pymysql模块
pymysql模块
我们要学的pymysql就是用来在python程序中如何操作mysql,它和mysql自带的那个客户端还有navicat是一样的,本质上就是一个套接字客户端,只不过这个套接字客户端是在python程序中用的,既然是客户端套接字,应该怎么用,是不是要连接服务端,并且和服务端进行通信啊,让我们来学习一下pymysql这个模块
#安装 pip3 install pymysql
一 链接、执行sql、关闭(游标)

import pymysql user=input('用户名: ').strip() pwd=input('密码: ').strip() #链接,指定ip地址和端口,本机上测试时ip地址可以写localhost或者自己的ip地址或者127.0.0.1,然后你操作数据库的时候的用户名,密码,要指定你操作的是哪个数据库,指定库名,还要指定字符集。不然会出现乱码 conn=pymysql.connect(host='localhost',port=3306,user='root',password='123',database='student',charset='utf8') #指定编码为utf8的时候,注意没有-,别写utf-8,数据库为
#得到conn这个连接对象 #游标 cursor=conn.cursor() #这就想到于mysql自带的那个客户端的游标mysql> 在这后面输入指令,回车执行 #cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) #获取字典数据类型表示的结果:{'sid': 1, 'gender': '男', 'class_id': 1, 'sname': '理解'} {'字段名':值} #然后给游标输入sql语句并执行sql语句execute sql='select * from userinfo where name="%s" and password="%s"' %(user,pwd) #注意%s需要加引号,执行这句sql的前提是医药有个userinfo表,里面有name和password两个字段,还有一些数据,自己添加数据昂 print(sql) res=cursor.execute(sql) #执行sql语句,返回sql查询成功的记录数目,是个数字,是受sql语句影响到的记录行数,其实除了受影响的记录的条数之外,这些记录的数据也都返回了给游标,这个就相当于我们subprocess模块里面的管道PIPE,乘放着返回的数据
#all_data=cursor.fetchall() #获取返回的所有数据,注意凡是取数据,取过的数据就没有了,结果都是元祖格式的
#many_data=cursor.fetchmany(3) #一下取出3条数据,
#one_data=cursor.fetchone() #按照数据的顺序,一次只拿一个数据,下次再去就从第二个取了,因为第一个被取出去了,取一次就没有了,结果也都是元祖格式的
fetchone:(1, '男', 1, '理解')
fetchone:(2, '女', 1, '钢蛋')
fetchall:((3, '男', 1, '张三'), (4, '男', 1, '张一'))
#上面fetch的结果都是元祖格式的,没法看出哪个数据是对应的哪个字段,这样是不是不太好看,想一想,我们可以通过python的哪一种数据类型,能把字段和对应的数据表示出来最清晰,当然是字典{'字段名':值}
#我们可以再创建游标的时候,在cursor里面加上一个参数:cursor=conn.cursor(cursor=pymysql.cursors.DictCursor)获取的结果就是字典格式的,fetchall或者fetchmany取出的结果是列表套字典的数据形式
上面我们说,我们的数据取一次是不是就没有了啊,实际上不是的,这个取数据的操作就像读取文件内容一样,每次read之后,光标就移动到了对应的位置,我们可以通过seek来移动光标
同样,我们可以移动游标的位置,继续取我们前面的数据,通过cursor.scroll(数字,模式),第一个参数就是一个int类型的数字,表示往后移动的记录条数,第二个参数为移动的模式,有两个值:absolute:绝对移动,relative:相对移动
#绝对移动:它是相对于所有数据的起始位置开始往后面移动的
#相对移动:他是相对于游标的当前位置开始往后移动的
#绝对移动的演示
#print(cursor.fetchall())
#cursor.scroll(3,'absolute') #从初始位置往后移动三条,那么下次取出的数据为第四条数据
#print(cursor.fetchone())
#相对移动的演示
#print(cursor.fetchone())
#cursor.scroll(1,'relative') #通过上面取了一次数据,游标的位置在第二条的开头,我现在相对移动了1个记录,那么下次再取,取出的是第三条,我相对于上一条,往下移动了一条
#print(cursor.fetchone())
print(res) #一个数字 cursor.close() #关闭游标 conn.close() #关闭连接 if res: print('登录成功') else: print('登录失败')

二 execute()之sql注入
之前我们进行用户名密码认证是先将用户名和密码保存到一个文件中,然后通过读文件里面的内容,来和客户端发送过来的用户名密码进行匹配,现在我们学了数据库,我们可以将这些用户数据保存到数据库中,然后通过数据库里面的数据来对客户端进行用户名和密码的认证。
自行创建一个用户信息表userinfo,里面包含两个字段,username和password,然后里面写两条记录

#我们来使用数据来进行一下用户名和密码的认证操作
