库、表的详细操作
1、创建数据库
1.1 语法
CREATE DATABASE 数据库名 charset utf8;
1.2 数据库命名规则
可以由字母、数字、下划线、@、#、$
区分大小写
唯一性
不能使用关键字如 create select
不能单独使用数字
最长128位
# 基本上跟python或者js的命名规则一样
2、数据库相关操作
也是一些基本操作,和我们之前说的差不多。

1 查看数据库 show databases; show create database db1; select database(); 2 选择数据库 USE 数据库名 3 删除数据库 DROP DATABASE 数据库名; 4 修改数据库 alter database db1 charset utf8;
关于库的内容,咱们就说这些吧,哈哈,有点少是吧,不是咱们的重点,来看下面的表操作~~~
1、存储引擎
存储引擎即表类型,mysql根据不同的表类型会有不同的处理机制,关于存储引擎的介绍看我这篇博客:https://www.cnblogs.com/clschao/articles/9953550.html
2、表介绍
表相当于文件,表中的一条记录就相当于文件的一行内容,表中的一条记录有对应的标题,称为表的字段
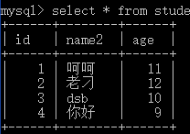
第一行的id、name2、age是字段,,其余的,一行内容称为一条记录。
3、创建表
3.1 建表语法
#语法: create table 表名( 字段名1 类型[(宽度) 约束条件], 字段名2 类型[(宽度) 约束条件], 字段名3 类型[(宽度) 约束条件] ); #注意: 1. 在同一张表中,字段名是不能相同 2. 宽度和约束条件可选、非必须,宽度指的就是字段长度约束,例如:char(10)里面的10 3. 字段名和类型是必须的


mysql> create database db1 charset utf8; mysql> use db1; mysql> create table t1( -> id int, -> name varchar(50), -> sex enum('male','female'), -> age int(3) -> ); mysql> show tables; #查看db1库下所有表名 mysql> desc t1; +-------+-----------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-----------------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | name | varchar(50) | YES | | NULL | | | sex | enum('male','female') | YES | | NULL | | | age | int(3) | YES | | NULL | | +-------+-----------------------+------+-----+---------+-------+ mysql> select id,name,sex,age from t1; Empty set (0.00 sec) mysql> select * from t1; Empty set (0.00 sec) mysql> select id,name from t1; Empty set (0.00 sec)
mysql> insert into t1 values -> (1,'chao',18,'male'), -> (2,'sb',81,'female') -> ; mysql> select * from t1; +------+------+------+--------+ | id | name | age | sex | +------+------+------+--------+ | 1 | chao | 18 | male | | 2 | sb | 81 | female | +------+------+------+--------+ mysql> insert into t1(id) values -> (3), -> (4); mysql> select * from t1; +------+------+------+--------+ | id | name | age | sex | +------+------+------+--------+ | 1 | chao | 18 | male | | 2 | sb | 81 | female | | 3 | NULL | NULL | NULL | | 4 | NULL | NULL | NULL | +------+------+------+--------+
4、查看表结构
mysql> describe t1; #查看表结构,可简写为:desc 表名 +-------+-----------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-----------------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | name | varchar(50) | YES | | NULL | | | sex | enum('male','female') | YES | | NULL | | | age | int(3) | YES | | NULL | | +-------+-----------------------+------+-----+---------+-------+ mysql> show create table t1\G; #查看表详细结构,可加\G
5、MySQL的基础数据类型
一 介绍
存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,每种数据类型都有自己的宽度,但宽度是可选的
详细参考:
- http://www.runoob.com/mysql/mysql-data-types.html
- http://dev.mysql.com/doc/refman/5.7/en/data-type-overview.html
mysql常用数据类型概览:
#1. 数字: 整型:tinyinit int bigint 小数: float :在位数比较短的情况下不精准 double :在位数比较长的情况下不精准 0.000001230123123123 存成:0.000001230000 decimal:(如果用小数,则用推荐使用decimal) 精准 内部原理是以字符串形式去存 #2. 字符串: char(10):简单粗暴,浪费空间,存取速度快 root存成root000000 varchar:精准,节省空间,存取速度慢 sql优化:创建表时,定长的类型往前放,变长的往后放 比如性别 比如地址或描述信息 >255个字符,超了就把文件路径存放到数据库中。 比如图片,视频等找一个文件服务器,数据库中只存路径或url。 #3. 时间类型: 最常用:datetime #4. 枚举类型与集合类型
二 数值类型
1、整数类型
整数类型:TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT
作用:存储年龄,等级,id,各种号码等
tinyint[(m)] [unsigned] [zerofill] 小整数,数据类型用于保存一些范围的整数数值范围: 有符号: -128 ~ 127 无符号: 0 ~ 255 PS: MySQL中无布尔值,使用tinyint(1)构造。 int[(m)][unsigned][zerofill] 整数,数据类型用于保存一些范围的整数数值范围: 有符号: -2147483648 ~ 2147483647 无符号: 0 ~ 4294967295 bigint[(m)][unsigned][zerofill] 大整数,数据类型用于保存一些范围的整数数值范围: 有符号: -9223372036854775808 ~ 9223372036854775807 无符号: 0 ~ 18446744073709551615
有符号和无符号tinyint 1.tinyint默认为有符号 mysql> create table t1(x tinyint); #默认为有符号,即数字前有正负号 mysql> desc t1; mysql> insert into t1 values -> (-129), -> (-128), -> (127), -> (128); mysql> select * from t1; +------+ | x | +------+ | -128 | #-129存成了-128 | -128 | #有符号,最小值为-128 | 127 | #有符号,最大值127 | 127 | #128存成了127 +------+ 2.设置无符号tinyint mysql> create table t2(x tinyint unsigned); mysql> insert into t2 values -> (-1), -> (0), -> (255), -> (256); mysql> select * from t2; +------+ | x | +------+ | 0 | -1存成了0 | 0 | #无符号,最小值为0 | 255 | #无符号,最大值为255 | 255 | #256存成了255 +------+ 有符号和无符号int 1.int默认为有符号 mysql> create table t3(x int); #默认为有符号整数 mysql> insert into t3 values -> (-2147483649), -> (-2147483648), -> (2147483647), -> (2147483648); mysql> select * from t3; +-------------+ | x | +-------------+ | -2147483648 | #-2147483649存成了-2147483648 | -2147483648 | #有符号,最小值为-2147483648 | 2147483647 | #有符号,最大值为2147483647 | 2147483647 | #2147483648存成了2147483647 +-------------+ 2.