB通过连接索引的字段名和排序顺序生成默认的索引名。 |
droupDups |
Boolean |
3.x版本已废弃。在建立唯一索引时是否删除重复记录,指定true创建唯一索引,默认值为false。 |
sparse |
Boolean |
对文档中不存在的字段数据不启用索引,这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档,默认值为false。 |
expireAfterSeconds |
Integer |
指定一个以秒为单位的数值,完成TTL设定,设定集合的生存时间。 |
v |
Index Version |
索引引擎的版本,默认的版本取决于创建索引时引擎的版本号。 |
weights |
Document |
数值在1~99999之间的权重值,表示该索引相对于其他索引字段的得分权重。 |
default_language |
String |
对于文本索引,该参数决定了停用词及词干分词器的规则列表,默认为英语。 |
language_override |
String |
对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值language。 |
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// 创建单列索引
db.s7.createIndex({"myIndex1": 1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
// 创建复合索引
db.collection.createIndex({"user_id": 1, "score": 1})
// 创建多键索引
db.collection.createIndex({"info.address": 1})
|
查看索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// 列出当前数据库中,所有索引
db.getCollectionNames().forEach(function(collection) {
indexes = db[collection].getIndexes();
print("Indexes for " + collection + ":");
printjson(indexes);
});
// 查询指定集合中所有索引信息
db.s7.getIndices()
db.s7.getIndexes()
[
{ // 一个字典存储一个索引的基本信息
"v" : 2, // 索引引擎的版本号
"key" : { // 索引字段
"_id" : 1 // 1:升序排序
},
"name" : "_id_", // 索引名称
"ns" : "t1.s7" // 索引所在的 namespace
},
{
"v" : 2,
"key" : {
"myIndex1" : 1
},
"name" : "myIndex1_1", // MongoDB拼接后的自定义索引
"ns" : "t1.s7"
}
]
// 返回集合中所有索引的keys
db.s7.getIndexKeys()
[ { "_id" : 1 }, { "myIndex1" : 1 } ]
// 返回集合中索引空间
db.s7.getIndexSpecs() // 等价于 db.s7.getIndexes()
|
删除索引
删除索引有以下几种方式:
1
2
3
4
5
6
7
8
|
// 根据特定索引
db.s7.dropIndex({"name": 1})
// 根据索引名称删除
db.s7.dropIndex("name_index") // name_index:索引名称
// 清除集合中所有索引,如果存在_id这个内置索引,则该索引不会被清除
db.s7.dropIndexes()
|
常用索引介绍
默认索引
默认的,在创建集合期间,MongoDB会在_id字段上创建唯一索引,用来防止客户端插入两个具有相同值的文档,我们也不能删除该默认索引,而通常我们在插入文档时,应该忽略该字段,让ObjectId对象来自动生成。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 准备一个新的集合并插入数据
db.s1.drop()
db.s1.insertMany([
{"name": "zhangkai", "age": 18},
{"name": "likai", "age": 20}
])
{
"acknowledged" : true,
"insertedIds" : [ // 自动生成的两个文档的 _id
ObjectId("600fe7e79ab2f8c54a73ea77"),
ObjectId("600fe7e79ab2f8c54a73ea78")
]
}
db.s1.find()
{ "_id" : ObjectId("600fe7e79ab2f8c54a73ea77"), "name" : "zhangkai", "age" : 18 }
{ "_id" : ObjectId("600fe7e79ab2f8c54a73ea78"), "name" : "likai", "age" : 20 }
// 可以根据 _id 进行过滤
db.s1.find({"_id": ObjectId("600fe7e79ab2f8c54a73ea78")})
{ "_id" : ObjectId("600fe7e79ab2f8c54a73ea78"), "name" : "likai", "age" : 20 }
|
单列索引
Single Field Indexes
MongoDB支持在文档的单个字段上创建自定义的升序/降序索引,称为——单列索引(Single Field Index),也可以称之为单字段索引。

在单列索引中,升序/降序并不影响查询性能。
创建单列索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
// 为 age 字段创建索引
db.s1.createIndex({"age": 1})
// 如下的查询将会走索引
db.s1.find({"age": {"$gt": 10}})
{ "_id" : ObjectId("600fe7e79ab2f8c54a73ea77"), "name" : "zhangkai", "age" : 18 }
{ "_id" : ObjectId("600fe7e79ab2f8c54a73ea78"), "name" : "likai", "age" : 20 }
// 从执行计划中,查看是否走了索引
db.s1.find({"age": {"$gt": 10}}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN", // 走了索引扫描
"keyPattern" : {
"age" : 1
},
"indexName" : "age_1", // 使用的索引
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"(10.0, inf.0]"
]
}
}
}
|
在嵌入式字段上创建单列索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
// 准备一个新的集合并插入数据
db.s1.drop()
db.s1.insertMany([
{"name": "zhangkai", "age": 18, "info": {"address": "beijing", "tel": "13011304424"}},
{"name": "likai", "age": 20, "info": {"address": "shanghai", "tel": "15011304424"}}
])
// 创建索引
db.s1.createIndex({"info.address": 1})
// 查询
db.s1.find({"info.address": "beijing"})
{ "_id" : ObjectId("600fec019ab2f8c54a73ea79"), "name" : "zhangkai", "age" : 18, "info" : [ { "address" : "beijing" }, { "tel" : "13011304424" } ] }
db.s1.find({"info.address": "beijing"}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN", // 走了索引查询
"keyPattern" : {
"info.address" : 1
},
"indexName" : "info.address_1", // 使用的索引
"isMultiKey" : false,
"multiKeyPaths" : {
"info.address" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"info.address" : [
"[\"beijing\", \"beijing\"]"
]
}
}
}
|
在嵌入式文档上创建单列索引:
1
2
3
4
5
6
7
|
// 创建索引
db.s1.createIndex({"info": 1})
// 查询
// 有结果返回
db.s1.find({"info": {"address": "shanghai", "tel": "15011304424"}})
// db.s1.find({"info": {"tel": "15011304424","address": "shanghai"}})
|
注意,当对嵌入式文档执行相等匹配时,字段顺序很重要,嵌入式文档必须完全匹配,才能返回结果。
另外,在嵌入式文档和嵌入式字段创建的索引不能混为一谈:
- 在嵌入式文档上创建的索引,会对整个嵌入的文档进行索引,它是一个整体,查询时,要进行完全匹配。
- 在嵌入式字段上创建的索引,只是对嵌入文档的指定字段进行索引,索引部分只包含嵌入文档的指定字段。
复合索引
Compound Indexes
MongoDB还支持多字段自定义索引,即复合索引(Compound Indexes),也可以称之为组合索引、联合索引。MongoDB中的复合索引在某些方面跟关系型数据库的组合索引是一样的,比如同样支持索引前缀。
创建复合索引:
1
2
3
4
5
6
7
8
9
10
|
// 准备一个新的集合并插入数据
db.s2.drop()
db.s2.insertMany([
{"userid": 1, "name": "zhangkai", "age": 18, "score": 98, "info": {"address": "beijing", "tel": "13011304424"}},
{"userid": 2, "name": "likai", "age": 20, "score": 88, "info": {"address": "shanghai", "tel": "15011304424"}},
{"userid": 3, "name": "wangkai", "age": 20, "score": 90, "info": {"address": "nanjing", "tel": "15111304442"}},
])
// 创建复合索引,首先根据 userid 字段升序排序,当 userid 字段相同时,再根据 score 字段降序排序
db.s2.createIndex({"userid": 1, "score": -1}, {"name": "compoundIndex1"})
|
复合索引与排序:
复合索引中字段的顺序非常重要,例如下图中的复合索引由{userid:1, score:-1}组成,则该复合索引首先按照userid升序排序;然后再每个userid的值内,再按照score降序排序。

在复合索引中,按照何种方式排序,决定了该索引在查询中是否能被应用到。
来看一下之前创建的复合索引compoundIndex1在排序中的应用情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// 如下排序走复合索引 compoundIndex1
db.s2.find().sort({"userid": 1, "score": -1})
db.s2.find().sort({"userid": -1, "score": 1})
// 如下排序不走复合索引 compoundIndex1
db.s2.find().sort({"userid": 1, "score": 1})
db.s2.find().sort({"userid": -1, "score": -1})
db.s2.find().sort({"score": 1, "userid": -1})
db.s2.find().sort({"score": 1, "userid": 1})
db.s2.find().sort({"score": -1, "userid": -1})
db.s2.find().sort({"score": -1, "userid": 1})
// 上述情况可以通过 explain 进行查看,如:
db.s2.find().sort({"score": -1, "userid": 1}).explain()
|
复合索引与索引前缀:
复合索引同样支持对索引前缀的查询,例如,考虑以下复合索引:
1
2
3
4
5
6
|
// 三个字段的复合索引
{"userid": 1, "socore": 1, "age": 1}
// 上面的复合索引有以下索引前缀
{"userid": 1}
{"userid": 1, "score": 1}
|
在以下情况的查询走索引:
useriduserid + scoreuserid + score + age。userid + age,尽管索引被使用,但效率不高。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// 为了避免混淆,先清空索引
db.s2.dropIndexes()
// 创建索引
db.s2.createIndex({"userid": 1, "socore": 1, "age": 1}, {"name": "compoundIndex2"})
// userid 走索引