import pymysql conn = pymysql.connect( host='127.0.0.1', port=3306, user='root', password='666', database='crm', charset='utf8' ) cursor = conn.cursor(pymysql.cursors.DictCursor) uname = input('请输入用户名:') pword = input('请输入密码:') sql = "select * from userinfo where username='%s' and password='%s';"%(uname,pword) res = cursor.execute(sql) #res我们说是得到的行数,如果这个行数不为零,说明用户输入的用户名和密码存在,如果为0说名存在,你想想对不 print(res) #如果输入的用户名和密码错误,这个结果为0,如果正确,这个结果为1 if res: print('登陆成功') else: print('用户名和密码错误!') #通过上面的验证方式,比我们使用文件来保存用户名和密码信息的来进行验证操作要方便很多。
但是我们来看下面的操作,如果将在输入用户名的地方输入一个 chao'空格然后--空格然后加上任意的字符串,就能够登陆成功,也就是只知道用户名的情况下,他就能登陆成功的情况:
uname = input('请输入用户名:') pword = input('请输入密码:') sql = "select * from userinfo where username='%s' and password='%s';"%(uname,pword) print(sql) res = cursor.execute(sql) #res我们说是得到的行数,如果这个行数不为零,说明用户输入的用户名和密码存在,如果为0说名存在,你想想对不 print(res) #如果输入的用户名和密码错误,这个结果为0,如果正确,这个结果为1 if res: print('登陆成功') else: print('用户名和密码错误!') #运行看结果:居然登陆成功 请输入用户名:chao' -- xxx 请输入密码: select * from userinfo where username='chao' -- xxx' and password=''; 1 登陆成功 我们来分析一下: 此时uname这个变量等于什么,等于chao' -- xxx,然后我们来看我们的sql语句被这个字符串替换之后是个什么样子: select * from userinfo where username='chao' -- xxx' and password=''; 其中chao后面的这个',在进行字符串替换的时候,我们输入的是chao',这个引号和前面的引号组成了一对,然后后面--在sql语句里面是注释的意思,也就是说--后面的sql语句被注释掉了。也就是说,拿到的sql语句是select * from userinfo where username='chao';然后就去自己的数据库里面去执行了,发现能够找到对应的记录,因为有用户名为chao的记录,然后他就登陆成功了,但是其实他连密码都不知道,只知道个用户名。。。,他完美的跳过了你的认证环节。
然后我们再来看一个例子,直接连用户名和密码都不知道,但是依然能够登陆成功的情况:
请输入用户名:xxx' or 1=1 -- xxxxxx 请输入密码: select * from userinfo where username='xxx' or 1=1 -- xxxxxx' and password=''; 3 登陆成功 我们只输入了一个xxx' 加or 加 1=1 加 -- 加任意字符串 看上面被执行的sql语句你就发现了,or 后面跟了一个永远为真的条件,那么即便是username对不上,但是or后面的条件是成立的,也能够登陆成功。
上面两个例子就是两个sql注入的问题,看完上面这两个例子,有没有感觉后背发凉啊同志们,别急,我们来解决一下这个问题,怎么解决呢?
有些网站直接在你输入内容的时候,是不是就给你限定了,你不能输入一些特殊的符号,因为有些特殊符号可以改变sql的执行逻辑,其实不光是--,还有一些其他的符号也能改变sql语句的执行逻辑,这个方案我们是在客户端给用户输入的地方进行限制,但是别人可不可以模拟你的客户端来发送请求,是可以的,他模拟一个客户端,不按照你的客户端的要求来,就发一些特殊字符,你的客户端是限制不了的。所以单纯的在客户端进行这个特殊字符的过滤是不能解决根本问题的,那怎么办?我们服务端也需要进行验证,可以通过正则来将客户端发送过来的内容进行特殊字符的匹配,如果有这些特殊字符,我们就让它登陆失败。
在服务端来解决sql注入的问题:不要自己来进行sql字符串的拼接了,pymysql能帮我们拼接,他能够防止sql注入,所以以后我们再写sql语句的时候按下面的方式写:
之前我们的sql语句是这样写的: sql = "select * from userinfo where username='%s' and password='%s';"%(uname,pword) 以后再写的时候,sql语句里面的%s左右的引号去掉,并且语句后面的%(uname,pword)这些内容也不要自己写了,按照下面的方式写 sql = "select * from userinfo where username=%s and password=%s;" 难道我们不传值了吗,不是的,我们通过下面的形式,在excute里面写参数: #cursor.execute(sql,[uname,pword]) ,其实它本质也是帮你进行了字符串的替换,只不过它会将uname和pword里面的特殊字符给过滤掉。 看下面的例子: uname = input('请输入用户名:') #输入的内容是:chao' -- xxx或者xxx' or 1=1 -- xxxxx pword = input('请输入密码:') sql = "select * from userinfo where username=%s and password=%s;" print(sql) res = cursor.execute(sql,[uname,pword]) #res我们说是得到的行数,如果这个行数不为零,说明用户输入的用户名和密码存在,如果为0说名存在,你想想对不 print(res) #如果输入的用户名和密码错误,这个结果为0,如果正确,这个结果为1 if res: print('登陆成功') else: print('用户名和密码错误!') #看结果: 请输入用户名:xxx' or 1=1 -- xxxxx 请输入密码: select * from userinfo where username=%s and password=%s; 0 用户名和密码错误!