设置无符号int mysql> create table t4(x int unsigned); mysql> insert into t4 values -> (-1), -> (0), -> (4294967295), -> (4294967296); mysql> select * from t4; +------------+ | x | +------------+ | 0 | #-1存成了0 | 0 | #无符号,最小值为0 | 4294967295 | #无符号,最大值为4294967295 | 4294967295 | #4294967296存成了4294967295 +------------+ 有符号和无符号bigint 1.有符号bigint mysql> create table t6(x bigint); mysql> insert into t5 values -> (-9223372036854775809), -> (-9223372036854775808), -> (9223372036854775807), -> (9223372036854775808); mysql> select * from t5; +----------------------+ | x | +----------------------+ | -9223372036854775808 | | -9223372036854775808 | | 9223372036854775807 | | 9223372036854775807 | +----------------------+ 2.无符号bigint mysql> create table t6(x bigint unsigned); mysql> insert into t6 values -> (-1), -> (0), -> (18446744073709551615), -> (18446744073709551616); mysql> select * from t6; +----------------------+ | x | +----------------------+ | 0 | | 0 | | 18446744073709551615 | | 18446744073709551615 | +----------------------+ 用zerofill测试整数类型的显示宽度 mysql> create table t7(x int(3) zerofill); mysql> insert into t7 values -> (1), -> (11), -> (111), -> (1111); mysql> select * from t7; +------+ | x | +------+ | 001 | | 011 | | 111 | | 1111 | #超过宽度限制仍然可以存 +------+
注意:对于整型来说,数据类型后面的宽度并不是存储长度限制,而是显示限制,假如:int(8),那么显示时不够8位则用0来填充,够8位则正常显示,通过zerofill来测试,存储长度还是int的4个字节长度。默认的显示宽度就是能够存储的最大的数据的长度,比如:int无符号类型,那么默认的显示宽度就是int(10),有符号的就是int(11),因为多了一个符号,所以我们没有必要指定整数类型的数据,没必要指定宽度,因为默认的就能够将你存的原始数据完全显示

int的存储宽度是4个Bytes,即32个bit,即2**32
无符号最大值为:4294967296-1
有符号最大值:2147483648-1
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完全,所以int类型默认的显示宽度为11是非常合理的
最后:整形类型,其实没有必要指定显示宽度,使用默认的就ok
2、浮点型
定点数类型 DEC,等同于DECIMAL
浮点类型:FLOAT DOUBLE
作用:存储薪资、身高、温度、体重、体质参数等
1.FLOAT[(M,D)] [UNSIGNED] [ZEROFILL] 定义: 单精度浮点数(非准确小数值),m是整数部分+小数部分的总个数,d是小数点后个数。m最大值为255,d最大值为30,例如:float(255,30) 有符号: -3.402823466E+38 to -1.175494351E-38, 1.175494351E-38 to 3.402823466E+38 无符号: 1.175494351E-38 to 3.402823466E+38 精确度: **** 随着小数的增多,精度变得不准确 **** 2.DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] 定义: 双精度浮点数(非准确小数值),m是整数部分+小数部分的总个数,d是小数点后个数。m最大值也为255,d最大值也为30 有符号: -1.7976931348623157E+308 to -2.2250738585072014E-308 2.2250738585072014E-308 to 1.7976931348623157E+308 无符号: 2.2250738585072014E-308 to 1.7976931348623157E+308 精确度: ****随着小数的增多,精度比float要高,但也会变得不准确 **** 3.decimal[(m[,d])] [unsigned] [zerofill] 定义: 准确的小数值,m是整数部分+小数部分的总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。比float和double的整数个数少,但是小数位数都是30位 精确度: **** 随着小数的增多,精度始终准确 **** 对于精确数值计算时需要用此类型 decimal能够存储精确值的原因在于其内部按照字符串存储。 精度从高到低:decimal、double、float decimal精度高,但是整数位数少 float和double精度低,但是整数位数多 float已经满足绝大多数的场景了,但是什么导弹、航线等要求精度非常高,所以还是需要按照业务场景自行选择,如果又要精度高又要整数位数多,那么你可以直接用字符串来存。
mysql> create table t1(x float(256,31)); ERROR 1425 (42000): Too big scale 31 specified for column 'x'. Maximum is 30. mysql> create table t1(x float(256,30)); ERROR 1439 (42000): Display width out of range for column 'x' (max = 255) mysql> create table t1(x float(255,30)); #建表成功 Query OK, 0 rows affected (0.02 sec) mysql> create table t2(x double(255,30)); #建表成功 Query OK, 0 rows affected (0.02 sec) mysql> create table t3(x decimal(66,31)); ERROR 1425 (42000): Too big scale 31 specified for column 'x'. Maximum is 30. mysql> create table t3(x decimal(66,30)); ERROR 1426 (42000): Too-big precision 66 specified for 'x'. Maximum is 65. mysql> create table t3(x decimal(65,30)); #建表成功 Query OK, 0 rows affected (0.02 sec) mysql> show tables; +---------------+ | Tables_in_db1 | +---------------+ | t1 | | t2 | | t3 | +---------------+ 3 rows in set (0.00 sec) mysql> insert into t1 values(1.1111111111111111111111111111111); #小数点后31个1 Query OK, 1 row affected (0.01 sec) mysql> insert into t2 values(1.1111111111111111111111111111111); Query OK, 1 row affected (0.00 sec) mysql> insert into t3 values(1.1111111111111111111111111111111); Query OK, 1 row affected, 1 warning (0.01 sec) mysql> select * from t1; #随着小数的增多,精度开始不准确 +----------------------------------+ | x | +----------------------------------+ | 1.111111164093017600000000000000 | +----------------------------------+ 1 row in set (0.00 sec) mysql> select * from t2; #精度比float要准确点,但随着小数的增多,同样变得不准确 +----------------------------------+ | x | +----------------------------------+ | 1.111111111111111200000000000000 | +----------------------------------+ 1 row in set (0.00 sec) mysql> select * from t3; #精度始终准确,d为30,于是只留了30位小数 +----------------------------------+ | x | +----------------------------------+ | 1.111111111111111111111111111111 | +----------------------------------+ 1 row in set (0.00 sec)
3、位类型(了解,不讲~~)
BIT(M)可以用来存放多位二进制数,M范围从1~64,如果不写默认为1位。
注意:对于位字段需要使用函数读取
bin()显示为二进制
hex()显示为十六进制