db.s2.find({"userid": {"$lt": 3}}).explain()
// userid + score 走索引
db.s2.find({"userid": {"$lt": 3}, "score": {"$lt": 98}}).explain()
// userid + score + age 走索引
db.s2.find({"userid": {"$lt": 3}, "score": {"$lt": 98}, "age": {"$lt": 30}}).explain()
// userid + age 走索引
db.s2.find({"userid": {"$lt": 3}, "age": {"$lt": 30}}).explain()
|
以下情况不走索引:
1
2
3
4
5
6
7
8
|
// score 不走索引
db.s2.find({"score": {"$lt": 98}}).explain()
// age 不走索引
db.s2.find({"age": {"$lt": 30}}).explain()
// score + age 不走索引
db.s2.find({"score": {"$lt": 98}, "age": {"$lt": 30}}).explain()
|
多键索引
Multikey Indexes
对于包含数组的文档,我们可以使用MongoDB提供了多键索引,为数组中的每个元素创建一个索引键,这些多键索引支持对数组字段的有效查询。

创建多键索引:
1
2
3
4
5
6
7
8
9
10
11
12
|
// 准备集合并插入数据
db.s3.drop()
db.s3.insertMany([
{ _id: 5, type: "food", item: "aaa", ratings: [ 5, 8, 9 ]},
{ _id: 6, type: "food", item: "bbb", ratings: [ 5, 9 ]},
{ _id: 7, type: "food", item: "ccc", ratings: [ 9, 5, 8 ]},
{ _id: 8, type: "food", item: "ddd", ratings: [ 9, 5 ] },
{ _id: 9, type: "food", item: "eee", ratings: [ 5, 9, 5 ]}
])
// 基于ratings字段创建多键索引
db.s3.createIndex({ratings:1})
|
基于一个数组创建索引,MongoDB会自动创建为多键索引,无需刻意指定,另外,多键索引不等于复合索引。
来看下刚才创建的多键索引的应用情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
// 查询ratings数组中等于 5和9 的文档,所以,只有 _id:6 的文档符合条件
db.s3.find({ratings:[5, 9]})
// 来看执行计划
db.s3.find({ratings:[5, 9]}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "FETCH",
"filter" : {
"ratings" : {
"$eq" : [
5,
9
]
}
},
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"ratings" : 1
},
"indexName" : "ratings_1",
"isMultiKey" : true, // 走了多键索引
"multiKeyPaths" : {
"ratings" : [
"ratings"
]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"ratings" : [
"[5.0, 5.0]",
"[[ 5.0, 9.0 ], [ 5.0, 9.0 ]]"
]
}
}
}
|
你可能对上面的查询结果有点疑惑,按道理说,只要ratings数组中包含5和9的文档,都应该被返回,但很遗憾不能这么理解,因为db.s3.find({ratings:[5, 9]})条件这么写,相当于[5, 9]是一个整体,文档的ratings数组的元素必须完全等于5和9才被返回。
而使用下面这种查询,才能返回你想要的结果:
1
2
|
// 只要数组包含5的文档都会被返回,并且走多键索引
db.s3.find({ratings:5})
|
嵌套文档中的多键索引的应用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// 准备集合并插入数据
db.s3.drop()
db.s3.insertMany([
{
_id: 1,
item: "abc",
stock: [
{ size: "S", color: "red", quantity: 25 },
{ size: "S", color: "blue", quantity: 10 },
{ size: "M", color: "blue", quantity: 50 }
]
},
{
_id: 2,
item: "def",
stock: [
{ size: "S", color: "blue", quantity: 20 },
{ size: "M", color: "blue", quantity: 5 },
{ size: "M", color: "black", quantity: 10 },
{ size: "L", color: "red", quantity: 2 }
]
},
{
_id: 3,
item: "ijk",
stock: [
{ size: "M", color: "blue", quantity: 15 },
{ size: "L", color: "blue", quantity: 100 },
{ size: "L", color: "red", quantity: 25 }
]
}
])
// 基于嵌套文档创建多键索引
db.s3.createIndex({"stock.size":1, "stock.quantity":1})
|
来看下刚才创建的多键索引的应用情况,下面几种情况都会走多键索引:
1
2
3
4
5
6
7
8
9
10
11
|
// 查询嵌套文档 stock.size为 S 的 执行计划
db.s3.find({"stock.size": "S"}).explain()["queryPlanner"]["winningPlan"]
// 条件过滤
db.s3.find({"stock.size": "S", "stock.quantity": {"$gt":20}}).explain()["queryPlanner"]["winningPlan"]
// 排序
db.s3.find().sort({"stock.size": 1, "stock.quantity": 1}).explain()["queryPlanner"]["winningPlan"]
// 过滤加排序
db.s3.find({"stock.size": "S"}).sort({"stock.quantity": 1}).explain()["queryPlanner"]["winningPlan"]
|
其他索引
MongoDB还支持地理空间索引(Geospatial Indexes)、文本索引(Text Indexes)、哈希索引(Hashed Indexes)。
地理空间索引(Geospatial Indexes):
为了支持对于地理空间坐标数据的有效查询,MongoDB提供了两种特殊的索引:
- 返回结果时使用平面几何的二维索引。
- 返回结果时使用球面几何的二维索引。
文本索引(Text Indexes):
MongoDB提供了一种文本索引类型,支持在集合中搜索字符串内容。
这些文本索引不存储特定语言的停用词(例如the、a、or),而是将集合中的词作为词干,只存储词根。
哈希索引(Hashed Indexes):
为了支持基于散列的分片,MongoDB提供了散列索引类型,它对字段值的散列进行索引,这些索引在其范围内的值分布更加随机,但支持相等匹配,不支持基于范围的查询。
索引属性
除了 MongoDB支持的众多索引类型外,索引还可以具有各种属性。创建索引时通过指定特定的属性,可以得到特定的索引。
TTL索引
什么是TTL索引:
TTL(Time To Live)索引是特殊的单列索引,通过在创建索引时指定expireAfterSeconds参数将普通的单列索引标记为TTL索引,实现为文档的自动过期删除功能。
TTL索引运行原理:
- MongoDB会开启一个后台线程读取该TTL索引的值来判断文档是否过期,但不会保证已过期的数据会立马被删除,因后台线程
每60秒触发一次删除任务,且如果删除的数据量较大,会存在上一次的删除未完成,而下一次的任务已经开启的情况,导致过期的数据也会出现超过了数据保留时间60秒以上的现象。
- 对于副本集而言,
TTL索引的后台进程只会在primary节点开启,在从节点会始终处于空闲状态,从节点的数据删除是由主库删除后产生的oplog来做同步。
- TTL索引除了有expireAfterSeconds属性外,
和普通索引一样。
TTL索引的使用:
第一种应用场景:为所有插入的文档指定一个统一的过期时间。
指定具体的过期时间,后续插入的记录都会在expireAfterSeconds指定的时间(单位:秒)后自动删除:
1
2
3
4
5
6
7
8
9
10
|
// 创建 TTL索引 并指定过期时间为 30 秒
db.s9.createIndex({"logTTL": 1}, {"expireAfterSeconds": 30}) // 指定过期时间是 30 秒
db.s9.insertMany([
{"logMessage": "error", "logTTL": new Date()}, // logTTL类型是Date,会自动过期
{"logMessage": "error", "logTTL": "2020-12-12"}, // logTTL类型是string,不会自动过期
])
// 在30秒后,查询,只剩下不会自动过期的那条记录了
db.s9.find()
{ "_id" : ObjectId("600f7fe064bc3da87653e9db"), "logMessage" : "error", "logTTL" : "2020-12-12" }
|
第二种应用场景:插入文档时时,自己指定过期时间。
就是创建索引期间,将expireAfterSeconds的值设置为0,让每篇文档自己指定何时过期:
1
2
3
4
5
6
7
8
9
10
11
12
|
db.s9.dropIndex({"logTTL": 1})
db.s9.createIndex({"logTTL": 1}, {"expireAfterSeconds": 0})
// 文档的过期时间,就是 logTTL 字段指定的时间
db.s9.insertMany([
{"logMessage": "error", "logTTL": new Date("January 26, 2021 10:56:00")},
{"logMessage": "error", "logTTL": [
new Date("January 26, 2021 10:56:00"),
new Date("January 27, 2021 10:56:00"),
new Date("January 28, 2021 10:56:00")
]} // 如果数组类型,且其中有个多个日期类型的值,将以最早的时间作为过期时间
])
|
那么如何修改expireAfterSeconds的值呢?除了删除重建索引之外,也可以通过collMod`来进行设置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// 之前的TTL索引 expireAfterSeconds 值为0
db.s9.getIndexes()[1]["expireAfterSeconds"]
0
// 现在修改为60
// 在 s9 集合所在的库中
db.runCommand(
{
"collMod": "s9", // 指定集合名称
"index": {
"keyPattern": {"logTTL": 1}, // 指定索引
"expireAfterSeconds": 60 // 新的过期时间
}
}
)
// 返回结果
{ "expireAfterSeconds_old" : 0, "expireAfterSeconds_new" : 60, "ok" : 1 }
|
TTL索引的使用限制:
- TTL索引只支持单例索引,复合索引不支持TTL。
_id字段不支持TTL索引。- 无法在上限集合上创建TTL索引,因为MongoDB无法从上限集合中删除文档。
- 如果某个字段已经存在非TTL索引,那么在该字段上无法再创建TTL索引。
关于上限集合,参考:https://www.cnblogs.com/Neeo/articles/14333344.html
唯一索引
唯一索引(Unique Indexes)可确保索引字段不会存储重复值;即对索引字段实施唯一性。默认情况下,MongoDB 在创建集合时会在_id字段上创建唯一索引。
创建唯一索引:
1
2
3
4
5
6
7
8
9
10
|
// 创建单列唯一索引
// unipue:true声明普通单列索引为唯一索引
db.userinfo.createIndex({"user": 1}, {"unique": true})
// 复合索引中的添加唯一属性
db.userinfo.createIndex({"user": 1, "tel": 1}, {"unique": true})
// 多键索引中添加唯一属性
db.userinfo.createIndex({"info.address": 1, "info.tel": 1}, {"unique": true})
|
唯一索引的一些限制:
对于那些已经存在的非唯一的列,在其上面创建唯一索引将失败:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// 数据是这样的
db.s10.insertMany([
{"name": "zhangkai"},
{"name": "zhangkai"}
])
// 创建唯一索引会报错
db.s10.createIndex({"name": 1}, {"unique": true})
{
"ok" : 0,