通过pymysql提供的excute完美的解决了问题。
总结咱们刚才说的两种sql注入的语句
#1、sql注入之:用户存在,绕过密码 chao' -- 任意字符 #2、sql注入之:用户不存在,绕过用户与密码 xxx' or 1=1 -- 任意字符
解决方法总结:
# 原来是我们对sql进行字符串拼接 # sql="select * from userinfo where name='%s' and password='%s'" %(user,pwd) # print(sql) # res=cursor.execute(sql) #改写为(execute帮我们做字符串拼接,我们无需且一定不能再为%s加引号了) sql="select * from userinfo where name=%s and password=%s" #!!!注意%s需要去掉引号,因为pymysql会自动为我们加上 res=cursor.execute(sql,[user,pwd]) #pymysql模块自动帮我们解决sql注入的问题,只要我们按照pymysql的规矩来。
三 增、删、改:conn.commit()
查操作在上面已经说完了,我们来看一下增删改,也要注意,sql语句不要自己拼接,交给excute来拼接
import pymysql #链接 conn=pymysql.connect(host='localhost',port='3306',user='root',password='123',database='crm',charset='utf8') #游标 cursor=conn.cursor() #执行sql语句 #part1 # sql='insert into userinfo(name,password) values("root","123456");' # res=cursor.execute(sql) #执行sql语句,返回sql影响成功的行数 # print(res)
# print(cursor.lastrowid) #返回的是你插入的这条记录是到了第几条了 #part2 # sql='insert into userinfo(name,password) values(%s,%s);' # res=cursor.execute(sql,("root","123456")) #执行sql语句,返回sql影响成功的行数 # print(res) #还可以进行更改操作:
#res=cursor.excute("update userinfo set username='taibaisb' where id=2")
#print(res) #结果为1 #part3 sql='insert into userinfo(name,password) values(%s,%s);' res=cursor.executemany(sql,[("root","123456"),("lhf","12356"),("eee","156")]) #执行sql语句,返回sql影响成功的行数,一次插多条记录 print(res) #上面的几步,虽然都有返回结果,也就是那个受影响的函数res,但是你去数据库里面一看,并没有保存到数据库里面, conn.commit() #必须执行conn.commit,注意是conn,不是cursor,执行这句提交后才发现表中插入记录成功,没有这句,上面的这几步操作其实都没有成功保存。 cursor.close() conn.close()
四 查:fetchone,fetchmany,fetchall