mysql> create table t9(id bit); mysql> desc t9; #bit默认宽度为1 +-------+--------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+--------+------+-----+---------+-------+ | id | bit(1) | YES | | NULL | | +-------+--------+------+-----+---------+-------+ mysql> insert into t9 values(8); mysql> select * from t9; #直接查看是无法显示二进制位的 +------+ | id | +------+ | | +------+ mysql> select bin(id),hex(id) from t9; #需要转换才能看到 +---------+---------+ | bin(id) | hex(id) | +---------+---------+ | 1 | 1 | +---------+---------+ mysql> alter table t9 modify id bit(5); mysql> insert into t9 values(8); mysql> select bin(id),hex(id) from t9; +---------+---------+ | bin(id) | hex(id) | +---------+---------+ | 1 | 1 | | 1000 | 8 | +---------+---------+
三 日期类型
类型:DATE,TIME,DATETIME ,IMESTAMP,YEAR
作用:存储用户注册时间,文章发布时间,员工入职时间,出生时间,过期时间等
YEAR YYYY(范围:1901/2155)2018 DATE YYYY-MM-DD(范围:1000-01-01/9999-12-31)例:2018-01-01 TIME HH:MM:SS(范围:'-838:59:59'/'838:59:59')例:12:09:32 DATETIME YYYY-MM-DD HH:MM:SS(范围:1000-01-01 00:00:00/9999-12-31 23:59:59 Y)例: 2018-01-01 12:09:32 TIMESTAMP YYYYMMDD HHMMSS(范围:1970-01-01 00:00:00/2037 年某时)
year: mysql> create table t10(born_year year); #无论year指定何种宽度,最后都默认是year(4) mysql> insert into t10 values -> (1900), -> (1901), -> (2155), -> (2156); mysql> select * from t10; +-----------+ | born_year | +-----------+ | 0000 | | 1901 | | 2155 | | 0000 | +-----------+ date,time,datetime: mysql> create table t11(d date,t time,dt datetime); mysql> desc t11; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | d | date | YES | | NULL | | | t | time | YES | | NULL | | | dt | datetime | YES | | NULL | | +-------+----------+------+-----+---------+-------+ mysql> insert into t11 values(now(),now(),now()); mysql> select * from t11; +------------+----------+---------------------+ | d | t | dt | +------------+----------+---------------------+ | 2017-07-25 | 16:26:54 | 2017-07-25 16:26:54 | +------------+----------+---------------------+ timestamp: mysql> create table t12(time timestamp); mysql> insert into t12 values(); mysql> insert into t12 values(null); mysql> select * from t12; +---------------------+ | time | +---------------------+ | 2017-07-25 16:29:17 | | 2017-07-25 16:30:01 | +---------------------+ ============注意啦,注意啦,注意啦=========== 1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入 2. 插入年份时,尽量使用4位值 3. 插入两位年份时,<=69,以20开头,比如50, 结果2050 >=70,以19开头,比如71,结果1971 mysql> create table t12(y year); mysql> insert into t12 values -> (50), -> (71); mysql> select * from t12; +------+ | y | +------+ | 2050 | | 1971 | +------+ ============综合练习=========== mysql> create table student( -> id int, -> name varchar(20), -> born_year year, -> birth date, -> class_time time, -> reg_time datetime); mysql> insert into student values -> (1,'sb1',"1995","1995-11-11","11:11:11","2017-11-11 11:11:11"), -> (2,'sb2',"1997","1997-12-12","12:12:12","2017-12-12 12:12:12"), -> (3,'sb3',"1998","1998-01-01","13:13:13","2017-01-01 13:13:13"); mysql> select * from student; +------+------+-----------+------------+------------+---------------------+ | id | name | born_year | birth | class_time | reg_time | +------+------+-----------+------------+------------+---------------------+ | 1 | sb1 | 1995 | 1995-11-11 | 11:11:11 | 2017-11-11 11:11:11 | | 2 | sb2 | 1997 | 1997-12-12 | 12:12:12 | 2017-12-12 12:12:12 | | 3 | sb3 | 1998 | 1998-01-01 | 13:13:13 | 2017-01-01 13:13:13 | +------+------+-----------+------------+------------+---------------------+
mysql的日期格式对字符串采用的是'放松'政策,可以以字符串的形式插入。
在实际应用的很多场景中,MySQL的这两种日期类型都能够满足我们的需要,存储精度都为秒,但在某些情况下,会展现出他们各自的优劣。下面就来总结一下两种日期类型的区别。 1.DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年。 2.DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。在mysql服务器,操作系统以及客户端连接都有时区的设置。 3.DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP比DATETIME的空间利用率更高。 4.DATETIME的默认值为null;TIMESTAMP的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP),如果不做特殊处理,并且update语句中没有指定该列的更新值,则默认更新为当前时间。
工作中一般都用datetime就可以了。
mysql> create table t1(x datetime not null default now()); # 需要指定传入空值时默认取当前时间 Query OK, 0 rows affected (0.01 sec) mysql> create table t2(x timestamp); # 无需任何设置,在传空值的情况下自动传入当前时间 Query OK, 0 rows affected (0.02 sec) mysql> insert into t1 values(); Query OK, 1 row affected (0.00 sec) mysql> insert into t2 values(); Query OK, 1 row affected (0.00 sec) mysql> select * from t1; +---------------------+ | x | +---------------------+ | 2018-07-07 01:26:14 | +---------------------+ 1 row in set (0.00 sec) mysql> select * from t2; +---------------------+ | x | +---------------------+ | 2018-07-07 01:26:17 | +---------------------+ 1 row in set (0.00 sec)
四 字符串类型
类型:char,varchar
作用:名字,信息等等