"errmsg" : "E11000 duplicate key error collection: t1.s10 index: name_1 dup key: { : \"zhangkai\" }",
"code" : 11000,
"codeName" : "DuplicateKey" // 重复键
}
|
对于数组类型的key,相同的值只能插入一次:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// 清空 s10
db.s10.remove({})
// 插入数据
db.s10.insert({"info": [{"tel": 13011303330}]})
// 创建唯一索引
db.s10.createIndex({"info.tel": 1}, {"unique": true})
// 再次插入相同的值,就报错了
db.s10.insert({"info": [{"tel": 13011303330}]})
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 11000,
"errmsg" : "E11000 duplicate key error collection: t1.s10 index: info.tel_1 dup key: { : 13011303330.0 }"
}
})
|
MongoDB只允许一篇文档缺少索引字段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// 清空 s10
db.s10.remove({})
// 插入数据,成功
db.s10.insert({"name": "zhangkai"})
// 创建唯一索引,成功
db.s10.createIndex({"name": 1}, {"unique": true})
// 插入重复则报错,符合预期
db.s10.insert({"name": "zhangkai"}) // "errmsg" : "E11000 duplicate key error collection: t1.s10 index: name_1 dup key: { : \"zhangkai\" }"
// 插入一个缺少 name 字段的文档,可以成功
db.s10.insert({"age": 18}) // mongodb会默认为 name 字段设置为null
// 再次插入缺少 name 字段的文档,就会失败,因为mongodb只允许一篇文档缺少索引字段
db.s10.insert({"age": 20}) // "errmsg" : "E11000 duplicate key error collection: t1.s10 index: name_1 dup key: { : null }"
|
另外,不能对哈希索引指定唯一约束。
稀疏索引
稀疏索引(Sparse Indexes)也叫做间隙索引,它只包含含有索引字段的文档,如果某个文档的不存在索引键,则跳过,所以,这种索引被称之为稀疏索引。
创建稀疏索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
// 准备数据
db.s11.insertMany([
{"name": "zhangkai"},
{"name": "likai", "score": 95},
{"name": "wangkai", "score": 92},
])
// 在创建索引时,指定 sparse:true 将普通索引标记为稀疏索引
db.s11.createIndex({"score": 1}, {"sparse": true})
// 通过查询语句的执行计划,查看稀疏索引的应用情况
db.s11.find({"score": {"$lt": 95}})
{ "_id" : ObjectId("600fb8d164bc3da87653e9f4"), "name" : "wangkai", "score" : 92 }
db.s11.find({"score": {"$lt": 95}}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "FETCH", // 根据索引检索指定的文档
"inputStage" : {
"stage" : "IXSCAN", // 使用了索引扫描
"keyPattern" : {
"score" : 1
},
"indexName" : "score_1", // 索引名称
"isMultiKey" : false,
"multiKeyPaths" : {
"score" : [ ]
},
"isUnique" : false,
"isSparse" : true, // 索引类型是稀疏索引
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"score" : [
"[-inf.0, 95.0)"
]
}
}
}
|
再来看稀疏索引无法使用的示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
db.s11.find().sort({"score": 1})
{ "_id" : ObjectId("600fb8d164bc3da87653e9f2"), "name" : "zhangkai" }
{ "_id" : ObjectId("600fb8d164bc3da87653e9f4"), "name" : "wangkai", "score" : 92 }
{ "_id" : ObjectId("600fb8d164bc3da87653e9f3"), "name" : "likai", "score" : 95 }
db.s11.find().sort({"score": 1}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "SORT",
"sortPattern" : {
"score" : 1
},
"inputStage" : {
"stage" : "SORT_KEY_GENERATOR",
"inputStage" : {
"stage" : "COLLSCAN", // 全集合扫描
"direction" : "forward"
}
}
}
|
我们也可以强制使用稀疏索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
// hint 明确指定索引
db.s11.find().sort({"score": 1}).hint({"score": 1})
{ "_id" : ObjectId("600fb8d164bc3da87653e9f4"), "name" : "wangkai", "score" : 92 }
{ "_id" : ObjectId("600fb8d164bc3da87653e9f3"), "name" : "likai", "score" : 95 }
db.s11.find().hint({"score": 1}) // 跟上一条语句的返回结果一致
{ "_id" : ObjectId("600fb8d164bc3da87653e9f4"), "name" : "wangkai", "score" : 92 }
{ "_id" : ObjectId("600fb8d164bc3da87653e9f3"), "name" : "likai", "score" : 95 }
db.s11.find().hint({"score": 1}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"score" : 1
},
"indexName" : "score_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"score" : [ ]
},
"isUnique" : false,
"isSparse" : true,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"score" : [
"[MinKey, MaxKey]"
]
}
}
}
// 当然,如果你要对文档进行计数时,不要使用 hint 和稀疏索引
db.s11.count()
3
db.s11.find().hint({"score": 1}).count()
2
|
部分索引
部分索引(Partial Indexes)是MongoDB3.2版本中的新功能,也叫做局部索引。
部分索引仅索引集合中符合指定过滤器表达式的文档,且由于部分索引是集合的子集,所以部分索引具有较低的存储需求,并降低了索引创建和维护的性能成本。部分索引通过指定过滤条件来创建,可以为MongoDB支持的所有索引类型使用部分索引。
部分索引中常用的过滤器表达式:
- 等式表达式,
$eq
$exists- 大于小于等于系列
$typeand
创建部分索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
// 准备数据
db.s12.insertMany([
{"name": "zhangkai", "score": 85},
{"name": "likai", "score": 95},
{"name": "wangkai", "score": 92},
{"name": "zhangkai1", "score": 87},
{"name": "likai1", "score": 97},
{"name": "wangkai1", "score": 99},
{"name": "zhangkai2", "score": 25},
{"name": "likai2", "score": 45},
{"name": "wangkai2", "score": 32},
])
// 创建部分索引
db.s12.createIndex(
{"score": 1},
{
"partialFilterExpression": {
"score":{
"$gte": 60
}
}
})
// 只有当查询条件大于等于60的时候,才走部分索引
db.s12.find({"score": {"$gte": 60}}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN", // 走了索引
"keyPattern" : {
"score" : 1
},
"indexName" : "score_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"score" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : true,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"score" : [
"[60.0, inf.0]"
]
}
}
}
// 下面示例,不会走部分索引
db.s12.find({"score": {"$gt": 59}}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "COLLSCAN", // 全集合扫描
"filter" : {
"score" : {
"$gt" : 59
}
},
"direction" : "forward"
}
|
再来看部分索引和唯一索引同时使用时的一些现象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
db.s12.remove({})
db.s12.insertMany([
{"name": "zhangkai", "score": 85},
{"name": "likai", "score": 95}
])
db.s12.createIndex(
{"name": 1},
{
"unique": true,
"partialFilterExpression": {
"score": {
"$gt": 60
}
}
}
)
// 插入 name 值相同的文档, 报错,不允许插入
db.s12.insert({"name": "zhangkai", "score": 77}) // "errmsg" : "E11000 duplicate key error collection: t1.s12 index: name_1 dup key: { : \"zhangkai\" }"
// 以下几种情况允许插入
db.s12.insertMany([
{"name": "zhangkai", "score": 30}, // name 值重复,score 值小于部分索引限制
{"name": "zhangkai", "score": null}, // name 值重复,score 值为 null
{"name": "zhaokai"}, // 忽略 score 字段
])
// 文档已存在,再插入就报错
db.s12.insert({"name": "zhangkai", "score": 85}) // score值大于部分索引限制,校验 name 唯一性
// score 值小于部分索引,允许插入重复 name 值
db.s12.insert({"name": "zhaokai", "score": 30})
// name 值不重复,score值重复,允许插入
db.s12.insert({"name": "sunkai", "score": 70})
|
由上例的测试结果可以发现,当对唯一索引添加部分索引时,插入时检查部分索引字段的唯一性,什么意思呢?如上例的索引,它只对于score值大于等于60的文档,才去校验name的唯一性,同时允许姓名不同,score值相同的文档插入。
部分索引和稀疏索对比:
部分索引主要是针对那些满足条件的文档(非字段缺失)创建索引,比稀疏索引提供了更具有表现力。
稀疏索引是文档上某些字段的存在与否,存在则为其创建索引,否则该文档没有索引键。
覆盖查询
再来了解一下MongoDB中的覆盖查询。
覆盖查询是一种查询现象。
当查询条件和查询的投影仅包含索引字段时,MongoDB会直接从索引中返回结果,而不扫描任何文档或者将文档带入内存,这样的查询性能非常高。

如上图,如果对score字段建立了索引,查询时只返回score字段,这就会触发覆盖索引,即查询结果来自于索引,而不走文档集。