import pymysql #链接 conn=pymysql.connect(host='localhost',user='root',password='123',database='egon') #游标 cursor=conn.cursor() #执行sql语句 sql='select * from userinfo;' rows=cursor.execute(sql) #执行sql语句,返回sql影响成功的行数rows,将结果放入一个集合,等待被查询 # cursor.scroll(3,mode='absolute') # 相对绝对位置移动 # cursor.scroll(3,mode='relative') # 相对当前位置移动 res1=cursor.fetchone() res2=cursor.fetchone() res3=cursor.fetchone() res4=cursor.fetchmany(2) res5=cursor.fetchall() print(res1) print(res2) print(res3) print(res4) print(res5) print('%s rows in set (0.00 sec)' %rows) conn.commit() #提交后才发现表中插入记录成功 cursor.close() conn.close() ''' (1, 'root', '123456') (2, 'root', '123456') (3, 'root', '123456') ((4, 'root', '123456'), (5, 'root', '123456')) ((6, 'root', '123456'), (7, 'lhf', '12356'), (8, 'eee', '156')) rows in set (0.00 sec) '''
五 获取插入的最后一条数据的自增ID
import pymysql conn=pymysql.connect(host='localhost',user='root',password='123',database='egon') cursor=conn.cursor() sql='insert into userinfo(name,password) values("xxx","123");' rows=cursor.execute(sql) print(cursor.lastrowid) #在插入语句后查看 conn.commit() cursor.close() conn.close()
Navicat
既然是mysql客户端,我们需要连接mysql服务端
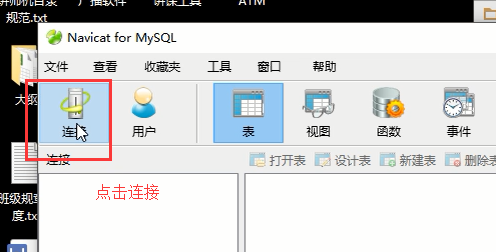
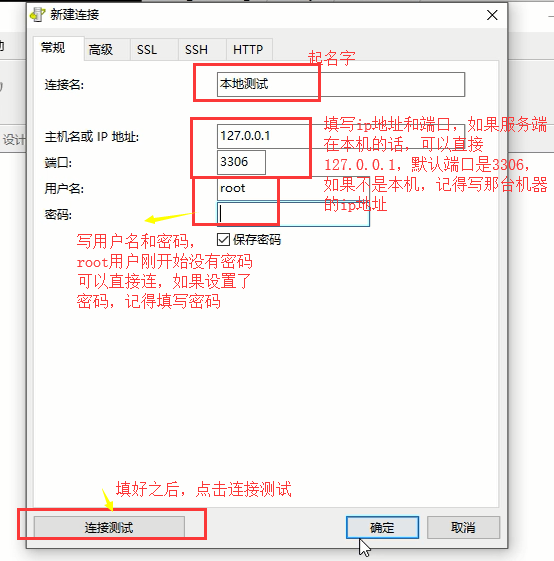
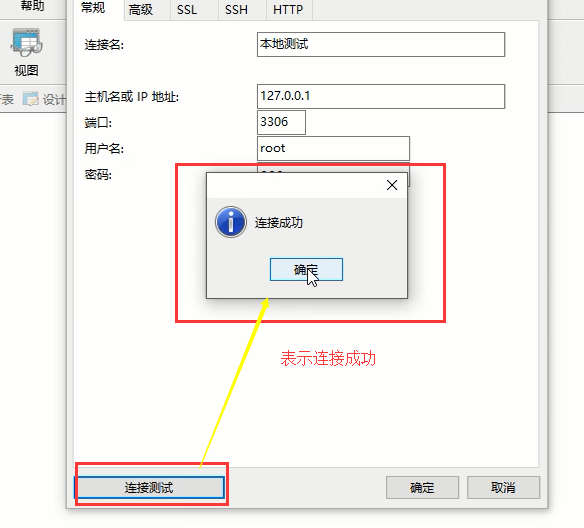
在弹出的界面输入mysql服务端的ip地址和端口,还有mysql用户名和密码
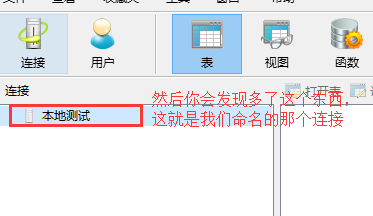
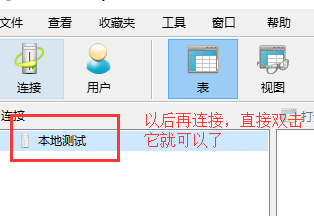

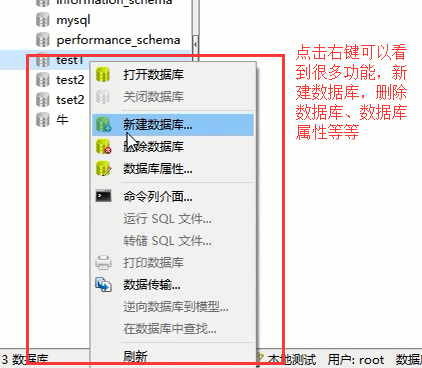
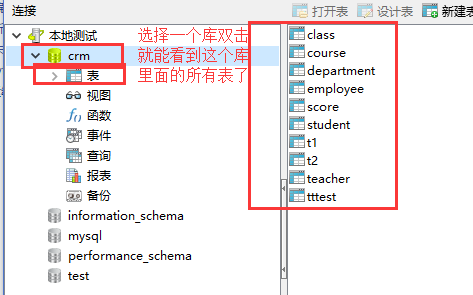
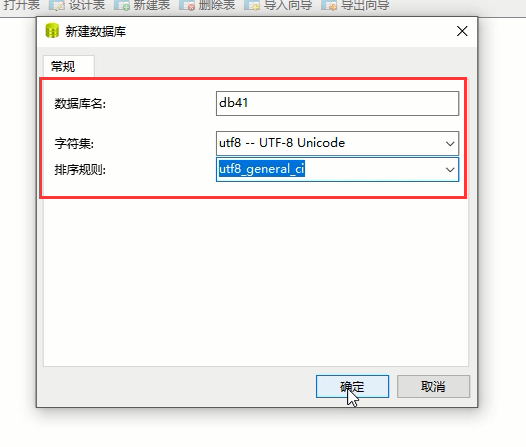
关于校对规则大家看看这两篇博客就明白了:
https://www.cnblogs.com/adforce/p/3282404.html
https://www.jb51.net/article/48775.htm
上面的步骤点击确定就建好一个数据库了:

然后我们到上面的数据库里面新建一张表
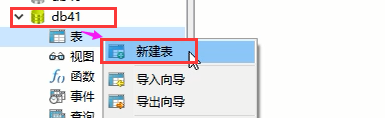
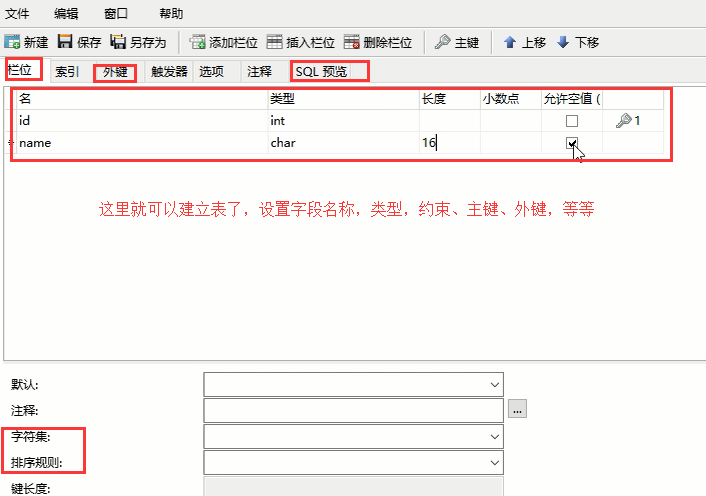
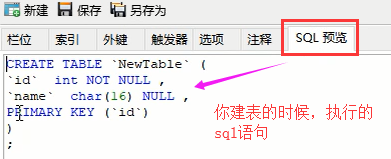