#官网:https://dev.mysql.com/doc/refman/5.7/en/char.html #注意:char和varchar括号内的参数指的都是字符的长度 #char类型:定长,简单粗暴,浪费空间,存取速度快 字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节) 存储: 存储char类型的值时,会往右填充空格来满足长度 例如:指定长度为10,存>10个字符则报错(严格模式下),存<10个字符则用空格填充直到凑够10个字符存储 检索: 在检索或者说查询时,查出的结果会自动删除尾部的空格,如果你想看到它补全空格之后的内容,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = 'strict_trans_tables,PAD_CHAR_TO_FULL_LENGTH';) #varchar类型:变长,精准,节省空间,存取速度慢 字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html) 存储: varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来 强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用) 如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255) 如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535) 检索: 尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
下面我们来进行一些测试,在测试之前,我们需要学一下mysql给我们提供的两个方法:
length(字段):查看该字段数据的字节长度
char_length(字段):查看该字段数据的字符长度
创建一个t1表,包含一个char类型的字段 create table t1(id int,name char(4)); 超过长度: 严格模式下(报错): mysql> insert into t1 values('xiaoshabi'); ERROR 1406 (22001): Data too long for column 'name' at row 1 非严格模式下(警告): mysql> set sql_mode='NO_ENGINE_SUBSTITUTION'; Query OK, 0 rows affected (0.00 sec) mysql> create table t1(id int,name char(4)); Query OK, 0 rows affected (0.40 sec) mysql> insert into t2 values('xiaoshabi'); Query OK, 1 row affected, 1 warning (0.11 sec) 查看一下结果: mysql> select * from t1; +------+------+ | id | name | +------+------+ | 1 | xiao | #只有一个xiao +------+------+ 1 row in set (0.00 sec) varchar类型和上面的效果是一样的,严格模式下也会报错。 如果没有超过长度,那么char类型时mysql会使用空格来补全自己规定的char(4)的4个字符,varchar不会,我们来做个对比 例如: #再创建一个含有varchar类型的表t2 然后插入几条和t1里面相同的数据 mysql>insert into t1 values(2,'a'),(3,'bb'),(4,'ccc'),(5,'d'); mysql>create table t2(id int,name varchar(4)); mysql> insert into t2 values(1,'xiao'),(2,'a'),(3,'bb'),(4,'ccc'),(5,'d'); 查看一下t1表和t2表的内容 mysql> select * from t1; +------+------+ | id | name | +------+------+ | 1 | xiao | | 2 | a | | 3 | bb | | 4 | ccc | | 5 | d | +------+------+ 5 rows in set (0.00 sec) mysql> select * from t2; +------+------+ | id | name | +------+------+ | 1 | xiao | | 2 | a | | 3 | bb | | 4 | ccc | | 5 | d | +------+------+ 5 rows in set (0.00 sec) 好,两个表里面数据是一样的,每一项的数据长度也是一样的,那么我们来验证一下char的自动空格在后面补全的存储方式和varchar的不同 通过mysql提供的一个char_length()方法来查看一下所有数据的长度 mysql> select char_length(name) from t1; +-------------------+ | char_length(name) | +-------------------+ | 4 | | 1 | | 2 | | 3 | | 1 | +-------------------+ 5 rows in set (0.00 sec) mysql> select char_length(name) from t2; +-------------------+ | char_length(name) | +-------------------+ | 4 | | 1 | | 2 | | 3 | | 1 | +-------------------+ 5 rows in set (0.00 sec) 通过查看结果可以看到,两者显示的数据长度是一样的,不是说好的char会补全吗,我设置的字段是char(4),那么长度应该都是4才对啊?这是因为mysql在你查询的时候自动帮你把结果里面的空格去掉了,如果我们想看到它存储数据的真实长度,需要设置mysql的模式,通过一个叫做PAD_CHAR_TO_FULL_LENGTH的模式,就可以看到了,所以我们把这个模式加到sql_mode里面: mysql> set sql_mode='PAD_CHAR_TO_FULL_LENGTH'; Query OK, 0 rows affected (0.00 sec) 然后我们在查看一下t1和t2数据的长度: mysql> select char_length(name) from t1; +-------------------+ | char_length(name) | +-------------------+ | 4 | | 4 | | 4 | | 4 | | 4 | +-------------------+ 5 rows in set (0.00 sec) mysql> select char_length(name) from t2; +-------------------+ | char_length(name) | +-------------------+ | 4 | | 1 | | 2 | | 3 | | 1 | +-------------------+ 5 rows in set (0.00 sec) 通过结果可以看到,char类型的数据长度都是4,这下看到了两者的不同了吧,至于为什么mysql会这样搞,我们后面有解释的,先看现象就可以啦。 现在我们再来看一个问题,就是当你设置的类型为char的时候,我们通过where条件来查询的时候会有一个什么现象: mysql> select * from t1 where name='a'; +------+------+ | id | name | +------+------+ | 2 | a | +------+------+ 1 row in set (0.00 sec) ok,结果没问题,我们在where后面的a后面加一下空格再来试试: mysql> select * from t1 where name='a '; +------+------+ | id | name | +------+------+ | 2 | a | +------+------+ 1 row in set (0.00 sec) ok,能查到,再多加一些空格试试,加6个空格,超过了设置的char(4)的4: mysql> select * from t1 where name='a '; +------+------+ | id | name | +------+------+ | 2 | a | +------+------+ 1 row in set (0.00 sec) ok,也是没问题的 总结:通过>,=,>=,<,<=作为where的查询条件的时候,char类型字段的查询是没问题的。 但是,当我们将where后面的比较符号改为like的时候,(like是模糊匹配的意思,我们前面见过,show variables like '%char%';来查看mysql字符集的时候用过) 其中%的意思是匹配任意字符(0到多个字符都可以匹配到),还有一个符号是_(匹配1个字符),这两个字符其实就像我们学的正则匹配里面的通配符,那么我们通过这些符号进行一下模糊查询,看一下,char类型进行模糊匹配的时候,是否还能行,看例子: mysql> select * from t1 where name like 'a'; Empty set (0.00 sec) 发现啥也没查到,因为char存储的数据是4个字符长度的,不满4个是以空格来补全的,你在like后面就只写了一个'a',是无法查到的。 我们试一下上面的通配符来查询: mysql> select * from t1 where name like 'a%'; +------+------+ | id | name | +------+------+ | 2 | a | +------+------+ 1 row in set (0.00 sec) 这样就能看到查询结果了 试一下_是不是匹配1个字符: mysql> select * from t1 where name like 'a_'; Empty set (0.00 sec) 发现一个_果然不行,我们试试三个_。 mysql> select * from t1 where name like 'a___'; +------+------+ | id | name | +------+------+ | 2 | a | +------+------+ 1 row in set (0.00 sec) 发现果然能行,一个_最多匹配1个任意字符。 如果多写了几个_呢? mysql> select * from t1 where name like 'a_____'; Empty set (0.00 sec) 查不到结果,说明_匹配的是1个字符,但不是0-1个字符。
测试结果总结:
针对char类型,mysql在存储的时候会将不足规定长度的数据使用后面(右边补全)补充空格的形式进行补全,然后存放到硬盘中,但是在读取或者使用的时候会自动去掉它给你补全的空格内容,因为这些空格并不是我们自己存储的数据,所以对我们使用者来说是无用的。
char和varchar性能对比:
以char(5)和varchar(5)来比较,加入我要存三个人名:sb,ssb1,ssbb2
char:
优点:简单粗暴,不管你是多长的数据,我就按照规定的长度来存,5个5个的存,三个人名就会类似这种存储:sb ssb1 ssbb2,中间是空格补全,取数据的时候5个5个的取,简单粗暴速度快
缺点:貌似浪费空间,并且我们将来存储的数据的长度可能会参差不齐
varchar:
varchar类型不定长存储数据,更为精简和节省空间
例如存上面三个人名的时候类似于是这样的:sbssb1ssbb2,连着的,如果这样存,请问这三个人名你还怎么取出来,你知道取多长能取出第一个吗?(超哥,我能看出来啊,那我只想说:滚犊子!)
不知道从哪开始从哪结束,遇到这样的问题,你会想到怎么解决呢?还记的吗?想想?socket?tcp?struct?把数据长度作为消息头。
所以,varchar在存数据的时候,会在每个数据前面加上一个头,这个头是1-2个bytes的数据,这个数据指的是后面跟着的这个数据的长度,1bytes能表示2**8=256,两个bytes表示2**16=65536,能表示0-65535的数字,所以varchar在存储的时候是这样的:1bytes+sb+1bytes+ssb1+1bytes+ssbb2,所以存的时候会比较麻烦,导致效率比char慢,取的时候也慢,先拿长度,再取数据。
优点:节省了一些硬盘空间,一个acsii码的字符用一个bytes长度就能表示,但是也并不一定比char省,看一下官网给出的一个表格对比数据,当你存的数据正好是你规定的字段长度的时候,varchar反而占用的空间比char要多。
| Value | CHAR(4) | Storage Required | VARCHAR(4) | Storage Required |
|---|---|---|---|---|
'' |
' ' |
4 bytes | '' |
1 byte |
'ab' |
'ab ' |
4 bytes | 'ab' |
3 bytes |
'abcd' |
'abcd' |
4 bytes | 'abcd' |
5 bytes |
'abcdefgh' |
'abcd' |
4 bytes | 'abcd' |
5 bytes |
缺点:存取速度都慢
总结:
所以需要根据业务需求来选择用哪种类型来存
其实在多数的用户量少的工作场景中char和varchar效率差别不是很大,最起码给用户的感知不是很大,并且其实软件级别的慢远比不上硬件级别的慢,所以你们公司的运维发现项目慢的时候会加内存、换nb的硬盘,项目的效率提升的会很多,但是我们作为专业人士,我们应该提出来这样的技术点来提高效率。
但是对于InnoDB数据表,内部的行存储格式没有区分固定长度和可变长度列(所有数据行都使用指向数据列值的头指针),因此在本质上,使用固定长度的CHAR列不一定比使用可变长度VARCHAR列性能要好。因而,主要的性能因素是数据行使用的存储总量。由于CHAR平均占用的空间多于VARCHAR,因此使用VARCHAR来最小化需要处理的数据行的存储总量和磁盘I/O是比较好的。
所以啊,两个选哪个都可以,如果是大型并发项目,追求高性能的时候,需要结合你们服务器的硬件环境来进行测试,看一下char和varchar哪个更好,这也能算一个优化的点吧~~~~
#官网:https://dev.mysql.com/doc/refman/5.7/en/char.html CHAR 和 VARCHAR 是最常使用的两种字符串类型。 一般来说 CHAR(N)用来保存固定长度的字符串,对于 CHAR 类型,N 的范围 为 0 ~ 255 VARCHAR(N)用来保存变长字符类型,对于 VARCHAR 类型,N 的范围为 0 ~ 65 535 CHAR(N)和 VARCHAR(N) 中的 N 都代表字符长度,而非字节长度。 ps:对于 MySQL 4.1 之前的版本,如 MySQL 3.23 和 MySQL 4.0,CHAR(N)和 VARCHAR (N)中的 N 代表字节长度。 #CHAR类型 对于 CHAR 类型的字符串,MySQL 数据库会自动对存储列的右边进行填充(Right Padded)操作,直到字符串达到指定的长度 N。而在读取该列时,MySQL 数据库会自动将 填充的字符删除。有一种情况例外,那就是显式地将 SQL_MODE 设置为 PAD_CHAR_TO_ FULL_LENGTH,例如: mysql> CREATE TABLE t ( a CHAR(10)); Query OK, 0 rows affected (0.03 sec) mysql> INSERT INTO t SELECT 'abc'; Query OK, 1 row affected (0.03 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> SELECT a,HEX(a),LENGTH(a) FROM t\G; *************************** 1. row *************************** a: abc HEX(a): 616263 LENGTH (a): 3 1 row in set (0.00 sec) mysql> SET SQL_MODE='PAD_CHAR_TO_FULL_LENGTH'; Query OK, 0 rows affected (0.00 sec) mysql> SELECT a,HEX(a),LENGTH(a) FROM t\G; *************************** 1. row *************************** a: abc HEX(a): 61626320202020202020 LENGTH (a): 10 1 row in set (0.00 sec) 在上述这个例子中,先创建了一张表 t,a 列的类型为 CHAR(10)。然后通过 INSERT语句插入值“abc”,因为 a 列的类型为 CHAR 型,所以会自动在后面填充空字符串,使其长 度为 10。接下来在通过 SELECT 语句取出数据时会将 a 列右填充的空字符移除,从而得到 值“abc”。通过 LENGTH 函数看到 a 列的字符长度为 3 而非 10。 接着我们将 SQL_MODE 显式地设置为 PAD_CHAR_TO_FULL_LENGTH。这时再通过 SELECT 语句进行查询时,得到的结果是“abc ”,abc 右边有 7 个填充字符 0x20,并通 过 HEX 函数得到了验证。这次 LENGTH 函数返回的长度为 10。需要注意的是,LENGTH 函数返回的是字节长度,而不是字符长度。对于多字节字符集,CHAR(N)长度的列最多 可占用的字节数为该字符集单字符最大占用字节数 *N。例如,对于 utf8 下,CHAR(10)最 多可能占用 30 个字节。通过对多字节字符串使用 CHAR_LENGTH 函数和 LENGTH 函数, 可以发现两者的不同,示例如下: mysql> SET NAMES gbk; Query OK, 0 rows affected (0.03 sec) mysql> SELECT @a:='MySQL 技术内幕 '; Query OK, 0 rows affected (0.03 sec) mysql> SELECT @a,HEX(@a),LENGTH(@a),CHAR_LENGTH(@a)\G; ***************************** 1. row **************************** a: MySQL 技术内幕 HEX(a): 4D7953514CBCBCCAF5C4DAC4BB LENGTH (a): 13 CHAR_LENGTH(a): 9 1 row in set (0.00 sec) 变 量 @ a 是 g b k 字 符 集 的 字 符 串 类 型 , 值 为 “ M y S Q L 技 术 内 幕 ”, 十 六 进 制 为 0x4D7953514CBCBCCAF5C4DAC4BB,LENGTH 函数返回 13,即该字符串占用 13 字节, 因为 gbk 字符集中的中文字符占用两个字节,因此一共占用 13 字节。CHAR_LENGTH 函数 返回 9,很显然该字符长度为 9。 #VARCHAR类型 VARCHAR 类型存储变长字段的字符类型,与 CHAR 类型不同的是,其存储时需要在 前缀长度列表加上实际存储的字符,该字符占用 1 ~ 2 字节的空间。当存储的字符串长度小 于 255 字节时,其需要 1 字节的空间,当大于 255 字节时,需要 2 字节的空间。所以,对 于单字节的 latin1 来说,CHAR(10)和 VARCHAR(10)最大占用的存储空间是不同的, CHAR(10)占用 10 个字节这是毫无疑问的,而 VARCHAR(10)的最大占用空间数是 11 字节,因为其需要 1 字节来存放字符长度。 ------------------------------------------------- 注意 对于有些多字节的字符集类型,其 CHAR 和 VARCHAR 在存储方法上是一样的,同样 需要为长度列表加上字符串的值。对于 GBK 和 UTF-8 这些字符类型,其有些字符是以 1 字节 存放的,有些字符是按 2 或 3 字节存放的,因此同样需要 1 ~ 2 字节的空间来存储字符的长 度。 ------------------------------------------------- 虽然 CHAR 和 VARCHAR 的存储方式不太相同,但是对于两个字符串的比较,都只比 较其值,忽略 CHAR 值存在的右填充,即使将 SQL _MODE 设置为 PAD_CHAR_TO_FULL_ LENGTH 也一样,例如: mysql> CREATE TABLE t ( a CHAR(10), b VARCHAR(10)); Query OK, 0 rows affected (0.01 sec) mysql> INSERT INTO t SELECT 'a','a'; Query OK, 1 row affected (0.00 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> SELECT a=b FROM t\G; *************************** 1. row *************************** a=b: 1 1 row in set (0.00 sec) mysql> SET SQL_MODE='PAD_CHAR_TO_FULL_LENGTH'; Query OK, 0 rows affected (0.00 sec) mysql> SELECT a=b FROM t\G; *************************** 1. row *************************** a=b: 1 1 row in set (0.00 sec)