首先是无索引情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// 文档长这样
db.s7.find( {"score":{ "$gt": 80 }}).limit(2)
{ "_id" : 28, "name" : "邓桂芳", "age" : 10, "info" : { "address" : "海口", "tel" : "13465340126" }, "score" : 81 }
{ "_id" : 31, "name" : "耿涛", "age" : 20, "info" : { "address" : "关岭", "tel" : "14581415750" }, "score" : 81 }
// 没有索引,没有投影,一个普通的查询,我们来看它的执行计划
db.s7.find( {"score":{ "$gt": 80 }}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "COLLSCAN", // 表示全集合扫描
"filter" : {
"score" : {
"$gt" : 80
}
},
"direction" : "forward"
}
// 没有索引,但有投影
db.s7.find( {"score":{ "$gt": 80 }}, {"score": 1, "_id": 0} ).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "PROJECTION", // 对 score 字段做了投影后的 stage 状态
"transformBy" : {
"score" : 1,
"_id" : 0
},
"inputStage" : {
"stage" : "COLLSCAN", // 还是全集合扫描
"filter" : {
"score" : {
"$gt" : 80
}
},
"direction" : "forward"
}
}
|
现在添加索引,再来看两个查询计划:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
// 添加索引
db.s7.createIndex({"score": 1})
// 加上索引后,但没有投影
db.s7.find( {"score":{ "$gt": 80 }}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "FETCH", // 根据索引检索指定的文档
"inputStage" : {
"stage" : "IXSCAN", // 索引扫描
"keyPattern" : {
"score" : 1
},
"indexName" : "score_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"score" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"score" : [
"(80.0, inf.0]"
]
}
}
}
// 有索引和对 score 字段做投影后的情况,这种情况就是覆盖查询
db.s7.find( {"score":{ "$gt": 80 }}, {"score": 1, "_id": 0} ).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "PROJECTION", // 对 score 字段做了投影后的 stage 状态
"transformBy" : {
"score" : 1,
"_id" : 0
},
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"score" : 1
},
"indexName" : "score_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"score" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"score" : [
"(80.0, inf.0]"
]
}
}
}
|
疯狂面试题
参考:https://www.cnblogs.com/Neeo/articles/10401392.html
四、Redis
简介
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,它的主要特点:
- 高性能Key-Value服务器
- 支持多种数据结构
- 丰富的功能:pipeline、慢查询、发布订阅
- 高可用分布式支持
Redis的前世今生
在2008年北京开奥运会的时候,意大利一个叫做塞尔瓦托的技术大佬, 做了一个基于MySQL的的网站实时统计系统LLOOGG.com。但不久,这个大佬, 对MySQL的性能感到失望,于是Redis慢慢就诞生了.
谁在使用Redis
嗯~~,试问,现在还有谁没有在用Redis?
Redis八大特性
速度快
官方说redis能达到十万OPS(operation per second)每秒操作的次数。
这是因为redis是由C语言实现,并且redis的数据存储在内存中。
持久化
redis的所有数据保存在内存中,对数据的更新将异步的保存在磁盘上。
多种数据结构
redis支持字符串、哈希、链表、集合和有序集合五种数据类型。
衍生的其他数据结构:
-
基于字符串实现:
- BitMaps:位图
- HyperLogLog:超小内存唯一值计数
-
基于集合实现:
支持多种客户端语言
Python、Java……..
功能丰富
发布订阅、事务、Lua脚本、Pipeline….
简单
Redis的单机源码大约只有23000行代码,所以,你可以去阅读它的源码,甚至自定义…..
Redis不依赖外部库
单线程模型
主从复制
Redis有主服务器和从服务器是实现高可用的基础。
高可用、分布式
Redis从v2.8开始使用Redis-Sentinel支持高可用。
Redis从v3.0开始使用Redis-Cluster支持分布式。
Redis典型应用场景
各平台安装Redis
Windows
截止到本书编写时,Redis还是没有正式支持Windows,但Redis是开源软件,所以,微软开放技术小组开发并维护了针对Win64的Windows接口程序,提供了一个windows版本的Redis分支。 所以我们可以从这个分支上下载安装包进行安装。
下载和安装
从GitHub地址中下载:https://github.com/MicrosoftArchive/redis/releases
这里以最新版本3.2.100的zip包安装方式为例。
- 将
Redis-x64-3.2.100.zip压缩包解压到任意(没有空格、没有中文和特殊符号)路径,这个路径也是安装路径,我这里以C:\Redis-x64-3.2.100为例。

- 将Redis安装路径添加到系统环境变量。
| variable | path |
|---|
Path |
C:\Redis-x64-3.2.100 |
- 将Redis添加到Windows系统服务,这样可以设置后台自动运行,以后直接使用客户端访问就好了,比较简单。以管理员的身份运行CMD并将路径切换到Redis安装路径下执行下面命令:
1
2
3
|
C:\Redis-x64-3.2.100>redis-server.exe --service-install redis.windows.conf
[6388] 20 Nov 09:35:59.132 # Granting read/write access to 'NT AUTHORITY\NetworkService' on: "C:\Redis-x64-3.2.100" "C:\Redis-x64-3.2.100\"
[6388] 20 Nov 09:35:59.132 # Redis successfully installed as a service.
|
上面的命令如果出现下面的报错:
1
2
|
C:\Redis-x64-3.2.100>redis-server.exe --service-install redis.windows.conf
[7348] 20 Nov 09:34:10.403 # HandleServiceCommands: system error caught. error code=1073, message = CreateService failed: unknown error
|
说明Redis已经添加到Windows服务了,这个时候需要从服务中删除Redis服务再重新添加即可。
1
2
3
4
5
|
# 卸载原有服务
redis-server.exe --service-install
# 重新安装
redis-server.exe --service-install redis.windows.conf
|
- 当你将Redis服务添加到了Windows的服务中,我们现在可以通过命令管理Redis服务:
1
2
3
|
net start redis
net restart redis
net stop redis
|
当能成功的启动Redis服务时,说明Redis已经安装完成了。 你也可以在Windows服务中设置Redis服务为自动运行。
testing
在任意路径打开终端执行:
1
2
|
C:\Redis-x64-3.2.100>redis-cli.exe --version
redis-cli 3.2.100
|
redis-cli.exe是Redis的客户端,你也可以执行这个客户端程序进入交互式环境:
1
2
3
4
5
|
C:\Redis-x64-3.2.100>redis-cli.exe
127.0.0.1:6379> set name "zhangkai"
OK
127.0.0.1:6379> get name
"zhangkai"
|
安装完成,尽情操作吧。
Linux
centos7.9 + redis3.0.7 Redis release:http://download.redis.io/releases/
- 解决依赖问题:
1
2
3
|
[root@cs software]# pwd
/opt/software
[root@cs software]# yum -y install gcc automake autoconf libtool make
|
- 下载
tag包并解压缩, 重命名下:
1
2
3
4
|
[root@cs software]# wget http://download.redis.io/releases/redis-3.0.7.tar.gz
[root@cs software]# tar xvf redis-3.0.7.tar.gz
[root@cs software]# rm -rf redis-3.0.7.tar.gz
[root@cs software]# mv redis-3.0.7/ redis
|
- 编译安装:
1
2
3
4
|
[root@cs software]# cd redis
[root@cs redis]# pwd
/opt/software/redis
[root@cs redis]# make
|
- 将安装目录中的
src目录(该目录相当于bin)配置到/etc/profile:
1
2
3
4
5
6
|
[root@cs redis]# cd src/
[root@cs src]# pwd
/opt/software/redis/src
[root@cs src]# vim /etc/profile
export PATH=/opt/software/redis/src:$PATH
[root@cs src]# source /etc/profile
|
- 当安装成功后,我们可以在任意目录启动Redis服务:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
[root@cs src]# cd /
[root@cs /]# redis-server &
9569:C 04 Dec 20:50:06.762 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
9569:M 04 Dec 20:50:06.762 * Increased maximum number of open files to 10032 (it was originally set to 1024).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 3.0.7 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 9569
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
9569:M 04 Dec 20:50:06.763 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
9569:M 04 Dec 20:50:06.763 # Server started, Redis version 3.0.7
9569:M 04 Dec 20:50:06.763 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
9569:M 04 Dec 20:50:06.763 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
9569:M 04 Dec 20:50:06.763 * The server is now ready to accept connections on port 6379
|
现在,让我们打开一个新的终端就可以通过客户端访问服务端了:
1
2
3
4
5
6
7
|
[root@cs ~]# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
|
默认的,redis-cli会通过本地127.0.0.1:6379来访问server端,我们也可以指定ip和port来访问:
1
2
3
4
5
6
|
[root@cs ~]# redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> exit
|
OK了!