也就是我们自己用鼠标点啊点之类的,也就是生成对应的sql语句去执行
然后点击保存:
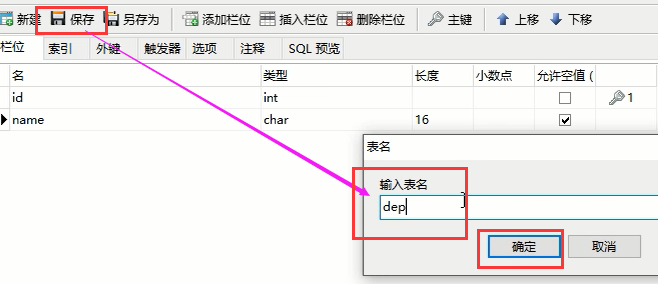
这个表就生成了:
不信我们去命令行看一看:这个表就存在了

以后我们直接就使用这个工具来操作数据库就可以了,因为命令行操作还是比较恶心的
然后我们看看建立外键
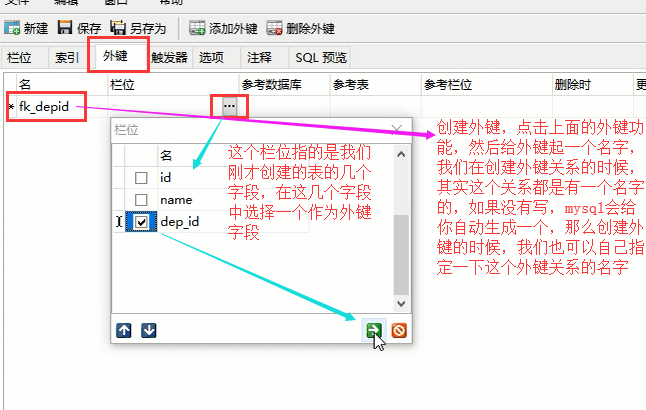
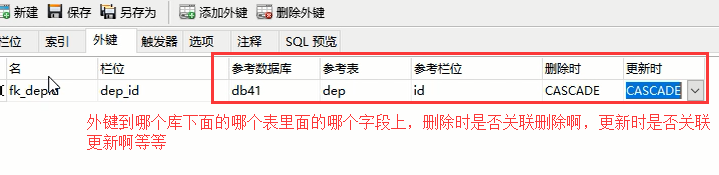
然后自动会生成对应的sql语句
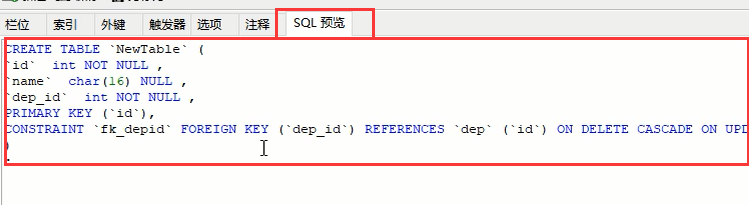

然后点击保存,起一个表名,就有了这个表了
然后双击上面的表名就可以插入数据了

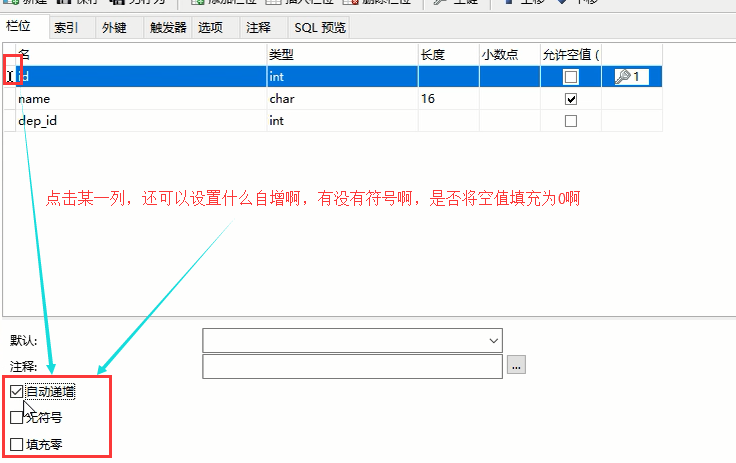
比方说我们上面这个dep表的id字段没有设置自增,我想改一下,让它这个id字段变为自增的怎么办
设计表:
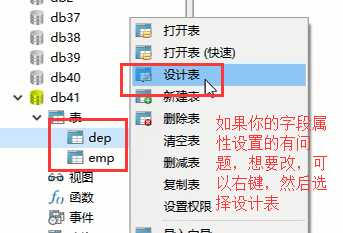
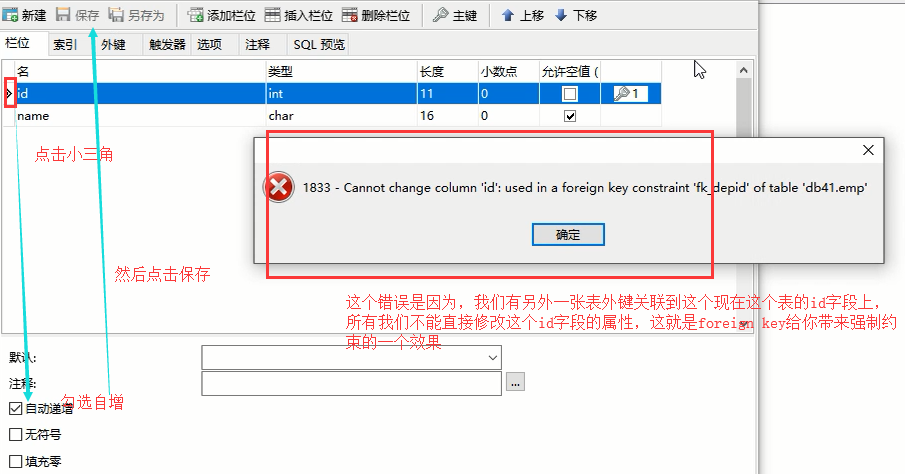
那我们该怎么办呢,直接删除这个表然后重新创建吗?你另外一个关联表肯定不让你这么做,所以你需要先将那个关联表的外键关系先取消,或者先将那个外键关联表删除
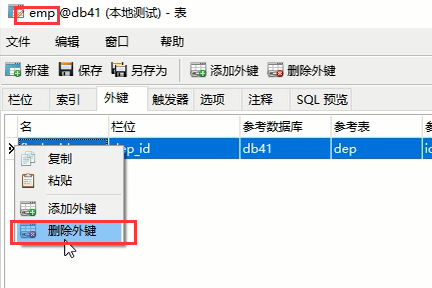
然后把这个关联表的外键删除,然后保存
然后再去我们想给id字段加上自增的那个dep表里面把id字段设置为自增,保存,然后在重新将emp表外键到dep的id字段上
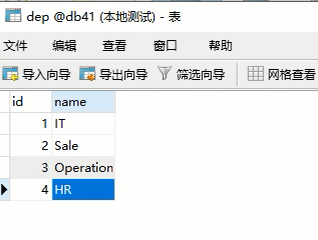
然后给dep表插入几条数据
这个工具还能将你的表之间的关系通过图形的形式来给你展示:
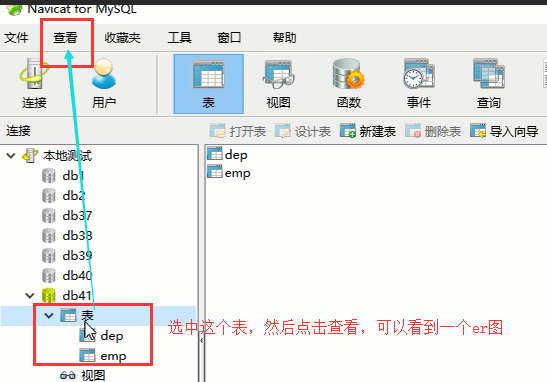
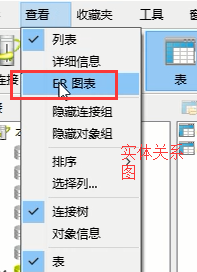
点击这个ER图,两者的关系图就显示出来了,那么将来你的表很多的时候,你就可以通过这个图来查看自己表和表之间的关系,看效果:
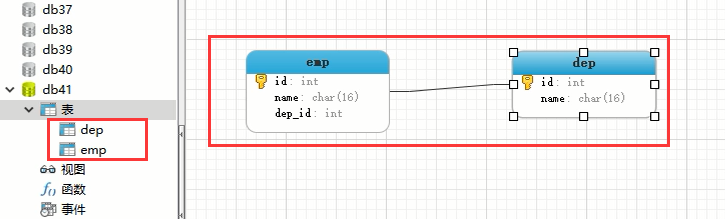
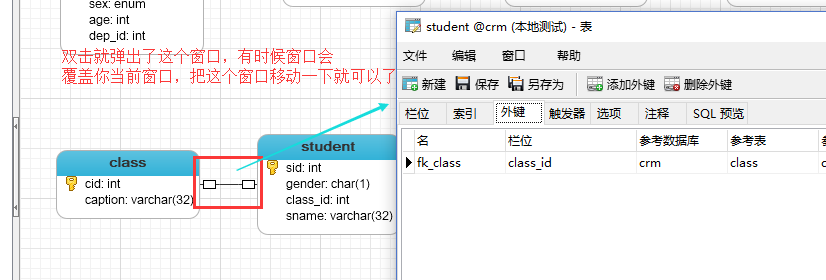
如果我们点击两个表之间的线,是可以看到两者之间的关系的:
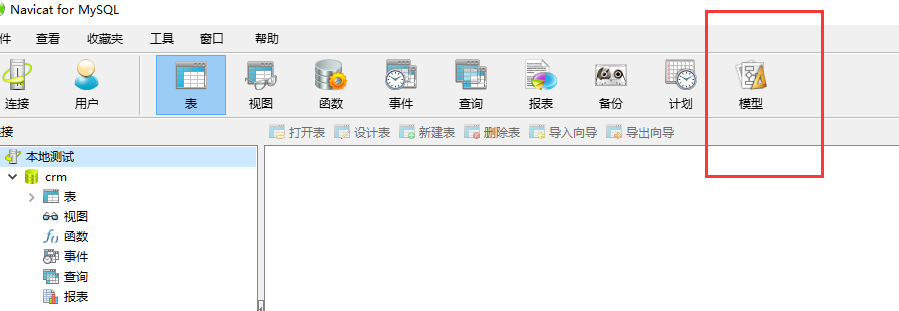
还可以选择上面的模型来直接创作图表,创建表之间的关系
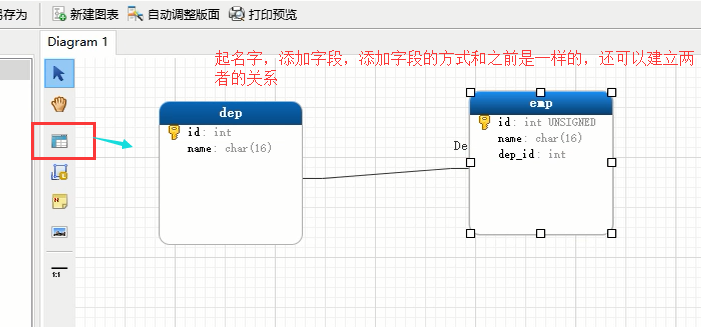
但是上面我们建立的这个模型,是不能直接创建到数据库里面的,需要将它以sql的形式导入,然后把导出的sql语句,到数据库里面去执行
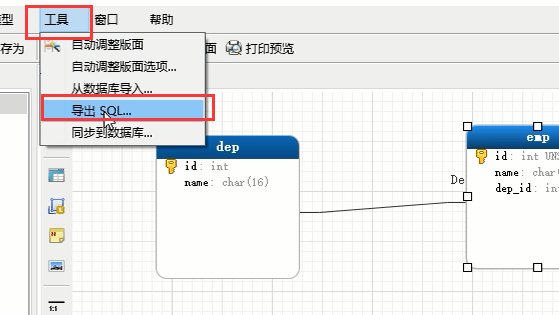
然后导出保存到一个地方
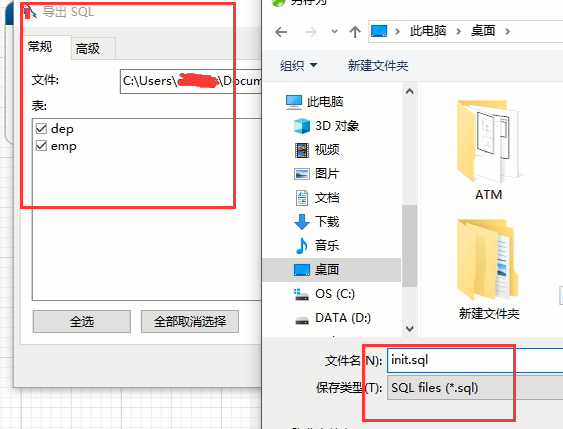
打开我们导出的文件,看一下里面的内容

你看,就是咱们创建的模型翻译成的sql语句,复制一下这些sql语句,但mysql里面去执行一下,就等到我们模型里面的两个表了,是不是很方便
Navicat工具还能写原生sql语句来进行数据库的操作
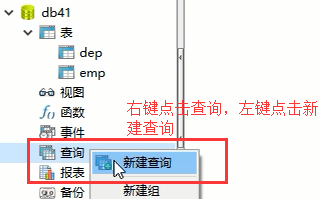
就看到一个输入sql语句的界面了:

然后写一个sql语句试一下:
然后运行一下:
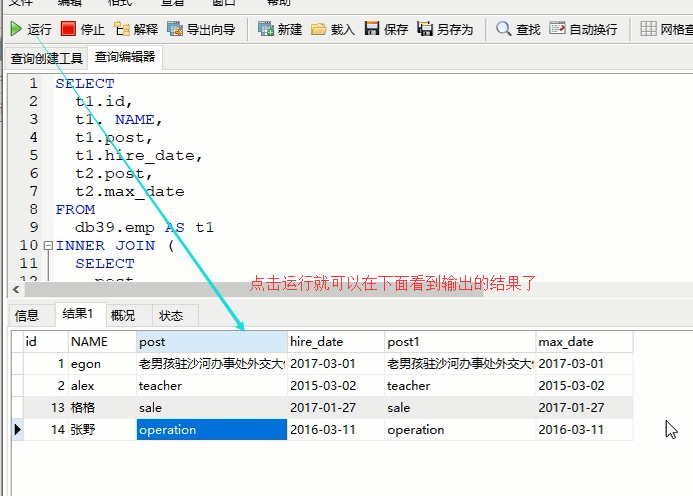
我们还可以将之前数据库中导出来的数据,以sql文件的形式通过navicat导入到数据库中:看步骤
假如我们有一个从数据库中导入的文件,文件名称为init.sql,里面的内容就下面的东东