其他的字符串类型:BINARY、VARBINARY、BLOB、TEXT

BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。 BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。 有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。 BLOB: 1._BLOB和_text存储方式不同,_TEXT以文本方式存储,英文存储区分大小写,而_Blob是以二进制方式存储,不分大小写。 2._BLOB存储的数据只能整体读出。 3._TEXT可以指定字符集,_BLO不用指定字符集。
五 枚举类型与集合类型
字段的值只能在给定范围中选择,如单选框,多选框,如果你在应用程序或者前端不做选项限制,在MySQL的字段里面也能做限制
enum 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
set 多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
枚举类型(enum) An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.) 示例: CREATE TABLE shirts ( name VARCHAR(40), size ENUM('x-small', 'small', 'medium', 'large', 'x-large') ); INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small'); 集合类型(set) A SET column can have a maximum of 64 distinct members. 示例: CREATE TABLE myset (col SET('a', 'b', 'c', 'd')); INSERT INTO myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
测试
6、表的完整性约束
7、修改表 alter table
下面的内容就不带着大家演示了,简单带大家看一下,都是固定的语法格式,按照这个写就行了,毫无逻辑可言,所以不做太多的演示,大家自己回去练一下:
语法给一个字段添加外键属性的语句:alter table 表2名 add foreign key(表2的一个字段) references 表1名(表1的一个字段);
注意一点:在mysql里面表名是不区分大小写的,如果你将一个名为t1的(小写的t1)改名为一个T1(大写的T1),是完全没用的,因为在数据库里面表名都是小写的。
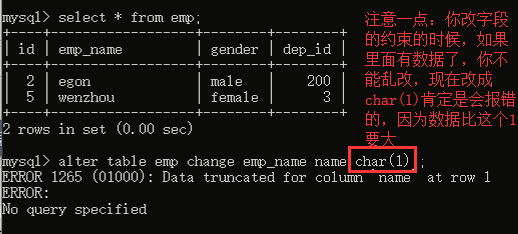
示例: 1. 修改存储引擎 mysql> alter table service -> engine=innodb; 2. 添加字段 mysql> alter table student10 -> add name varchar(20) not null, -> add age int(3) not null default 22; mysql> alter table student10 -> add stu_num varchar(10) not null after name; //添加name字段之后 mysql> alter table student10 -> add sex enum('male','female') default 'male' first; //添加到最前面 3. 删除字段 mysql> alter table student10 -> drop sex; mysql> alter table service -> drop mac; 4. 修改字段类型modify mysql> alter table student10 -> modify age int(3); mysql> alter table student10 -> modify id int(11) not null primary key auto_increment; //修改为主键 5. 增加约束(针对已有的主键增加auto_increment) mysql> alter table student10 modify id int(11) not null primary key auto_increment; ERROR 1068 (42000): Multiple primary key defined mysql> alter table student10 modify id int(11) not null auto_increment; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 6. 对已经存在的表增加复合主键 mysql> alter table service2 -> add primary key(host_ip,port); 7. 增加主键 mysql> alter table student1 -> modify name varchar(10) not null primary key; 8. 增加主键和自动增长 mysql> alter table student1 -> modify id int not null primary key auto_increment; 9. 删除主键 a. 删除自增约束 mysql> alter table student10 modify id int(11) not null; b. 删除主键 mysql> alter table student10 -> drop primary key;
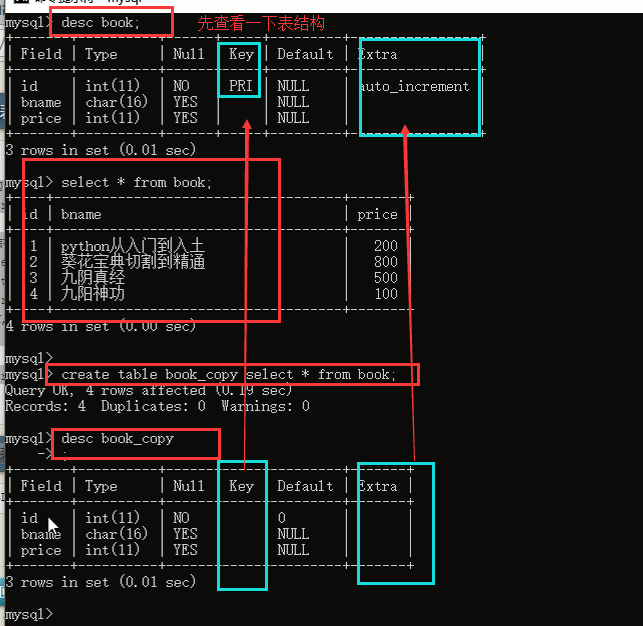
8、复制表
我们通过select查询出来的结果既有表结构又有表记录(数据),我们在重新创建一个和它一样的表的时候,之前用create还需要自己将表结构写好,然后把那些数据插入到新建的表中,很麻烦,那么我们就可以直接使用mysql提供的复制表的功能:(复制表用的很少昂,了解一下就行了)
语法:复制表结构+记录 (key不会复制: 主键、外键和索引)
mysql> create table new_service select * from service;#这句话的意思是你从service表里面查询出来的数据不要在屏幕上打印了,你直接给我的新表new_service
我们自己写个例子:
虽然我们不能复制key,但是我们可以给他加回去啊:alter table xxx
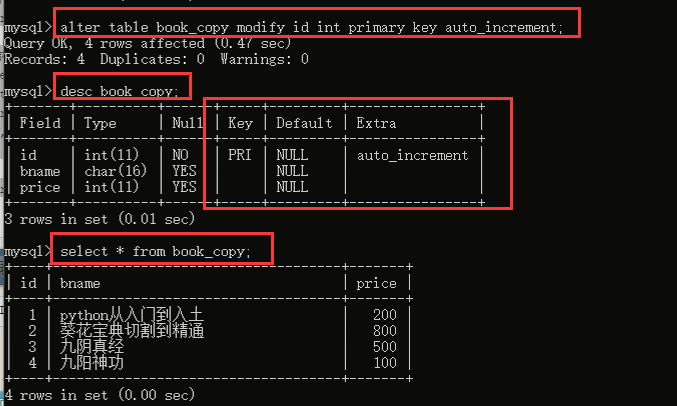
只复制表结构,不要数据
mysql> select * from service where 1=2; //条件为假,查不到任何记录,所以我们可以通过它来只复制表结构,看下面一句
Empty set (0.00 sec)
mysql> create table new1_service select * from service where 1=2; #筛选数据的条件为假,那么只拿到了结构,并没有查询出任何的数据,所以做到了只复制表结构
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> create table t4 like employees; #获取用like可以达到这个效果
补充: MySQL的sql_mode模式说明及设置
MySQL的sql_mode合理设置
sql_mode是个很容易被忽视的变量,默认值是空值,在这种设置下是可以允许一些非法操作的,比如允许一些非法数据的插入。在生产环境必须将这个值设置为严格模式,所以开发、测试环境的数据库也必须要设置,这样在开发测试阶段就可以发现问题.
sql model 常用来解决下面几类问题
(1) 通过设置sql mode, 可以完成不同严格程度的数据校验,有效地保障数据准备性。
(2) 通过设置sql model 为宽松模式,来保证大多数sql符合标准的sql语法,这样应用在不同数据库之间进行迁移时,则不需要对业务sql 进行较大的修改。
(3) 在不同数据库之间进行数据迁移之前,通过设置SQL Mode 可以使MySQL 上的数据更方便地迁移到目标数据库中。
sql_mode常用值如下:
ONLY_FULL_GROUP_BY:
对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么这个SQL是不合法的,因为列不在GROUP BY从句中
NO_AUTO_VALUE_ON_ZERO:
该值影响自增长列的插入。默认设置下,插入0或NULL代表生成下一个自增长值。如果用户 希望插入的值为0,而该列又是自增长的,那么这个选项就有用了。
STRICT_TRANS_TABLES:
在该模式下,如果一个值不能插入到一个事务表中,则中断当前的操作,对非事务表不做限制
NO_ZERO_IN_DATE:
在严格模式下,不允许日期和月份为零
NO_ZERO_DATE:
设置该值,mysql数据库不允许插入零日期,插入零日期会抛出错误而不是警告。
ERROR_FOR_DIVISION_BY_ZERO:
在INSERT或UPDATE过程中,如果数据被零除,则产生错误而非警告。如 果未给出该模式,那么数据被零除时MySQL返回NULL
NO_AUTO_CREATE_USER:
禁止GRANT创建密码为空的用户
NO_ENGINE_SUBSTITUTION:
如果需要的存储引擎被禁用或未编译,那么抛出错误。不设置此值时,用默认的存储引擎替代,并抛出一个异常
PIPES_AS_CONCAT:
将"||"视为字符串的连接操作符而非或运算符,这和Oracle数据库是一样的,也和字符串的拼接函数Concat相类似
ANSI_QUOTES:
启用ANSI_QUOTES后,不能用双引号来引用字符串,因为它被解释为识别符
ORACLE的sql_mode设置等同:PIPES_AS_CONCAT, ANSI_QUOTES, IGNORE_SPACE, NO_KEY_OPTIONS, NO_TABLE_OPTIONS, NO_FIELD_OPTIONS, NO_AUTO_CREATE_USER.