docker
- 拉取Redis镜像
# 查询可用镜像
docker search redis
# 拉取镜像, 下面命令是最新版
docker pull redis
- 查看拉取的镜像
[root@r ~]# docker images | grep redis
redis latest 4cdbec704e47 9 days ago 98.2MB
- 启动一个redis容器
# 创建本地持久化目录
[root@r ~]# mkdir -p /docker_data/redis_data/
# 启动
docker run --name myredis -p 6379:6379 --restart=always -v /docker_data/redis_data/data:/data -d redis redis-server --appendonly yes
[root@r ~]# docker run --name myredis -p 6379:6379 --restart=always -v /docker_data/redis_data:/data -d redis redis-server --appendonly yes
7c322e3633d2dfa41e0cf79a5b3aa748ccc7f18ef44c82caec6e92a46e55f8d9
[root@r ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7c322e3633d2 redis "docker-entrypoint.s…" 3 seconds ago Up 3 seconds 0.0.0.0:6379->6379/tcp myredis
参数说明:
--name myredis,指定该容器名称,查看和进行操作都比较方便-p 6379:6379,将redis的6379端口(冒号右边)映射到宿主机的6379端口(冒号左边)-v /docker_data/redis_data:/data,文件挂载-d redis redis-server,后台启动--appendonly yes,开启redis 持久化
- 测试
docker exec -it 容器ID bash
[root@r ~]# docker exec -it 7c322e3633d2 bash
root@7c322e3633d2:/data# redis-cli
127.0.0.1:6379> set name zhangkai
OK
127.0.0.1:6379> get name
"zhangkai"
127.0.0.1:6379> exit
root@7c322e3633d2:/data# exit
快速上手
本小节主要介绍,Redis安装后的基础操作。
启动和停止
启动
Redis安装成功后,有以下几种启动方式:
简单启动: 就是使用redis-server以默认配置的方式启动。生产环境用的不多。
1
|
[root@cs ~]# redis-server
|
启动后,默认监听本机6379端口。
动态参数启动:
1
|
[root@cs redis]# redis-server --port 6380
|
启动一个新的Redis实例,监听6380端口,跟之前的6379不冲突:
1
2
3
4
|
[root@cs redis]# ps -ef | grep redis-server
root 8622 1 0 10:28 ? 00:00:00 redis-server *:6379
root 8637 8548 0 10:37 pts/1 00:00:00 redis-server *:6380
root 8641 8074 0 10:38 pts/0 00:00:00 grep --color=auto redis-server
|
配置文件启动:
默认的,Redis的配置文件,在Redis的安装目录下,我们可以在启动时使用配置文件启动:
1
2
3
4
5
|
[root@cs redis]# pwd
/opt/software/redis
[root@cs redis]# ls |grep redis.conf
redis.conf
[root@cs redis]# redis-server redis.conf
|
如上示例,使用默认配置启动Redis服务。这里只做演示,工作中我们需要自己维护配置文件。
小结:
启动后,可以通过下面命令来查看Redis服务:
1
2
3
|
ps -ef | grep redis
netstat -antpl|grep redis
redis-cli -h ip -p port ping
|
对于上述三种启动方式,建议:
- 生产环境建议选择配置文件启动
- 单机多实例配置文件可以用端口进行区分
停止
可以通过客户端的命令来启动。
1
2
3
4
5
6
7
8
9
|
# 方式1,直接调用命令
[root@cs src]# redis-cli shutdown
# 方式2,进入客户端,执行命令
[root@cs src]# redis-cli
127.0.0.1:6379> shutdown
4878:M 26 Dec 19:47:02.368 # User requested shutdown...
4878:M 26 Dec 19:47:02.368 * Saving the final RDB snapshot before exiting.
4878:M 26 Dec 19:47:02.370 * DB saved on disk
4878:M 26 Dec 19:47:02.370 # Redis is now ready to exit, bye bye...
|
客户端的返回值说明
当Redis服务启动后,就可以通过Redis客户端连接它了:
1
2
3
4
5
6
7
8
|
redis-cli -h 10.0.0.200 -p 6379
> ping
PONG
> set hello world
OK
> get hello
"world"
> exit # 退出客户端,或者CTRL + C也行
|
在与客户端的交互中,通常由以下几种形式的回复。
状态回复:
错误回复:
1
2
3
4
5
6
|
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> hget hello field
(error) WRONGTYPE Operation against a key holding the wrong kind of value
|
整数回复:
1
2
|
127.0.0.1:6379> incr hello
(integer) 1
|
字符串回复:
多行字符串回复:
1
2
3
|
> mget hello foo
"world"
"bar"
|
初始配置
详细配置参考:https://www.cnblogs.com/Neeo/articles/13952586.html
通常,单机多实例环境下,都是通过端口号来区分各实例,所以我们需要自己维护配置文件,我们通常在Redis目录建立两个目录:
1
2
|
[root@cs redis]# mkdir -p /data/redis_data/6379
[root@cs redis]# vim /data/redis_data/6379/redis.conf
|
现在只需要这些初始配置即可:
1
2
3
4
5
|
daemonize yes
port 6379
logfile "/data/redis_data/6379/redis.log"
dir "/data/redis_data/6379"
dbfilename dump.rdb
|
其中:
daemonize:是否后台运行。port:Redis对外端口号,默认是6379。在单机多实例中,必须配置。logfile:Redis系统日志。dir:Redis工作目录。dbfilename:RDB持久化数据文件。
现在再次使用配置文件启动:
1
|
[root@cs redis]# redis-server /data/redis_data/6379/redis.conf
|
安全配置
我们可以通过设置配置文件来决定谁能操作Redis:
1
2
|
bind 127.0.0.1 10.0.0.200
requirepass 1234
|
其中:
bind控制谁能访问,多个IP以空格分割。requirepass控制访问密码。
注意, Redis没有用户名的概念,而且谁都可以登录到Redis,但想操作Redis的话,就要通过Redis的认证了。 所以,要想通过认证,有两种方式,第一种,登录和认证一起:
1
|
[root@cs 6379]# redis-cli -h 127.0.0.1 -p 6379 -a 1234
|
第二种, 先登录,完事再认证:
1
2
3
4
5
6
7
8
9
|
[root@cs 6379]# redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> set hello world # 认证之前,没有操作权限
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth 1234 # 认证
OK
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
|
在线查看和修改配置
我们可以在线查看和修改Redis的配置,来个示例:
1
2
3
4
5
6
|
127.0.0.1:6379> CONFIG GET bind # 查看指定配置
1) "bind"
2) "127.0.0.1 10.0.0.200"
127.0.0.1:6379> CONFIG GET * # 查看所有的配置,Redis中大约有70个配置
127.0.0.1:6379> CONFIG GET b* # 支持模糊查询
127.0.0.1:6379> CONFIG SET requirepass 1234 # 在线修改配置
|
注意,这种修改是临时,当重启Redis服务时,配置将失效,如果要永久生效,还是要将配置写入到配置文件中。
基础操作
所谓的基础操作其实就是学习对Redis的几种常用类型的相关操作。
Redis中用的最多的数据类型有String、Hash、List、Set、Zset。 而Redis的key都是字符串,不同的数据类型指的是value的类型。
key的通用操作
在Redis中的终端中,一般命令无大小写之分,也可以使用tab键补全和切换命令。
1
2
3
4
5
6
7
|
127.0.0.1:6379> keys * # 返回所有的key,尽量避免在生产中使用
127.0.0.1:6379> keys k* # 可以用模糊匹配来替代 keys *
127.0.0.1:6379> keys k1 # 返回k1
127.0.0.1:6379> type k1 # 返回k1的value类型
127.0.0.1:6379> DEL k2 # 删除一个key
127.0.0.1:6379> EXISTS k2 # 判断 key 是否存在
127.0.0.1:6379> RENAME k3 k33 # 重命名
|
设置键值对的生存时间:
1
2
3
4
5
6
7
8
9
10
11
12
|
# EXPIRE/PEXPIRE 以秒/毫秒为单位设置生存时间
# TTL/PTTL 以秒/毫秒为单位返回剩余的生存时间
# PERSIST 即在生存时间内,取消生存时间设置
127.0.0.1:6379> EXPIRE k2 20 # 为 k2 设置生存时间为20秒
(integer) 1
127.0.0.1:6379> ttl k2 # 返回 k2 剩余的生存时间
(integer) 15
127.0.0.1:6379> PERSIST k2 # 取消生存时间设置
(integer) 1
127.0.0.1:6379> ttl k2 # 表示没有设置生存时间
(integer) -1
|
注意,不要将大量的键值对设置为同一时间失效,避免造成缓存雪崩!