/* 数据导入: Navicat Premium Data Transfer Source Server : localhost Source Server Type : MySQL Source Server Version : 50624 Source Host : localhost Source Database : sqlexam Target Server Type : MySQL Target Server Version : 50624 File Encoding : utf-8 Date: 10/21/2016 06:46:46 AM */ SET NAMES utf8; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for `class` -- ---------------------------- DROP TABLE IF EXISTS `class`; CREATE TABLE `class` ( `cid` int(11) NOT NULL AUTO_INCREMENT, `caption` varchar(32) NOT NULL, PRIMARY KEY (`cid`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of `class` -- ---------------------------- BEGIN; INSERT INTO `class` VALUES ('1', '三年二班'), ('2', '三年三班'), ('3', '一年二班'), ('4', '二年九班'); COMMIT; -- ---------------------------- -- Table structure for `course` -- ---------------------------- DROP TABLE IF EXISTS `course`; CREATE TABLE `course` ( `cid` int(11) NOT NULL AUTO_INCREMENT, `cname` varchar(32) NOT NULL, `teacher_id` int(11) NOT NULL, PRIMARY KEY (`cid`), KEY `fk_course_teacher` (`teacher_id`), CONSTRAINT `fk_course_teacher` FOREIGN KEY (`teacher_id`) REFERENCES `teacher` (`tid`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of `course` -- ---------------------------- BEGIN; INSERT INTO `course` VALUES ('1', '生物', '1'), ('2', '物理', '2'), ('3', '体育', '3'), ('4', '美术', '2'); COMMIT; -- ---------------------------- -- Table structure for `score` -- ---------------------------- DROP TABLE IF EXISTS `score`; CREATE TABLE `score` ( `sid` int(11) NOT NULL AUTO_INCREMENT, `student_id` int(11) NOT NULL, `course_id` int(11) NOT NULL, `num` int(11) NOT NULL, PRIMARY KEY (`sid`), KEY `fk_score_student` (`student_id`), KEY `fk_score_course` (`course_id`), CONSTRAINT `fk_score_course` FOREIGN KEY (`course_id`) REFERENCES `course` (`cid`), CONSTRAINT `fk_score_student` FOREIGN KEY (`student_id`) REFERENCES `student` (`sid`) ) ENGINE=InnoDB AUTO_INCREMENT=53 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of `score` -- ---------------------------- BEGIN; INSERT INTO `score` VALUES ('1', '1', '1', '10'), ('2', '1', '2', '9'), ('5', '1', '4', '66'), ('6', '2', '1', '8'), ('8', '2', '3', '68'), ('9', '2', '4', '99'), ('10', '3', '1', '77'), ('11', '3', '2', '66'), ('12', '3', '3', '87'), ('13', '3', '4', '99'), ('14', '4', '1', '79'), ('15', '4', '2', '11'), ('16', '4', '3', '67'), ('17', '4', '4', '100'), ('18', '5', '1', '79'), ('19', '5', '2', '11'), ('20', '5', '3', '67'), ('21', '5', '4', '100'), ('22', '6', '1', '9'), ('23', '6', '2', '100'), ('24', '6', '3', '67'), ('25', '6', '4', '100'), ('26', '7', '1', '9'), ('27', '7', '2', '100'), ('28', '7', '3', '67'), ('29', '7', '4', '88'), ('30', '8', '1', '9'), ('31', '8', '2', '100'), ('32', '8', '3', '67'), ('33', '8', '4', '88'), ('34', '9', '1', '91'), ('35', '9', '2', '88'), ('36', '9', '3', '67'), ('37', '9', '4', '22'), ('38', '10', '1', '90'), ('39', '10', '2', '77'), ('40', '10', '3', '43'), ('41', '10', '4', '87'), ('42', '11', '1', '90'), ('43', '11', '2', '77'), ('44', '11', '3', '43'), ('45', '11', '4', '87'), ('46', '12', '1', '90'), ('47', '12', '2', '77'), ('48', '12', '3', '43'), ('49', '12', '4', '87'), ('52', '13', '3', '87'); COMMIT; -- ---------------------------- -- Table structure for `student` -- ---------------------------- DROP TABLE