如果使用mysql,为了继续保留大家使用oracle的习惯,可以对mysql的sql_mode设置如下:
在my.cnf添加如下配置
[mysqld]
sql_mode='ONLY_FULL_GROUP_BY,NO_AUTO_VALUE_ON_ZERO,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,
ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,PIPES_AS_CONCAT,ANSI_QUOTES'
注意:MySQL5.6和MySQL5.7默认的sql_mode模式参数是不一样的,5.6的mode是NO_ENGINE_SUBSTITUTION,其实表示的是一个空值,相当于没有什么模式设置,可以理解为宽松模式。5.7的mode是STRICT_TRANS_TABLES,也就是严格模式。
如果设置的是宽松模式,那么我们在插入数据的时候,即便是给了一个错误的数据,也可能会被接受,并且不报错,例如:我在创建一个表时,该表中有一个字段为name,给name设置的字段类型时char(10),如果我在插入数据的时候,其中name这个字段对应的有一条数据的长度超过了10,例如'1234567890abc',超过了设定的字段长度10,那么不会报错,并且取前十个字符存上,也就是说你这个数据被存为了'1234567890',而'abc'就没有了,但是我们知道,我们给的这条数据是错误的,因为超过了字段长度,但是并没有报错,并且mysql自行处理并接受了,这就是宽松模式的效果,其实在开发、测试、生产等环境中,我们应该采用的是严格模式,出现这种错误,应该报错才对,所以MySQL5.7版本就将sql_mode默认值改为了严格模式,并且我们即便是用的MySQL5.6,也应该自行将其改为严格模式,而你记着,MySQL等等的这些数据库,都是想把关于数据的所有操作都自己包揽下来,包括数据的校验,其实好多时候,我们应该在自己开发的项目程序级别将这些校验给做了,虽然写项目的时候麻烦了一些步骤,但是这样做之后,我们在进行数据库迁移或者在项目的迁移时,就会方便很多,这个看你们自行来衡量。mysql除了数据校验之外,你慢慢的学习过程中会发现,它能够做的事情还有很多很多,将你程序中做的好多事情都包揽了。
改为严格模式后可能会存在的问题:
若设置模式中包含了NO_ZERO_DATE,那么MySQL数据库不允许插入零日期,插入零日期会抛出错误而不是警告。例如表中含字段TIMESTAMP列(如果未声明为NULL或显示DEFAULT子句)将自动分配DEFAULT '0000-00-00 00:00:00'(零时间戳),也或者是本测试的表day列默认允许插入零日期 '0000-00-00' COMMENT '日期';这些显然是不满足sql_mode中的NO_ZERO_DATE而报错。
模式设置和修改(以解决上述问题为例):
方式一:先执行select @@sql_mode,复制查询出来的值并将其中的NO_ZERO_IN_DATE,NO_ZERO_DATE删除,然后执行set sql_mode = '修改后的值'或者set session sql_mode='修改后的值';,例如:set session sql_mode='STRICT_TRANS_TABLES';改为严格模式
此方法只在当前会话中生效,关闭当前会话就不生效了。
方式二:先执行select @@global.sql_mode,复制查询出来的值并将其中的NO_ZERO_IN_DATE,NO_ZERO_DATE删除,然后执行set global sql_mode = '修改后的值'。
此方法在当前服务中生效,重新MySQL服务后失效
方法三:在mysql的安装目录下,或my.cnf文件(windows系统是my.ini文件),新增 sql_mode = ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,
添加my.cnf如下:
[mysqld]
sql_mode=ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER
然后重启mysql。
此方法永久生效.当然生产环境上是禁止重启MySQL服务的,所以采用方式二加方式三来解决线上的问题,那么即便是有一天真的重启了MySQL服务,也会永久生效了。
MySQL字符集详解
一、MySQL字符集编码简单介绍
在使用MySQL时要注意6个需要编码的地方:系统的编码、客户端、服务端、库、表、列。字符集编码不仅影响数据存储,还影响client程序和数据库之间的交互.在mysql中输入命令show session variables like '%char%'能够看到例如以下一些字符集(下面是以win10为例,生产中多数时linux,在linux里面除了latin1之外都是utf8的字符集):
mysql> show variables like "%char%";
+--------------------------+-------------------------------------------+
| Variable_name | Value |
+--------------------------+-------------------------------------------+
| character_set_client | gbk |
| character_set_connection | gbk |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | gbk |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | F:\jj\mysql-5.6.42-winx64\share\charsets\ |
+--------------------------+-------------------------------------------+
8 rows in set (0.00 sec)
mysql中的字符集都相应着一个默认的校对规则(COLLATION),当然一个字符集也可能相应多个校对规则,可是两个不同的字符集不能相应同一个规则。使用默认的就可以了
以下来看看上面命令列出的字符集相关变量的含义:
- character_set_client:server解析客户端sql语句的字符集.(The character set for statements that arrive from the client. The session value of this variable is set using the character set requested by the client when the client connects to the server).
- character_set_connection:字符串字面值(literal strings)的字符集.
- character_set_results:server返回给客户端的查询结果或者错误提示的字符集编码.(The character set used for returning query results such as result sets or error messages to the client)
- character_set_system:这是mysqlserver用来存储元数据的编码,通常就是utf8,不要去改动它.
- character_sets_dir:这是mysql字符集编码存储文件夹.
- character_set_filesystem:这是文件系统字符集编码,主要用于解析用于文件名称的字符串字面值,如LOAD DATA INFILE和SELECT ...INTO OUTFILE等语句以及LOAD_FILE()函数.在打开文件之前,文件名称会从character_set_client转换为character_set_filesystem指定的编码.默认值为binary,也就是说不会进行转换.比如我们设置的character_set_client=GBK,而character_set_filesystem为默认值的话,则采用SELECT...INTO OUTFILE "文件名称",文件名称为GBK编码.反之,假设我们设置了character_set_filesystem=UTF8,则导出的文件名称为UTF8编码. 比如:linux系统的终端编码是UTF8,系统默认语言和编码为zh_CN.UTF8.我们有一个数据库名为test,test中有个表名为t1,编码为latin1,另外,我们在mysqlclient运行了SET NAMES GBK,假设我们不改动character_set_filesystem的值,运行SELECT * FROM t1 INTO OUTFILE '文件1', 能够发现相应的文件夹以下生成了一个名为"文件1"的文件,那文件名称编码是什么呢?事实上这里有几个地方须要注意,首先,我们的sql语句里面的"文件1"原生编码就是终端编码UTF8,也就是'\xe6\x96\x87\xe4\xbb\xb61',而导出数据的语句SELECT * FROM t1 INTO OUTFILE '文件1',依照前面的说法,由于character_set_filesystem为binary,因此'\xe6\x96\x87\xe4\xbb\xb61'不会转换,这样终于还是'\xe6\x96\x87\xe4\xbb\xb61',这样在zh_CN.UTF8的系统中文件名称不会乱码.而假设我们设置了character_set_filesystem=UTF8,则原生的'\xe6\x96\x87\xe4\xbb\xb61'会先依照GBK解码,然后用UTF8编码,最后的结果是"\xe9\x8f\x82\xe5\x9b\xa6\xe6\xac\xa21",这样文件名称就会乱码了.所以这个变量也最好不要改动,用默认值就OK.
- character_set_server:服务器默认字符集编码,假设创建数据库的时候没有指定编码,则采用character_set_server指定编码.
- character_set_database:默认数据库的字符集编码.假设没有默认数据库,则该变量值与character_set_server同样.事实上这个值代表的就是你当前数据库的编码而已,比方使用"use test",而test数据库的编码为latin1的话,这个值就是latin1.而你切换的时候"use test2",则character_set_database的值就是数据库test2的编码.