string
应用场景:
- session 共享
- 常规计数:评论数、粉丝数、礼物数、订阅数
字符串的相关操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
# 如果key存在,则覆盖原来的value值,若key不存在,就设置key和value
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
# 先get再set
127.0.0.1:6379> getset k1 v1 # 先get,因为k1不存在,返回空nil,然后在设置一个值v1
(nil)
127.0.0.1:6379> get k1 # 可以看到设置成功了
"v1"
127.0.0.1:6379> getset k1 v2 # 先get,获取到的值是上一次的结果,再set一个新值
"v1"
127.0.0.1:6379> get k1 # 最新值
"v2"
# 在set的时候指定存活时间,在存活时间内,可以获取到该值
127.0.0.1:6379> setex k2 10 v2
OK
127.0.0.1:6379> ttl k2
(integer) 6
127.0.0.1:6379> get k2
"v2"
127.0.0.1:6379> get k2
(nil)
# 如果key不存在,就设置一个key:value,如果key存在则什么都不做
127.0.0.1:6379> setnx k3 v3
(integer) 1
127.0.0.1:6379> get k3
"v3"
127.0.0.1:6379> setnx k3 v33
(integer) 0
127.0.0.1:6379> get k3
"v3"
# 批量设置和批量获取
127.0.0.1:6379> mset k4 v4 k5 v5 k6 v6
OK
127.0.0.1:6379> mget k4 k5 k6
1) "v4"
2) "v5"
3) "v6"
# 删除key
127.0.0.1:6379> del k1
(integer) 1
# 追加值,若key不存在,相当于add,若key存在,就是相当于拼接字符串
127.0.0.1:6379> get k5 # k5存在
"v5"
127.0.0.1:6379> append k5 5 # 因为k5存在,所以拼接字符串,并返回拼接后的字符串长度
(integer) 3
127.0.0.1:6379> get k5 # 拼接后的value
"v55"
127.0.0.1:6379> del k5
(integer) 1
127.0.0.1:6379> append k5 5 # k5不存在,相当于添加一个key:value 并返回value的长度
(integer) 1
127.0.0.1:6379> get k5 # 添加后的值
"5"
# 为指定字节位置的元素替换为指定值
127.0.0.1:6379> set k7 0123456789
127.0.0.1:6379> setrange k7 5 A # 将第5个字节位置的值替换为 A
(integer) 10
127.0.0.1:6379> get k7 # 替换后的结果
"01234A6789"
127.0.0.1:6379> setrange k7 12 BC # 如果指定的字节数超出字符串长度,就补零
(integer) 14
127.0.0.1:6379> get k7
"01234A6789\x00\x00BC"
127.0.0.1:6379> setrange k7 6 7 BC # 不允许这种将第6~7字节位置的元素替换为指定值
(error) ERR wrong number of arguments for 'setrange' command
# 判断key是否存在,存在返回1,否则返回0
127.0.0.1:6379> EXISTS k1
(integer) 1
# 如果keyy存在,返回值的长度,否则返回0
127.0.0.1:6379> get k1
"v2"
127.0.0.1:6379> STRLEN k1
(integer) 2
127.0.0.1:6379> STRLEN k222 # k222不存在
(integer) 0
# 返回字符串指定字节范围的值
127.0.0.1:6379> set k7 0123456789
OK
127.0.0.1:6379> GETRANGE k7 1 5 # 第1~5个字节范围内的值
"12345"
127.0.0.1:6379> GETRANGE k7 5 15 # 第5~15个字节范围内的值,如果字符串长度不够,以起始位置开始,有多少返回多少
"56789"
127.0.0.1:6379> GETRANGE k7 15 20 # 起始和结束范围都不在字符串范围内,返回空
""
|
上例中有对范围设置值或者取值的操作,但谨记,不能对中文这么做,因为一个中文由多个字节组成。
计数器功能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
127.0.0.1:6379> INCR num # 每次调用incr命令,num值自加一
(integer) 1
127.0.0.1:6379> INCR num
(integer) 2
127.0.0.1:6379> INCRBY num 1000 # 一次性累加指定数
(integer) 1002
127.0.0.1:6379> INCRBY num 1000
(integer) 2002
127.0.0.1:6379> INCR num
(integer) 2003
127.0.0.1:6379> DECR num # decr 使num自减一
(integer) 2002
127.0.0.1:6379> DECR num
(integer) 2001
127.0.0.1:6379> DECRBY num 1000 # 一次性累减指定数
(integer) 1001
127.0.0.1:6379> DECRBY num 1000
(integer) 1
127.0.0.1:6379> get num # 可以通过get获取该计数器的值
"1"
|
hash
应用场景:
hash类型是最接近MySQL表结构的一种类型。
使用hmset来声明一个hash类型的一组或者多组键值对;使用hmget来获取一组或者多组键值对的值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# 增,若某字段存在,就更新其value,否则就是添加key:value
127.0.0.1:6379> hmset user_1 id 1 name zhangkai age 18 gender m
OK
127.0.0.1:6379> hmset user_2 id 2 name wangkai age 20 gender m
OK
# 查
127.0.0.1:6379> hget user_1 name # 获取指定字段的值
127.0.0.1:6379> hmget user_1 id name age # 获取多个字典的值
127.0.0.1:6379> hgetall user_1 # 返回所有字段和值
127.0.0.1:6379> HKEYS user_1 # 返回key中所有的字段
127.0.0.1:6379> HVALS user_1 # 返回key中所有的字段值
127.0.0.1:6379> HEXISTS user_1 name # 判断指定字段是否存在,存在返回1,否则返回0
127.0.0.1:6379> HLEN user_1 # 返回key中所有字段的数量
# 改
127.0.0.1:6379> HINCRBY user_1 age 1 # 为整型字段的值加一
127.0.0.1:6379> hget user_1 age
127.0.0.1:6379> hset user_1 name zhangkai2 # 为指定字段重新赋值
|
list
应用场景:
- 消息队列系统
- 最新的微博消息,比如我们将最新发布的热点消息都存储到Redis中,只有翻看"历史久远"的个人信息,这类冷数据时,才去MySQL中查询
列表的特点:
- 后插入的在最前面,相当于每次都默认在索引0前面做插入操作。这个特性相当于微信朋友圈,最新发布的的动态在最上面。
- 列表内每一个元素都有自己的下标索引,从左到右,从0开始;从右到左,从
-1开始,这跟Python中的列表一样。
- 列表中的元素可重复。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
127.0.0.1:6379> LPUSH msg "message day1"
(integer) 1
127.0.0.1:6379> LPUSH msg "message day2"
(integer) 2
127.0.0.1:6379> LPUSH msg "message day3"
(integer) 3
127.0.0.1:6379> LPUSH msg "message day4"
(integer) 4
127.0.0.1:6379> LRANGE msg 0 -1
1) "message day4"
2) "message day3"
3) "message day2"
4) "message day1"
|
来看操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# 增
LPUSH l1 a b # 如果 l1 不存在就创建,然后将 a b 插入到 l1 中,如果 l1 存在,直接将 a b 插入到 l1 中
LPUSHX l1 c # 如果 key 存在则插入,不存在则什么也不做
LINSERT l1 before a a1 # 在元素 a 前面插入 a1
LINSERT l1 after a a2 # 在元素 a 后插入 a2
RPUSH l1 1 # 在列表尾部追加 元素 1
RPUSH l1 2 3 # 在列表尾部先追加 2 再追加 3
RPUSHX l1 4 # 如果列表 l1 存在就将元素4追加到列表尾部,如果列表不存在则什么也不做
# 查,根据索引下标取值
LRANGE l1 0 -1 # 从索引0开始取到-1,也就是从头取到尾,获取列表中的所有元素
LRANGE l1 0 2 # 取索引 0 1 2 三个索引对应的元素
LRANGE l1 0 0 # 取索引 0 对应的元素
LRANGE l1 10 15 # 如果索引不在合法范围内,则取空
LINDEX l1 1 # 根据索引下标返回元素
# 删除
LPOP l1 # 抛出列表头部元素
RPOP l1 # 抛出列表尾部元素
RPOPLPUSH l1 l2 # 将列表 l1 尾部的元素抛出并且添加到列表 l2 中
LREM l1 2 a1 # 从左到右,删除指定个数的元素 a1 ,本示例中,若 a1 有 1 个,就删一个,若 a1 有 3 个或者更多,也就删除 2 个
LTRIM l1 2 4 # 保留索引2-4的元素,其余删除
# 改
LSET l1 0 a # 将列表索引为0的元素修改为指定值,如果索引位置不存在则报错
POPLPUSH l1 l1 # 将列表尾部的元素抛出并插入到列表的头部
|
set
集合的应用场景:
- 适用于各种需要求交集、并集、差集的场景,比如共同好友,共同关注的场景。
- 另外这里的集合也有数学上的集合特性,去重,交、并、差集的运算。
基础操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# 增,声明key并添加 a b c 三个元素
127.0.0.1:6379> sadd s1 a b c
# 查
127.0.0.1:6379> SMEMBERS s1 # 返回 s1 中所有元素