IF EXISTS `student`; CREATE TABLE `student` ( `sid` int(11) NOT NULL AUTO_INCREMENT, `gender` char(1) NOT NULL, `class_id` int(11) NOT NULL, `sname` varchar(32) NOT NULL, PRIMARY KEY (`sid`), KEY `fk_class` (`class_id`), CONSTRAINT `fk_class` FOREIGN KEY (`class_id`) REFERENCES `class` (`cid`) ) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of `student` -- ---------------------------- BEGIN; INSERT INTO `student` VALUES ('1', '男', '1', '理解'), ('2', '女', '1', '钢蛋'), ('3', '男', '1', '张三'), ('4', '男', '1', '张一'), ('5', '女', '1', '张二'), ('6', '男', '1', '张四'), ('7', '女', '2', '铁锤'), ('8', '男', '2', '李三'), ('9', '男', '2', '李一'), ('10', '女', '2', '李二'), ('11', '男', '2', '李四'), ('12', '女', '3', '如花'), ('13', '男', '3', '刘三'), ('14', '男', '3', '刘一'), ('15', '女', '3', '刘二'), ('16', '男', '3', '刘四'); COMMIT; -- ---------------------------- -- Table structure for `teacher` -- ---------------------------- DROP TABLE IF EXISTS `teacher`; CREATE TABLE `teacher` ( `tid` int(11) NOT NULL AUTO_INCREMENT, `tname` varchar(32) NOT NULL, PRIMARY KEY (`tid`) ) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of `teacher` -- ---------------------------- BEGIN; INSERT INTO `teacher` VALUES ('1', '张磊老师'), ('2', '李平老师'), ('3', '刘海燕老师'), ('4', '朱云海老师'), ('5', '李杰老师'); COMMIT; SET FOREIGN_KEY_CHECKS = 1;
首先我们新建一个库:

然后选择这个数据库,点击右键,选择运行sql文件;
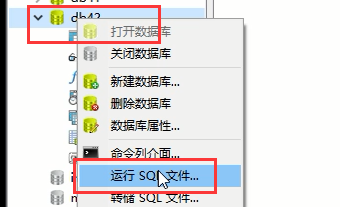
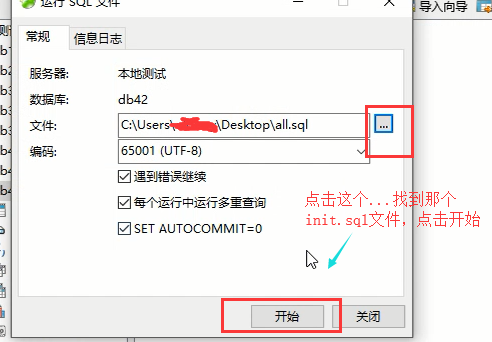
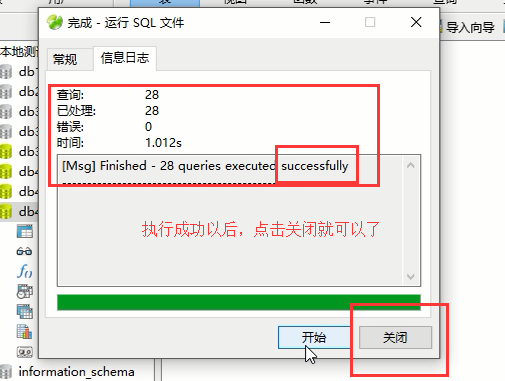
注意上面这一步,直接关闭就可以了,不要再次点击开始了
然后通过ER图,来看看,各个表的关系就看的很清楚了。
我们还可以对sql语句进行注释:选中语句然后ctrl+/就能多行注释,ctrl+shift+/ 就能取消注释
ok,Navicat简单的就介绍完了,大家可以练一练了~~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号