二、MySQL字符集编码层次
第一部分主要是归纳了MySQL文档中关于字符集编码的说明。这部分主要说明下MySQL中字符集编码层次:服务端-->数据库-->表-->字段。
关于系统的编码主要针对的是我们将来在存储文件的时候,有可能会将文件直接存贮在mysql的服务器上,那么,我们在数据库里面存的就是这些文件的路径,实际文件是存在系统里面的,那么文件名称就会受到你系统编码的影响,比如我们mysql设置的utf8编码的格式存储的文件路径,但是系统默认是gbk编码的,那么文件在保存到系统里的时候,文件的名称和你存在mysql里面的文件名称就对应不上了,出现乱码显示的问题,所以也要注意系统的编码。客户端的编码问题,我们在第一节的时候说了一下,大家应该比较了解啦。所以我们下面之说mysql内部设置的这些编码问题。
简单来说,服务器编码就是character_set_server来指定的.当我们创建数据库的时候能够指定编码,假设没有指定,采用的就是character_set_server指定的编码.比如:我们使用"create database t1 character set gbk",这里我们指定了数据库t1的编码为gbk,所以不会采用character_set_server指定的编码.而假设我们使用"create database t2",则通过"show create database t2"能够看到t2的编码为character_set_server定的编码.
同理,mysql表也能够有自己独立的编码,在创建表的时候能够指定,假设没有指定,则默认采用数据库的编码.比方我们再之前的数据库t1创建表t11,"create table t11(i int) character set utf8",则表t11的编码为utf8,假设不指定编码则编码为数据库t1的编码gbk.
此外,mysql表中的字段也能够有自己的编码,假设不指定字段编码,则字段编码与表的编码一致.
三、MySQL连接字符集
前面谈到的编码内容基本都不会产生乱码问题,mysql中容易产生乱码的地方在character_set_client, character_set_connection, character_set_results这三个变量的设定.能够简单的通过set names utf8或者charset utf8命令来一次设置这三个參数.
从文档中的解释来看,mysql连接字符集转换主要包含以下三个步骤:
- 1.character_set_client是client发送过来的sql语句的编码,由于服务端本身并不知道client的sql语句的编码是什么,所以是以这个变量作为clientsql语句的初始编码.而服务端接收到sql语句后,则会将sql语句转换为character_set_connection指定的编码(注意,对于字面值字符串,假设前面有introducer标记如latin1或utf8,则不会进行这一步转换).转换完毕,才会真正运行sql语句.
- 2.进行内部操作前将sql语句中的数据从character_set_connection转换为数据表中对应字段的编码.
- 3.将操作结果从内部字符集编码转换为character_set_results编码.
MySQL5.6的4个自带库详解
1.information_schema详细介绍:
information_schema数据库是MySQL自带的,它提供了访问数据库元数据的方式。什么是元数据呢?元数据是关于数据的数据,如数据库名或表名,列的数据类型,或访问权限等。有些时候用于表述该信息的其他术语包括“数据词典”和“系统目录”。 在MySQL中,把 information_schema 看作是一个数据库,确切说是信息数据库。其中保存着关于MySQL服务器所维护的所有其他数据库的信息。如数据库名,数据库的表,表栏的数据类型与访问权 限等。在INFORMATION_SCHEMA中,有数个只读表。它们实际上是视图,而不是基本表,因此,你将无法看到与之相关的任何文件。 information_schema数据库表说明:
SCHEMATA表:提供了当前mysql实例中所有数据库的信息。是show databases的结果取之此表。 TABLES表:提供了关于数据库中的表的信息(包括视图)。详细表述了某个表属于哪个schema,表类型,表引擎,创建时间等信息。是show tables from schemaname的结果取之此表。
COLUMNS表:提供了表中的列信息。详细表述了某张表的所有列以及每个列的信息。是show columns from schemaname.tablename的结果取之此表。
STATISTICS表:提供了关于表索引的信息。是show index from schemaname.tablename的结果取之此表。
USER_PRIVILEGES(用户权限)表:给出了关于全程权限的信息。该信息源自mysql.user授权表。是非标准表。
SCHEMA_PRIVILEGES(方案权限)表:给出了关于方案(数据库)权限的信息。该信息来自mysql.db授权表。是非标准表。
TABLE_PRIVILEGES(表权限)表:给出了关于表权限的信息。该信息源自mysql.tables_priv授权表。是非标准表。
COLUMN_PRIVILEGES(列权限)表:给出了关于列权限的信息。该信息源自mysql.columns_priv授权表。是非标准表。
CHARACTER_SETS(字符集)表:提供了mysql实例可用字符集的信息。是SHOW CHARACTER SET结果集取之此表。
COLLATIONS表:提供了关于各字符集的对照信息。
COLLATION_CHARACTER_SET_APPLICABILITY表:指明了可用于校对的字符集。这些列等效于SHOW COLLATION的前两个显示字段。
TABLE_CONSTRAINTS表:描述了存在约束的表。以及表的约束类型。
KEY_COLUMN_USAGE表:描述了具有约束的键列。
ROUTINES表:提供了关于存储子程序(存储程序和函数)的信息。此时,ROUTINES表不包含自定义函数(UDF)。名为“mysql.proc name”的列指明了对应于INFORMATION_SCHEMA.ROUTINES表的mysql.proc表列。
VIEWS表:给出了关于数据库中的视图的信息。需要有show views权限,否则无法查看视图信息。
TRIGGERS表:提供了关于触发程序的信息。必须有super权限才能查看该表
2. mysql作用介绍:
mysql:这个是mysql的核心数据库,类似于sql server中的master表,主要负责存储数据库的用户、权限设置、关键字等mysql自己需要使用的控制和管理信息。不可以删除,如果对mysql不是很了解,也不要轻易修改这个数据库里面的表信息。
3. performance_schema作用介绍:
mysql 5.5 版本 新增了一个性能优化的引擎: PERFORMANCE_SCHEMA这个功能默认是关闭的: 需要设置参数: performance_schema 才可以启动该功能,这个参数是静态参数,只能写在my.ini 中 不能动态修改。 先看看有什么东西吧:
mysql> use performance_schema;
Database changed
mysql> show tables ;
+----------------------------------------------+
| Tables_in_performance_schema |
+----------------------------------------------+
| cond_instances |
| events_waits_current |
| events_waits_history |
| events_waits_history_long |
| events_waits_summary_by_instance |
| events_waits_summary_by_thread_by_event_name |
| events_waits_summary_global_by_event_name |
| file_instances | | file_summary_by_event_name |
| file_summary_by_instance |
| mutex_instances |
| performance_timers |
| rwlock_instances |
| setup_consumers |
| setup_instruments |
| setup_timers |
| threads |
+----------------------------------------------+
17 rows in set (0.00 sec)
这里的数据表分为几类:
1) setup table : 设置表,配置监控选项。
2) current events table : 记录当前那些thread 正在发生什么事情。
3) history table 发生的各种事件的历史记录表
4) summary table 对各种事件的统计表
5) 杂项表,乱七八糟表。
setup 表:
mysql> SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES -> WHERE TABLE_SCHEMA = 'performance_schema' -> AND TABLE_NAME LIKE 'setup%';
+-------------------+
| TABLE_NAME |
+-------------------+
| setup_consumers |
| setup_instruments |
| setup_timers |
+-------------------+
setup_consumers 描述各种事件 setup_instruments 描述这个数据库下的表名以及是否开启监控。 setup_timers 描述 监控选项已经采样频率的时间间隔
4. test作用介绍:
这个是安装时候创建的一个测试数据库,和它的名字一样,是一个完全的空数据库,没有任何表,可以删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号