127.0.0.1:6379> SCARD s1 # 返回 s1 中元素的个数
127.0.0.1:6379> SRANDMEMBER s1 # 随机返回集合中的元素
127.0.0.1:6379> SISMEMBER s1 a # 判断元素 a 是否存在
# 删除
127.0.0.1:6379> SPOP s1 # 随机删除一个元素,并将这个元素返回
127.0.0.1:6379> del s1 # 删除 key
# 移动
127.0.0.1:6379> smove s1 s2 a # 将元素 a 从s1移动到s2中,如果s2不存在,就先创建再移动
|
再来看集合的运算。我们来个示例,有个需求,现有个培训学校欧德博爱开设了Python和Linux两门课程,来学习的同学都有如下情况:
- 有的同学学习Linux
- 有的学习Python
- 还有的既学了Linux又学了Python
那现在问题来了,我们要对这些同学的情况做统计,比如找出两门课都报了的同学?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
# 先把数据准备好
127.0.0.1:6379> sadd python xiaoA xiaoB xiaoC xiaoMaque Huluwa
127.0.0.1:6379> sadd linux xiaoC xiaoD xiaoE xiaoDongbei xiaoMaque
# 求交集,找出即学习了Python又学习了Linux的同学
127.0.0.1:6379> SINTER python linux
1) "xiaoC"
2) "xiaoMaque"
# 求并集,找出学习两门课程的所有人
127.0.0.1:6379> SUNION python linux
1) "xiaoC"
2) "xiaoA"
3) "xiaoD"
4) "xiaoDongbei"
5) "xiaoMaque"
6) "xiaoB"
7) "xiaoE"
8) "Huluwa"
# 求差集,找出只学习了Python(或者Linux)课程的人
127.0.0.1:6379> SDIFF python linux # 只学习Python课程的人
1) "xiaoA"
2) "Huluwa"
3) "xiaoB"
127.0.0.1:6379> SDIFF linux python # 只学习Linux课程的人
1) "xiaoE"
2) "xiaoD"
3) "xiaoDongbei"
# 集合 a 和 b 先求差集,将结果再和 c 求差集
127.0.0.1:6379> sadd tmp Huluwa xiaoDongbei # Huluwa是学习python的人,xiaoDongbei是学习Linux的人
127.0.0.1:6379> SDIFF python linux tmp # 先求只学习了python课程的人,然后拿着这些人去和 tmp 集合再次求差集
1) "xiaoA"
2) "xiaoB"
127.0.0.1:6379> SDIFF linux python tmp # 先求只学习了Linux课程的人,然后拿着这些人去和 tmp 集合再次求差集
1) "xiaoE"
2) "xiaoD"
# 集合 a 分别和 b、c求差集,并将结果保存到 s 中
127.0.0.1:6379> SDIFFSTORE s2 python linux tmp # 集合python分别和 Linux、tmp求差集,将结果保存到 s2 中, s2 不存在就先创建
(integer) 2
127.0.0.1:6379> SMEMBERS s2
1) "xiaoA"
2) "xiaoB"
127.0.0.1:6379> SDIFFSTORE s3 linux python tmp # 集合Linux分别和 Python、tmp求差集,将结果保存到 s3 中, s3 不存在就先创建
(integer) 2
127.0.0.1:6379> SMEMBERS s3
1) "xiaoE"
2) "xiaoD"
127.0.0.1:6379> SINTER python linux tmp # 求三个集合的交集,但这个示例中他们的交集为空
127.0.0.1:6379> SINTERSTORE s4 python linux tmp # 求三个集合的交集,然后将结果保存到 s4 中,这个示例中,s4 也为空
127.0.0.1:6379> SUNION python linux tmp # 求三个集合的并集
127.0.0.1:6379> SUNIONSTORE s5 python linux tmp # 求三个集合的并集,然后将结果保存到 s5 中
|
Zset
有序集合在集合的基础上增加了排序功能,比如以点击数为条件进行排序。 有序集合的典型应用场景:
在有序集合中,我们一般称其元素为成员,其成员对应的值为分数。 来个音乐排行榜的示例:
# 创建初始的音乐排行榜,初始每首歌播放量都是0
127.0.0.1:6379> ZADD topN 0 aiqing 0 guxiang 0 lanlianhua 0 shiguang
# 模拟每首歌的播放量
127.0.0.1:6379> ZINCRBY topN 123 aiqing
"123"
127.0.0.1:6379> ZINCRBY topN 223 guxiang
"223"
127.0.0.1:6379> ZINCRBY topN 2323 lanlianhua
"2323"
127.0.0.1:6379> ZINCRBY topN 23 shiguang
# 返回播放量前三名的歌名
127.0.0.1:6379> ZREVRANGE topN 0 2
1) "lanlianhua"
2) "guxiang"
3) "aiqing"
# 返回播放量前三名的歌名和播放量
127.0.0.1:6379> ZREVRANGE topN 0 2 withscores
1) "lanlianhua"
2) "2323"
3) "guxiang"
4) "223"
5) "aiqing"
6) "123"
基础操作:
# 增
ZADD topN 0 disanji 0 jiandan # 为topN添加两个成员,并且设置初始值
# 查, withscores是可选参数
ZSCORE topN shiguang # 返回topN中,指定成员的分数,如果指定成员不存在则返回nil
ZRANGE topN 0 -1 # 返回topN中所有成员,默认以时间排序,即最后添加在最前面
ZRANGE topN 0 -1 withscores # 返回topN中所有成员和它的分数
ZRANK topN shiguang # 返回成员在有序集合中的索引下标,如果成员不存在返回nil
ZCARD topN # 返回topN中成员的数量
ZCOUNT topN 20 200 # 返回topN中分数在 20 <= 分数 <= 200 这个范围内的成员的数量
ZRANGEBYSCORE topN 20 200 # 返回topN中分数在 20 <= 分数 <= 200 这个范围内的成员
ZRANGEBYSCORE topN -inf +inf # 返回topN中所有成员,-inf表示第一个成员,+inf表示最后一个成员,结果默认以其分数的大小排序
ZRANGEBYSCORE topN -inf +inf withscores # 返回topN中所有成员和分数
ZREMRANGEBYSCORE topN 2200 2400 # 删除分数在指定范围内的成员,并返回删除成员的数量
ZREMRANGEBYRANK topN 0 1 # 删除topN中指定索引范围内 0 <= index <= 1 的成员
ZREVRANGE topN 0 -1 # 返回topN中所有成员,并且以索引从大到小排序
ZREVRANGE topN 0 2 # 返回topN中 0 <= index <= 2 索引范围内的成员
ZREVRANGEBYSCORE topN 100 20 # 返回topN中分数范围在 100 <= 的 <= 20 范围内的成员,并以的的大小降序排序
# 改
ZADD topN 23231 shiguang # 为指定成员重新赋值
ZINCRBY topN 2 shiguang # 为指定成员增加指定分数,并返回增加后的分数
# 删除
DEL topN # 删除key
ZREM topN shiguang aiqing # 删除topN中一个或者多个成员,返回实际删除的个数
进阶操作
本小节来研究Redis中稍微进阶的操作,如事务、发布订阅模式这些。
发布订阅
消息队列
Redis中的发布订阅模式,类似于RabbitMQ中的主题订阅模式。 在发布订阅模式中,有三个角色:
- 生产者,它同样是一个redis客户端,负责生产消息。可以有一个或者多个生产者往一个或者多个频道中发布消息。
- channel,频道,类似于主题,接收来自于生产者产生的消息,为不同的消息打个标签,可以有多个频道。它维护在redis的server中。
- 消费者,也是一个Redis客户端,可以订阅感兴趣的消息,也就是可以(一个或者多个)订阅不同频道的消息。

如上图,有三个生产者负责生产消息,并且发布到指定的频道中,消费者可以选择订阅一个或者多个频道中的消息。
操作:
# 首先要现有多个消费者订阅不同的频道,订阅一个、多个、模糊匹配;你可以起三个终端来分别订阅
SUBSCRIBE fm103
SUBSCRIBE fm103 fm104
PSUBSCRIBE fm*
# 然后有不同的生产者往指定的频道生产消息,可以用三个终端来发布消息,也可以用一个也行,分别向不同的频道发布消息
PUBLISH fm103 "fm103.9 it's my radio, messages1"
PUBLISH fm103 "fm103.9 it's my radio, messages2"
PUBLISH fm103 "fm103.9 it's my radio, messages3"
PUBLISH fm104 "fm104.9 it's my radio, messages1"
PUBLISH fm104 "fm104.9 it's my radio, messages2"
PUBLISH fm104 "fm104.9 it's my radio, messages3"
PUBLISH fm105 "fm105.9 it's my radio, messages1"
PUBLISH fm105 "fm105.9 it's my radio, messages2"
PUBLISH fm105 "fm105.9 it's my radio, messages3"
上述几个消费者就能根据自己的规则接收到不同的频道的消息,其效果如下图: 这里需要注意的是,消费者不会接收频道的历史消息,只会接受订阅后产生的消息。
这里需要注意的是,消费者不会接收频道的历史消息,只会接受订阅后产生的消息。
其他操作:
# 取消订阅频道
UNSUBSCRIBE # 不跟频道号则取消订阅所有频道
UNSUBSCRIBE fm103 # 取消订阅fm103频道
UNSUBSCRIBE fm103 fm104 # 取消订阅多个频道
UNSUBSCRIBE fm* # 取消订阅以fm开头的频道
Redis的发布订阅模式不如专业的消息队列软件实现的功能多,所以用的较少些!这里不在多表。
事务
Redis的事务是基于队列实现的;而MySQL的事务是基于事务日志和锁机制实现;Redis是乐观锁机制。
Redis使用mulit开启事务,即事务中的修改操作都会push到队列中,此时并没有执行修改命令,什么时候提交事务呢?当你exec时,Redis会将事务队列中的命令操作都一一的执行一边;所以Redis的回滚也非常的简单,直接把事务队列删除就完了,命令是discard。
操作:
# 正常开启并提交事务的示例
127.0.0.1:6379> MULTI # 使用multi开启事务
OK
127.0.0.1:6379> set t1 a # 操作,返回了queued,说明把操作放到了事务队列中了
QUEUED
127.0.0.1:6379> set t1 b
QUEUED
127.0.0.1:6379> EXEC # 提交事务
1) OK
2) OK
127.0.0.1:6379> get t1 # 结果正常
"b"
# 回滚的事务示例
127.0.0.1:6379> EXISTS t2 # 首先,key不存在
(integer) 0
127.0.0.1:6379> MULTI # 开启事务
OK
127.0.0.1:6379> set t2 a
QUEUED
127.0.0.1:6379> DISCARD # 回滚,即把事务队列删除
OK
127.0.0.1:6379> EXISTS t2 # 可以看到事务没有执行成功,key仍然不存在
(integer) 0
由于Redis是乐观锁机制,所以它允许多个客户端同时操作同一个key,这点和MySQL不一样,MySQL遇到这种情况,当一个客户端在修改一条记录时,会加个锁,别的客户端要修改这条记录,会遇到锁等待。 那Redis是如何处理这种情况呢?答案非常简单,哪个事务先提交就以哪个事务为准。
使用Redis的事务模拟抢票的示例,第一回合:
可以看到,应该当余票为0时,就不能在下单成功了!所以,要完善这个示例,就要用到新的命令watch,该命令用于监控指定的key,如果在事务执行之前,检测到这个key被别的事务所修改,那么就会终止当前事务的执行,即让当前事务执行失败。 第二回合:

持久化
所谓持久化,就是将缓存的数据刷写到磁盘,达到持久化和数据恢复的目的。
在Redis中,有RDB快照(snapshotting)和AOF(appendonly-file)两种持久化方式。 我们分别来看看。
RDB快照
RDB有两种触发方式,分别是手动触发和自动触发。 无论如何触发,都是以覆盖写的形式写入到同一份RDB文件中。
手动触发
手动触发这里介绍两个命令:
save,同步命令,也就是该命令会占用Redis的主进程,在save命令执行期间,Redis将会阻塞所有的客户端请求,所以,当数据量非常大使,不推荐使用该命令。bgsave,异步命令,Redis使用Linux的fork()生成一个子进程来做持久化的工作,而主进程则继续提供其他服务。
手动触发这里只需要在配置文件中配置:
1
2
|
dir "/data/redis_data/6379" # 持久化文件保存的目录
dbfilename dump.rdb # 持久化文件名,可以带端口号也可以不带 dump-6379.rdb
|
完事重启Redis服务,就可以在线执行持久化操作了:
1
2
3
4
5
6
7
8
9
|
[root@cs 6379]# ls # 在save执行之前,还没有 rdb 文件
redis.conf redis.log
[root@cs 6379]# redis-cli -h 127.0.0.1 -p 6379 -a 1234
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> save # 持久化
OK
[root@cs 6379]# ls # 现在就有了
dump.rdb redis.conf redis.log
|
来个bgsave的演示:
1
2
3
|
[root@cs 6379]# redis-cli -h 127.0.0.1 -p 6379 -a 1234
127.0.0.1:6379> bgsave
Background saving started
|
save和bgsave对比:
| 命令 | save | bgsave |
|---|
| I/O类型 |
同步 |
异步 |
| 是否阻塞 |
是 |
是(阻塞发生在fock()阶段,但通常非常快) |
| 复杂度 |
O(n) |
O(n) |
| 优点 |
不会消耗额外的内存 |
不阻塞客户端命令 |
| 缺点 |
阻塞客户端命令 |
需要fork子进程,消耗额外内存 |
当然了,生产中一般不会使用上述两个命令,而是使用自动触发机制。
自动触发
自动触发需要在配置文件中配置了,如下示例介绍了RDB的相关配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
# RDB 自动持久化规则
# 当 900 秒内至少有 1 个key被改动时,自动执行持久化操作
save 900 1
# 当 300 秒内至少有 10 个key被改动时,自动执行持久化操作
save 300 10
# 当 60 秒内至少有 10000 个key被改动时,自动执行持久化操作
save 60 10000
# 数据持久化文件存储目录
dir "/data/redis_data/6379"
# RDB持久化文件名
dbfilename dump.rdb # 持久化文件名,可以带端口号也可以不带 dump-6379.rdb
# bgsave过程中发生错误时,是否停止写入,通常为 yes
rdbcompression yes
# 是否对RDB文件进行校验,通常为 yes
rdbchecksum yes
|
RDB的优点:
- RDB是一个非常紧凑的文件,它保存了某个时间点得数据集,非常适用于数据集的备份,比如你可以在每个小时报保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集。
- RDB是一个紧凑的单一文件,很方便传送到另一个远端数据中心,非常适用于灾难恢复。
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能。
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些。
RDB缺点:
- 耗时、耗性能。RDB 需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求。如果数据集巨大并且CPU性能不是很好的情况下,这种情况会持续1秒,AOF也需要fork,但是你可以调节重写日志文件的频率来提高数据集的耐久度。
- 不可控、丢失数据。如果你希望在redis意外停止工作(例如电源中断)的情况下丢失的数据最少的话,那么RDB不适合你。虽然你可以配置不同的save时间点(例如每隔5分钟并且对数据集有100个写的操作),是Redis要完整的保存整个数据集是一个比较繁重的工作,你通常会每隔5分钟或者更久做一次完整的保存,万一在Redis意外宕机,你可能会丢失几分钟的数据。
使用RDB文件恢复数据
当只配置了RDB的持久化时,重启Redis服务时,会自动读取RDB文件进行数据恢复。
AOF
RDB持久化并不是完美的,如果Redis因为某些原因造成了宕机,那么将会丢失最近写入、但并未保存到快照中的数据。 在Redis1.1开始,增加了AOF来补充RDB的不足。 AOF持久化的工作机制是,每当Redis执行修改数据集的命令时,这个命令就会被追加到AOF文件的末尾。数据恢复时重放这个AOF文件即可恢复数据。数到这里,你有没有想到MySQL binlog…. 我们可以在配置文件中开启AOF:
1
2
|
appendonly yes
appendsync always/everyesc/no
|
其中:
appendonly:是(yes)否(no)开启AOF持久化,默认appendsync: 触发持久化的条件,有下面三种选项:
always:每当修改数据集都会记录,慢但非常安全。everysec:每秒钟fync一次,足够快(和使用 RDB 持久化差不多),就算有故障时也只会丢失 1 秒钟的数据。推荐(并且也是默认)使用该策略, 这种 fsync 策略可以兼顾速度和安全性。no:由操作系统来决定什么时候同步数据。更快,也更不安全的选择,这个选项不常用。
AOF重写机制 因为AOF会一直将命令追加到文件末尾,导致该文件的体积会越来越大,而且它会保存一些重复性的命令,而这些重复性的命令可以用一条或者极少的命令就能替代…. 为了优化这种情况,Redis支持:在不妨碍正常处理客户端请求中,对AOF文件进行重建(rebuild),也就是执行bgrewriteaof命令,会生成一个新的AOF文件,这个文件包含重建当前数据集所需要的最少命令。 在Redis2.2版本之前,需要手动执行bgrewriteaof命令,该命令会异步执行一个AOF文件重写操作,重写时会创建一个当前AOF文件的优化版本,即使bgrewriteaof执行失败,也不会有任何数据丢失,因为旧的AOF文件在bgrewriteaof执行成功之前不会被修改和覆盖。 到了Redis2.4则开始支持配置自动触发AOF重写机制了。 AOF重写机制的特点:减少AOF文件对磁盘的空间占用;加速数据恢复。
相关参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# 开启AOF持久化方式
appendonly yes
# AOF持久化文件名
appendfilename appendonly-<port>.aof
# 每秒把缓冲区的数据同步到磁盘
appendfsync everysec
# 数据持久化文件存储目录
dir "/data/redis_data/6379"
# 是否在执行重写时不同步数据到AOF文件
# 这里的 yes,就是执行重写时不同步数据到AOF文件
no-appendfsync-on-rewrite yes
# 触发AOF文件执行重写的最小尺寸
auto-aof-rewrite-min-size 64mb
# 触发AOF文件执行重写的增长率
auto-aof-rewrite-percentage 100
|
关于AOF重写,当AOF文件的体积大于64Mb,并且AOF文件的体积比上一次重写之久的体积大了至少一倍(100%)时,Redis将执行 bgrewriteaof 命令进行重写。
AOF的优点
- 使用AOF 会让你的Redis更加耐久: 你可以使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync。使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据。
- AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用redis-check-aof工具修复这些问题。
- Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。 AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF的缺点
- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
持久化小结
RDB和AOF对比:
| 选项 | RDB | AOF |
|---|
| 数据恢复优先级 |
低 |
高 |
| 体积 |
小 |
大 |
| 恢复速度 |
快 |
慢 |
| 数据安全性 |
丢数据 |
根据策略决定 |
注意,这两种持久化方式可以同时使用,只不过日志量比较大而已;但生产中一般都是二选一;但在数据恢复中,优先选择AOF。
一般来说,如果想要保证足够的数据安全性,你应该同时使用两种持久化功能。 当然,AOF也是好的选择,而RDB文件则非常适合做备份,并且数据恢复也更快些。
最后,如果同时配置了RDB和AOF,那么在数据恢复时,Redis会优先选择AOF文件进行数据恢复,如果你就想使用RDB恢复怎么办?可以在配置文件中先把AOF关闭,然后重启Redis,恢复完数据,在线开启AOF即可。
疯狂面试题
参考:https://www.cnblogs.com/Neeo/articles/10521013.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号